{kind=link}
Kód
plotly::plot_ly(USArrests,
x = ~Murder, y = ~Assault, z = ~Rape,
color = ~UrbanPop,
size = 2) |>
plotly::add_markers()


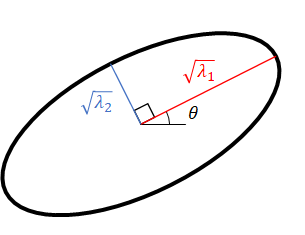
\mathbf{V} = \begin{pmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{pmatrix}
plotly::plot_ly(USArrests,
x = ~Murder, y = ~Assault, z = ~Rape,
color = ~UrbanPop,
size = 2) |>
plotly::add_markers()c("mean", "var") |>
sapply(function(x) apply(USArrests, 2, FUN = x)) |>
t() |> round(1) Murder Assault UrbanPop Rape
mean 7.8 170.8 65.5 21.2
var 19.0 6945.2 209.5 87.7# manuálny výpočet:
# USArrests |> cor() |> eigen() |> getElement("values") |> sqrt() # std.dev.
# V <- USArrests |> cor() |> eigen() |> getElement("vectors") # loadings
# Z <- USArrests |> as.matrix() |> apply(2, scale) |> (`%*%`)(V) # scores
# automatika:
fit <- prcomp(USArrests, scale = TRUE)
fit$rotation |> round(3) PC1 PC2 PC3 PC4
Murder -0.536 -0.418 0.341 0.649
Assault -0.583 -0.188 0.268 -0.743
UrbanPop -0.278 0.873 0.378 0.134
Rape -0.543 0.167 -0.818 0.089fit$x |> head() |> round(2) PC1 PC2 PC3 PC4
Alabama -0.98 -1.12 0.44 0.15
Alaska -1.93 -1.06 -2.02 -0.43
Arizona -1.75 0.74 -0.05 -0.83
Arkansas 0.14 -1.11 -0.11 -0.18
California -2.50 1.53 -0.59 -0.34
Colorado -1.50 0.98 -1.08 0.00biplot(fit, scale = 0, cex = 0.7) # scale=0 aby šípky zodpovedali záťažiam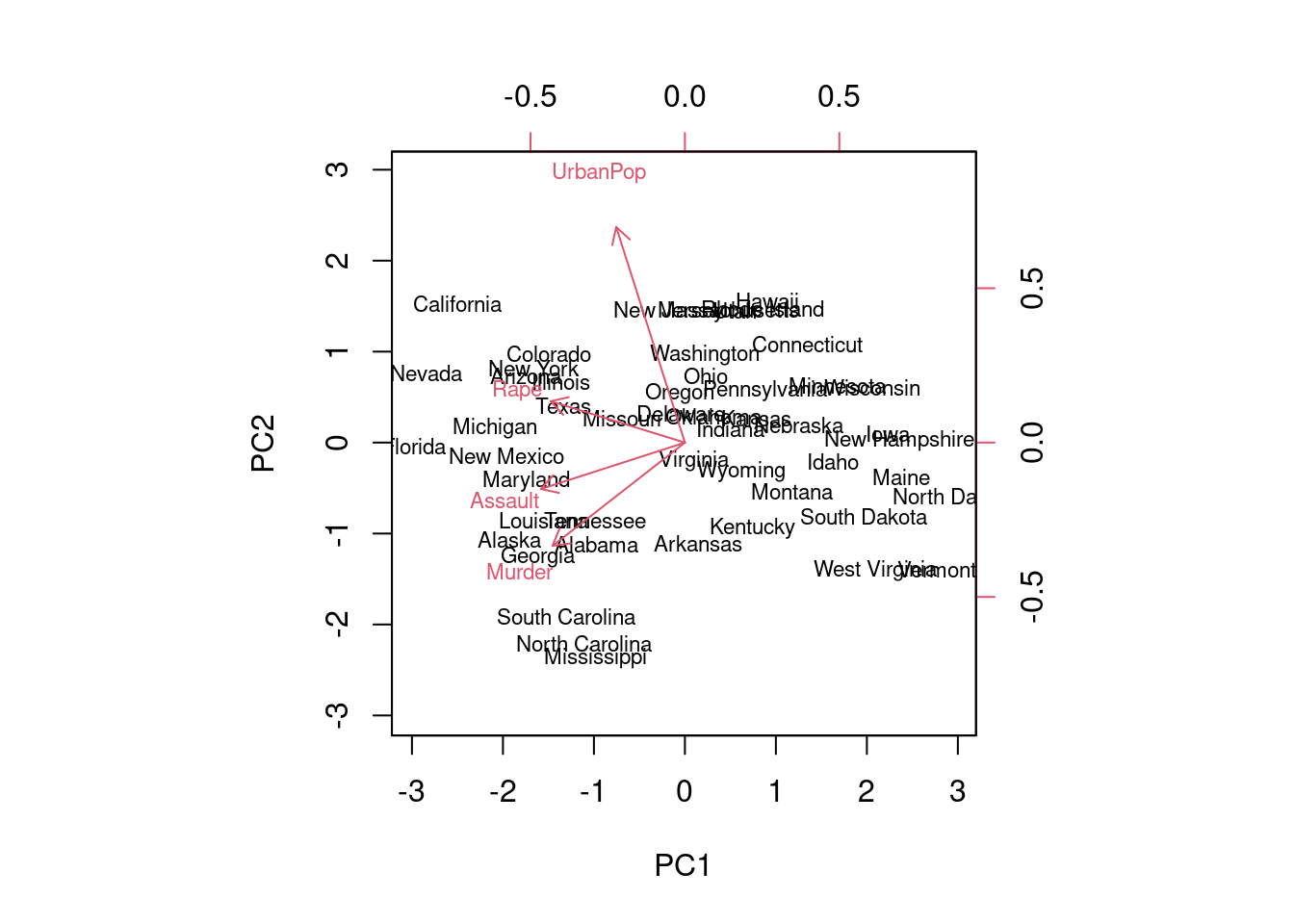
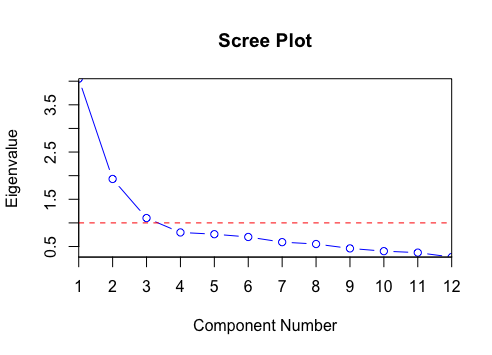
screeplot(fit, type = "lines", main = "")
abline(h = 1, lty = 2)
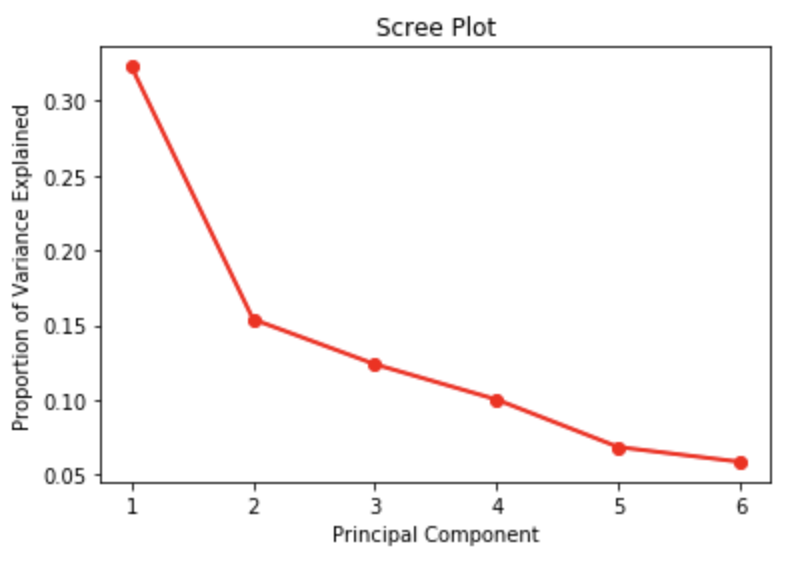
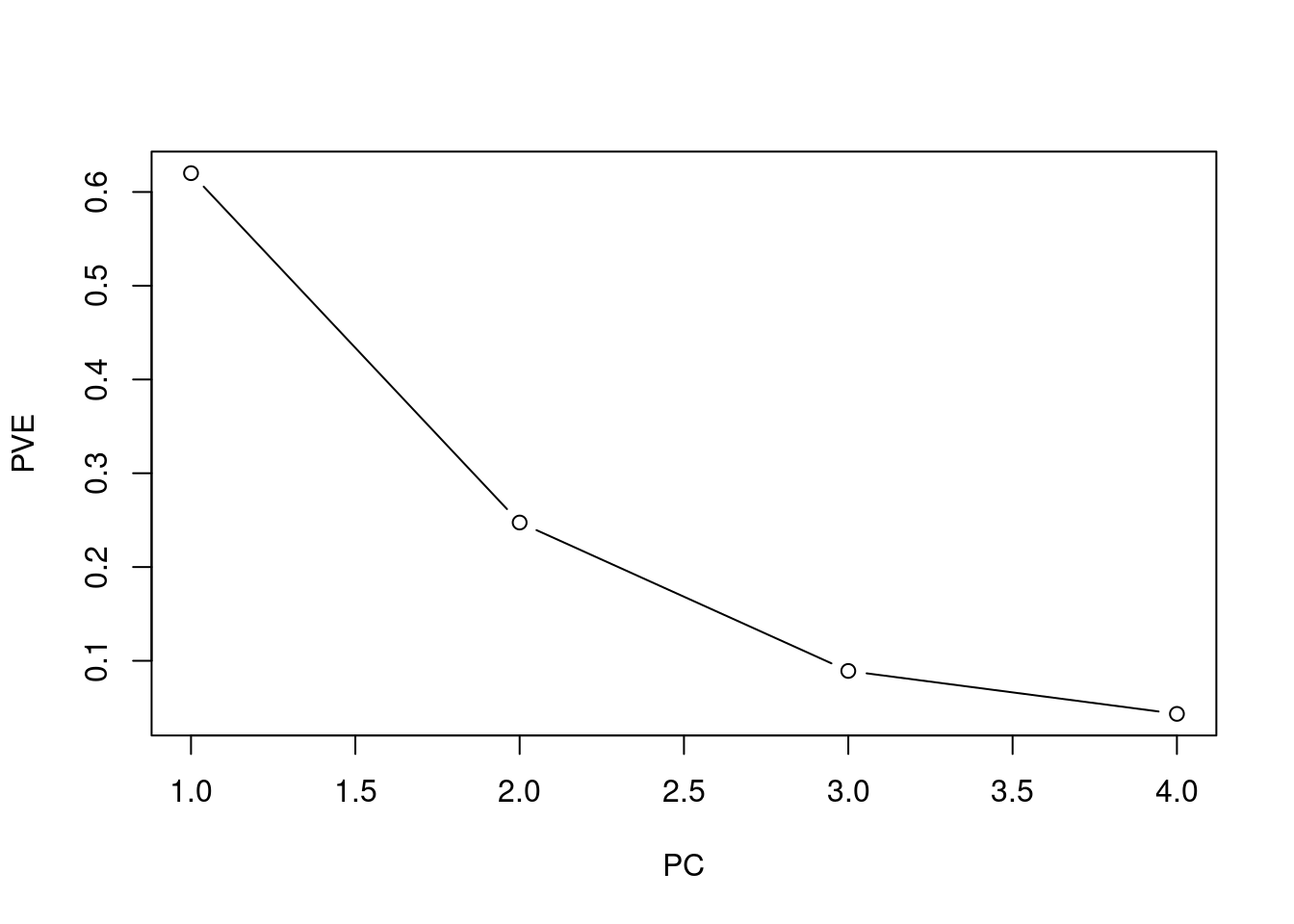
plot(fit$sdev^2 / sum(fit$sdev^2), type = "b", ylab = "PVE", xlab = "PC")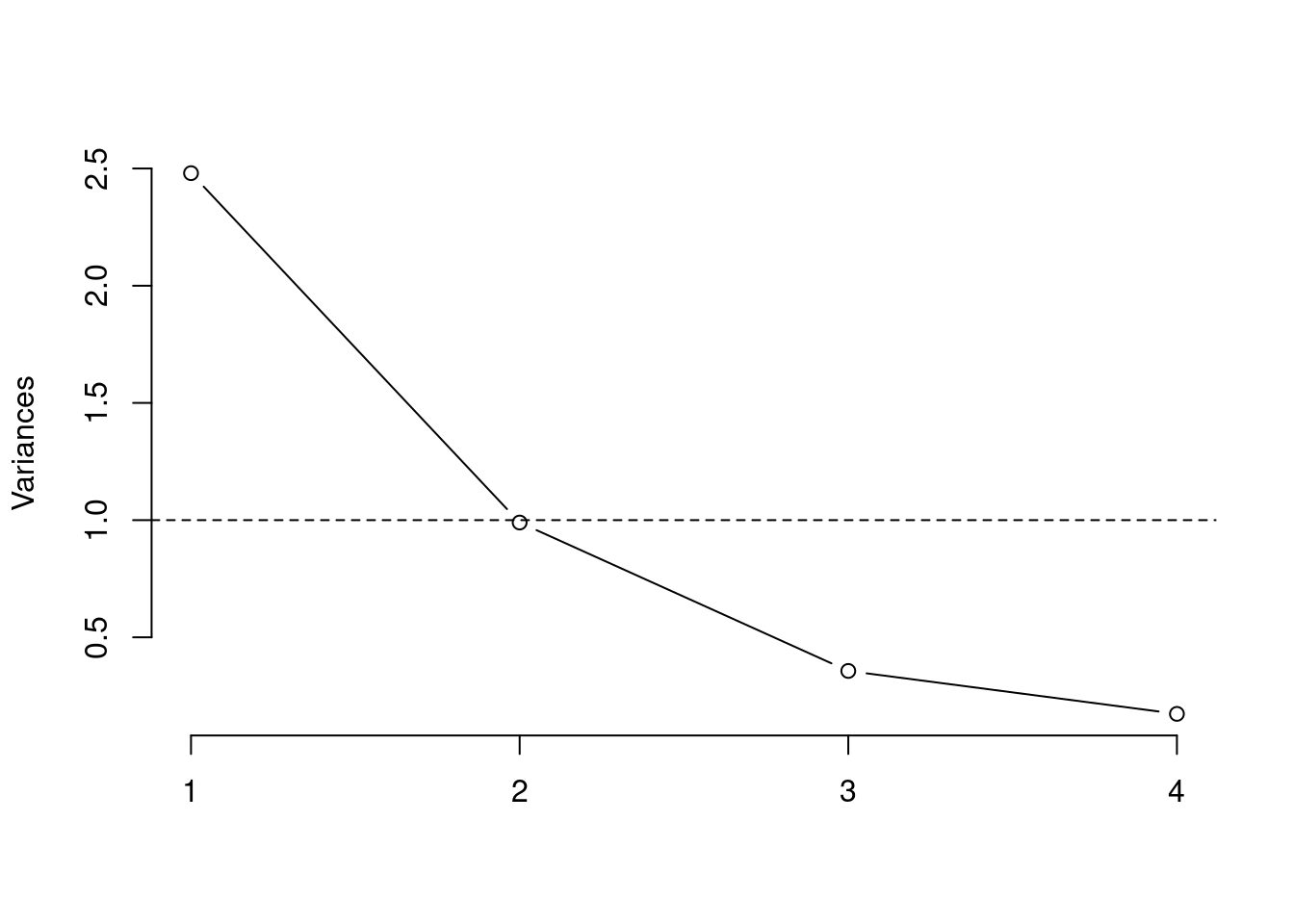

Jednoduchá a elegantná metóda.
