Kód
# knižnice
library(ggplot2)
library(patchwork)
# kontajnery:
# dat - na súbory údajov, zväčša v tabuľkovej podobe
# fit - na objekty odhadnutých modelov
dat <- fit <- list()Balík forecast funguje s takými časovými radmi, ktoré sú uložené v dátovom objekte ts, čiže vo vektore, ktorý má atribútom tsp definovaný začiatok, koniec, a vzorkovaciu frekvenciu. Pre podrobnosti o analýze časových radov s použitím tohto softvérového nástroja pozri online učebnicu Hyndman a Athanasopoulos (2018).
Na rozdiel od predošlej kapitoly, tu budeme uprednostňovať grafiku definovanú balíkom ggplot2.
# knižnice
library(ggplot2)
library(patchwork)
# kontajnery:
# dat - na súbory údajov, zväčša v tabuľkovej podobe
# fit - na objekty odhadnutých modelov
dat <- fit <- list()Načítanie údajov:
dat$all <- "data/Poloha_denne.dat" |> # zdrojový súbor údajov
read.table(header=T, skip = 1) |> # načítanie, vynechaný riadok obsahuje popis
setNames(c("time", "observed"))
# n <- nrow(dat$all)
head(dat$all) time observed
1 1 0.0
2 2 -1.4
3 3 0.3
4 4 -0.2
5 5 1.1
6 6 0.5Dáta predstavujú denné pozorovania polohy v milimetroch pomocou GPS na permanentnej monitorovacej stanici po dobu 2 rokov. Konkrétne ide o severnú zložku topocentrického súradnicového systému s počiatkom v polohe z prvého dňa merania.
Aby sme mohli pracovať s balíkom forecast, uložíme časový rad ako vektor typu ts s atribútom frequency = 365, aby zodpovedal prirodzenému časovému obdobiu (perióde sezónnej zložky). Je potrebné si predtým overiť, že časový rad je skutočne pravidelný.
# dat$all$time |> diff() |> range() |> diff() # should be zero
dat$all$observed <- ts(dat$all$observed, start = 0, frequency = 365)Zobrazenie časového radu v redefinovanom časovom systéme:
dat$all$observed |>
forecast::autoplot() + labs(y = "observed [mm]", x = "time [year]")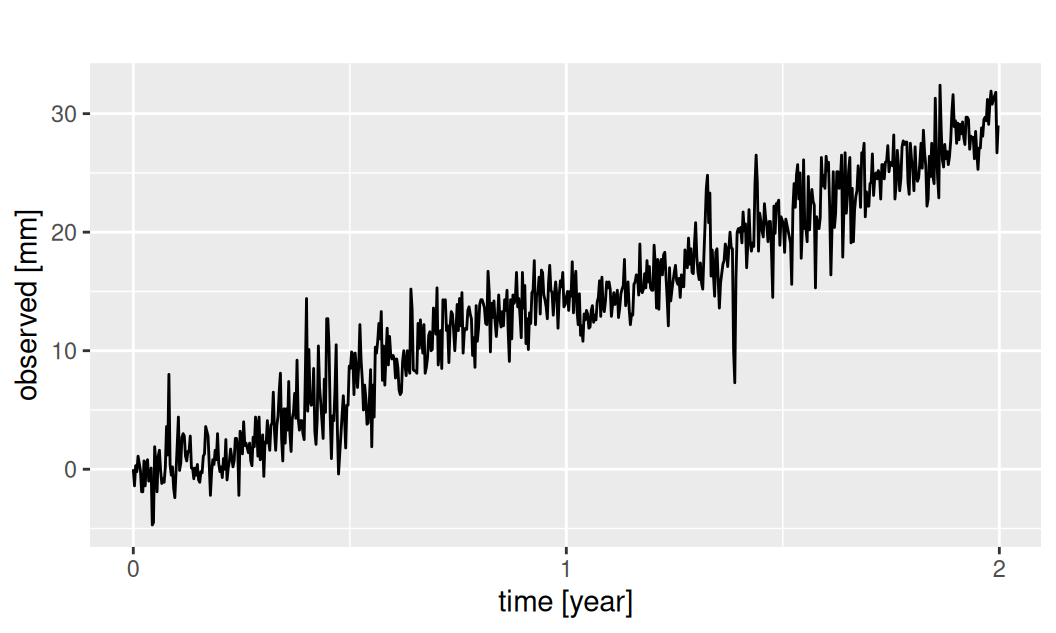
Vypočítame základnú číselnú charakteristiku časového radu,
c("length","min","max","median","mean","sd") |>
sapply(function(x) eval(call(x, dat$all$observed))) |>
round(2)length min max median mean sd
730.00 -4.70 32.40 14.30 13.97 8.81 rozdelíme ho na trénovaciu a validačnú vzorku približne v pomere 80% ku 20%.
