deviancia (cross-entropy) obsahuje logaritmus odhadu pravdepodobnosti iba pre pozorovanú triedu
D = -\sum_{i=1}^n\sum_{k=1}^K I(y_i=c_k)\log\hat{Pr}(\hat y_i=y_i)
takže obzvlášť trestá za nízke hodnoty.
Vo všeobecnosti sa delia podľa typu predpovedí, teda či sa počítajú
z predpovedí samotných hodnôt odozvy (hard predictions),
alebo ich pravdepdobnosti (soft predictions).
9.2 Klasifikačná matica a celková chyba
Namiesto jediného súhrnného čísla môže byť užitočnejšie zobraziť maticu počtu prípadov správnej a nesprávnej klasifikácie, tzv. confussion matrix\mathbf{S}
y
1
2
3
1
s_{11}
s_{12}
s_{13}
\hat{y}
2
s_{21}
s_{22}
s_{23}
3
s_{31}
s_{32}
s_{33}
pričom prvky s_{jk}=\sum_{i=1}^nI(\hat{y_i}=c_j)I(y_i=c_k) predstavujú početnosti v jednotlivých situáciách. Prirodzene platí s_{jk}\geq0 a tiež \sum_{j,k} s_{jk} = n.
Dokonalý klasifikátor má nenulové prvky iba na hlavnej diagonále.
Celková klasifikačná chyba sa vypočíta ako podiel súčtu mimo-diagonálnych a všetkých prvkov
ER = 1 - \frac{\sum_ks_{kk}}{n} = \frac{\sum_{j\neq k}s_{jk}}{n}
Člen \frac{\sum_ks_{kk}}{n} sa označuje ako celková presnosť klasifikáce (accuracy).
Ak ER < 0.5, potom model je úspešnejší ako náhodné hádanie.
Zdalo by sa, že najlepší model je ten, ktorý má najvyššiu celkovú presnosť. To však neplatí, ak
sú početnosti tried rôzne. Vtedy sa môže stať, že konštantný model (predpovedá iba najpočetnejšiu triedu) je “celkovo” presnejší ako nejaký sofistikovanejší model.
triedy nemajú rovnakú váhu. Napr. banka viac stratí na neplatičovi než získa na úrokoch od platiaceho klienta, preto jej záleží na dobrej klasifikácii menej častých prípadov.
Problém s nevyváženým počtom tried rieši Cohenovo kappa, \kappa\in[-1,1], ktoré sa v aplikáciách používa hlavne ako miera zhody dvoch hodnotiteľov. Je definovaná vzťahom
\kappa = \frac{p_o-p_e}{1-p_e}
kde
p_o = \frac1n\sum_ks_{kk} je relatívna početnosť prípadov, kedy došlo ku zhode (“o” ako “observed”),
p_e = \frac1{n^2}\sum_k s_{k\boldsymbol\cdot}s_{\boldsymbol\cdot k} je relatívna početnosť hypotetických prípadov, kedy by došlo ku zhode, ak by bol klasifikátor úplne náhodný (“e” ako “expected”). Člen s_{k\boldsymbol\cdot}=\sum_j s_{kj} je riadkový súčet, analogicky je definovaný aj stĺpcový súčet s_{k \boldsymbol\cdot} = \sum_k s_{kj}.
Hodnota \kappa=0 predstavuje nezávislosť (náhodné tipovanie), zatiaľčo \kappa=1 dokonalú zhodu.
Pri druhom probléme – rozdielnej dôležitosti tried – je potrebné chyby špecifikovať podľa záujmu/zamerania klasifikačnej úlohy.
9.3 Špecifické chyby
Z klasifikačnej matice sa dá vyvodiť niekoľko špecifických mier presnosti, jednoduchšie však bude ukázať ich na prípade binárnej odozvy, ktorá indikuje nastatie nejakej udalosti (+/-), napr. splatenie pôžičky klientom banky.
y
(+)
(–)
\hat{y}
(+)
True Positive
False Positive
(–)
False Negative
True Negative
Samozrejme celková presnosť sa potom vyjadrí vzťahom accuracy = \frac{TP+TN}{n}.
