Diskriminačné metódy ako napr. logistická regresia modelujú podmienenú pravdepodobnosť Pr[Y=y|\vec X= \mathbf{x}]priamo.
Generatívne metódy idú na problém nepriamo:
Najprv sa modeluje rozdelenie vysvetľujúcich premenných \vec X=(X_1,X_2,\ldots,X_p) zvlášť pre každú hodnotu odozvy Y.
Pomocou Bayesovej vety sa potom konvertuje na podmienené rozdelenie odozvy.
Ak je rozdelenie \vec X normálne, oba prístupy dávajú veľmi podobný výsledok, generatívny je však
s menším počtom údajov presnejší,
pri dokonalej separácii hodnôt netrpí nestabilitou odhadu parametrov (tak ako logistická regresia).
Generatívny prístup je jednoducho a prirodzene rozšíriteľný na viac ako 2 triedy.
Nech
odozva Y je kvalitatívna (nominálna alebo ordinálna) premenná s oborom hodnôt \mathcal H(Y)=\{c_1,\ldots,c_K\}, kde K\geq2,
\pi_k je pravdepodobnosť, že náhodne zvolené pozorovanie patrí do triedy k, teda
\pi_k = Pr[Y=c_k]
V bayesovskom kontexte sa nazýva apriórna.
Funkcia f_k sa nazýva vierohodnosť (likelihood) a bude označovať
(v prípade vektora diskrétnych náhodných premenných \vec X) pravdepodobnostnú funkciu,
f_k(\mathbf{x})= Pr[\vec X = \mathbf{x}|Y=c_k],
(v spojitom prípade) hustotu pravdepodobnosti, čiže
f_k(\mathbf{x})dx_1dx_2\ldots dx_p= Pr[\vec X=\mathbf{x}|Y=c_k],
ktorá nadobúda veľké hodnoty, ak pre pozorovanie z k-tej triedy je \vec X\approx\mathbf{x}, a naopak, malé, ak hodnoty \vec X sú ďaleko od \mathbf{x}.
Potom podľa Bayesovej vety platí vzťah pre pravdepodobnosť, že pozorovanie \vec X=\mathbf{x} patrí do k-tej triedy,
Pr[Y=c_k|\vec X=\mathbf{x}] = \frac{\pi_k f_k(\mathbf{x})}{\sum_{\ell=1}^K \pi_\ell f_\ell(\mathbf{x})}.
Nazýva sa aj aposteriórna pravdepodobnosť.
Menovateľ vo vzťahu sa nazýva marginálna pravdepodobnosť/vierohodnosť.
Čitateľ predstavuje združenú pravdepodobnosť \vec X, Y v danej triede (unnormalized posterior).
Keďže (bayesovský) klasifikátor zaradí pozorovanie X=\mathbf{x} do tej triedy, ktorej zodpovedá najvyššia aposteriórna pravdepodobnosť, stačí túto podmienenú pravdepodobnosť nahradiť jednoduchšou funkciou.
Tou je tzv. diskriminačná funkcia \delta_k. Vznikne
transformáciou Bayesovej vety pomocou logaritmu (kvôli numerickej stabilizácii súčinu malých hodnôt) a
vynechaním členov spoločných pre všetky triedy (menovateľ a časti čitateľa),
takže proporcionalita medzi skupinami zostáva zachovaná:
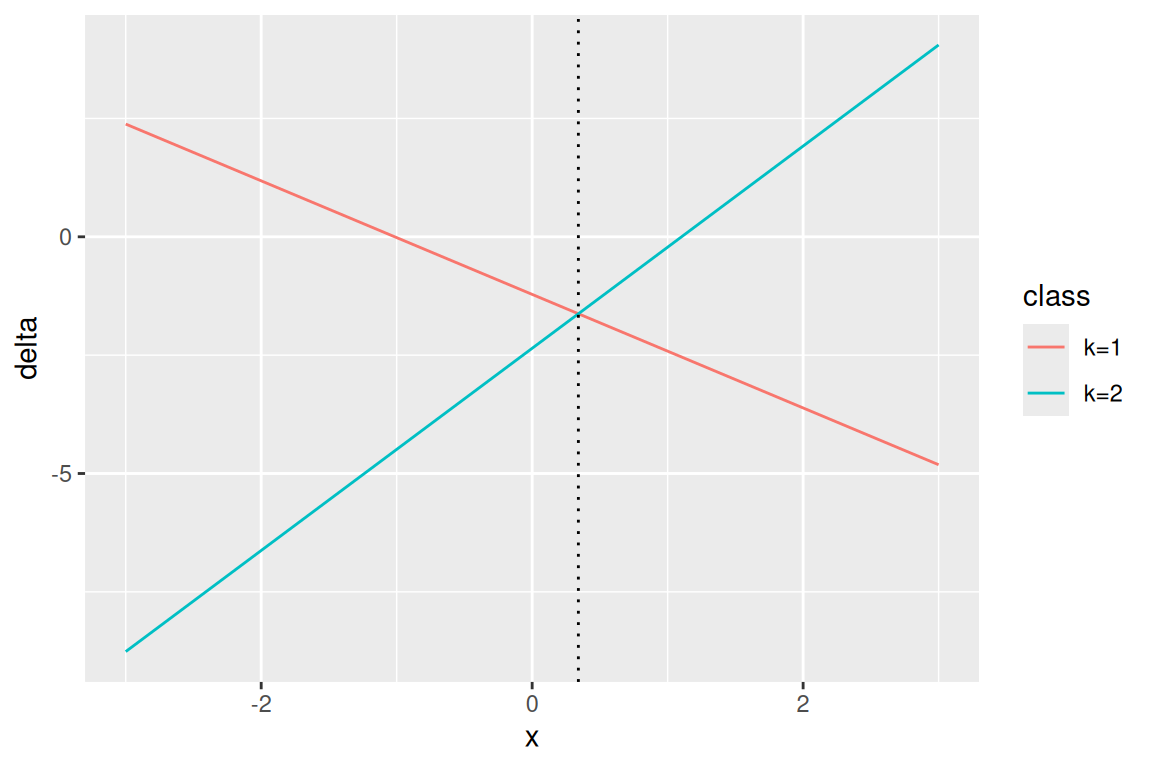
Aposteriórne pravdepodobnosti sa dajú spätne získať z hodnôt \delta_k pre všetky triedy pomocou funkcie softmax.
Na klasifikačné účely to prakticky znamená, že nám stačí odhadnúť \pi_k, f_k a dosadiť do vzťahu pre \delta_k.
Odhad apriórnej pravdepodobnosti je jednoducho iba relatívna početnosť (podiel počtu pozorovaní v konkrétnej skupine ku počtu všetkých), teda \pi_k=\frac{n_k}{n}.
Odhad hustoty f_k je však už náročnejší, a aby sa dal rozumne rýchlo vypočítať, budeme potrebovať zjednodušujúce predpoklady.
V nasledujúcom si preberieme tri (generatívne) klasifikátory, ktoré používajú rôzne odhady hustoty f_k.
8.2 Lineárna diskriminačná analýza
8.2.1 Jeden prediktor
V lineárnej diskriminačnej analýze (LDA) predpokladáme, že f_k je hustota normálneho rozdelenia,
f_k(x) = \frac{1}{\sqrt{2\pi}\sigma_k}\exp\left(-\frac{(x-\mu_k)^2}{2\sigma_k^2}\right),
kde \mu_k a \sigma_k^2 sú stredná hodnota a rozptyl prediktoru X v k-tej triede.
Ďalej predpokladáme, že \sigma_1=\ldots=\sigma_K=\sigma.
Po dosadení takto špecifikovanej hustoty do Bayesovej vety dostávame
Pr[Y=c_k|X=x] = \frac{\pi_k \frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(x-\mu_k)^2}{2\sigma^2}\right)}{\sum_{\ell=1}^K \pi_\ell \frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(x-\mu_\ell)^2}{2\sigma^2}\right)}.
Po zlogaritmovaní a vynechaní spoločných členov dostávame diskriminačnú funkciu
\delta_k(x) = x\frac{\mu_k}{\sigma^2} - \frac{\mu_k^2}{2\sigma^2} + \log\pi_k.
ktorá je zjavne lineárna v premennej x, čo vysvetľuje názov metódy.
Parametre skutočného rozdelenia sotvakedy poznáme. Ako odhad môžeme použiť výberový priemer a (vážený) rozptyl
\begin{split}
\hat\mu_k &= \frac1{n_k}\sum_{i:\ y_i=c_k}x_i\ , \\
\hat\sigma^2 &= \frac1{n-K}\sum_{k=1}^K\ \sum_{i:\ y_i=c_k}(x_i-\hat\mu_k)^2=\frac1{n-K}\sum_{k=1}^K(n_k-1)\sigma_k^2\ .