Počet tried K treba definovať vopred.
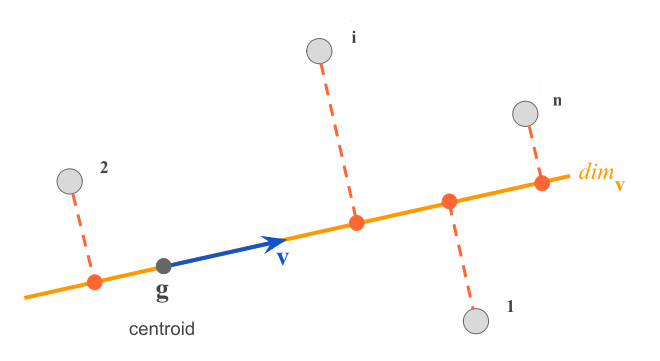
Matematicky je problém formulovaný nasledovne: ak C_1,\ldots,C_K označujú množiny indexov objektov (pozorovaní) v každom zhluku, pričom
čiže každý objekt patrí práve do jedného zhluku, potom cieľom je minimalizovať vnútro-zhlukový rozptyl W, \underset{C_1,\ldots,C_K}{minimize}\left\{\sum_{k=1}^K W(C_k)\right\},\qquad\text{kde}\quad W(C_k)=\frac1{n_k}\sum_{i\in C_k}\sum_{j=1}^p(x_{ij}-g_{kj})^2, g_{kj}=\frac1{n_k}\sum_{i\in C_k}x_{ij} a použitá bola euklidovská vzdialenosť.
Nájsť presné riešenie je veľmi náročné.
Našťastie existuje jednoduchý algoritmus, ktorým sa dá nájsť celkom dobré riešenie, aj keď predstavuje iba lokálne optimum.
S danými počiatočnými hodnotami centroidov \mathbf{g}_1,\ldots,\mathbf{g}_K sa opakujú nasledujúce kroky:
až kým sa zaradenie v bode 1 nezmení.
Počiatočné hodnoty sa určia buď






# skrátenie výpisu z objektu vráteného funkciou kmeans
print.kmeans <- function (x, ...)
{
cat("K-means clustering with ", length(x$size), " clusters of sizes ",
paste(x$size, collapse = ", "), "\n", sep = "")
cat("\nCluster means:\n")
print(x$centers, ...)
cat("\nClustering vector:\n")
print(head(x$cluster,10), ...)
cat("...\n")
cat("\nWithin cluster sum of squares by cluster:\n")
print(x$withinss, ...)
ratio <- sprintf(" (between_SS / total_SS = %5.1f %%)\n",
100 * x$betweenss/x$totss)
