Lineárny regresný model má svoje obmedzenia (aditivita, linearita) ktoré ho znevýhodňujú pri predikcii v prípade zložitejších vzťahov medzi odozvou a prediktormi. Napriek tomu je v praxi veľmi obľúbeným nástrojom – je jednoducho vysvetliteľný (dedukcia) a prekvapivo často konkurencieschopný (z hľadiska predikcie).
Ako sme si ukázali, niektoré obmedzenia (aditivita, linearita) sa dajú vyriešiť rozšírením modelu pomocou vhodných bázových funkcií. Neskôr sa ešte povenujeme rozšíreniu konštrukcie lineárneho modelu na adaptovanie sa nelineárnym vzťahom (pri zachovaní aditivity).
Lineárny regresný model sa však dá vylepšiť aj vhodnou metódou odhadu – tak z hľadiska presnosti predpovedí ako aj intepretovateľnosti modelu.
Z hľadiska presnosti predpovede:
Ak je skutočný vzťah lineárny, potom klasická metóda najmenších štvorcov dáva odhad s nízkou výchylkou (bias) a navyše, ak je k dispozícii dostatok dát (n\gg p), tak aj s nízkou varianciou.
Avšak, ak n nie je oveľa väčšie ako p, potom odhad môže byť veľmi premenlivý a viesť k prehnanému prispôsobeniu pozorovaniam (overfitting), čo v konečnom dôsledku znamená nekvalitné predpovede.
Nakoniec, ak p>n, tak obyčajná metóda najmenších štvorcov sa ani nedá použiť, pretože neexistuje jediné riešenie (variancia je nekonečná).
Obmedzením (stlačením) odhadov parametrov sa dá významne zredukovať variancia, a to na úkor iba zanedbateľného nárastu výchylky (bias).
Z hľadiska interpretovateľnosti modelu:
Viaceré premenné použité v regresii nemajú žiaden vzťah ku odozve takže iba zbytočne zvyšujú komplexnosť modelu.
Ich odstránenie – t.j. stlačenie zodpovedajúcich parametrov až na nulu – zlepší interpretovateľnosť modelu.
Obyčajná MNŠ prakticky nikdy nevyústi do nulových odhadov parametrov.
To je úlohou automatických metód na výber podmnožiny relevantných prediktorov (feature/variable selection).
Je veľa alternatív ako nahradiť obyčajnú metódu najmenších štvorcov na odhad modelu. Najznámejšie sú tieto tri triedy metód:
výber podmnožiny relevantných prediktorov (subset selection),
redukcia vplyvu irelevantných prediktorov (shrinkage),
transformácia priestoru prediktorov do podpriestoru s väčšou informačnou hodnotou (dimension reduction).
4.2 Výber podmnožiny
Niektoré metódy z tejto triedy sme si v krátkosti predstavili už v kapitole o regresnom modeli.
4.2.1 Metóda hrubej sily
Úloha vybrať najlepší z 2^p možných lineárnych regresných modelov už napohľad (kvôli množstvu kombinácií) nie je triviálna.
Metóda výberu najlepšej podmnožiny prediktorov (best subset selection) na to ide hrubou silou.
Postup je rozdelený do dvoch krokov:
Pre k=0,1,\ldots,p zopakovať procedúru:
odhadnúť \binom{p}{k} modelov, ktoré obsahujú presne k prediktorov,
model s najmenším RSS (alebo najväčším R^2) označiť ako \mathcal{M}_k.
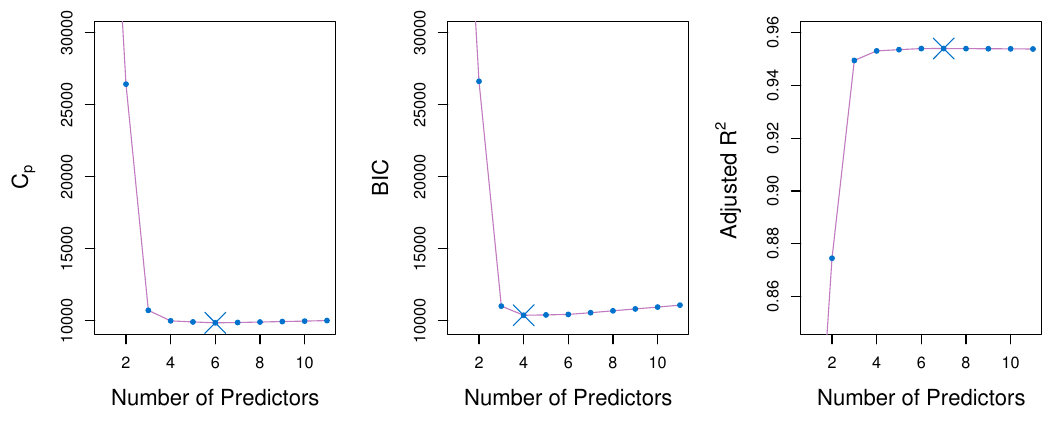
Spomedzi \mathcal{M}_0,\ldots,\mathcal{M}_p vybrať najlepší model v zmysle jedného z kritérii: krížová validácia, C_p (AIC), BIC, korigovaný R^2.
