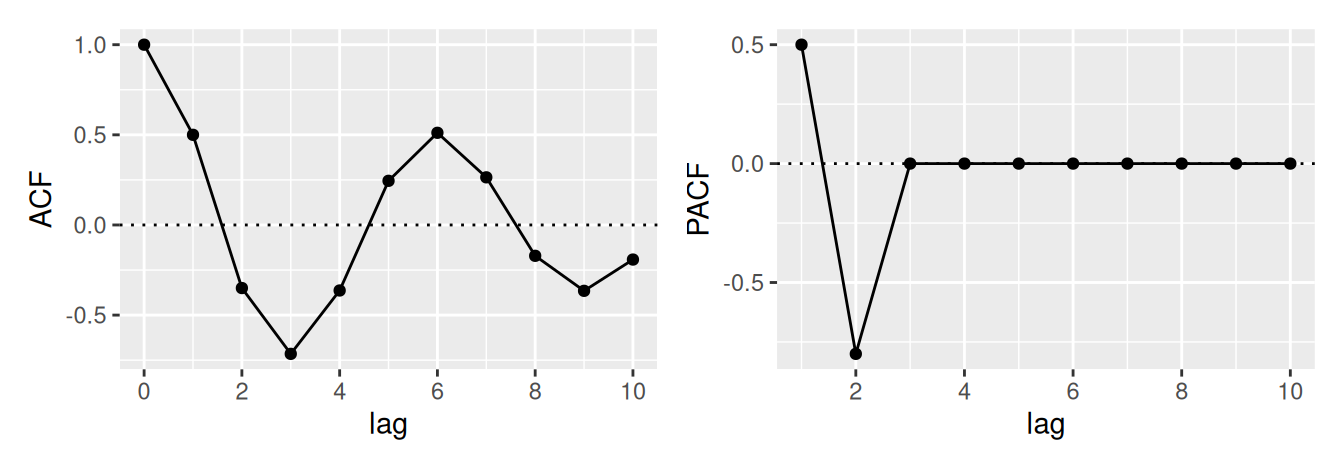
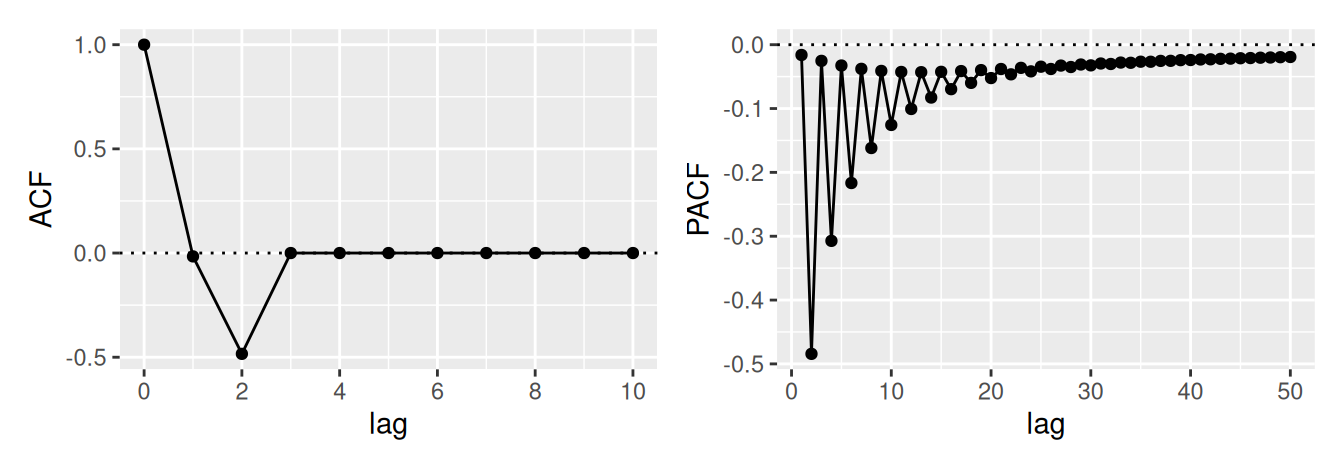
Ukázali sme, že ak reziduálnu zložku možno považovať za lineárnu kombináciu postupnosti nekorelovaných rovnako rozdelených náhodných premenných \(\varepsilon_t\), vieme ju popísať triedou modelov ARMA, ktoré určíme pomocou tzv. Box-Jenkinsovej metodológie. Je to relatívne starý matematický aparát, prvý raz bol popísaný v r. 1976, no dodnes sa často uplatňuje pri modelovaní ČR. Ako sme videli, za základ analýzy berie reziduálnu zložku tvorenú korelovanými (alebo závislými) náhodnými premennými.