\end{split}
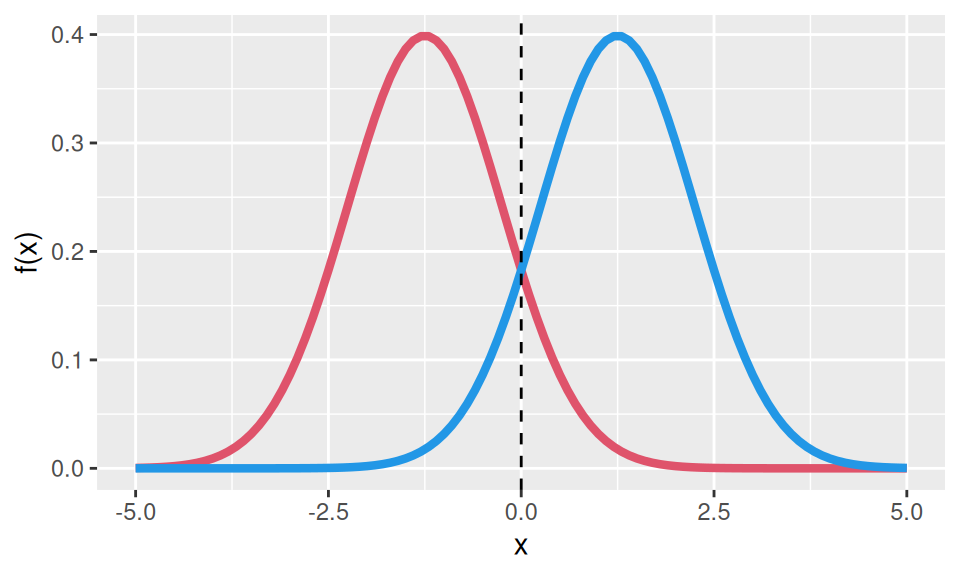
PoznámkaIlustrácia (LDA)
Pre K=2 a \pi_1=\pi_2, z rovnice \delta_1(x)=\delta_2(x) dostaneme intuitívnu hranicu (decision boundary) medzi triedami v bode x=\frac{\mu_1+\mu_2}{2}.
Teoretická hodnota rozhodovacej hranice pre rozdelenia N(-1.25,1^2) a N(1.25,1^2) je teda nula.
Rozšírenie modelu o ďalšie vysvetľujúce premenné so sebou prináša zahrnutie predpokladov nielen o ich marginálnom ale aj o ich združenom rozdelení pravdepodobnosti.
LDA predpokladá združené normálne rozdelenie, ktoré v sebe implicitne obsahuje aj normálne marginálne rozdelenia.
Nech \vec{X}=(X_1,\ldots,X_p) je náhodný vektor vysvetľujúcich premenných. Potom jeho rozdelenie pre Y=c_k je formálne \vec{X}\sim N(\boldsymbol{\mu}_k,\mathbf{\Sigma}) s hustotou definovanou vzťahom
f_k(\mathbf{x})=\frac1{(2\pi)^{p/2}|\mathbf{\Sigma}|^{1/2}}\exp\left(-\frac12(\mathbf{x}-\boldsymbol{\mu}_k)^T\mathbf{\Sigma}^{-1}(\mathbf{x}-\boldsymbol{\mu}_k)\right),
kde parameter
\boldsymbol{\mu}_k=E[\vec{X}|Y=c_k] je vektor stredných hodnôt a
\mathbf{\Sigma}=cov[\vec{X}|Y=c_1]=\ldots=cov[\vec{X}|Y=c_K] je p\times p kovariančná matica.
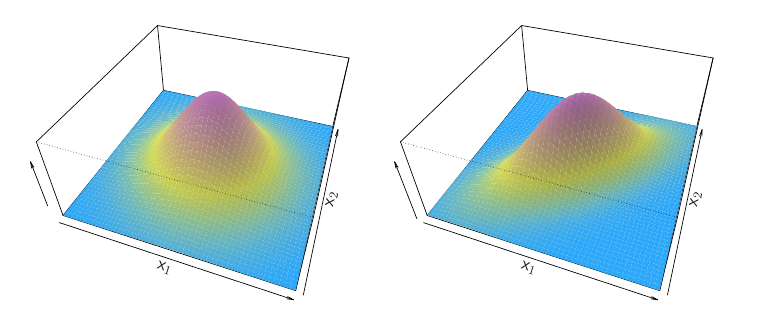
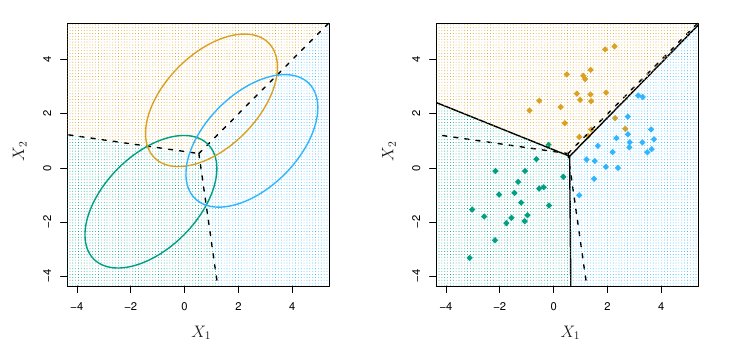
PoznámkaIlustrácia (2D normálne rozdelenie)
Príklad hustoty dvojrozmerného združeného normálneho rozdelenia s identickými varianciami a
diagonálnou kovariančnou maticou (na obrázku vľavo),
kladnou kovarianciou (vpravo).
Diskriminačná funkcia potom nadobudne tvar
\delta_k(\mathbf{x}) = \mathbf{x}^T\mathbf{\Sigma}^{-1}\boldsymbol{\mu}_k - \frac12\boldsymbol{\mu}_k^T\mathbf{\Sigma}^{-1}\boldsymbol{\mu}_k + \log\pi_k
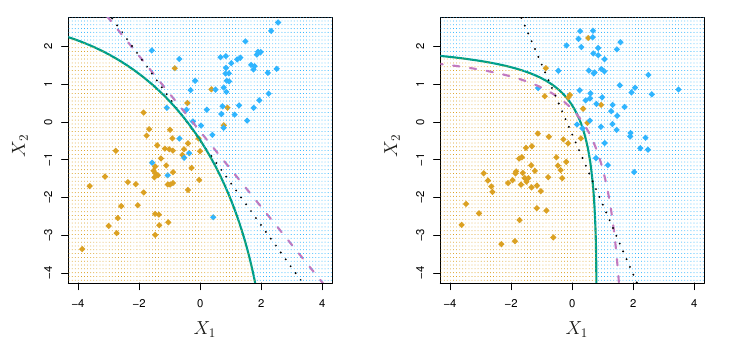
PoznámkaIlustrácia (LDA)
Príklad pre 3 triedy a 2 prediktory so strednými hodnotami \boldsymbol{\mu}_1=(1,2.5)^T, \boldsymbol{\mu}_2=(2.5,1)^T, \boldsymbol{\mu}_3=(-1.25,-1.25)^T a kovariančnou maticou \mathbf{\Sigma}=\begin{pmatrix} 1 & 0.5 \\ 0.5 & 1 \end{pmatrix}.
Z každého rozdelenia pochádza 20 pozorovaní, čiarkované sú teoretické rozhodovacie hranice, plné sú určené na základe pozorovaní.
8.3 Kvadratická diskriminačná analýza
Kvadratická diskriminačná analýza, QDA, zovšeobecňuje LDA v tom, že umožňuje každej skupine mať vlastnú kovariančnú maticu \mathbf{\Sigma}_k=cov[\vec{X}|Y=c_k], takže
(\vec X|Y=c_k)\sim N(\boldsymbol{\mu}_k,\mathbf{\Sigma}_k).
V dôsledku toho má diskriminačná funkcia tvar
\begin{split}
\delta_k(\mathbf{x}) &= -\frac12(\mathbf{x}-\boldsymbol{\mu}_k)^T\mathbf{\Sigma}_k^{-1}(\mathbf{x}-\boldsymbol{\mu}_k) - \frac12\log|\mathbf{\Sigma}_k^{-1}| + \log\pi_k \\
&= -\frac12 \mathbf{x}^T\mathbf{\Sigma}_k^{-1}\mathbf{x} + \mathbf{x}^T\mathbf{\Sigma}_k^{-1}\boldsymbol{\mu}_k - \frac12 \boldsymbol{\mu}_k^T\mathbf{\Sigma}_k^{-1}\boldsymbol{\mu}_k - \frac12\log|\mathbf{\Sigma}_k^{-1}| + \log\pi_k
\end{split}
čiže je kvadratickou funkciou argumentu x.
Pri QDA treba odhadnúť Kp(p+1) parametrov, zatiaľčo pri LDA iba Kp parametrov. Voľba medzi nimi je často otázkou bias-variance kompromisu.
Zhruba sa však dá povedať, že LDA zvolíme pri menšom počte dát, kedy je dôležité redukovať rozptyl modelu. Naproti tomu QDA sa odporúča pri veľkej trénovacej vzorke (takže rozptyl modelu nie je veľký problém), alebo vtedy, keď je zjavný rozdiel medzi kovariančnými maticami v jednotlivých triedach.
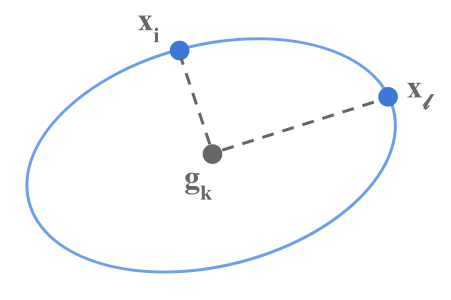
PoznámkaIlustrácia (LDA, QDA)
Príklad s 2 triedami a 2 prediktormi: čiarkovanou fialovou je skutočná hranica medzi triedami, bodkovanou čiernou LDA a plnou zelenou QDA rozhodovacia hranica. Všimnime si rozdiel v tvare/orientácii mraku bodov na pravom obrázku.
