Kód
# libraries
library(ggplot2)
library(tsibble) # needs to be loaded with ggplot
# containers:
# dat - datasets in tabular form
# fit - fitted models objects
# fore - forecasts
dat <- fit <- fore <- list()# libraries
library(ggplot2)
library(tsibble) # needs to be loaded with ggplot
# containers:
# dat - datasets in tabular form
# fit - fitted models objects
# fore - forecasts
dat <- fit <- fore <- list()Časové rady v tzv. “tidy” (čistom/poriadnom) prístupe sú reprezentované tabuľkou údajov, v ktorej minimálne jeden stĺpec predstavuje časovú premennú. Dáta by teda už nemali byť vo forme vektora s časovým atribútom (objekt typu ts). Ekosystém balíkov tidyverts bol inšpirovaný ekosystémom tidyverse. Pre podrobnosti o analýze časových radov s praktickými ukážkami týmto prístupom pozri online učebnicu Hyndman a Athanasopoulos (2021). Zvlášť o modelovaní časových radov pomocou balíku fable (súčasť tidyverts) hovorí prehľadný návod Tidy time series forecasting with fable.
Dataset obsahuje dva stĺpce, v prvom je poradové číslo dňa, v druhom relatívna zmena polohy bodu v milimetroch (v severnej súradnici topocentrického systému) oproti prvému dňu. Pretože nie je k dispozícii údaj o roku merania, nastavíme počiatok na začiatok roku 2021. Dĺžka časového radu je 730 dní, čiže dva nepriestupné roky.
dat$all <- "data/Poloha_denne.dat" |> # source data file
read.table(header=T, skip = 1) |> # load, skip description line
setNames(c("time", "observed")) |>
dplyr::mutate(time = as.Date(time, origin = "2020-12-31")) |>
as_tsibble(index = time, key = NULL)
head(dat$all)# A tsibble: 6 x 2 [1D]
time observed
<date> <dbl>
1 2021-01-01 0
2 2021-01-02 -1.4
3 2021-01-03 0.3
4 2021-01-04 -0.2
5 2021-01-05 1.1
6 2021-01-06 0.5Dataset je uložený v objekte triedy tbl_ts (tsibble)1, kde jedna premenná (stĺpec) vystupuje v roli časového indexu. Ak je prítomná aj kategorická premenná, tá zvyčajne predstavuje tzv. key variable, čiže príslušnosť pozorovania do nejakej triedy (tu napríklad by to mohlo byť označenie sledovaného bodu). Všetky ostatné stĺpce v tsibble predstavujú náhodné premenné.
Číselný súhrn:
dat$all |>
tibble::as_tibble() |> # to enable summarizing over time
dplyr::summarize(across(
observed,
.fns = list(length = length, min = min, max = max,
median = median, mean = mean, sd = sd),
.names = "{.fn}")) |>
dplyr::mutate(across(mean:sd, ~round(.x, 1)))# A tibble: 1 × 6
length min max median mean sd
<int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 730 -4.7 32.4 14.3 14 8.8Rozdelenie súboru na trénovaciu a validačnú vzorku:
dat$all <- dat$all |>
dplyr::mutate(sample = ifelse(time < "2022-08-01", "train", "valid"))
dat$train <- dat$all |> dplyr::filter(sample == "train")
dat$valid <- dat$all |> dplyr::filter(sample == "valid")Zobrazenie tabuľky časových radov (tsibble) zjednodušuje generická funkcia ggplot2::autoplot s metódou definovanou balíkom fabletools.
dat$all |>
fabletools::autoplot(observed) + aes(color = sample) +
theme(legend.position = "inside", legend.position.inside = c(0.9,0.2)) +
scale_color_manual(values = c(train = 1, valid = 2))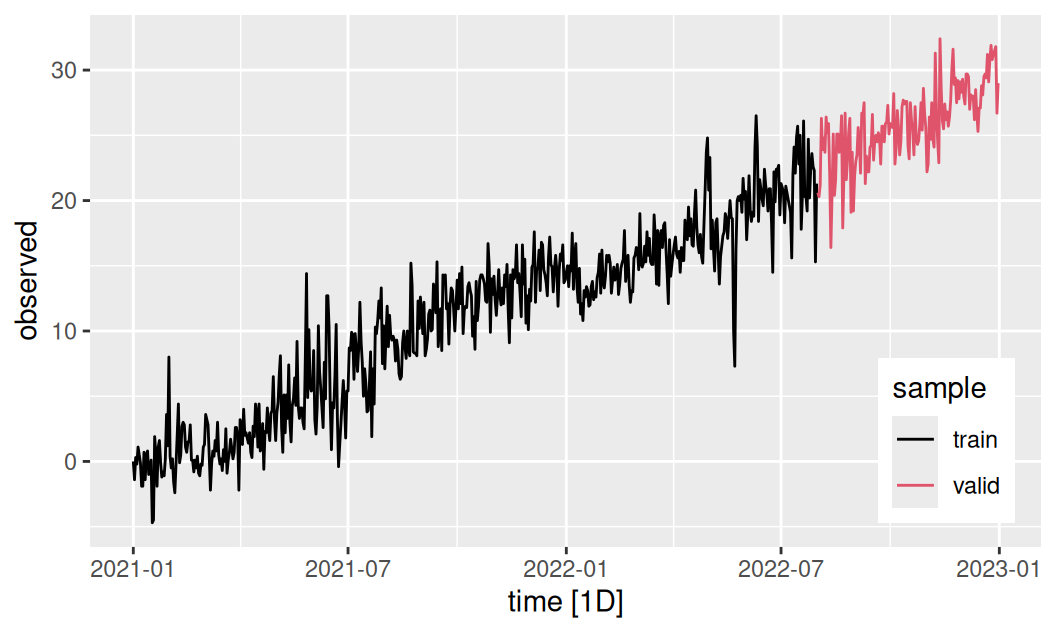
Na trénovacej vzorke identifikujeme a odhadneme modely jednotlivých zložiek stochastického procesu a pomocou validačnej posúdime presnosť predpovedí.
Keďže je časový rad stacionárny v rozptyle, dekompozícia bude aditívna.
Prieskumná dekompozícia adaptívnou metódou na trend, sezónnu zložku a rezíduá nie je kvôli vysokej perióde sezónnej zložky možná, napr. ani pomocou feasts::classical_decomposition. Ideme teda rovno na regresnú metódu izolácie zložiek časového radu.
Lineárny trend je zrejme jediný vhodný typ trendu.
fit$trend <- dat$train |>
fabletools::model(
linear = fable::TSLM(observed ~ trend())
)Funkcia trend() zatiaľ neumožňuje iný ako lineárny a po častiach lineárny trend (pozri položku common_xregs v nápovede ku balíku fable). Polynomický či logistický trend možno nájsť v balíku prophet.
Uložený objekt je triedy mdl_df, preto sa nazýva aj “mable”, respektíve “model table”.
fit$trend |> class()[1] "mdl_df" "tbl_df" "tbl" "data.frame"Jednoduchý pohľad na tento dátový objekt veľa neprezradí, pretože obsahuje iba jediný riadok – podľa počtu hodnôt kľúčovej premennej, ktorú v našom prípade nemáme. Stĺpce sú pomenované podľa modelov, v našom prípade je opäť iba jeden. Vďaka tabuľkovému tvaru sa však s objektom mable dá ľahko manipulovať, najmä s pomocou viacerých nástrojov balíku dplyr ako napr. bind_cols, select či filter.
fit$trend# A mable: 1 x 1
linear
<model>
1 <TSLM>Užitočný náhľad poskytne generická funkcia glance (so zodpovedajúcou metódou v balíku fabletools), vďaka ktorej sa odhadnuté modely dajú porovnať (r_squared, AIC,…). V našom prípade nie je čo porovnávať, pretože máme jediný model.
fit$trend |> generics::glance()# A tibble: 1 × 15
.model r_squared adj_r_squared sigma2 statistic p_value df log_lik AIC
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <dbl> <dbl>
1 linear 0.882 0.882 5.72 4308. 2.86e-269 2 -1321. 1010.
# ℹ 6 more variables: AICc <dbl>, BIC <dbl>, CV <dbl>, deviance <dbl>,
# df.residual <int>, rank <int>Jeden model sa dá pozrieť detailnejšie (výsledok je zobrazený podobne ako z funkcie stats::summary.lm).
fit$trend |> dplyr::select(linear) |> fabletools::report()Series: observed
Model: TSLM
Residuals:
Min 1Q Median 3Q Max
-12.1102 -1.5468 -0.2216 1.5330 9.1560
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.5245108 0.1994289 -2.63 0.00877 **
trend() 0.0392415 0.0005979 65.64 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.392 on 575 degrees of freedom
Multiple R-squared: 0.8822, Adjusted R-squared: 0.882
F-statistic: 4308 on 1 and 575 DF, p-value: < 2.22e-16Generická funkcia augment (opäť s metódou vo fabletools) spojí dataset spolu s výsledkami odhadu modelov do jednej tabuľky (v dlhom formáte), takže sa modely dajú vizuálne porovnať.
fit$trend |>
generics::augment() |>
print() |> # just only to show intermediate result
ggplot(aes(x = time)) +
geom_line(aes(y = observed)) +
geom_line(aes(y = .fitted, colour = .model), linewidth = 1, show.legend = FALSE) +
scale_color_manual(values = c(linear = 4))# A tsibble: 577 x 6 [1D]
# Key: .model [1]
.model time observed .fitted .resid .innov
<chr> <date> <dbl> <dbl> <dbl> <dbl>
1 linear 2021-01-01 0 -0.485 0.485 0.485
2 linear 2021-01-02 -1.4 -0.446 -0.954 -0.954
3 linear 2021-01-03 0.3 -0.407 0.707 0.707
4 linear 2021-01-04 -0.2 -0.368 0.168 0.168
5 linear 2021-01-05 1.1 -0.328 1.43 1.43
6 linear 2021-01-06 0.5 -0.289 0.789 0.789
7 linear 2021-01-07 -0.1 -0.250 0.150 0.150
8 linear 2021-01-08 -1.9 -0.211 -1.69 -1.69
9 linear 2021-01-09 -1.9 -0.171 -1.73 -1.73
10 linear 2021-01-10 0.7 -0.132 0.832 0.832
# ℹ 567 more rows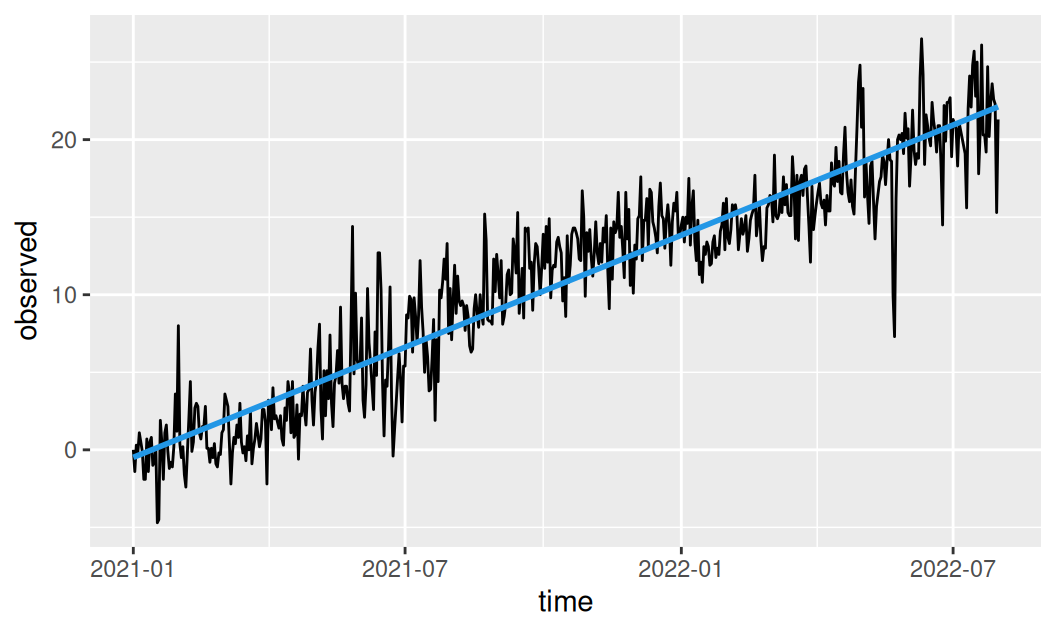
Odhadnuté rezíduá lineárneho trendu uložíme do dátového rámca trénovacej vzorky, aby sme v nich následne mohli hľadať sezónnu zložku. Prvý krok je potom zobrazenie korelogramu.
dat$train$resTlin <- fit$trend |>
dplyr::select(linear) |>
residuals() |> # tsibble residuals
dplyr::pull(".resid")dat$train |>
autoplot(resTlin)
dat$train |>
feasts::ACF(resTlin, lag_max = 500) |>
autoplot()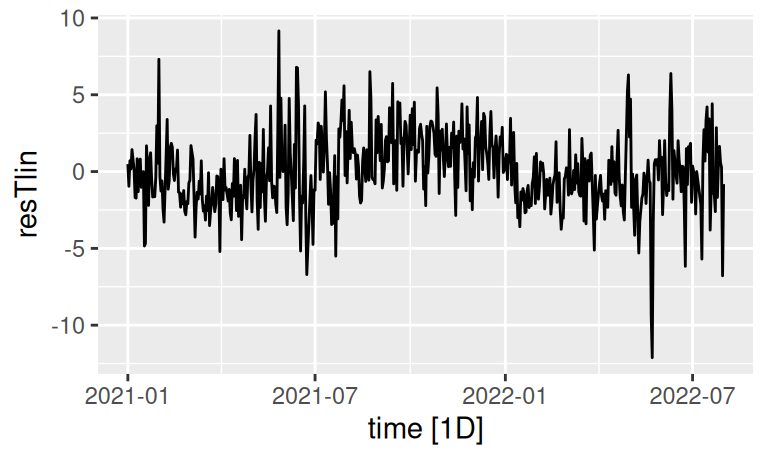
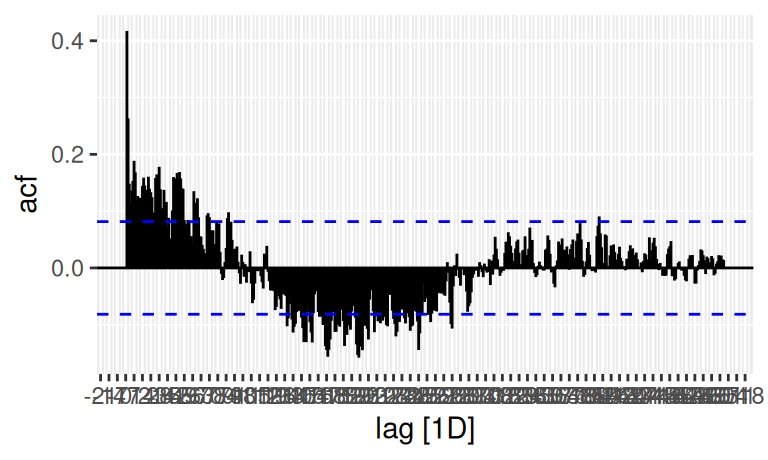
Z neho je zjavné to, že sezónna zložka s veľkou periódou je pomerne výrazná. Nemá zmysel ju modelovať pomocou indikátorových premenných (pretože model by mal 365 parametrov), vhodný je teda harmonický regresný model so základnou peródou \(L=365\) a súdiac podľa deformácie tvaru obyčajnej sinusoidy, bude treba minimálne jedna odvodená perióda, začneme s polovičnou, \(L=365/2\). Ak nie je postačujúca, spektrálny obraz rezíduí modelu sezónnej zložky nám to prezradí.
Vo funkcii TSLM slúži na konštrukciu harmonického regresoru sezónnosti funkcia fourier, dĺžku periódy je možné vyjadriť aj opisne. Parameter \(K\) určuje počet harmonických zložiek.