Ako nevýhody sa uvádza napr. to, že
Praktický postup určenia modelu daného časového radu v rámci Box-Jenkinsovej metodológie zahŕňa tri kroky:
Identifikácia modelu
Identifikovať model znamená určiť vonkajšie parametre (nazývané aj hyper-parametre), teda tie, ktoré sa nedajú odhadnúť klasickou optimalizačnou metódou spolu s vnútornými parametrami. V kontexte modelov ARMA ide o stupne AR a MA polynómov (\(p,q\)). Používajú sa dve metódy:
- neparametrická - pomocou odhadov ACF a PACF,
- parametrická - prostredníctvom informačných kritérií.
Neparametrická
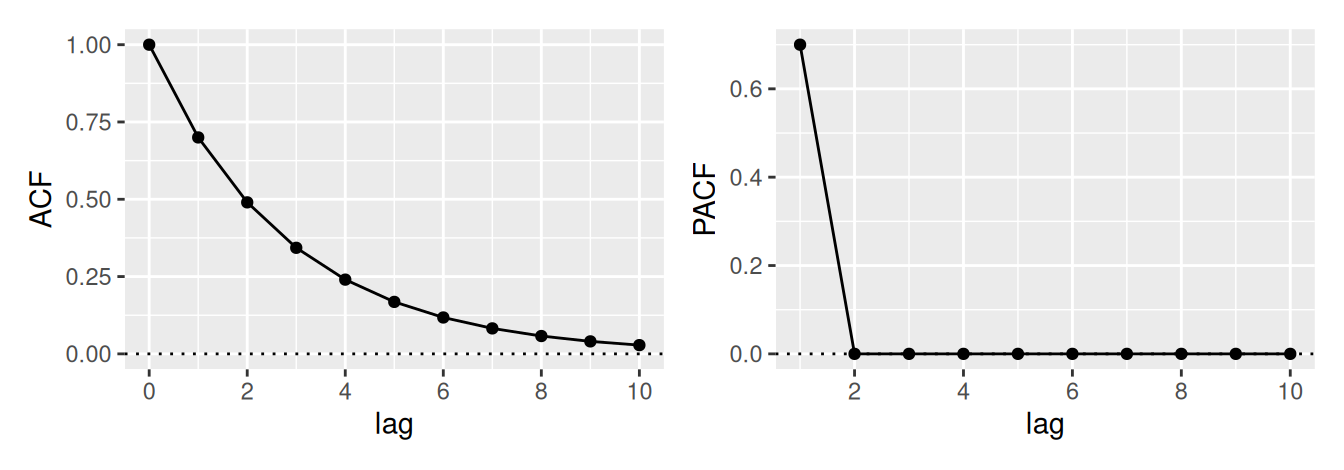
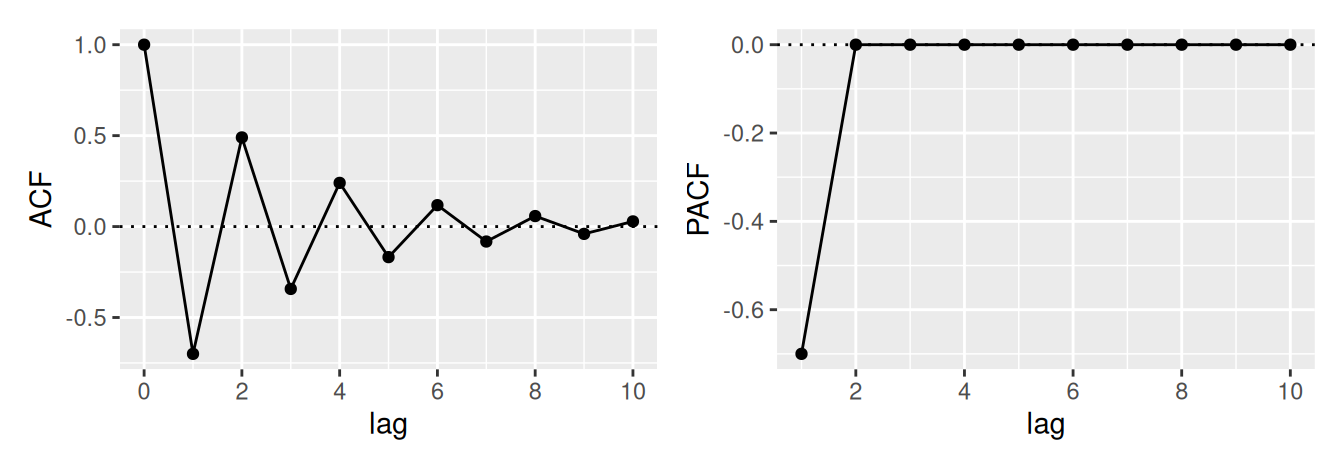
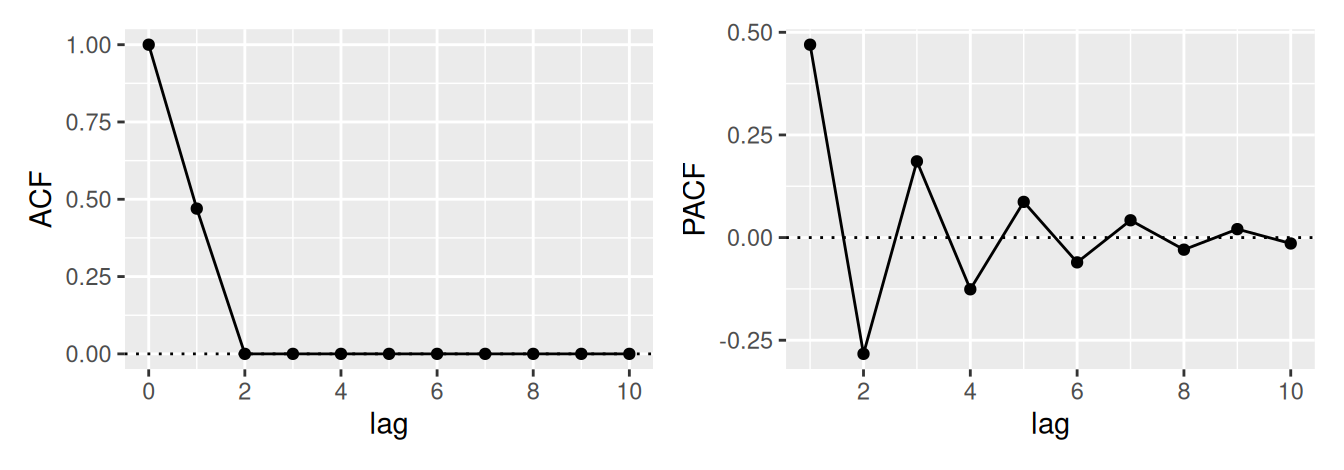
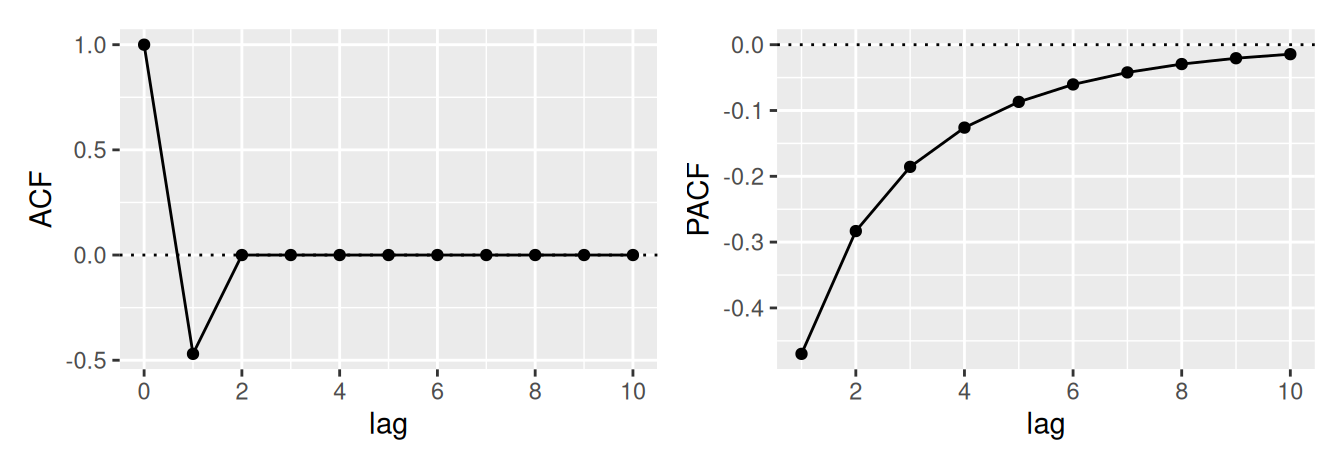
V neparametrickom prístupe využijeme informácie z predošlej podkapitoly a na základe priebehu výberovej ACF \(\hat\rho(k)\) a PACF \(\hat\rho^*(k)\) určíme typ a stupeň vhodného modelu, pre zhrnutie pozri Tab. 3.1.
