Klasická i logistická regresia sú špeciálnymi prípadmi zovšeobecneného lineárneho modelu (angl. generalized linear model, GLM), ktorý sa skladá z troch častí (alebo skupín predpokladov):
rozdelenie pravdepodobnosti Y,
lineárny prediktor, napr. lineárna funkcia \eta(x) = b_1+b_2x,
link funkcia g, pre ktorú platí
\mu = g^{-1}(\eta) \qquad\text{resp.}\qquad g(\mu) = \eta
kde \mu tradične predstavuje strednú hodnotu Y, teda \mu(x)\equiv E[Y|X=x].
Variancia odozvy je modelovaná dvojzložkovo, var[Y|X]=\sigma^2 V(\mu), kde V je variančná funkcia (definovaná rozdelením) a \sigma^2 je základný rozptyl.
7.2 Rozdelenie pravdepodobnosti
Premenná Y môže mať ktorékoľkvek z exponenciálnej triedy rozdelení, ktorá je daná hustotou
f_Y(y|\theta) = h(y)\exp\Big(\alpha(\theta)\cdot T(y)-A(\theta)\Big)
so známymi funkciami h, \alpha, T, A.
Do exponenciálnej triedy patria napríklad
z diskrétnych rozdelení: Bernouliho, binomické (s daným n), Poissonovo,
zo spojitých rozdelení: normálne, exponenciálne, gamma, \chi^2, beta.
Niektoré rozdelenia sú členom exponenciálnej triedy iba pre zafixované hodnoty niektorého zo svojich parametrov. Podmienkou je totiž nemenný nosič hustoty pravdepodobnosti.
Napríklad pravdepodobnostná funkcia (prob. mass function) binomického rozdelenia s fixným parametromn sa dá prepísať do všeobecného tvaru:
f(y) = {n \choose y} p^y(1-p)^{n-y} = {n \choose y} \exp\left(y\log\left(\frac{p}{1-p}\right)+n\log(1-p)\right)
pre y\in\{0,1,2,\ldots,n\}, kde je vidieť, že
h(y)={n \choose y},
\alpha=logit,
T(y)=y,
A(p)=-n\log(1-p).
Pre normálne rozdelenief(y;\mu,\sigma) = \frac1{2\pi\sigma^2}exp\left(-\frac{(y-\mu)^2}{2\sigma^2}\right) zas platí
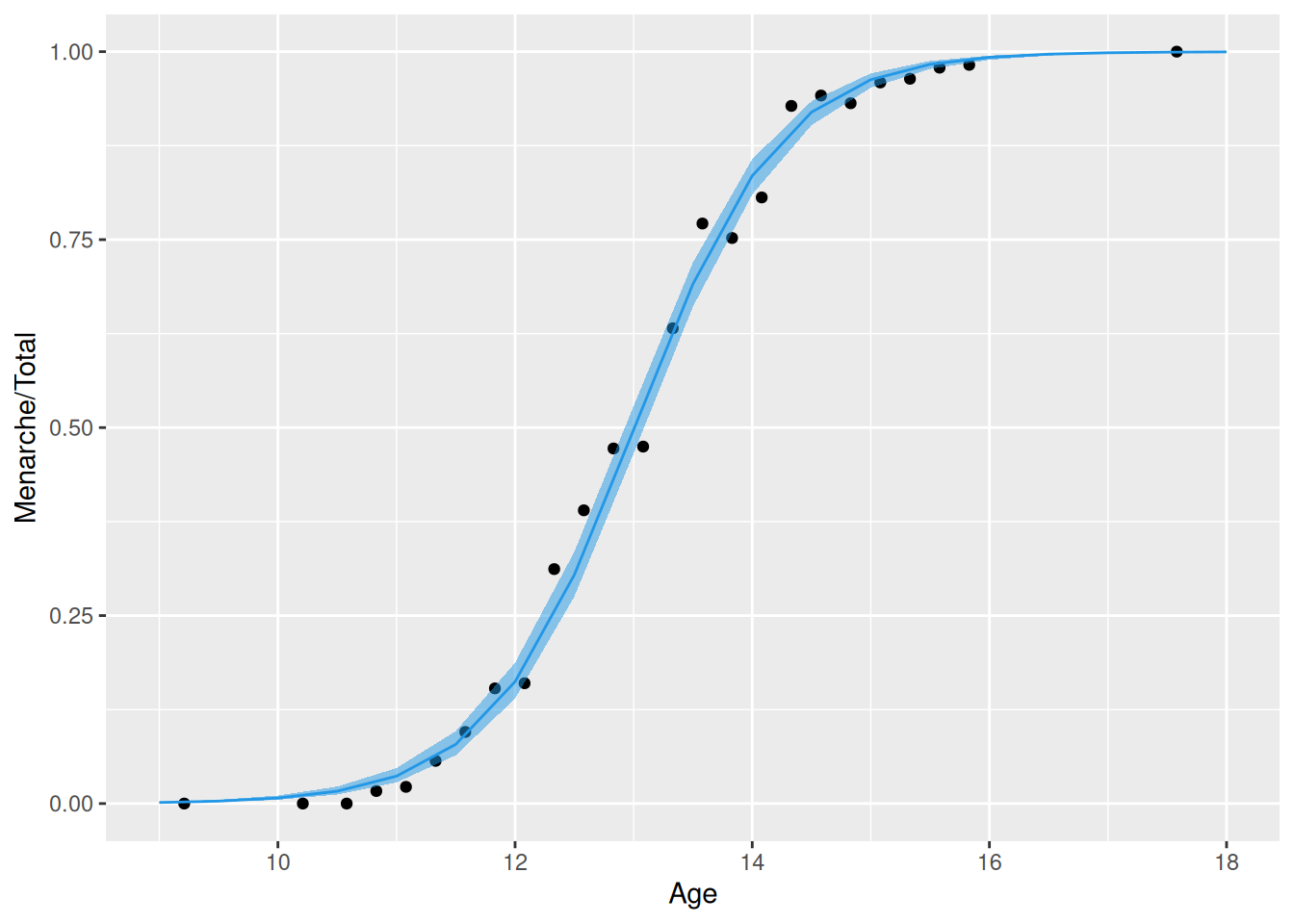