fit$seasonal <- dat$train |>
fabletools::model(
harmonic = fable::TSLM(resTlin ~ fourier(period = "1 year", K=2))
)Zbežný pohľad do reportu modelu prezradí, že obe harmonické zložky sú štatisticky významné:
fit$seasonal |> dplyr::select(harmonic) |> fabletools::report()Series: resTlin
Model: TSLM
Residuals:
Min 1Q Median 3Q Max
-11.6680 -1.2915 -0.0875 1.1557 9.5450
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.28686 0.09602 2.987 0.00293
fourier(period = "1 year", K = 2)C1_365 0.10714 0.13092 0.818 0.41350
fourier(period = "1 year", K = 2)S1_365 -1.43049 0.13983 -10.230 < 2e-16
fourier(period = "1 year", K = 2)C2_365 -0.09852 0.13065 -0.754 0.45109
fourier(period = "1 year", K = 2)S2_365 -0.29464 0.13473 -2.187 0.02915
(Intercept) **
fourier(period = "1 year", K = 2)C1_365
fourier(period = "1 year", K = 2)S1_365 ***
fourier(period = "1 year", K = 2)C2_365
fourier(period = "1 year", K = 2)S2_365 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.198 on 572 degrees of freedom
Multiple R-squared: 0.1603, Adjusted R-squared: 0.1544
F-statistic: 27.3 on 4 and 572 DF, p-value: < 2.22e-16Model vyzerá uspokojivo aj po vizuálnej stránke:
fit$seasonal |>
fabletools::augment() |>
ggplot(aes(x = time)) +
geom_line(aes(y = resTlin)) +
geom_line(aes(y = .fitted, colour = .model), linewidth = 1, show.legend = FALSE) +
scale_color_manual(values = c(harmonic = 4))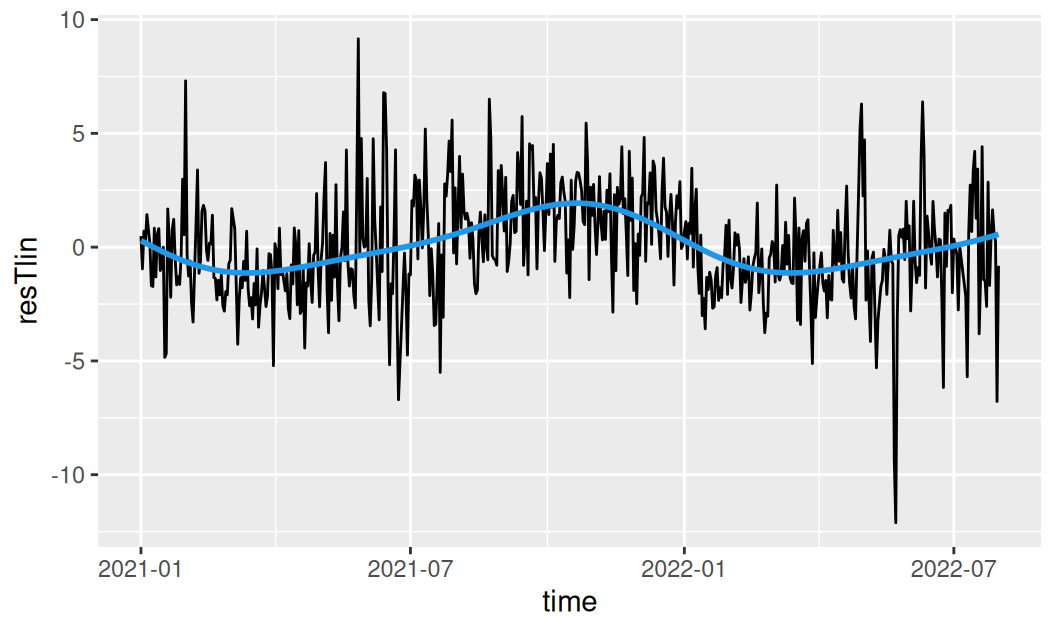
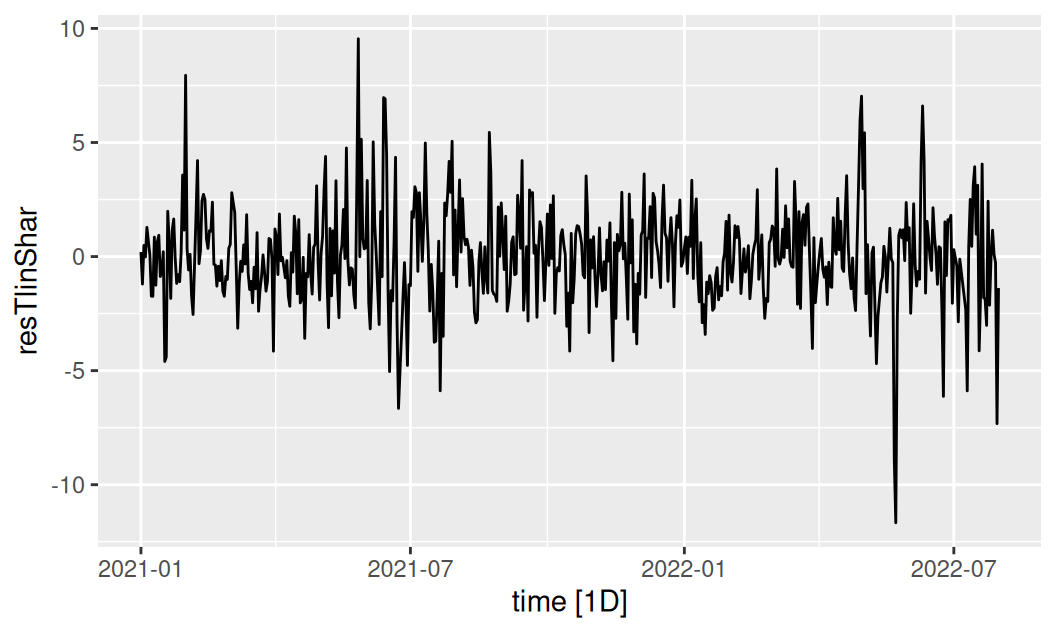
Zobrazíme rezíduá sezónneho modelu a ich spektrálnu hustotu.
dat$train$resTlinShar <- fit$seasonal |>
dplyr::select(harmonic) |>
residuals() |> # tsibble residuals
dplyr::pull(".resid")dat$train |> autoplot(resTlinShar)
tmp <- dat$train |>
with({
lomb::lsp(resTlinShar, type = "period", ofac = 10)
})
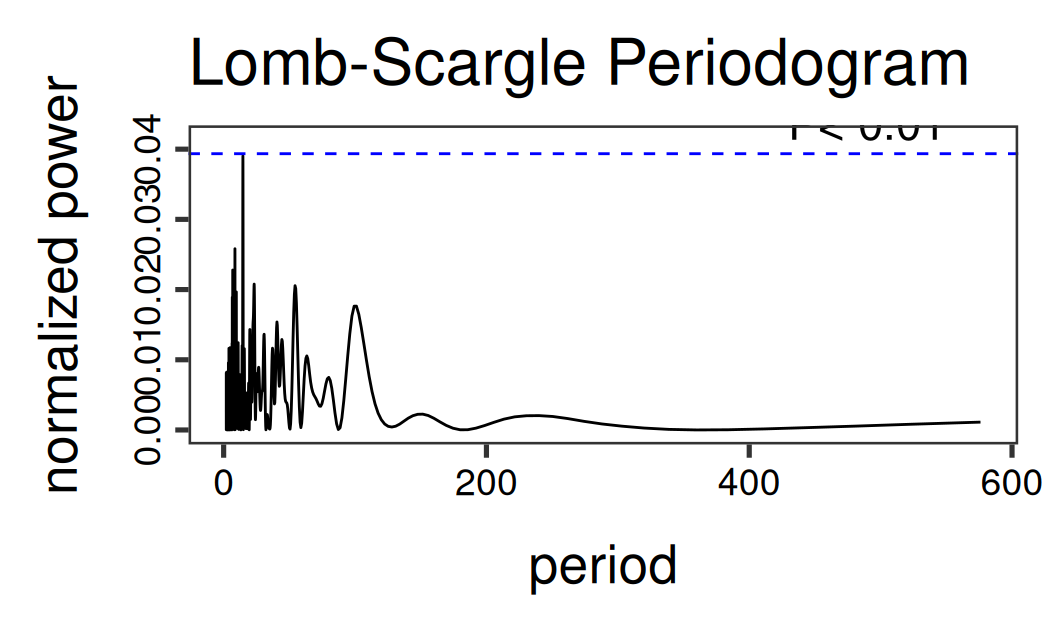
tmp$peak.at |> setNames(c("period", "frequency")) period frequency
14.65648855 0.06822917 Jediná podozrivá hodnota je okolo 15 dní, čo môže súvisieť so slapmi, no pre slabú intenzitu tento (iba potenciálny) signál zanedbáme. V opačnom prípade by sme iba pridali regresor fourier(period = 14.7, K=1) do formule funkcie TSLM.
Keďže cyklickú zložku neuvažujeme, model bude obsahovať iba trend a sezónnosť.
fit$systematic <- fabletools::model(
.data = dat$train,
TlinShar = fable::TSLM(resTlin ~ trend() + fourier(period = "1 year", K=2))
)fit$systematic |>
dplyr::select(TlinShar) |>
feasts::gg_tsresiduals()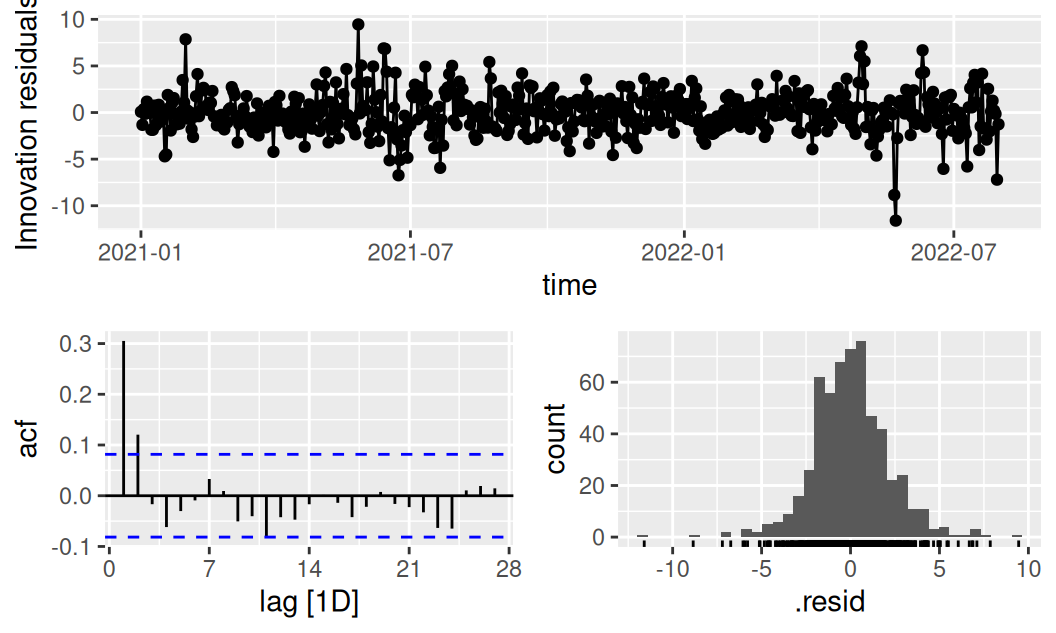
Rezíduá vyzerajú byť okrem autokorelácie do posunu \(k=2\) dni už náhodné. Významnosť autokorelácie súhrnne potvrdzuje aj Box-Pierce test.
fit$systematic |>
dplyr::select(TlinShar) |>
generics::augment() |>
fabletools::features(.resid, features = feasts::box_pierce, lag = 2)# A tibble: 1 × 3
.model bp_stat bp_pvalue
<chr> <dbl> <dbl>
1 TlinShar 62.1 3.28e-14Zvyšková korelácia síce nevychýli predpovede odhadnuté týmto modelom, no predpovedný interval bude širší. Aby sme využili aj informáciu obsiahnutú v rezíduách, je potrebné rozšíriť model systematických zložiek o lineárny model triedy ARMA.
Neparametrická identifikácia lineárneho procesu
dat$train |>
feasts::ACF(resTlinShar, lag_max = 10) |>
autoplot()
dat$train |>
feasts::PACF(resTlinShar, lag_max = 10) |>
autoplot()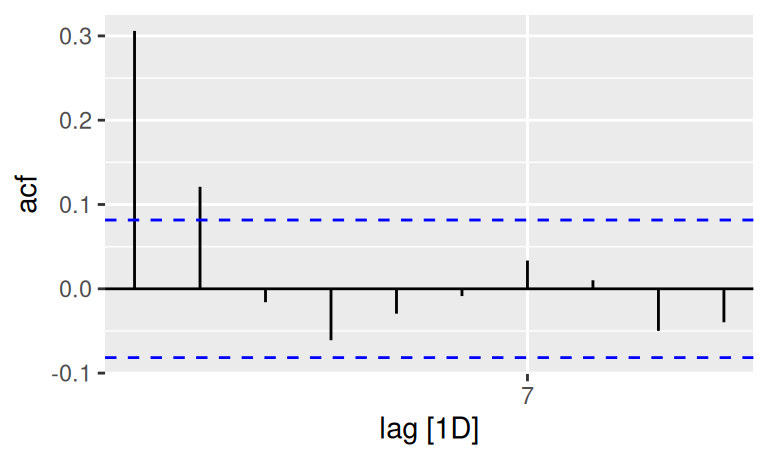
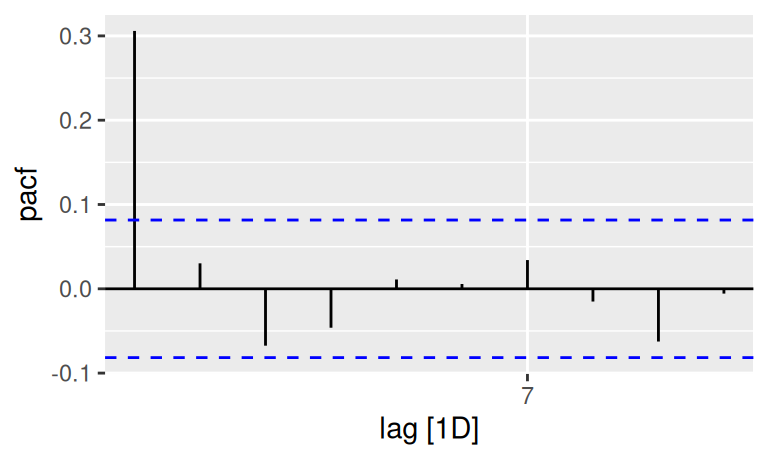
Pôjde o jednoduchý lineárny proces, buď AR(1) alebo nanajvýš MA(2) či ARMA (1,1).
fit$residual <- dat$train |>
fabletools::model(
#auto = fable::ARIMA(resTlinShar ~ pdq(d=0)), # will select AR(1)
ar1 = fable::ARIMA(resTlinShar ~ pdq(1,0,0)),
ma2 = fable::ARIMA(resTlinShar ~ pdq(0,0,2))
)
fit$residual |> generics::glance()# A tibble: 2 × 8
.model sigma2 log_lik AIC AICc BIC ar_roots ma_roots
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <list> <list>
1 ar1 4.35 -1242. 2489. 2489. 2497. <cpl [1]> <cpl [0]>
2 ma2 4.34 -1241. 2488. 2488. 2501. <cpl [0]> <cpl [2]>Neprekvapivo má model MA(2) najnižší reziduálny rozptyl (sigma^2) a aj podľa AIC by bol považovaný za vhodnejšieho kandidáta na finálny model reziduálnej zložky. Avšak podľa striktnejšieho kritéria BIC by nám mal stačiť aj model AR(1). Ten by bol zvolený aj automatickou procedúrou, ktorá sa aktivuje vtedy, keď pomocnej funkcii pdq neposkytneme všetky hyper-parametre (\(p,d,q\)), alebo naopak, zadáme viac hodnôt pre aspoň jeden hyper-parameter.
fit$residual |> dplyr::select(ar1) |> fabletools::report()Series: resTlinShar
Model: ARIMA(1,0,0)
Coefficients:
ar1
0.3055
s.e. 0.0396
sigma^2 estimated as 4.348: log likelihood=-1242.26
AIC=2488.51 AICc=2488.54 BIC=2497.23Z hodnoty jediného parametra je zjavné, že AR(1) model je stacionárny, ale môžeme to overiť aj funkciou. Zároveň overíme invertibilitu MA(2).
fit$residual |> feasts::gg_arma()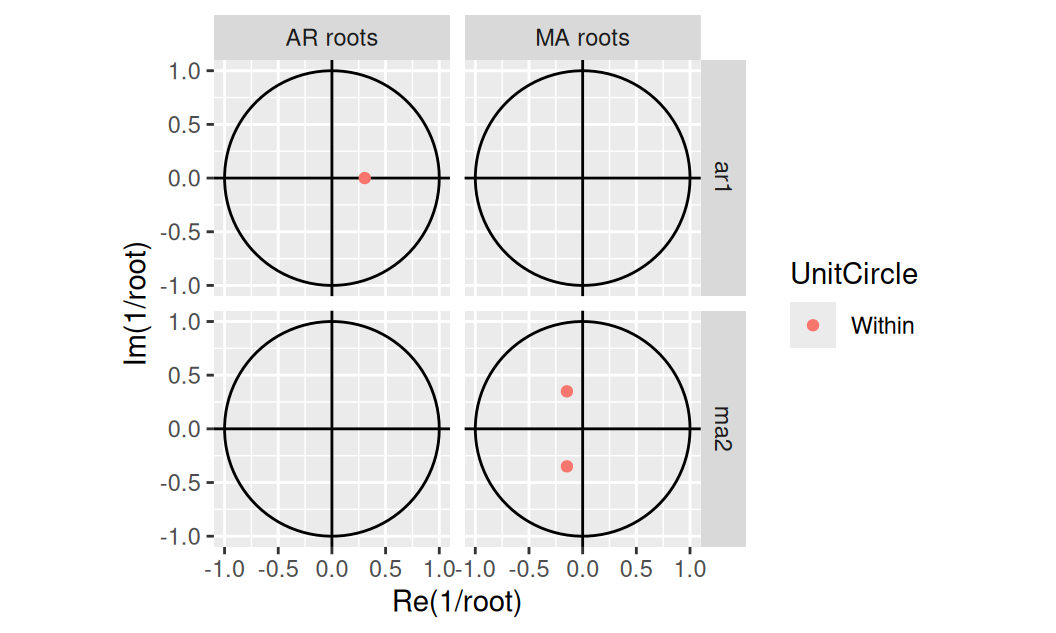
AR polynóm má jediný, reálny koreň, ktorý je zjavne väčší ako 1 (\(1/x<1\)). Podobne aj korene MA(2) polynómu sú mimo jednotkovej kružnice, takže proces je invertibilný.