Bod useknutia \(k_0\) tu predstavuje najväčšiu hodnotu časového posunu, pre ktorý je ACF, resp. PACF ešte nenulová. Na určenie \(k_0\) v teste nulovosti hodnôt ACF sa môže použiť presnejšia, Bartlettova aproximácia rozptylu výberovej autokorelácie, ktorá (namiesto bieleho šumu) predpokladá proces MA(\(k_0\)). Potom \[
|\hat\rho(k)|<2\sqrt{\frac1n(1+2\sum_{i=1}^{k_0}\hat\rho(j)^2)}\quad\text{pre } k>k_0
\] na hladine významnosti 5%.
Pre test nulovosti PACF je k dispozícii iba doteraz používaná, tzv. Quenouilleova aproximácia, ktorá v nulovej hypotéze predpokladá biely šum. Takže ak \(H_0\) platí, potom asymptoticky \[
\hat\rho^*(k) \sim N\left(0, \frac1n\right) \quad\text{pre } k>k_0.
\]
Prirodzene, ak je ACF všade blízke 0, časový rad je pravdepodobne realizáciou procesu bieleho šumu. Naopak, ak je pokles k nule veľmi pomalý, proces je nestacionárny.
Parametrická
V parametrickom prístupe sa najprv určia horné hranice \(p_{max}\) a \(q_{max}\) pre správny stupeň modelu ARMA(\(p,q\)). Ak by bol odhad hyperparametrov \(p,q\) založený iba na minimalizácii odhadu rozptylu \(\hat{\sigma}_{p,q}^2\) chybovej zložky procesu ARMA(\(p,q\)), preferoval by neúmerne vysoké hodnoty. Namiesto toho je lepšie minimalizovať funkciu \[
A_{p,q} = (1 + w_n(p, q) )*\hat{\sigma}_{p,q}^2, \qquad p = 0, 1, ..., p_{max}, \quad q = 0, 1, ..., q_{max},
\] kde \(w_n(p, q)\) je tzv. penalizačná funkcia, ktorá znevýhodňuje voľbu príliš veľkého stupňa modelu a musí mať tieto dve vlastnosti:
- pri pevnej dĺžke č.radu \(n\) musí byť rastúca funkcia argumentov \(p\) a \(q\)
- pri pevných hodnotách \(p\) a \(q\) musí pre rastúce \(n\) konvergovať k 0.
Voľbou \(w_n(p, q)\) a zlogaritmovaním \(A_{p,q}\) vznikne konkrétne kritérium, najčastejšie používané sú:
- Akaikeho informačné kritérium \(AIC(p,q)=\ln(\hat{\sigma}_{p,q}^2) + (p+q) \frac{2}{n}\),
- Bayesovské informačné kritérium \(BIC(p,q)=\ln(\hat{\sigma}_{p,q}^2) + (p+q) \frac{\ln(n)}{n}\).
Ak sa z nejakého dôvodu obmedzíme iba na AR, stupeň \(p\) možno určiť aj subjektívne, z grafu reziduálneho rozptylu odhadnutých modelov AR(1), AR(2) …, kedy disperzia od kritického bodu už prudko neklesá.
(TO DO: urobiť príklady na základe simulovaných procesov)
Odhad parametrov modelu
Po identifikácii modelu (t.j. určení triedy modelu a jeho hyperparametrov) prichádza k slovu odhad jeho parametrov. Pripomeňme požiadavku, aby bol časový rad stacionárny a s nulovou strednou hodnotou. V opačnom prípade môžeme získať nekorektný model, prípadne výpočet môže byť numericky nestabilný.
Na odhad parametrov AR modelov slúži napr.
- Yule-Walkerova metóda,
- Levinson-Durbinov algoritmus,
parametre všeobecnejších modelov ARMA sa odhadujú pomocou
- Long AR metódy,
- Hannan-Rissanenova procedúry,
- metódy maximálnej vierohodnosti.
