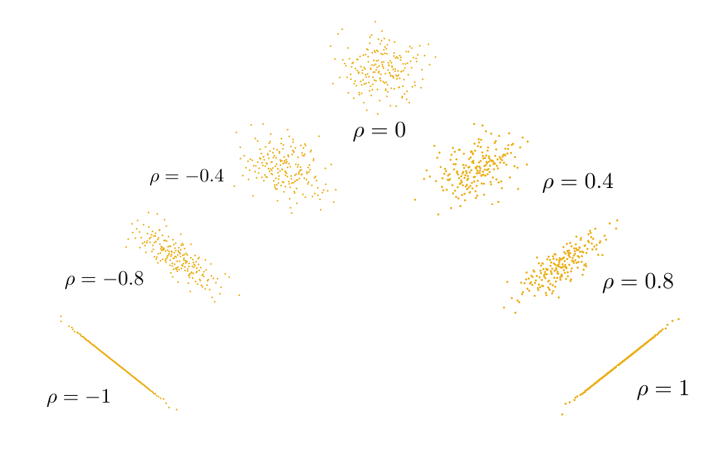V regresnej úlohe štatistického učenia sme modelovali rozdelenie pravdepodobnosti jedinej náhodnej premennej – odozvy. Rozdelenie vysvetľujúcich premenných – prediktorov – nás zväčša nezaujímalo.
Ak je odozva náhodný vektor (multivariate regression), modelované rozdelenie už nie je jednorozmerné, ale združené (štandardne z normálneho rozdelenia).
Vďaka zovšeobecnenému lineárnemu modelu môže mať odozva rozdelenie z exponenciálnej triedy rozdelení - spojitých aj diskrétnych.
Tak môžeme v klasifikačnej úlohe modelovať rozdelenie binárnej odozvy (Bernouliho r.) pomocou rozdelenia logaritmu šance (normálne r.) priamo cez link funkciu (p\rightarrow\mu). To je princíp logistickej regresie.
Naproti tomu generatívne metódy v klasifikačnej úlohe počítajú s vysvetľujúcimi premennými ako náhodnými, teda aj s definovaným združeným rozdelením.
Neasistovaná verzia generatívnych klasifikačných metód je známa ako zhluková analýza založená na zmesi rozdelení.
10.2 Cieľ a prostriedky
Náhodný vektor je vektor náhodných premenných, napr. \vec X=(X_1,X_2).
Vo všeobecnosti, ak by sme poznali združené rozdelenie náhodného vektora, dokázali by sme pomocou podmieňovania (Bayesova veta) vyjadriť rozdelenie pravdepodobnosti jednej alebo viacerých jeho premenných.
Vyjadriť alebo odhadnúť združené rozdelenie je náročné a táto náročnosť rastie so zvyšujúcim sa rozmerom náhodného vektora. Preto je často nutné zaviesť zjednodušujúce predpoklady, napr. o nezávislosti niektorých (alebo všetkých) premenných.
Tento všeobecný prístup si ukážeme na regresnej úlohe, v ktorej všetky premenné budeme uvažovať ako spojité.
Potrebujeme na to sadu teoretických i praktických nástrojov.
Z tých teoretických je treba pochopiť pojem okrajového (marginálneho) rozdelenia, podmieňovanie, nezávislosť, miery a funkcie popisujúce rozdelenie (momenty, korelačné koeficienty, PDF, CDF), rozklad združeného rozdelenia.