8.4 Naivný Bayesov klasifikátor
Namiesto predpokladu, že združená hustota f_k je z konkrétnej parametrickej triedy (z normálneho rozdelenia v prípade diskriminačnej analýzy), naivný Bayesov klasifikátor predpokladá iba nezávislosť prediktorovX_1,\ldots,X_p, čiže
f_k(\mathbf{x}) = f_{k1}(x_1)\cdot f_{k2}(x_2)\cdot\ldots\cdot f_{kp}(x_p)
kde f_{kj} je hustota rozdelenia premennej X_j ak Y=c_k.
To znamená, že už netreba odhadovať parametre združeného rozdelenia zodpovedné za vzťahy medzi prediktormi (v prípade normálneho rozdelenia to boli kovariancie).
Nezávislosti prediktorov samozrejme veľmi neveríme, preto názov naivný, no tento predpoklad slúži na uľahčenie výpočtu a často vedie k slušným výsledkom. Voľba je opäť otázkou bias-variance kompromisu.
Odhad f_{kj} závisí od typu premennej, máme niekoľko možností.
Ak je X_j kvantitatívna, potom môžeme predpokladať normalitu (X_j|Y=c_k)\sim N(\mu_{kj},\sigma_{kj}^2). Vtedy je to špeciálny prípad QDA s diagonálnymi kovariančnými maticami. Namiesto normálneho však môžeme predpokladať akékoľvek iné parametrické, spojité rozdelenie.
Ak je X_j kvantitatívna, ale nechceme model viazať predpokladom o parametrickej triede rozdelenia, môžeme použiť histogram alebo jadrový odhad hustoty.
Ak je X_j kvalitatívna, potom nám stačí rozdelenie odhadnúť relatívnou početnosťou v skupinách.
8.5 Geometrický pohľad na LDA
8.5.1 Hľadanie vhodného podpriestoru
8.5.1.1 Problém
Klasifikačný problém sa dá riešiť aj geometricky. Je základom špeciálneho prípadu LDA, ktorý sa volá Kanonická diskriminačná analýza (canonical discrimination analysis, CDA). Vyžaduje rovnaké apriórne pravdepodobnosti aj kovariančné matice naprieč skupinami.
Pre jednoduchosť majme dva prediktory X_1,X_2 a trojhodnotovú odozvu Y (t.j. 3 skupiny).
Z prieskumného/popisného hľadiska hľadáme taký podpriestor, v ktorom by boli skupiny dobre rozlíšiteľné.
Projekcia na jednu či druhú os nie je vo všeobecnosti najlepšia.
Hľadáme takú os (sprostredkovanú takým vektorom \mathbf{u}), že lineárna kombinácia Z=u_1X_1 + u_2X_2 pomôže skupiny oddeliť najlepšie
8.5.1.2 Rozptyl v skupinách a medzi skupinami
Celková variancia sa dá rozložiť na varianciu vo vnútri skupín (angl. within) a varianciu medzi skupinami (angl. between):
\mathbf{V} = \mathbf{W} + \mathbf{B}
kde
celková variancia je daná vzťahom \mathbf{V}=\frac1{n-1}\mathbf{X}^T\mathbf{X},
variancia vo vnútri skupín sa skladá z jednotlivých variančných matíc,
\mathbf{W}=\sum_{k=1}^K\frac{n_k-1}{n-1}\mathbf{W}_k
pričom \mathbf{W}_k=\frac1{n_k-1}\mathbf{X}_k^T\mathbf{X}_k,
variancia medzi skupinami vyjadruje variabilitu centroidov \mathbf{g}_k jednotlivých skupín okolo globálneho centroidu (ťažiska) \mathbf{g}, takže platí
\mathbf{B}=\sum_{k=1}^K\frac{n_k}{n-1}(\mathbf{g}_k-\mathbf{g})(\mathbf{g}_k-\mathbf{g})^T
kde \mathbf{g}=\sum_{k=1}^K\frac{n_k}{n} \mathbf{g}_k, a \mathbf{g}_k=(\bar{x}_{k1},\ldots,\bar{x}_{kp})^T, pričom \bar{x}_{kj} je priemer j-tej premennej v k-tej skupine.
8.5.1.3 Reformulácia problému
Z rozkladu celkovej variancie dostávame aj rozklad kvadratickej formy
\mathbf{u}^T\mathbf{V}\mathbf{u} = \mathbf{u}^T\mathbf{W}\mathbf{u} + \mathbf{u}^T\mathbf{B}\mathbf{u}
Algebraicky, hľadáme takú lineárnu kombináciu prediktorov, ktorá (ideálne)
minimalizuje rozptyl vo vnútri skupín: \min\{\mathbf{u}^T\mathbf{W}\mathbf{u}\}
maximalizuje rozptyl medzi skupinami: \max\{\mathbf{u}^T\mathbf{B}\mathbf{u}\}
To je však (vo všeobecnosti) nemožné dosiahnuť súčasne.
Východiskom z patovej situáce je kompromis.
8.5.1.4 Kompromisné kritérium
Sú dve možnosti:
korelačný pomer \max\left\{\frac{\mathbf{u}^T\mathbf{B}\mathbf{u}}{\mathbf{u}^T\mathbf{V}\mathbf{u}}\right\}
Oba optimalizačné problémy sa riešia rovnako, ukážeme si prvý z nich.
Najprv je výhodné zaviesť normalizačné obmedzenie \mathbf{u}^T\mathbf{V}\mathbf{u}=1. Problém sa zmení na hľadanie extrému funkcie s podmienkou, a to metódou Lagrangeových multiplikátorov,
\begin{split}
L(\mathbf{u}) = \mathbf{u}^T\mathbf{B}\mathbf{u} - \lambda(\mathbf{u}^T\mathbf{V}\mathbf{u}-1) & \\
\frac{\partial L(\mathbf{u})}{\partial \mathbf{u}} = 2\mathbf{B}\mathbf{u} - 2\lambda\mathbf{V}\mathbf{u} \qquad\qquad & \\
\qquad\qquad 2\mathbf{B}\hat{\mathbf{u}} - 2\lambda\mathbf{V}\hat{\mathbf{u}} & = 0 \\
\mathbf{B}\hat{\mathbf{u}} & = \lambda\mathbf{V}\hat{\mathbf{u}} \\
\mathbf{V}^{-1}\mathbf{B}\hat{\mathbf{u}} & = \lambda\hat{\mathbf{u}}
\end{split}
takže náš hľadaný optimálny vektor \hat{\mathbf{u}} je vlastný vektor matice \mathbf{V}^{-1}\mathbf{B}.
(Pre detaily riešenia problému zovšeobecnených vlastných čísel pozri Ghojogh et al., 2022.)
8.5.1.5 Šikmá projekcia
Princíp hľadania vhodného podpriestoru využíva aj tzv. analýza hlavných komponentov (angl. principal component analysis, PCA), čo je metóda učenia bez asistencie. Hľadá takú lineárnu transformáciu, aby osi boli orientované v smere postupne od najväčšieho rozptylu údajov až po najmenší rozptyl.
Diskriminačná analýza môže v špeciálnom prípade pripomínať PCA vykonanú na centroidoch, avšak na rozdiel od nej, diskriminačná analýza body jednotlivých pozorovaní zobrazuje na osi šikmo, v smere hlavnej poloosi elipsoidu spoľahlivosti, čiže v smere vektora \mathbf{u}.
Po nájdení prvej významnej osi (canonical axis) asociovanej s prvým optimálnym vektorom \mathbf{u}_1 môžeme hľadať druhú, ktorá je s predošlou nekorelovaná a je čo najviac diskriminačná (v smere čo najväčšieho rozptylu, aby sa ukázali ďalšie rozdiely medzi triedami odozvy), atď.
Počet q hľadaných osí Z_1,\ldots,Z_q je daný vzťahom q=\min(K-1,p). V praktických aplikáciách sa použije iba prvých r diskriminantov,
či už r\in\{1,2\} kvôli zobrazovacím možnostiam,
alebo tak, aby dokopy vysvetlili 90-95% medzi-skupinového rozptylu (vyjadrené podielom vlastných čísel \sum_j^r\lambda_j/\sum_j^q\lambda_j).