Špecifické miery presnosti klasifikátora:
precision = \frac{TP}{TP+FP} predstavuje podmienenú pravdepodobnosť Pr[Y=\oplus|\hat Y=\oplus].
false negative rate FNR = 1-TPR=\frac{FN}{TP+FN} je doplnkom ku TPR, podobne
false positive rate FPR=1-TNR=\frac{FP}{TN+FP}.
Ideálne by sme chceli klasifikátor, ktorý zároveň minimalizuje FPR aj FNR, problém je však v tom, že sa to nedá – so zvyšovaním senzitivity sa znižuje špecificita a naopak. Je potrebný kompromis.
Pozn.: Príkladom binárnej klasifikácie je aj testovanie štatistických hypotéz. Ak platnosť H_0 zodpovedá kladnej hodnote odozvy, potom chyba I druhu (\alpha, zamietnutie platnej H_0) zodpovedá FNR, a chyba II druhu (\beta, prijatie neplatnej H_0) zodpovedá FPR. Aj tu platí nepriama úmernosť medzi oboma chybami. Keďže sa \alpha zvykne zafixovať (najčastejšie na 5%), je výhodné použiť taký štatistický test, ktorý má čo najnižšiu chybu \beta, t.j. čo najväčšiu silu (1-\beta). (Napr. parametrické testy majú väčšiu silu, ak sú splnené predpoklady - zväčša o normalite údajov.)
9.4 ROC krivka
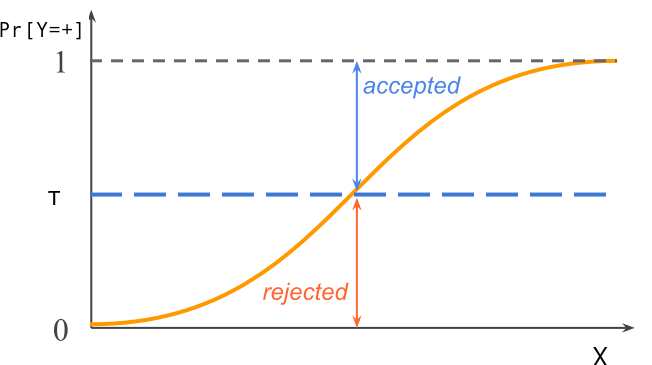
Kompromis medzi FPR a FNR závisí na voľbe rozhodovacieho pravidla - konkrétne na voľbe hraničnej pravdepodobnosti \tau, po ktorú je bod zaradený do jednej triedy a od ktorej je už zaradený do druhej triedy.
V príklade s rozhodnutím, či poskytnúť alebo neposkytnúť pôžičku, voľba \tau=0.5 z pohľadu banky nedáva veľký zmysel, pretože poskytnutie pôžičky so sebou prináša vyššie riziko než je zisk z úrokov. Banka teda pre ochranu svojich záujmov radšej zodvihne hranicu, napr. na \tau=0.7.
Samozrejme v inom scenári je lepšie zvoliť nižšie hodnoty prahovej hodnoty \tau.