# modelfit <-glm(cbind(Menarche, Total - Menarche) ~ Age, dat, family = binomial)# alternatívne: glm(Menarche/Total ~ Age, dat, family = binomial, weights = dat$Total)fit
Call: glm(formula = cbind(Menarche, Total - Menarche) ~ Age, family = binomial,
data = dat)
Coefficients:
(Intercept) Age
-21.226 1.632
Degrees of Freedom: 24 Total (i.e. Null); 23 Residual
Null Deviance: 3694
Residual Deviance: 26.7 AIC: 114.8
Kód
# zobrazenielinkinv <- fit$family$linkinv data.frame(Age =seq(9, 18, by =0.5)) |> (\(x) cbind(x, predict(fit, newdata = x, se.fit =TRUE)) )() |>transform(up = fit +2*se.fit, # 95% interval spoľahlivostilo = fit -2*se.fit,se.fit =NULL,residual.scale =NULL) |> dplyr::mutate(across(-Age, .fns = linkinv)) |># do pôvodnej mierkyggplot() +aes(x = Age) +geom_point(aes(y = Menarche/Total), data = dat) +geom_ribbon(aes(ymin = lo, ymax = up), fill =4, alpha =0.5) +geom_line(aes(y = fit), color =4)
Pre modelovanie spojitej premennej predstavujúcej pomer v otvorenom intervale(0,1) je vhodná tzv. beta-regresia (v R pomocou balíku betareg), taký model však už nepatrí do triedy GLM. Pre veľké n_i dáva podobné výsledky ako GLM.
7.4.4 Poissonova regresia
Poissonovo rozdelenie s pravdepodobnostnou funkciou p(y)=\frac{e^{-\mu}\mu^y}{y!} a momentami E[Y]=var[Y]=\mu vznikne z binomického rozdelenia, keď pravdepodobnosť úspechu v jednom pokuse je stlačená smerom k nule a naopak, počet pokusov rastie k nekonečnu, takže stredná hodnota zostáva rovnaká.
Tým je Poissonovo rozdelenie vhodné na modelovanie premenných predstavujúcich počet (angl. count) bez horného ohraničenia.
Pretože stredná hodnota musí byť nezáporná, prirodzenou voľbou link funkcie je g(\mu)=\log(\mu). Keďže \dot g(\mu)=1/\mu, potom váhy budú w=\mu.
V bežnej regresii by sme s rastúcim rozptylom zmenšovali váhu pozorovania, no tu je to naopak, pretože väčšie stredné hodnoty počtu poskytujú viac informácií o parametroch.