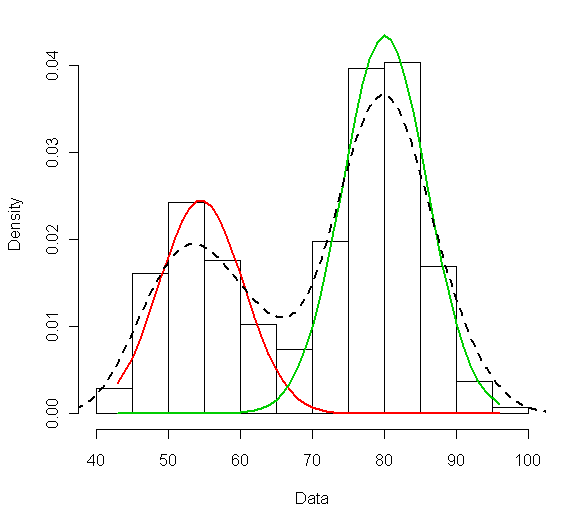
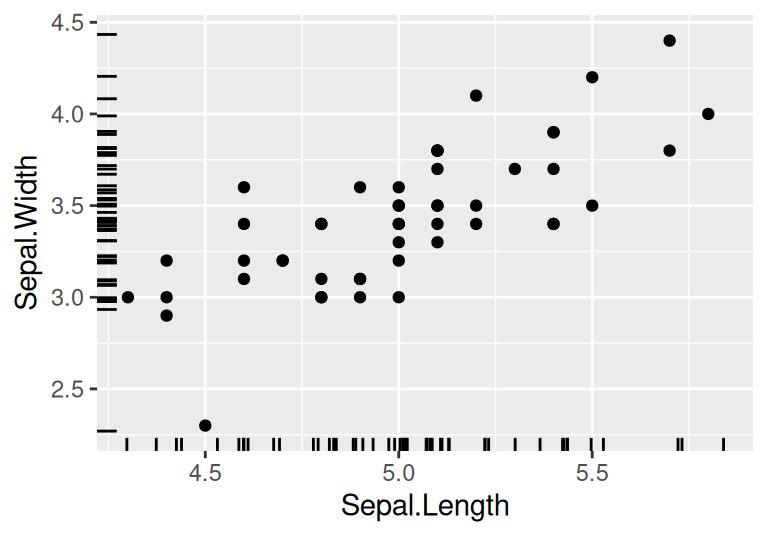
Tie praktické zahŕňajú aj nástroje popisnej štatistiky ako histogram, kobercový a bodový graf, ktoré odhaľujú charakter jedno- resp. dvojrozmerného rozdelenia (okrajové rozdelenie aj koreláciu).
Rovnako ako v jednorozmernom prípade, aj združené rozdelenie je charakterizované
napr. distribučnou funkciou (angl. joint cumulative distribution function, CDF) alebo
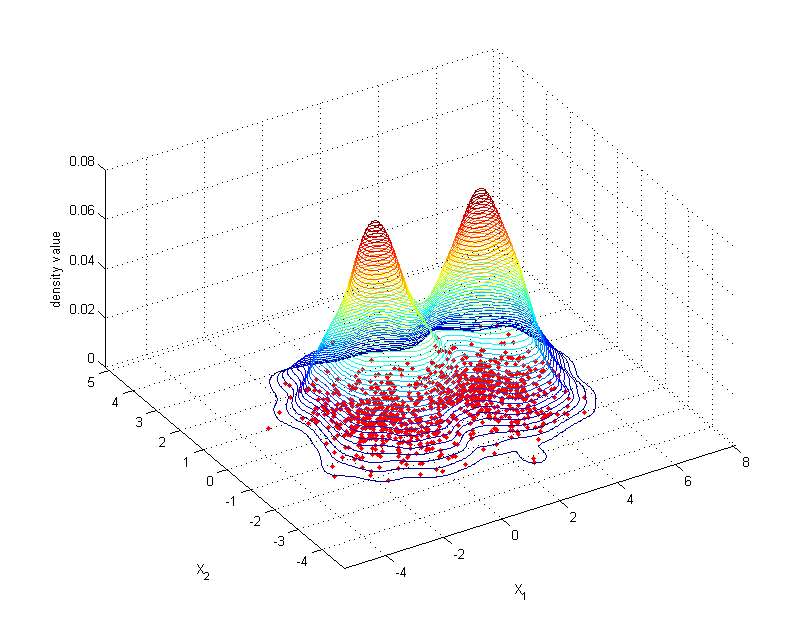
ešte názornejšie – hustotou (angl. joint probability density function, PDF).
Zvyčajne nás zaujíma pravdepodobnosť, že sa náhodné prememenné zrealizujú do (t.j. že spozorujeme ich hodnoty v) určitej oblasti priestoru.
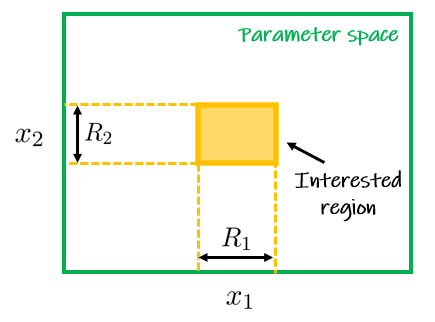
Môžeme si to predstaviť ako združené javy (A & B), kedy jav A predstavuje zrealizovanie X_1 do oblasti R_1 a analogicky jav B predstavuje nadobudnutie hodnoty premennou X_2 z oblasti R_2.
V jednotlivých prípadoch by nám stačili hustoty f_i(x_i) pre každú premennú X_i zvlášť, ale na vyjadrenie pravdepodobnosti súčasného nastatia oboch javov potrebujeme združenú hustotu f(x_1,x_2).