Yule-Walkerova metóda
Používa sa na odhad parametrov modelu AR(\(p\)) pre dané \(p\). Vychádza z rovnice AR procesu, ktorá postupnými úpravami
\[
\begin{split}
y_t - \varphi_1 y_{t-1} - \ldots - \varphi_p y_{t-p} & = \varepsilon_t \\
y_t y_{t-k} - \varphi_1 y_{t-1} y_{t-k} - \ldots - \varphi_p y_{t-p} y_{t-k} & = \varepsilon_t y_{t-k} \\
E(y_t y_{t-k}) - \varphi_1 E(y_{t-1} y_{t-k}) - \ldots - \varphi_p E(y_{t-p} y_{t-k}) & = E(\varepsilon_t y_{t-k}),
\end{split}
\qquad
\begin{split}
/ & y_{t-k} \\
/ & \text{E} \\
k &= 0,1,...,p
\end{split}
\] vedie na systém (\(p+1\)) rovníc o (\(p+1\)) neznámych \[
\begin{split}
\gamma(k) - \varphi_1 \gamma(k-1) -\varphi_2 \gamma(k-2) -...- \varphi_p \gamma(k-p) & = 0, \\
\gamma(0) - \varphi_1 \gamma(1) -\varphi_2 \gamma(2) -...- \varphi_p \gamma(p) & = \sigma_{\varepsilon}^2,
\end{split}
\qquad
\begin{split}
k & = 1, 2, ..., p, \\
k & = 0,
\end{split}
\] ktorý sa rieši finitnou metódou pomocou inverznej matice. V maticovom zápise \[
\boldsymbol{\Gamma\varphi}=\boldsymbol\gamma,\quad \sigma_{\varepsilon}^2=\gamma(0)-\boldsymbol{\varphi'\gamma},
\] kde \(\boldsymbol\Gamma = \{\gamma(k-j)\}_{j,k=1}^p\) je \(p\times p\) matica, \(\boldsymbol\varphi=(\varphi_1,\ldots,\varphi_p)'\) a \(\boldsymbol\gamma=(\gamma(1),\ldots,\gamma(p))'\). Potom metódou momentov a úpravami, kedy namiesto teoretickej použijeme výberovú autokovariančnú funkciu \(\hat\gamma(k)\), dostávame odhady \(\hat{\boldsymbol\varphi}=\hat\Gamma^{-1}\hat{\boldsymbol\gamma}\) a \(\sigma_{\varepsilon}^2=\hat\gamma(0)-\hat{\boldsymbol\gamma}'\hat\Gamma^{-1}\hat{\boldsymbol\gamma}\), alebo analogicky pomocou ACF \[
\hat{\boldsymbol\varphi}=\hat{\mathbf{R}}^{-1}\hat{\boldsymbol\rho}, \qquad \hat{\sigma}_{\varepsilon}^2=\hat\gamma(0)\left[1-\hat{\boldsymbol\rho}'\hat{\mathbf{R}}^{-1}\hat{\boldsymbol\rho}\right],
\] kde \(\mathbf{R}=\boldsymbol{\Gamma}/\gamma(0)\).
Levinson-Durbinov algoritmus
Je založený na rekurzívnom riešení Yule – Walkerových rovníc. Počíta vhodné modely AR(1), AR(2), …, AR(\(p_{max}\)), kde \(p_{max}\) volíme, pričom skutočný stupeň \(p \leq p_{max}\).
Výhodou Levinson–Durbinovho algoritmu je, že okrem priameho riešenia YW rovníc (bez použitia inverznej matice) získame aj odhady PACF – výstupom je \(p_{max}\) modelov AR(\(p\)), \(p=1,...,p_{max}\), pričom posledný koeficient každého z nich predstavuje hodntu PACF \(\hat\rho^*(p)\). To umožní vybrať vhodný stupeň AR priamo v procese odhadu.
Long AR metóda
Používa sa na odhad koeficientov modelu ARMA(\(p,q\)), ale aj AR(\(p\)) (pre \(q = 0\)), resp. MA(\(q\)) (pre \(p = 0\)). Využíva fakt, že invertibilný model ARMA(\(p,q\)) môžeme aproximovať modelom AR(\(k\)) pre dostatočne veľké \(k\).
Najprv odhadneme model AR(\(k\)) pre dostatočne veľké \(k\): \[
y_t=\phi_1 \, y_{t-1}+\phi_2 \, y_{t-2}+...+\phi_k \, y_{t-k}+z_t
\tag{3.1}\] Odhady koeficientov \(\hat{\phi}_1,\ldots,\hat{\phi}_k\) získame klasickou metódou najmenších štvorcov. Tieto odhady dosadíme do (3.1), čím získame odhady rezíduí \[
\hat{z}'_t=y_t-\hat{\phi}_1 \, y_{t-1}-\ldots-\hat{\phi}_k \, y_{t-k}, \quad t=k+1,...,n.
\] Po dosadení do modelu ARMA(\(p,q\)), \[
y_t-\varphi_1 \, y_{t-1}-\varphi_2 \, y_{t-2}-\ldots-\varphi_p \, y_{t-p}=\varepsilon_t+\theta_1 \, \hat{z}'_{t-1}+\ldots+\theta_q \, \hat{z}'_{t-q}
\] klasickou metódou najmenších štvorcov odhadneme parametre \(\varphi_1,\ldots,\theta_q\) modelu ARMA(\(p,q\)). Rozptyl chybovej zložky bude \[
\hat{\sigma}_{\varepsilon}^2=\sum_{t=t_1+1}^n \frac{\hat{\varepsilon}_t^2}{n-t_1}, \quad\text{ kde } t_1=\max (q+k,p).