cat(sub(".", getOption("OutDec"), ratio, fixed = TRUE), "Available components:\n",
sep = "\n")
print(names(x))
if (!is.null(x$ifault) && x$ifault == 2L)
cat("Warning: did *not* converge in specified number of iterations\n")
invisible(x)
}dat <- MASS::geyser
fit <- kmeans(dat, centers = 3, nstart = 10)
print(fit) # modifikovaná metóda pre skrátenie niektorých dlhších výpisovK-means clustering with 3 clusters of sizes 123, 99, 77
Cluster means:
waiting duration
1 76.54472 3.218835
2 54.83838 4.438889
3 88.02597 2.589827
Clustering vector:
1 2 3 4 5 6 7 8 9 10
1 1 2 1 1 1 2 3 1 2
...
Within cluster sum of squares by cluster:
[1] 2020.012 2819.925 1444.276
(between_SS / total_SS = 89.1 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault" dat |>
transform(cluster = as.factor(fit$cluster)) |>
ggplot() + aes(x = waiting, y = duration) +
geom_point(aes(color = cluster)) +
geom_point(data = as.data.frame(fit$center), shape = 2)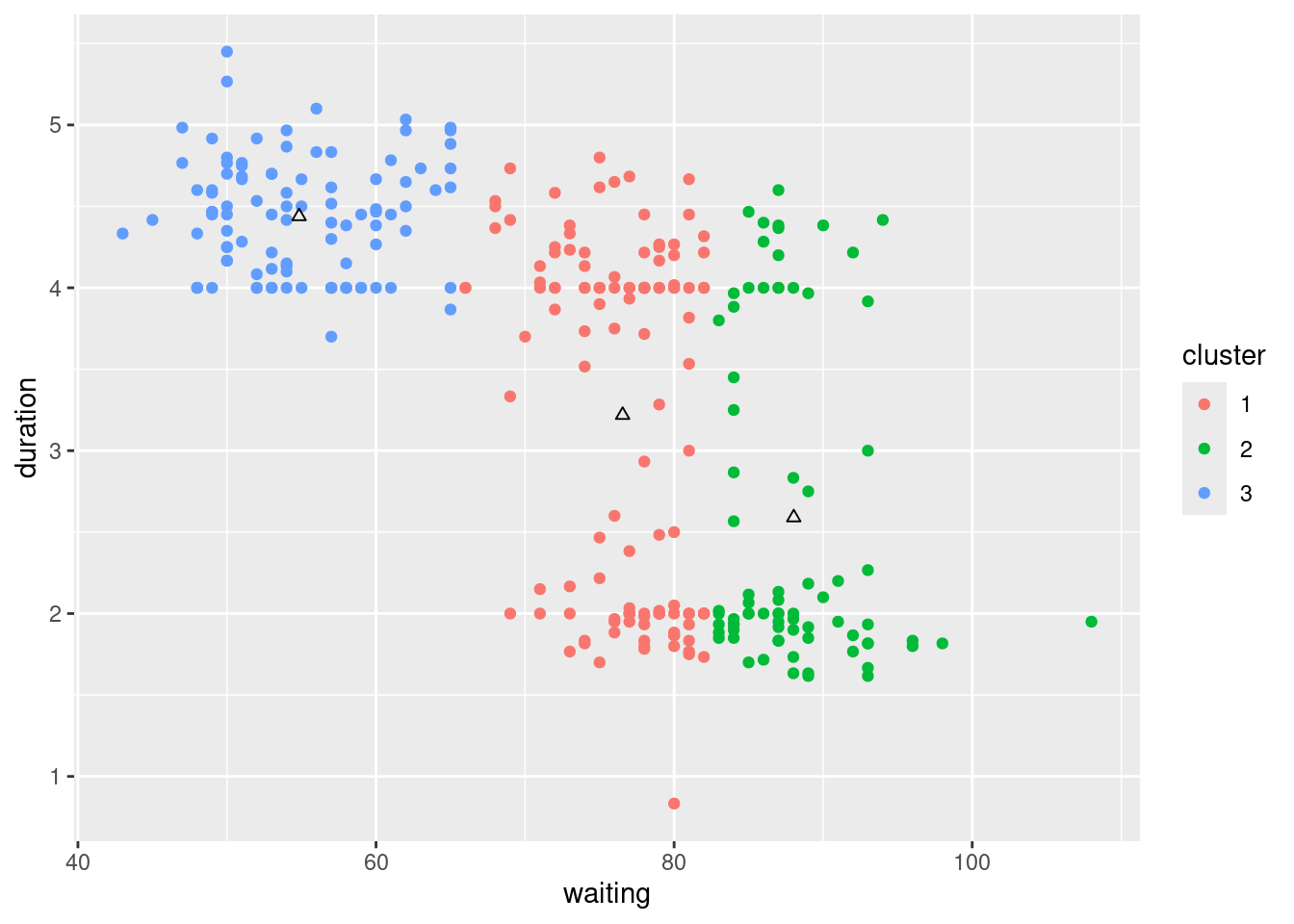
# inverse to function scale()
# - x is matrix or data frame to be unsclaed,
# - scaled is the output of scale()
unscale <- function(x, scaled = x) {
par <- attributes(scaled)[c("scaled:center", "scaled:scale")] |>
setNames(c("mean","sd"))
n <- nrow(x)
x * rep(par$sd, each=n) + rep(par$mean, each=n)
}
# clustering on scaled data
sdat <- MASS::geyser |>
scale()
fit <- kmeans(sdat, centers = 3, nstart = 10)