Nakoniec zobrazíme MA(2) model reziduálnej zložky spolu s modelom systematických zložiek:
dat$train$Rma2 <- fit$residual |>
generics::augment() |>
dplyr::filter(.model == "ma2") |>
dplyr::pull(.fitted)
dat$train |>
ggplot(aes(x = time)) +
geom_line(aes(y = observed, color = "observed")) +
geom_line(aes(y = observed - resTlinShar + Rma2, colour = "model")) +
scale_color_manual(values = c(observed = 1, model = 4), name = "series") +
theme(legend.position = "inside", legend.position.inside = c(0.8,0.2)) +
ylab("")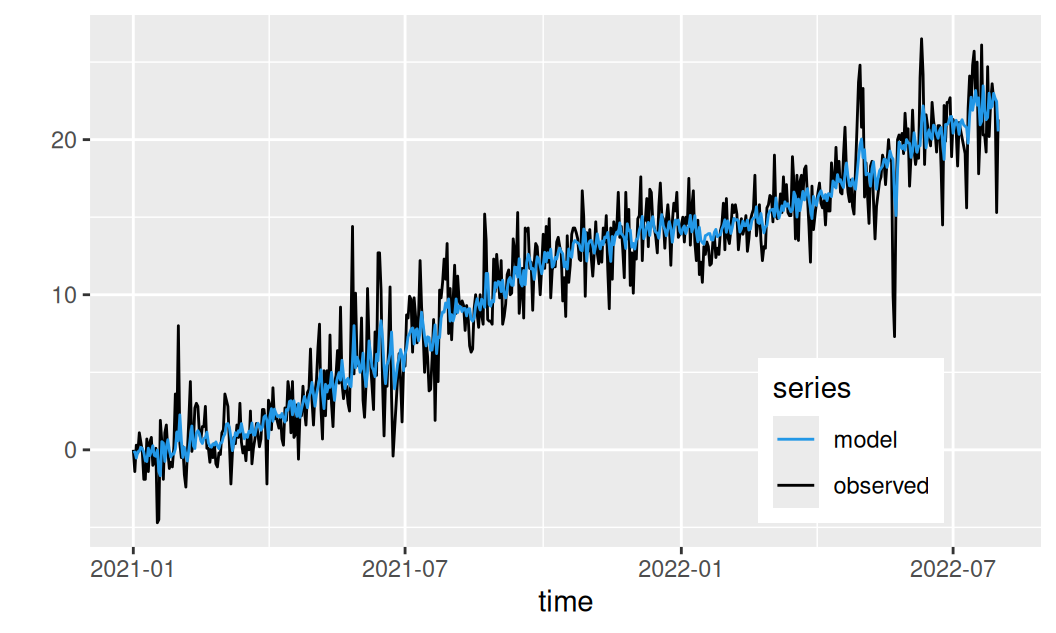
Zápis plného modelu je jednoduchý, vo funkcii fable::ARIMA sa použijú rovnaké členy ako v predošlých čiastkových modeloch.
fit$full <- dat$train |>
fabletools::model(
TlinSharRar1 = fable::ARIMA(
observed ~ trend() + fourier(period = "1 year", K=2) + pdq(1,0,0)
),
TlinSharRma2 = fable::ARIMA(
observed ~ trend() + fourier(period = "1 year", K=2) + pdq(0,0,2)
)
)
fit$full |> dplyr::select(TlinSharRar1) |> fabletools::report()Series: observed
Model: LM w/ ARIMA(1,0,0) errors
Coefficients:
ar1 trend() fourier(period = "1 year", K = 2)C1_365
0.3052 0.0385 0.0837
s.e. 0.0396 0.0004 0.1798
fourier(period = "1 year", K = 2)S1_365
-1.4478
s.e. 0.1877
fourier(period = "1 year", K = 2)C2_365
-0.0887
s.e. 0.1786
fourier(period = "1 year", K = 2)S2_365
-0.3245
s.e. 0.1834
sigma^2 estimated as 4.384: log likelihood=-1242.17
AIC=2498.34 AICc=2498.54 BIC=2528.85fit$full |>
dplyr::select(TlinSharRar1) |>
feasts::gg_tsresiduals() + ggtitle("TlinSharRar1 model residuals") 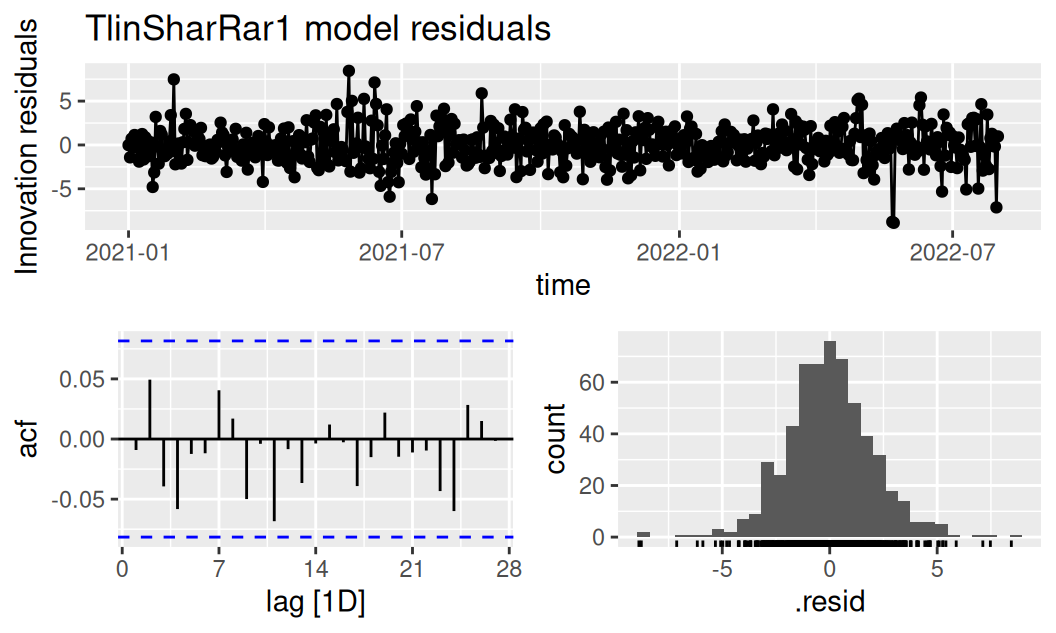
fit$full |>
dplyr::select(TlinSharRma2) |>
feasts::gg_tsresiduals() + ggtitle("TlinSharRma2 model residuals") 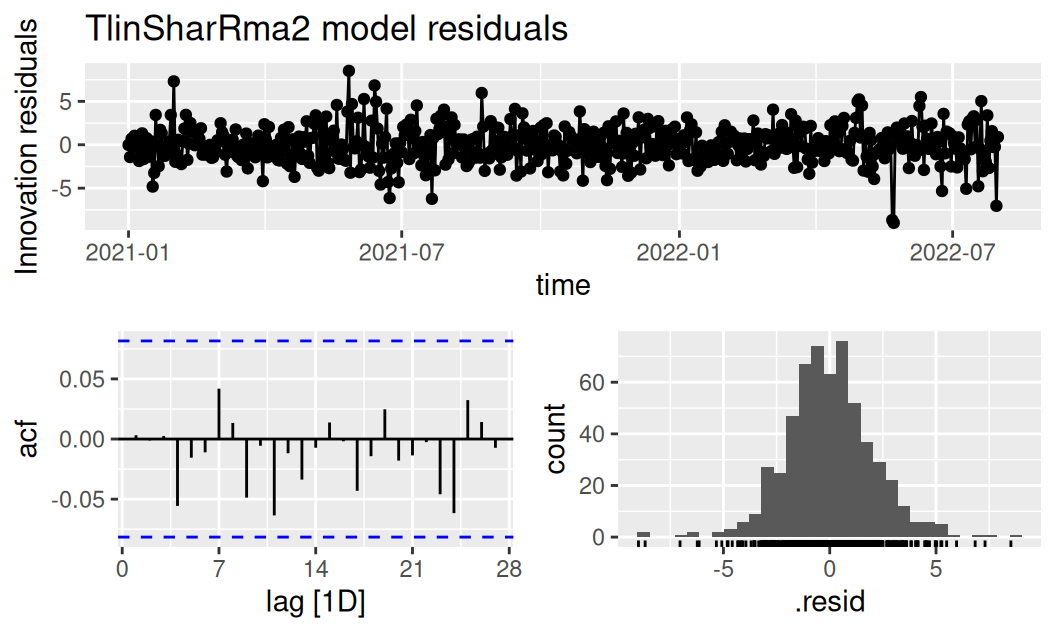
Rezíduá oboch modelov sú nekorelované a z histogramu sa zdá, že aj normálne rozdelené.
K obom úplným modelom (teda pre systematické i náhodnú zložku) pridáme naivný predpovedný model
fit$full$naive <- fabletools::model(dat$train, naive = fable::NAIVE(observed))$naivea zobrazíme presnosť ich popisnej schopnosti, aby sa neskôr dala porovnať s predpovednou.
fit$full |>
generics::accuracy() |>
dplyr::mutate(across(where(is.numeric), ~round(.x,3)))# A tibble: 3 × 10
.model .type ME RMSE MAE MPE MAPE MASE RMSSE ACF1
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 TlinSharRar1 Training -0.017 2.08 1.57 -Inf Inf 0.679 0.682 -0.009
2 TlinSharRma2 Training -0.017 2.08 1.57 -Inf Inf 0.679 0.68 0.003
3 naive Training 0.037 2.58 1.97 -Inf Inf 0.852 0.845 -0.369Vytvoríme kontajner na skupiny viackrokových a jednokrokových predpovedí a začneme viackrokovými do horizontu \(h=153\) dní.
# add multi-step forecasts
fore$mult <- fit$full |>
generics::forecast(h = 153)
# peek into
fore$mult |>
dplyr::arrange(time) |>
head(3)# A tsibble: 3 x 4 [1D]
# Key: .model [3]
.model time
<chr> <date>
1 TlinSharRar1 2022-08-01
2 TlinSharRma2 2022-08-01
3 naive 2022-08-01
# ℹ 2 more variables: observed <dist>, .mean <dbl>Náhľad do prvých troch riadkov výslednej tabľky (tu najprv zoradenej podľa času) ukazuje nový prístup ku predpovedaniu: už sa neobmedzuje na prvé dva momenty rozdelenia ( strednú hodnotu a rozptyl) ale umožňuje modelovať celé rozdelenie pravdepodobnosti. Štandardne sa predpokladá normálne rozdelenie \(N(\mu,\sigma^2)\), alternatívou je (zatiaľ iba) vzorkovacie rozdelenie (sampling distribution) pomocou prevzorkovacej metódy bootstrap.[^bootstrtap]
autoplot(dat$valid, observed) +
autolayer(dplyr::filter(dat$train, "2022-07-01" < time), observed) +
autolayer(fore$mult, alpha = 0.5) +
facet_grid(rows = vars(.model), scales = "free_y")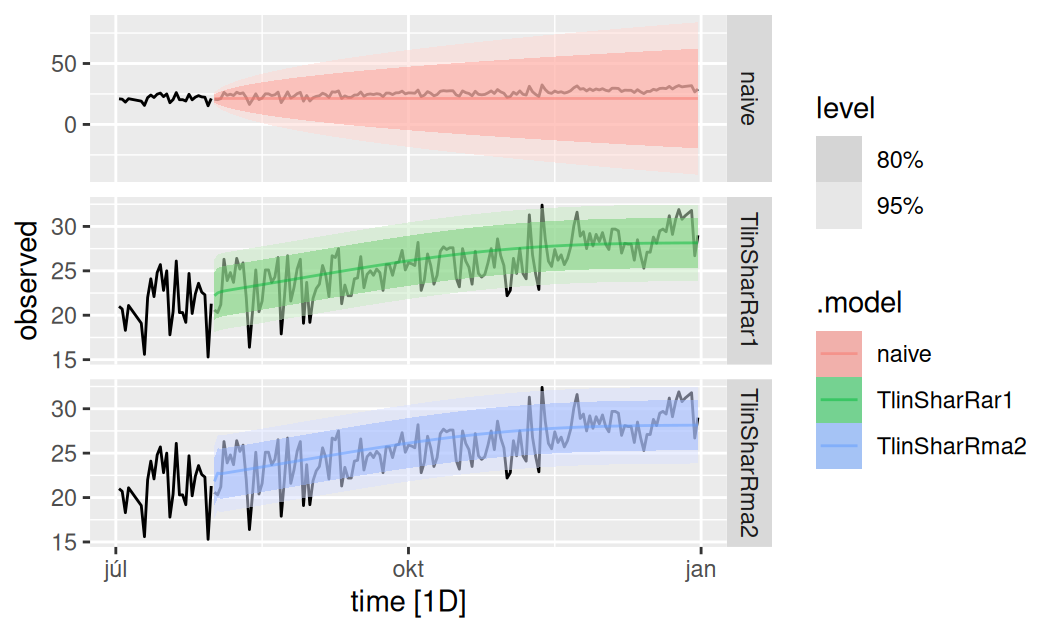
Oba vybudované modely dávajú prakticky totožné viackrokové predpovede, pretože to, v čom sa líšia, je model reziduálnej zložky s krátkou pamäťou. Oba sú veľmi dobré oproti naivnému modelu.
fore$mult |>
fabletools::accuracy(dat$valid) |>
dplyr::select(.model:MAPE) |>
dplyr::mutate(across(where(is.numeric), ~round(.x,3))) |>
dplyr::arrange(desc(.model))# A tibble: 3 × 7
.model .type ME RMSE MAE MPE MAPE
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 naive Test 4.57 5.42 4.78 16.5 17.7
2 TlinSharRma2 Test -0.404 2.20 1.76 -2.40 7.18
3 TlinSharRar1 Test -0.405 2.20 1.76 -2.40 7.18tmp <- fit$full |>
generics::refit(new_data = dat$valid)
tmp |>
generics::augment() |>
ggplot() + aes(x = time) +
geom_line(aes(y = observed)) +
geom_line(aes(y = .fitted, color = .model)) +
facet_grid(rows = vars(.model))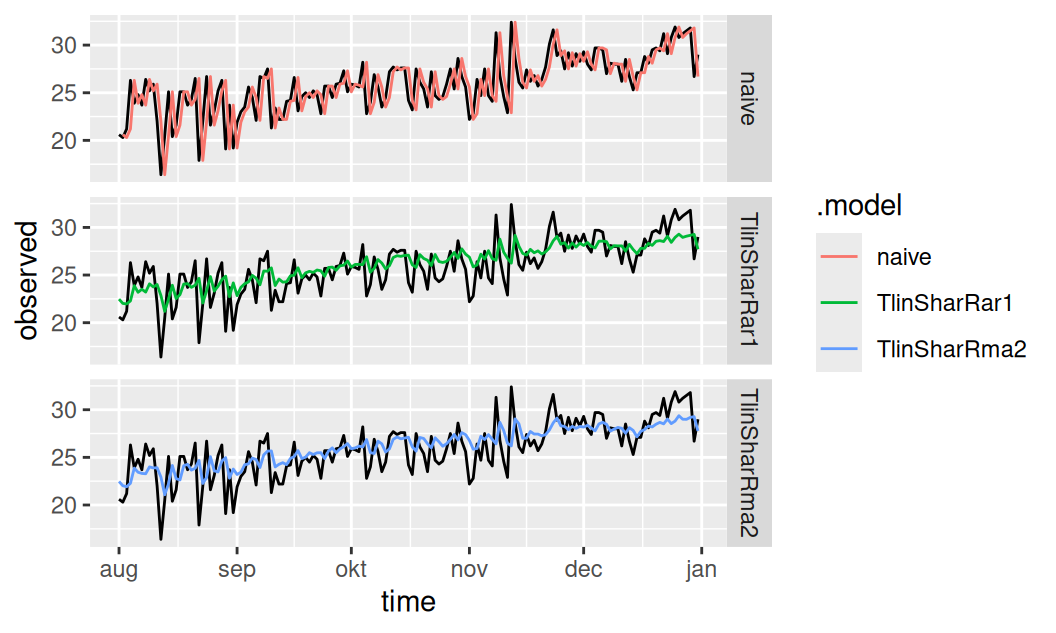
Presnosť 1-krokových predpovedí oboch vystavaných modelov je výborná.
tmp |>
generics::accuracy() |>
dplyr::mutate(.type = "Test") |> # correct the sample label
dplyr::mutate(across(where(is.numeric), ~round(.x,3)))# A tibble: 3 × 10
.model .type ME RMSE MAE MPE MAPE MASE RMSSE ACF1
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 TlinSharRar1 Test -0.282 2.11 1.63 -1.85 6.61 0.719 0.731 -0.035
2 TlinSharRma2 Test -0.283 2.12 1.64 -1.86 6.67 0.725 0.737 -0.022
3 naive Test 0.055 2.62 1.96 -0.362 7.92 0.865 0.909 -0.374Jednoduchším, AR(1) modelom sme dosiahli ešte lepšie výsledky ako so zložitejším, MA(2) modelom reziduálnej zložky.
# clear containers
dat <- fit <- fore <- list()
# load data
dat$all <- "data/HDP_kvart.dat" |> # data source file
read.table(header=T, skip = 1) |> # load file but skip description line
setNames(c("time", "observed")) # name columns
head(dat$all) time observed
1 1964.00 49.00
2 1964.25 54.48
3 1964.50 60.38
4 1964.75 62.88
5 1965.00 52.09
6 1965.25 59.35Časový rad predstavuje kvartálne záznamy hrubého domáceho produktu (HDP) jednej európskej krajiny v rokoch 1964–1998 v jednotkách miliárd EUR. Nech trénovacia vzorka končí bodom 1991 Q4, a validačná začína 1992 Q1.
Aby sme mohli pracovať so systémom balíkov tidyverts, uložíme časový rad ako tsibble s indexom time vo formáte rok-kvartál.
dat$all <- dat$all |>
dplyr::mutate(
time = time |> lubridate::date_decimal() |> tsibble::yearquarter(),
sample = ifelse(time <= tsibble::yearquarter("1991 Q4"), "train", "valid")
) |>
tsibble::as_tsibble(index = time)
dat$train <- dat$all |> dplyr::filter(sample == "train")
dat$valid <- dat$all |> dplyr::filter(sample == "valid")
dat$all |>
fabletools::autoplot(observed) + aes(color = sample) +
theme(legend.position = "inside", legend.position.inside = c(0.9,0.2)) +
scale_color_manual(values = c(train = 1, valid = 2)) +
scale_y_log10()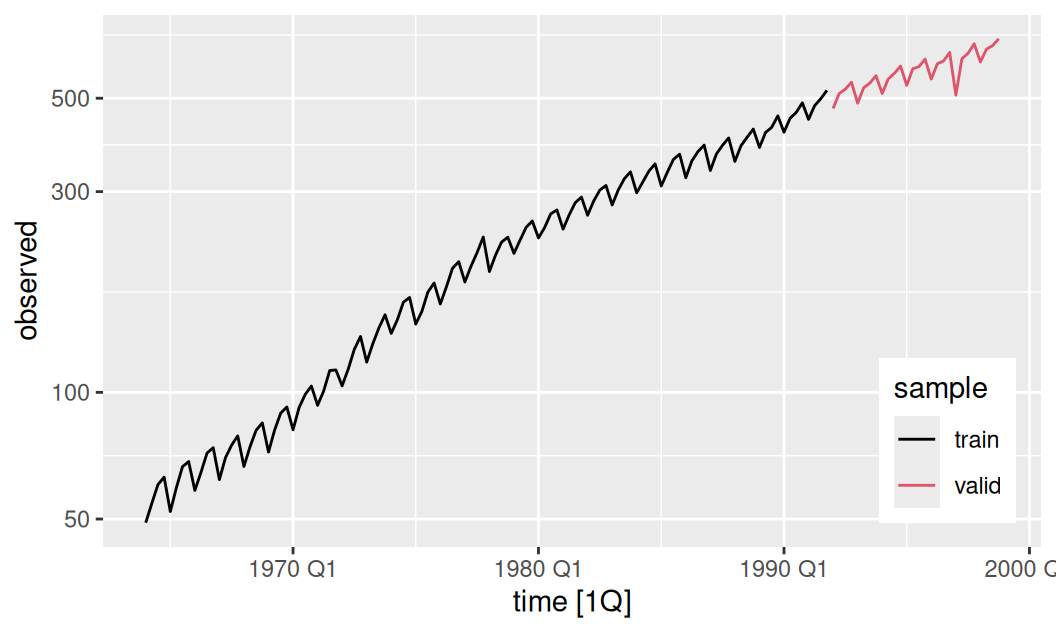
Časový rad je okrem strednej hodnoty zjavne nestacionárny aj v rozptyle.
Parameter Box-Coxovej transformácie odhadneme tzv. Guerrerovou metódou.
lambda <- dat$train |>
fabletools::features(.var = observed, features = feasts::guerrero) |>
dplyr::pull(lambda_guerrero) |>
c(lambda = _) |> # optional step
print() lambda
0.2544408 Podľa tohoto odhadu teda logaritmická transformácia (\(\lambda=0\)) nie je optimálna stacionarizujúca transformácia.
Kvôli nestacionarite v rozptyle je aditívny rozklad jednoduchšie urobiť na transformovanom časovom rade než na časovom rade v pôvodnej mierke.
