Lineárna regresia je jednoduchý prístup ku asistovanému učeniu.
Oproti moderným metódam sa môže zdať až príliš jednoduchý, ale zároveň patrí medzi najužitočnejšie, bežne používané nástroje štatistického modelovania.
Zároveň je dobrým štartovacím bodom pre pochopenie a využitie novších prístupov, pretože mnohé z nich ho zovšeobecňujú.
TipPríklad (reklama)
Oprášme príklad inzerovania v troch médiách. Našou úlohou je (na základe dát) navrhnúť marketingovú stratégiu na zvýšenie odbytu pre ďalšie obdobie. Aké informácie by na poskytnutie takého odorúčania mohli byť užitočné?
Tu je zopár dôležitých otázok, na ktoré budeme hľadať odpovede:
Existuje vzťah medzi rozpočtom na reklamu a odbytom? Prvou úlohou je teda zistiť, či pozorovnia poskytujú dostatočný dôkaz o súvislosti medzi premennými. Ak nie, potom je zbytočné utrácať peniaze za reklamu.
Ak existuje vzťah, aký je silný?
Ktoré médiá súvisia s odbytom? Chceme rozlíšiť významnosť príspevok jednotlivých médií, ak sme investovali do všetkých troch.
Aký silný je vzťah medzi odbytom a jednotlivými médiami? O koľko sa zvýši odbyt s každým dolárom naliatym do reklamy v konkrétnom médiu a ako presne dokážeme tento nárast predpovedať?
Aká je presnosť predpovede budúceho odbytu? Pre akúkoľvek kombináciu objemu reklamy v médách.
Je vzťah lineárny? Ak sa dá vzťah reklamy v jednotlivých médiách ku odbytu vyjadriť priamkou, potom lineárna regresia je vhodný nástroj. Ak nie, dá sa linearizovať transformáciou prediktorov alebo odozvy?
Je medzi médiami synergia?/ Je možné, aby investovanie napr. $50,000 do reklamy v TV a $50,000 v rádiu prineslo vyšší odbyt než $100,000 iba v jednom z nich? Toto sa v štatistike nazýva efekt interakcie.
Lineárna regresia sa dá použiť na zodpovedanie všetkých týchto otázok.
2.2 Jednoduchá regresia (jeden prediktor)
Lineárny regresný model s jediným prediktorom X sa zvykne označovať ako jednoduchá regresia (simple linear regression), formálne zapísaný vzťahom
Y = \beta_0 + \beta_1 X + \varepsilon
\tag{2.1} kde \beta_0,\beta_1 sú neznáme parametre (koeficienty) vyjadrujúce priesečník regresnej priamky s osou Y (intercept) a sklon (slope). Chybový člen \varepsilon je náhodná premenná s nulovou strednou hodnotou, štandardnou odchýlkou \sigma a je nezávislá od X.
2.2.1 Odhad parametrov
Parametre musia byť odhadnuté tak, aby priamka bola čo najbližšie ku pozorovaniam X a Y, teda bodom so súradnicami (x_1,y_1), (x_2, y_2), \ldots, (x_n, y_n).
Najpoužívanejšou mierou blízkosti je súčet štvorcov rezíduí (residual sum of squares), RSS = \sum_{i=1}^n \hat\varepsilon_i^2
Rezíduá sú odchýlky reality od modelu, \hat\varepsilon_i = y_i - \hat y_i = y_i - \hat \beta_0 - \hat \beta_1x_i.
Minimalizáciou RSS (metóda najmenších štvorcov, least squares) dostaneme odhady parametrov
\begin{split}
\hat\beta_1 &= \frac{\sum_{i=1}^n(x_i-\bar x)(y_i-\bar y)}{\sum_{i=1}^n(x_i-\bar x)^2},\\
\hat\beta_0 &= \bar y - \hat\beta_1\bar x,
\end{split}
kde \bar y \equiv \frac1n\sum_{i=1}^n y_i a analogicky aj \bar x sú výberové priemery.
TipPríklad (reklama)
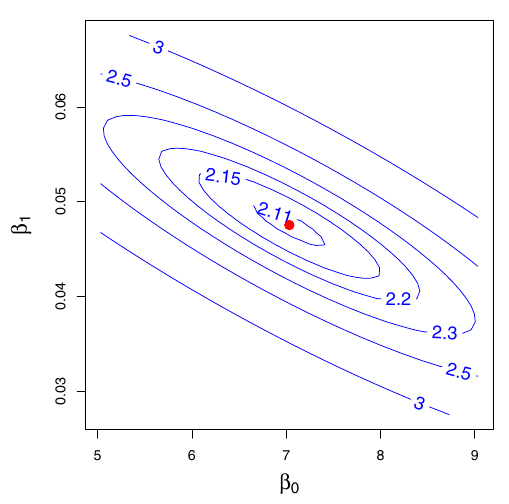
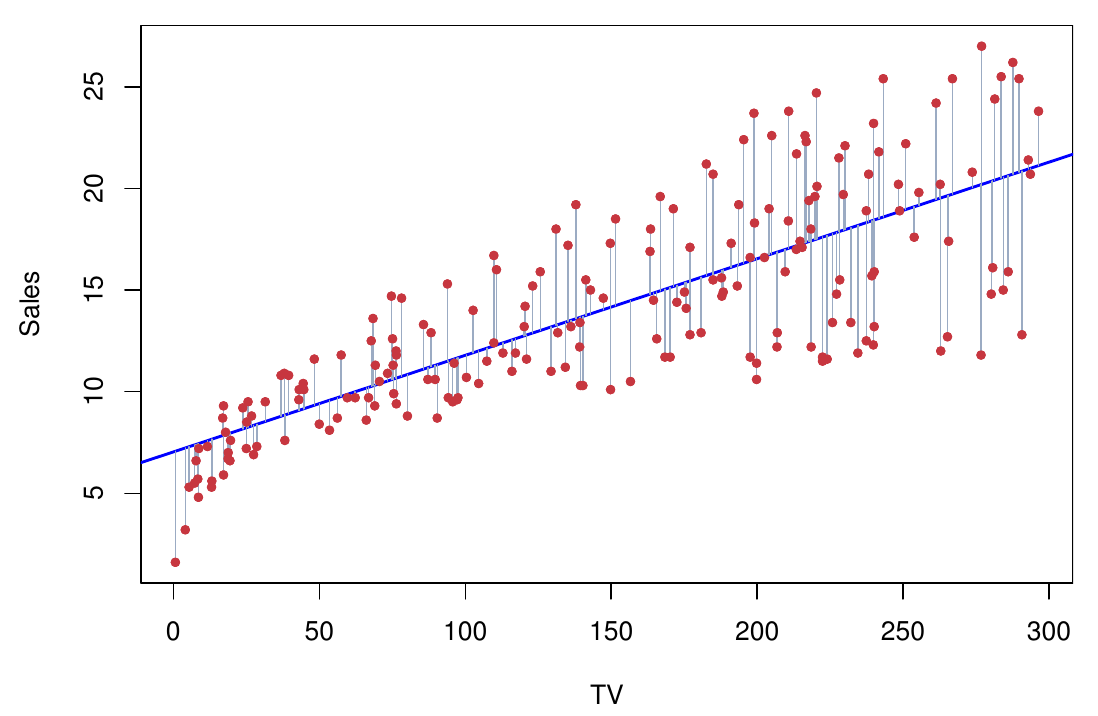
Odhad metódou najmenších štvrcov v priestore parametrov (vľavo s izočiarami RSS) a v priestore premenných (vpravo s naznačením rezíduí):
Kód
dat_Advertising <-read.csv("data/Advertising.csv")[-1]fit <-lm(sales ~ TV, dat_Advertising) fit |>coefficients() |>round(3)
(Intercept) TV
7.033 0.048
Podľa modelu by bol priemerný objem predaja pri nulovej reklame v TV 7,033 jednotiek a s každým navýšením o 1,000 dolárov (o 1 v mierke datasetu) by vzrástol o 48 jednotiek (0.048 v mierke datasetu).
2.2.2 Presnosť parametrov
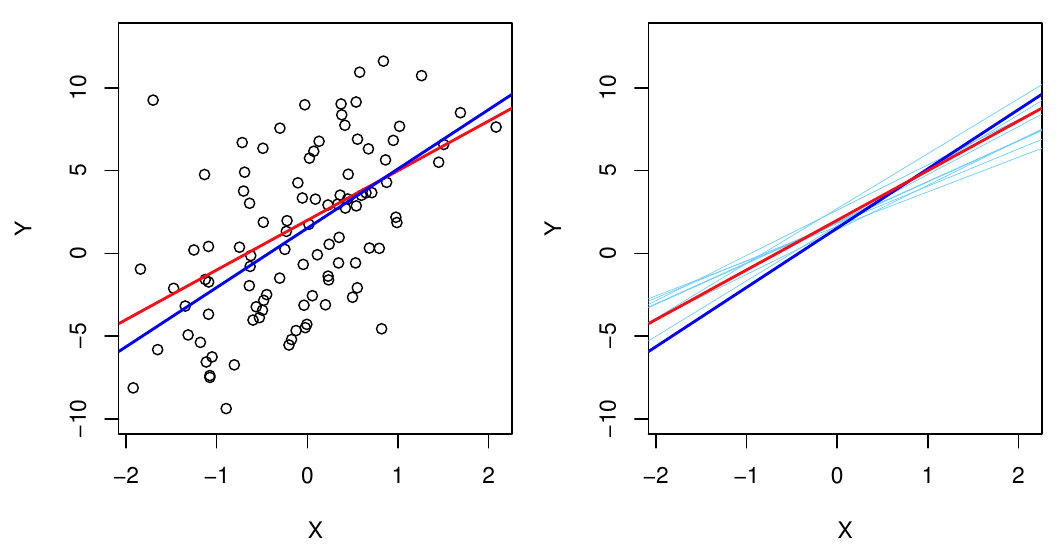
PoznámkaIlustrácia (priamka)
Nech je skutočný regresný vzťah daný funkciou f(X) = 2 + 3X.
Odhad na základe jednej realizácie náhodného výberu (simulácie z modelu {\color{red} Y = 2 + 3X} + \varepsilon) je zobrazený na obrázku vľavo (spolu s dátami). Na obr. vpravo je zobrazený spolu s odhadmi regresnej priamky získaných na základe ďalších 10 simulovaných datasetov.
Všetky odhadnuté priamky sa nachádzajú niekde okolo skutočnej priamky v dôsledku neistoty v určení parametrov.
Pretože metóda najmenších štvorcov dáva nevychýlený odhad (za podmienky splnenia predpokladov), spriemerovanie veľkého množstva odhadov vedie ku skutočnej hodnote (tu ku priamke).
V praxi máme iba jeden dataset, preto nás zaujíma, ako blízko sme sa pomocou neho dostali ku skutočnosti.
Podobne ako presnosť odhadu nepodmienenej strednej hodnoty (čo je vlastne 1D prípad) závisela od štandardnej odchýlky údajov a ich počtu (pripomeňme si vzťah var(\hat\mu)=SE(\hat\mu)^2=\sigma^2/n), tak to bude platiť aj pri presnosti odhadu parametrov,
var(\hat\beta_0) = \sigma^2\left(\frac1n+\frac{\bar x^2}{\sum_{i=1}^n(x_i-\bar x)^2}\right),
\quad
var(\hat\beta_1) = \left(\frac{\sigma^2}{\sum_{i=1}^n(x_i-\bar x)^2}\right),
na ich presnosť navyše vplýva aj rozptyl hodnôt x_i.
Rozptyl \sigma^2 je tiež neznámy parameter modelu. Odhadne sa jednoducho ako
\hat\sigma^2 = RSS / (n-2).
Štandardné chyby sa dajú použiť na konštrukciu intervalov spoľahlivosti,
\hat\beta_j\pm t_{1-\alpha/2}(n-2)\cdot SE(\hat\beta_j).
Interpretácia: ak by sme veľa-krát opakovali náhodný výber a zakaždým určili 95%-ný interval spoľahlivosti, potom 95% z nich by obsahovalo skutočnú hodnotu parametra.
Rovnako tak sa dajú použiť na testovanie štatistických hypotéz o parametroch, napr. H_0\colon\beta_1=0 (t.j. neexistuje vzťah medzi X a Y). Treba rozhodnúť, či \hat\beta_1 je dostatočne blízko (H_0), resp. ďaleko (H_1) od nuly. Ale koľko je “dostatočne”? To závisí od presnosti odhadu. Preto testovacia štatistika t-testu
t = \frac{\hat\beta_1-0}{SE(\hat\beta_1)} \quad\sim t(n-2)
vyjadruje počet štandardných chýb o ktoré je \hat\beta_1 vzdialené od 0.
2.2.3 Vyhodnotenie presnosti modelu
Akonáhle sme pomocou testu sklonu regresnej priamky vyhodnotili, že vzťah medzi premennými je významný, zaujíma nás, do akej miery model vystihuje dáta.
Jednou populárnou mierou (do akej model nevystihuje dáta) je reziduálny rozptyl (resp. reziduálna štandardná chyba). Jej nevýhodou je závislosť od mierky dát, takže je občas ťažké posúdiť, aké hodnoty ešte predstavujú dobrú zhodu.
Alternatívnou mierou je koeficient determinácie
R^2 = \frac{TSS-RSS}{TSS}=1-\frac{RSS}{TSS}
kde TSS=\sum_{i=1}^n(y_i-\bar y)^2 je celková suma štvorcov (čiže RSS obyčajného priemeru). Je zjavné, že ako pomer variancie vysvetlenej modelom ku celkovej variancii, je R^2 bezrozmerný a v rozsahu intervalu [0,1], takže nezávisí od mierky Y.
Je tiež zaujímavé, že R^2 sa zhoduje s druhou mocninou koeficientu korelácie medzi X a Y.