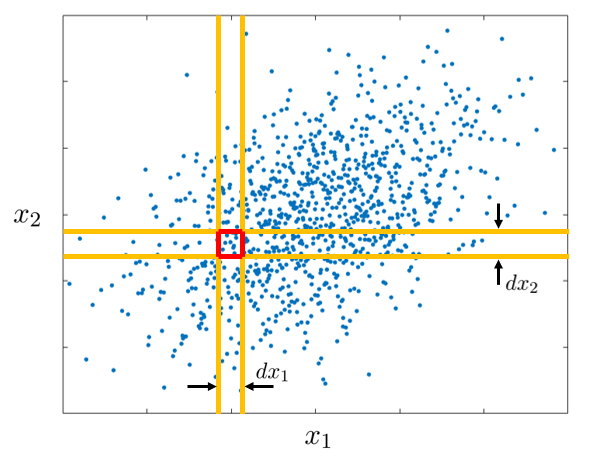
Ak R_1=[x_1,x_1+dx_1] a R_2=[x_2,x_2+dx_2] pre malé diferencie dx_1,dx_2, potom pravdepodobnosť nastatia združeného javu A & B je približne násobok hustoty a plochy oblasti R_1\times R_2,
Pr(x_1\leq X_1\leq x_1+dx_1,\ x_2\leq X_2\leq x_2+dx_2) \approx f(x_1,x_2)dx_1dx_2.
Presnejšie, pre ľubovoľnú oblasť [a_1,b_1]\times[a_2,b_2] to bude
Pr(a_1\leq X_1\leq b_1, a_2\leq X_2\leq b_2) = \int_{a_2}^{b_2}\int_{a_1}^{b_1}f(x_1,x_2)dx_1dx_2.
Integrál hustoty cez celý priestor sa musí rovnať pravdepodobnosti istej udalosti,
\iint_{\mathcal{R}^2}f(x_1,x_2)dx_1dx_2 = 1.
10.4 Marginálne rozdelenie
Rozdelenie pravdepodobnosti iba určitej podmnožiny náhodného vektora sa nazýva okrajové, marginálne rozdelenie. Dostaneme ho napr. marginalizáciou celého združeného rozdelenia.
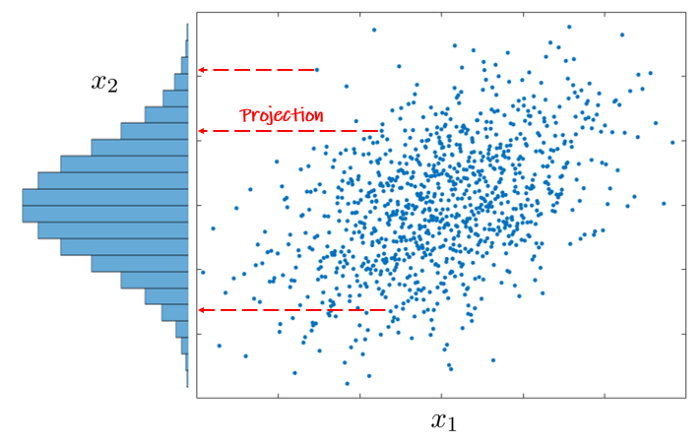
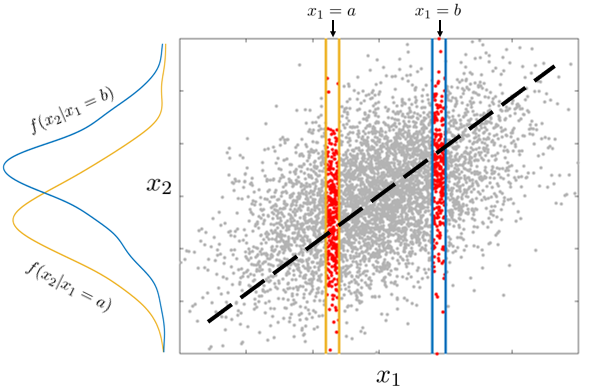
Majme bodový graf a chceme vizualizovať hustotu rozdelenia iba jednej z premenných, napr. X_2.
Vtedy stačí jednoducho zobraziť každý bod na vertikálnu os a vykresliť zodpovedajúci histogram.
Po jeho normalizácii, teda preškálovaní plochy stĺpcov, aby sa v súčte rovnala jednej, dostávame aproximáciu hustoty f_2(x_2).
Tým prakticky zanedbáme rozdelenie X_1 a zobrazíme histogram na základe hodnôt datasetu v stĺpci premennej X_2.