Označme stacionarizujúcu, Box-Coxovu transformáciu s parametrom \(\lambda\) symbolom \(BC_{\lambda}\) a komponenty pozorovaného časového radu v okamihu \(t\) symbolmi \(T_t\) (trend), \(S_t\) (sezónnosť), \(C_t\) (cyklická zložka) a \(R_t\) (reziduum). Keďže aditívny rozklad na komponenty v pôvodnej mierke \[ x_t = T_t + S_t + C_t + R_t \] je z analytického hľadiska náročné, budeme pracovať s transformovanej mierke s náhradnými komponentami \(T'_t\), \(S'_t\), \(C'_t\) a \(R'_t\), pričom platí \[ BC_{\lambda}(x_t) = T'_t + S'_t + C'_t + R'_t \] a iba pri trende možno počítať s prevodným vzťahom \(BC_{\lambda}(T_t) = T'_t\). Výhoda zložiek značených bez čiarky je, že sú v rovnakých jednotkách ako pozorovaný časový rad, preto ich budeme analyzovať najmä v časti o interpretácii modelu.
Keďže Box-Coxova transformácia je definovaná vzťahom \[ BC_{\lambda}(x)=\begin{cases} \frac{x^\lambda-1}\lambda & \text{pre } \lambda\neq0\\ \ln{x} & \text{pre } \lambda=0, \end{cases} \] k nej inverzná transformácia má tvar \[ BC_{\lambda}^{-1}(x)=\begin{cases} (\lambda x + 1)^{1/\lambda} & \text{pre } \lambda\neq0\\ e^{x} & \text{pre } \lambda=0. \end{cases} \] V špeciálnom prípade, keď optimálne \(\lambda=0\), je možné aditívnu dekompozíciu zjednodušiť na multiplikatívnu, \[ \begin{split} \ln x_t &= T'_t + S'_t + C'_t + R'_t \\ x_t &= e^{T'_t + S'_t + C'_t + R'_t} \\ x_t &= e^{T'_t}\cdot e^{S'_t}\cdot e^{C'_t}\cdot e^{R'_t} \\ x_t &= T''_t \cdot S''_t \cdot C''_t \cdot R''_t \end{split} \] pričom komponenty \(S''_t\), \(C''_t\) a \(R''_t\) sú stacionárne v rozptyle. V takom prípade sa časový rad dá jednoducho modelovať aj v pôvodnej mierke, avšak treba mať na pamäti, že v jednotkách časového radu je iba trend \(T''_t\) a ostatné zložky sú bezrozmerné, pomerné ku trendu.
Na prvotný prieskumný rozklad použijeme adaptívnu metódu multiplikatívnej i aditívnej dekompozície, konkrétne metódou kĺzavých priemerov.
# load fabletools just for classical_decomposition to find inv_box_cox :(
# hopefully this bug will be eliminated in the future
library(fabletools)
fit$adapt <- dat$train |>
fabletools::model(
Mult = feasts::classical_decomposition(observed, type = "multiplicative"),
bcAdd = feasts::classical_decomposition(fabletools::box_cox(observed, lambda),
type = "additive")
)
detach("package:fabletools")fit$adapt |>
dplyr::select(Mult) |>
fabletools::components() |>
feasts::autoplot()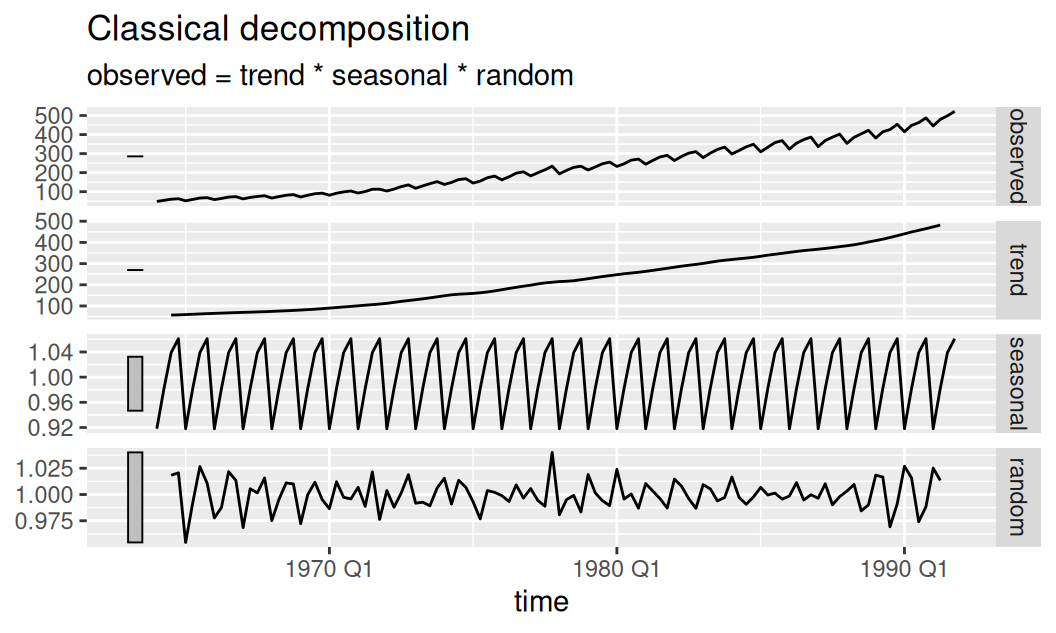
Na vizualizácii multiplikatívneho rozkladu je vidieť rastúci trend (v mld EUR) a výraznú sezónnu zložku v rozsahu od 92% do 106% strednej hodnoty. Heteroskedasticita šumu (rozdiel v rozptyle medzi centrálnou časťou a koncami) prezrádza, že logaritmická funkcia stojaca za multiplikatívnou dekompozíciou nie je optimálna stacionarizujúca transformácia.
fit$adapt |>
dplyr::select(bcAdd) |>
fabletools::components() |>
feasts::autoplot()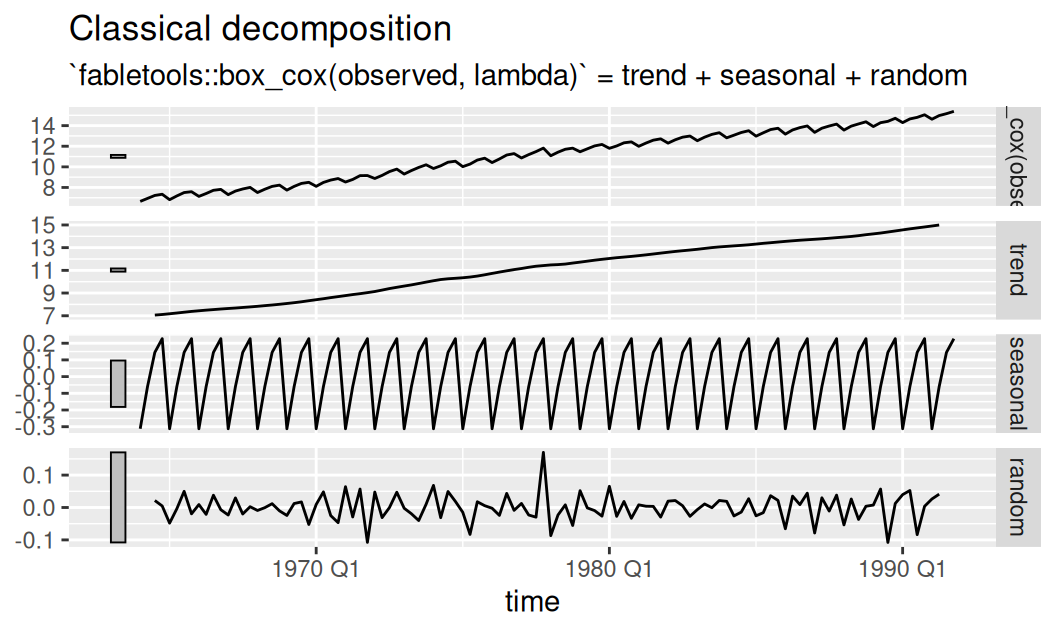
Box-Coxova transformácia s parametrom \(\lambda=0.25\) umožnuje v novej mierke aditívnu dekompozíciu pričom rezíduá už vyzerajú homoskedastické.
Izolovaný trend pripomína exponenciálnu funkciu. V logaritmickej mierke zodpovedá lineárnemu trendu. Preto pokusne zvolíme jeden model s ohľadom na ľahkú interpretovateľnosť, pri ostatných modeloch použijeme Box-Coxovú transformáciu s vopred odhadnutým parametrom lambda.
Stacionarizujúca transformácia sa kóduje priamo v rovnici modelu (na rozdiel od extra argumentu vo funkciách balíku forecast). Odhadnime 4 modely:
# knots for linear spline:
knots_lsp <- c("1970 Q1", "1979 Q1") |>
tsibble::yearquarter()
# fitting models
fit$trend <- dat$train |>
fabletools::model(
linear = fable::TSLM(log(observed) ~ trend()),
linspline = fable::TSLM(
fabletools::box_cox(observed, lambda) ~ trend(knots = knots_lsp)
),
natspline = fable::TSLM(
fabletools::box_cox(observed, lambda) ~ splines::ns(time, df = 10)
),
quadratic = fable::TSLM(
fabletools::box_cox(observed, lambda) ~ poly(time, 2))
)fit$trend |>
generics::glance() |>
dplyr::mutate(across(where(is.numeric), ~signif(.x,3)))# A tibble: 4 × 15
.model r_squared adj_r_squared sigma2 statistic p_value df log_lik AIC
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 linear 0.973 0.973 0.0123 4000 2.56e- 88 2 88.2 -488
2 linspl… 0.992 0.992 0.0522 4420 8.72e-113 4 8.47 -325
3 natspl… 0.993 0.992 0.0505 1370 4.43e-103 11 14.1 -322
4 quadra… 0.989 0.989 0.0722 4780 7.16e-107 3 -10.2 -289
# ℹ 6 more variables: AICc <dbl>, BIC <dbl>, CV <dbl>, deviance <dbl>,
# df.residual <dbl>, rank <dbl>dat$trend <- fit$trend |>
generics::augment()
dat$trend |>
ggplot(aes(x = time)) +
geom_line(aes(y = observed)) +
geom_line(aes(y = .fitted, colour = .model), linewidth = 0.8)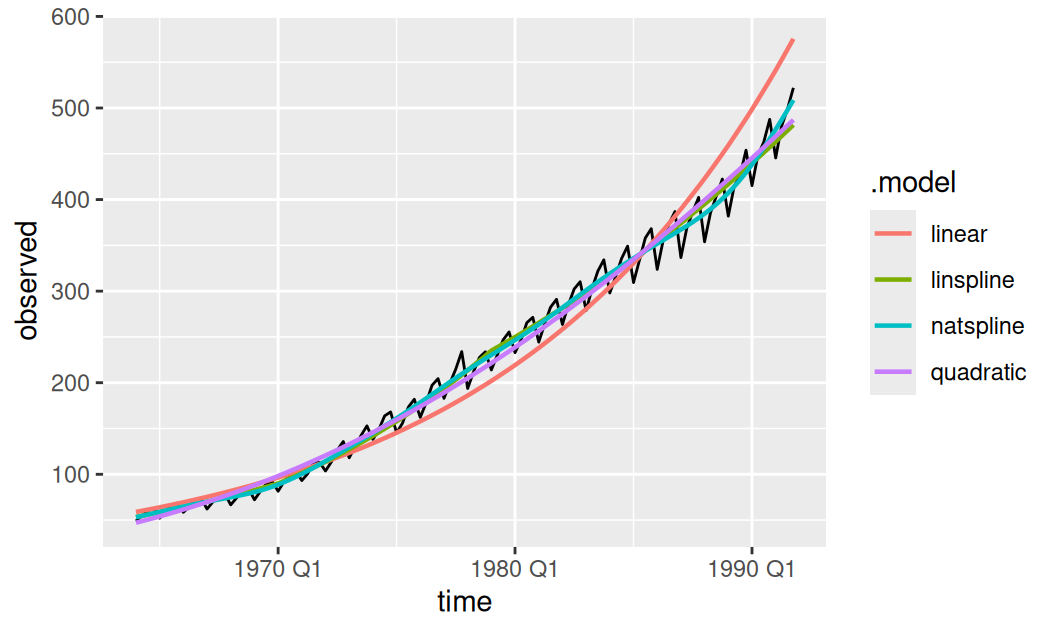
fit$trend |>
dplyr::select(linear) |> # one way of picking up a model
generics::augment() |>
ggplot() + aes(x = time) +
geom_line(aes(y = observed)) +
geom_line(aes(y = .fitted, color = .model)) +
scale_color_manual(values = c(linear = scales::hue_pal()(4)[1])) +
scale_y_continuous(transform = "log", breaks = c(50,100, 200, 400)) +
labs(y = "log scale") +
theme(legend.position = "inside", legend.position.inside = c(0.8,0.2))
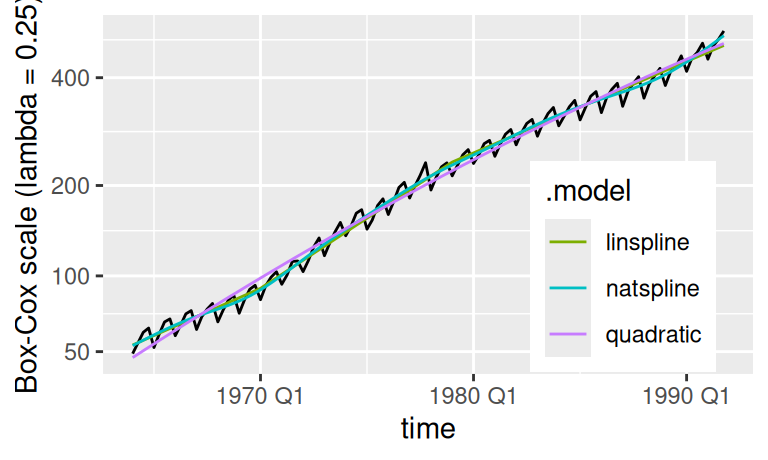
dat$trend |>
dplyr::filter(.model != "linear") |> # another way
ggplot() + aes(x = time) +
geom_line(aes(y = observed)) +
geom_line(aes(y = .fitted, color = .model)) +
scale_color_manual(values = c(scales::hue_pal()(4)[-1])) +
scale_y_continuous(transform = scales::boxcox_trans(lambda),
breaks = c(50,100, 200, 400)
) +
labs(y = "Box-Cox scale (lambda = 0.25)") +
theme(legend.position = "inside", legend.position.inside = c(0.8,0.3))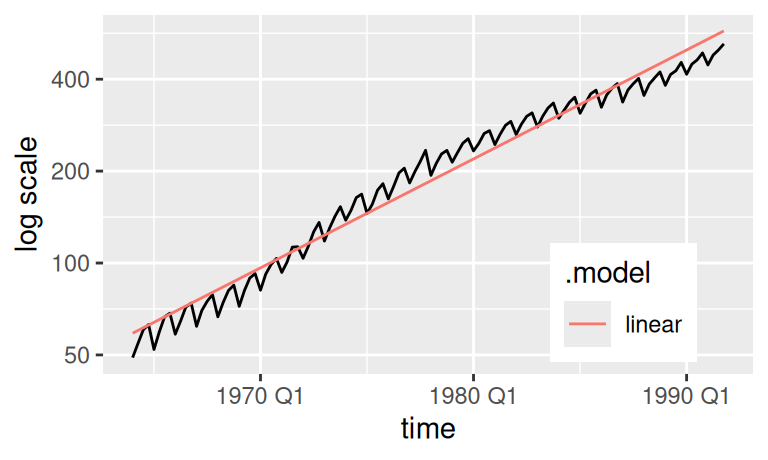
Pozrime na rezíduá (v transformovanej mierke identifikované ako innovations):
dat$trend |>
ggplot() + aes(x = time, y = .innov) + geom_line() + geom_line() +
facet_wrap(~ .model) +
labs(title = "Residuals in transformation scale")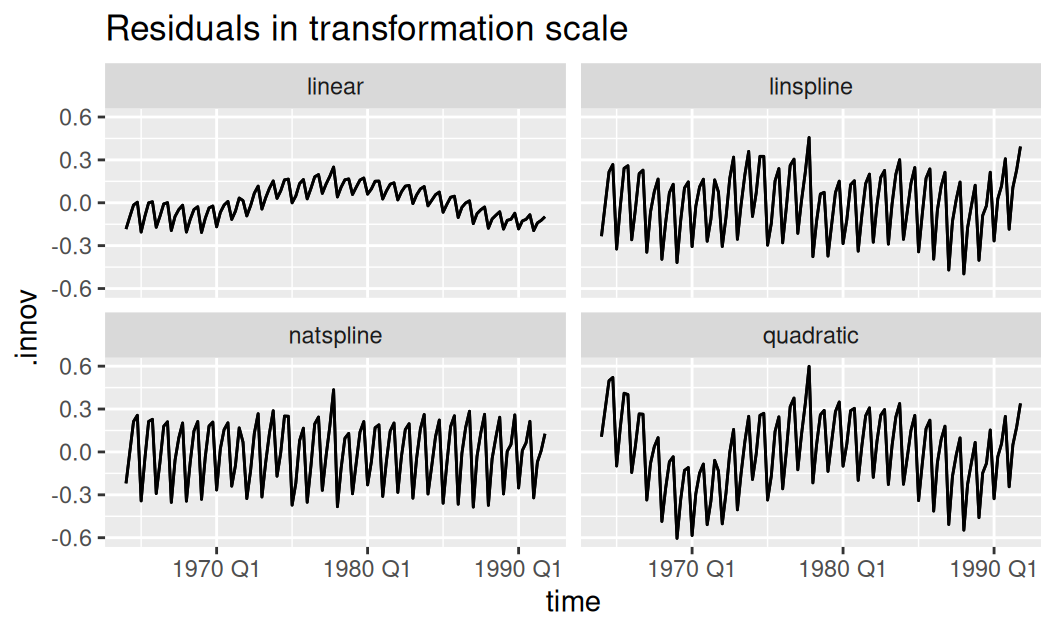
Na rezíduách vidieť, že ani Box-Coxová transformácia (odhad Guererovou metódou) si s heteroskedasticitou úplne neporadila. Ešte lepšie to bude vidieť na rezíduách po sezónnej zložke.
Je zjavné, že prirodzený kubický splajn s 10 stupňami voľnosti popísal trénovaciu vzorku najlepšie. To však nedáva záruku najlepších predpovedí (ba skôr naopak, môže sa prejaviť nežiadúci jav známy ako overfitting). Pretože nemáme tušenie, čo spôsobuje dlhoperiodickú fluktuáciu okolo jednoduchších trendov, budeme cyklickú zložku modelovať radšej iba pri lineárnom trende, ktorý má najhoršiu popisnú schopnosť a aj pre predpovedanie je pravdepodobne príliš jednoduchý (underfitting ako opačný extrém).