# plot unscaled data
centroids <- fit$centers |>
unscale(sdat) |>
as.data.frame() |>
tibble::rownames_to_column("cluster")
dat |>
transform(cluster = as.factor(fit$cluster)) |>
ggplot() + aes(x = waiting, y = duration) +
geom_point(aes(color = cluster)) +
geom_point(data = centroids, shape = 13, size = 3, show.legend = FALSE)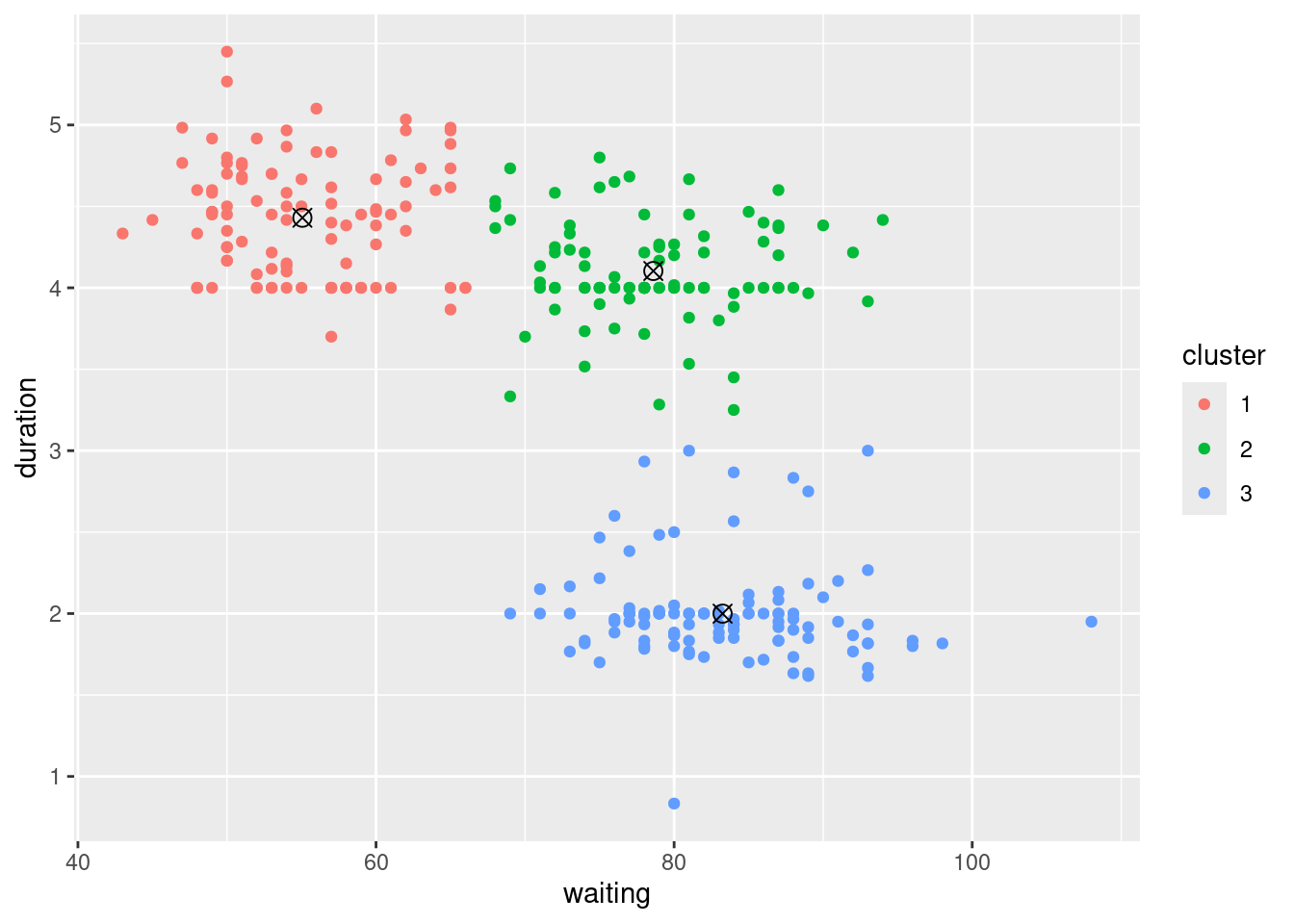
dat1 <- data.frame(
X1 = c(-1.5, -1.4, -1.0, -0.6, -0.1, 0.1, 0.7, 1.3, 1.5),
X2 = c(-0.4, -1.5, -1.1, -1.0, 0.9, -0.8, -0.2, -0.3, 0.0)
)
plot(X2 ~ X1, dat1, asp = 1, type = "n")
text(X2 ~ X1, dat1, labels = row.names(dat1))
fit <- dat1 |>
dist() |> # distance matrix calculation
hclust() # hierarchical clustering
plot(fit, ann = FALSE)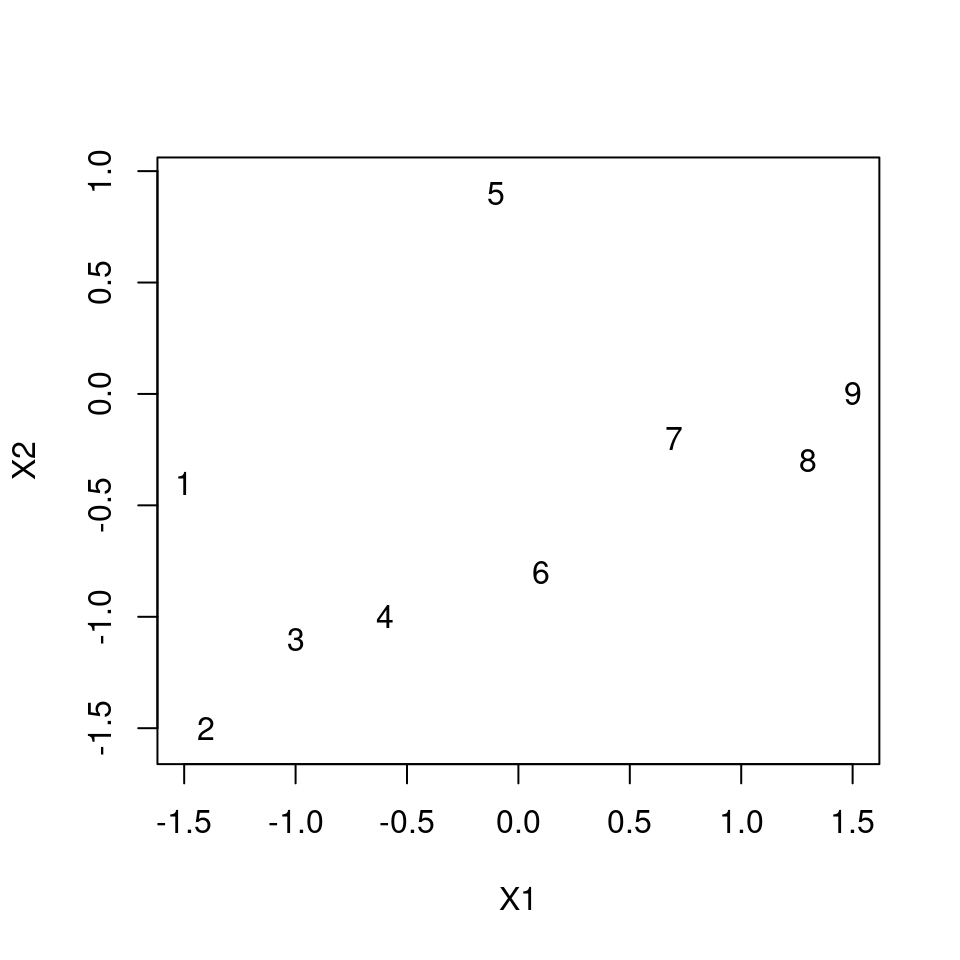
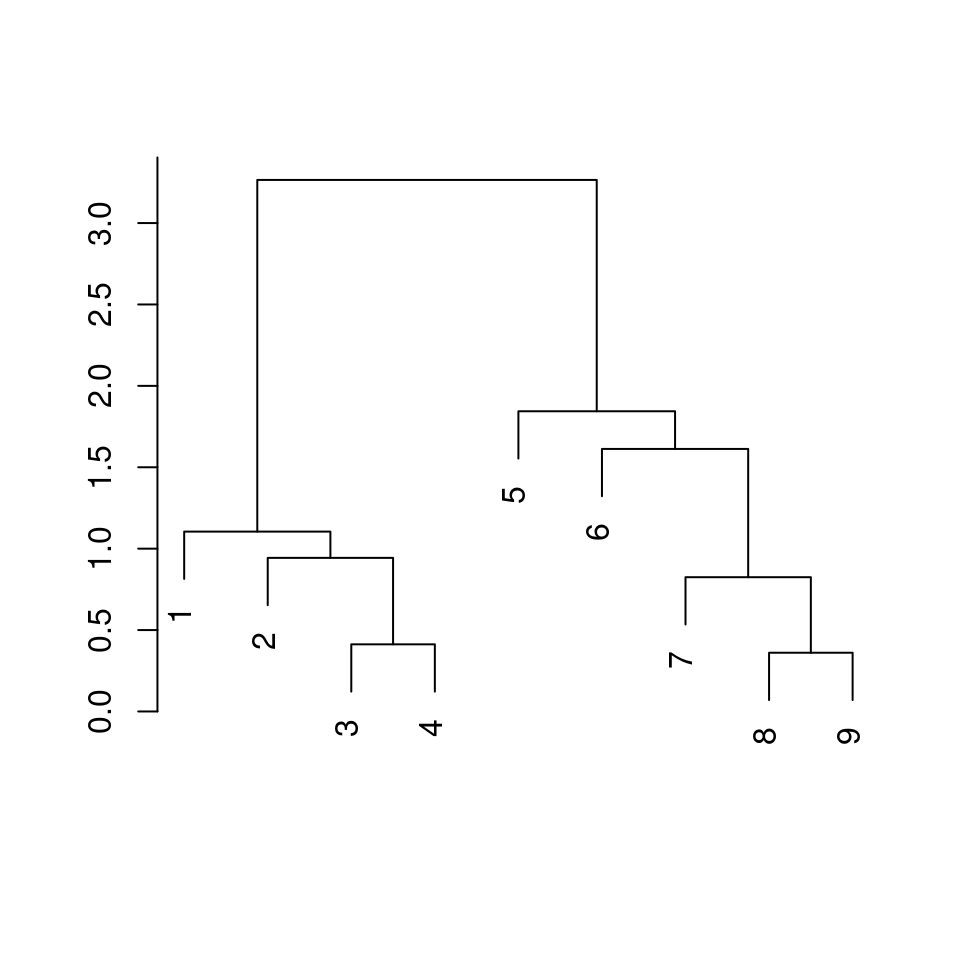
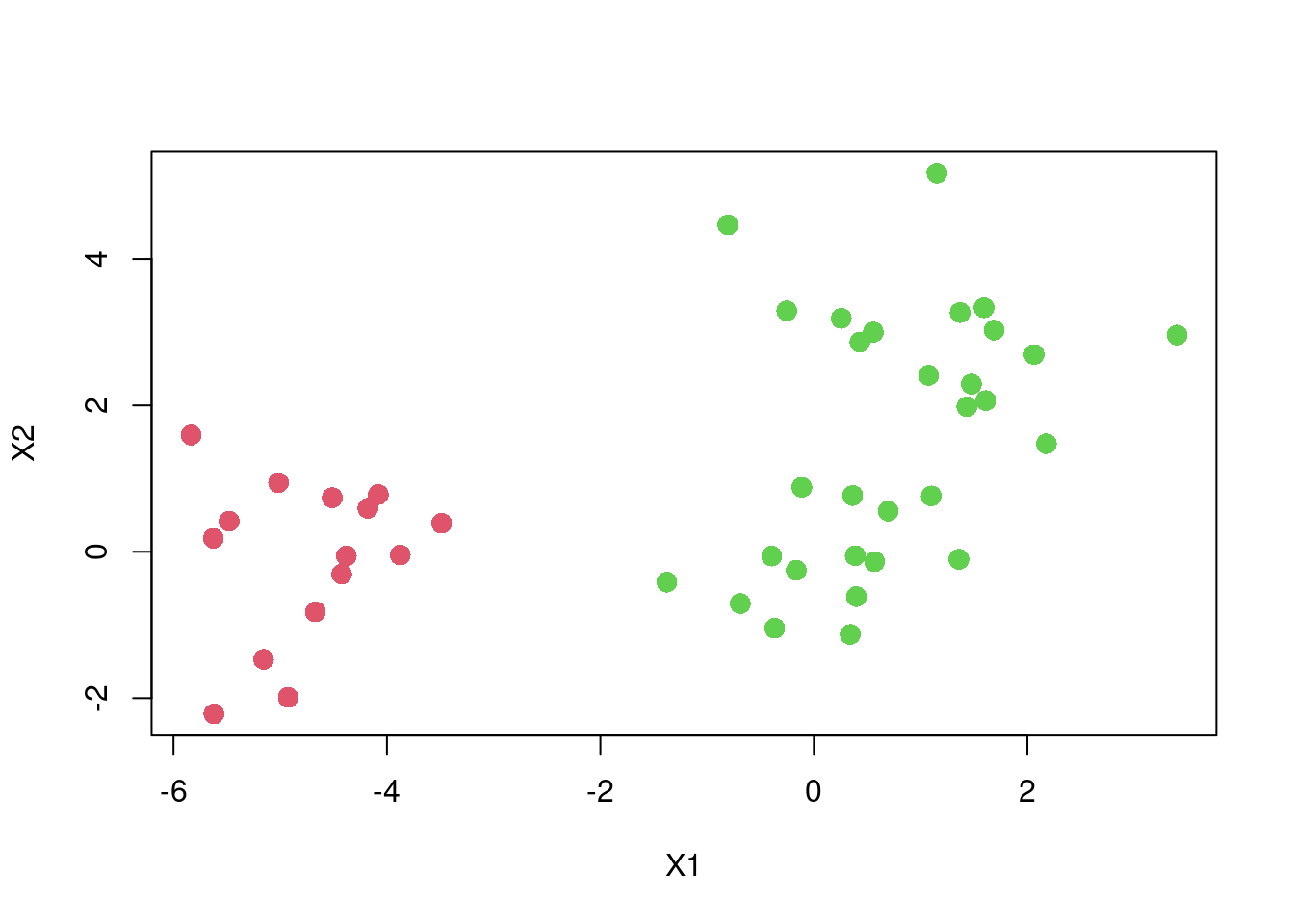
# generate data
set.seed(1)
dat <- list(A = c(-5,0), B = c(0,0), C = c(1,3)) |>
lapply(mvtnorm::rmvnorm, n = 15, sigma = diag(2)) |>
lapply(as.data.frame) |>
lapply(setNames, nm = paste0("X",1:2)) |>
dplyr::bind_rows(.id = "class") |>
dplyr::mutate(class = as.factor(class))
# fit model
fit <- dat |>
dplyr::select(-class) |>
dist() |>
hclust()
# --- visualize result
# basic dendrogram
#fit |>
# plot(hang = -1, cex = 0.6, main="", ylab="")
# cut to get 2 clusters
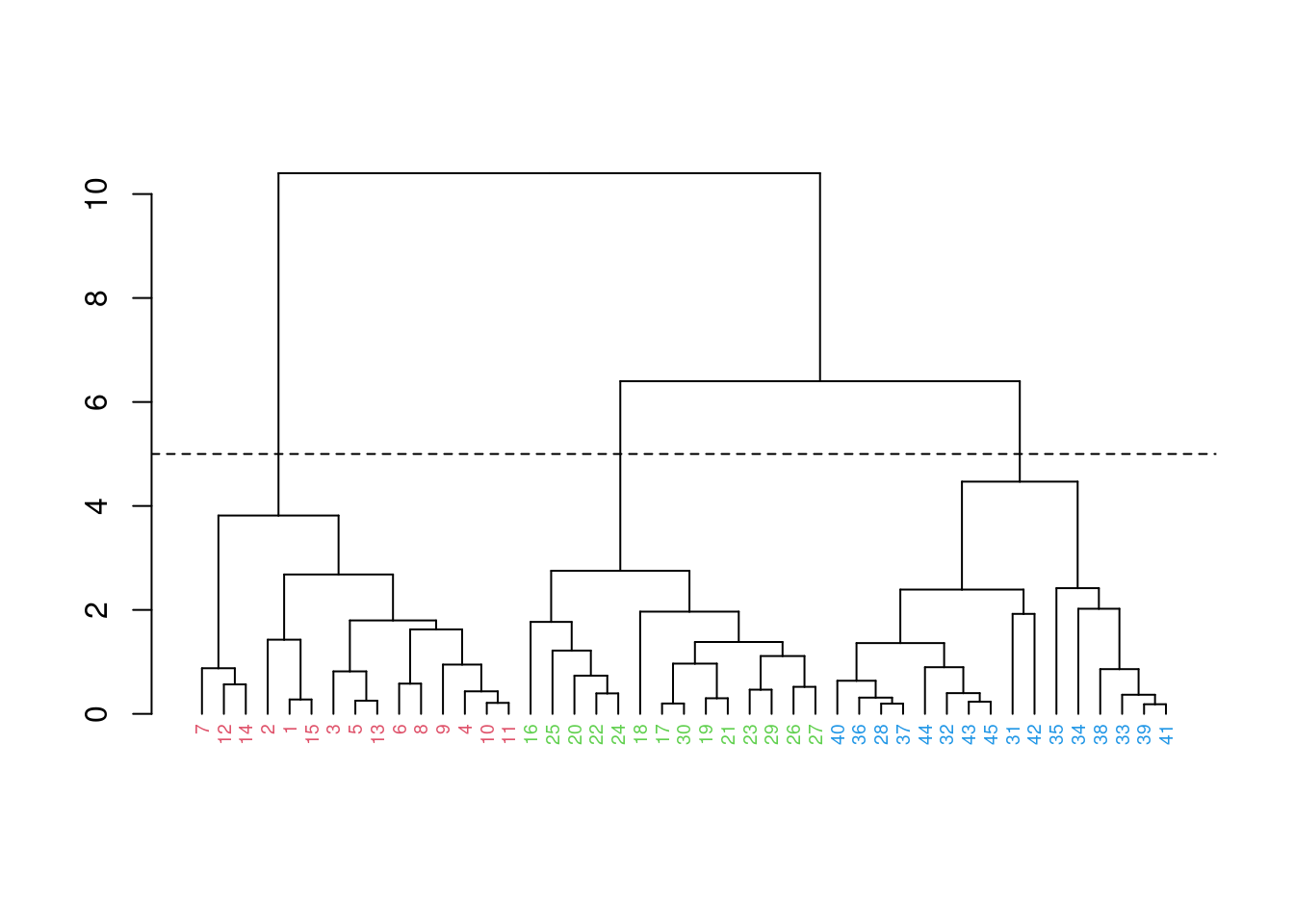
fit |>
as.dendrogram() |>
dendextend::set("labels_col", 2:3, k=2) |>