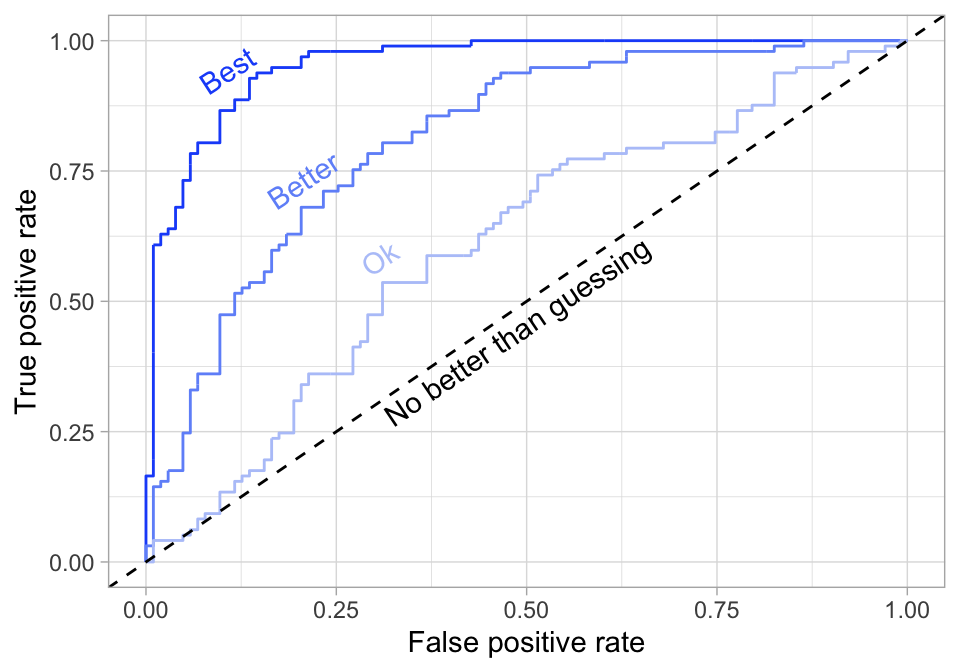
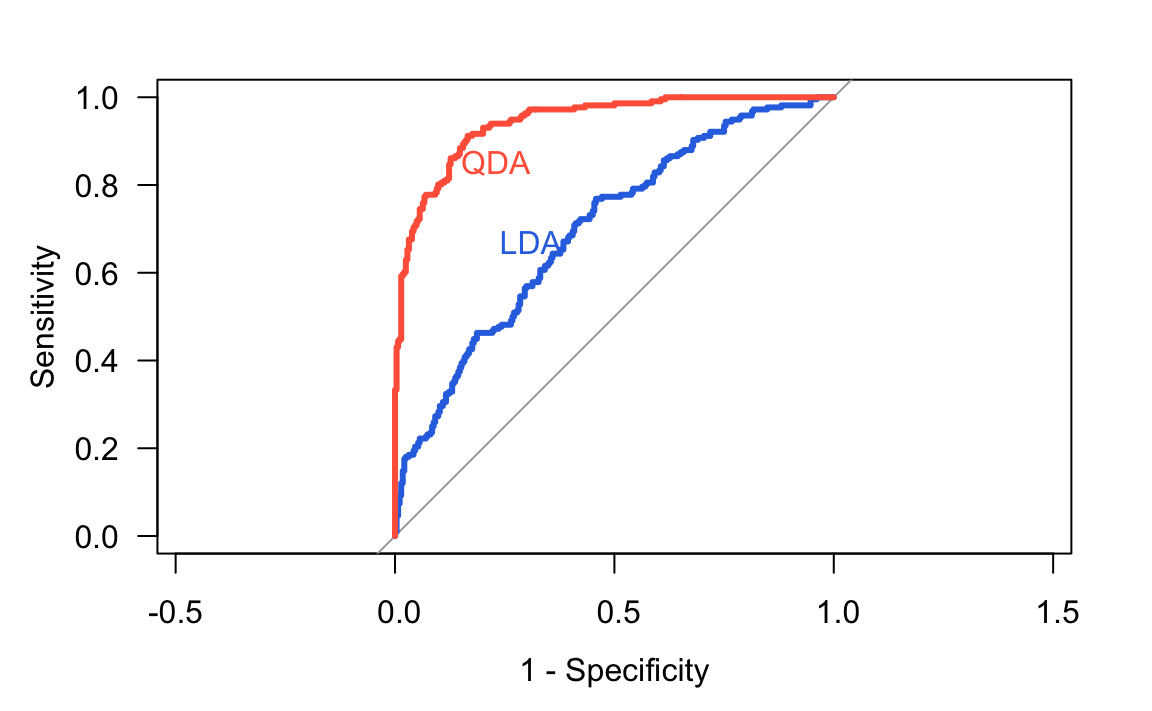
S rozhodnutím, aké \tau zvoliť, pomáha tzv. ROC krivka (Receiver Operating Characteristic, názov pochádza z prvej aplikácie v obsluhe vojenského radarového prijímača). Znázorňuje vzťah medzi TPR a FPR.