Všimnime si ešte na predošlých obrázkoch, ako ľahko môže mierka transformácie pomýliť pri posúdení priliehavosti modelu. Hoci má lineárny trend rezíduá na obrázku menej rozptýlené ako kvadratický trend, v pôvodnej mierke sú rezíduá lineárneho trendu podstatne väčšie. Logaritmická transformácia teda hodnoty časového radu stláča k nule agresívnejšie než Box-Coxova transformácia s parametrom \(\lambda=0.25\).
V prípade kvartálnych časových radov je sezónnosť vhodné modelovať pomocou indikačných bázových funkcií.
fit$season <- dat$trend |>
#dplyr::filter(.model == "linear") |>
dplyr::rename(trend.innov = .innov) |>
fabletools::model(indicator = fable::TSLM(trend.innov ~ season()))
tmp <- fit$season |>
dplyr::rename(trend.model = .model) |>
# dplyr::filter(.model == "linear") |>
# dplyr::select(-.model) |>
generics::augment() |>
dplyr::rename(season.model = .model)
ggplot(tmp) + aes(x = time, y = .innov) + geom_line() +
facet_wrap(~ trend.model) +
labs(title = "Seasonal residuals for each trend model")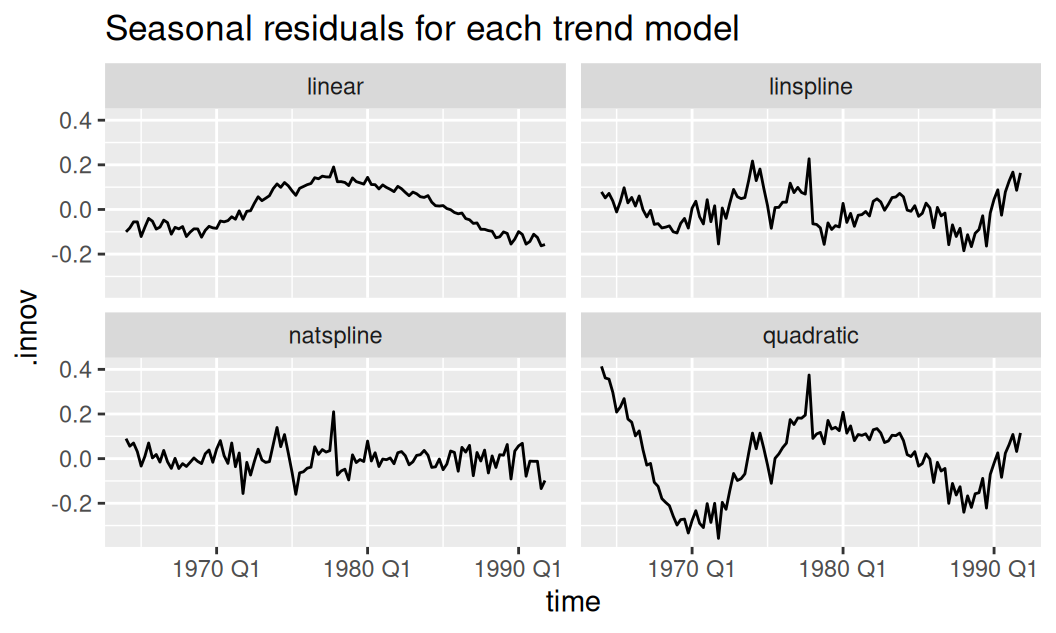
Rezíduá budú samozrejme po spoločných modeloch vyzerať trochu inak. V nasledujúcej kapitole sa zameriame na cyklickú zložku v rezíduách z prvého obrázku (vľavo hore).
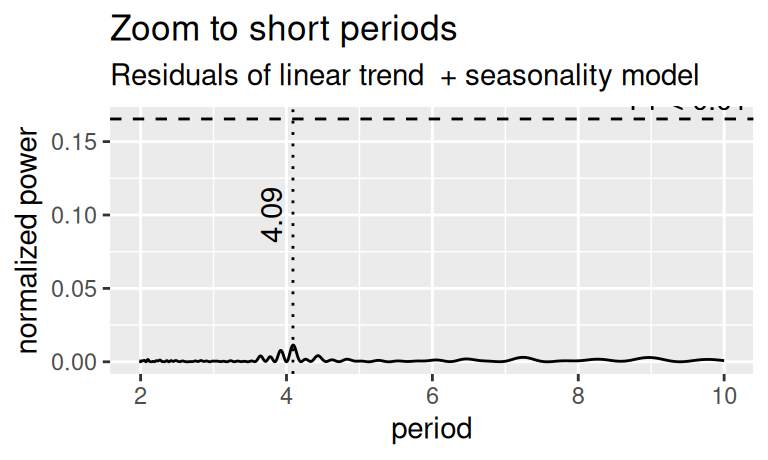
Rezíduá modelu lineárneho trendu a sezónnosti v logaritmickej mierke javia známky krátko-periodickej (sezónnej) zložky (najmä na koncoch) i dlho-periodickej (cyklickej) zložky, čo potvrdzuje aj nasledujúci periodogram.
Pre krajšie zobrazenie periodogramu si najprv vytvoríme ggplot2 nadstavbu funkcie lomb::lsp.
# Function to plot least squares periodogram with ggplot2.
# in: x - data to be analysed
# ... - other arguments to be passed to lomb::lsp()
# out: ggplot object
gglsp <- function(x, ...) {
# get periodogram object
obj <- lomb::lsp(x, plot = FALSE, ...)
# plot
ggplot(as.data.frame(obj[c("scanned", "power")])) +
aes(x = scanned, y = power) + geom_line() +
geom_hline(yintercept = obj$sig.level, linetype = 2) +
geom_vline(xintercept = obj$peak.at[1], linetype = 3) +
annotate("text", label = paste("Pr <", obj$alpha),
x = max(obj$scanned), y = obj$sig.level,
hjust = 0.8, vjust = -0.4) +
annotate("text", label = obj$peak.at[1] |> signif(3) |> as.character(),
x = obj$peak.at[1], y = 0.1, angle = 90, vjust = -0.5) +
labs(x = obj$type, y = "normalized power")
}Ak funkcii dodáme iba samotný vektor rezíduí, periódy budú v jednotkách kvartálov.
tmp |>
dplyr::filter(trend.model == "linear", season.model == "indicator") |>
_[[".innov"]] |>
gglsp(type = "period", ofac = 20) +
labs(title = "Full spectrum periodogram", subtitle = "Residuals of linear trend + seasonality model")
tmp |>
dplyr::filter(trend.model == "linear", season.model == "indicator") |>
_[[".innov"]] |>
gglsp(type = "period", to = 10, ofac = 20) +
labs(title = "Zoom to short periods", subtitle = "Residuals of linear trend + seasonality model")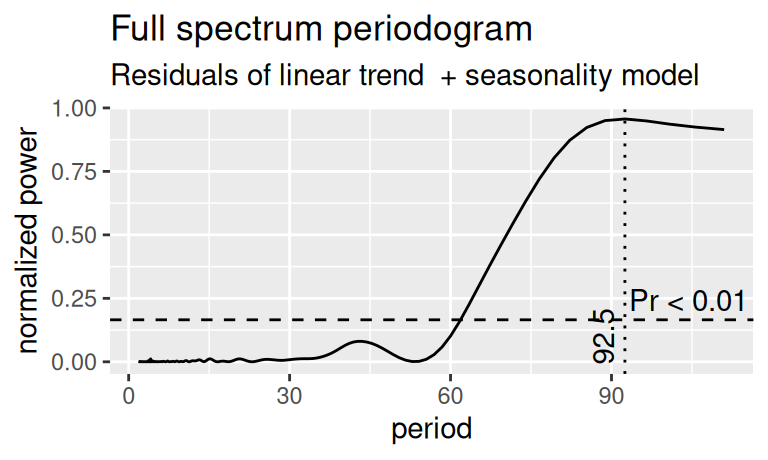
V spoločnom modeli systematických zložiek v nasledujúcej časti pridáme k modelu lineárneho trendu a sezónnosti (pomocou indikačných bázových funkcií) aj model cyklickej zložky pomocou harmonických funkcií so základnou periódou \(L= 23Y= 92Q\) a zahrnutím polovičnej periódy.
Rezíduá ostatných modelov ponecháme bez popisu cyklickou zložkou, i keď ešte pri kvadratickom trende by sme detekovali významnú periódu okolo 64 kvartálov (16 rokov). Ponecháme ho ako jediný predpovedný model, ktorý popisuje iba dve najvýraznejšie zložky: trend a sezónnosť, aj za cenu autokorelovaných rezíduí. Zároveň poslúži ako ilustračný príklad pri detekcii nenáhodnosti rezíduí.
Všetky doterajšie poznatky zhrnieme do formulácie spoločných modelov systematických zložiek a ich odhadom spresníme predošlé odhady parametrov i rezíduí.
fit$systematic <- fabletools::model(
.data = dat$train,
logTlinSindC23 = fable::TSLM(
log(observed) ~ trend() + season() + fourier(period = "23 years", K=2)
),
bcTlspSind = fable::TSLM(
fabletools::box_cox(observed, lambda) ~ trend(knots = knots_lsp) + season()
),
bcTnspSind = fable::TSLM(
fabletools::box_cox(observed, lambda) ~ splines::ns(time, df = 10) +
season()
),
bcTquaSind = fable::TSLM(
fabletools::box_cox(observed, lambda) ~ poly(time, 2, raw = TRUE) + season()
)
)
fit$systematic |>
generics::glance() |>
dplyr::mutate(across(where(is.numeric), ~signif(.x,4)))# A tibble: 4 × 15
.model r_squared adj_r_squared sigma2 statistic p_value df log_lik AIC
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 logTl… 0.999 0.999 4.36e-4 14550 1.44e-153 9 279. -856.
2 bcTls… 0.999 0.999 7.02e-3 16540 8.35e-154 7 122. -547.
3 bcTns… 1.00 1.00 3.05e-3 17600 8.70e-159 14 173 -634.
4 bcTqu… 0.996 0.995 2.98e-2 4661 1.72e-122 6 41.0 -386.
# ℹ 6 more variables: AICc <dbl>, BIC <dbl>, CV <dbl>, deviance <dbl>,
# df.residual <dbl>, rank <dbl>fit$systematic |>
generics::augment() |>
dplyr::mutate(.model = forcats::as_factor(.model)) |>
ggplot() + aes(x = time) +
geom_line(aes(y = observed), data = dat$train) +
geom_line(aes(y = .fitted, color = .model), show.legend = FALSE) +
facet_wrap(~ .model) +
labs(y = "observed and fitted")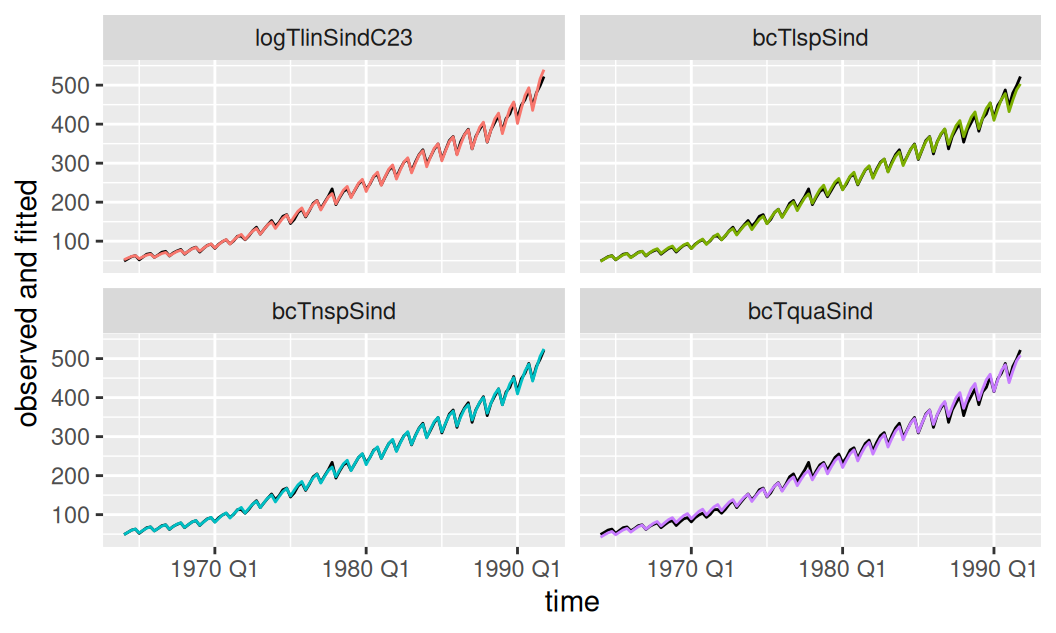
fit$systematic |>
generics::augment() |>
dplyr::filter(.model == "logTlinSindC23") |>
autoplot(.innov) +
labs(title = "Residuals of logTlinSindC23 model")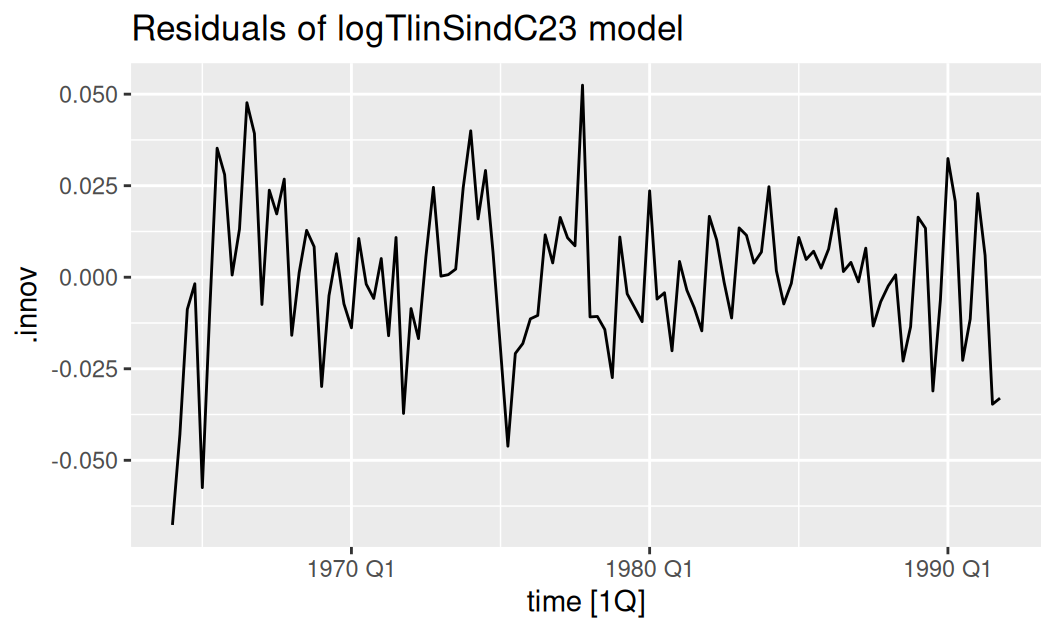
Vyšetríme autokoreláciu rezíduí v transformovanej mierke.
fit$systematic |>
generics::augment() |>
dplyr::mutate(.model = forcats::as_factor(.model)) |> # to preserve order
feasts::ACF(.innov) |>
fabletools::autoplot(.vars = acf) +
facet_wrap(~ .model) +
labs(title = "ACF of model residuals")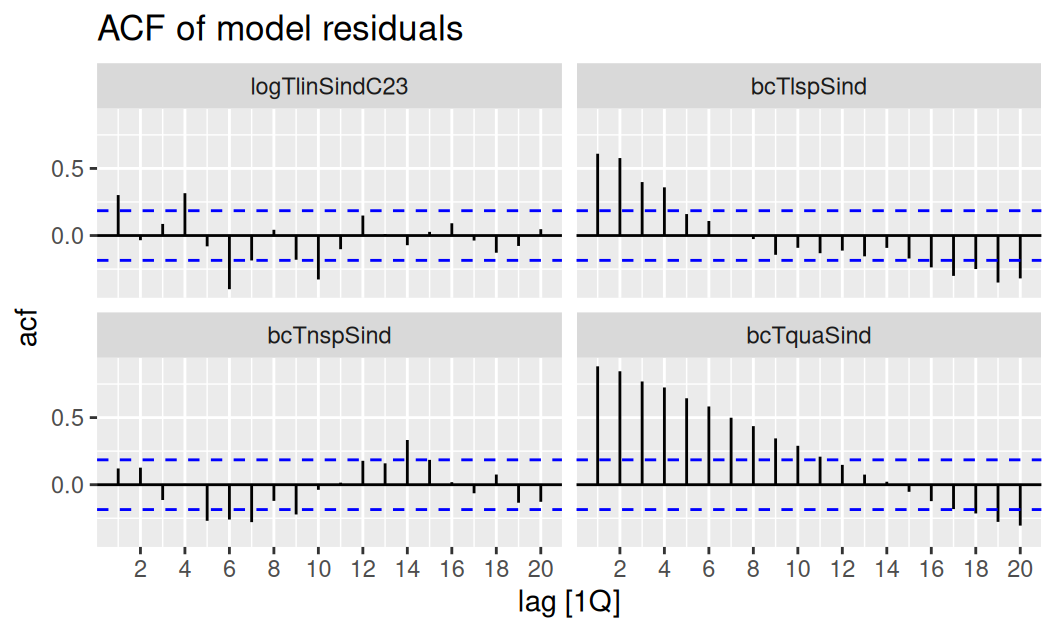
Model s prirodzeným splajnom (vľavo dole) má rezíduá najbližšie ku bielemu šumu a prakticky už nepotrebuje dalšiu úpravu. Modely s lineárnym a po častiach lineárnym trendom doplníme o náhodnú zložku. Posledný model (s kvadratickým trendom) sme sa rozhodli ponechať bez zmeny ako najjednoduchšiu alternatívu na predpovedanie.