\]
Hannan – Rissanenova procedúra
Rozširuje Long AR metódu o určenie stupňov \(k_{max},p,q\) pomocou informačných kritérií. Pozostáva z nasledujúcich krokov:
- Zvolia sa 4 hodnoty: \(k_{max}\) pre Long AR - metódu, \(p_{max}\) - maximálny stupeň AR, \(q_{max}\) - maximálny stupeň MA, \(m\) - počet modelov s najmenšími BIC.
- Použije sa Lewinson – Durbinov algoritmus (alebo iná metóda) na odhad parametrov modelov AR(1), AR(2), …, AR(\(k_{max}\)).
- Vypočíta sa AIC pre všetky modely AR(1), …, AR(\(k_{max}\)) a vyberie sa model AR(\(k\)) s minimálnym AIC (odporúčam \(k\geq p_{max}\)).
- Pre vybraný model AR(\(k\)) sa vypočíta časový rad rezíduí \(\hat{z}'_t\).
- Ku každej kombinácii hyperparametrov \(p \leq \min(p_{max}, k)\) a \(q \leq q_{max}\) sa pomocou MNŠ odhadne model ARMA(\(p,q\)) - parametre aj rozptyl chybovej zložky.
- Vyberie sa \(m\) modelov s najmenším BIC.
Metóda maximálnej vierohodnosti
Predpokladáme, že biely šum \(\varepsilon_t\) stacionárneho ARMA(\(p,q\)) procesu s nulovou strednou hodnotou je gaussovský, teda platí \(\varepsilon_t \sim N(0, \sigma_\varepsilon^2 )\). Združená hustota pravdepodobnosti náhodného vektora \(\boldsymbol{\varepsilon}=(\varepsilon_1,..., \varepsilon_n)\) je \[
f(\boldsymbol{\varepsilon})=(2 \pi \sigma_\varepsilon^2)^{-\frac{n}{2}} \; e^{-\frac{1}{2\sigma_\varepsilon^2} \sum_{t=1}^n \varepsilon_t^2}.
\] Dosadením \(\varepsilon_t = y_t-\varphi_1y_{t-1}-\ldots-\varphi_py_{t-p}-\theta_1z_{t-1}-\ldots-\theta_qz_{t-q}\) dostávame hustotu ako funkciu parametrov \(\varphi_1,\ldots,\theta_q\) (a \(\sigma_\varepsilon^2\)). Zlogaritmovaním získame tzv. funkciu vierohodnosti (angl. likelihood function) \[
L(\boldsymbol{\varphi},\boldsymbol{\theta},\sigma_\varepsilon^2) = -\frac{n}{2} \ln (2 \pi) -\frac{n}{2} \ln (\sigma_\varepsilon^2)-\frac{1}{2\sigma_\varepsilon^2} \sum_{t=1}^n \varepsilon_t^2
\] ktorej maximalizáciou (ekvivalentne minimalizáciou reziduálneho súčtu štvorcov \(S(\boldsymbol{\varphi},\boldsymbol{\theta})=\sum_{t=1}^n \varepsilon_t^2\)) dostaneme odhady parametrov \(\hat\varphi_1,\ldots,\hat\theta_q\) a \(\hat\sigma_\varepsilon^2=\frac{S(\boldsymbol{\hat\varphi},\boldsymbol{\hat\theta})}{n-p-q}\). Pretože hodnoty \(y_0, y_{-1}, ...\) a \(\varepsilon_0, \varepsilon_{-1},...\) nie sú známe, začneme od \(t=p+1\) a v prípade \(q>p\), neznáme hodnoty \(\{\varepsilon_t\}_{t\leq0}\) nahradíme strednou hodnotou, čiže 0 (hovoríme o podmienenej metóde max.vierohodnosti), inak by sme museli spätne extrapolovať.
Metódou maximálnej vierohodnosti získame nevychýlené efektívne odhady parametrov.