TipPríklad (reklama)
Vyjadrime vzťah reklamy v TV a odbytom pomocou lineárneho regresného modelu.
Kód
fit |>summary()
Call:
lm(formula = sales ~ TV, data = dat_Advertising)
Residuals:
Min 1Q Median 3Q Max
-8.3860 -1.9545 -0.1913 2.0671 7.2124
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.032594 0.457843 15.36 <2e-16 ***
TV 0.047537 0.002691 17.67 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.259 on 198 degrees of freedom
Multiple R-squared: 0.6119, Adjusted R-squared: 0.6099
F-statistic: 312.1 on 1 and 198 DF, p-value: < 2.2e-16
Odhad parametra \beta_1 je asi 17-násobne väčší než jeho štandardná chyba, preto aj p-hodnota je veľmi malá a H_0 zamietneme, čo značí výrazný vzťah medzi TV a sales.
Skutočný odbyt by v priemere fluktuoval 3.26 tisíc jednotiek okolo predpovede.
Model pomocou reklamy v TV vystihuje asi 61% variability odbytu.
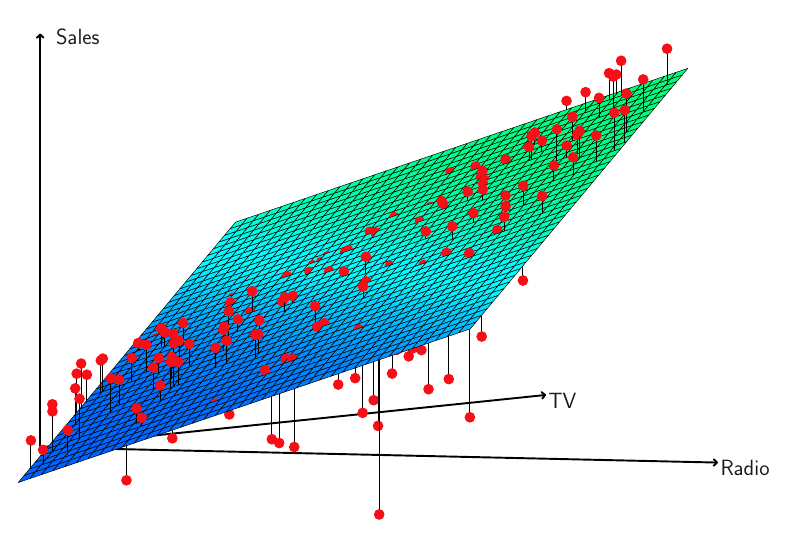
2.3 Viacnásobná regresia (viac prediktorov)
V praxi je zvyčajne k dispozícii viac premenných, ktoré môžu byť užitočné na vysvetlenie zmeny v strednej hodnote odozvy.
Zopakovať jednoduchú regresiu pre každú premennú naráža (minimálne) na problém, ako z viacerých modelov skonštruovať jedinú predpoveď.
Najjednoduchšie rozšírenie jednoduchej lineárnej regresie predpokladá aditivitu vplyvov jednotlivých prediktorov X_1,X_2,\ldots,X_p a má tvar
Y = \beta_0 + \beta_1 X_1 + \ldots + \beta_p X_p + \varepsilon
\tag{2.2}
Hodnota \beta_j sa interpretuje ako priemerný vplyv jednotkového nárastu premennej X_j na odozvu Yza stavu, v ktorom všetky ostatné prediktory zostávajú nezmenené.
2.3.1 Odhad parametrov
Odhad je analogický jednorozmernému prípadu a jednoduchšie sa reprezentuje v maticovej podobe.
Nech \mathbf{X} je matica plánu (regresná matica), ktorej i-ty riadok tvorí vektor (1, x_{i1}, \ldots, x_{ip}), pričom i=1,\ldots,n, ďalej \mathbf{y} je vektor pozorovaní odozvy Y a nakoniec \boldsymbol\beta = (\beta_0,\beta_1,\ldots,\beta_p)'.
Odhad parametrov metódou najmenších štvorcov dostaneme zo vzťahu
\hat{\boldsymbol\beta} = (\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}.
Potom predikcie dostaneme ako podmienenú strednú hodnotu \hat{\mathbf{y}} \equiv E(Y|\mathbf{X}) = \mathbf{X} \hat{\boldsymbol\beta}, rezíduá budú \hat{\boldsymbol{\varepsilon}} = \mathbf{y} - \hat{\mathbf{y}} a odhad rozptylu chybovej zložky
\hat{\sigma}_\varepsilon^2 = \frac{\hat{\boldsymbol\varepsilon}'\hat{\boldsymbol\varepsilon}}{n-(p+1)},
Kovariančná matica odhadu neznámych parametrov sa vypočíta zo vzťahu
\hat{\boldsymbol\Sigma}_{\beta} = \hat\sigma_\varepsilon^2(\mathbf{X}'\mathbf{X})^{-1}.
Jej diagonálu tvoria štvorce štandardných chýb odhadov parametrov.
TipPríklad (reklama)
Okrem TV uvažujme aj reklamu v rádiu a novinách.
Jednoduché regresné modely by mali nasledujúce odhady parametrov:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.0326 0.4578 15.3603 0
TV 0.0475 0.0027 17.6676 0
Estimate Std. Error t value Pr(>|t|)
(Intercept) 9.3116 0.5629 16.5422 0
radio 0.2025 0.0204 9.9208 0
Estimate Std. Error t value Pr(>|t|)
(Intercept) 12.3514 0.6214 19.8761 0.0000
newspaper 0.0547 0.0166 3.2996 0.0011
Viacnásobný lineárny regresný model má odhady parametrov pre TV a rádio veľmi podobné, no v prípade novín sa zásadne líši: vplyv reklamy v novinách vyzerá byť nevýznamný:
Kód
fit <-lm(sales ~ TV + radio + newspaper, dat_Advertising)fit |>summary() |>coef() |>round(4)
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.9389 0.3119 9.4223 0.0000
TV 0.0458 0.0014 32.8086 0.0000
radio 0.1885 0.0086 21.8935 0.0000
newspaper -0.0010 0.0059 -0.1767 0.8599
Vysvetlenie treba hľadať v interpretáci koeficientov. Všimnime si korelácie medzi premennými:
Kód
cor(dat_Advertising) |>round(3)
TV radio newspaper sales
TV 1.000 0.055 0.057 0.782
radio 0.055 1.000 0.354 0.576
newspaper 0.057 0.354 1.000 0.228
sales 0.782 0.576 0.228 1.000
Objem reklamy v novinách koreluje s ďalším prediktorom – reklamou v rádiu. Obe médiá pozitívne korelujú s odbytom. To znamená, že v jednoduchej regresii noviny iba sprostredkovali (nahrádzali) vplyv reklamy v rádiu a ako také nemajú dosah na zvýšenie odbytu.
Táto zdanlivá kontroverzia z príkladu o reklame je prítomná v mnohých reálnych situáciách.
PoznámkaIlustrácia (žraloky)
Uvažujme absurdný príklad, keď sa na základe záznamov z dovolenkových rezortov snažíme vysvetliť počet napadnutí žralokom pomocou odbytu zmrzliny.
Je pravdepodobné, že nám vyjde pozitívna korelácia a regresný koeficient je štatisticky významný.
Zdravý rozum nám hovorí, že netreba hneď zakazovať predaj zmrzliny.
Dôvod je celkom zjavne v tom, že vyššia teplota priláka na pláž viac ľudí a tým stúpne spotreba zmrzliny i prípady kolízie so žralokom.
Uvedená situácia sa nazýva zdanlivá regresia (spurious regression) a býva rizikom vtedy, ak si koreláciu mýlime s kauzalitou.
2.3.2 Využitie modelu
Viacnásobný regresný model nám umožňuje zodpovedať nasledujúce otázky:
Je aspoň jeden z prediktorov užitočný pre odhad strednej hodnoty odozvy?
Sú všetky prediktory užitočné, alebo len niektoré?
Nakoľko model vystihuje pozorované dáta?
Za predpokladu danej množiny prediktorov, aká je predikcia hodnoty odozvy a jej presnosť?
2.3.2.1 Test prítomnosti vzťahu s aspoň jedným prediktorom
V prípade jednoduchej regresie stačí zistiť, či \beta_1=0.
Pri viacnásobnej regresii však už treba overiť platnosť zložitejšej hypotézy,
H_0\colon \beta_1 = \beta_2 = \ldots = \beta_p=0
oproti alternatívnej, H_1\colonaspoň jedno\beta_j\neq0.
Testovacia štatistika má tvar
F = \frac{(TSS-RSS)/p}{RSS/(n-p-1)}\quad \sim F(p,n-p-1)
ak vzťah absentuje, jej hodnota (pri veľkom n) je blízka 1,
naopak, ak H_0 neplatí, potom E[(TSS-RSS)/p)]>\sigma^2
TipPríklad (reklama)
Hoci sú výsledky F-testu dostupné už v súhrne modelu (dostupnom cez funkciu summary), ukážeme si detaily porovnaním viacnásobného regresného modelu s konštantnou funkciou (baseline model):
Kód
lm(sales ~1, dat_Advertising) |>anova(fit)
Analysis of Variance Table
Model 1: sales ~ 1
Model 2: sales ~ TV + radio + newspaper
Res.Df RSS Df Sum of Sq F Pr(>F)
1 199 5417.1
2 196 556.8 3 4860.3 570.27 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Z nich vidieť, že TSS=5417 a RSS=557, takže testovacia štatistika F=570 je vysoko nad 1 a plocha pod hustotou F-rozdelenia za hodnotou F je menšia než 5% (dokonca menšia než 2.2\cdot 10^{-16}), a to znamená, že H_0 zamietneme: reklama v aspoň jednom médiu má významný vzťah ku odbytu.
Podobne sa dá overiť hypotéza, že iba časť (napríklad posledných q) parametrov je nulová, H_0\colon \beta_{p-q+1} = \ldots = \beta_p=0. Potom druhý, porovnávací linárny model (baseline) bude obsahovať všetky okrem tých q testovaných parametrov a testovacia štatistika sa zmení na
F = \frac{(RSS_0-RSS)/q}{RSS/(n-p-1)}\quad \sim F(q,n-p-1)
kde RSS_0 zodpovedá baseline modelu (a teda i nulovej hypotéze).
F-testom tak testujeme parciálny vplyv pridania ďalších parametrov do modelu.
TipPríklad (reklama)
Overme, že vplyv reklamy v novinách je nevýznamný.
Analysis of Variance Table
Model 1: sales ~ TV + radio
Model 2: sales ~ TV + radio + newspaper
Res.Df RSS Df Sum of Sq F Pr(>F)
1 197 556.91
2 196 556.83 1 0.088717 0.0312 0.8599
V prípade pridania iba jedného parametra je vidieť zhodu s t-testom jeho významnosti (t^2=F, porovnaj s riadkom pre newspaperv príklade z predošlej časti).
Ak však máme p-hodnoty ku jednotlivým parametrom, načo nám je celkový F-test? Veď sa zdá pravdepodobné, že ak aspoň jedna p-hodnota je malá, tak aspoň jeden prediktor má vzťah s odozvou, či nie? Žiaľ, takéto uvažovanie je chybné, obzvlášť pri veľkom počte prediktorov.
Napr. nech p=100 a hypotézaH_0\colon \beta_1=\ldots=\beta_p=0 je pravdivá. V dôsledku náhody približne 5 p-hodnôt (z individuálnych t-testov) bude i tak menších ako 0.05 (to je dôvod, prečo sa vo viacnásobnom testovaní zavádzajú korekcie p-hodnôt, napr. Bonferroniho).
F-test touto devalváciou netrpí, pretože zohľadňuje počet prediktorov.
Ak je prediktorov príliš veľa (relatívne ku počtu pozorovaní), alebo dokonca ak p>n, potom F-test nebude (dobre alebo vôbec) fungovať.
2.3.2.2 Dôležité prediktory
Ak pomocou F-testu zistíme nejaký vzťah ku odozve, je prirodzené pýtať sa: Tak ktoré prediktory sú za to zodpovedné, t.j. ktoré sú vlastne užitočné?
Mohli by sme sa pozrieť na individuálne p-hodnoty, ale pri väčšom počte je to riziko (nekorigované viacnásobné testovanie).
Problému určenia užitočných premenných (variable selection) sa budeme dôkladnejšie venovať v samostatnej prednáške, tu spomeňme iba základné metódy.
Pri p=2 prediktoroch sú 2^p=4 rôzne možnosti, ako zostaviť model (bez prediktorov, iba s jedným alebo druhým a s oboma). Ako však rozhodnúť, ktorý je najlepší? Používajú sa na to rôzne štatistiky, napr. Mallowove C_p , Akaikeho a bayesovské informačné kritériá (AIC, BIC), alebo korigovaný (adjusted) R^2.
Pri veľkom počte p je takýto postup výpočtovo náročný (už 2^{20}>10^6 môže byť dosť), preto sa používajú efektívnejšie postupy na výber premenných.
Medzi klasiku patrí výber premenných po krokoch (stepwise selection):
pridávaním prediktorov (forward selection) - Začína sa základným modelom bez prediktorov, v každom kroku sa pridá ten prediktor, ktorý prispel najviac (pridaním do modelu z predošlého kroku sa dosiahlo najmenšie RSS) a procedúra sa končí vtedy, keď už žiaden nový príspevok nie je štatisticky významný.
uberaním (backward selection) - Postup je opačný, z plného modelu sa postupne odstraňujú premenné, ktoré najmenej vysvetľujú variabilitu odozvy.
kombináciou (mixed selection) - Odstraňuje niektoré nevýhody predošlých postupov.