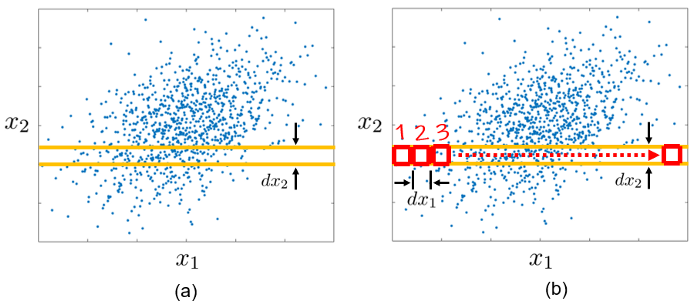
Z druhého uhla pohľadu, marginálne rozdelenie premennej X_2 “vyjadruje” pravdepodobnosť, že hodnota X_2 padne do nekonečne malého intervalu [x_2,x_2+dx_2], čo v kontexte bodového grafu je to isté, ako pravdepodobnosť, že bod (x_1,x_2) sa ocitne v oranžovom páse.
Ak si pás rozdelíme na plôšky dx_1dx_2, potom z nich váženým súčtom dostaneme
Pr(x_2\leq X_2\leq x_2+dx_2) \approx \color{red}{\sum_i}f(x_1^{(i)},x_2)dx_2dx_1
a porovnaním so vzťahom pre jednorozmernú hustotu
Pr(x_2\leq X_2\leq x_2+dx_2) \approx f_2(x_2)dx_2
vznikne
\begin{split}
f_2(x_2) & \approx \sum_i f(x_1^{(i)},x_2)dx_1 \\
f_2(x_2) & = \int_{-\infty}^{\infty} f(x_1,x_2)dx_1
\end{split}
Analogicky to platí aj pre X_1,
f_1(x_1) = \int_{-\infty}^{\infty} f(x_1,x_2)dx_2
Rozšírenie pre p-rozmerný náhodný vektor je jednoduché,
f_1(x_1) = \int\limits_{-\infty}^{\infty}\ldots\int\limits_{-\infty}^{\infty} f(x_1,\ldots,x_p)dx_2\ldots dx_p
Vyjadriť sa dá aj združené marginálne rozdelenie,
f_{12}(x_1, x_2) = \int\limits_{-\infty}^{\infty}\ldots\int\limits_{-\infty}^{\infty} f(x_1,\ldots,x_p)dx_3\ldots dx_p
10.5 Podmienené rozdelenie
Marginálne rozdelenie nám hovorí o tom, ako sa správa X_2, ale bez ohľadu na rozdelenie X_1.
Niekedy sa v praxi stáva, že odpozorujeme hodnotu X_1 a chceme vedieť, či a ako táto znalosť ovplyvní predpokladané rozdelenie X_2. Hľadáme teda rozdelenie X_2podmienené tým, že X_1 nadobudne konkrétnu hodnotu.
Podmienené rozdelenie tvorí kľúčový pojem v štatistickej dedukcii, kde hlavným cieľom je usúdiť, aká je hodnota nejakého parametra rozdelenia a to na základe pozorovaných údajov (t.j. parameter je podmienený pozorovaniami).
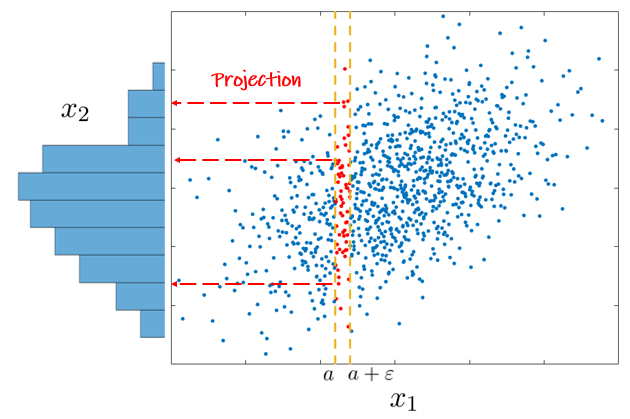
V príklade s bodovým grafom sa dá podmienená hustota f_{2|1}(x_2|X_1=a) odhadnúť nasledujúcim spôsobom:
Zameriame sa iba na body v úzkom páse pri hodnote X_1=a.
Tieto body zobrazíme na os X_2 a vypočítame normalizovaný histogram.