TipPríklad (bicykle)
S pomocou súboru údajov ISLR2::Bikeshare modelujeme počet požičaných bicyklov za hodinu pomocou vonkajšej teploty – preškálovanej vzťahom temp=\frac{T-T_{\min}}{T_{\max}-T_{\min}}.
Dáta sú obmedzené na jarné obdobie počas víkendov za slnečného počasia. Ukážka:
# modelfit <-glm(bikers ~ temp, dat, family = poisson) fit |>summary()
Call:
glm(formula = bikers ~ temp, family = poisson, data = dat)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.30850 0.01873 176.6 <2e-16 ***
temp 3.31208 0.03024 109.5 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 45711 on 374 degrees of freedom
Residual deviance: 32270 on 373 degrees of freedom
AIC: 34727
Number of Fisher Scoring iterations: 5
Kód
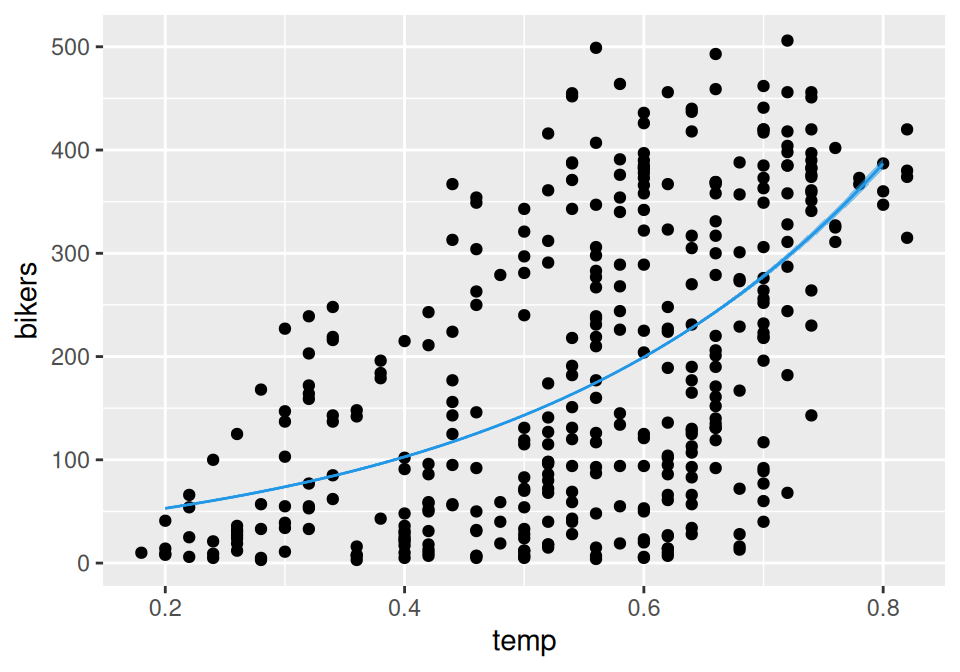
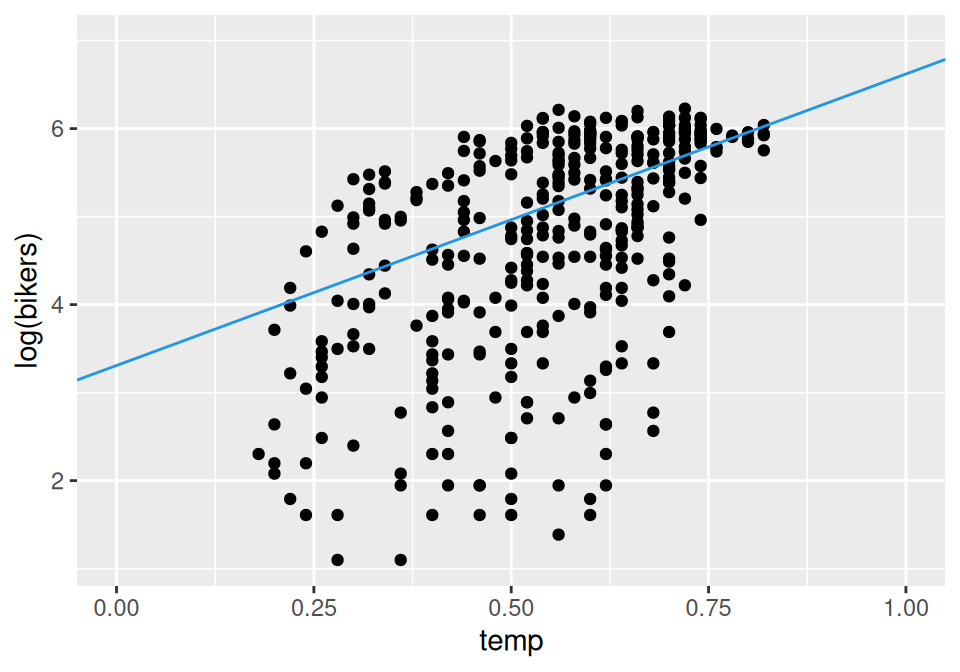
# zobrazenielinkinv <- fit$family$linkinv data.frame(temp =seq(0.2, 0.8, by =0.01)) |> (\(x) cbind(x, predict(fit, newdata = x, se.fit =TRUE)) )() |>transform(up = fit +2*se.fit, # 95% interval spoľahlivostilo = fit -2*se.fit,se.fit =NULL,residual.scale =NULL) |> dplyr::mutate(across(-temp, .fns = linkinv)) |># do pôvodnej mierkyggplot() +aes(x = temp) +geom_point(aes(y = bikers), data = dat) +geom_ribbon(aes(ymin = lo, ymax = up), fill =4, alpha =0.5) +geom_line(aes(y = fit), color =4) dat |>ggplot() +aes(x= temp, y =log(bikers)) +geom_point() +geom_abline(intercept = fit$coefficients[1], slope = fit$coefficients[2], color =4) +expand_limits(x =c(0,1), y =7)
Predikcia z modelu a interpretácia parametrov:
Počet cyklistov pri minimálnej teplote by mal byť v priemere e^{3.308}\approx27.
Pri maximálnej teplote (temp=1) by ich malo byť e^{3.312}=27.4-násobne viac (teda 27\cdot27.4 \approx 750 = e^{3.308 + 3.312\cdot1}).
Zvýšenie teploty o 10% jej bežného rozsahu (\Delta temp=0.1) by podľa modelu malo priniesť e^{3.312/10}\approx1.4-násobný nárast počtu cyklistov (čiže o 40% vyšší).
Z grafu je vidieť, že rozptyl pozorovaní so strednou hodnotou stúpa, čo zodpovedá predpokladom modelu.
Všimnime si však aj to, že (reziduálna) deviancia je až cca 100-násobne vyššia oproti počtu stupňov voľnosti. (Ak D\sim\chi^2(k) potom E[D]=k a var[D]=2k.) To naznačuje oveľa vyšší rozptyl, než s akým model na základe predpokladaného rozdelenia Y počíta. Je to badať aj z príliš úzkeho pásu spoľahlivosti okolo regresnej krivky.
7.5 Modelovanie rozptylu
S voľbou triedy (podmieneného) rozdelenia Y dostaneme aj variančnú funkciu V(\mu(x)). Skutočná podmienená variancia var[Y|X=x] však tomu nemusí zodpovedať.
Ak je skutočný rozptyl väčší, potom proces je označený ako over-dispersed. V opačnom prípade under-dispersed. Prvý prípad je častejší a tiež závažnejší.
Vyšší rozptyl je veľa krát spôsobený nejakým zanedbaným faktorom (chýbajúci prediktor alebo autokorelované pozorovania).
Ak pôvod prebytočnej variancie nezahrnieme do modelu, ešte stále sa dá použiť symptomatická liečba a zvoliť rozdelenie, ktoré dokáže rozptyl škálovať podľa potreby.
Takými sú rozdelenia z triedy tzv. kvázi-rozdelení.