8.5.2 Vzdialenosť a klasifikácia
8.5.2.1 Metrika
Euklidovská vzdialenosť ľubovoľných dvoch vektorov \mathbf{a},\mathbf{b}\in\mathbb{R}^p sa dá vyjadriť pomocou skalárneho súčinu (a jednoduchej metriky danej jednotkovou maticou \mathbf{I}_p)
d^2(\mathbf{a},\mathbf{b})=(\mathbf{a}-\mathbf{b})^T(\mathbf{a}-\mathbf{b})=(\mathbf{a}-\mathbf{b})^T\mathbf{I}_p(\mathbf{a}-\mathbf{b})
Vo všeobecnosti môže byť vzdialenosť daná nejakou metrikou, ktorú reprezentuje matica \mathbf{M},
d_\mathbf{M}^2(\mathbf{a},\mathbf{b})=(\mathbf{a}-\mathbf{b})^T\mathbf{M}(\mathbf{a}-\mathbf{b})
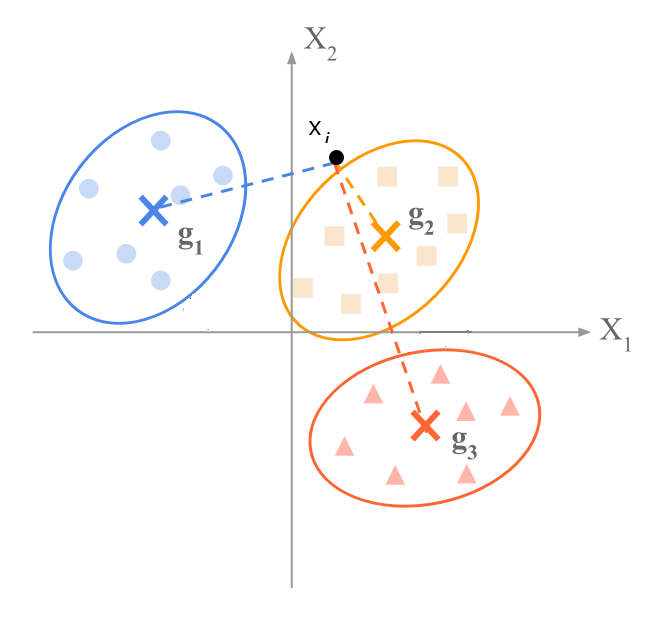
Keď chceme zaradiť určitý bod \mathbf{x}_i do jednej z tried, musíme porovnať vzdialenosti k ich centroidom \mathbf{g}_k a vybrať tú najmenšiu. Namiesto euklidovskej metriky, ktorá nerešpektuje korelačnú štruktúru v skupinách, sa použije Mahalanobisova metrika s maticou \mathbf{W}^{-1}, pre ktorú je vzdialnosť daná
d^2(\mathbf{x}_i,\mathbf{g}_k)=(\mathbf{x}_i-\mathbf{g}_k)^T\mathbf{W}^{-1}(\mathbf{x}_i-\mathbf{g}_k)
Napríklad, na nasledujúcom obrázku body \mathbf{x}_i,\mathbf{x}_\ell ležia na tom istom elipsoide (t.j. vrstevnici hustoty rozdelenia). Mahalanobisova vzdialenosť je rovnaká, avšak euklidovská nie.
8.5.2.2 Klasifikácia
Keď rozvinieme vzťah pre Mahalanobisovu vzdialenosť,
\begin{split}
d^2(\mathbf{x}_i,\mathbf{g}_k) &= (\mathbf{x}_i-\mathbf{g}_k)^T\mathbf{W}^{-1}(\mathbf{x}_i-\mathbf{g}_k) \\
&= \underbrace{\mathbf{x}_i^T\mathbf{W}^{-1}\mathbf{x}_i}_{\text{konšt.}} - \underbrace{2\mathbf{x}_i^T\mathbf{W}^{-1}\mathbf{g}_k + \mathbf{g}_k^T\mathbf{W}^{-1}\mathbf{g}_k}_{\text{závisí od } k}
\end{split}
okamžite vidno podobnosť s diskriminačnou funkciou LDA.
8.6 Príklady
8.6.1 Lineárna diskriminačná analýza
TipPríklad (kosatce)
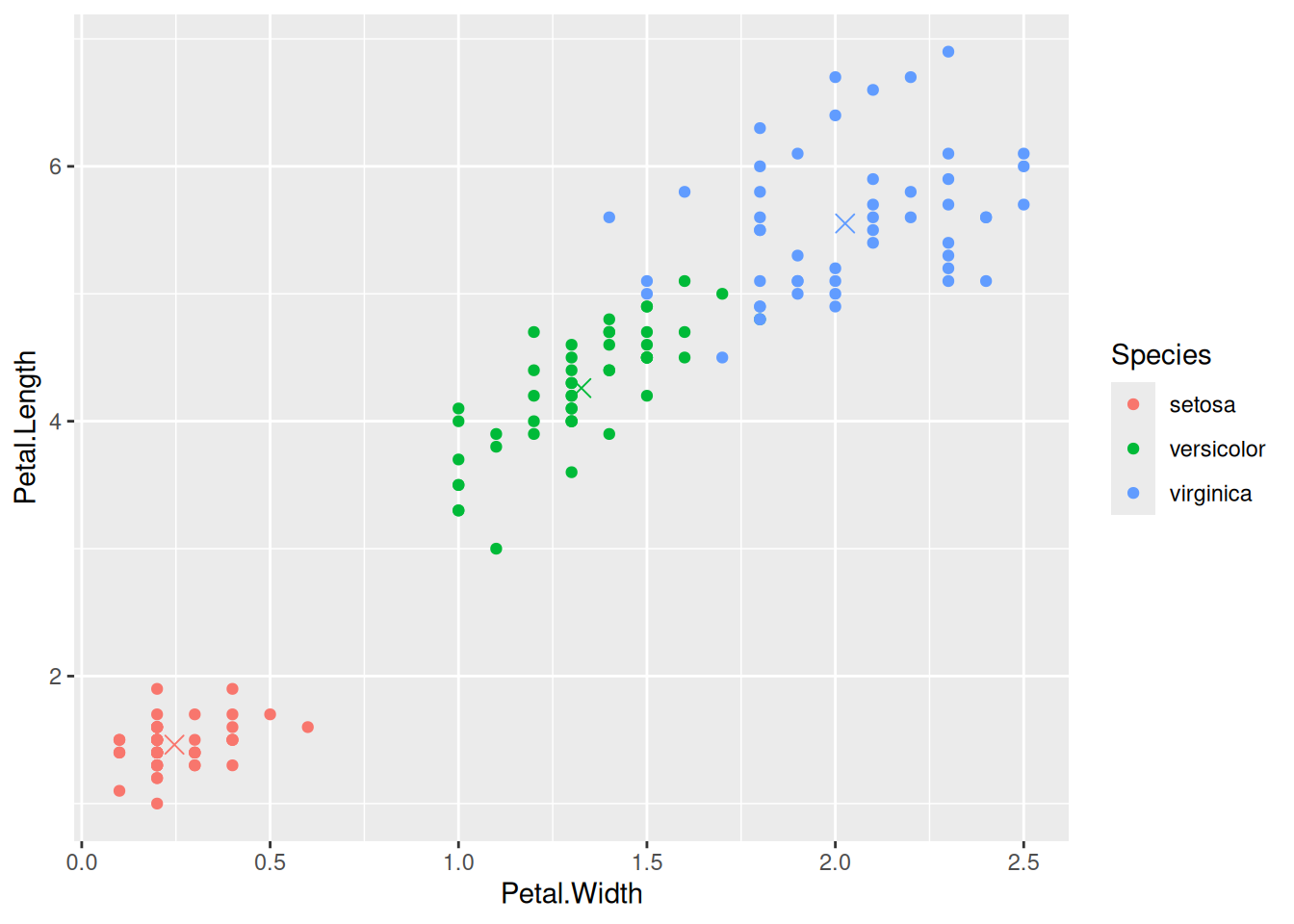
Príklad s rozmermi korunného lupienku kosatcov: 2 prediktory (šírka a dĺžka lupienku), 3 triedy.
Call:
lda(Species ~ Petal.Width + Petal.Length, data = iris)
Prior probabilities of groups:
setosa versicolor virginica
0.3333333 0.3333333 0.3333333
Group means:
Petal.Width Petal.Length
setosa 0.246 1.462
versicolor 1.326 4.260
virginica 2.026 5.552
Coefficients of linear discriminants:
LD1 LD2
Petal.Width 2.402394 5.042599
Petal.Length 1.544371 -2.161222
Proportion of trace:
LD1 LD2
0.9947 0.0053
Výstup z funkcie MASS::lda obsahuje
odhady apriórnych pravdepodobností \pi_k,
skupinové priemery \mu_{kj} (centroidy \boldsymbol{\mu}_k=(\mu_{k1},\mu_{k2}) ktoré poznáme aj ako \mathbf{g}_k),
transformačné vektory \mathbf{u}_i (stĺpce) a nakoniec
percento vysvetlenosti medzi-skupinovej variability jednotlivými diskriminantami. Tu by nám na klasifikáciu zjavne stačil iba prvý z nich.
Zobrazíme východiskovú situáciu s vypočítanými centroidmi.
Kód
# zobrazenie tried v priestore prediktorov aj s centroidmicentr.df <- fit |>getElement("means") |># treba ich ešte tibble::as_tibble(rownames ="Species") iris |>ggplot() +aes(x = Petal.Width, y = Petal.Length, color = Species) +geom_point() +geom_point(data = centr.df, shape =4, size =3, show.legend =FALSE)
Vidno, že triedy sú pomerne dobre vymedzené, ale v priestore lineárnych diskriminantov bude separácia ešte presnejšia.