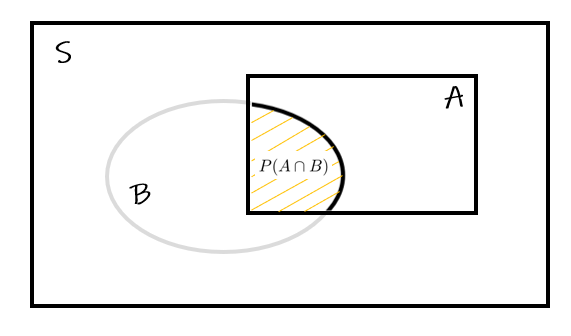
Pravdepodobnosť nastatia javu B – ak nastal jav A – sa vypočíta ako podiel nejakej miery (napr. počet pozorovaní) v priestore javu A, teda Pr(B|A) = \frac{n(A\cap B)}{n(A)}
Normovaním mierou celého priestoru získame podiel pravdepodobností
Pr(B|A) = \frac{n(A\cap B)/n(S)}{n(A)/n(S)} = \frac{Pr(A\cap B)}{Pr(A)}
Prepojením na predošlý kontext, ak B=(x_2\leq X_2\leq x_2+dx_2) a A=(a\leq X_1\leq a + \varepsilon), potom je možné pravdepodobnosti prepísať v reči hustoty na
f_{2|1}(x_2|X_1=a)dx_2 = \frac{f(a,x_2)dx_2}{f_1(a)}
Vo všeobecnosti a po úprave je podmienená hustota premennej X_2 (ak je známa hodnota X_1) daná vzťahom
f_{2|1}(x_2|x_1) = \frac{f(x_1,x_2)}{f_1(x_1)}
Pretože podmienená hustota je stále hustota pravdepodobnosti, integrovaním predošlého vzťahu sa dá ukázať, že platí \int_{\mathcal{R}}f(x_2|x_1)dx_2=1 a rovnako môžeme písať
Pr(a\leq X_2\leq b|X_1=x_1) = \int_a^bf_{2|1}(x_2|x_1)dx_2
Integrovaním vzťahu pre združenú hustotu podľa x_1
f(x_1,x_2)=f_{2|1}(x_2|x_1)f_1(x_1)
dostávame alternatívne vyjadrenie marginálnej hustoty
f_2(x_2) = \int_{\mathcal{R}}f_{2|1}(x_2|x_1)f_1(x_1)dx_1
ktoré je známe ako veta o úplnej pravdepodobnosti.
Analogicky podmienená pravdepodobnosť pre X_1 je daná vzťahom
f_{1|2}(x_1|x_2) = \frac{f(x_1,x_2)}{f_2(x_2)}
Rozšírenie na p-rozmerný náhodný vektor je priamočiare,
f_{1|2...p}(x_1|x_2,\ldots,x_p) = \frac{f(x_1,\ldots,x_p)}{f_{2...p}(x_2,\ldots,x_p)}
Funkcia v menovateli je hustota združeného marginálneho rozdelenia premenných X_2,\ldots,X_p.
Podmienená pravdepodobnosť sa využíva okrem iného na faktorizáciu združenej hustoty (t.j. rozloženie na činitele), napr.
f(x_1,x_2,x_3) = f_{1|23}(x_1|x_2,x_3)f_{2|3}(x_2|x_3)f_3(x_3)
ktorú by inak bolo ťažké vyjadriť priamo.
10.6 Bayesova veta
Bayesova veta je jednou z najdôležitejších v teórii pravdepodobnosti, tvorí základ bayesovskej štatistickej dedukcie.
Ak vyjdeme z oboch možných faktorizácií dvojrozmernej združenej hustoty,
\begin{split}
f(x_1,x_2) &= f_{2|1}(x_2|x_1)f_1(x_1) \\
f(x_1,x_2) &= f_{1|2}(x_1|x_2)f_2(x_2)
\end{split}
ich kombináciou dostaneme Bayesov vzorec
f_{2|1}(x_2|x_1) = \frac{f_{1|2}(x_1|x_2)f_2(x_2)}{f_1(x_1)}
10.7 Bayesovská štatistika
Príklady otázok, ktoré možno riešiť bayesovskou štatistikou:
Ak hodíme mincu 10 krát a pozorujeme 7-krát hlavu a 3-krát znak, ako veľmi sa môžme spoľahnúť, že minca nie je falošná?
Ak je ráno zamračené, aká je pravdepodobnosť že popoludní spŕchne?
Majúc dataset dvojíc (x_i,y_i), aké parametre sú najlepšie na preloženie priamky?
Ako veľmi si môžeme byť istí, že naše odhadnuté parametre sú správne?
Bayesovská štatistika ponúka jeden spôsob štatistickej dedukcie, čiže ako odhaliť fundamentálny model z pozorovaných dát.
Bayesovské usudzovanie
zvyčajne začína predpokladmi o fundamentálnom pravdepodobnostnom modeli. Vopred môžeme mať napríklad informáciu, že model má určitú formu a jeho parametre sa nachádzajú v určitých intervaloch. Tieto predpoklady tvoria východzie (prior) znalosti.
Následne zbierame dáta, pričom dúfame, že nám tieto pozorované údaje odhalia viac informácií o modeli.
Nakoniec použijeme Bayesovu vetu na získanie týchto informácií z údajov a aktualizovanie východzích predpokladov. Tým dostávame posteriórny odhad (posterior).