9.5 Plocha pod ROC krivkou
Čím je model úspešnejší v súčasnej minimalizácii FNR a FPR, tým je ROC krivka vypuklejšia smerom ku rohu [0,1].
Plocha pod krivkou (area under the curve, AUC) tak slúži ako miera úspešnosti klasifikačného modelu.
Hodnota plochy
0 zodpovedá dokonale neúspešnému modelu,
1/2 hádaniu (náhodnému tipovaniu, hodu mincou),
1 dokonalej klasifikácii.
Ak má odozva viac hodnôt, klasifikačný model sa dá vyhodnotiť dvoma spôsobmi, a to výpočtom ROC/AUC pre jednu triedu voči
ostatným triedam (One-vs-Rest),
inej triede (One-vs-One).
Súhrnná AUC je potom už len priemerom z jednotlivých kombinácií.
9.6 Príklady
TipPríklad (kreditky)
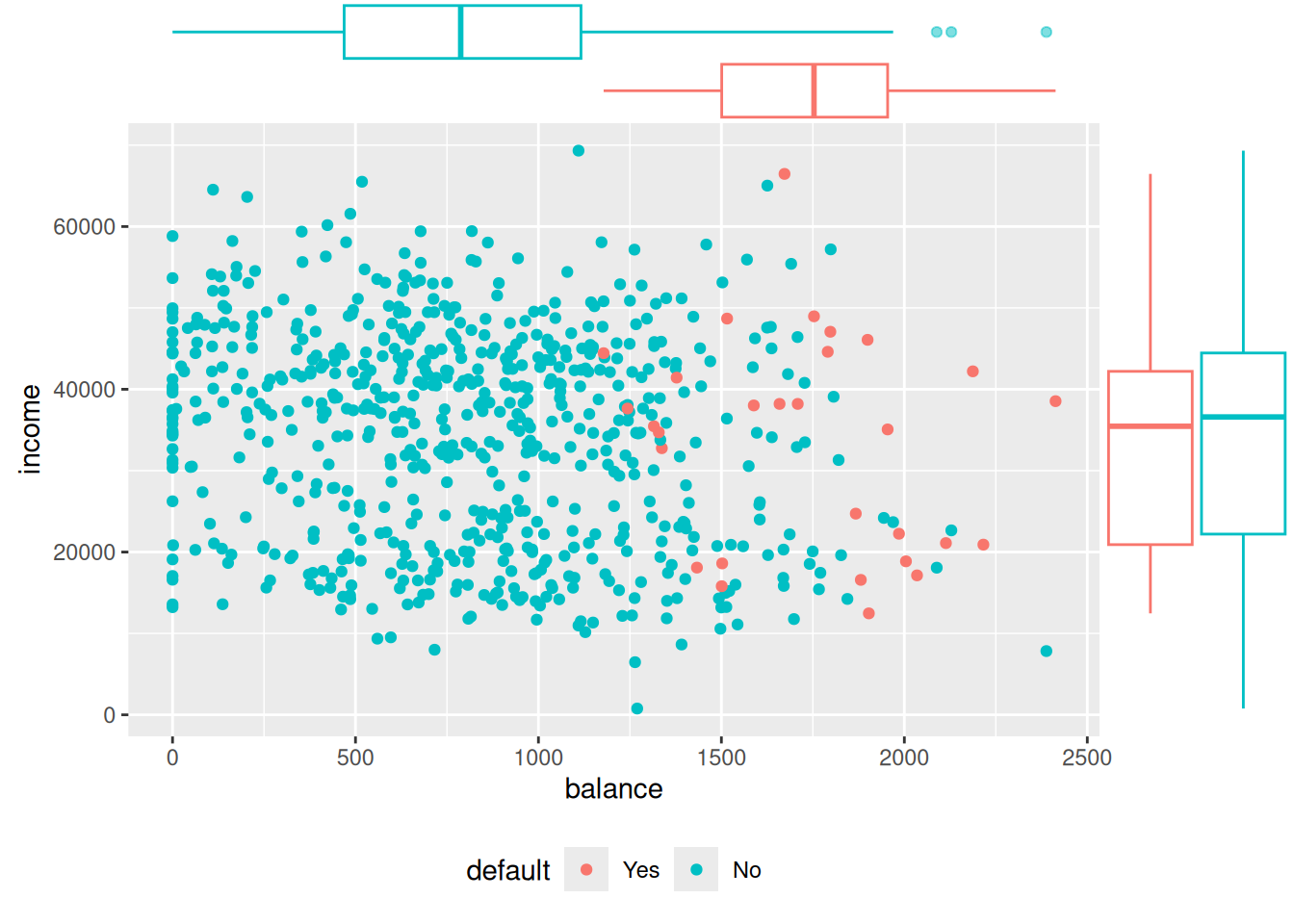
Zo (simulovaného) datasetu ISLR2::Default použijeme záznamy o 1000 klientoch banky na predpovedanie, či držiteľ kreditnej karty zlyhá v splácaní svojho dlhu (premešká lehotu splatnosti, angl. default on payment).