Napríklad pre ARMA(1,1), čiže \(\varepsilon_t=y_t-\varphi_1y_{t-1}-\theta_1\varepsilon_{t-1}\) bude vierohodnostná funkcia v tvare \[
L(\boldsymbol{\varphi},\boldsymbol{\theta},\sigma_\varepsilon^2) = -\frac n2 \ln(2\pi) - \frac n2 \ln(\sigma_\varepsilon^2) - \frac1{2\sigma_\varepsilon^2}\sum_{t=1}^n(y_t-\varphi_1y_{t-1}-\theta_1\varepsilon_{t-1})^2
\] a štandardným postupom hľadania lokálnych extrémov \[
\begin{split}
\frac{\partial L(\boldsymbol{\varphi},\boldsymbol{\theta},\sigma_\varepsilon^2)}{\partial\varphi_1} = -\frac1{\sigma_\varepsilon^2} \sum_{t=1}^n(y_t-\varphi_1y_{t-1}-\theta_1\varepsilon_{t-1})(-y_{t-1}) & \\
\sum_{t=1}^n(y_t-\hat\varphi_1y_{t-1}-\hat\theta_1\varepsilon_{t-1})(-y_{t-1}) &= 0 \\
\hat\varphi_1\sum_{t=1}^ny_{t-1}^2 + \hat\theta_1\sum_{t=1}^n\varepsilon_{t-1}y_{t-1} &= \sum_{t=1}^ny_ty_{t-1} \\
\frac{\partial L(\boldsymbol{\varphi},\boldsymbol{\theta},\sigma_\varepsilon^2)}{\partial\theta_1} = 0 \quad\Rightarrow \quad
\hat\varphi_1\sum_{t=1}^ny_{t-1}\varepsilon_{t-1} + \hat\theta_1\sum_{t=1}^n\varepsilon_{t-1}^2 & = \sum_{t=1}^ny_t\varepsilon_{t-1}
\end{split}
\] dostávame dve rovnice o dvoch neznámych \(\hat\varphi_1, \hat\theta_1\).
Na záver ešte spomenieme asymptotické vlastnosti maximálne vierohodných odhadov.
Nech \(\boldsymbol{\beta} = (\varphi_1, ..., \varphi_p, \theta_1, ..., \theta_q)^T\) sú skutočné parametre stacionárneho a invertibilného procesu ARMA(, ) a \(\hat{\boldsymbol{\beta}}\) je odhad vektora \(\boldsymbol{\beta}\), získaný metódou maximálnej vierohodnosti alebo podmienenou metódou maximálnej vierohodnosti. Pre \(n \rightarrow \infty\) platí \(\sqrt{n}\; \left(\hat{\boldsymbol{\beta}} - \boldsymbol{\beta} \right)\sim N(0, \mathbf{V}(\beta)),\) kde \(\mathbf{V}(\beta)\) je asymptotická kovariančná matica odhadov parametrov typu \((p + q) \times (p + q)\).
V praxi nie sú skutočné hodnoty parametrov \(\boldsymbol{\beta}\) známe. Preto sa používa aproximácia asymptotickej kovariančnej matice pomocou informačnej matice.
Informačná matica je stredná hodnota matice 2. parciálnych derivácií logaritmu vierohodnostnej funkcie podľa jej parametrov. Inverzná matica k informačnej matici je kovariančná matica odhadov parametrov. Aproximácia spočíva v tom, že namiesto stredných hodnôt sa používajú výberové kvantily. Štandardné chyby odhadov parametrov sú druhé odmocniny diagonálnych prvkov kovariančnej matice vydelené \(\sqrt{n}\).
Diagostika modelu
Posledným bodom postupu je overenie adekvátnosti odhadnutého modelu, či už vyšetrením vlastností modelu alebo vlastností rezíduí, napr. nasledujúcimi metódami:
- V prípade modelov ARMA sa vyšetruje stacionarita, jednak či korene autoregresného polynómu ležia mimo (alebo ich prevrátené hodnoty vo vnútri) jednotkového kruhu, jednak pomocou tzv. impulse response analýzy, kedy sa model ARMA prevedie do formy lineárneho procesu (Woldova reprezentácia) a skúma sa vplyv vzruchu (impulz) v konkrétnom čase \(s\), napr. \(\tilde\varepsilon_s=2\sigma_\varepsilon\), na nasledujúce hodnoty odozvy (response) \(y_t\), \(s<t\), pričom ostatné hodnoty sú položené nule, \(\tilde\varepsilon_t=0\). Ak je analyzovaný proces stacionárny, mala by odozva na jediný impulz s postupom času odznieť až na nulovú hodnotu.
- Vyšetrenie zhody korelačnej štruktúry vypočítanej z časového radu a vypočítanej z modelu.
- Test nekorelovanosti rezíduí, a to nielen jednotlivo pomocou nám už známej aproximácie, \(\rho(k)\sim N(0,1/n)\), ale aj súhrnne pomocou tzv. portmanteau testov, napr. Box-Pierce a Ljung-Box testov.
- Test normality rezíduí, napr. pomocou šikmosti a špicatosti Jarque-Bera testom.
- Test podmienenej homoskedasticity rezíduí, napr. White testom.
Dobrý (lineárny) model časových radov určite spĺňa podmienku nekorelovanosti rezíduí (ktoré samozrejme zároveň majú strednú hodnotu nulovú). V opačnom prípade predpovedný model nevyužíva všetky informácie dostupné v časovom rade. Vlastnosť normality a konštantného rozptylu rezíduí nie je nevyhnutná, skôr je užitočná pri konštrukcii intervalových odhadov/predpovedí (niekedy sa dá zabezpečiť vhodnou transformáciou časového radu).