TipPríklad (kreditky)
Dataset Credits obsahuje okrem odozvy (Balance) aj 10 ďalších premenných, z toho jednu kvalitatívnu s viac ako dvomi úrovňami (Region), takže celkový počet prediktorov je 11.
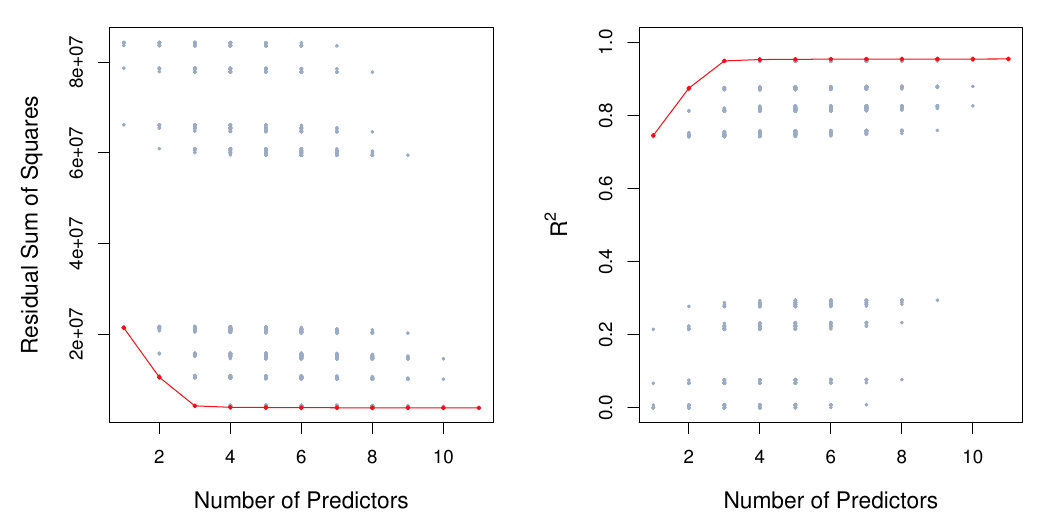
Na obrázkoch nižšie sú zobrazené hodnoty RSS, resp. R^2 pre všetky možné lineárne regresné modely. Červená krivka spája najnižšie hodnoty pre každý počet parametrov.
Od modelu s tromi prediktormi je už zjavne iba minimálne zlepšenie. Tie tri sú v poradí (podľa súhrnu nižšie) Rating, Income a Student.
výpočtová náročnosť – napr. pri p=30 prediktoroch už treba odhadnúť miliardu modelov,
riziko overfiting-u – čím väčší priestor, tým väčšia šanca nájdenia modelu, ktorý sadne na trénovacie dáta, ale zlyhá na testovacích.
4.2.2 Metóda postupného výberu
Oproti metóde hrubej sily prejde metóda postupného výberu oveľa menšiu sadu modelov.
Pri metóde dopredného (forward) výberu je postup nasledujúci:
Odhadnúť model bez prediktorov \mathcal{M}_{0} a pre k=1,2,\ldots,p zopakovať procedúru:
Odhadnúť (p-k+1) modelov, ktoré vzniknú pridaním 1 premennej ku modelu \mathcal{M}_{k-1}, takže obsahujú presne k prediktorov.
Model s najmenším RSS (alebo najväčším R^2) označiť ako \mathcal{M}_{k+1}.
Spomedzi \mathcal{M}_0,\ldots,\mathcal{M}_p vybrať najlepší model v zmysle jedného z kritérii: krížová validácia, C_p (AIC), BIC, korigovaný R^2.
Dopredný výber žiaľ negarantuje nájdenie najlepšieho modelu. Napr. pre p=3 ak najlepší jedno-prediktorový model obsahuje X_1 a najlepši dvoj-prediktorový model obsahuje X_2,X_3, potom ten v doprednej procedúre nebude vybraný, pretože \mathcal{M}_2 už musí obsahovať prediktor X_1.
Alternatívna metóda ku doprednej je spätná (backward stepwise selection):
Odhadnúť model so všetkými prediktormi \mathcal{M}_{p} a pre k=p-1,p-2,\ldots,0 zopakovať procedúru:
Odhadnúť k+1 rôznych modelov, ktoré vzniknú odobratím 1 premennej z modelu \mathcal{M}_{k+1}, takže obsahujú presne k prediktorov.
Model s najmenším RSS (alebo najväčším R^2) označiť ako \mathcal{M}_{k}.
Spomedzi \mathcal{M}_0,\ldots,\mathcal{M}_p vybrať najlepší model v zmysle jedného z kritérii: krížová validácia, C_p (AIC), BIC, korigovaný R^2.
Podobne negarantuje nájdenie najlepšieho modelu. Nedá sa použiť v prípade n<p.
Ďalšou alternatívou sú hybridné prístupy, ktoré riešia nevýhodu predošlých dvoch a pri pridávaní nových premenných do modelu môžu niektoré neproduktívne aj uberať.