Dá sa chápať ako proces prerozdelovania dôveryhodnosti medzi možnosťami: spočiatku máme iba predstavu o možných scenároch, každý má pridelenú svoju pravdepodobnosť. No potom tým scenárom, ktoré sú v zhode s pozorovaniami, sa pravdepodobnosť navyšuje, na úkor tých, ktoré dátam nezodpovedajú až tak dobre.
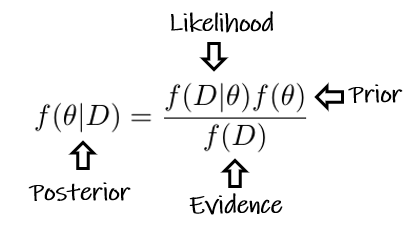
Bayesovská štatistika je elegantná, pretože tento abstraktný proces aktualizovania vedomostí opisuje merateľným spôsobom. Pozrime sa na jednotlivé komponenty Bayesovho vzorca, ktorý najprv prepíšeme do symbolického tvaru
Člen \theta predstavuje parameter fundamentálneho pravdepodobnostného modelu, ktorý je predmetom odhadu, a D označujú dáta. Potom
f(\theta) je apriorné rozdelenie parametra \theta, formuluje naše predstavy o skutočnom parametri pred tým, než zrealizujeme pozorovania,
f(D|\theta) je funkcia vierohodnosti, poskytuje pravdepodobnosť toho, že by sme pozorovali rovnaké dáta ako D, ak by platil predpoklad o \theta,
f(\theta|D) je aposteriórne rozdelenie \theta, teda aktualizácia naších predstáv urobená na základe reálnych pozorovaní,
f(D) predstavuje celkovú pravdepodobnosť pozorovania D vypočítanú ako vážený priemer vierohodnostnej funkcie naprieč všetkými hodnotami \theta, čiže f(D)=\int f(D|\theta)f(\theta)d\theta. Nazýva sa aj marginálnou vierohodnosťou.
Menovateľ f(D) nezávisí od \theta. Často je to jednoducho normalizačná konštanta, ktorá zabezpečuje, že f(\theta|D) je riadna hustota pravdepodobnosti.
V praxi sú vierohodnostná funkcia a prior často natoľko komplikované, že sa posterior neoplatí riešiť analyticky. Na uľahčenie výpočtu boli vyvinuté a používajú sa metódy ako Laplaceova aproximácia, Markov Chain Monte Carlo (MCMC) a variational Bayes.
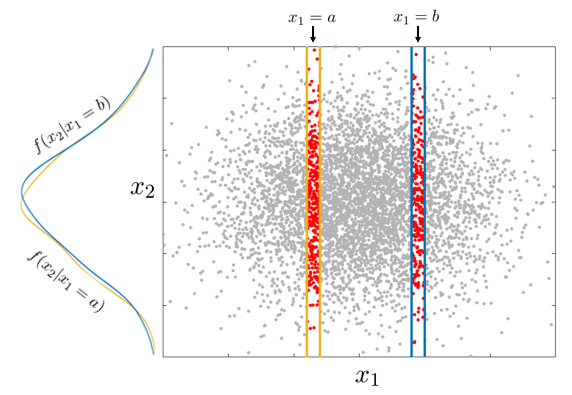
Ak dve náhodné premenné spolu nesúvisia (nie sú vo vzájomnom vzťahu), hovoríme, že sú štatisticky nezávislé. Potom
f_{1|2}(x_1|x_2)=f_1(x_1),\qquad\qquad f_{2|1}(x_2|x_1)=f_2(x_2)
a dosadením do vzťahov vyjadrujúcich faktorizáciu združenej hustoty dostávame
f(x_1,x_2) = f_1(x_1)f_2(x_2)
V praxi sa nezávislosť najjednoduchšie posúdi vizuálne – z bodového grafu.
10.9 Podmienená nezávislosť
Podmienená nezávislosť znamená takú situáciu, keď dve premenné X_1 a X_2 sa javia ako nezávislé, ak poznáme ich vzťah ku tretej premennej X_3, a inak sa prejavujú, akoby boli závislé. Vtedy pre podmienenú hustotu platí vzťah
f_{12|3}(x_1,x_2|x_3) = f_{1|3}(x_1|x_3) f_{2|3}(x_2|x_3)
Názorný príklad: Vo vrecku sú dve mince, jedna obyčajná (s hlavou aj znakom), druhá falošná s dvoma znakmi. Náhodne vyberiem jednu mincu a 2-krát ju hodím.
Jav A: Prvý hod ukáže znak.
Jav B: Druhý hod ukáže znak.
Jav C: Vybraná minca je obyčajná (nie je falošná).