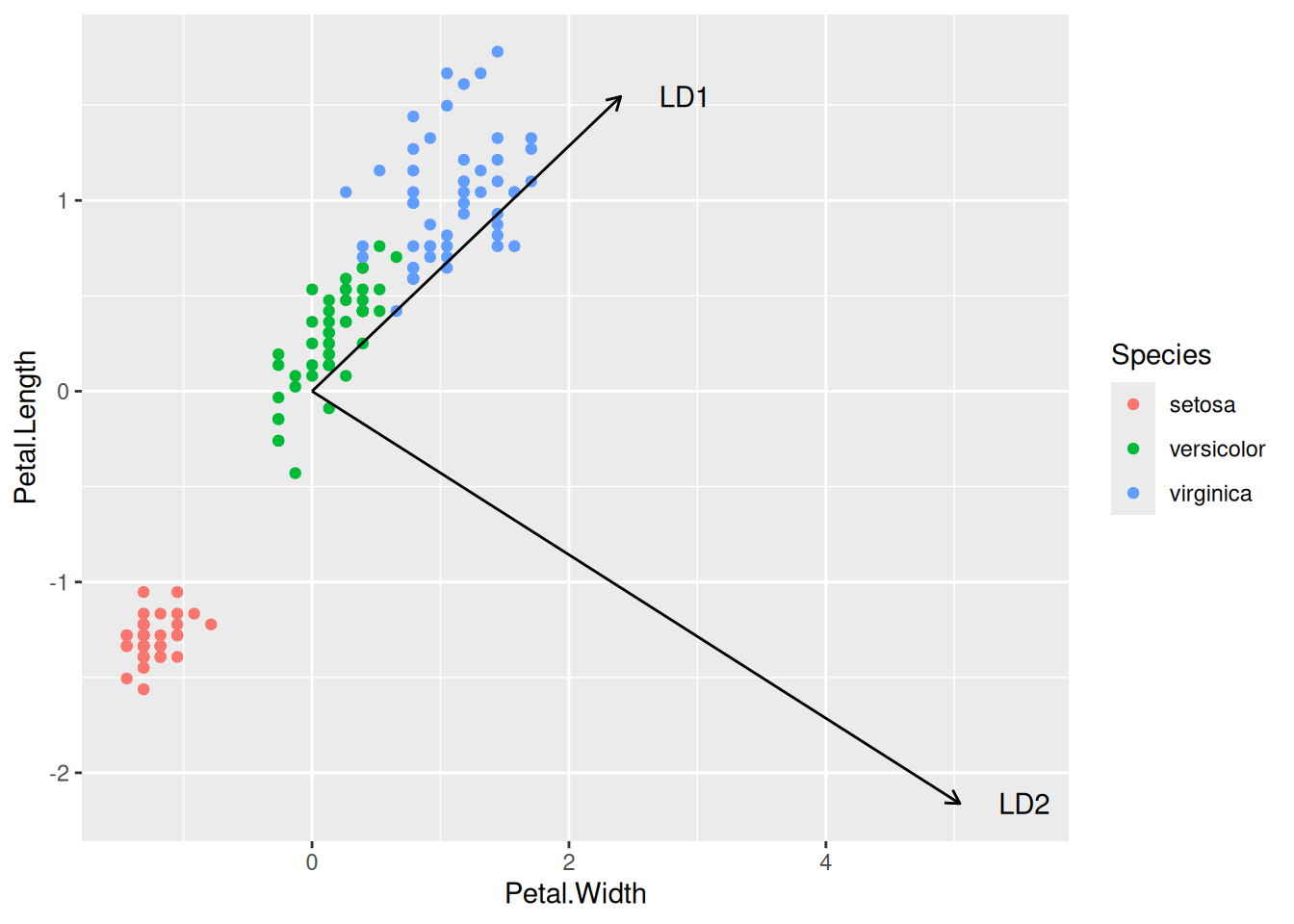
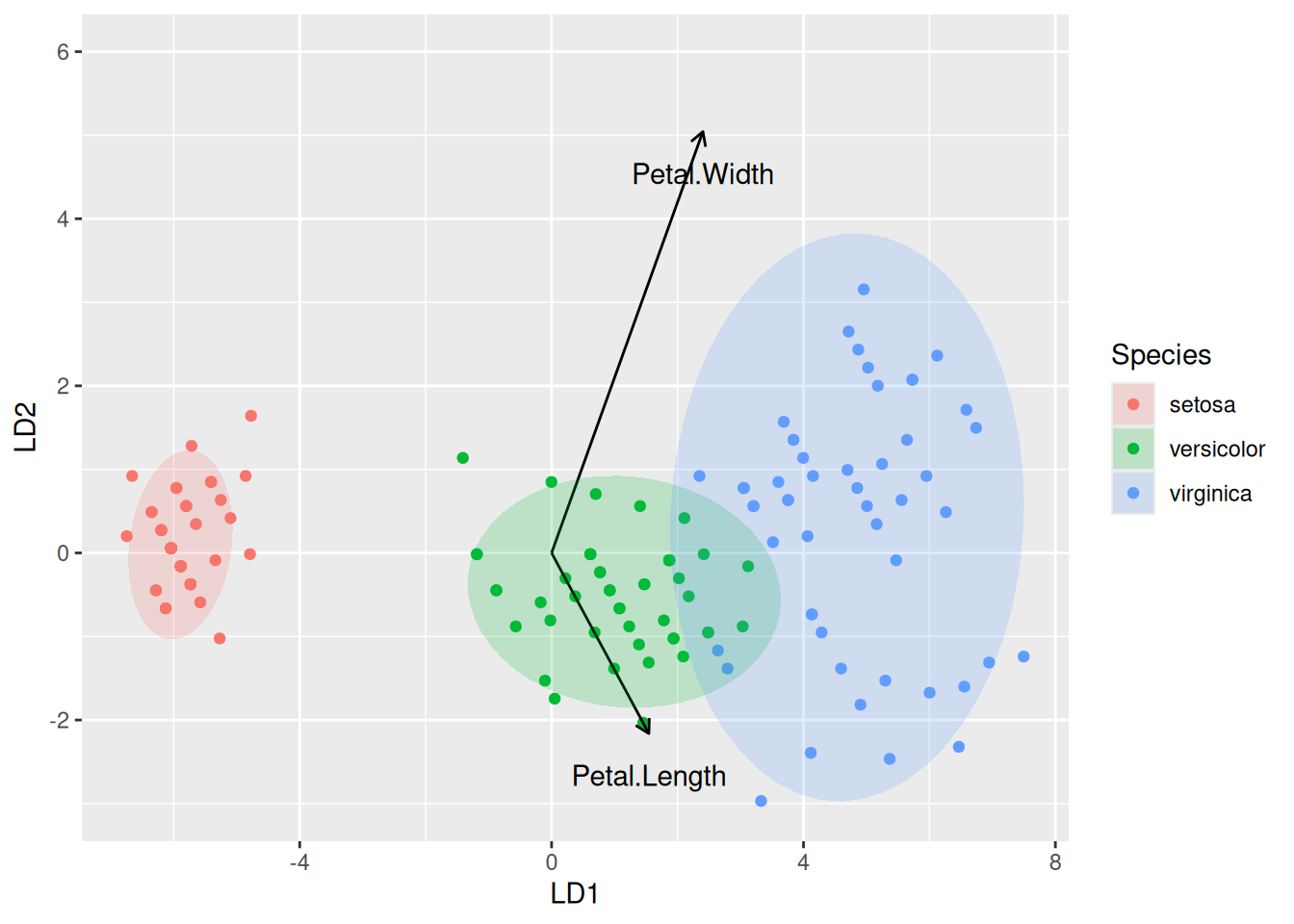
Pomocou tzv. biplotu (pozri detailnú publikáciu Greenacre, 2010) zobrazíme oba priestory premietnuté na sebe.