Pre neparametrickú identifikáciu lineárneho procesu zobrazíme ku ACF z predošlej časti aj PACF.
fit$systematic |>
dplyr::select(logTlinSindC23, bcTlspSind) |>
generics::augment() |>
dplyr::mutate(.model = forcats::as_factor(.model)) |> # to preserve order
feasts::PACF(.innov) |>
fabletools::autoplot(.vars = acf) +
facet_wrap(~ .model) +
labs(title = "PACF of model residuals")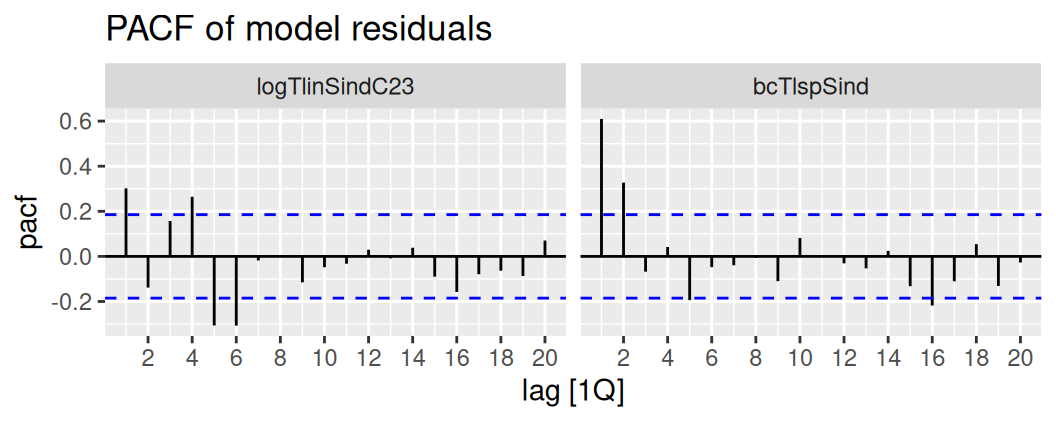
V prvom prípade pre jednoduchosť vyberieme MA(1), v druhom AR(2).
Systematické a náhodnú (reziduálnu) zložku odhadneme spoločne v jednom modeli. Prvú časť rovnice modelu prevezmeme z modelov systematických zložiek. Keďže systém balíkov tidyverts neposkytuje nástroj na extrakciu formule z tabuľky mable, vytvoríme vlastnú funkciu.
# Function to extract formulas from model table (mable) object.
# in: x - mable
# out: named list of formulas
formula.mable <- function(x) {
x |> # model table
dplyr::slice(1) |> # first row, formula is invariant to key variable
dplyr::select(where(~ "lst_mdl" %in% class(.x))) |> # extract models
as.data.frame() |> # mable to df
lapply(function(x) formula(x[[1]]$model)) # extract formula
}Zvyšok rovnice doplníme členom pdq podľa identifikácie v predošlej podkapitole.
tmp <- fit$systematic |>
formula.mable() # extract formulas from model objects
fit$full <- fabletools::model( # Estimate new models ...
.data = dat$train, # on training dataset ...
logTlinSindC23Rma1 = tmp$logTlinSindC23 |> # using formula ...
update.formula(.~. + pdq(0,0,1) + PDQ(0,0,0)) |> # updated to contain ...
fable::ARIMA(), # residual component.
bcTlspSindRar2 = tmp$bcTlspSind |> # second model
update.formula(.~.+ pdq(2,0,0) + PDQ(0,0,0)) |>
fable::ARIMA()
)fit$full |>
dplyr::select(logTlinSindC23Rma1) |>
feasts::gg_tsresiduals() + ggtitle("logTlinSindC23Rar1 model residuals") 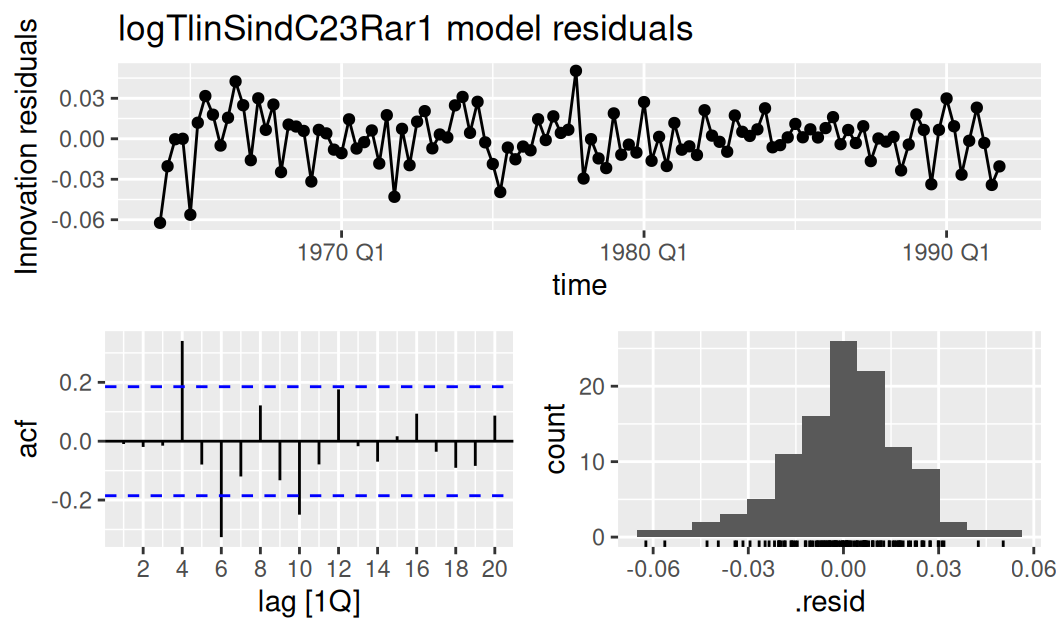
Rezíduá prvého modelu sú ešte stále korelované, avšak budeme to tolerovať, pretože v opačnom prípade by sme museli zvýšiť stupeň MA (alebo AR) polynómu a tak by model reziduálnej zložky suploval sčasti aj úlohu modelu sezónnej zložky. Dynamickým modelom sezónnej zložky sa venujeme v podkapitolách o SARIMA a ETS.
fit$full |>
dplyr::select(bcTlspSindRar2) |>
feasts::gg_tsresiduals() + ggtitle("bcTlspSindRar2 model residuals") 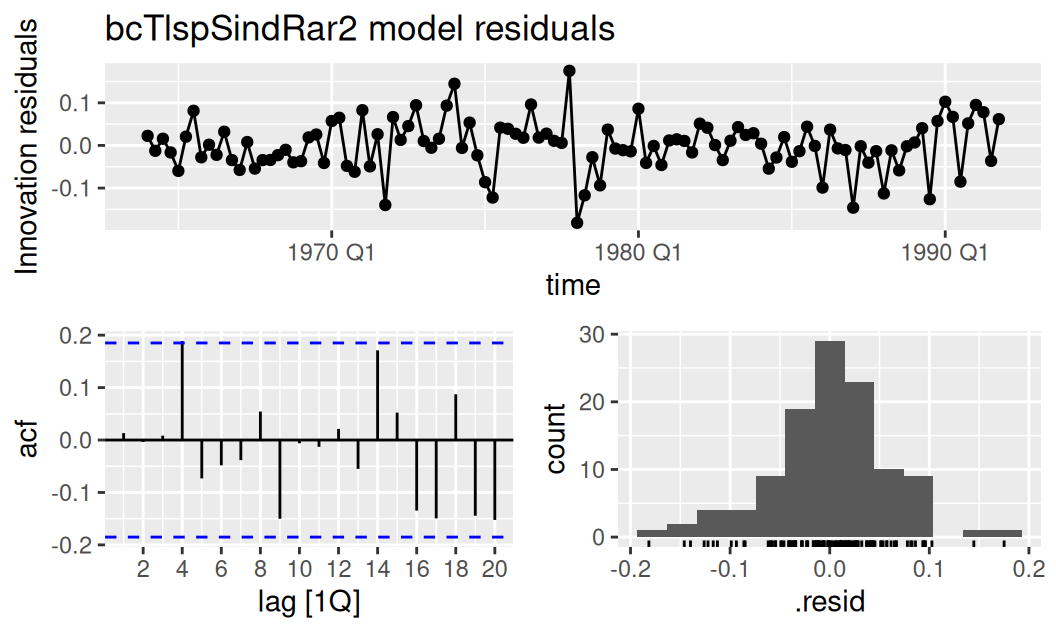
Rezíduá druhého modelu sú prakticky nekorelované a z histogramu sa zdá, že aj normálne rozdelené.
Medzi modely pridáme jednoduchý naivný a sezónny naivný predpovedný model.
# create naive forecast models
fit$naive <- fabletools::model(
dat$train,
naive = fable::NAIVE(fabletools::box_cox(observed, lambda)),
snaive = fable::SNAIVE(fabletools::box_cox(observed, lambda))
)# select models for forecasting
fit$selected <- fit[c("systematic", "full", "naive")] |>
dplyr::bind_cols() |>
dplyr::select(bcTquaSind, bcTnspSind,
logTlinSindC23Rma1, bcTlspSindRar2,
naive, snaive) Zobrazíme presnosť popisnej schopnosti všetkých modelov, aby sa neskôr dala porovnať s predpovednou presnosťou.
fit$selected |>
generics::accuracy() |>
dplyr::mutate(across(where(is.numeric), ~signif(.x,2))) |>
{\(x) dplyr::slice(x, match(x$.model, names(fit$selected)))}() # reordering# A tibble: 6 × 10
.model .type ME RMSE MAE MPE MAPE MASE RMSSE ACF1
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 bcTquaSind Train… 0.14 7.8 6.5 -0.14 4 0.41 0.43 8.2e-1
2 bcTnspSind Train… 0.013 3 2.1 -0.012 1 0.13 0.17 5.5e-3
3 logTlinSindC23Rma1 Train… -0.079 4.3 2.9 -0.0031 1.4 0.18 0.24 2.5e-2
4 bcTlspSindRar2 Train… 0.011 3.7 2.5 -0.029 1.2 0.16 0.21 9.7e-4
5 naive Train… 4.3 20 17 1.7 8.2 1.1 1.1 -3.2e-1
6 snaive Train… 16 18 16 7.6 7.6 1 1 8.1e-1Pri viackrokových predpovediach sa použije generická funkcia forecast so zadaním tsibble tabuľky validačnej vzorky, z ktorej si vezme iba časové okamihy time a ntime.
# add multi-step forecasts
fore$mult <- fit$selected |>
generics::forecast(new_data = dat$valid) |>
dplyr::mutate(.model = factor(.model, levels = names(fit$selected))) # ordering
# peek into
fore$mult |>
dplyr::arrange(time) |>
head(3)# A tsibble: 3 x 5 [1Q]
# Key: .model [3]
.model time observed .mean sample
<fct> <qtr> <dist> <dbl> <chr>
1 bcTnspSind 1992 Q1 t(N(6.6, 0.004)) 48.7 valid
2 bcTquaSind 1992 Q1 t(N(15, 0.033)) 462. valid
3 logTlinSindC23Rma1 1992 Q1 t(N(6.2, 0.00039)) 475. valid Náhľad do prvých troch riadkov výslednej tabuľky fable (forecast table) pripomína, že predmetom predpovede nie sú iba prvé dva momenty rozdelenia (stredná hodnota a rozptyl) ale celé rozdelenie pravdepodobnosti v danom okamihu. Štandardne sa pre (transformovanú) náhodnú premennú predpokladá normálne rozdelenie \(N(\mu,\sigma^2)\), alternatívou je (zatiaľ iba) vzorkovacie rozdelenie (sampling distribution) pomocou prevzorkovacej metódy bootstrap.2
autoplot(dat$valid, observed) +
autolayer(dplyr::filter(dat$train, tsibble::yearquarter("1989 Q4") < time), observed) +
autolayer(fore$mult, .mean, alpha = 0.5) +
facet_grid(rows = vars(.model), scales = "free_y")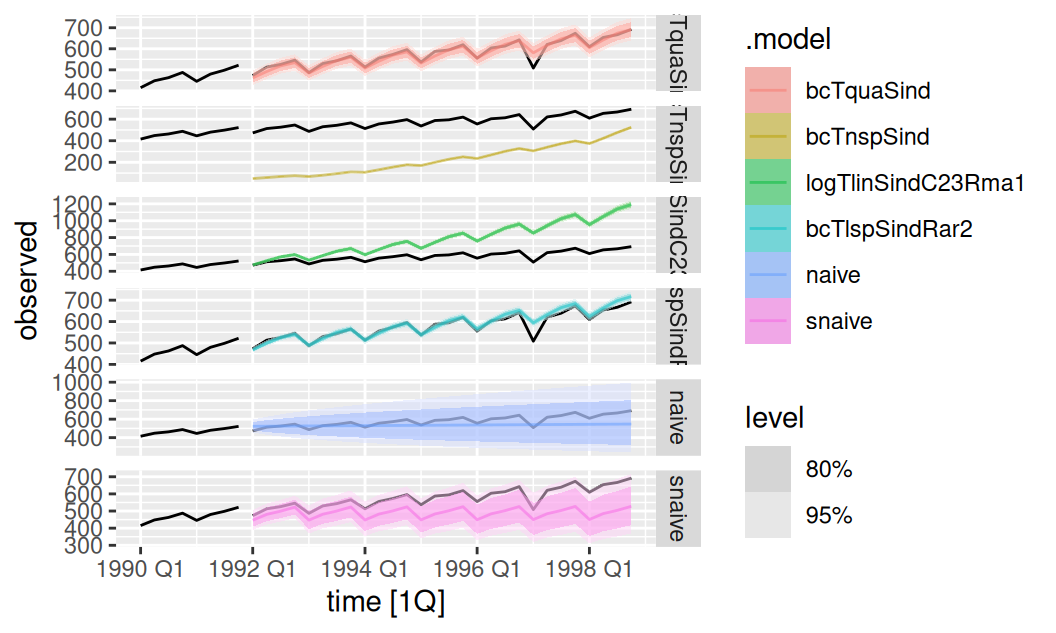
Vidíme, že model s najnižšou popisnou schopnosťou (obsahujúci kvadratický trend) dosahuje najpresnejšie predpovede. Náš predpoklad o tlmení lineárneho trendu bol teda správny. Veľmi podobne však uspel aj model s lineárnym splajnom. Naopak, najhoršie skončil model s linárnym trendom, ktorého nezachránilo ani zaradenie člena pre cyklickú zložku. Je dokonca horší ako naivné predpovede.
Pri predpovediach pomocou prirodzeného splajnu sme zaznamenali chybu v implementácii metódy funkcie forecast. Funkcia splines::ns (podobne ako poly v štandardnom nastavení raw=FALSE) vracia hodnoty ortogonálnych bázových funkcií, a zrejme s tým má forecast.TSLM problém.
fore$mult |>
fabletools::accuracy(dat$valid) |>
dplyr::select(.model:MAPE) |>
dplyr::mutate(across(where(is.numeric), ~round(.x,3))) # A tibble: 6 × 7
.model .type ME RMSE MAE MPE MAPE
<fct> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 bcTquaSind Test 3.18 16.7 10.2 0.528 1.85
2 bcTnspSind Test 352. 364. 352. 62.4 62.4
3 logTlinSindC23Rma1 Test -209. 254. 209. -34.4 34.4
4 bcTlspSindRar2 Test -7.66 20.3 12.2 -1.27 2.11
5 naive Test 45.0 68.7 55.7 6.94 9.12
6 snaive Test 90.4 101. 90.4 15.1 15.1 tmp <- fit$selected |>
generics::refit(new_data = dat$valid)
tmp |>
generics::augment() |>
dplyr::mutate(.model = factor(.model, levels = names(fit$selected))) |> # reorder
ggplot() + aes(x = time) +
geom_line(aes(y = observed)) +
geom_line(aes(y = .fitted, color = .model)) +
facet_grid(rows = vars(.model))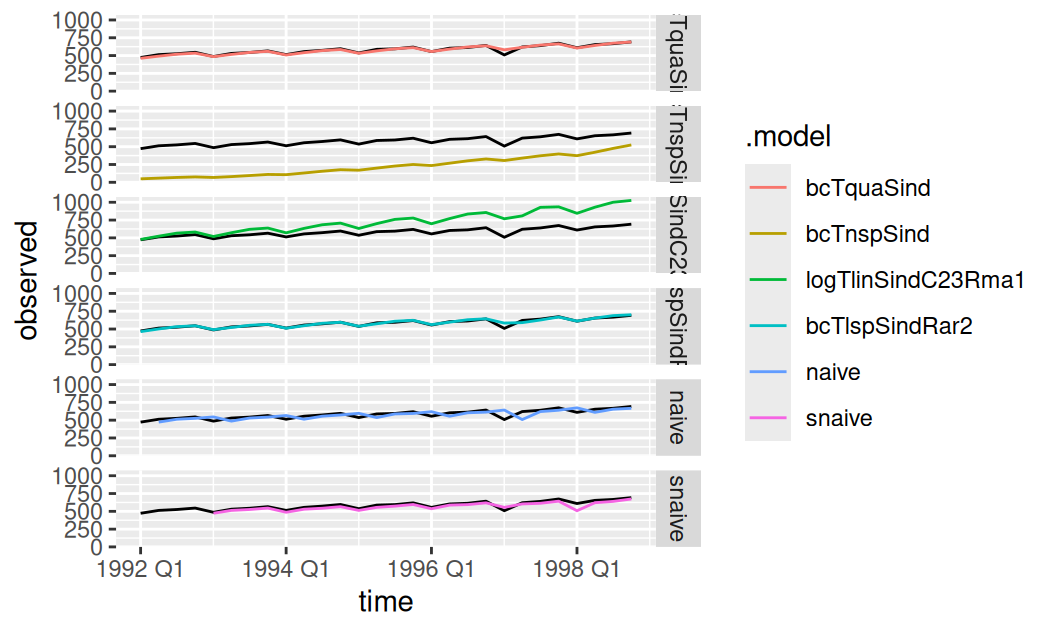
Aj pri jednokrokových predpovediach sa prejavila chyba v implementácii pri modeli s prirodzeným splajnom. Poradie modelov z hľadiska presnosti 1-krokových predpovedí je rovnaké ako pri viackrokových, samnotná presnosť je však pri všetkých dynamických modeloch oveľa vyššia (samozrejme vrátane naivných).
tmp |>
generics::accuracy() |>
dplyr::mutate(.model = factor(.model, levels = names(fit$selected))) |> # ordering
dplyr::mutate(.type = "Test") |> # correct the sample label
dplyr::mutate(across(where(is.numeric), ~round(.x,3)))# A tibble: 6 × 10
.model .type ME RMSE MAE MPE MAPE MASE RMSSE ACF1
<fct> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 bcTnspSind Test 352. 364. 352. 62.4 62.4 12.8 11.3 0.831
2 bcTquaSind Test 3.49 16.7 10.4 0.582 1.87 0.379 0.518 -0.056
3 logTlinSindC23Rm… Test -148. 177. 148. -24.3 24.3 5.37 5.49 0.832
4 bcTlspSindRar2 Test -2.40 17.7 10.5 -0.456 1.86 0.381 0.547 -0.264
5 naive Test 8.13 49.7 40.2 1.02 7.08 1.46 1.54 -0.523
6 snaive Test 23.6 32.3 27.5 3.90 4.66 1 1 0.176To, že sme jednoduchým modelom s kvadratickým trendom dosiahli najlepšie výsledky, môže byť bez hlbšej znalosti časového radu do značnej miery iba náhoda. Navyše, model predpokladá ďalšie spomalovanie rastu, čo by v dlhodobom horizonte tento model zásadne znevýhodňovalo.