TipPríklad (reklama)
Kód
fit1 <-step(fit, direction ="backward")
Start: AIC=212.79
sales ~ TV + radio + newspaper
Df Sum of Sq RSS AIC
- newspaper 1 0.09 556.9 210.82
<none> 556.8 212.79
- radio 1 1361.74 1918.6 458.20
- TV 1 3058.01 3614.8 584.90
Step: AIC=210.82
sales ~ TV + radio
Df Sum of Sq RSS AIC
<none> 556.9 210.82
- radio 1 1545.6 2102.5 474.52
- TV 1 3061.6 3618.5 583.10
Model s reklamou v TV a rádiu má najnižšie AIC.
2.3.2.3 Miera zhody s dátami
Na vyjadrenie kvality odhadu modelu sa najčastejšie používajú miery ako reziduálny rozptyl a koeficient determinácie.
V prípade jednoduchej regresie je R^2 zhodné so štvorcom korelácie odozvy a prediktoru, teda cor^2(X,Y).
Aj vo viacnásobnej regresii súvisí s koreláciou, pretože vo všeobecnosti R^2=cor^2(Y,\hat Y).
Zatiaľ čo R^2 vždy rastie s počtom parametrov p, reziduálny rozptyl klesá s p len, ak príspevok prediktoru nie je príliš malý.
Okrem číselných mier je dobré zhodu modelu s dátami posúdiť pomocou grafických súhrnov, pretože pomocou nich dokážeme odhaliť slabé miesta modelu. Napr. neuváženie synergie prediktorov a špecifické odchýlky od linearity.
2.3.2.4 Predikcie
Predpovede z viacnásobného lineárneho regresného modelu sú zaťažené 3 druhmi neistoty:
Nepresnosť odhadu parametrov súvisí s redukovateľnou chybou (z minulej prednášky). Intervalom spoľahlivosti (confidence interval) určíme, ako blízko bude \hat Y ku f(X).
Voľba lineárnej aproximácie f(X) je ďalší zdroj redukovateľnej chyby (model bias).
Ak by sme aj poznali f(X), i tak sa odozva nedá predpovedať presne - kvôli neredukovateľnej chybe. Predpovedným intervalom (prediction interval) určíme, ako blízko Y kolíše okolo \hat Y. Vždy je širší ako konfidenčný, pretože obsahuje obe chyby - neredukovateľnú chybu aj neistotu určenia f(X).
TipPríklad (reklama)
Predpokladajme výdavky 100,000 USD na reklamu v TV a 20,000 USD v rádiu.
Skutočná stredná hodnota E(Y|TV=100,Radio=20) sa s 95% pravdepodobnosťou nachádza niekde medzi 10,990 a 11,530. Interval vyjadruje neistotu sprevádzajúcu priemer cez veľké množstvo trhov (miest).
Odbyt v jednom konkrétnom meste by sa pohyboval pravdepodobne niekde v rozmedzí 7,930 až 14,580.
2.4 Kvalitatívny prediktor
Prediktory nemusia byť iba kvantitatívne.
Regresný model však ako vstupy vyžaduje iba číselné hodnoty, preto je nutné kvalitatívne premenné vhodne nahradiť.
Situácia je jednoduchá v prípade binárnej premennej. Jej hodnoty sa iba prekódujú na 0 a 1. (V prostredí strojového učenia sa to nazýva one-hot encoding.)
Vo všeobecnosti, náhodnú premennú X s m možnými hodnotami \{a_1,\ldots,a_m\} treba nahradiť (m-1) pomocnými, indikačnými premennými (označovaných aj ako dummy), napr. pomocou indikačnej funkcie
1_x(X) = \begin{cases}
1 & \text{ak } X = x \\
0 & \text{inak}
\end{cases}
Ak hodnotu x_1 nastavíme ako základnú (referenčnú, baseline), regresný vzťah má potom tvar
\begin{split}
Y &= \beta_1 + \beta_2 1_{a_2}(X) + \ldots + \beta_{m} 1_{a_m}(X) + \varepsilon\\
&= \begin{cases}
\beta_1 + \varepsilon \quad\qquad \text{pre} & X = a_1 \\
\beta_1 + \beta_2 + \varepsilon & X = a_2 \\
\vdots & \\
\beta_1 + \beta_{m} + \varepsilon & X = a_m \\
\end{cases}
\end{split}
Interpretácia parametrov je tak priamočiara:
\beta_1 = E(Y|X=a_1), čiže absolútny člen \beta_1 predstavuje strednú hodnotu Y pri prvej úrovni X,
\beta_j = E(Y|X=a_j) - E(Y|X=a_1), j\geq2, teda rozdiel v strednej hodnote Y oproti prvej úrovni X.
Možností kódovania je veľa. Nemajú vplyv na odhad modelu ani test významnosti, iba na interpretáciu parametrov. Slúžia na ľahšie vyhodnotenie konkrétnych rozdielov (contrasts), špecifických pre potreby danej praktickej aplikácie.
TipPríklad (kreditky)
Majme údaje z datasetu Credit o držiteľoch kreditných kariet:
odozvu priemerný dlh (balance),
niekoľko kvantitatívnych prediktorov ako vek, počet kariet (cards), počet rokov vzdelania, príjem, limit, úverové hodnotenie (rating),
a kvalitatívnych prediktorov ako vlastníctvo domu (own), či študuje (student), životný stav (status, slobodný atď.) a región (východ,západ,juh).
Vzťah výšky dlhu a toho, či klient vlastní dom, sa z dát neukazuje významný. Test významnosti parametra je totožný s dvojvýberovým t-testom (pri rovnakom rozptyle).
Estimate Std. Error t value Pr(>|t|)
(Intercept) 509.803 33.128 15.389 0.000
OwnYes 19.733 46.051 0.429 0.669
Kód
t.test(Balance ~ Own, ISLR2::Credit)
Welch Two Sample t-test
data: Balance by Own
t = -0.42838, df = 395.58, p-value = 0.6686
alternative hypothesis: true difference in means between group No and group Yes is not equal to 0
95 percent confidence interval:
-110.29408 70.82784
sample estimates:
mean in group No mean in group Yes
509.8031 529.5362
Test vzťahu dlhu a regiónu je totožný s analýzou rozptylu (jednofaktorová ANOVA pri homogénnom rozptyle). Opäť sa vzťah nepotvrdil.
Kód
lm(Balance ~ Region, ISLR2::Credit) |>summary()
Call:
lm(formula = Balance ~ Region, data = ISLR2::Credit)
Residuals:
Min 1Q Median 3Q Max
-531.00 -457.08 -63.25 339.25 1480.50
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 531.00 46.32 11.464 <2e-16 ***
RegionSouth -12.50 56.68 -0.221 0.826
RegionWest -18.69 65.02 -0.287 0.774
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 460.9 on 397 degrees of freedom
Multiple R-squared: 0.0002188, Adjusted R-squared: -0.004818
F-statistic: 0.04344 on 2 and 397 DF, p-value: 0.9575
One-way analysis of means
data: Balance and Region
F = 0.043443, num df = 2, denom df = 397, p-value = 0.9575