TipPríklad (bicykle)
Kód
# modelfit <-glm(bikers ~ temp, dat, family = quasipoisson) fit |>summary()
Call:
glm(formula = bikers ~ temp, family = quasipoisson, data = dat)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.3085 0.1687 19.62 <2e-16 ***
temp 3.3121 0.2722 12.17 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for quasipoisson family taken to be 81.0479)
Null deviance: 45711 on 374 degrees of freedom
Residual deviance: 32270 on 373 degrees of freedom
AIC: NA
Number of Fisher Scoring iterations: 5
Kód
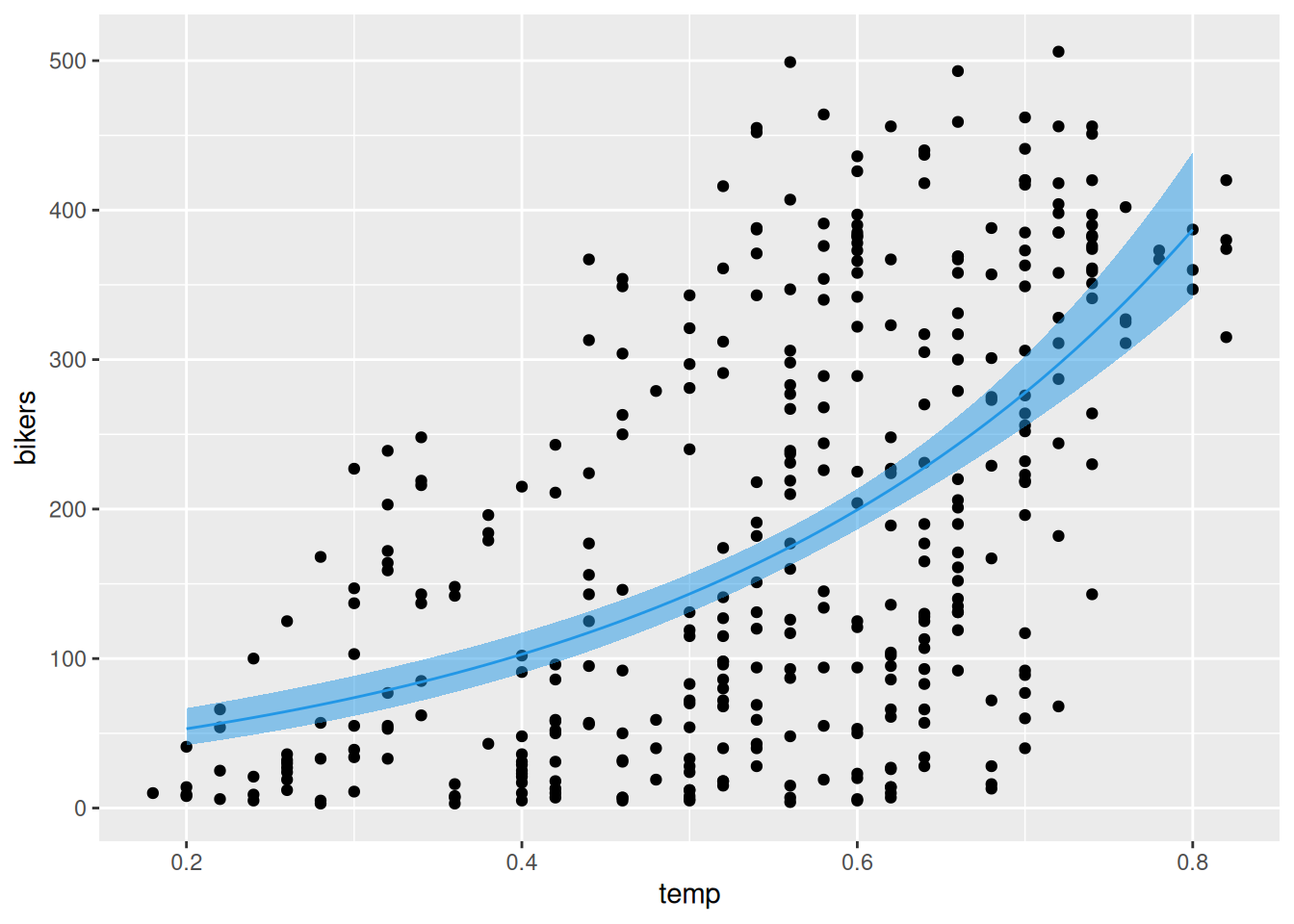
# zobrazenielinkinv <- fit$family$linkinv data.frame(temp =seq(0.2, 0.8, by =0.01)) |> (\(x) cbind(x, predict(fit, newdata = x, se.fit =TRUE)) )() |>transform(up = fit +2*se.fit, # 95% interval spoľahlivostilo = fit -2*se.fit,se.fit =NULL,residual.scale =NULL) |> dplyr::mutate(across(-temp, .fns = linkinv)) |># do pôvodnej mierkyggplot() +aes(x = temp) +geom_point(aes(y = bikers), data = dat) +geom_ribbon(aes(ymin = lo, ymax = up), fill =4, alpha =0.5) +geom_line(aes(y = fit), color =4)
Všimnime si rádovo vyššie štandardné chyby parametrov, na základe ktorých je teraz test významnosti vplyvu prediktorov na odozvu podstatne spoľahlivejší.
Neohraničené počty s vyšším rozptylom sa zvyknú modelovať aj pomocou negatívneho binomického rozdelenia (v R napr. pomocou funkcie MASS::glm.nb).