Javy A a B nie sú nezávislé, výskyt A ovplyvní pravdepodobnosť výskytu B, tzn. Pr(B|A)\neq Pr(B), pretože ak pozorujeme jav A je viac pravdepodobné, že bola použitá falošná minca, čo zvyšuje pravdepodobnosť výskytu B.
Ak však vieme, že nastal jav C, potom javy A a B sú nezávislé, lebo hádžeme obyčajnou mincou.
Znalosť podmienenej nezávislosti je užitočná, pretože zjednodušuje faktorizáciu združenej PDF.
\begin{split}
f(x_1,x_2,x_3) & \overset{\phantom{X_1\perp X_2|X_3}}{=} f_{1|23}(x_1|x_2,x_3)f_{2|3}(x_2|x_3)f_3(x_3) \\
& \overset{X_1\perp X_2|X_3}{=} f_{1|3}(x_1|x_3)f_{2|3}(x_2|x_3)f_3(x_3)
\end{split}
Toto zjednodušenie je základom Bayesovských sietí, čo sú pravdepodobnostné modely využívajúce grafickú reprezentáciu na vyjadrenie podmienenej závislosti (ktorá v mnohorozmernom prípade môže byť značne komplikovaná).
Vo všeobecnosti, náhodné premenné X_1,\ldots,X_p sú štatisticky nezávislé, ak platí
f(x_1,\ldots,x_p) = f_1(x_1)\cdot f_2(x_2)\cdot\ldots\cdot f_p(x_p).
10.10 Stredná hodnota a rozptyl
Rovnako ako v jednorozmernom prípade, aj na popis združeného rozdelenia sa používa stredná hodnota a rozptyl.
Stredná hodnota sa stane vektorom, E[\vec X]=(E[X_1],\ldots,E[X_p]). Jednotlivo platí
E[X_1] = \int_{\mathcal{R}} x_1f_1(x_1)dx_1
kde f_1(x_1) je marginálna hustota, za ktorú ak dosadíme skoršie vyjadrenie f_1(x_1)=\int_{\mathcal{R}} f(x_1,x_2)dx_2, dostaneme
E[X_1] = \iint_{\mathcal{R}^2} x_1f(x_1,x_2)dx_1dx_2
Podobne rozptyl, ktorý vyjadruje mieru variability okolo strednej hodnoty,
\begin{split}
var[X_1] &= E\left[(X_1-E[X_1])^2\right] =
\int_{\mathcal{R}} (x_1-E[X_1])^2f_1(x_1)dx_1 \\
& \phantom{= E\left[(X_1-E[X_1])^2\right]} = \iint_{\mathcal{R}^2} (x_1-E[X_1])^2f(x_1,x_2)dx_1dx_2 \\
&= E[X_1^2]-E[X_1]^2,
\end{split}
kde E[X_1^2] = \int_{\mathcal{R}} x_1^2f_1(x_1)dx_1.
10.11 Kovariancia
Pri viac než jednej premennej je okrem strednej hodnoty a variancie potrebné na popis rozdelenia vziať do úvahy aj mieru závislosti. Jednou takou mierou je kovariancia.
Kovariancia vyjadruje to, ako sa dve premenné menia spolu,
\begin{split}
cov[X_1,X_2] &= E[(X_1-E[X_1])(X_2-E[X_2])] \\
&= \iint_{\mathcal{R}^2} (x_1-E[X_1])(x_2-E[X_2])f(x_1,x_2)dx_1dx_2
\end{split}
Jednoduchší je výpočet zo vzťahu po úprave,
cov[X_1,X_2]=E[X_1X_2]-E[X_1]E[X_2],
pričom E[X_1X_2] = \iint_{\mathcal{R}^2} x_1x_2f(x_1,x_2)dx_1dx_2.
Zopakujme si aj vlastnosti kovariancie:
cov[X_1,X_1]=var[X_1]
cov[X_1,X_2]=cov[X_2,X_1]
cov[a\cdot X_1,X_2]=a\cdot cov[X_1,X_2]
cov[X_1+c,X_2]=cov[X_1,X_2]
cov[X_1,X_2]\overset{X_1\perp X_2}{=}0\quad (tzn. keď X_1,X_2 sú nezávislé)
10.12 Korelačný koeficient
Nevýhodou kovariancie je to, že jej veľkosť (sama o sebe) neprezrádza silu vzájomného vzťahu medzi premennými. Pretože závisí od mierky.
Toto je napravené normalizáciou kovariancie v Pearsonovom korelačnom koeficiente
\rho_P = corr(X_1,X_2)=\frac{cov[X_1,X_2]}{\sqrt{var[X_1]var[X_2]}}
Korelačný koeficient (a kovariancia) vyjadruje stupeň iba lineárnej závislosti, preto nulová hodnota neznamená automaticky nezávislosť. Ak sú však dve premenné nezávislé, potom korelácia/kovariancia je vždy nulová.