Funkcia lm použila štandardné kódovanie kvalitatívnej premennej, ktoré sa dá zistiť pomocou options("contrasts") a zobraziť funkciou contrasts: vľavo sú pôvodné hodnoty X, hore sú členy použité v regresnej rovnici.
Kód
contrasts(ISLR2::Credit$Region)
South West
East 0 0
South 1 0
West 0 1
2.5 Aditivita a linearita
Štandardná viacnásobná lineárna regresia (2.2) má minimálne dva, veľmi obmedzujúce predpoklady:
aditivita – vzťah medzi odozvou a prediktorom X_j nezávisí od hodnôt ostatných prediktorov,
linearita – zmena Y spojená s jednotkovou zmenou X_j je konštantná.
2.5.1 Uvoľnenie aditivity
Jedným zo spôsobov, ako odstrániť predpoklad o nezávislosti vplyvu jedného prediktoru od vplyvu druhého prediktoru, je pridať do rovnice tretí prediktor, tzv. interakčný člen, ktorý je iba násobkom prvých dvoch, takže model má tvar
\begin{split}
Y &= \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \beta_3 X_1 X_2 + \varepsilon \\
&= \beta_0 + \underbrace{(\beta_1 + \beta_3 X_2)}_{\tilde\beta_1}X_1 + \beta_2 X_2 + \varepsilon
\end{split}
Parameter \tilde\beta_1 je zjavne lineárnou funkciou X_2, čiže vzťah medzi X_1 a Y sa mení s premennou X_2 (rovnako aj v obrátenom poradí prediktorov).
PoznámkaIlustrácia (výrobné linky)
Skúmajme produktivitu v továrni. Chceme predpovedať objem produkcie výrobkov pomocou počtu výrobných liniek a celkového počtu pracovníkov.
Prirodzene očakávame, že efekt pridávania liniek závisí od dostupnosti ich obsluhy (žiaden pracovník rovná sa žiadna výroba).
Ak by model mal tvar Výroba \approx 0 + 0\cdot Linky + 0\cdot Pracovníci + 3\cdot (Linky\cdot Pracovníci),
potom by pridanie jednej linky zvýšilo produkciu o 3\times počet pracovníkov.
Samozrejme takýto model nerieši situáciu, keď si pracovníci pre veľký počet začnú navzájom zavadzať.
TipPríklad (reklama)
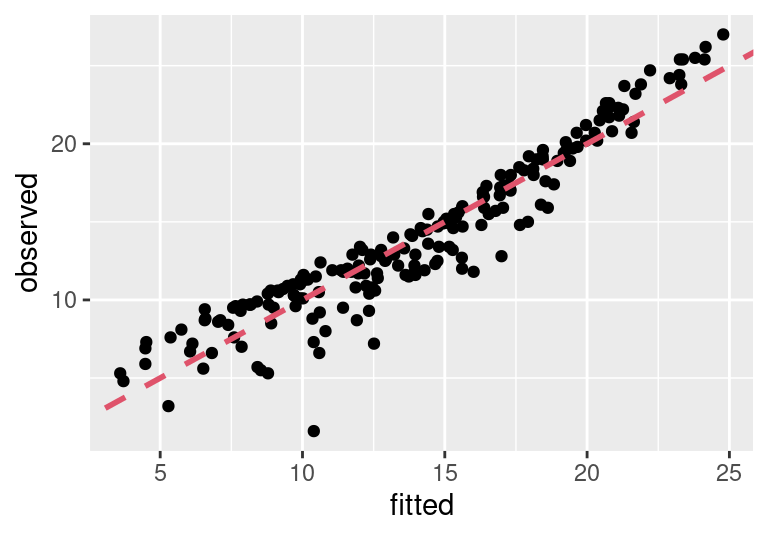
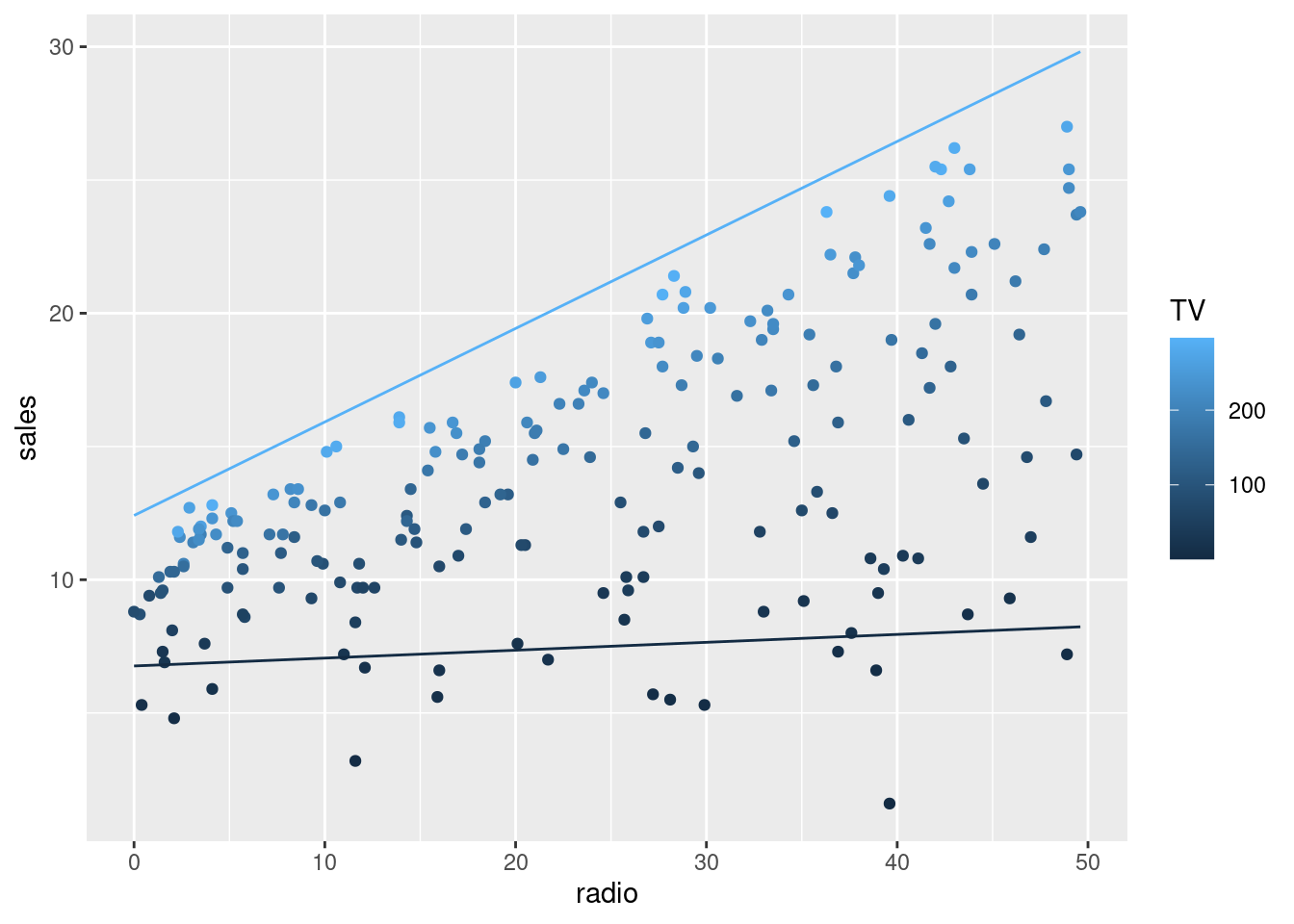
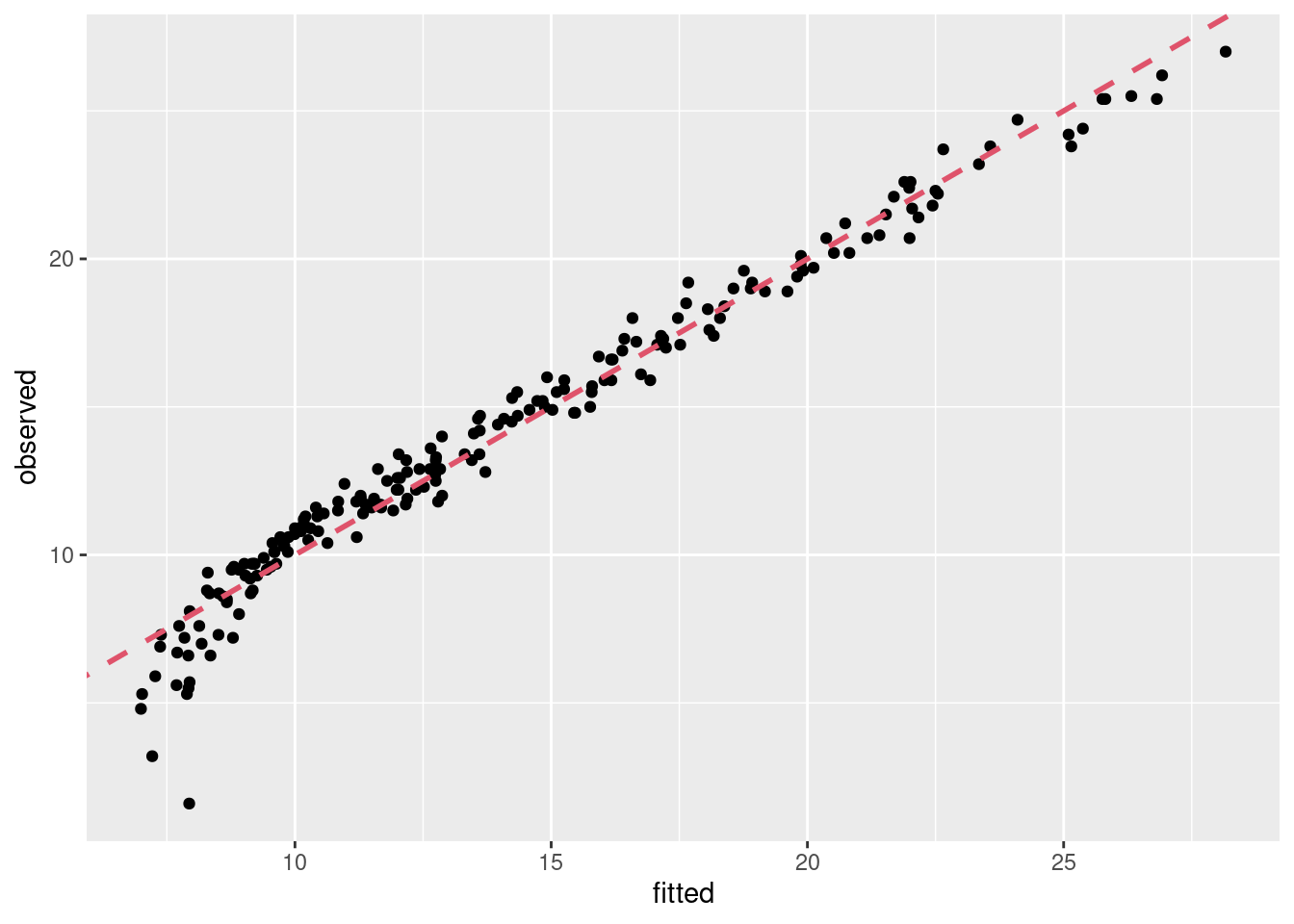
Hoci koeficient determinácie pre model s TV a rádiom je pomerne optimistický (R^2=0.897), pri pohľade na bodový graf vzťahu odhadnutých a pozorovaných hodnôt (obrázok vľavo) cítime, že niečo škrípe.
Pre lepšiu predstavu treba model zobraziť v priestore všetkých zúčastnených premenných.
Kód
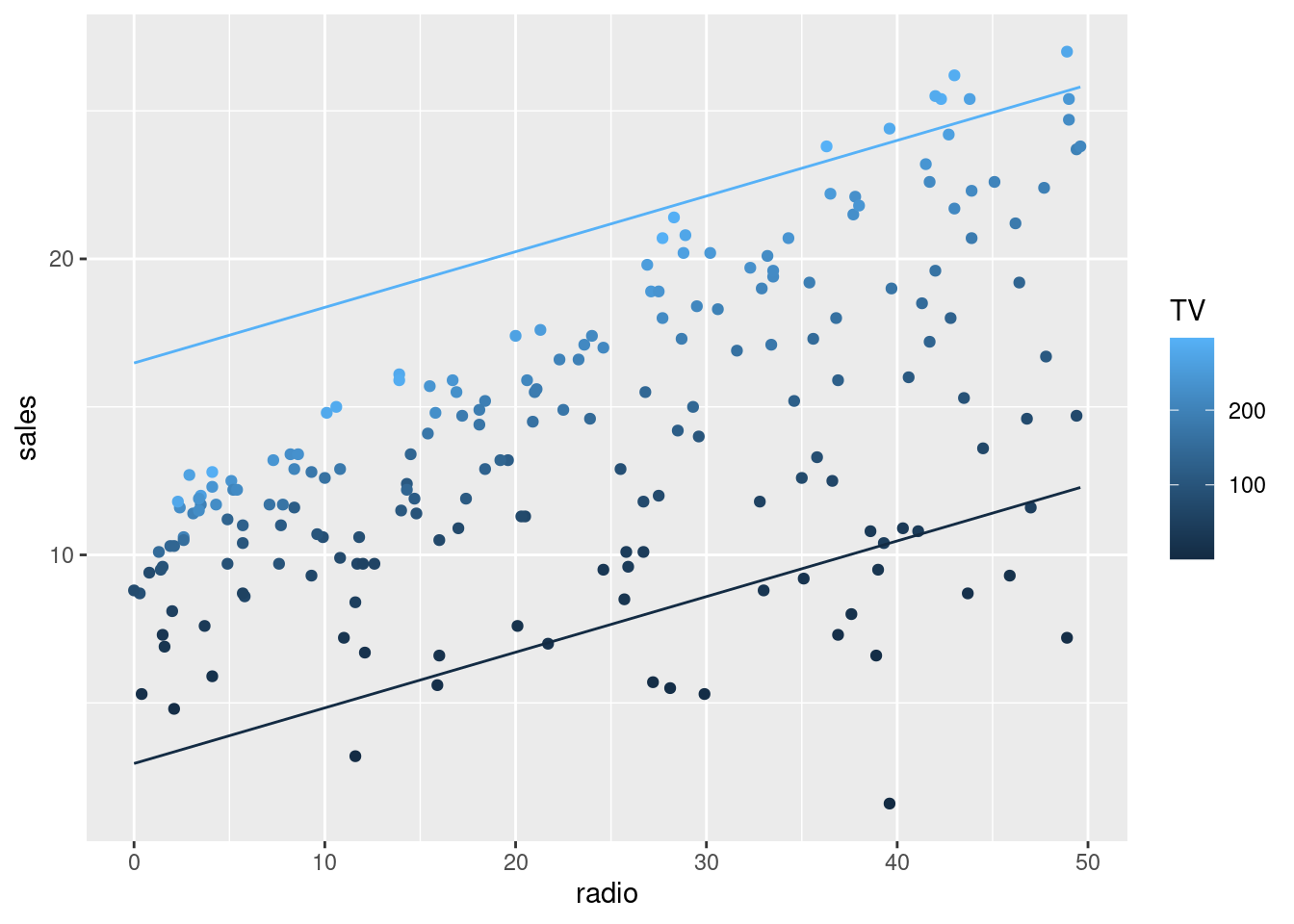
grid_Advertising <-expand.grid(TV =range(dat_Advertising$TV),radio =range(dat_Advertising$radio)) |> modelr::add_predictions(fit1, var ="sales")ggplot() +aes(x = radio, y = sales, color = TV) +geom_point(data = dat_Advertising) +geom_line(aes(group =as.factor(TV)), data = grid_Advertising)
Aditívny Lineárny model má tendenciu podhodnocovať v oblasti blízko diagonály (v rovine na obr. vľavo), tam kde je rozpočet na reklamu v oboch médiách v rovnováhe. Naopak, odbyt je nadhodnocovaný v prípadoch nesymetrických investícií do reklamy.
Odhadnime teda model s interakciou medzi TV a rádiom.
Kód
fit2 <-update(fit1, . ~ . + TV:radio, data = dat_Advertising)summary(fit2)
Call:
lm(formula = sales ~ TV + radio + TV:radio, data = dat_Advertising)
Residuals:
Min 1Q Median 3Q Max
-6.3366 -0.4028 0.1831 0.5948 1.5246
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.750e+00 2.479e-01 27.233 <2e-16 ***
TV 1.910e-02 1.504e-03 12.699 <2e-16 ***
radio 2.886e-02 8.905e-03 3.241 0.0014 **
TV:radio 1.086e-03 5.242e-05 20.727 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9435 on 196 degrees of freedom
Multiple R-squared: 0.9678, Adjusted R-squared: 0.9673
F-statistic: 1963 on 3 and 196 DF, p-value: < 2.2e-16
Kód
grid_Advertising <- modelr::add_predictions(data = grid_Advertising, model = fit2, var ="sales")ggplot() +aes(x = radio, y = sales, color = TV) +geom_point(data = dat_Advertising) +geom_line(aes(group =as.factor(TV)), data = grid_Advertising)
Nový model je podstatne lepší, interakčný člen pomohol vysvetliť (96.8-89.7)/(100-89.7)=69\% zvyšnej variability odbytu. Rezervu má v oblasti nízkeho odbytu, avšak môže ísť aj o prítomnosť extrémne nízkych pozorovaní. Tzv. outlier-om sa ešte budeme venovať.
Ak navýšime rozpočet na reklamu v rádiu o 1,000 USD, odbyt by mal stúpnuť o 29 + 1.1\cdot TV jednotiek. Čiže napr. o 139,000 ak TV=100,000 USD.
V poslednom príklade vyšiel efekt interakčného člena aj oboch premenných signifikantný. Avšak nie vždy to tak býva a jeden (alebo aj oba) individuálne členy môžu vyjsť nevýznamné. V takom prípade sa – podľa hierarchického princípu – v modeli ponechávajú aj samostatne všetky premenné, ktoré vystupujú v interakčnom člene. (Inak by sa interakčný člen ťažko interpretoval.)
Interakcia (synergia) sa neobmedzuje len na spojité prediktory. Nech X_1 je kvantitatívna a X_2 kvalitatívna premenná, ktorá náhodne nadobúda jednu z m hodnôt \{a_1,\ldots,a_m\}. Potom model viažuci obe premenné aj ich interakciu má tvar
\begin{split}
Y &= \beta_0 + \beta_1X_1 + \beta_2 1_{a_2}(X_2) + \ldots + \beta_{m} 1_{a_m}(X_2) + \, \\
& \qquad + \beta_{m+1}X_1 1_{a_2}(X_2) + \ldots + \beta_{2m-1}X_1 1_{a_m}(X_2) + \varepsilon\\[1em]
&= \begin{cases}
\beta_0 + \beta_1X_1 + \varepsilon \phantom{ + (\beta_1 + \beta_{2m+1})X_1 + } \text{pre} & X_2 = a_1 \\
(\beta_0 + \beta_2) + (\beta_1 + \beta_{m+1})X_1 + \varepsilon & X_2 = a_2 \\
\vdots \\
(\beta_0 + \beta_{m}) + (\beta_1 + \beta_{2m-1})X_1 + \varepsilon & X_2 = a_m \\
\end{cases}
\end{split}
Pre každú hodnotu premennej X_2 tvorí model jednu regresnú priamku s odlišným priesečníkom i sklonom. Tento rozdiel je daný prírastkom \beta_2,\ldots,\beta_m resp. \beta_{m+1},\ldots,\beta_{2m-1} oproti parametrom pre prvú, referenčnú úroveň prediktora X_2.