dendextend::set("labels_cex", 0.6) |>
plot()
abline(h = 8, lty = 2)
# plot with dots or labels
plot(X2 ~ X1, dat,
col = cutree(fit, k = 2) + 1,
pch = 16, cex=1.5)
#plot(X2 ~ X1, dat, type = "n")
#text(X2 ~ X1, dat,
# col = cutree(fit, k = 3) + 1,
# labels = rownames(dat))
# cut to get 3 clusters
fit |>
as.dendrogram() |>
# dendextend::set("branches_k_col", 2:4, k=3) |>
dendextend::set("labels_col", 2:4, k=3) |>
dendextend::set("labels_cex", 0.6) |>
plot()
abline(h = 5, lty = 2)
# plot with dots or labels
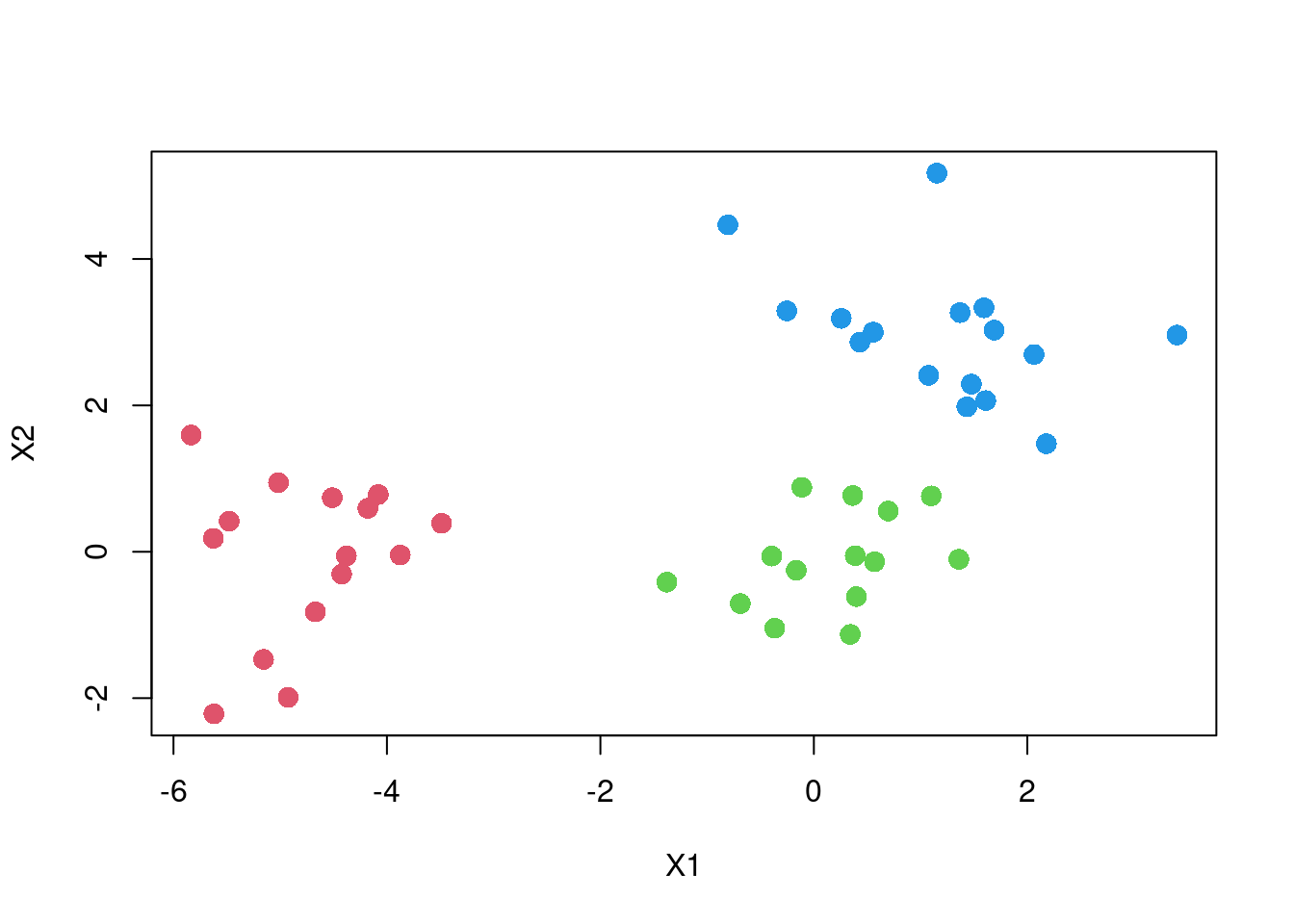
plot(X2 ~ X1, dat,
col = cutree(fit, k = 3) + 1,
pch = 16, cex=1.5)
#plot(X2 ~ X1, dat, type = "n")
#text(X2 ~ X1, dat,
# col = cutree(fit, k = 3) + 1,
# labels = rownames(dat))
# use package dendextend to color leaves and possibly branches
# https://talgalili.github.io/dendextend/articles/dendextend.html
# http://www.sthda.com/english/wiki/beautiful-dendrogram-visualizations-in-r-5-must-known-methods-unsupervised-machine-learning 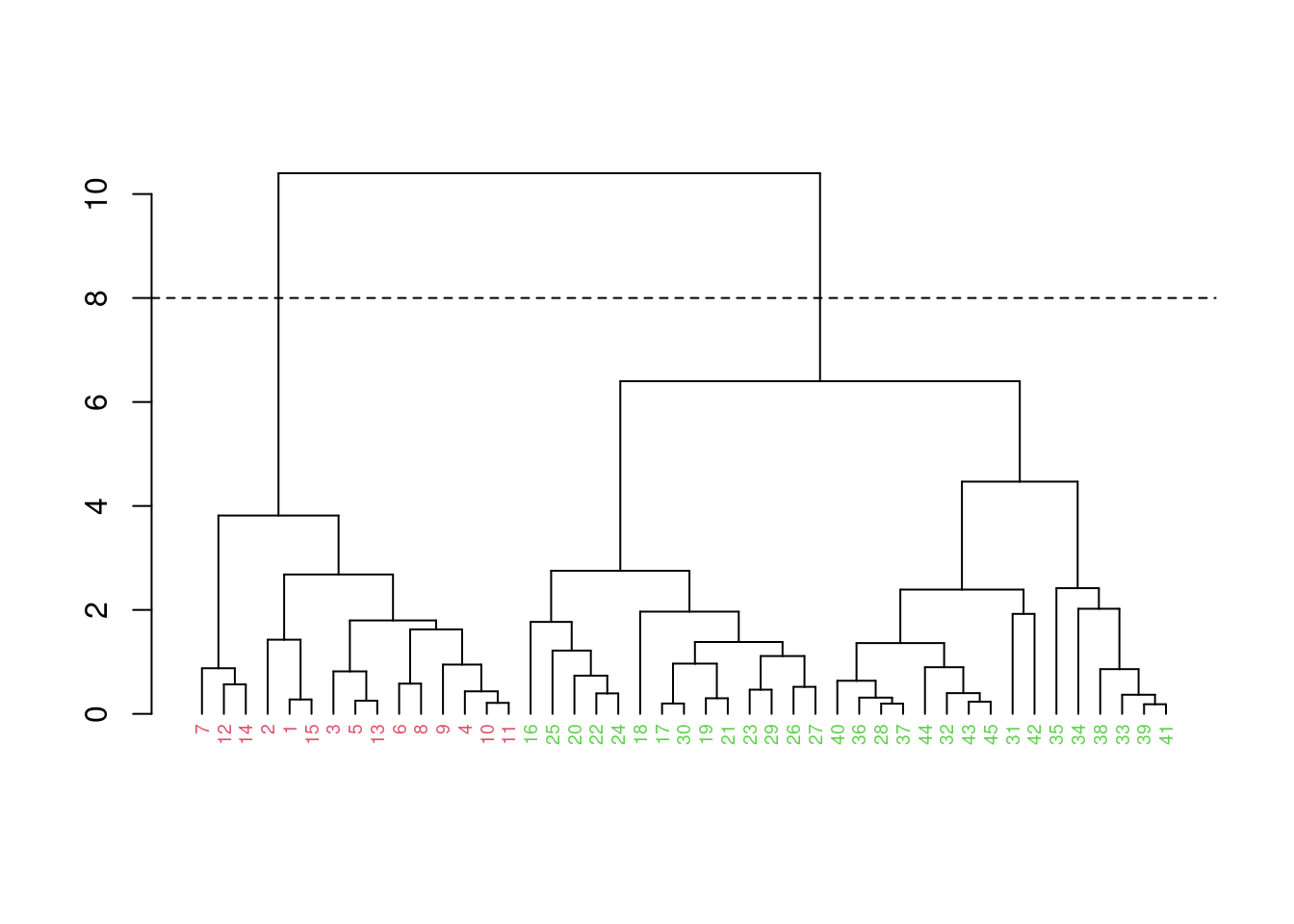
plot(X2 ~ X1, dat1, asp = 1, type = "n")
text(X2 ~ X1, dat1, labels = row.names(dat1))
dat1 |>
dist() |> # distance matrix calculation
hclust(method = "complete") |> # hierarchical clustering
plot(xlab = "", ylab = "", main = "max (complete)", sub = "")
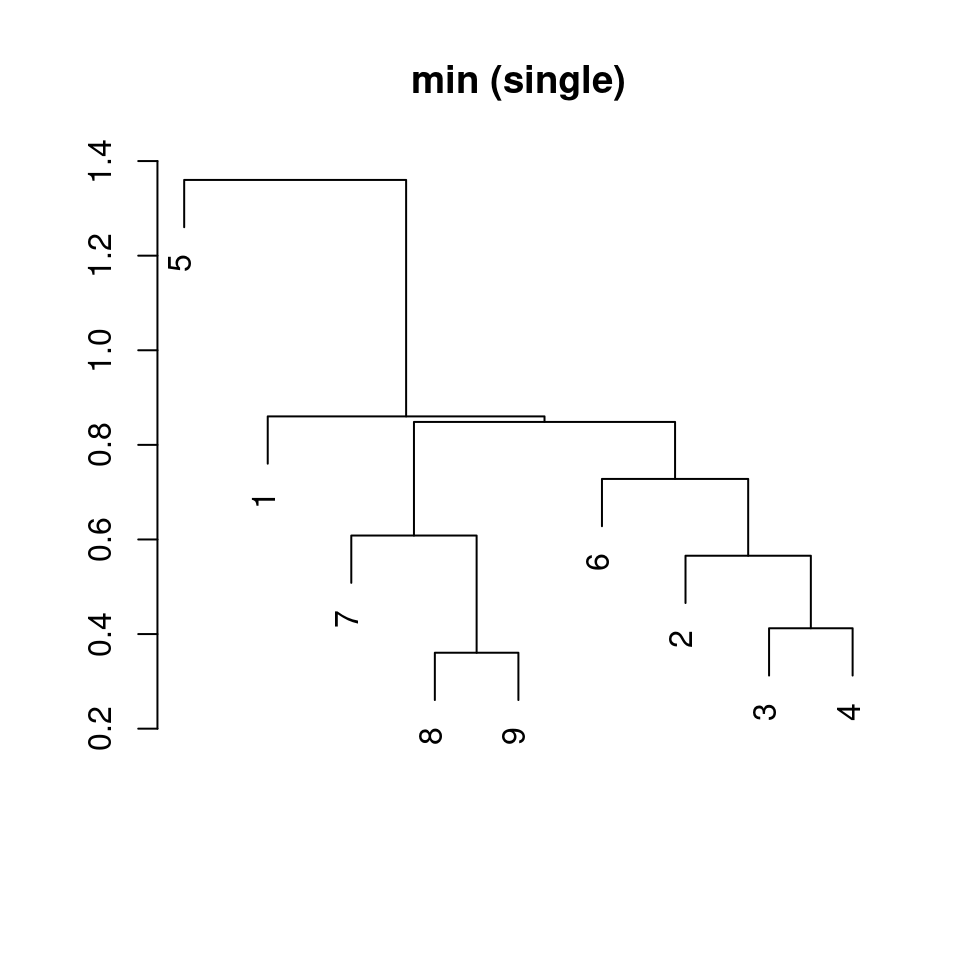
dat1 |>
dist() |> # distance matrix calculation
hclust(method = "single") |> # hierarchical clustering