fit <-list(LogisR =glm(default ~ balance + income, dat$train, family = binomial) )fit$LogisR |>summary()
Call:
glm(formula = default ~ balance + income, family = binomial,
data = dat$train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.112e+01 1.468e+00 -7.576 3.56e-14 ***
balance 5.300e-03 7.400e-04 7.163 7.91e-13 ***
income 3.110e-05 1.703e-05 1.826 0.0678 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 240.85 on 692 degrees of freedom
Residual deviance: 132.59 on 690 degrees of freedom
AIC: 138.59
Number of Fisher Scoring iterations: 8
Zdá sa, že ani model nenašiel veľmi užitočnú informáciu vo výške príjmu. Okrem toho je badať, že disperzia je modelom mierne nadhodnotená (under-dispersion). Použitie kvázi-binomického rozdelenia by vplyv income trochu zvýraznil (klesol by odhad štandardnej chyby), avšak na hladine významnosti 5% by jeho parameter stále nemusel byť odlíšiteľný od nuly.
Pre prahovú hodnotu pravdepodobnosti \tau=0.5 vypočítajme klasifikačnú maticu, hodnoty celkovej presnosti a bod na ROC krivke.
Kód
prob <-data.frame(LogisR = fit$LogisR |>predict(newdata = dat$eval, type ="response") ) pred =list(LogisR =ifelse(prob$LogisR >0.5, "Yes", "No") |>factor() ) # confusion matixcm <-data.frame(predicted = pred$LogisR, true = dat$eval$default) |> purrr::map_df(relevel, ref ="Yes") |># iba kvôli zoradeniutable()cm
true
predicted Yes No
Yes 6 2
No 4 295
Kód
# celková presnosťaccuracy_kappa <-function(cmatrix) { n <-sum(cmatrix) pO <-sum(diag(cmatrix)) / n pE <-sum(rowSums(cmatrix) *colSums(cmatrix)) / (n^2)c(accuracy = pO,kappa = (pO-pE)/(1-pE) )}# bod na ROC krivke pre roc <-function(cmatrix) {c(TPR = cmatrix["Yes","Yes"]/sum(cmatrix[,"Yes"]),FPR = cmatrix["Yes","No"]/sum(cmatrix[,"No"]) )}c(accuracy_kappa(cm), roc(cm) ) |>round(4) |>rbind("tau=0.5: "= _)
James, Witten, Hastie, Tibshirani (2021): An Introduction to Statistical Learning - with Applications in R. 2nd ed. Springer. https://www.statlearning.com/
Kuhn, M., Johnson, K. (2019). Feature engineering and selection: A practical approach for predictive models. CRC Press. https://bookdown.org/max/FES/measuring-performance.html#class-metrics
Sanchez, G., Marzban, E. (2020) All Models Are Wrong: Concepts of Statistical Learning. https://allmodelsarewrong.github.io/classperformance.html#classification-error-measures