4.2.3 Kritériá výberu optimálneho modelu
Všetky spomenuté metódy výberu podmnožiny prediktorov majú jeden krok spoločný: výber modelu, ktorý je optimálny z hľadiska testovacej chyby. Sú dva prístupy k jej odhadu:
jeden ju nepriamo nahrádza kritériami, v ktorých je trénovacia chyba korigovaná o stupne voľnosti,
druhý priamo odhaduje testovaciu chybu pomocou metódy jednej validačnej sady alebo pomocou krížovej validácie.
4.2.3.1 Korekcia trénovacej chyby
Označme k\leq p ako počet prediktorov použitých v posudzovanom modeli.
Prvým z nepriamych odhadov testovacej chyby, ktorý preberieme, je MallowovoC_p, dané vzťahom
C_p = \frac1n(RSS_k+2k\hat\sigma^2)
kde RSS_k je RSS posudzovaného modelu, \hat\sigma^2 je odhad rozptylu skutočnej chybovej zložky (zväčša sa odhadne pomocou plného modelu s p prediktormi). Dá sa ukázať, že ak je \hat\sigma^2 nevychýleným odhadom \sigma^2, potom je aj C_p nevychýleným odhadom testovacej MSE.
Akaikeho informačné kritérium je zvyčajne definované pomocou funkcie vierohodnosti, ale ak je splnený prepoklad normality chybovej zložky, potom sú metódy odhadu pomocou maximálnej vierohodnosti a najmenších štvorcov totožné a kritérium je dané podobným vzťahom ako C_p (vyberú rovnaký model). V prípade MNŠ sa zvykne používať aj druhý vzťah pre AIC, ktorý explicitne neobsahuje odhad \sigma^2.
Bayesovské informačné kritérium bolo odvodené z bayesovského pohľadu, ale jeho tvar je nakoniec veľmi podobný AIC (a C_p až na násobnú konštantu),
BIC = \frac1n\left(RSS+\ln(n)k\hat\sigma^2\right)
pričom je zjavné, že pre n>7 je penalizácia počtu prediktorov silnejšia než pre AIC.
Ďalšou, softvérmi často reportovanou mierou je korigovaný (adjusted) koeficient detrminácie R^2,
adjR^2 = 1-\frac{RSS/(n-k-1)}{TSS/(n-1)}
ktorý s presnosťou modelu rastie – na rozdiel od predošlých kritérií. A zatiaľčo RSS s počtom prediktorov vždy klesá, korekcia RSS/(n-k-1) môže aj rásť a tak penalizovať prebytočné prediktory.
Kritériá C_p, AIC a BIC majú za sebou starostlivé teoretické zdôvodnenie spoliehajúce na asymptotické (t.j. n\to\infty) vlastnosti odhadov.
TipPríklad (kreditky)
4.2.3.2 Validácia a krížová validácia
Oproti predošlému prístupu má tento niekoľko výhod:
priamy odhad testovacej chyby,
menej predpokladov o skutočnom modeli,
využitie v širšom spektre úloh (nevyžaduje určenie stupňov voľnosti ani odhad \sigma^2)
Nevýhoda v podobe výpočtovej náročnosti bola z veľkej časti odstránená modernými počítačmi.
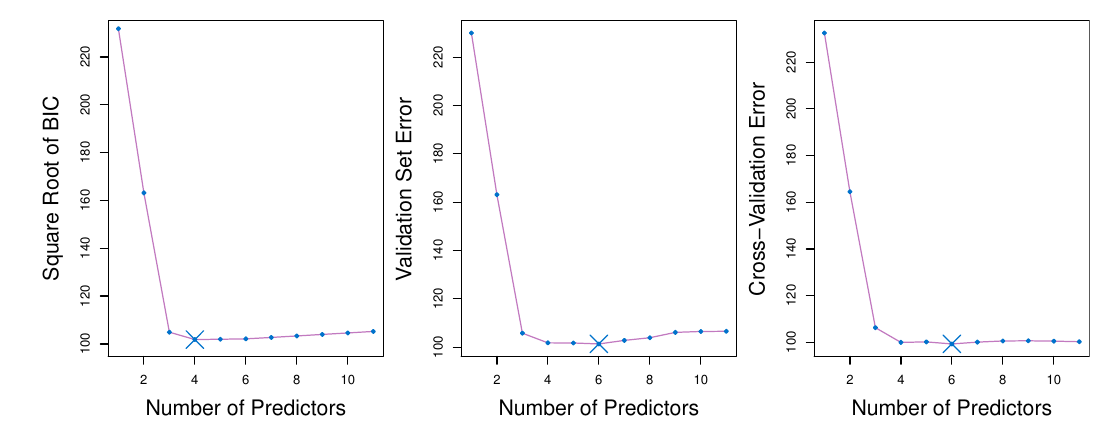
TipPríklad (kreditky)
Príklad s určením počtu prediktorov pre modelovanie dlhu držiteľov kreditných kariet.