plot(xlab = "", ylab = "", main = "min (single)", sub = "")
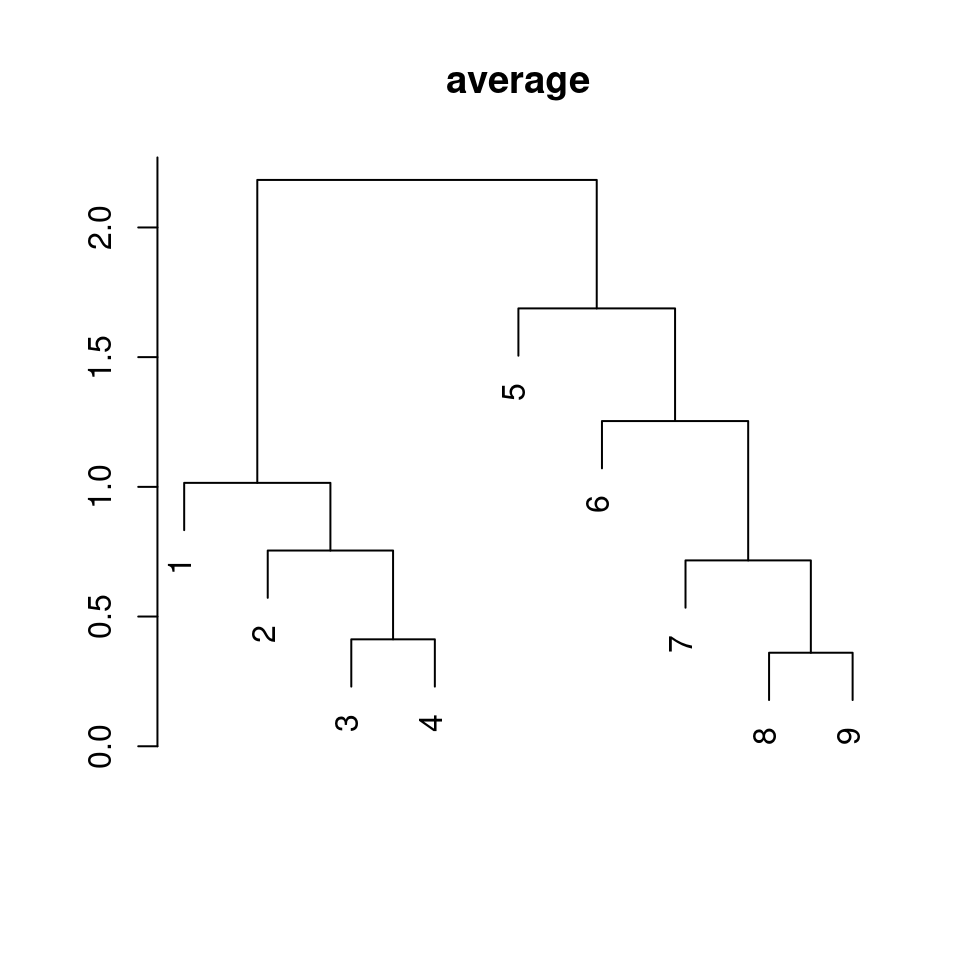
dat1 |>
dist() |> # distance matrix calculation
hclust(method = "average") |> # hierarchical clustering
plot(xlab = "", ylab = "", main = "average", sub = "")
dat1 |>
dist() |> # distance matrix calculation
hclust(method = "centroid") |> # hierarchical clustering
plot(xlab = "", ylab = "", main = "centroid", sub = "")
dat1 |>
dist() |> # distance matrix calculation
hclust(method = "ward.D") |> # hierarchical clustering
plot(xlab = "", ylab = "", main = "Ward", sub = "")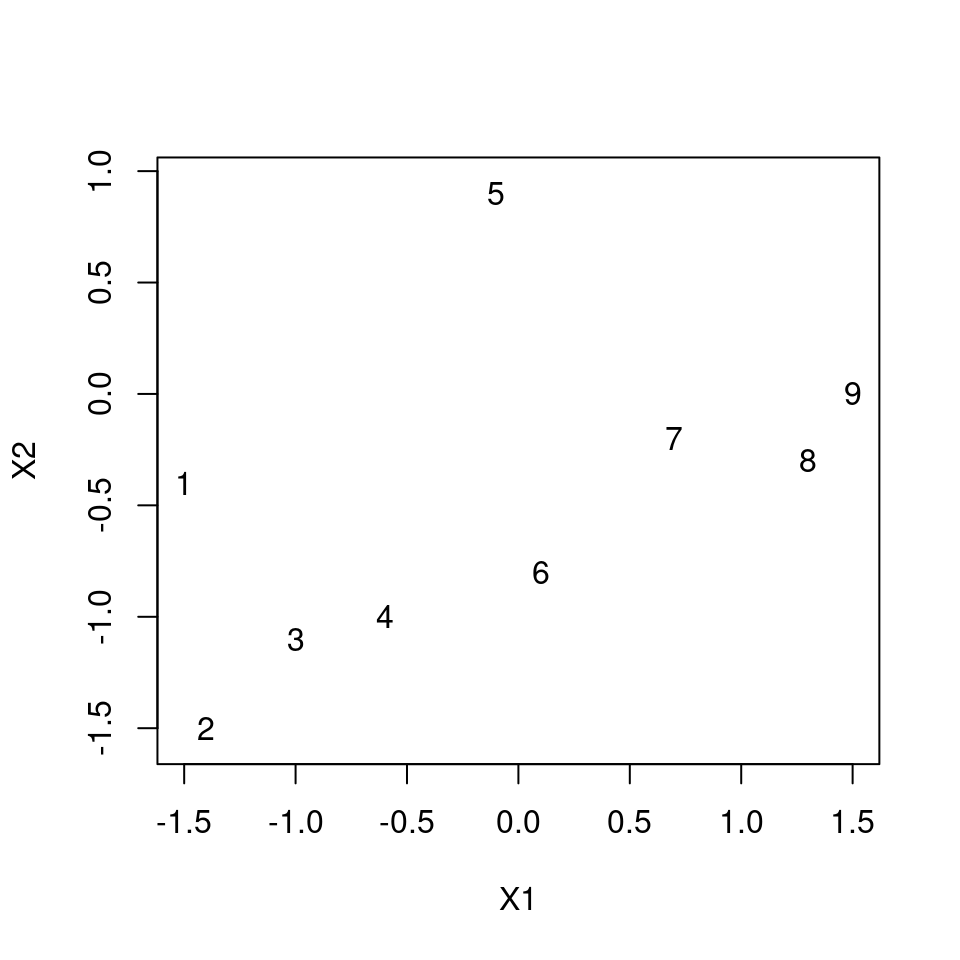
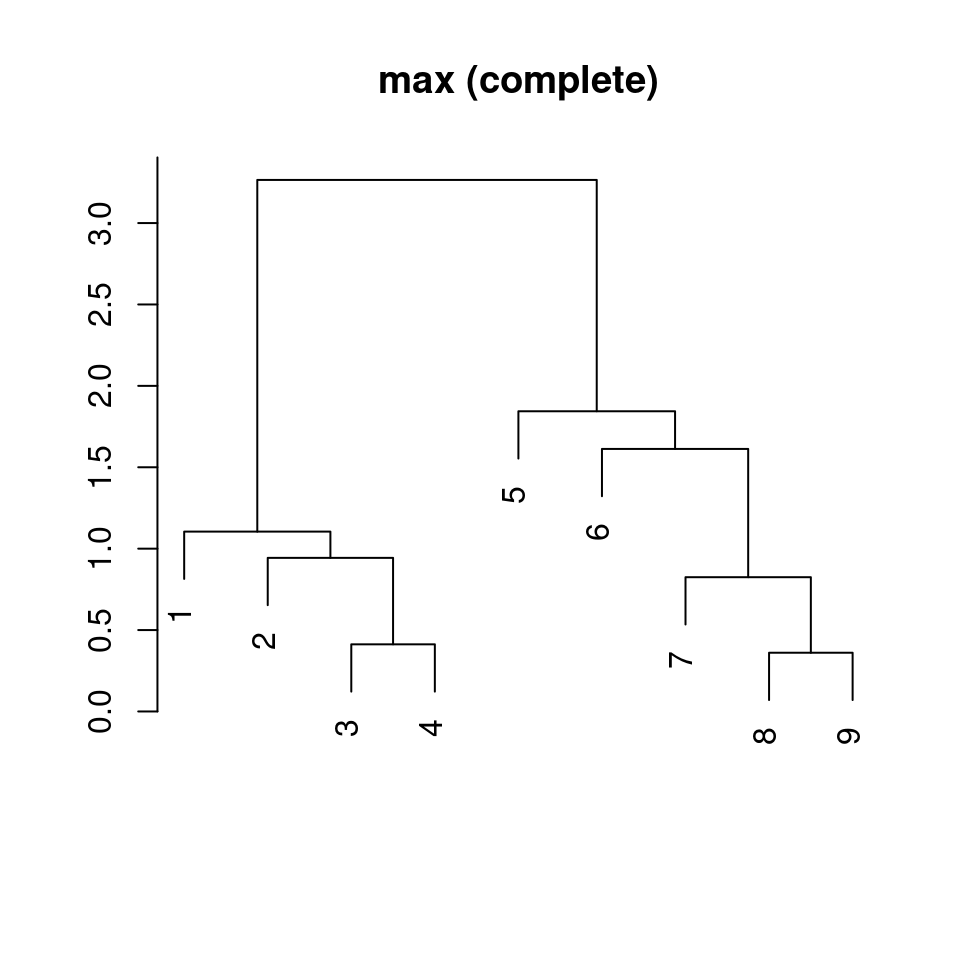
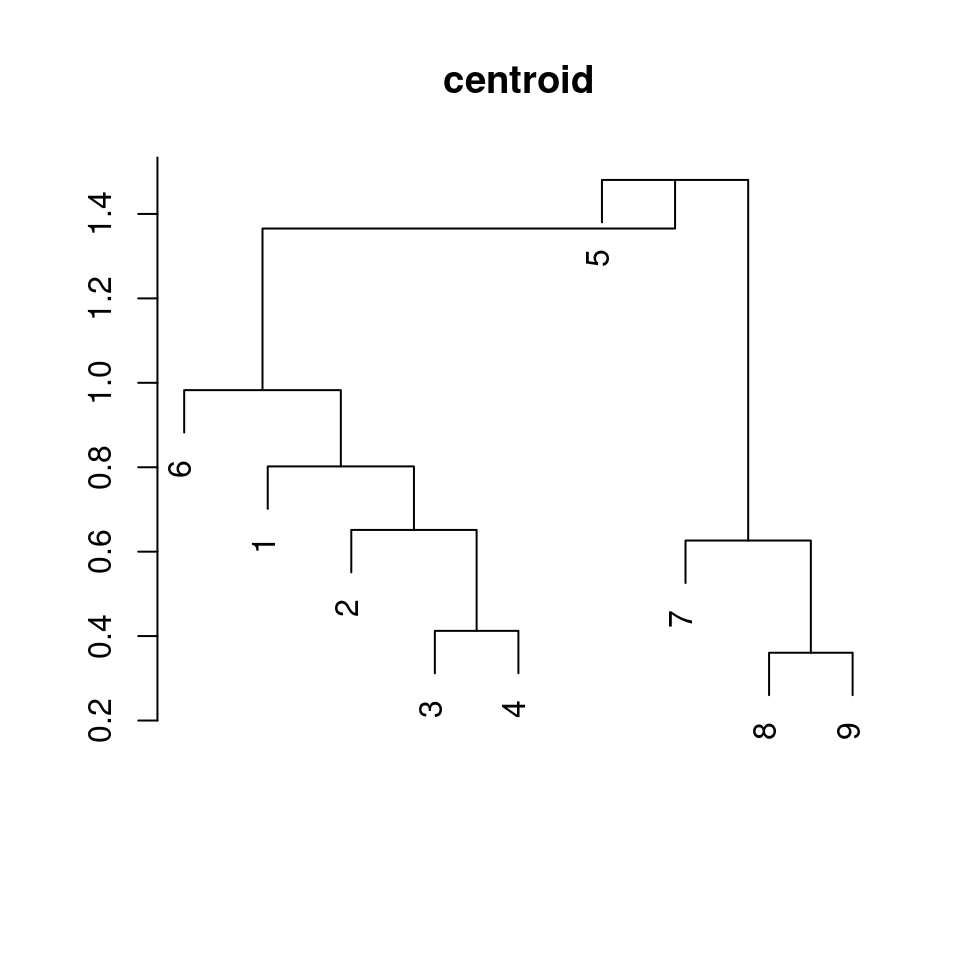
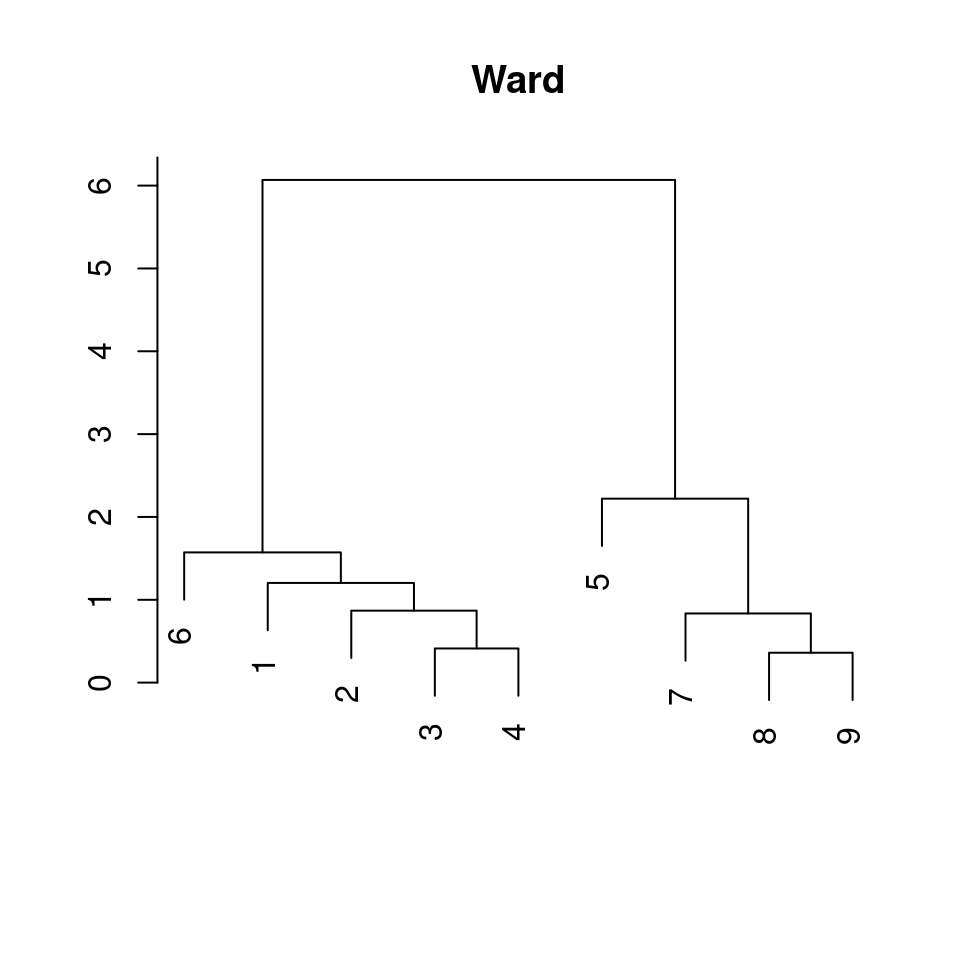
c("complete", "single", "average", "ward") |>
sapply(function(x) cluster::agnes(dat1, method = x)$ac) |>
round(2) |>
rbind(AC = _) complete single average ward
AC 0.73 0.54 0.65 0.8dat <- MASS::geyser
fit <- dat |>
cluster::agnes(stand = TRUE, method = "ward")
plot(fit, which = 2, labels = FALSE)
abline(h=15, lty=2)
#fit |> as.dendrogram() |> plot()
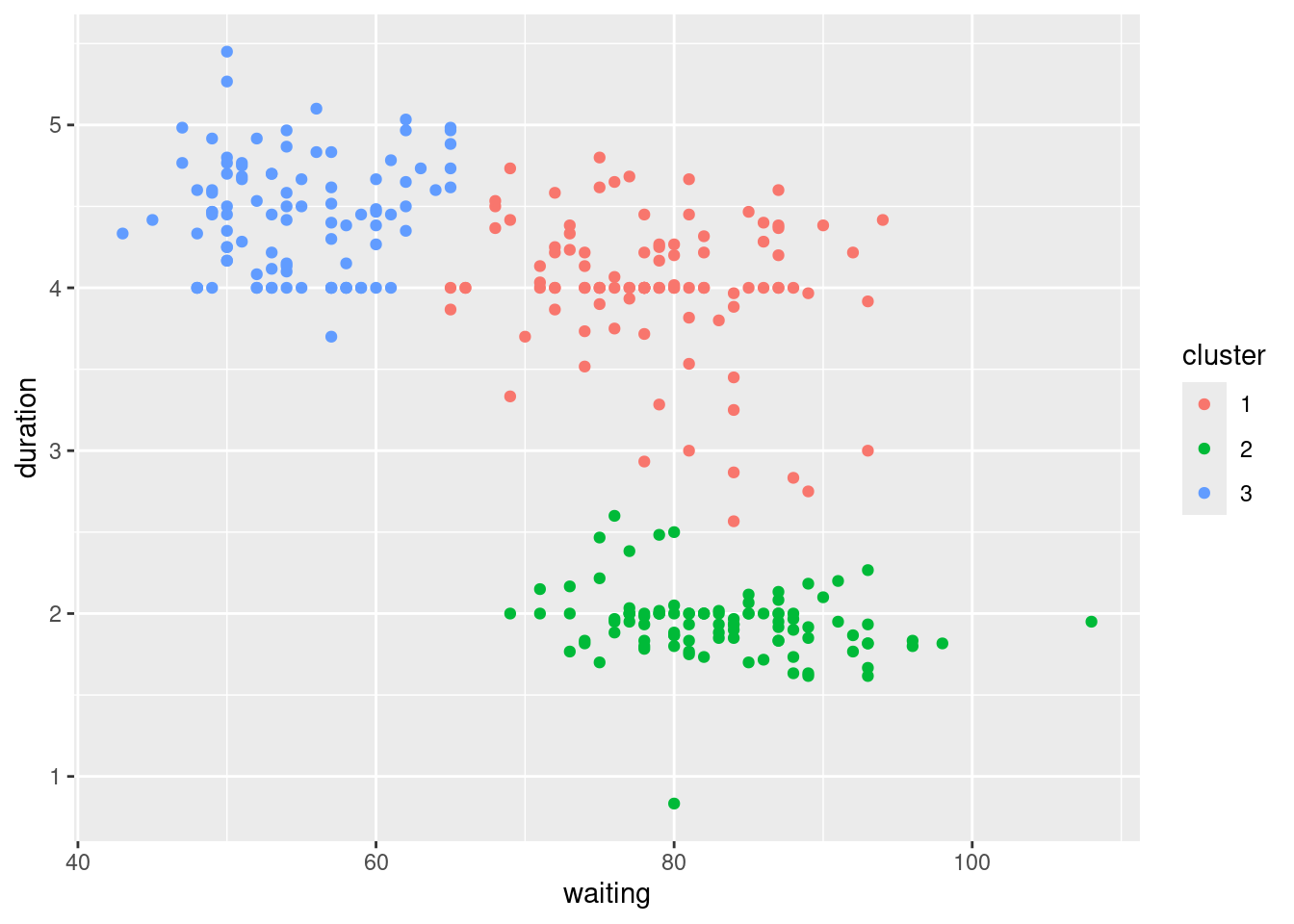
dat |>
transform(
cluster = fit |> cutree(k = 3) |> as.factor()
) |>
ggplot() + aes(x = waiting, y = duration) +
geom_point(aes(color = cluster))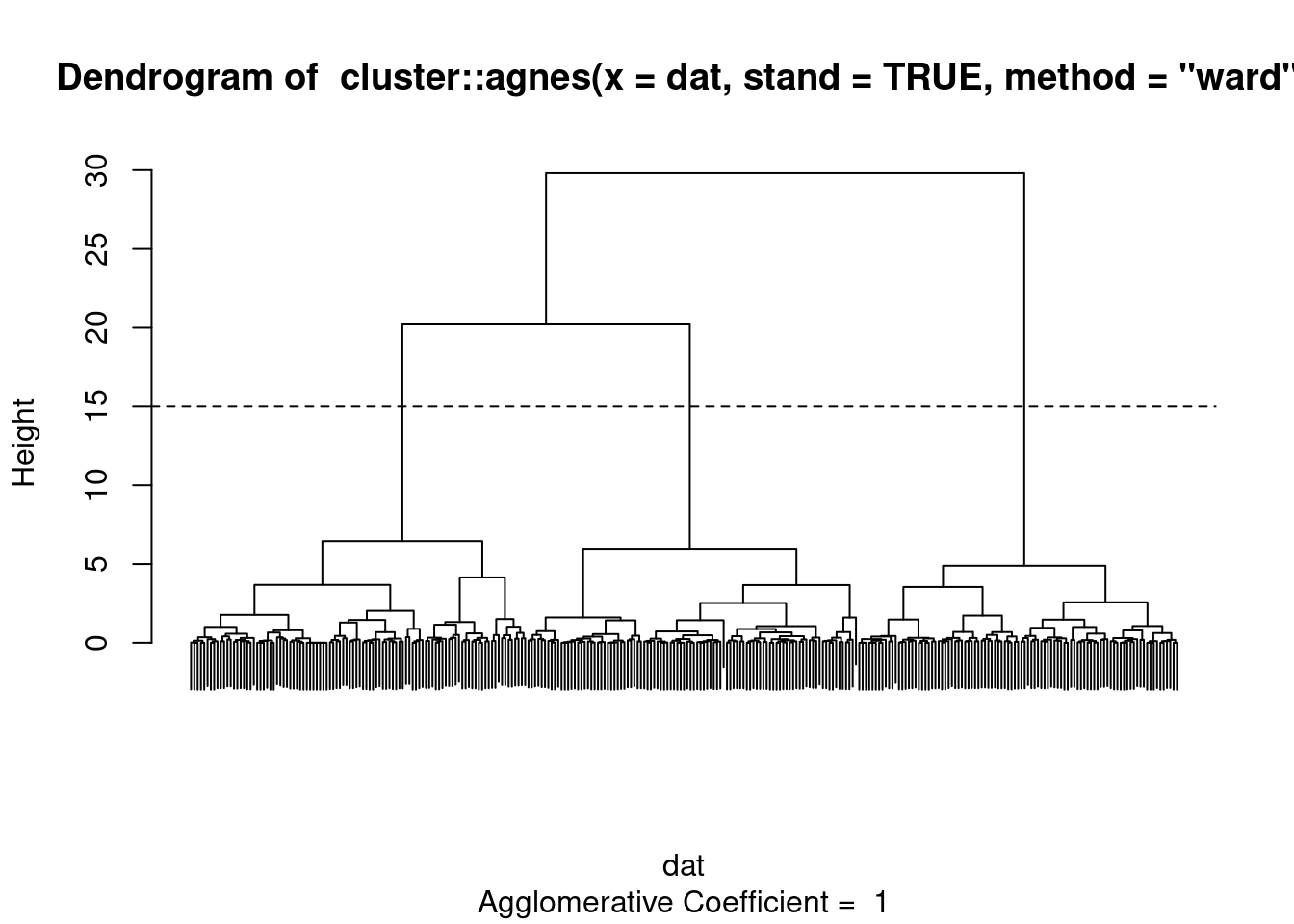