TipPríklad (kreditky)
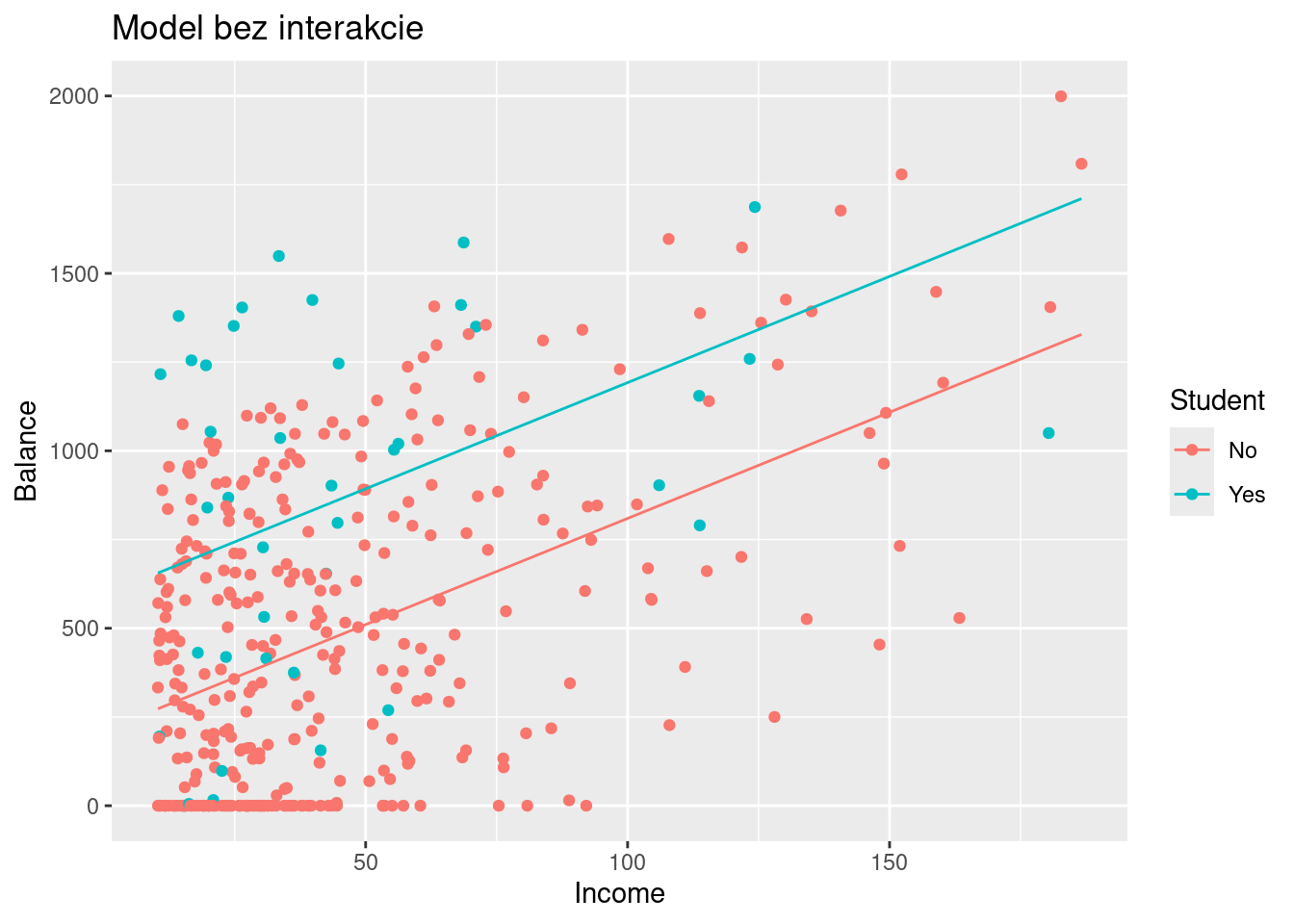
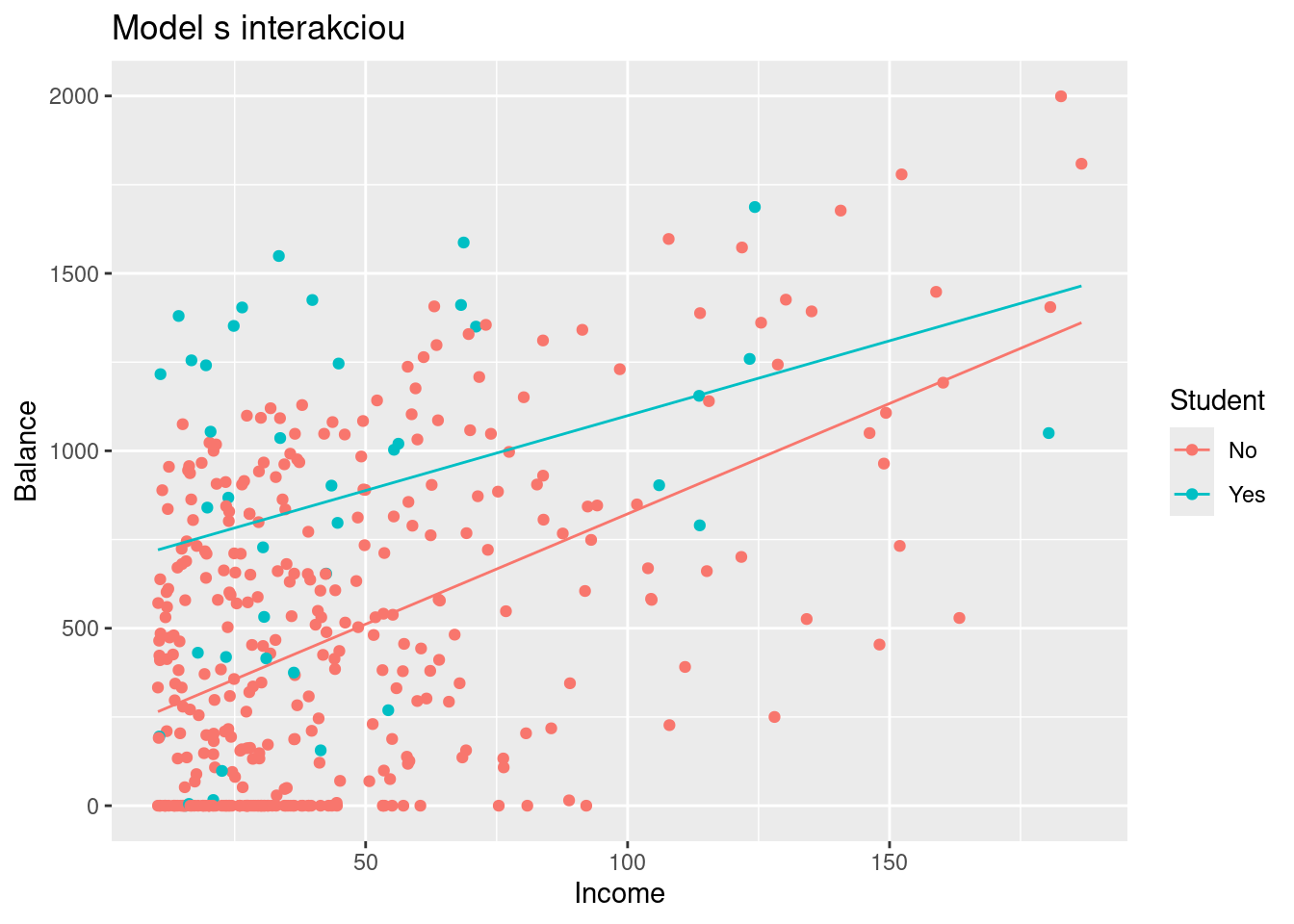
Chceme predpovedať veľkosť dlhu držiteľov kreditných kariet pomocou dvoch prediktorov: mesačného príjmu (income) a indikátoru štúdia.
Vytvoríme dva modely – jeden bez a druhý s interakciou – a porovnáme ich.
Kód
fit1 <-lm(Balance ~ Income + Student, data = ISLR2::Credit)fit1 |>summary() |>coef() |>round(3)
Estimate Std. Error t value Pr(>|t|)
(Intercept) 211.143 32.457 6.505 0
Income 5.984 0.557 10.751 0
StudentYes 382.671 65.311 5.859 0
grid_Credit <-expand.grid(Income =range(ISLR2::Credit$Income),Student =levels(ISLR2::Credit$Student) # alebo unique()) |> modelr::add_predictions(fit1, var ="Balance")ggplot() +aes(x = Income, y = Balance, color = Student) +geom_point(data = ISLR2::Credit) +geom_line(aes(group =as.factor(Student)), data = grid_Credit) +ggtitle("Model bez interakcie")
Kód
grid_Credit <- grid_Credit |> modelr::add_predictions(fit2, var ="Balance")ggplot() +aes(x = Income, y = Balance, color = Student) +geom_point(data = ISLR2::Credit) +geom_line(aes(group =as.factor(Student)), data = grid_Credit) +ggtitle("Model s interakciou")
Hoci druhý model neprispieva ku vysvetleniu variability dlhu významnejšie ako prvý model (interakčný člen je štatisticky nevýznamný), príklad dobre ilustruje, že s interakciou dochádza k zmene sklonu regresnej priamky.
2.5.2 Uvoľnenie linearity
Lineárny regresný model (2.1) predpokladá linearitu medzi odozvou Y a prediktorom.
To reálne nebýva často splnené.
Aj v takých prípadoch sa však lineárny model dá použiť, a to rozšírením pomocou bázových funkciíb_j,
Y = \beta_0 + \beta_1 b_1(X) + \beta_2 b_2(X) + \ldots + \beta_q b_q(X) + \varepsilon
Bázové funkcie sú zvolené vopred, takže model zostáva lineárny v parametroch a dá sa rovnako elegantne odhadnúť metódou najmenších štvorcov ako aj použiť nástroje štatistickej dedukcie o kvalite modelu, o jeho parametroch a predikcii. To, čo treba osobitne prispôsobiť rozšíreniu, je interpretácia.
Ako jednoduché bázové funkcie sa často používajú mocninové transformácie b_j(x)=x^j (výsledkom je tzv. polynomická regresia), ďalej odmocninové, logaritmické, po častiach lineárne či goniometrické transformácie.
Nakoniec, aj indikačná funkcia, ktorou sme prekódovali kvalitatívnu premennú do \{0,1\}, sa dá zaradiť medzi bázové funkcie.
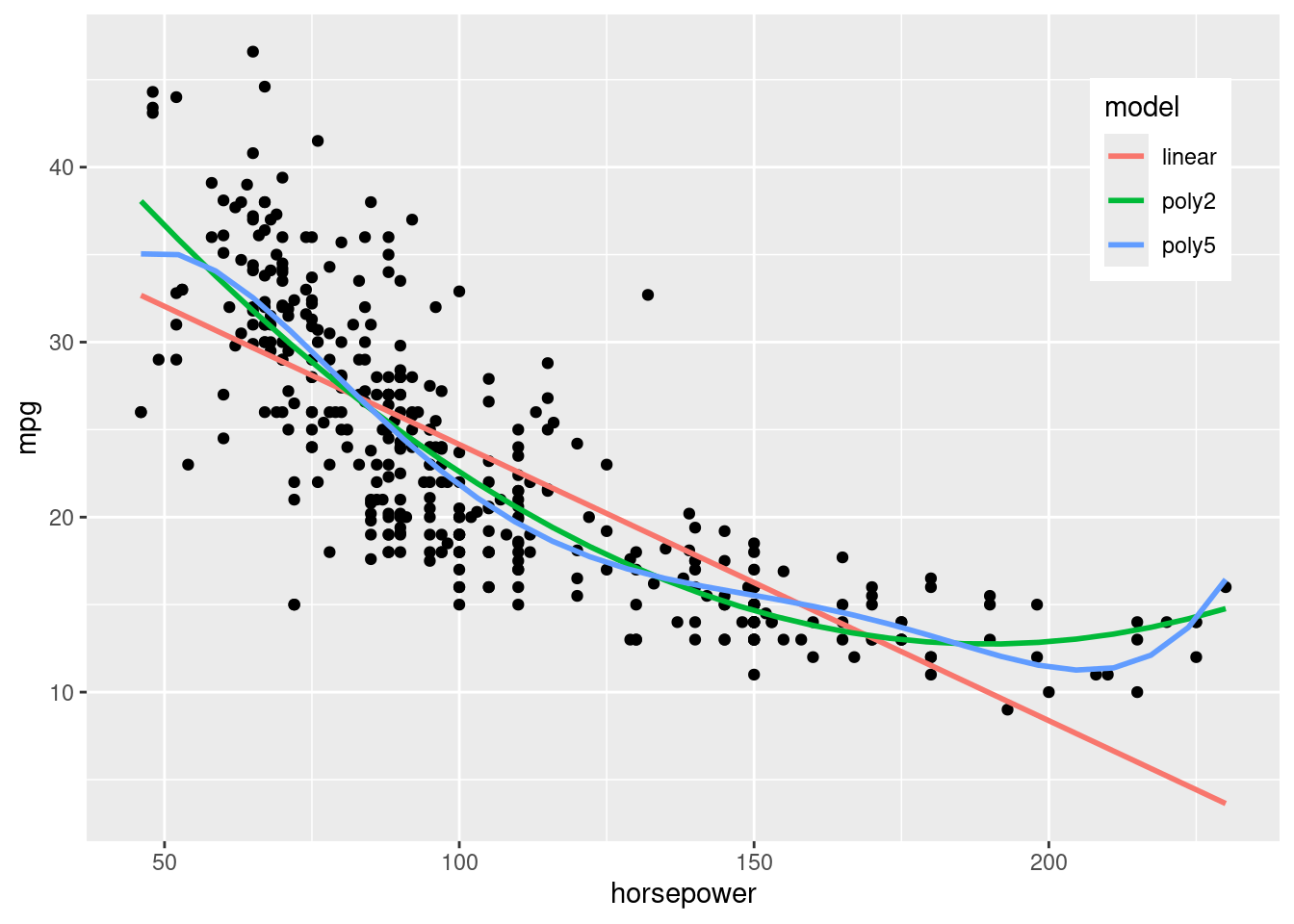
TipPríklad (autá)
Majme dataset pozorovaní o 392 automobiloch, ktorý obsahuje také vlastnosti ako dojazd (mpg, miles per gallon), počet valcov, zdvihový objem, výkon motora (horsepower), váha, zrýchlenie, pôvod, rok návrhu a názov modelu.
Chceme modelovať vzťah medzi dojazdom a výkonom motora.
Lineárna funkcia už napohľad nepostačuje, preto siahneme po polynomickej regresii s rôznym stupňom.
S rastúcim stupňom polynómu klesá vychýlenosť a rastie rozptyl modelu (zložka redukovateľej chyby). Optimálny stupeň by sa určil pomocou testovacej chyby, avšak z interpretačného hladiska nie je ani polynomický model ideálny – hlavne kvôli zmene monotónnosti. Je nelogické, aby s rastúcim výkonom (nad 180 koní) rástol aj dojazd.