Kód
# prvky transformačných vektorov "u" pre zobrazenie v priestore prediktorovtrans.df <- fit |>coef() |># to isté ako getElement("scaling")# apply(2, function(x) x/sqrt(sum(x^2))) |> # konverzia na jednotkové vektory (voliteľné)t() |>as.data.frame() |># setNames(fit$scaling |> rownames()) |> # lebo apply zruší názvy riadkovcbind(variable = fit$scaling |>colnames())# biplotiris |> purrr::map_if(is.numeric, scale) |># centrovanie a škálovanieas.data.frame() |>ggplot() +aes(x = Petal.Width, y = Petal.Length) +geom_point(aes(color = Species)) +geom_segment(aes(x =0, y =0, xend = Petal.Width, yend = Petal.Length), data = trans.df,arrow =arrow(length =unit(0.5, "char")) ) +geom_text(aes(x = Petal.Width, y = Petal.Length, label = variable), data = trans.df, nudge_x =0.5) # biplot pomocou externého balíku# library(devtools)# install_github('fawda123/ggord')# ggord::ggord(fit, iris$Species, size = 2)# prvky transformačných vektorov "u" pre zobrazenie v priestore diskriminantovtrans.df <- fit |>getElement("scaling") |>as.data.frame() |> tibble::rownames_to_column(var ="variable")# výpočet hodnôt diskriminantov (aj pomocou predict(fit)$x)LD <- iris[,4:3] |>as.matrix() |> (`%*%`)(fit$scaling) |># transformácia dát do priestoru diskriminantovapply(2, scale, center =TRUE, scale =FALSE) |># centrovanie diskriminantovcbind.data.frame(iris[5]) # biplot v priestore diskriminantov LD |>ggplot() +aes(LD1, LD2) +geom_point(aes(color = Species)) +geom_segment(aes(x =0, y =0, xend = LD1, yend = LD2), data = trans.df,arrow =arrow(length =unit(0.5, "char")) ) +geom_text(aes(x = LD1, y = LD2, label = variable), data = trans.df, nudge_y =-0.5) +stat_ellipse(aes(fill = Species), geom ="polygon", alpha =0.2) +ylim(-3, 6)
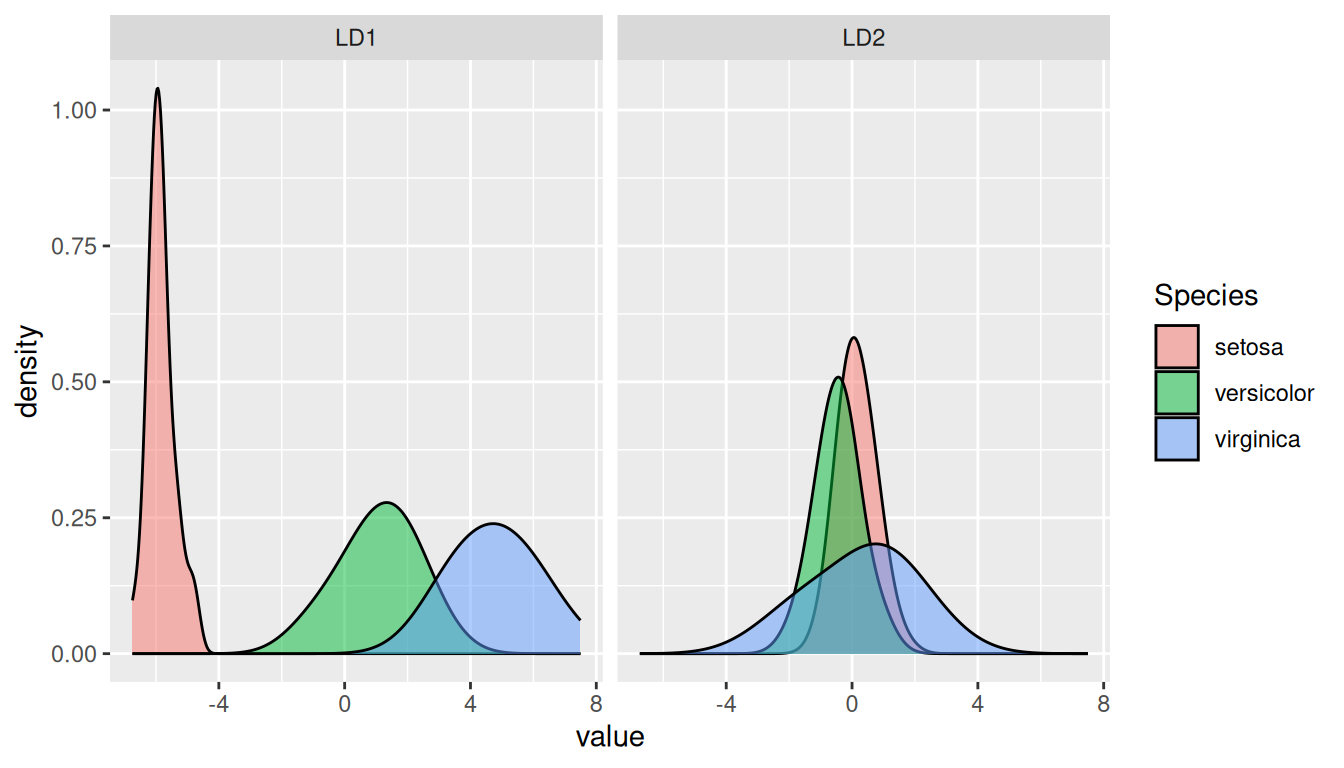
Vyhladená hustota hodnôt diskriminantov napovie, ako vyzerá výsledná, aposteriórna pravdepodobnosť jednotlivých tried.
Kód
# hustota pravdepodobnosti podľa tried v priestore diskriminantovLD |> tidyr::pivot_longer(-Species, names_to ="diskriminant", values_to ="value") |>ggplot() +aes(x = value, fill = Species) +geom_density(alpha =0.5, adjust =2) +facet_wrap(~diskriminant)
Kód