Videli sme, že metódy funkcií forecast a refit si nedokázali poradiť s predpovedaním pomocou konštruktora spline::ns. Je to preto, že na extrapoláciu regresnej matice do validačného obdobia používajú klasický spôsob, teda rovnakú funkciu ako pre trénovacie obdobie. Klasika funguje pri všetkých bázach, kde nedochádza ku ortogonalizácii. Videli sme, že ortoogonalizácii sa dá pri konštruktore polynomických báz poly zabrániť argumentom raw.
Ortogonalizácia však má svoj význam a navyše pri prirodzenom splajne konštruktorom ns sa nedá obísť. V takých prípadoch je potrebné použiť metódu funkcie predict, tu konkrétne predict.ns.
Prvým krokom opravy predpovede z modelu bcTnspSind je teda konštrukcia správnej matice plánu pre validačné obdobie. Okrem prirodzeného splajnu musí obsahovať aj stĺpce pre sezónnu zložku. Vo formuli modelu sme ich vytvorili regesorom season(), ktorý však tu, v manuálnom prístupe, nie je priamo použiteľný ale môžeme siahnuť po metóde season.tbl_ts a funkcii as_model_matrix definovaných v balíku fable interne. Detailnejšie je o tejto téme písané neskôr, v časti o interpretácii modelu rekonštrukciou bázových funkcií.
# function to construct design matrix for natural spline and indicator seasonals
# in: x - a tsibble, new data to feed basis functions
# df - integer, degrees of freedom
# knots - vector of time points in the same format as index variable of x
# period - either integer or string understood by the package tools
# train - a tsibble, data used when fitting this model
# out: matrix
make_regX_TnspSind <- function(x, df = 1, knots = NULL, period = "1 year", train = x) {
if(!is.null(knots)) df <- NULL
cbind(
1,
splines::ns(train$time, df = df, knots = knots) |> predict(x$time),
fable:::season.tbl_ts(x, period = period) |> # factor
fable:::as_model_matrix() # alter: _[[1]] |> {\(x) contrasts(x)[x,]}()
) |> as.matrix()
}
# create regression matrices for training and validation set
regXtrain_TnspSind <- make_regX_TnspSind(dat$train, df = 10)
regXvalid_TnspSind <- make_regX_TnspSind(dat$valid, train = dat$train, df = 10)Druhý krok tvorí výpočet rozdelenia predpovedí vrátane spätnej Box-Coxovej transformácie a prepísanie chybných hodnôt v stĺpcoch observed (celé rozdelenie) a .mean (iba stredná hodnota).
# Model parameters can be extracted from `fit` object and used below.
# params <- fit$selected |>
# dplyr::select(bcTnspSind) |>
# coef() |>
# dplyr::pull(estimate)
# Forecast distribution including inverse Box-Cox transformation
tmp <- local({
y <- fabletools::box_cox(dat$train$observed, lambda) # response transformed
Xt <- regXtrain_TnspSind # design matrix in training period
Xv <- regXvalid_TnspSind # design matrix in validation per.
invXX <- solve(t(Xt) %*% Xt)
b <- invXX %*% t(Xt) %*% y # parameters b = params$estimate
yhat <- Xt %*% b # fitted values
ypred <- c(Xv %*% b) # predicted values
# s2t = fit$selected$bcTnspSind[[1]]$fit$sigma2
s2t <- c( t(y - yhat) %*% (y - yhat) ) / (nrow(Xt) - ncol(Xt)) # res.variance
s2v <- diag( s2t * ( 1 + Xv %*% invXX %*% t(Xv) ) )
distributional::dist_transformed(
dist = distributional::dist_normal(ypred, sqrt(s2v)),
transform = function(x) fabletools::inv_box_cox(x, lambda),
inverse = function(x) fabletools::box_cox(x, lambda)
)
#distributional::dist_normal(ypred, sqrt(s2v))
}) |>
`dimnames<-`("observed")
# Extract mean value in original scale
# tmp1 <- tmp |>
# lapply(unlist) |>
# sapply(function(x) x$inverse(x$dist.mu))
# Replace wrong records in `fore$mult`
fore$mult[fore$mult$.model == "bcTnspSind", c("observed", ".mean")] <-
tibble::tibble(observed = tmp, .mean = mean(tmp))Posledný krok je zobrazenie predpovedí a výpčet predpovedných chýb.
# Display
fore$mult |>
dplyr::filter(.model == "bcTnspSind") |>
autoplot(color = scales::hue_pal()(length(fore$mult))[2]) +
autolayer(dat$valid, observed) +
autolayer(dplyr::filter(dat$train, tsibble::yearquarter("1989 Q4") < time), observed)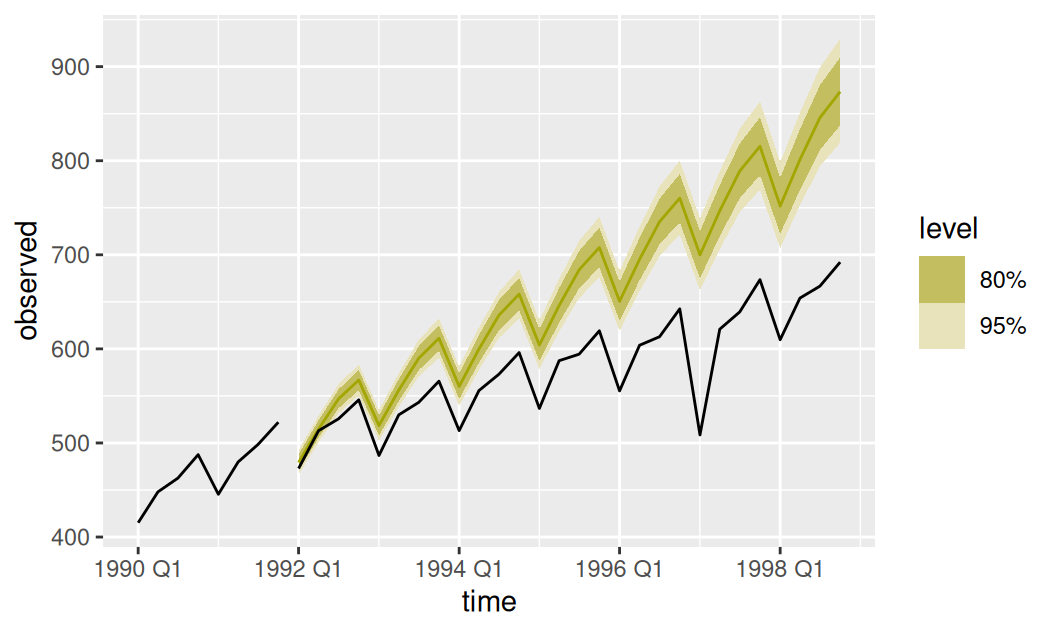
fore$mult |>
dplyr::filter(.model == "bcTnspSind") |>
fabletools::accuracy(dat$valid) |>
dplyr::select(.model:MAPE) |>
dplyr::mutate(across(where(is.numeric), ~round(.x,3))) # A tibble: 1 × 7
.model .type ME RMSE MAE MPE MAPE
<fct> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 bcTnspSind Test -85.9 102. 85.9 -14.3 14.3Trend v nasledujúcom období sa nám týmto modelom zjavne nepodarilo vystihnúť, pretože vývoj HDP výrazne nadhodnocuje, hoci nie až tak prehnane, ako model s lineárnym trendom a cyklickou zložkou (RMSE = 254).
Okrem predpovedania sa model používa aj na porozumenie mechanizmu, ktorý časový rad generoval. To vyžaduje analýzu jednotlivých zložiek matematického modelu. Žiaľ, extrakcia (systematických) zložiek z výstupu funkcie TSLM nie je v momentálnej verzii implementovaná.
Vezmime si model s lineárnym splajnom. Jeho formula prezrádza, že obsahuje tri zložḱy: lineárnu lomenú funkciu s dvoma uzlami, sezónnosť s indikačnými premennými a autoregresný model reziduálnej zložky stupňa 2:
fit$selected$bcTlspSindRar2[[1]]$model |> formula()fabletools::box_cox(observed, lambda) ~ trend(knots = knots_lsp) +
season() + pdq(2, 0, 0) + PDQ(0, 0, 0)Počet členov v každej zložke je zjavný z výpisu parametrov modelu:
params <- fit$selected |>
dplyr::select(bcTlspSindRar2) |>
coef() |>
dplyr::select(term:estimate) |>
print()# A tibble: 9 × 2
term estimate
<chr> <dbl>
1 ar1 0.421
2 ar2 0.352
3 trend(knots = knots_lsp)trend 0.0618
4 trend(knots = knots_lsp)trend_25 0.0328
5 trend(knots = knots_lsp)trend_61 -0.0319
6 season()year2 0.252
7 season()year3 0.455
8 season()year4 0.541
9 intercept 6.56 Na zrekonštruovanie matice plánu je potrebné poznať definície metód jednotlivých pomocných funkcií. Tie sú interné a je náročné ich objaviť štandardnými cestami (napr. nefunguje funkcia methods ani príkaz .S3methods("season", envir = asNamespace("fable"))). Iba zo zdrojového kódu (súbor 00_specials.R) vieme, že pre season aj trend existuje metóda *.tbl_ts, ktorá vzápätí volá metódu *.numeric. Tá pre trend implementuje do-počiatku-posunuté a nulou-orezané lineárne bázové funkcie pmax(0,x-knot), zatiaľčo sezónnosť kóduje ako factor (ktorý je neskôr, pred samotným odhadom konvertovaný ma indikačné bázové funkcie).
# run if curious
fable:::trend.tbl_ts
fable:::trend.numeric
fable:::season.tbl_ts
fable:::season.numericVytvoríme funkciu na vytvorenie matice plánu pre model s lineárnym splajnom a sezónnosťou podľa hodnôt jej argumentov: uzlov (knots), počiatku (origin) a periódy. Počiatok je potrebný pre zabezpečenie kompatibility s odhadmi prametrov a štandardne je nastavený na prvú hodnotu dodaného datasetu (pri využití funkcie na predpovedanie je potrebné manuálne nastaviť počiatok na prvú hodnotu trénovacej vzorky).
Pre čo najlepšie využitie balíku fable budú na konštrukciu použité jeho vlastné externé regresory (funkcie skupiny common_xregs), no pre ilustráciu uvádzame aj manuálnu konštrukciu. Tak bude prípadná modifikácia funkcie na iné (aj neštandardné) typy trendov, sezónnosti a cyklicity už pomerne jednoduchá.
# function to construct design matrix for linear spline and indicator seasonals
# in: x - a tsibble
# knots - vector of time points in the same format as index variable of x
# origin - single time point in the same format as index variable of x
# period - either integer or string understood by the package tools
# out: matrix
make_regX_TlspSind <- function(x, knots, origin = NULL, period = "1 year") {
if(is.null(origin)) origin <- x$time[1]
cbind(
1,
fable:::trend.tbl_ts(x, knots = knots, origin = origin),
fable:::season.tbl_ts(x, period = period) |> # factor
fable:::as_model_matrix() |> # alter: _[[1]] |> {\(x) contrasts(x)[x,]}()
(`rownames<-`)(NULL)
) |> as.matrix()
}
# manual construction of model/design matrix using formula (assuming period = 4)
#
# make_regX_TlspSind <- function(x, knots, origin = NULL) {
# if(is.null(origin)) origin <- x$time[1]
# paste(
# "~", # equal sign
# "I(time - origin + 1) +", # linear trend
# "pmax(0, time - knots[1]) + pmax(0, time - knots[2]) +", # linear spline
# "as.factor(lubridate::quarter(time))" # seasonality (L=4)
# ) |>
# as.formula() |>
# model.matrix(data = x)
# }
# make regression matrix with training set
regX_TlspSind <- make_regX_TlspSind(dat$train, knots_lsp)
# show first lines
regX_TlspSind |>
head(4) 1 trend trend_25 trend_61 season_42 season_43 season_44
[1,] 1 1 0 0 0 0 0
[2,] 1 2 0 0 1 0 0
[3,] 1 3 0 0 0 1 0
[4,] 1 4 0 0 0 0 1Prvé štyri stĺpce zodpovedajú trendu (vrátane absolútneho členu), zvyšné tri sezónnosti. Toto spolu s indexami zodpovedajúcich prvkov vektora parametrov zapíšeme do zoznamu a použijeme pre odhad stredných hodnôt jednotlivých zložiek.
# component basis indices in
# - parameter vector from mable
# - regression matrix
ind_comp <- list( # component indices in ...
param = list(trend = c(9,3:5), season = 6:8, ar=1:2), # parameter vector
regmat = list(trend = 1:4, season = 5:7) # regression matrix
)
# component mean values in transformed scale (bc*) and in original scale
dat$train <- dat$train |>
dplyr::mutate(
bcTlsp = regX_TlspSind[,ind_comp$regmat$trend] %*% params$estimate[ind_comp$param$trend],
Tlsp = bcTlsp |> fabletools::inv_box_cox(lambda),
bcSind = regX_TlspSind[,ind_comp$regmat$season] %*% params$estimate[ind_comp$param$season],
Sind = fabletools::inv_box_cox(bcTlsp + bcSind, lambda) - Tlsp
)Zatiaľčo pri modelovaní bolo lepšie pracovať v transformovanej mierke, z hľadiska interpretovateľnosti modelu je vhodnejšie zobrazovať zložky v pôvodnej mierke.
# Trend
dat$train |>
ggplot() + aes(x = time) +
geom_line(aes(y = observed)) +
geom_line(aes(y = Tlsp), color = 4) +
labs(title = "Piecewise linear trend")
# Seasonal
dat$train |>
ggplot() + aes(x = time) +
geom_line(aes(y = observed - Tlsp)) +
geom_line(aes(y = Sind), color = 4) +
labs(title = "Seasonality (Sind)", y = "value around trend")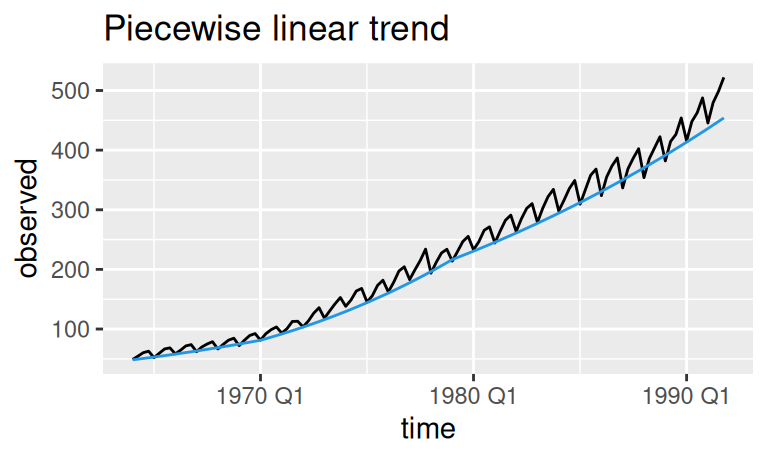
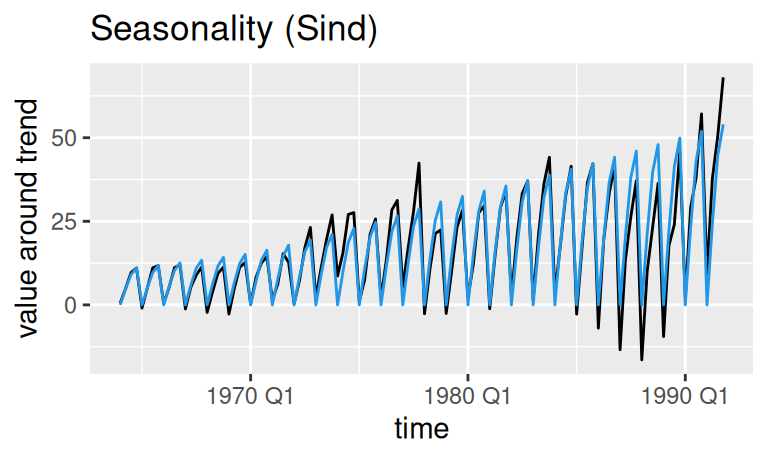
Trend \(T_t\) má zjavne tri fázy rastu ohraničené uzlami . V každej z nich kvôli spätnej transformácii nerastie konštantne, ale má kladnú druhú deriváciu, čiže rast zrýchľuje. Napr. posledný segment trendu (od roku 1979) má rovnicu \[ \begin{split} \frac{T_t^\lambda-1}\lambda &= (6.55 - 0.0328\cdot25 + 0.0318\cdot61) + (0.0618 + 0.0328 - 0.0318) t \\ T_t &= \Big(\lambda (7.67 + 0.0628 t) + 1\Big)^{1/\lambda} \end{split} \]
pričom premenná \(t\) je počet kvartálov od počiatku časového radu, takže medziročný nárast v poslednom roku je \(T_{112}-T_{108} = 23.6\) a medziročné tempo rastu (growth rate) je \((T_{112}-T_{108})/T_{108} = 5.5\)%.
Model sezónnej zložky \(S_t\) a jej vzťah ku trendu môžeme vyjadriť rovnicami \[ \begin{split} \hat S'_t &= \begin{cases} 0 \quad\text{pre obdobie} & Q1 \\ 0.252 & Q2 \\ 0.455 & Q3 \\ 0.541 & Q4 \\ \end{cases} \\ BC_{\lambda}(T_t + S_t) &= T'_t + S'_t \\ S_t &= BC_{\lambda}^{-1}(T'_t + S'_t) - T_t \end{split} \] pričom samozrejme \(T'_t = BC_{\lambda}(T_t)\).
dat$train |>
# dplyr::mutate(case_when(
# time < tsibble::yearquarter("1965 Q1") ~ "1965"
# ))
dplyr::slice(1:4, 109:112) |>
tidyr::separate_wider_delim(time, delim = " ", names = c("year", "quarter")) |>
ggplot() + aes(x = quarter, y = Sind, color = year, group = year) +
geom_line() +
labs(title = "Seasonality in one period (Sind)", y = "value around trend")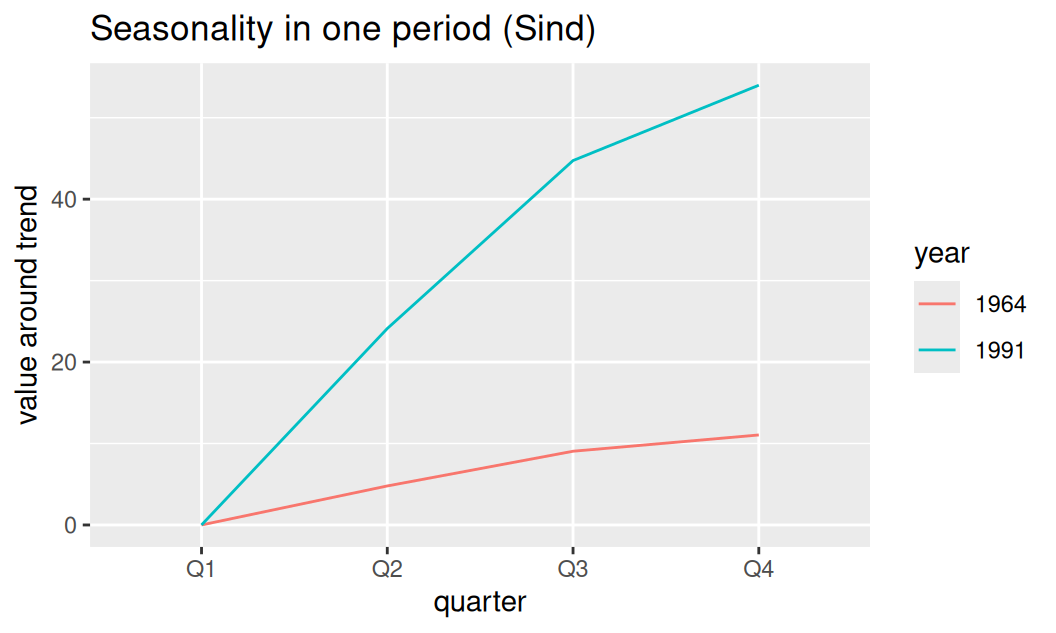
Prvý kvartál je referenčný, rozdiely oproti trendu HDP v priebehu kalendárneho roka rastú, najväčší prírastok je v štvrtom kvartáli. Rozptyl sezónnej zložky rastie so strednou hodnotou, preto je najväčší sezónny výkyv v roku 1964 iba 21, zatiaľčo na konci trénovacieho obdobia až 55.