Ako dočasnú náhradu za vyhodnotenie všetkých troch modelov pomocou odhadu testovacej chyby teraz použijeme F-test – sériovo (čiže prvý oproti druhému a druhý voči tretiemu).
Kód
anova(fit1, fit2, fit3)
Analysis of Variance Table
Model 1: mpg ~ horsepower
Model 2: mpg ~ horsepower + I(horsepower^2)
Model 3: mpg ~ poly(horsepower, 5)
Res.Df RSS Df Sum of Sq F Pr(>F)
1 390 9385.9
2 389 7442.0 1 1943.89 103.8767 < 2.2e-16 ***
3 386 7223.4 3 218.66 3.8949 0.009196 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Z popisného hľadiska polynomická funkcia nielen druhého stupňa (oproti lineárnej) vystihuje dáta ale aj piateho stupňa (oproti kvadratickej).
Rozšírenie tohoto prístupu na viacnásobnú regresiu s prediktormi \vec X = (X_1,X_2,\ldots,X_p) je tiež pomerne priamočiare,
Y = \beta_0 + \beta_1 b_1(\vec X) + \beta_2 b_2(\vec X) + \ldots + \beta_q b_q(\vec X) + \varepsilon
a zahŕňa aj lineárny model s interakciou, napr. ak b_1(\vec X)=X_1, b_2(\vec X)=X_2 a b_3(\vec X)=X_1X_2.
2.6 Nesplnené predpoklady
Žiaden model nie je univerzálny – každý je spoľahlivý iba vtedy, ak sú splnené určité podmienky.
Ak nie sú splnené predpoklady použitia lineárnych regresných modelov,
nie sú spoľahlivé ani závery dedukcie urobené pomocou (takto) odhadnutého modelu a
presnosť predikcií výrazne klesá.
Hlavné príčiny problémov sú:
nelinearita vzťahu odozvy a prediktorov
korelácia v šumovej zložke
premenlivý rozptyl šumovej zložky
odľahlé pozorovania
pozorovania s veľkým pákovým efektom
silný vzťah medzi prediktormi (tzv. kolinearita)
Identifikácia a prekonanie týchto problémov niekdy hraničí až s umením.
Preto je dobré poznať niekoľko užitočných diagnostických nástrojov.
2.6.1 Nelinearita
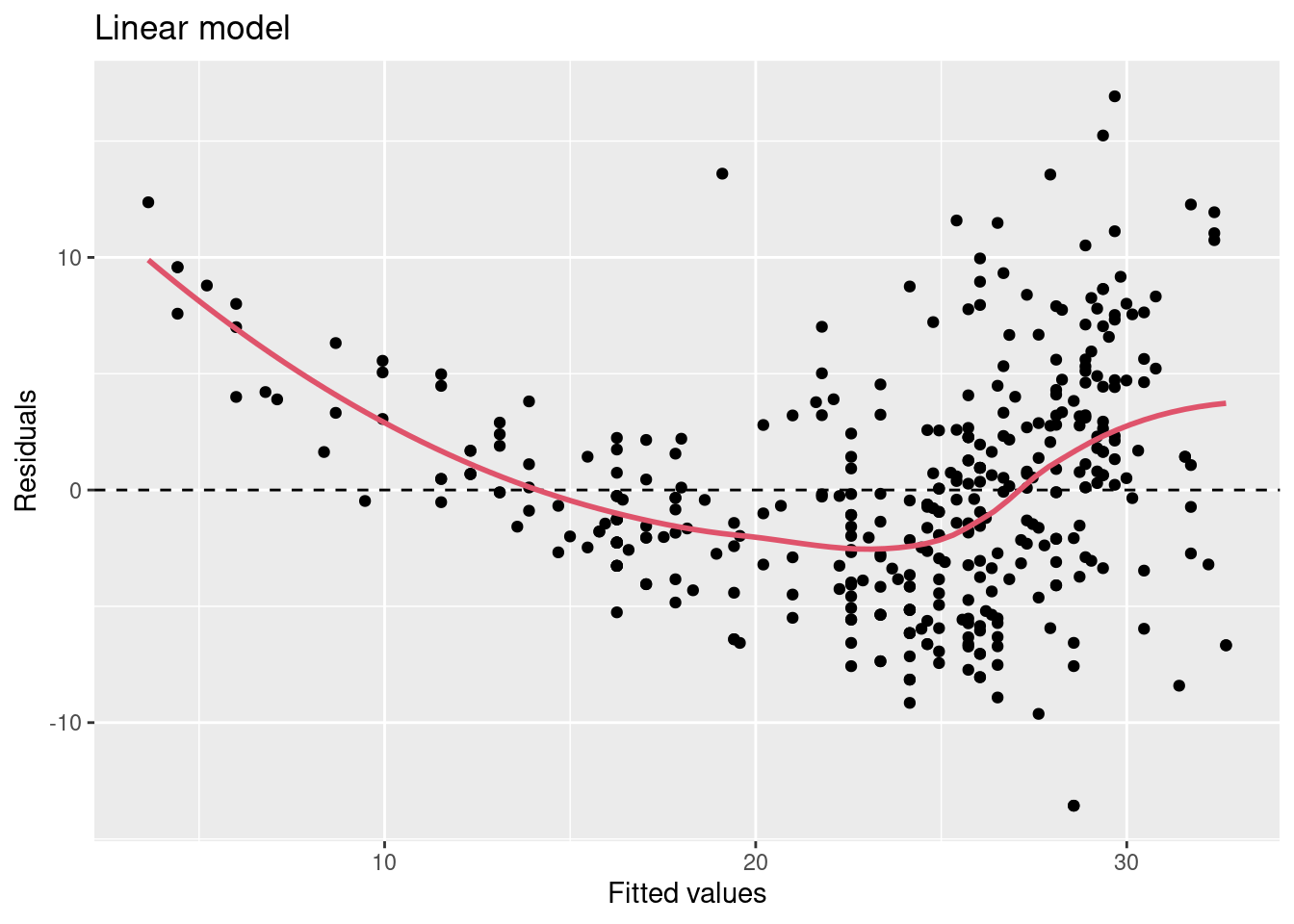
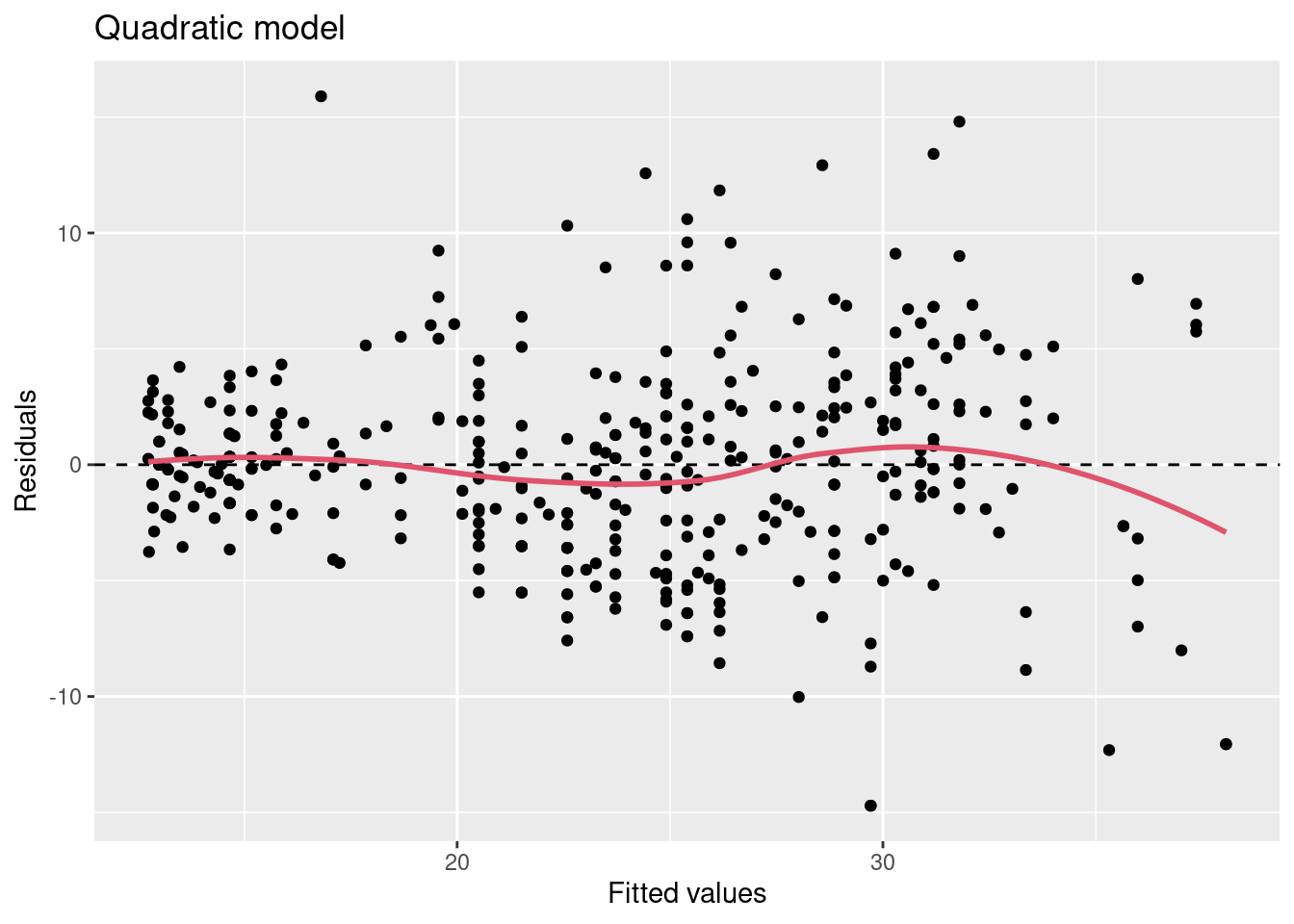
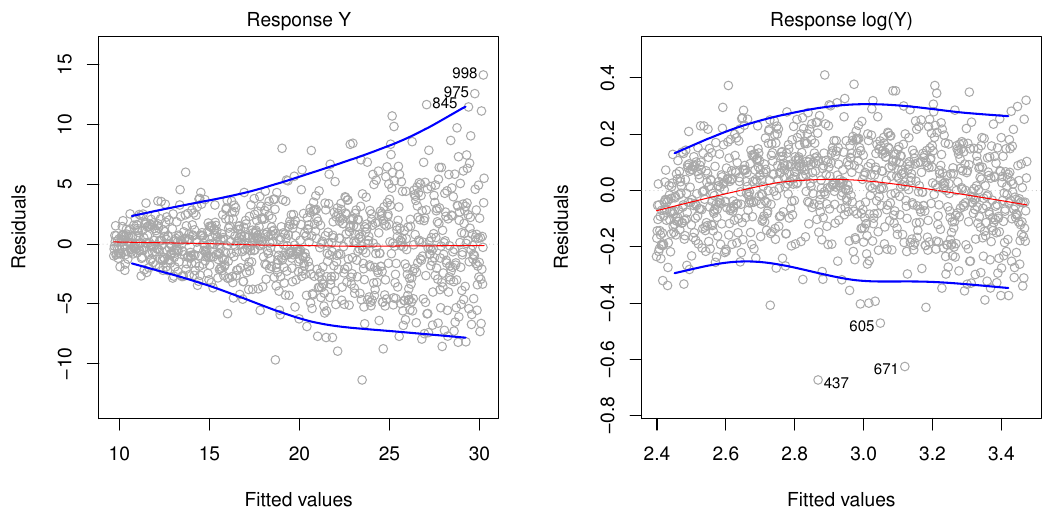
Jedným z diagnostických nástrojov je graf rezíduí (voči predikciám) modelu. Pomocou neho sa dá odhaliť aj porušenie predpokladu linearity regresnej funkcie.
TipPríklad (autá)
Reziduálne grafy (prvých dvoch modelov z predošlého príkladu) odhaľujú jednak
výraznu zmenu v strednej hodnote rezíduí lineárneho modelu, jednak
konštantnosť strednej hodnoty rezíduí kvadratického modelu.
To ukazuje na vychýlenosť (bias) lineárneho modelu.
Kód
fit1 |> broom::augment() |>ggplot() +aes(x = .fitted, y = .resid) +geom_point() +geom_hline(yintercept =0, linetype =2) +geom_smooth(se =FALSE, color =2) +labs(title ="Linear model", x ="Fitted values", y ="Residuals")fit2 |> broom::augment() |>ggplot() +aes(x = .fitted, y = .resid) +geom_point() +geom_hline(yintercept =0, linetype =2) +geom_smooth(se =FALSE, color =2) +labs(title ="Quadratic model", x ="Fitted values", y ="Residuals")# alternatívely e.g. # fit1 |> ggfortify:::autoplot.lm(which = 1, ncol = 1)# or tools of the packages ggResidpanel, gglm ...
V tomto prípade bol problém vyriešený mocninovou transformáciou prediktoru (rozšírením modelu pomocou polynomickej bázovej funkcie).