# 1D
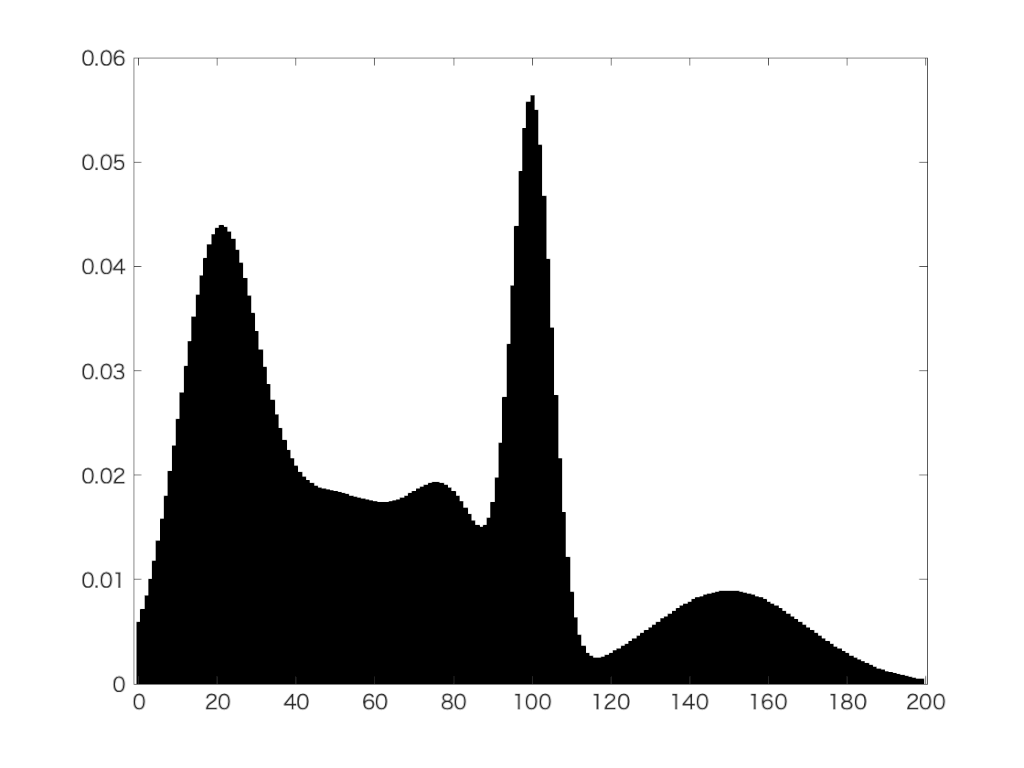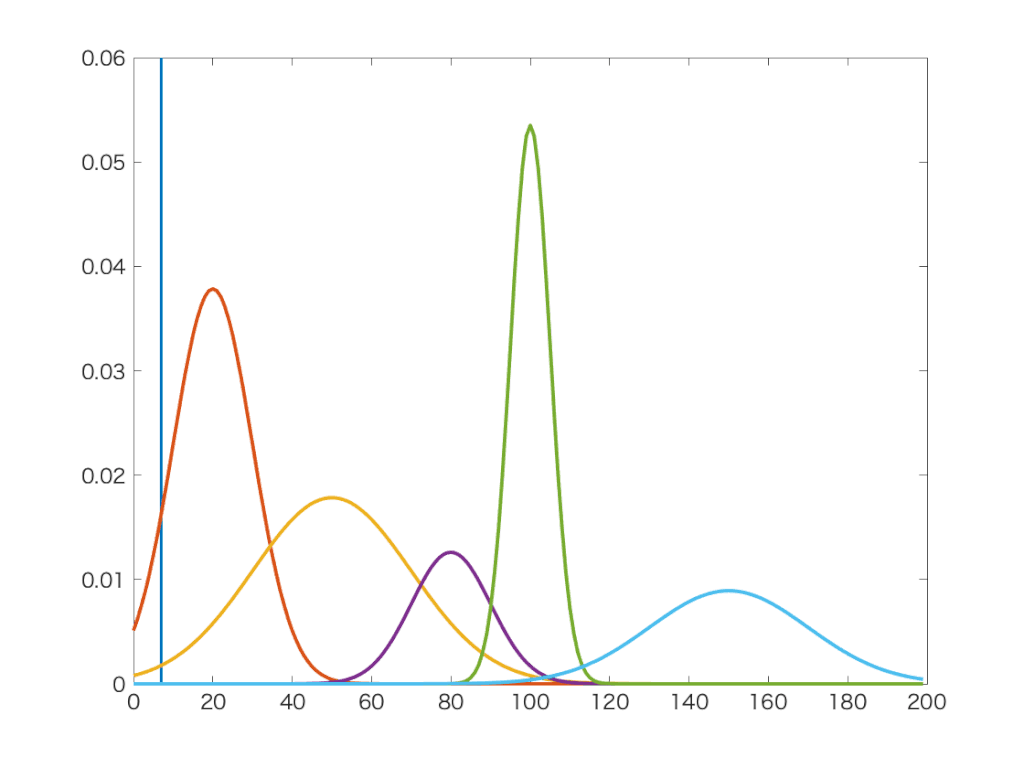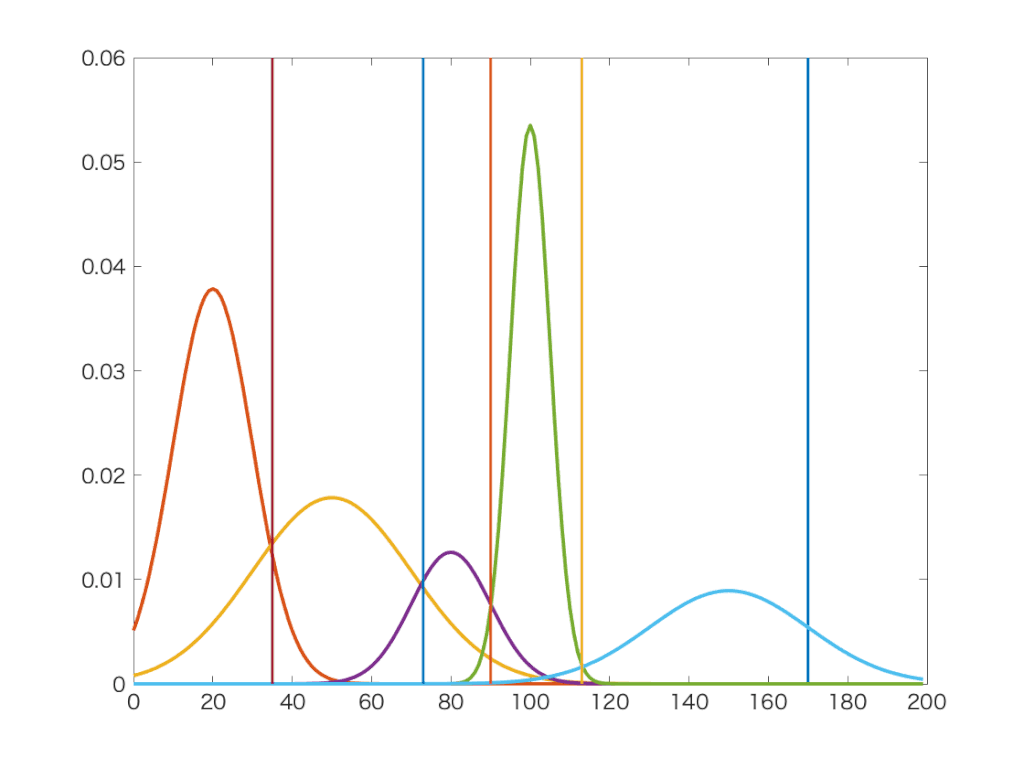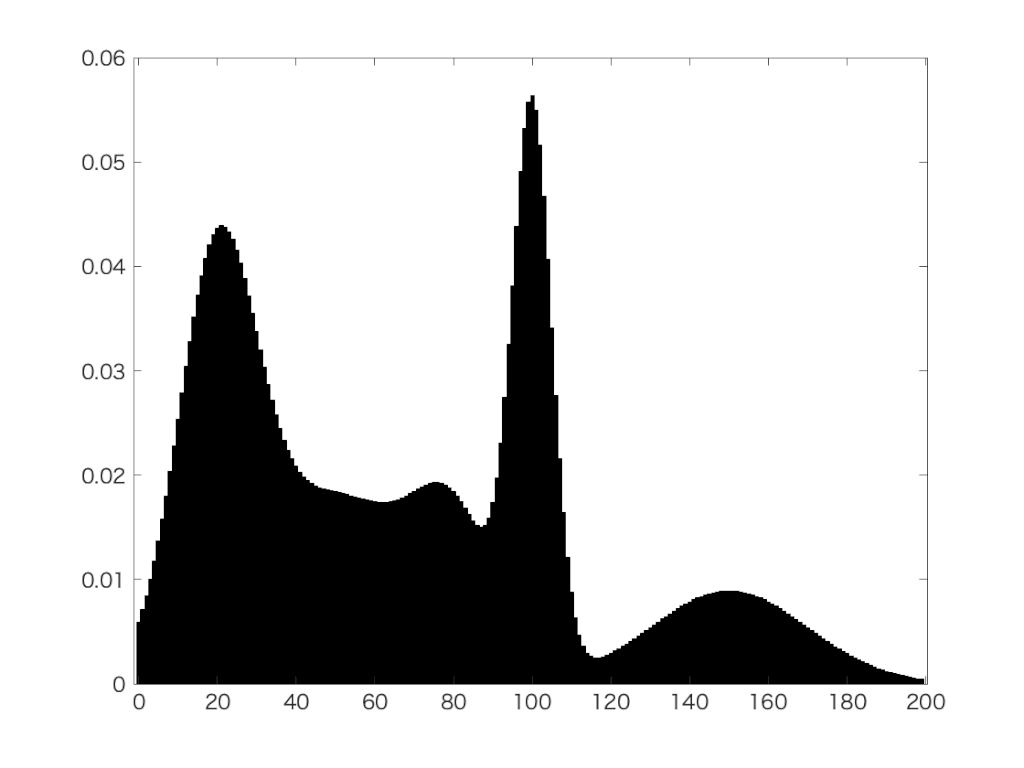
fit <- mclust::acidity |>
mclust::densityMclust(plot = FALSE)
fit |>
plot(what = "density", data = mclust::acidity, breaks = 15, xlab = "acidity")
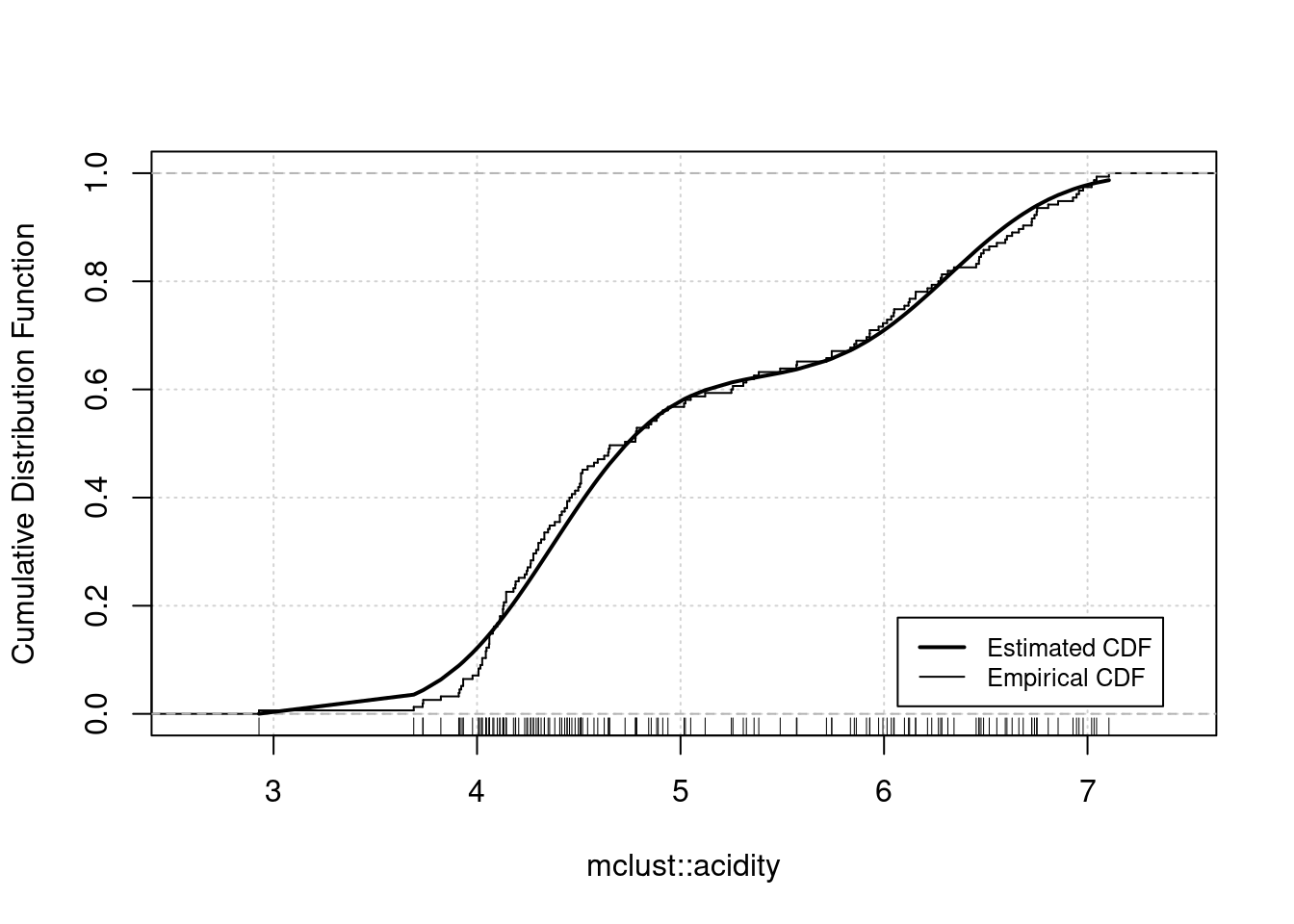
fit |>
plot(what = "diagnostic", type = "cdf")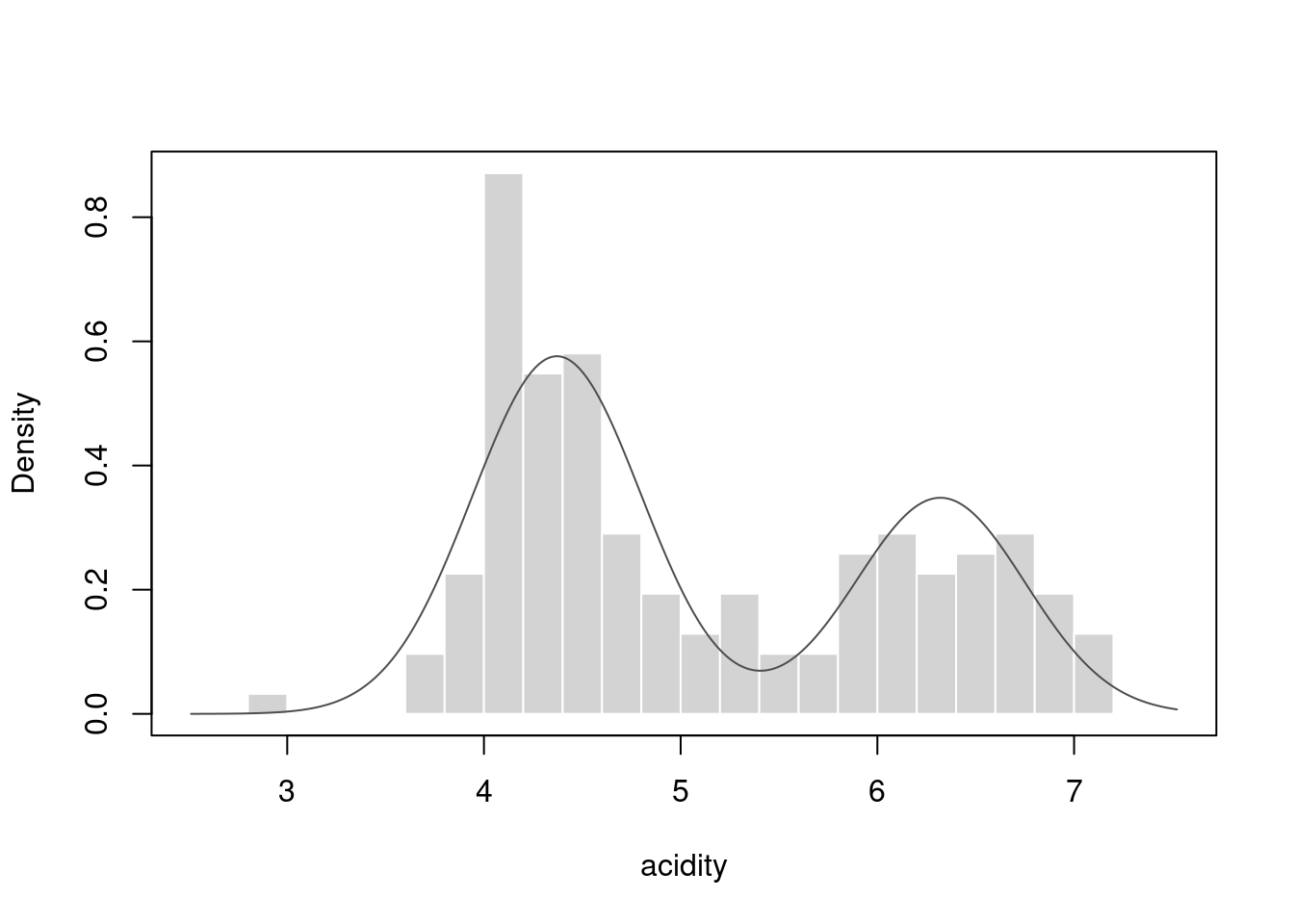
# 2D
fit <- faithful |>
mclust::densityMclust(plot = FALSE)
fit |>
plot(what = "density", type = "hdr",
data = faithful, points.cex = 0.5)
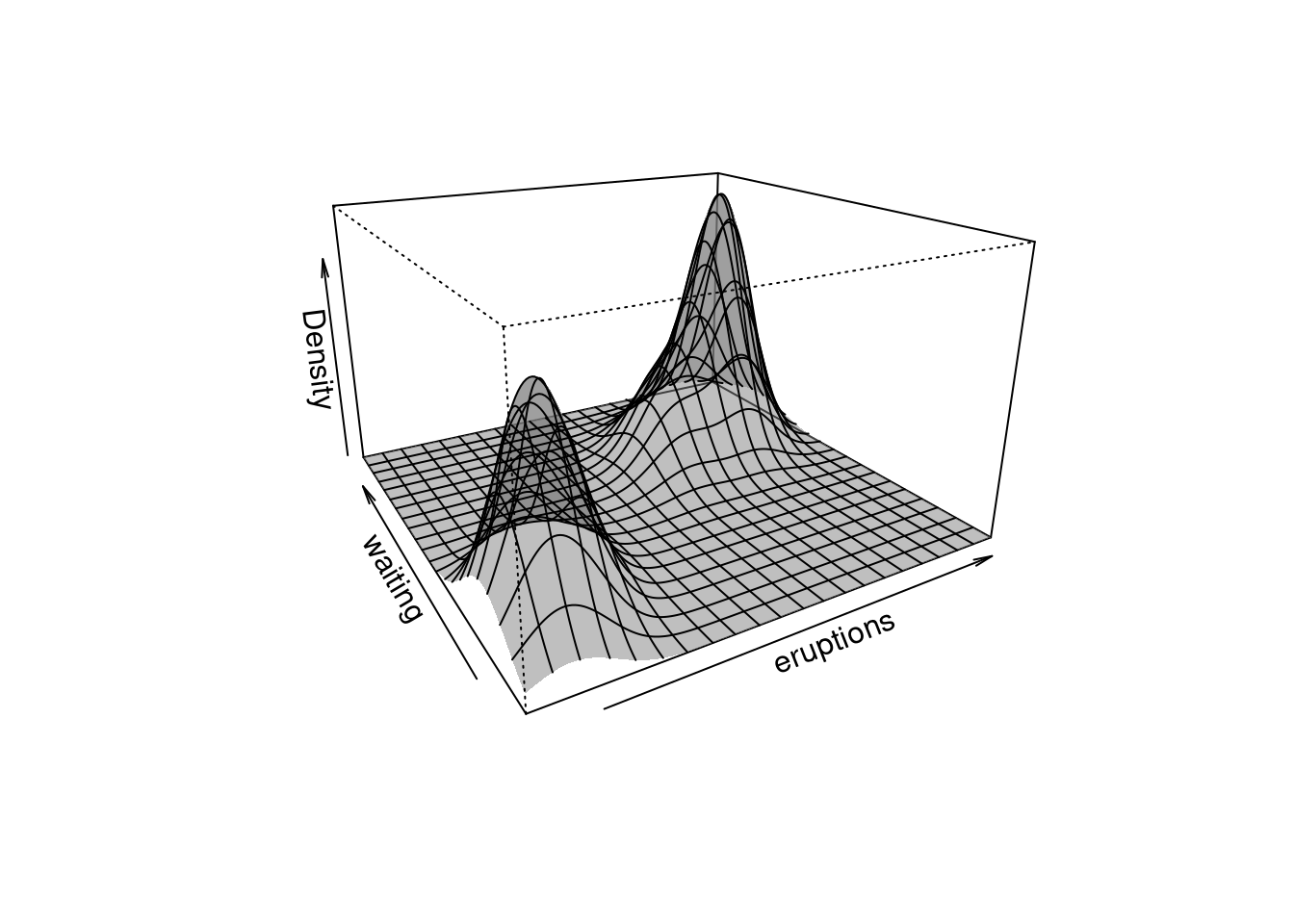
fit |>
plot(what = "density", type = "persp")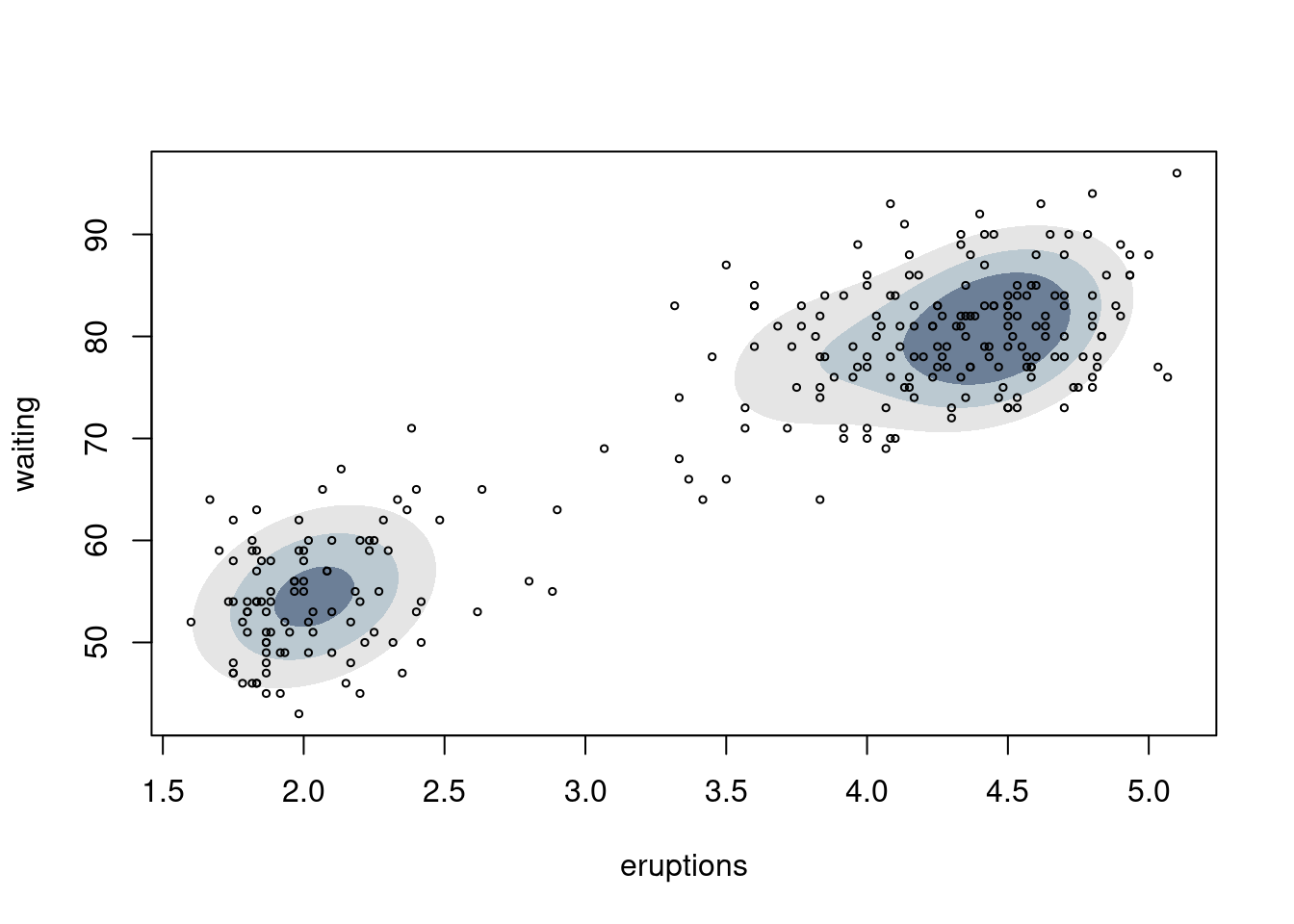
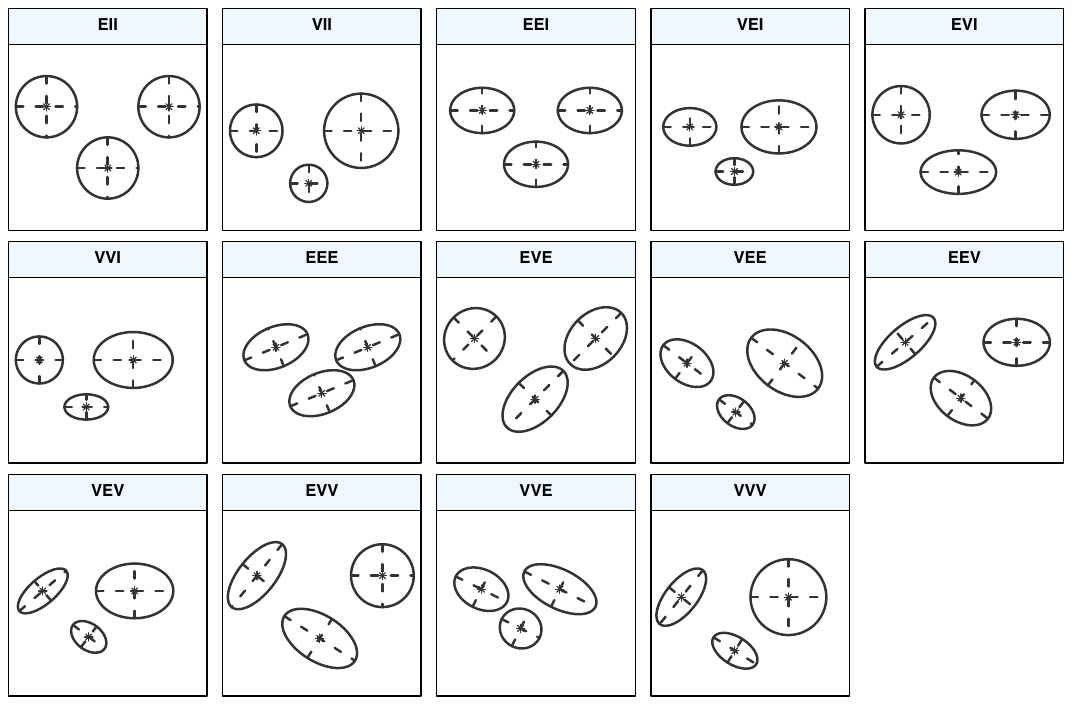
| Model | \mathbf{\Sigma}_k | Distribution | Volume | Shape | Orientation |
|---|---|---|---|---|---|
| EII | \lambda\mathbf{I} | Spherical | Equal | Equal | — |
| VII | \lambda_k\mathbf{I} | Spherical | Variable | Equal | — |
| EEI | \lambda\mathbf{A} | Diagonal | Equal | Equal | Coordinate axes |
| VEI | \lambda_k\mathbf{A} | Diagonal | Variable | Equal | Coordinate axes |
| EVI | \lambda\mathbf{A}_k | Diagonal | Equal | Variable | Coordinate axes |
| VVI | \lambda_k\mathbf{A}_k | Diagonal | Variable | Variable | Coordinate axes |
| EEE | \lambda\mathbf{D}\mathbf{A}\mathbf{D}^\intercal | Ellipsoidal | Equal | Equal | Equal |
| EVE | \lambda\mathbf{D}\mathbf{A}_k\mathbf{D}^\intercal | Ellipsoidal | Equal | Variable | Equal |