Priebeh testovacej chyby (priamym či nepriamym odhadom) je od modelu s tromi prediktormi veľmi stabilný, plochý, takže určenie minima kolíše od metódy ku metóde medzi hodnotami 4 až 7, a aj zopakovaním krížovej validácie by sme pravdepodobne dostali inú než aktuálne zobrazenú hodnotu 6.
Aby v prípade plochého priebehu testovcej chyby (ako v príklade s kreditkami) nebol náhodne zvolený zbytočne zložitý model, môžeme s krížovou validáciou použiť pravidlo jednej štandardnej chyby:
pre každý model sa spolu s odhadom MSE vypočíta aj jeho štandardná chyba SE(\widehat{MSE}),
vyberie sa taký najmenší model, ktorý je ešte v dosahu jednej štandardnej chyby od minima.
(V príklade s kreditkami by to znamenalo výber modelu s tromi prediktormi.)
4.3 Redukcia parametrov (regularizácia)
Metódy výberu podmnožiny prediktorov používali MNŠ na odhad jednotlivých modelov s danou sadou premenných.
Alternatívnym prístupom je odhad plného modelu (obsahujúceho všetkých p prediktorov) so zavedením podmienok na parametre, ktoré by stláčali ich odhady smerom k nule.
4.3.1 Hrebeňová (ridge) regresia
Ridge regresia rozširuje MNŠ o penalizačný člen so súčtom štvorcov parametrov modelu, takže ich odhadom
\hat{\boldsymbol\beta}^R = \underset{\boldsymbol\beta}{\arg\min}\left\{ \underbrace{\sum_{i=1}^n\left(y_i - \beta_0 - \sum_{j=1}^p\beta_jx_{ij}\right)^2}_{RSS} + \underbrace{\lambda\sum_{j=1}^p\beta_j^2}_{\lambda||\boldsymbol\beta||_2^2} \right\}
nedovolí narásť do zbytočne veľkých hodnôt, resp. stlačí vplyv menej dôležitých prediktorov smerom k nule.
Parameter \lambda určuje pomer vplyvu tých dvoch členov na odhad regresných koeficientov:
keď \lambda=0, potom je metóda totožná s MNŠ,
a \lambda\to\infty spôsobí stlačenie odhadu koeficientov až takmer na nulu.
Správny výber \lambda je pre úspech metódy kritický a v praxi sa naň používa krížová validácia.
V maticovom tvare sa odhad dá vyjadriť vzťahom
\hat{\boldsymbol\beta}^R = (\mathbf{X}'\mathbf{X} + \lambda\mathbf{I})^{-1}\mathbf{X}'\mathbf{y}
z ktorého je vidieť, že regularizácia je spôsobená “hrebeňom” (ridge) lambda parametrov na diagonále penalizačnej matice \lambda\mathbf{I}.
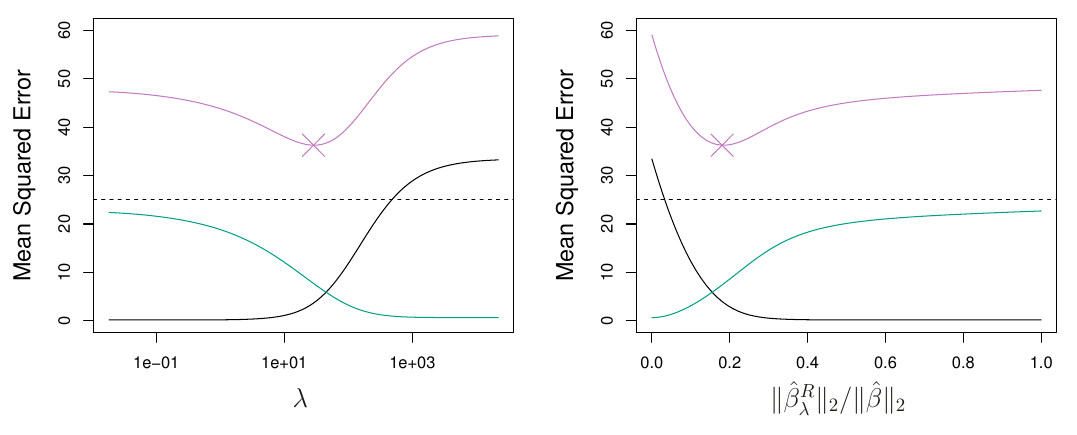
Ridge regresia ako regularizačná technika dokáže spresniť odhad MNŠ preto, že prenáša problém bias-variance kompromisu na problém voľby \lambda. Hodí sa na prípady, kedy je p porovnateľne veľké ako n, takže odhady MNŠ majú veľký rozptyl (t.j. drobné zmeny v dátach vyvolajú veľké zmeny v odhadoch). Ridge regresia dokáže tento rozptyl významne znížiť – za cenu iba malého nárastu výchylky.