Reziduálnu zložku tvorí AR(2) proces. Prakticky sa dá vyjadriť ako rozdiel pozorovaných hodnôt, systematických zložiek a rezíduí plného modelu \(\varepsilon_t\), \[ \begin{split} R'_t &= 0.42 R'_{t-1} + 0.35 R'_{t-2} + \varepsilon'_t \\ R_t &= x_t - T_t - S_t - \varepsilon_t \end{split} \]
tmp <- fit$full |>
dplyr::select(bcTlspSindRar2) |>
generics::augment() |>
dplyr::bind_cols(dat$train[c("Tlsp", "Sind")]) |> # add systematic components
dplyr::mutate(Rar2 = observed - Tlsp - Sind - .resid)
tmp |> ggplot() +
aes(x = time, y = Rar2) + geom_line() +
labs(title = "Residual component (Rar2)", y = "value around trend and seasonal")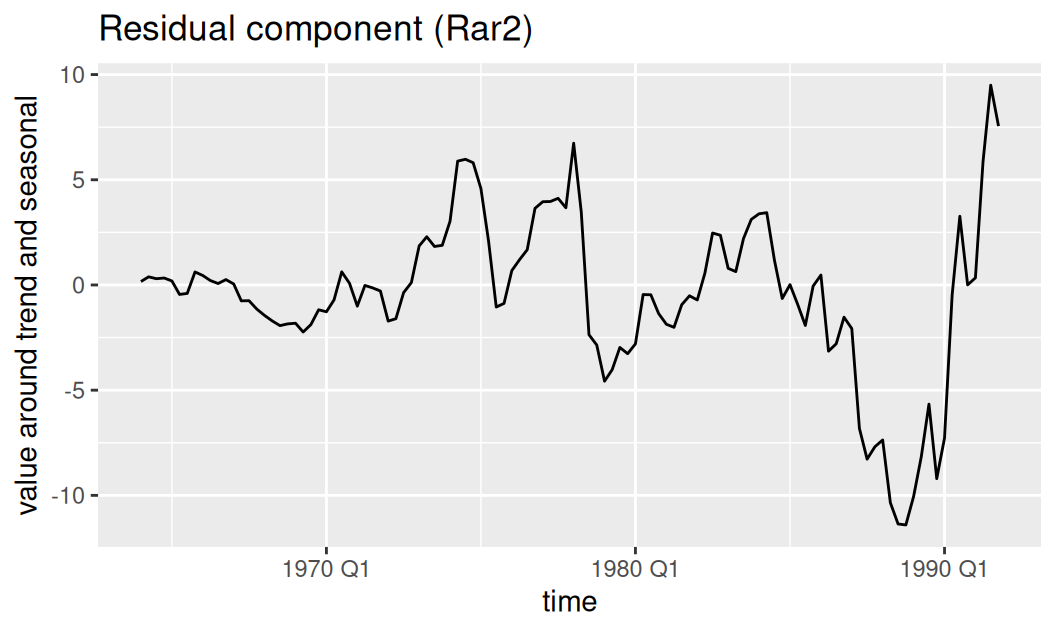
I keď v pôvodnej mierke je nestacionárny, samotný AR proces je stacionárny, o čom svedčia aj korene AR polynómu, ktoré v komplexnej rovine ležia mimo jednotkového kruhu (v absolútnej hodnote sú väčšie ako 1).
fit$full |>
dplyr::select(bcTlspSindRar2) |> # feasts::gg_arma()
generics::glance() |>
dplyr::pull(ar_roots) |>
_[[1]] |>
abs() |>
round(2) |> setNames(paste0("root", 1:2))root1 root2
1.19 2.39 Parametre modelu napovedajú, že náhodné fluktuácie okolo trendu a sezónnosti majú polročnú pamäť (vplyv dvoch predošlých hodnôt je pomerne vyrovnaný a slabý).
Interpretáciu dekompozičných modelov je možné vykonať aj nepriamo. Všetky regresné modely majú približne rovnakú popisnú schopnosť, ktorá je porovnateľná s adaptívnymi metódami dekompozície.3 A keďže dostať sa ku zložkám adaptívnych modelov je veľmi jednoduché (aspoň v transformovaniej mierke), použijeme teraz model s Box-Coxovou transformáciou na analýzu jednotlivých zložiek časového radu.
# container
comp <- list()
# omponents in BC scale
comp$bc <- fit$adapt |>
dplyr::select(bcAdd) |>
generics::components()
comp$bc# A dable: 112 x 7 [1Q]
# Key: .model [1]
# : fabletools::box_cox(observed, lambda) = trend + seasonal + random
.model time fabletools::box_cox(ob…¹ trend seasonal random season_adjust
<chr> <qtr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 bcAdd 1964 Q1 6.65 NA -0.312 NA 6.96
2 bcAdd 1964 Q2 6.94 NA -0.0599 NA 7.00
3 bcAdd 1964 Q3 7.23 7.06 0.145 0.0216 7.08
4 bcAdd 1964 Q4 7.34 7.11 0.227 0.00470 7.12
5 bcAdd 1965 Q1 6.82 7.18 -0.312 -0.0482 7.13
6 bcAdd 1965 Q2 7.18 7.24 -0.0599 -0.00389 7.24
7 bcAdd 1965 Q3 7.51 7.31 0.145 0.0498 7.36
8 bcAdd 1965 Q4 7.59 7.38 0.227 -0.0195 7.36
9 bcAdd 1966 Q1 7.14 7.44 -0.312 0.00905 7.45
10 bcAdd 1966 Q2 7.41 7.49 -0.0599 -0.0212 7.47
# ℹ 102 more rows
# ℹ abbreviated name: ¹`fabletools::box_cox(observed, lambda)`Zložky sú zatiaľ v takej mierke, v ktorej boli separovateľné aditívne, takže teraz je potrebné dostať ich do pôvodnej mierky HDP.
comp$orig <- comp$bc |>
dplyr::rename(observed = "fabletools::box_cox(observed, lambda)") |>
dplyr::mutate(
trend_seas = trend + seasonal,
trend_rand = trend + random,
across(c(observed, dplyr::starts_with("trend")),
~fabletools::inv_box_cox(.x, lambda)),
seasonal = trend_seas - trend,
random = trend_rand - trend
) |>
dplyr::select(-season_adjust, -trend_seas, -trend_rand)
comp$orig |>
tidyr::pivot_longer(c(observed, trend, seasonal, random),
names_to = "series",
names_transform = list(series = forcats::as_factor)
) |>
ggplot() + aes(x = time, y = value) + geom_line() +
facet_grid(rows = vars(series), scales = "free_y")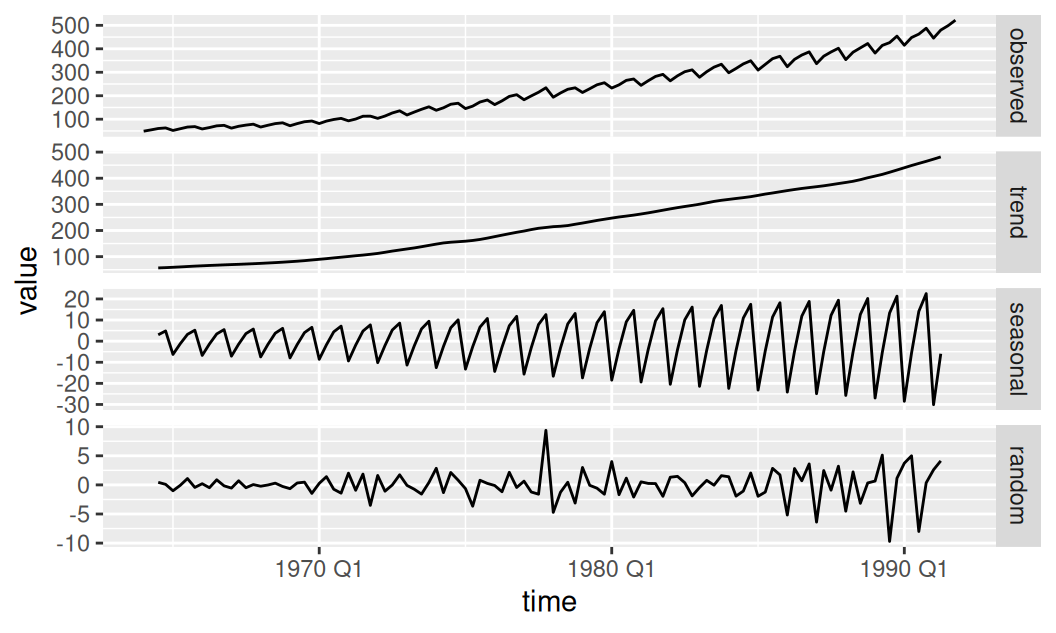
Keďže na rozklad bola použitá metóda kĺzavých priemmerov s oknom širokým jednu periódu, komponenty časového radu majú na oboch stranách dve chýbajúce hodnoty.
comp$orig |>
dplyr::mutate(diff1 = c(NA, diff(trend)),
diff2 = c(NA, NA, diff(trend, differences = 2))
) |>
tidyr::pivot_longer(c(trend, diff1, diff2),
names_to = "series",
names_transform = list(series = forcats::as_factor)
) |>
ggplot() + aes(x = time, y = value) + geom_line() +
facet_grid(rows = vars(series), scales = "free_y")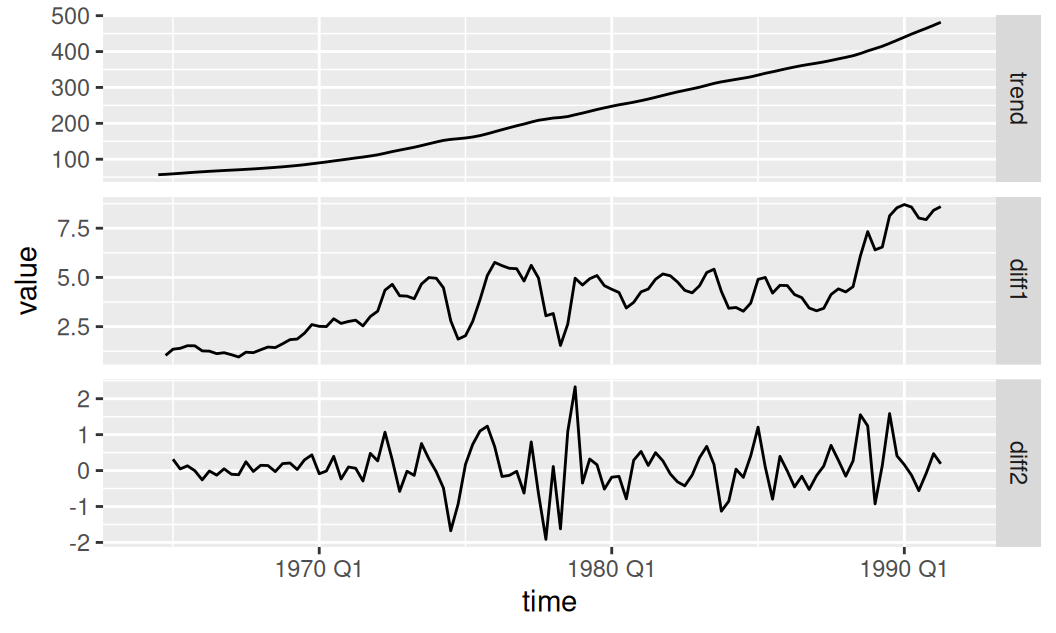
Trend má približne tri obdobia rastu: do roku 1970 bol medziročný nárast HDP v priemere približne 10 menových jednotiek, potom dlhé obdobie do roku 1989 v priemere cca 15 menových jednotiek a v nasledujúcich dynamických rokoch poskočil na 20. Z hľadiska krátkodobých zmien boli v histórii dva významné okamihy poklesu veľkosti rastu: prvý v roku 1974, druhý koncom roku 1977 a v priebehu 1978. V oboch prípadoch sa rast spomalil až o \(10 mj/rok\). Bolo by zaujímavé zistiť, čo stálo za tak prudkými zmenami.
comp$orig |>
dplyr::mutate(diff2r = c(rep(NA, 4*2), diff(trend, lag=4, differences = 2))) |>
dplyr::select(time, diff2r) |>
dplyr::slice_min(order_by = diff2r, n = 2, na_rm = TRUE) |>
dplyr::arrange(time)# A tsibble: 2 x 2 [1Q]
time diff2r
<qtr> <dbl>
1 1975 Q2 -9.62
2 1978 Q3 -10.4 Amplitúda sezónnej zložky rástla so strednou hodnotou. Keďže nemáme k dispozícii všetky hodnoty krajných rokov, zobrazíme sezónnu zložku v susedných rokoch.
tmp <- comp$orig |>
tidyr::separate_wider_delim(time, delim = " ", names = c("year", "quarter"),
cols_remove = FALSE) |>
dplyr::filter(year %in% c("1965", "1990"))
tmp |>
ggplot() + aes(x = quarter, y = seasonal, color = year, group = year) +
geom_line() +
labs(title = "Seasonality in one period", y = "value around trend")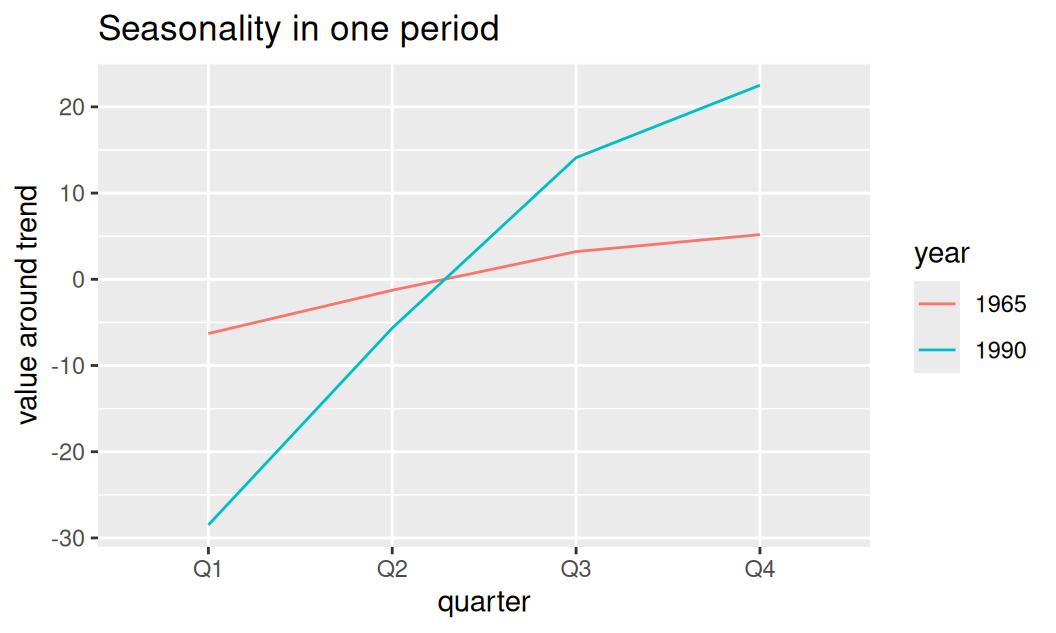
Prvé dva kvartály sú z hladiska HDP podpriemerné, najväčší rozdiel je medzi prvým a štvrtým.
tmp |>
dplyr::summarize(range = diff(range(seasonal)), .by = year)# A tibble: 2 × 2
year range
<chr> <dbl>
1 1965 11.5
2 1990 51.0Na začiatku je rozdiel cca 10mj, na konci trénovacieho obdobia cca 50mj, čo predstavuje priemerný medziročný nárast o 1.6 menových jednotiek. Nárast však nie je lineárny, pretože závisí od trendu, ktorý tiež nie je lineárny.
Posledná, reziduálna zložka prezrádza tri výnimočne veľké výkyvy oproti normálu.
comp$orig |>
dplyr::slice_max(order_by = abs(random), n = 3) |>
dplyr::mutate(rand2seas = random/seasonal) |>
dplyr::select(time, random, rand2seas) |>
dplyr::arrange(time)# A tsibble: 3 x 3 [1Q]
time random rand2seas
<qtr> <dbl> <dbl>
1 1977 Q4 9.37 0.745
2 1989 Q3 -9.70 -0.728
3 1990 Q3 -8.00 -0.567Prvý výkyv je z roku 1977, kedy hodnota HDP v poslednom kvartáli vystrelila o 70% nad sezónny priemer. Ostatné dva výkyvy sú z Q3 posledných dvoch rokov, kedy došlo v priemer ku 60% poklesu HDP oproti sezónnemu priemeru.
(under construction)
(under construction)
Balík tsibble prispôsobuje dátové objekty tibble (trieda tbl_df) špecifickosti časových radov, výsledkom je nový formát tsibble (trieda tbl_ts, viac o ňom na stránke https://otexts.com/fpp3/tsibble-objects.html). Umožňuje využívať funkcie balíkov feasts, fable či fabletools.↩︎
Pri metóde boostrap sa šum použitý pri odhade predpovedných trajektórií generuje náhodným výberom z rezíduí modelu.]↩︎
Žiaľ, k presnosti sa nedá dopracovať funkciou accuracy, pretože vedie ku chybe.↩︎