| VEE | \lambda_k\mathbf{D}\mathbf{A}\mathbf{D}^\intercal | Ellipsoidal | Variable | Equal | Equal |
| VVE | \lambda_k\mathbf{D}\mathbf{A}_k\mathbf{D}^\intercal | Ellipsoidal | Variable | Variable | Equal |
| EEV | \lambda\mathbf{D}_k\mathbf{A}\mathbf{D}_k^\intercal | Ellipsoidal | Equal | Equal | Variable |
| VEV | \lambda_k\mathbf{D}_k\mathbf{A}\mathbf{D}_k^\intercal | Ellipsoidal | Variable | Equal | Variable |
| VVV | \lambda_k\mathbf{D}_k\mathbf{A}_k\mathbf{D}_k^\intercal | Ellipsoidal | Variable | Variable | Variable |
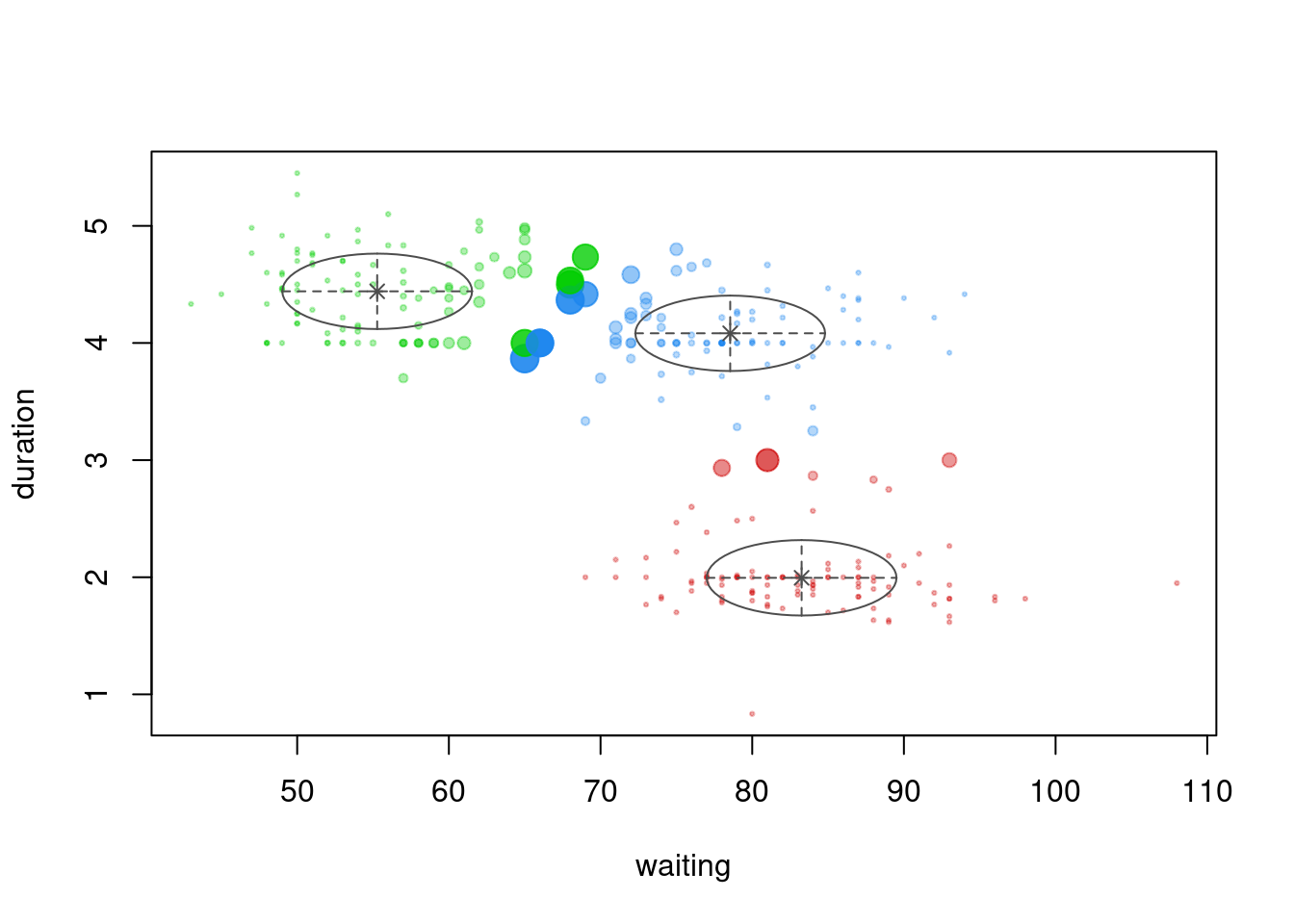
library(mclust)
fit <- MASS::geyser |>
mclust::Mclust(G = 3)
plot(fit, what = "density")
points(MASS::geyser, pch=19, cex=0.5)
plot(fit, what = "uncertainty")
fit |> summary()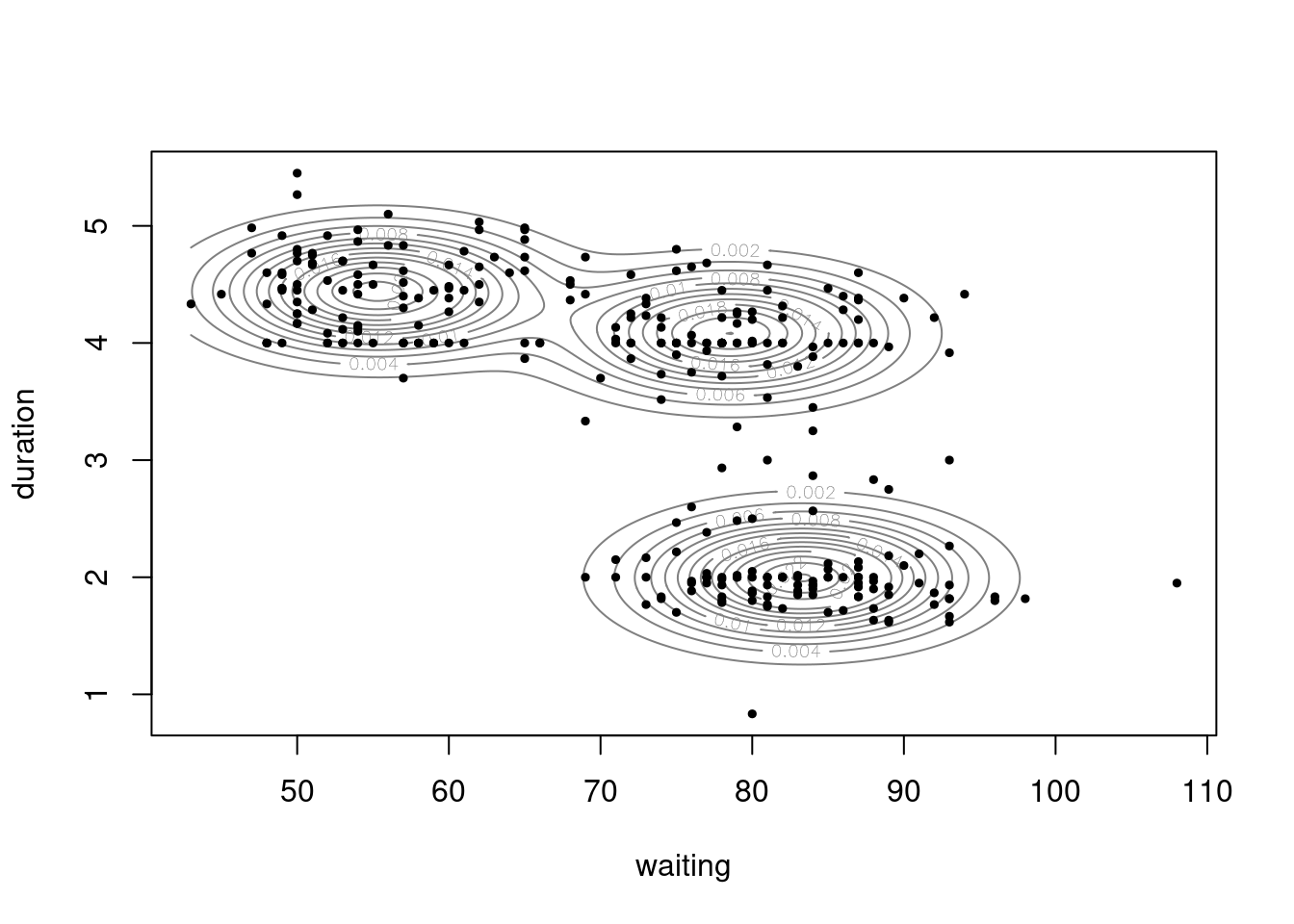
----------------------------------------------------
Gaussian finite mixture model fitted by EM algorithm
----------------------------------------------------
Mclust EEI (diagonal, equal volume and shape) model with 3 components:
log-likelihood n df BIC ICL
-1371.823 299 10 -2800.65 -2814.577
Clustering table:
1 2 3
91 107 101 Ďalšími ordinačnými metódami sú napr. principal coordinate analysis (PCoA) resp. multidimensional scaling (MDS), uniform manifold approximation and projection for dimension reduction (UMAP), t-distributed stochastic neighbor embedding (t-SNE)…↩︎