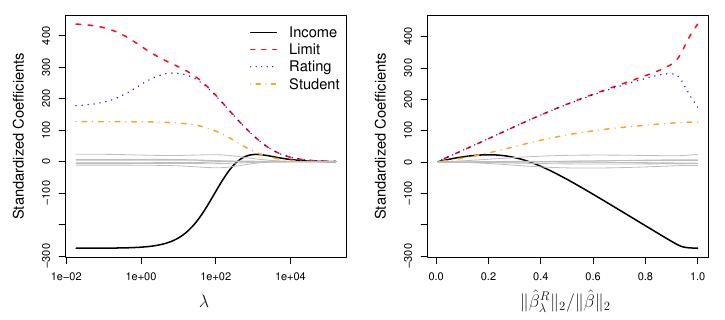
TipPríklad (kreditky)
Oproti metóde hrubej sily má výpočtovú výhodu: namiesto množstva modelov odhaduje iba jeden (pre dané \lambda).
4.3.2 LASSO
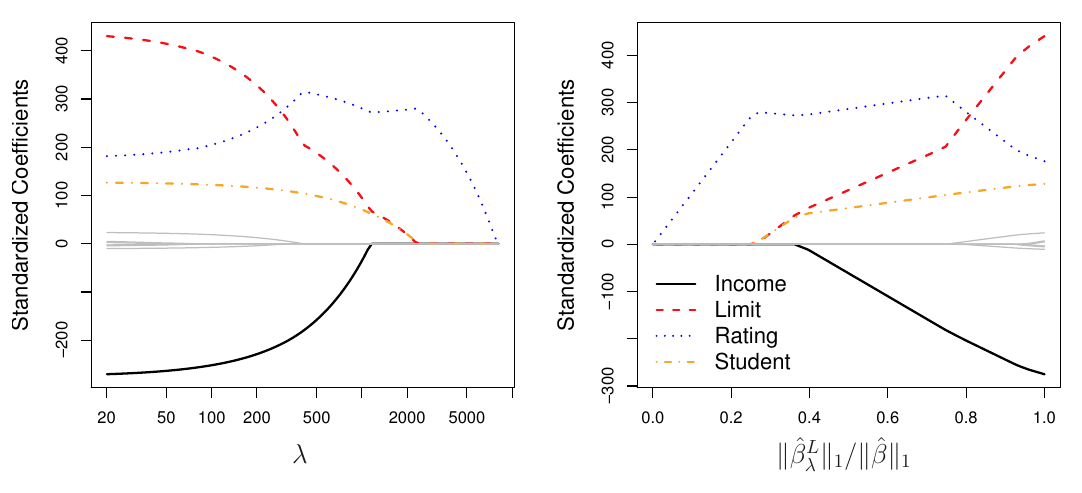
Hrebeňová regresia má však aj jednu podstatnú nevýhodu: vplyv irelevantných premenných nikdy nie je stlačený úplne na nulu, takže na rozdiel od metód výberu podmnožiny prediktorov, finálny model z hrebeňovej regresie bude vždy obsahovať všetkých p prediktorov.
To komplikuje najmä interpretáciu modelu.
Alternatíva v podobe metódy LASSO (least absolute shrinkage and selection operator) túto nevýhodu odstraňuje a to malou modifikáciou penalizačného člena,
\hat{\boldsymbol\beta}^L = \underset{\boldsymbol\beta}{\arg\min}\left\{ \underbrace{\sum_{i=1}^n\left(y_i - \beta_0 - \sum_{j=1}^p\beta_jx_{ij}\right)^2}_{RSS} + \underbrace{\lambda\sum_{j=1}^p|\beta_j|}_{\lambda||\boldsymbol\beta||_1} \right\}
(čiže zmenou normy \ell_2 na \ell_1).
Dôsledkom je to, že hodnoty parametrov môžu klesnúť úplne na nulu, ak je \lambda dostatočne veľké.
LASSO teda môžeme zaradiť aj medzi metódy výberu premenných.
TipPríklad (kreditky)
4.3.3 Porovnanie
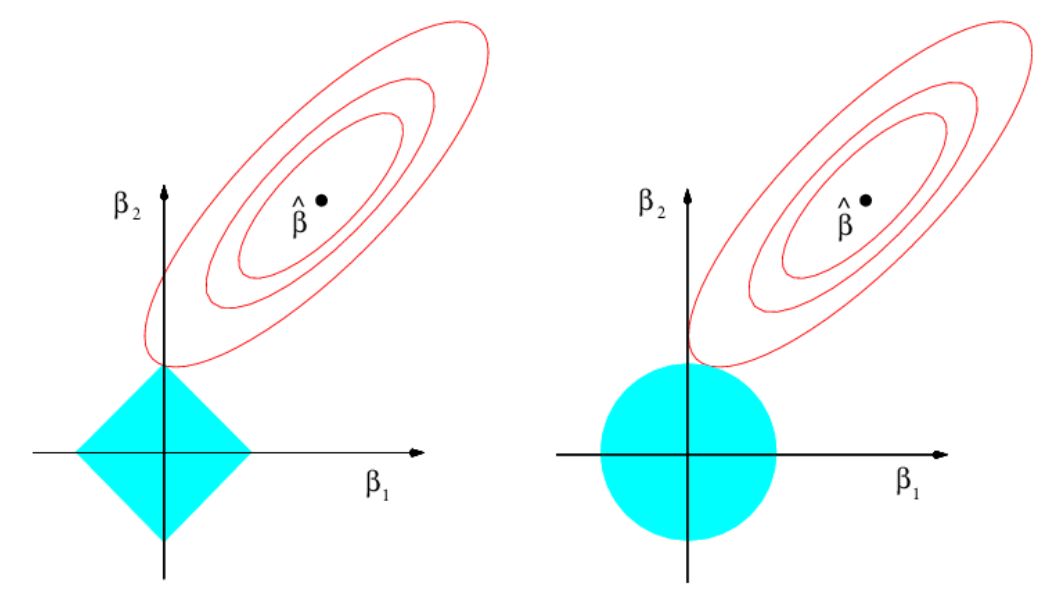
Odhad LASSO aj ridge regresie sa dá preformulovať ako problém hľadania minima funkcie RSS(\boldsymbol\beta) na oblasti danej hranicou
||\boldsymbol\beta||_1\leq s pre LASSO,
||\boldsymbol\beta||_2\leq s pre ridge regresiu,
kde úroveň s môžeme interpretovať ako rozpočet na prerozdelenie medzi parametre.