2.6.2 Korelácia šumovej zložky
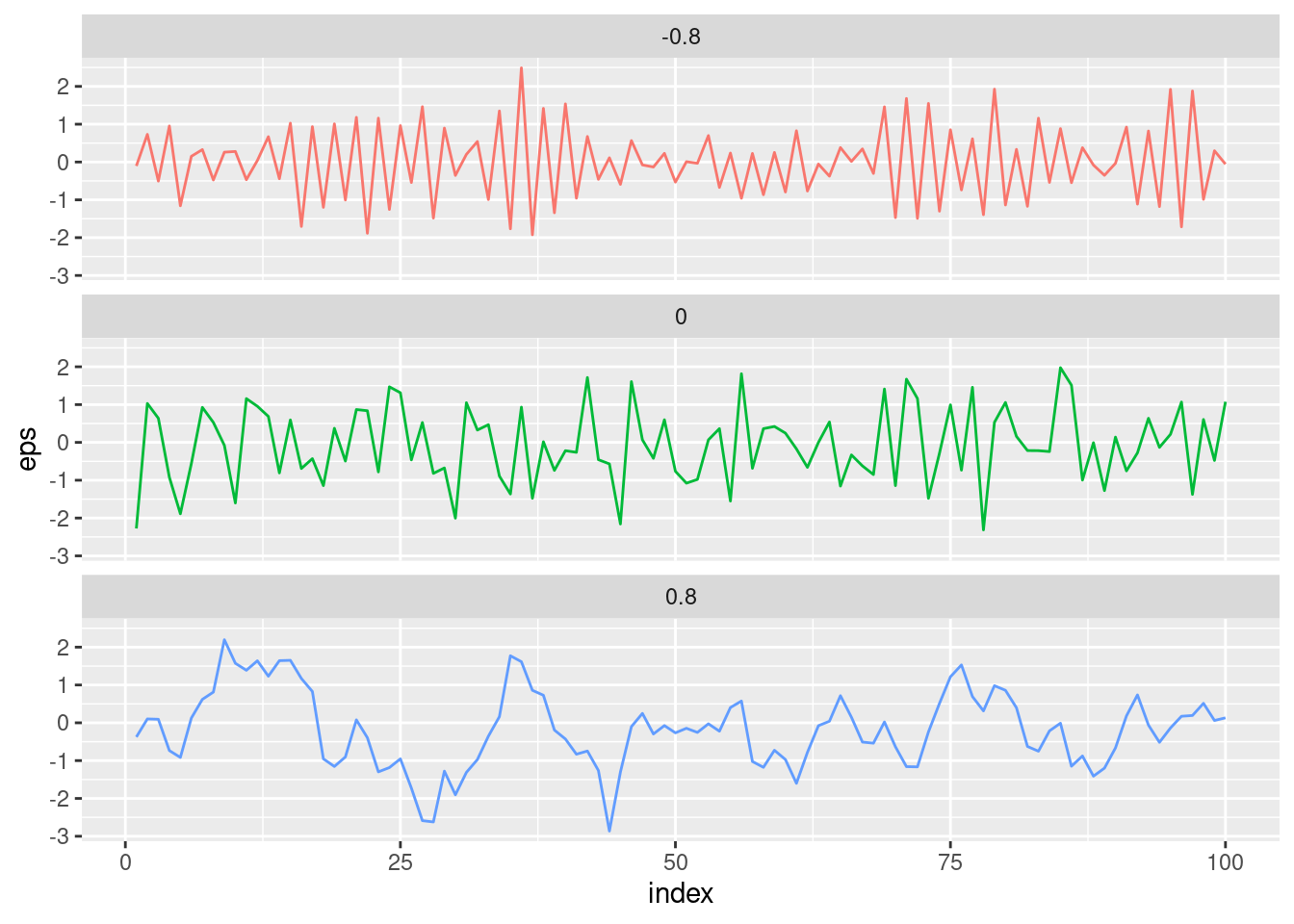
Lineárna regresia predpokladá, že hodnoty chybovej zložky majú rovnaké rozdelenie a navzájom nijak nesúvisia, teda napr. že realizácia \varepsilon_i neposkytuje žiadnu informáciu o tom, akú hodnotu nadobudne \varepsilon_{i+1}.
Ak to nie je splnené, konkrétne ak je prítomná pozitívna sériová korelácia, potom odhady štandardných chýb parametrov sú podhodnotené, čo vyústi do
užších konfidenčných a predikčných intervalov (napr. 95% interval bude v skutočnosti zodpovedať menšej pravdepodobnosti než 0.95, že obsahuje skutočnú hodnotu parametra),
menších p-hodnôt testu významnosti modelu, takže sa môžeme mylne domnievať, že regresný vzťah je významný.
Ak sú teda chyby kladne autokorelované, vedie nás to k prehnanej dôvere ku modelu.
Korelovanosť chýb často vzniká v kontexte časových radov, teda pozorovaní získaných v časových okamihoch nasledujúcich “dostatočne krátko” po sebe.
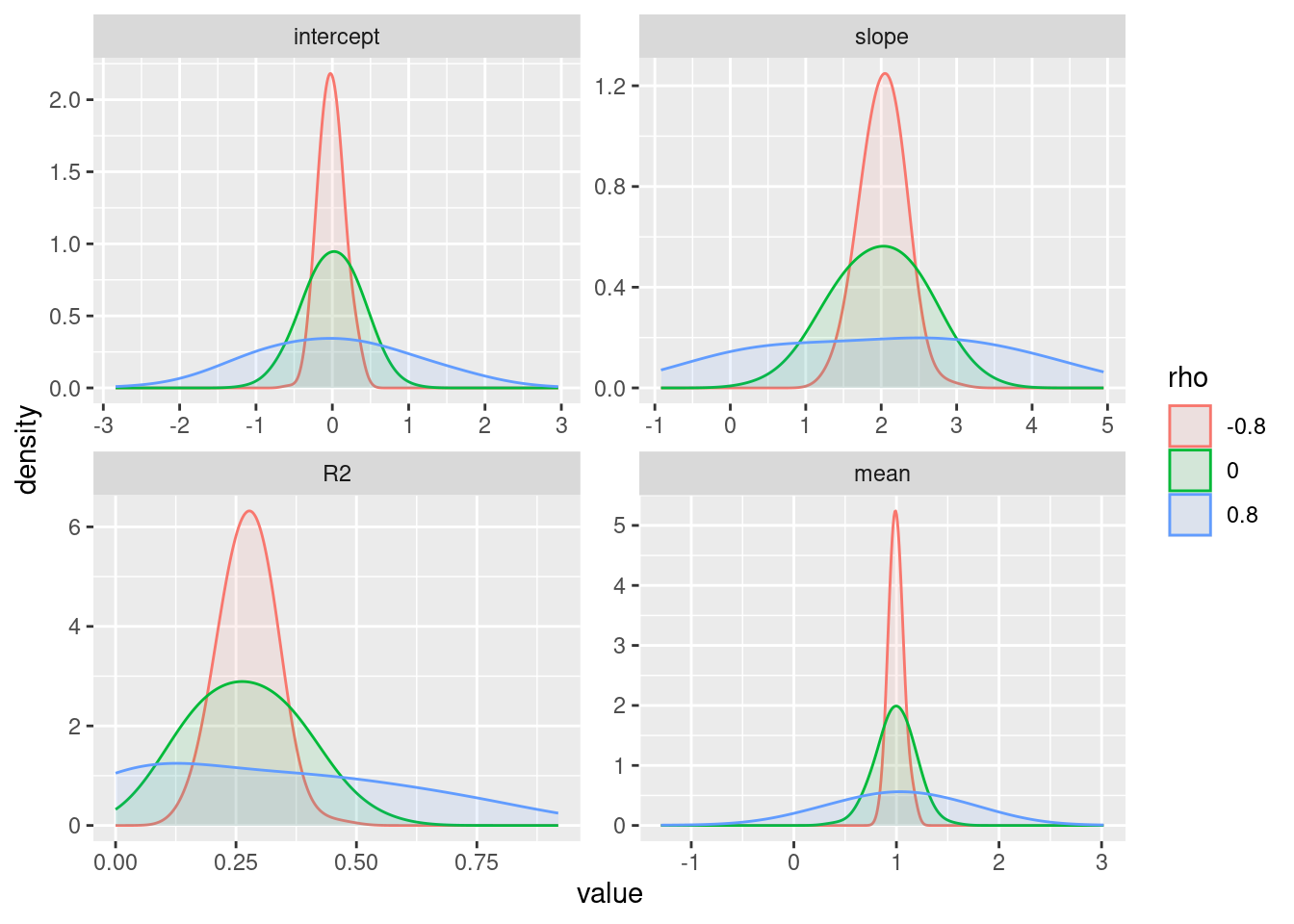
TipIlustrácia (autokorelácia)
Grafy znázorňujú šumovú zložku generovanú AR(1) procesom pre tri rôzne hodnoty parametra a jej vplyv na presnosť určenia niekoľkých štatistík súvisiacich s modelom. Skutočný vzťah je daný rovnicou Y = 0 + 2 X + \varepsilon, pričom \sigma_\varepsilon=1 a predpoveď (mean) bola počítaná v bode X=0.5.
Kód
set.seed(4)lapply(c(-0.8, 0, 0.8), FUN =function(x) { n <-100arima.sim(list(ar = x), n = n) |>suppressWarnings() |>cbind.data.frame(index =1:n, eps = _, rho = x) |>transform(eps = eps/sd(eps))}) |> dplyr::bind_rows() |> dplyr::mutate(rho =factor(rho)) |>ggplot() +aes(x = index, y = eps, color = rho) +geom_line(show.legend =FALSE) +facet_wrap(vars(rho), ncol =1)
Kód
# Function to calculate sampling distribution of several estimates involved in simple linear regression (intercept, slope, conditional mean value) using AR noise series.# in: xvalues - numeric vector, values of the predictor# xpredict - numeric value, point of conditional mean# linepars - numeric vector, true model parameters# rho - numeric value, parameter of AR(1) model# sd_noise - numeric value, standard deviation of noise series# N - integer, number of replications# out: Nx3 data framefun_simplereg_sim <-function(xvalues =seq(0, 1, length.out =30), xpredict =median(xvalues),linepars =c(b0 =0, b1 =2), rho =0, sd_noise =1,N =300) { n <-length(xvalues) noise <-replicate(N, { out <-arima.sim(list(ar = rho), n = n) |>suppressWarnings() out/sd(out)*sd_noise }) signal <- ( cbind(1,xvalues) %*% linepars ) |>rep(N) |>matrix(ncol = N) data <- signal + noiseapply(data, 2, function(y) { fit <-lm(y ~ xvalues) pars <-coefficients(fit) |>unname() mean <-predict(fit, newdata =data.frame(xvalues = xpredict)) |>unname()c(intercept = pars[1],slope = pars[2], R2 =cor(fit$fitted.values, y)^2,mean = mean ) }) |>t() |>data.frame()}lapply(c(-0.8, 0, 0.8), FUN =function(x) {fun_simplereg_sim(rho = x) |>cbind(rho = x) }) |> dplyr::bind_rows() |> tidyr::pivot_longer(-rho, names_to ="variable", values_to ="value") |> dplyr::mutate(rho =factor(rho), variable = forcats::as_factor(variable)) |>ggplot() +aes(x = value, fill = rho, color = rho) +geom_density(adjust =2, alpha =0.1) +facet_wrap(vars(variable), ncol =2, scales ="free")
Výsledky pre sklon a R^2 sú veľmi citlivé na rozdelenie prediktoru. V tomto príklade bola pre hodnoty X použitá rovnomerná mriežka 30 bodov v intervale [0,1].
Na riešenie problému takéhoto druhu (keď model nevyužíva informáciu dôležitého prediktoru – času) slúžia metódy analýzy časových radov.
Korelácia šumu však môže vzniknúť aj v dôsledku vynechania kvalitatívnej premennej ako významného faktoru vplývajúceho na odozvu. Napríklad ak v analýze výšky jednotlivcov pomocou ich váhy zanedbáme fakt, že niektorí sú členmi jednej rodiny, dodržiavajú tú istú diétu, alebo boli vystavení rovnakým vplyvom prostredia.
Ak sa takýmto vplyvom dá vyhnúť, zvyčajne sa problém vyrieši dobrým návrhom experimentu (design of experiment). Ak nie, a štatistické jednotky prirodzene tvoria skupiny, ktorých vplyv však nie je predmetom záujmu výskumu, vtedy sa na modelovanie používajú tzv. linear mixed-effects modely.
2.6.3 Premenlivá variabilita
Narušenie podmienky konštantnosti rozptylu šumovej zložky, var(\varepsilon_i)=\sigma^2, ktoré sa nazýva heteroskedasticita, má vplyv na štandardné chyby odhadov a tak aj na testy hypotéz, ktoré s modelom súvisia.
Jedným z príkladov je rozptyl rastúci so strednou hodnotou, kedy rezíduá majú tvar lievika. Riešením môže byť vhodná konkávna transformácia odozvy, napr. odmocninová, logaritmická alebo ich zovšeobecnenie – Box-Coxova transformácia.
PoznámkaIlustrácia (heteroskedasticita)
Iným zdrojom heteroskedasticity býva agregovanie pozorovaní. Napr. nech i-ta hodnota odozvy (i=1,\ldots,n) vznikne priemerom n_i surových nekorelovaných pozorovaní s rozptylom \sigma^2. Jej rozptyl tak bude \sigma_i^2=\sigma^2/n_i.
V tomto prípade je pomoc tiež jednoduchá – odhadnúť model metódou vážených najmenších štvorcov (weighted least squares)
\hat{\boldsymbol\beta} = (\mathbf{X}'\mathbf{W}\mathbf{X})^{-1}\mathbf{X}'\mathbf{W}\mathbf{y}.
s diagonálnou váhovou maticou \mathbf{W}, kde vo všeobecnosti W_{ii}=1/\sigma_i^2. Pre lepšiu numerickú stabilitu sa váhy na diagonále zvyknú preškálovať ich strednou hodnotou alebo inou konštantou, čo v prípade priemerovaných pozorovaní často vedie ku W_{ii}=n_i.
2.6.4 Odľahlé pozorovania
Odľahlé pozorovanie (outlier) je bod v ktorom je hodnota odozvy nezvyčajne ďaleko od predpovede modelu.
Vznikajú z rôznych dôvodov, napr. omylom pri zázname merania.
Odľahlé pozorovania nemusia mať výrazný vplyv na odhad parametrov modelu (ak nevytvárajú pákový efekt). Nezvyknú mať ani netypické hodnoty prediktorov. Avšak spôsobujú iné problémy, napr. zvýšením RSS dôjde k rozšíreniu konfidenčných intervalov, zvýšeniu p-hodnoty testov významnosti či zníženiu R^2.