10.13 Distribučná funkcia
Okrem hustoty sa rozdelenie pravdepodobnosti dá reprezentovať aj kumulatívnou distribučnou funkciou (CDF), ktorá je vo všeobecnosti definovaná ako pravdepodobnosť súčasného neprekročenia hodnôt \mathbf{x} = (x_1,\ldots,x_p),
F(\mathbf{x}) \equiv Pr(X_1\leq x_1\wedge X_2\leq x_2 \wedge\ldots\wedge X_p\leq x_p)
a voči hustote platia nasledujúce prevodové vzťahy:
\begin{split}
F(\mathbf{x}) &= \int_{-\infty}^{x_1}\cdots\int_{-\infty}^{x_p} f(y_1,\ldots,y_p)dy_1\ldots dy_p \\
f(\mathbf{x}) &= \frac{\partial F(y_1,\ldots, y_p)}{\partial y_1\ldots\partial y_p}\Bigg|_{\mathbf{y}=\mathbf{x}}
\end{split}
Podmienená distribučná funkcia sa vypočíta analogicky, a to ako určitý integrál podmienenej hustoty, napr.
\begin{split}
F_{12|3...p}(x_1,x_2|x_3,\ldots,x_p) &= \int_{-\infty}^{x_1}\int_{-\infty}^{x_2} f_{12|3...p}(y_1,y_2|x_3,\ldots,x_p)dy_1dy_2 \\
&= \int_{-\infty}^{x_1}\int_{-\infty}^{x_2} \frac{f(y_1,y_2,x_3\ldots,x_p)}{f_{3...p}(x_3,\ldots,x_p)}dy_1dy_2\\
&= \frac
{\int_{-\infty}^{x_1}\int_{-\infty}^{x_2} f(y_1,y_2,x_3,\ldots,x_p)dy_1dy_2}
{\int_{-\infty}^{\infty}\int_{-\infty}^{\infty} f(y_1,y_2,x_3\ldots,x_p)dy_1dy_2} \\
&= \frac
{\frac{\partial F(y_1,y_2,x_3\ldots, x_p)}{\partial y_1\partial y_2}\Big|_{ y_1=x_1,y_2=x_2}}
{\int_{-\infty}^{\infty}\int_{-\infty}^{\infty} f(y_1,y_2,x_3\ldots,x_p)dy_1dy_2}
\end{split}
Podobnou úvahou dostaneme aj marginálnu distribučnú funkciu
F_{12}(x_1,x_2) = \int_{-\infty}^{x_1}\int_{-\infty}^{x_2}\int_{-\infty}^{\infty}\cdots\int_{-\infty}^{\infty} f(y_1,\ldots,y_p)dy_1\ldots dy_p
Inverzná funkcia ku jednorozmernej distribučnej funkcii F_X premennej X sa nazýva kvantilová funkciaQ_X. Čiže ak platí, že F_X(q) \equiv Pr(X\leq q) = p, potom platí aj
Q_X(p)\equiv F_X^{-1}(p) = q, \qquad \forall p\in[0,1]
Hodnota q sa nazýva kvantil premennej X, niekedy sa značí aj s dolným indexom, q_p=Q_X(p), najznámejšie sú
medián q_{0.5},
kvartily q_{0.25} (dolný) a q_{0.75} (horný),
decily q_{0.1}, q_{0.2},\ldots, q_{0.9} a
percentily (kde p=0.01,0.02,\ldots,0.99).
10.14 Funkcia prežitia
Duálna funkcia ku CDF v zmysle doplnkovej pravdepodobnosti sa nazýva tzv. funkcia prežitia S (survival function), ktorá predstavuje pravdepodobnosť (súčasného) prekročenia určitých kvantilov náhodnými premennými, napr. v prvých troch rozmeroch sa vypočíta podľa vzťahov
\begin{split}
S_1(x_1) &\equiv Pr(X_1>x_1) = 1 - F_1(x_1) \\
S_{12}(x_1,x_2) &\equiv Pr(X_1>x_1\land X_2>x_2) \\
&= 1 - F_1(x_1) - F_2(x_2) + F_{12}(x_1,x_2) \\
S_{123} &= 1-F_1-F_2-F_3+F_{12}+F_{13}+F_{23}-F_{123}
\end{split}
Pozor, jednoduchý doplnok distribučnej funkcie do plnej pravdepodobnosti znamená pravdepodobnosť prekročenia aspoň v jednej premennej (v jednej alebo v druhej alebo … vo všetkých súčasne), teda napr.
1-F_{12}(x_1,x_2) = Pr(X_1>x_1 \lor X_2>x_2)