Ak je rozpočet dostatočne veľký na to, aby pokryl odhad MNŠ, tak minimum je práve v ňom (to je prípad \lambda=0). V opačnom prípade globálne minimum leží niekde na hranici.
PoznámkaIlustrácia (LASSO/ridge)
Z geometrického hladiska hranica má v dvojrozmernom prípade tvar štvorca (LASSO) resp. kruhu (ridge). Na obrázku dole je spolu s izočiarami RSS.
Vo svetle poslednej formulácie sú obe metódy podobné metóde výberu najlepšej podmnožiny (t.j. metóde hrubej sily), ktorá minimum RSS(\boldsymbol\beta) hľadá na oblasti \sum_{j=1}^pI(\beta_j\neq0)\leq s, kde I značí indikačnú funkciu. V pôvodnej formulácii zodpovedá penalizačnému členu \lambda\sum_{j=1}^p|\beta_j|^0 s konvenciou 0^0=0.
Aby odhady okrem ladiaceho (tuning) parametra \lambda nezáviseli aj od mierky jednotlivých parametrov, je potrebné hodnoty prediktorov vopred vydeliť štandardnou odchýľkou (aby mali jednotkový rozptyl), čiže v regresii použiť pozorovania \tilde x_{ij} = x_{ij}/\hat\sigma_{X_j}.
Ak okrem škálovania na jednotkový rozptyl hodnoty prediktorov aj centrujeme (aby mali nulovú strednú hodnotu) – spolu sa táto transformácia nazýva štandardizácia – potom \hat\beta_0=\bar y a centrovaním odozvy možno zmenšiť priestor hľadaných parametrov o \beta_0.
Štandardizáciu robí softvér automaticky.
Ani jedna z regularizačných metód nie je vo všeobecnosti lepšia, než tá druhá. Ridge je vhodnejšia v prípade, že každý prediktor má aspoň minimálny vplyv na odozvu, zatiaľčo LASSO predpokladá absenciu vplyvov niektorých premenných.
V prípade korelovaných prediktorov ridge stláča parametre tejto skupiny spoločne, zatiaľčo LASSO má tendenciu uprednostniť jeden prediktor pred ostatnými.
Z výpočtového hľadiska sú vďaka efektívnym algoritmom obe metódy podobne náročné ako MNŠ.
LASSO aj hrebeňová regresia sú špeciálnymi prípadmi tzv. elastickej siete s penalizačným členom
\lambda\sum_{j=1}^p\left(\frac{1-\alpha}{2}\beta_j^2 + \alpha|\beta_j|\right)
ktorá spája výhody oboch 1. Napr. v prípade skupiny korelovaných prediktorov nastavenie \alpha=0.5 má tendenciu vybrať alebo vynechať celú skupinu.
Parameter \alpha má aj stabilizačnú funkciu: napr. elastická sieť s \alpha blízkou 1 sa správa ako LASSO, ale zároveň odstraňuje anomálie spôsobené extrémnymi koreláciami medzi prediktormi.
TipPríklad (autá)
Súbor údajov ISLR2::Auto obsahuje niekoľko vlastností 392 automobilov: dojazd (mpg), počet valcov (cylinders), zdvihový objem (displacement), výkon (horsepower), hmotnosť (weight), zrýchlenie (acceleration), rok uvedenia modelu (year), pôvod (origin) a nakoniec názov modelu (name).