# empirická hustota v triedach pre prvý diskriminant vstavanou funkciou# MASS::ldahist(iris[3:4], iris$Species)
Nakoniec v pravidelnej mriežke hodnôt prediktorov (šírky a dĺžky lupienkov) vykonáme predpovede a zobrazíme delenie priestoru, takže je možná aj vizuálna klasifikácia.
Kód
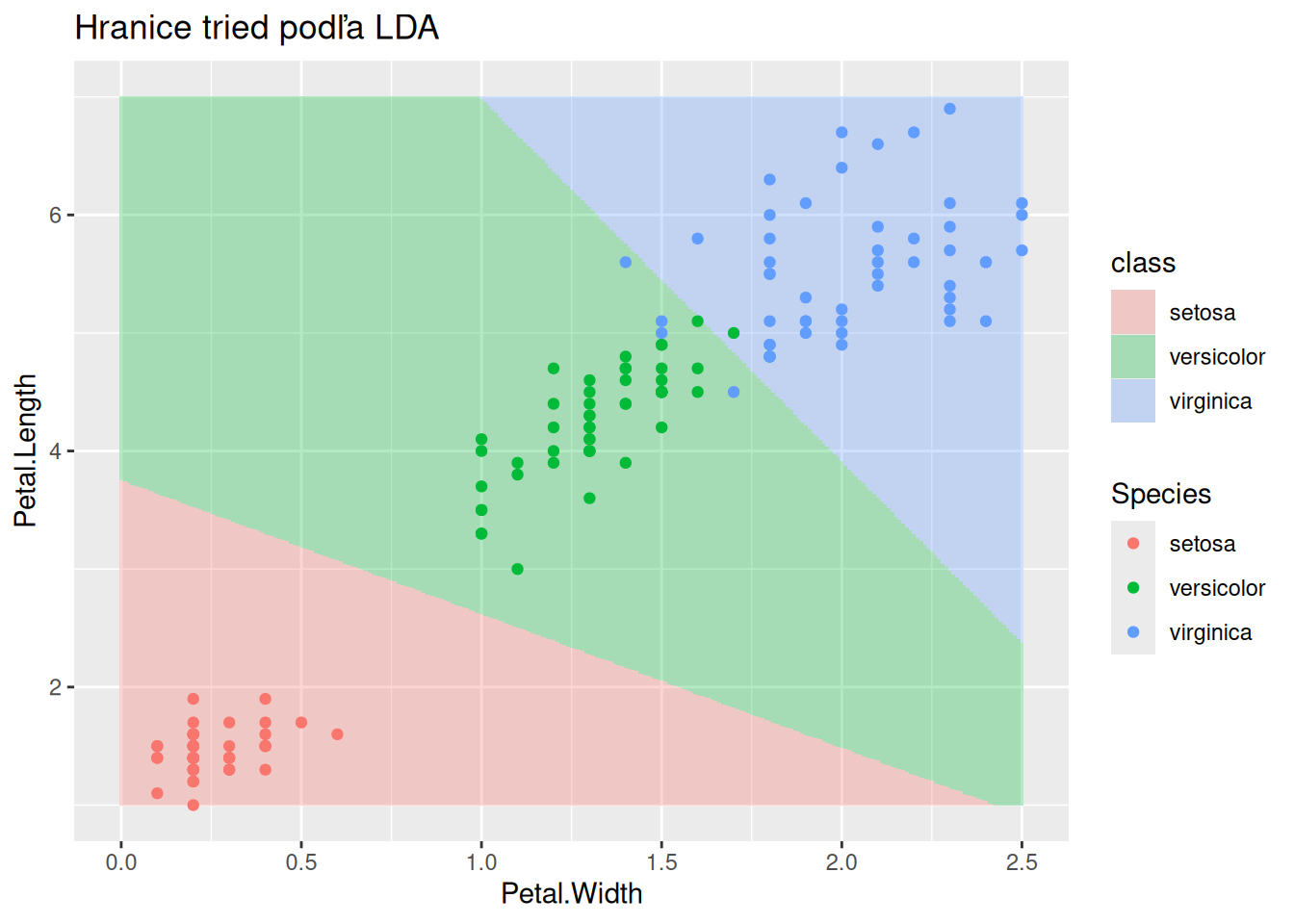
# predikcia v trénovacej vzorke (obsahuje triedy, ich pravdepodobnosti aj hodnoty diskriminantov)# pred <- predict(fit)# (urpbiť: vykresliť pravdepodobnosti pre jednotlivé triedy a diskrimininanty ako alternatívu ku vyhladeným frekvenčným polynómom hore)# nové dáta a predpovedexgrid <-expand.grid(Petal.Length =seq(1,7,0.01), Petal.Width =seq(0,2.5,0.01)) pred <-cbind.data.frame( xgrid, class =predict(fit, newdata = xgrid) |>getElement("class"))# zobrazenie oblastí klasifikácie do jednotlivých triedpred |>ggplot() +aes(x = Petal.Width, y = Petal.Length) +geom_tile(aes(fill = class), alpha =0.3) +geom_point(aes(color = Species), data = iris) +ggtitle("Hranice tried podľa LDA")
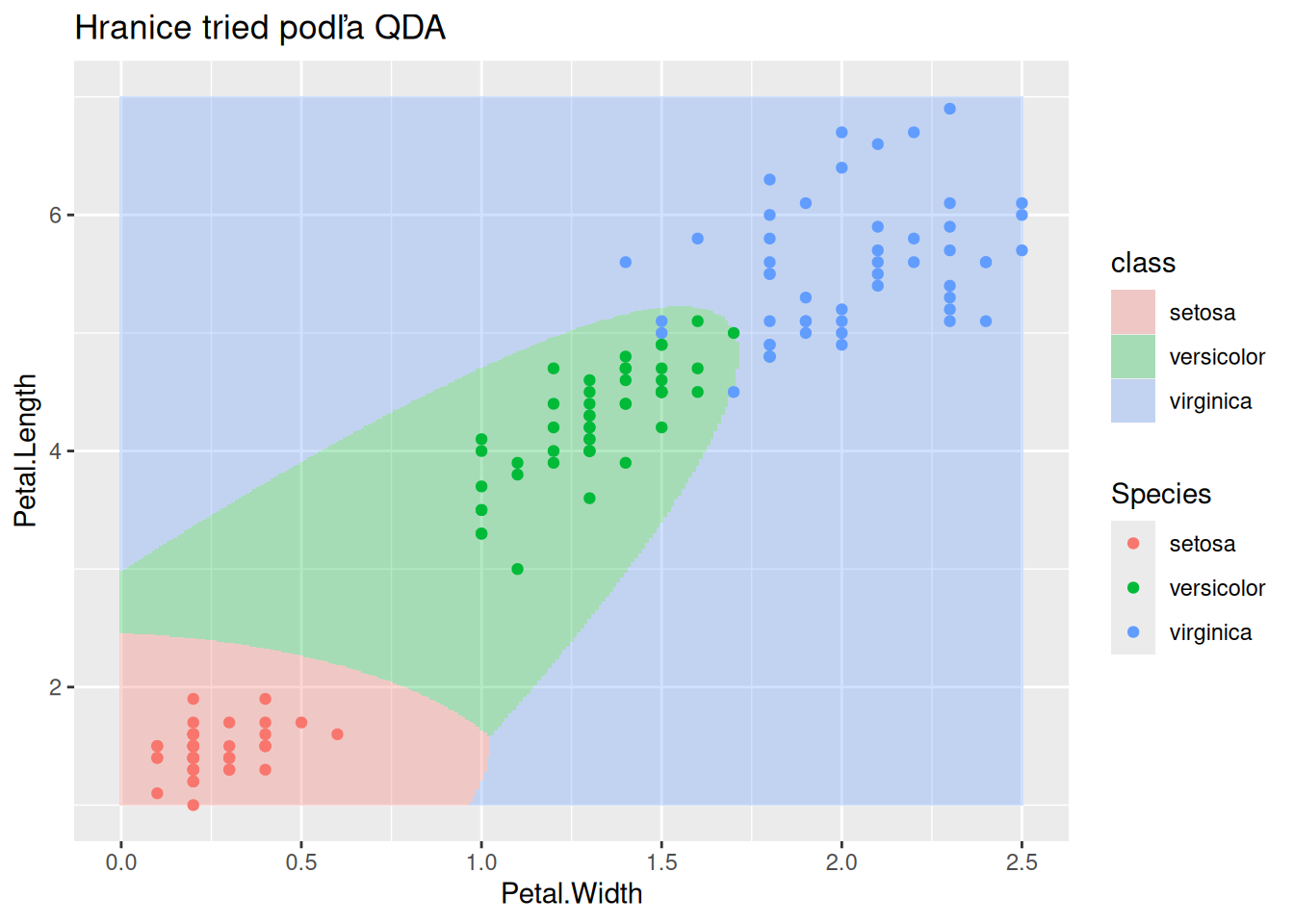
Rovnaký príklad, ale tentokrát umožníme triedam mať svoju vlastnú kovariančnú maticu. Delenie priestoru sa zásadne zmení, pretože hranice už nie sú lineárne, ale kvadratické.
# nové dáta a predpovedexgrid <-expand.grid(Petal.Length =seq(1,7,0.01), Petal.Width =seq(0,2.5,0.01) ) pred <-cbind.data.frame( xgrid, class =predict(fit, newdata = xgrid) |>getElement("class"))# zobrazenie oblastí klasifikácie do jednotlivých triedpred |>ggplot() +aes(x = Petal.Width, y = Petal.Length) +geom_tile(aes(fill = class), alpha =0.3) +geom_point(aes(color = Species), data = iris) +ggtitle("Hranice tried podľa QDA")
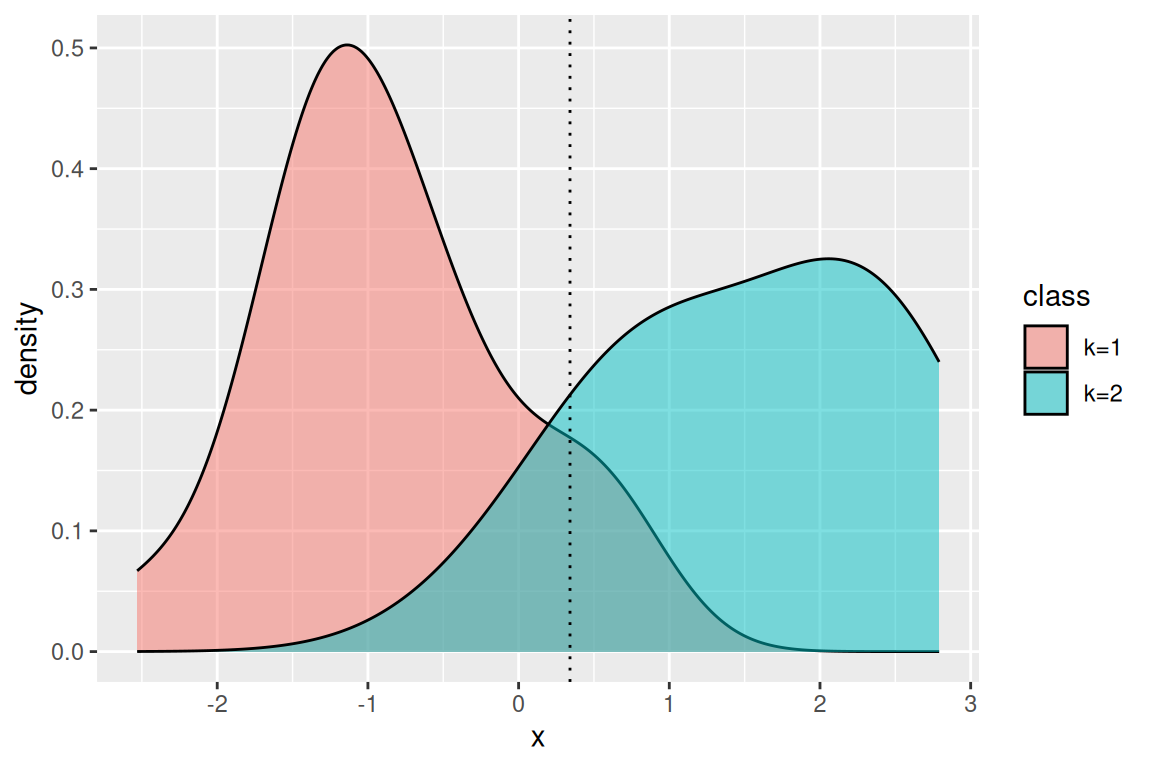
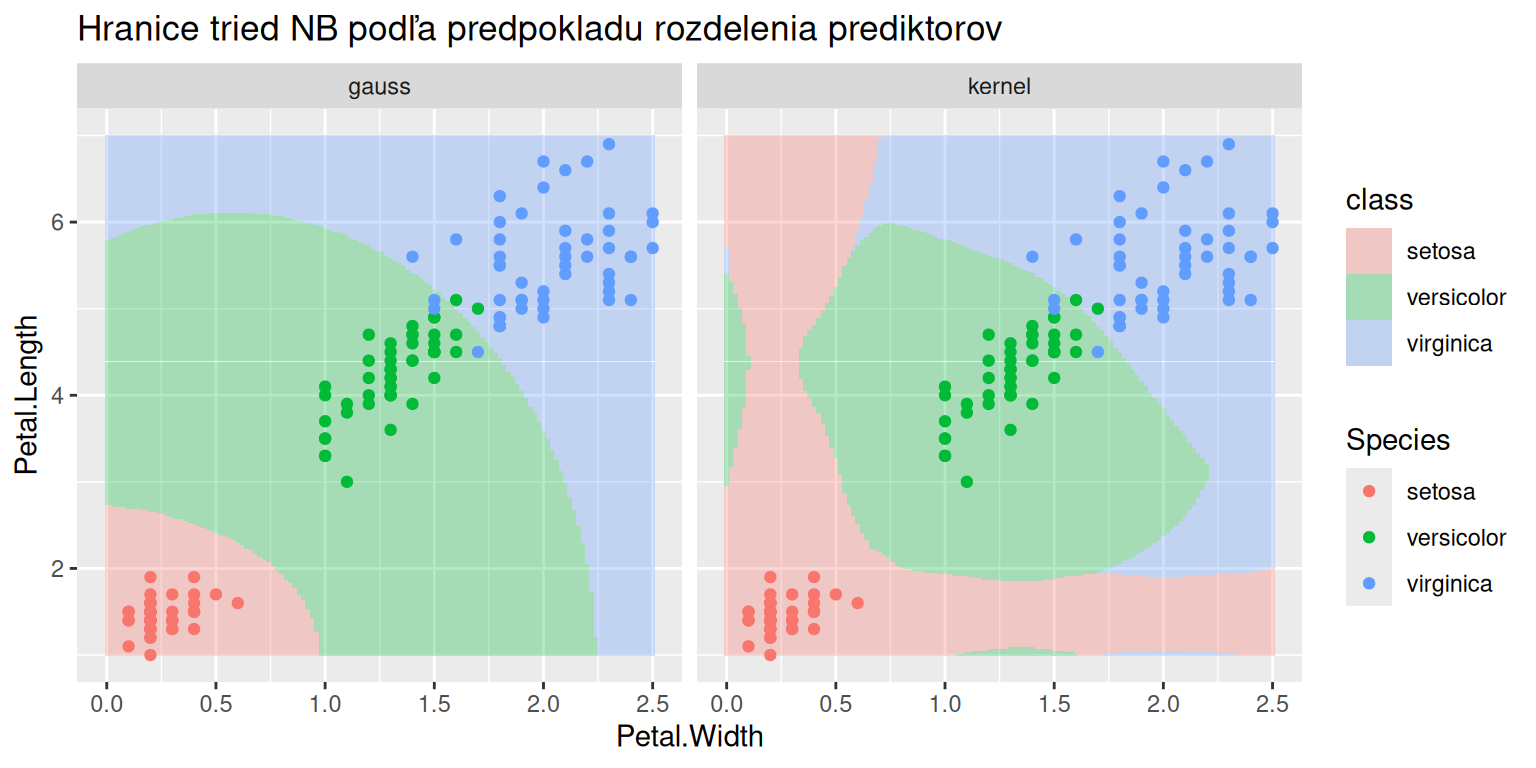
8.6.3 Naivný Bayesov klasifikátor
TipPríklad (kosatce)
Tentokrát uvoľníme požiadavku normality, a na druhej strane zavedieme obmedzenie – nezávislosť prediktorov.