Test autokorelácie rezíduí
Okrem testovania hodnoty ACF pre každý posun osobitne a to známym testom, ktorým sme už vyšetrovali náhodnosť rezíduí po modeli systematických zložiek, môžeme použiť testy z triedy Portmanteau testov, kde pravdivosť štatistických hypotéz formulovaných \[
H_0\colon \rho(k)=0, \; k = 1, ..., m, \qquad H_1\colon \exists k: 0 < k \leq m, \; \rho(k)\neq 0
\] skúmame na základe výberovej autokorelačnej funkcie rezíduí stacionárneho procesu ARMA(\(p,q\)) pre prvých \(m\) hodnôt spolu (\(m \leq \frac{n}{4}\)), pričom testovacia štatistika, najčastejšie
- Box-Pierce testu \(Q_{BP}=n \sum_{k=1}^m \hat\rho(k)^2\), alebo
- Ljung-Box testu \(Q_{LB}=n(n+2)\sum_{k=1}^m \frac{\hat\rho(k)^2}{n-k}\)
má pri platnosti \(H_0\) rozdelenie \(\chi^2(m - p - q)\). Test je jednostranný, teda ak \(Q > \chi_{1-\alpha}^2(m - p - q)\), model ARMA(\(p,q\)) nepovažujeme za vhodný (na hladine významnosti \(\alpha\)).
Test normality
Jarque-Bera test normality rezíduí, teda hypotézy \(H_0\), že rezíduá \(\hat\varepsilon_t\) sú generované normálnym rozdelením, je založený na súčasnom testovaní šikmosti a špicatosti.
Za predpokladu platnosti \(H_0\) a nulovej strednej hodnoty rezíduí sú výberová šikmosť \(SK\) a špicatosť \(SP\) dané vzťahmi a rozdelením (pre dostatočne veľké \(n\)): \[
SK=\frac{\frac{1}{n}\sum_{t=1}^n \hat{\varepsilon}_t^3}{\left[\frac{1}{n}\sum_{t=1}^n \hat{\varepsilon}_t^2 \right]^{\frac{3}{2}}}\sim N\left(0,\frac6n\right),
\qquad
SP=\frac{\frac{1}{n}\sum_{t=1}^n \hat{\varepsilon}_t^4}{\left[\frac{1}{n}\sum_{t=1}^n \hat{\varepsilon}_t^2 \right]^{2}}\sim N\left(3,\frac{24}n\right)
\] Testovacia štatistika Jarque-Bera testu, \[
JB = n \left( \frac{SK^2}{6}+ \frac{(SP-3)^2}{24}\right)
\] má potom rozdelenie \(\chi^2(2)\).
Test podmienenej homoskedasticity
Testujeme hypotézu \(H_0\), že časový rad rezíduí \(\hat{\varepsilon}_t\) je rad s podmienenou homoskedasticitou, formálne \[
H_0\colon var(\varepsilon_t|y_{t-1},y_{t-2},...) = \mbox{ konšt.}
\] Engleho test je založený na Lagrangeových multiplikátoroch. Postup je nasledovný:
- Vypočítame odhady rezíduí \(\hat{\varepsilon}_t\) ARMA(\(p,q\)) modelu.
- Odhadneme autoregresný model AR(\(w\)) pre štvorce rezíduí \[
\hat{\varepsilon}_t^2 = \phi_0+\phi_1 \, \hat{\varepsilon}_{t-1}^2 +...+\phi_w \, \hat{\varepsilon}_{t-w}^2 + e_t,
\] vypočítame reziduálny súčet štvorcov \(RSS=\sum_{t=t_1+1}^n \hat{e}_t^2\) a celkový súčet štvorcov \(TSS=\sum_{t=t_1+1}^n (\hat{\varepsilon}_t^2-\hat{\mu}_{\hat\varepsilon_t^2})^2\), kde \(t_1=\max (p,q,w)\).
- Vypočítame index determinácie \(R^2=1-\frac{RSS}{TSS}\) a testovaciu štatistiku \(TS=n*R^2\).
- Za predpokladu platnosti nulovej hypotézy \(H_0: \phi_0=\phi_1 = ... = \phi_w = 0\) má testovacia štatistika asymptoticky \(\chi^2(w+1)\) – rozdelenie.
- Ak \(H_0\) zamietneme (na hladine významnosti \(\alpha\)), rezíduá sú generované ARMA(\(p,q\)) procesom s podmienenou heteroskedasticitou.