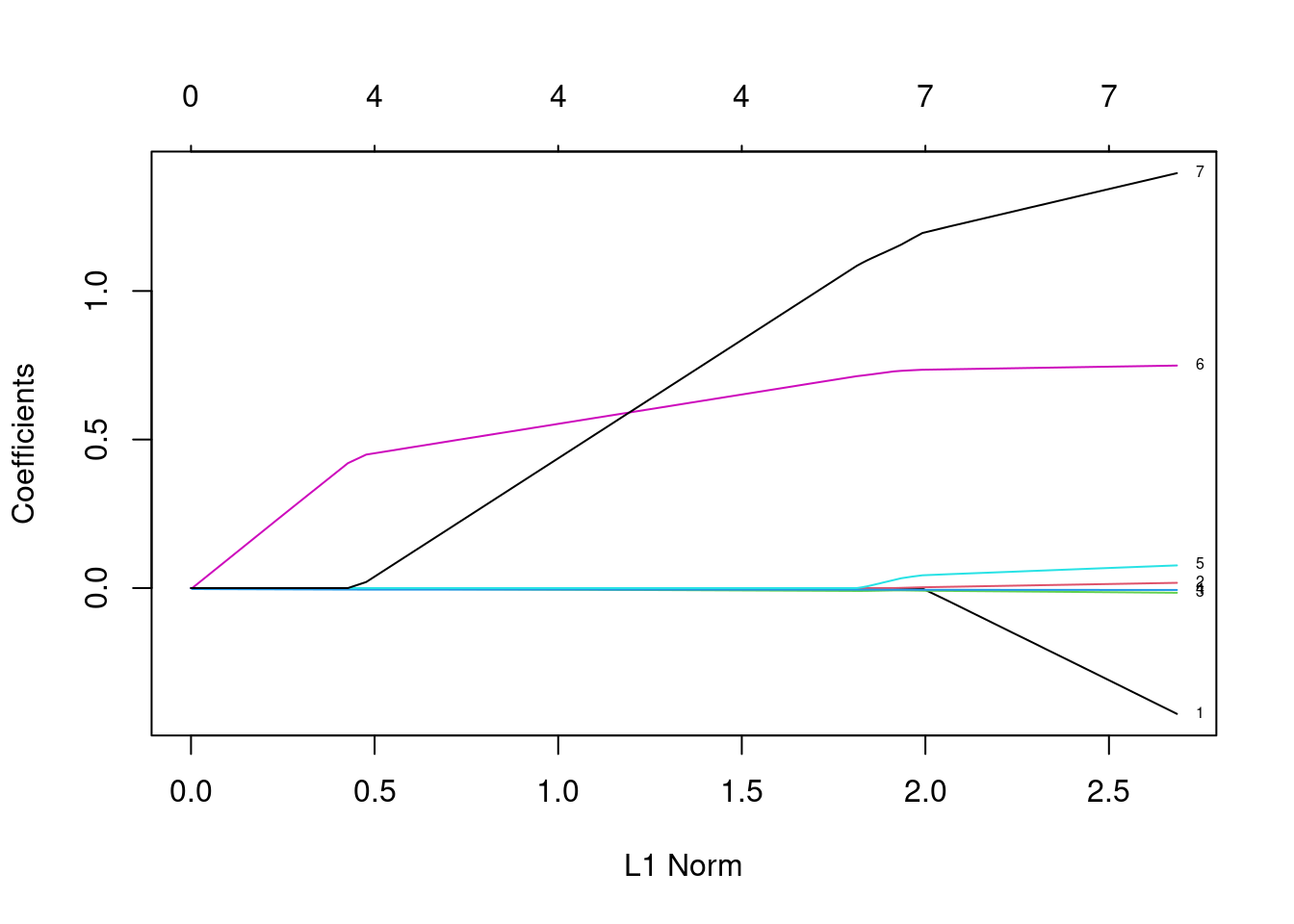
Nech dojazd je odozva, potom regularizačnou metódou elastická sieť (prakticky LASSO) odhadnime lineárny regresný model so všetkými premennými zo súboru okrem názvu modelu.
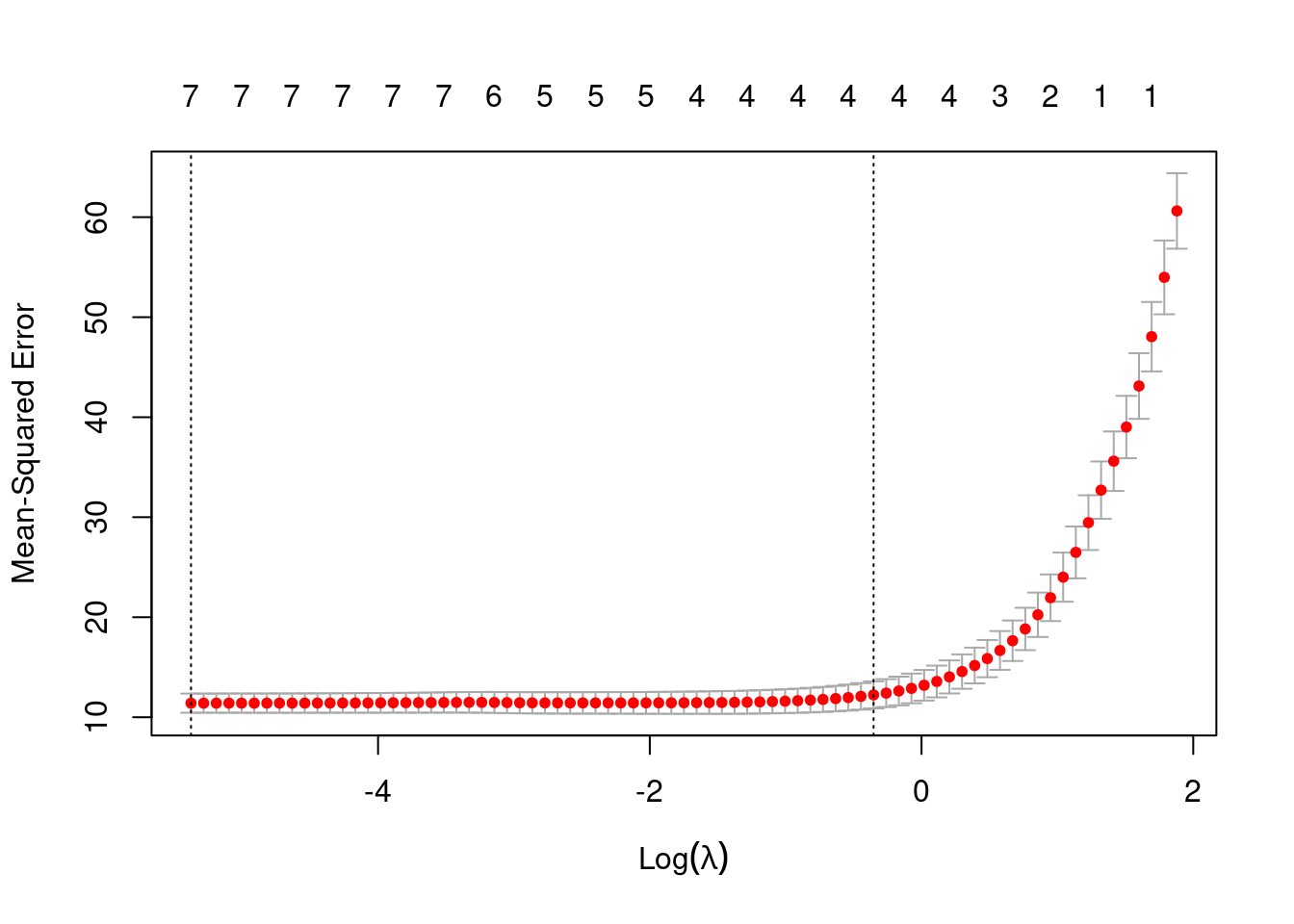
Funkcia glmnet z balíku glmnet odhadne model na predvolenej mriežke hodnôt \lambda. Na grafe vľavo je namiesto nich na osi x zobrazený počet nenulových parmetrov (hore) a ich súčty v absolútnej hodnote (dole).
Kód
X <-model.matrix(mpg ~ . - name, data = ISLR2::Auto)[,-1] # without onesy <- ISLR2::Auto$mpgglmnet::glmnet(x = X, y = y, alpha =0.99) |>plot(label =TRUE)set.seed(12)cvfit <- glmnet::cv.glmnet(x = X, y = y, alpha =0.99)plot(cvfit)
Vhodný počet parametrov (resp. vhodnú hodnotu \lambda) je objektívnejšie zvoliť minimalizáciou testovacej chyby (odhadu pomocou krížovej validácie). Podľa grafu vpravo by sme mali zvoliť model so siedmimi prediktormi (minimum indikované zvislou čiarou vľavo), ale uplatnením pravidla jednej štandardnej chyby uprednostníme model so 4 prediktormi.
Kód
cvfit[c("lambda.min","lambda.1se")] |>unlist() # column leftfit <- glmnet::glmnet(x = X, y = y, alpha =0.99, lambda = cvfit$lambda.1se)coef(fit) # column right
lambda.min lambda.1se
0.004622949 0.702647151