Z tých známejších balíkov sú dostupné funkcie klaR::NaiveBayes a e1071::naiveBayes, avšak z hladiska funkcionality, rýchlosti, užívateľskej prívetivosti aj (minimálnej) externej závislosti je najlepší balík naivebayes.
Kód
# --- balíkom klaR# fit <- klaR::NaiveBayes(Species ~ Petal.Width + Petal.Length, data = iris, usekernel = T, adjust = 2.) # výstup je neformátovaný, list# plot(fit)# --- balíkom e1071# fit <- e1071::naiveBayes(Species ~ Petal.Width + Petal.Length, data = iris)# výstup tvorí vektor apriórnych pravdepodobností a pod názvom "Conditional probabilities" stredná hodnota a štandardná odchýlka prediktorov v jednotlivých triedach (žiaľ neoznačné).# --- balíkom naivebayes# odhad modelu s predpokladom normálneho (parametrického) a vyhladeného (neparametrického) rozdelenia. Argument adjust násobí prednastavenú šírku pásma jadrového vyhladenia.fit <-list(gauss = naivebayes::naive_bayes(Species ~ Petal.Width + Petal.Length, data = iris),kernel = naivebayes::naive_bayes(Species ~ Petal.Width + Petal.Length, data = iris,usekernel =TRUE, adjust =2))
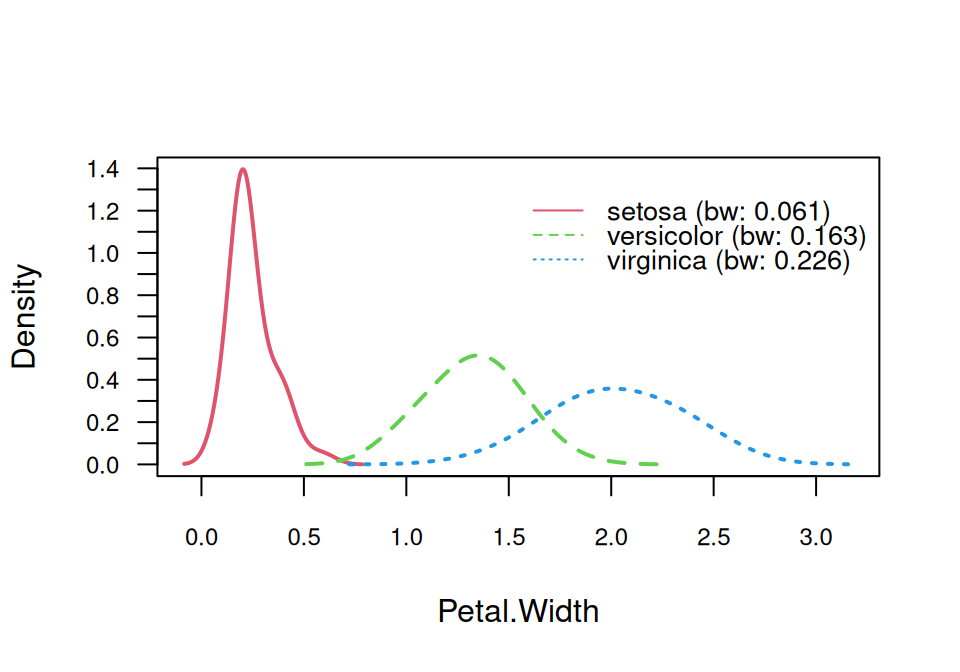
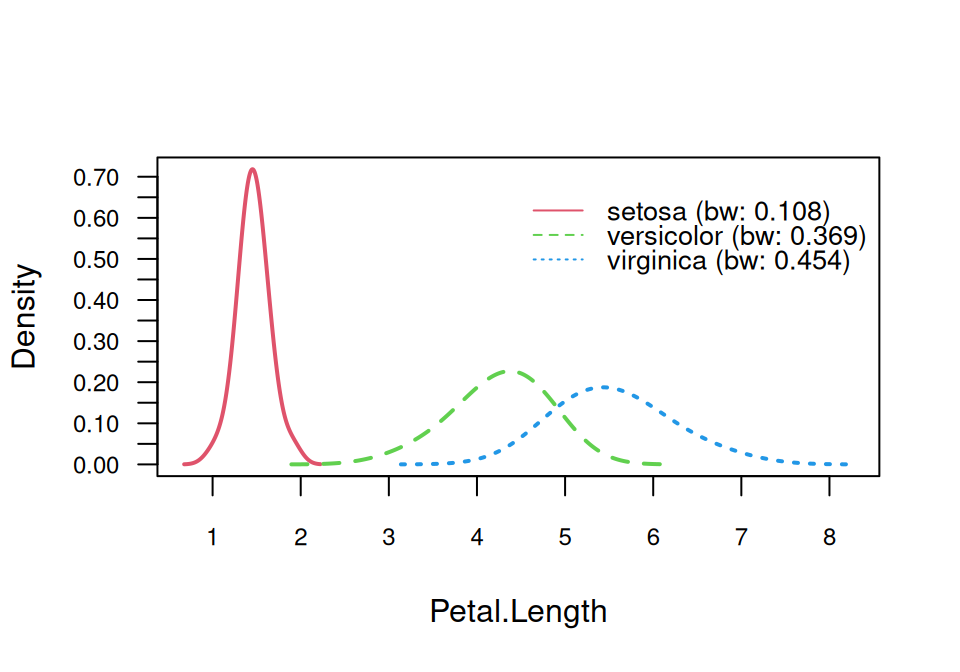
Najprv zobrazíme (vyhladenú) hustotu v triedach.
Kód
# zobrazenie vyhladenej hustoty v jednotlivých triedachfit$kernel |>plot(arg.num =list(lwd =2))
Následne zobrazíme delenie priestoru podľa jednotlivých modelov (predpokladov).
Kód
xgrid <-expand.grid(Petal.Length =seq(1,7,0.02), Petal.Width =seq(0,2.5,0.02) ) fit |> purrr::map_dfc(predict, newdata = xgrid, type ="class") |>cbind(xgrid) |> tidyr::pivot_longer(c(gauss, kernel), names_to ="distrib", values_to ="class") |>ggplot() +aes(x = Petal.Width, y = Petal.Length) +geom_tile(aes(fill = class), alpha =0.3) +geom_point(aes(color = Species), data = iris) +facet_wrap(~distrib) +ggtitle("Hranice tried NB podľa predpokladu rozdelenia prediktorov")
8.7 Zdroje
James, Witten, Hastie, Tibshirani (2021): An Introduction to Statistical Learning - with Applications in R. 2nd ed. Springer. https://www.statlearning.com/
Sanchez, G., Marzban, E. (2020) All Models Are Wrong: Concepts of Statistical Learning. https://allmodelsarewrong.github.io
Venables, W. N. and Ripley, B. D. (2002) Modern Applied Statistics with S. Fourth edition. Springer.










{kind=link}