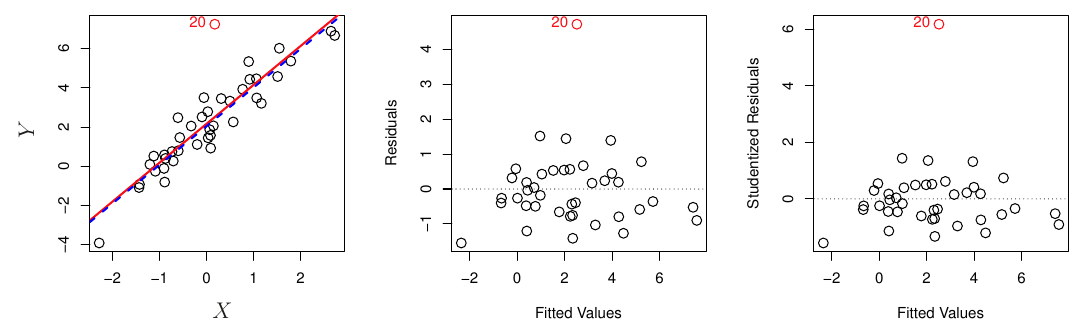
Identifikovať sa dajú z grafu rezíduí, ale ešte lepšie z rezíduí normovaných vlastnou štandardnou odchýlkou (studentized residuals), pretože potom stačí podozrivú hodnotu porovnať s kvantilom t-rozdelenia zodpovedajúcim nejakej vysokej pravdepodobnosti, najčastejšie sa nahrubo porovná s hodnotou 3.
Ak outlier považujeme za omyl pri zázname, je vhodné ho jednoducho zo súboru pozorovaní vylúčiť. Avšak pozor, môže indikovať aj slabinu modelu, ako napr. chýbajúci prediktor.
TipIlustrácia (outlier)
2.6.5 Pákový efekt
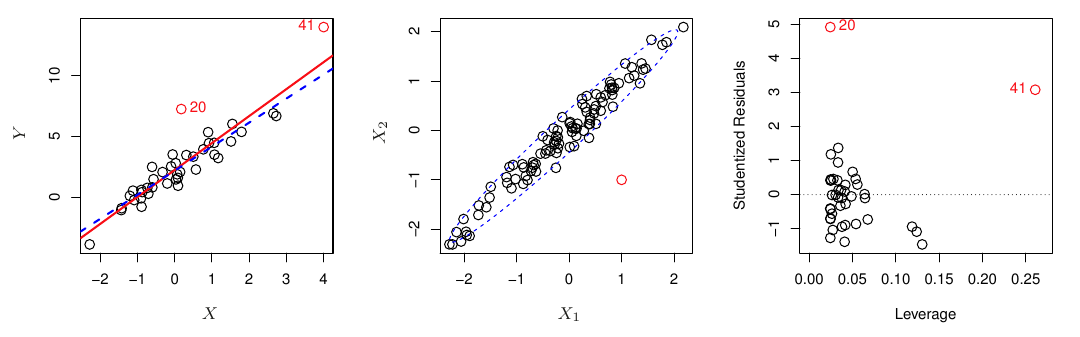
Oproti pozorovaniam s odľahlou hodnotou odozvy z predošlej časti, pozorovania s veľkým pákovým vplyvom (leverage effect) na odhad modelu sú tie, ktoré majú odľahlé hodnoty prediktorov.
V jednoduchej regresii je identifikácia takých bodov jednoduchá (v nasledujúcej ilustrácii na obrázku vľavo).
Vo viacnásobnej regresii sa však nemusia prejaviť nezvyčajnou hodnotou jednotlivých prediktorov (obr. v strede) a vo vyšších rozmeroch na odhalenie nestačia ani grafické nástroje.
Preto je užitočné vypočítať mieru pákového efektu (leverage statistics, obr. vpravo). Vo všeobecnosti je definovaná ako miera vplyvu odozvy i-teho pozorovania na predikciu,
h_i = \frac{\partial\hat y_i}{\partial y_i}
\tag{2.3}
V kontexte jednoduchej regresie sa vypočíta zo vzťahu
h_i = \frac1n + \frac{(x_i-\bar{x})^2}{\sum_{k=1}^n(x_k-\bar x)^2} \ ,
z korého vidieť, že h_i\in[\frac1n,1] a závisí od vzdialenosti hodnoty prediktora od jeho priemeru.
Pri viacnásobnej regresii pákovú štatistiku vyjadríme ako diagonálny prvok orto-projekčnej matice \mathbf{H} (hat matrix). Ak na lineárny regresný model pozeráme ako na špeciálny prípad lineárneho vyhladzovania (čiže váženého priemeru, kde váhy závisia od prediktorov),
\hat{\mathbf{y}} = \mathbf{X}\hat{\boldsymbol\beta} = \underbrace{ \mathbf{X}(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}' }_\mathbf{H}\ \mathbf{y}
potom práve \mathbf{H} je tá matica, ktorá obsahuje váhy. Takže znovu, vezmúc do úvahy všeobecnú definíciu (2.3), potom
h_i = \{\mathbf{H}\}_{ii}
Súčet diagonálnych prvkov sa rovná počtu parametrov (stupňov voľnosti lineárneho modelu), df\equiv tr(\mathbf{H}) = p+1.
Podľa jednoduchého zaužívaného pravidla má i-te pozorovanie výrazný pákový efekt vtedy, keď h_i>2\frac{p+1}n.
Alternatívne sa na identifikáciu dá použiť tzv. Cookova vzdialenosťD_i = \frac{\hat\varepsilon_i^2}{(p+1)\hat\sigma_i^2}\left[\frac{h_i}{(1-h_i)^2}\right] ktorá indikuje pákový efekt ak (pre veľké n) D_i>1.
PoznámkaIlustrácia (leverage)
- Z obrázku vpravo vidno, že bežný outlier (bod 20) nemá výrazný pákový efekt, naopak bod 41 je odľahlý nielen v odozve ale i hodnotou prediktoru, čo je výrazne riziková kombinácia pre vznik pákového efektu.
2.6.6 Kolinearita
Kolinearita predstavuje situáciu, keď dva alebo viac prediktorov navzájom spolu úzko súvisia.
Lineárnu regresiu komplikuje preto, lebo je náročné oddeliť efekt jednotlivých premenných na odozvu.
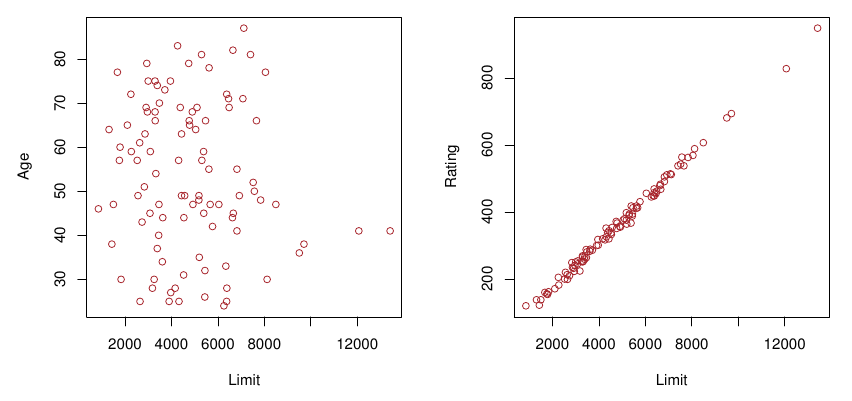
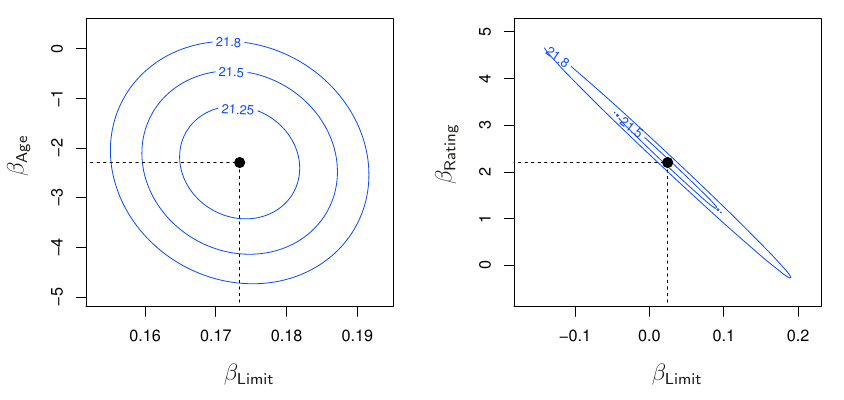
TipPríklad (kreditky)
Modelujme zadĺženie (balance) držiteľov kreditnej karty pomocou premenných ako vek (age), povolené prečerpanie (limit) a odhad schopnosti splácať úver (credit rating).
Zatiaľčo prvé dva prediktory spolu takmer nekorelujú, posledné dva sú korelované takmer dokonale.
Ako sa to prejaví na modelovaní súvislosti dlhu a jednotlivých dvojíc? Na nasledujúcom obrázku je zobrazenie oboch modelov v priestore parametrov (v rozsahu 4\cdot SE(\beta)) s izočiarami RSS.
Vľavo je optimum jednoznačne určené bodom (0.173, -2.3), avšak vpravo vidieť celé údolie bodov s hodnotami RSS blízko minimu. To znamená vyššiu citlivosť na súbor údajov, ked malá zmena v pozorovaných údajoch spôsobí veľkú zmenu v odhadoch parametrov (pozdĺž toho údolia) a to až do takých hodnôt, napr. (-0.1, 4), ktoré by sme sotva očakávali (a dokázali interpretovať).
Kolinearita teda redukuje presnosť odhadu parametrov, t.j. zvyšuje ich štandardnú chybu a znižuje testovaciu štatistiku v t-teste významnosti, takže menej často (než v 95%) dokážeme zamietnuť nulovú hypotézu H_0\colon\beta_j=0 keď v skutočnosti neplatí – tzn. znižuje silu testu.
Dôležitosť významných prediktorov je tak v dôsledku kolinearity zamaskovaná, ťažšie odhaliteľná.
Jednoduchým spôsobom detekcie kolinearity je pohľad na korelačnú maticu prediktorov. Ten žiaľ nefunguje v prípade kolinearity troch a viac premenných, teda multikolinearity.
Istejšou cestou je výpočet tzv. faktoru inflácie rozptylu (variance inflation factor, VIF), ktorý predstavuje pomer rozptylu parametra \beta_j v plnom modeli ku rozptylu v modeli, kde je \beta_j jediným prediktorom.
Najnižšou možnou hodnotou VIF je 1 (žiadna kolinearita). Zaužívaným pravidlom je spozornieť, keď VIF prekročí hodnotu 5 alebo 10.
Prakticky sa vypočíta pomocou vzťahu
VIF(\hat\beta_j) = \frac{1}{1-R_{X_j|X_{-j}}^2}
kde R_{X_j|X_{-j}}^2 je koeficient determinácie regresného modelu závislosti X_j od ostatných prediktorov. Ten bude v prítomnosti kolinearity blízko 1, takže VIF veľmi narastie.
Na kolinearitu sú dve jednoduché riešenia:
vynechať z regresie jednu z problémových premenných (keďže je z hľadiska informačnej hodnoty nadbytočná),
skombinovať korelujúce premenné do jedného (no stále ešte interpretovateľného) prediktoru.
Na začiatku sme si ako analytici položili sedem otázok. Teraz, s novými znalosťami ich vieme zodpovedať:
Existuje vzťah medzi rozpočtom na reklamu a odbytom?
Viacnásobnou regresiou a výpočtom vysokej hodnoty F-štatistiky (nízkej p-hodnoty) sme získali dôkaz o ich vzťahu.
Aký je silný?
Podľa R^2 taký model vysvetľuje takmer 90% variability odbytu.
Ktoré médiá sú za to zodpovedné?
Testy významnosti parametrov modelu ukazujú na reklamu v TV a rádiu.
Aký silný je ich vzťah (z hladiska reklamy) ku odbytu?
Interval spoľahlivosti ukazuje na zmenu v odbyte medzi 43 až 49 jednotiek v prípade TV a medzi 172 až 206 jednotiek v prípade rádia s každou zmenou rozpočtu na reklamu (v danom médiu) o 1,000 USD.
Ako presne dokážeme predpovedať odbyt?
Ak chceme predpovedať odbyt v konkrétnom meste, použijeme predikčný interval. Naopak, na určenie neistoty predpovede strednej hodnoty (priemerný odbyt na všetkých trhoch) je potrebný konfidenčný interval.
Je vôbec ich vzťah lineárny?
Pomocou grafu pozorovaných vs. predpovedaných hodnôt sme zistili, že lineárny regresný model (a predpoklad aditivity) je nedostačujúci …
Nie je medzi médiami synergia?
… pretože prediktory pôsobia v pozitívnej interakcii. S rastom rozpočtu pre TV rastie efekt rádia na odbyt (aj v opačnom poradí). Po rozšírení modelu súčinovou bázovou funkciou nie je v grafe rezíduí badať už žiaden podozrivý, systematický vzorec správania, a aj R^2 vzrástlo z 90% na takmer 97%.
 - Z obrázku vpravo vidno, že bežný outlier (bod 20) nemá výrazný pákový efekt, naopak bod 41 je odľahlý nielen v odozve ale i hodnotou prediktoru, čo je výrazne riziková kombinácia pre vznik pákového efektu.
- Z obrázku vpravo vidno, že bežný outlier (bod 20) nemá výrazný pákový efekt, naopak bod 41 je odľahlý nielen v odozve ale i hodnotou prediktoru, čo je výrazne riziková kombinácia pre vznik pákového efektu.