8 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) -6.459341529
cylinders .
displacement .
horsepower -0.006472496
weight -0.005411354
acceleration .
year 0.601425571
origin 0.633118032
Parametre sú v pôvodnej mierke prediktorov, takže sa z nich priamo dajú vypočítať predikcie. Napr. pre model s výkonom 100 koní, váhou 3000 libier, rokom uvedenia (19)80 a pôvodom z USA.
Kód
list(horsepower =100, weight =3000, year =80, origin =1) |>with(c(manual =-6.46-0.00647*horsepower -0.00541*weight +0.601*year +0.633*origin,built_in = fit |>predict(newx =cbind(NA, NA, horsepower, weight, NA, year, origin)) |>c(),lm =lm(mpg ~ horsepower + weight + year + origin, ISLR2::Auto) |>predict(newdata =as.list(environment())) |>unname() )) |>rbind(prediction = _) # just a cosmetics
Ak by rovnaký model auta bol vyvinutý v Japonsku, podľa modelu by mal stredný dojazd dlhší o 2\cdot0.63 = 1.26 míle na galón paliva. Tu treba poznamenať, že premenná origin je nesprávne považovaná za numerickú premennú. Vopred mala byť prevedená na dátový typ factor.
Na záver ešte porovnajme výber premenných s VIF faktorom všetkých pôvodných. Vidno, že (aspoň v tomto prípade) LASSO viedlo k vylúčeniu časti premenných v multikolinearite s ostatnými, pričom vo výslednom modeli sú prediktory oveľa menej prepojené.