# end of train sample, example for split ratio (train/all) = 0.80:
# - year = 0 + (0.80*n) %/% 365 = 1
# - day = floor( (0.80*n) %% 365 ) = 219
# split and store
dat$train <- data.frame(observed = window(dat$all$observed, end = c(1, 219)))
dat$valid <- data.frame(observed = window(dat$all$observed, start = c(1, 219+1)))Pridáme časovú premennú time zodpovedajúcu ts objektu, ktorá sa využije pri konštrukcii modelu systematických zložiek a napokon aj pri predpovedaní pre vytvorenie matice plánu na validačné obdobie.
dat <- lapply(dat, function(x) within(x, {
time <- stats::time(observed)
}))Obe časti spolu zobrazíme.
list(train = dat$train$observed,
valid = dat$valid$observed) |>
with({
ggplot() + autolayer(train) + autolayer(valid) +
scale_color_manual(values = c(train = 1, valid = 2),
labels = c("train", "validation")) +
guides(color = guide_legend(title = "sample")) +
theme(legend.position = "inside",
legend.position.inside = c(0.99, 0.01),
legend.justification = c("right","bottom")) +
labs(x = "year", y = "observed")
})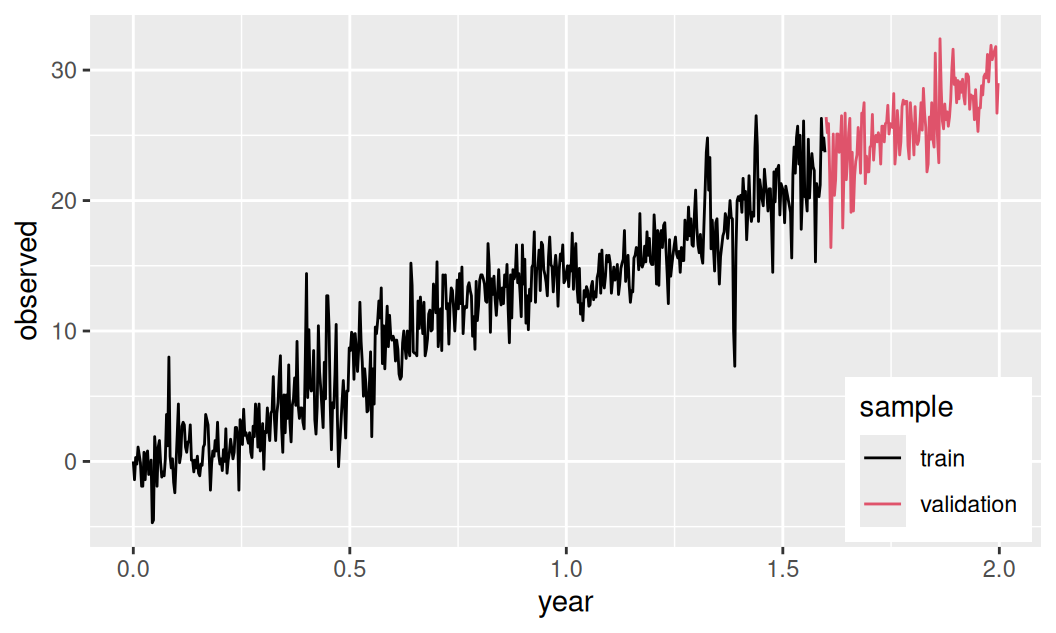
Časový rad je zjavne nestacionárny v strednej hodnote, no stacionárny v rozptyle.
Na trénovacej vzorke identifikujeme a odhadneme modely jednotlivých zložiek stochastického procesu a pomocou validačnej posúdime presnosť predpovedí.
Keďže je časový rad stacionárny v rozptyle, dekompozícia bude aditívna.
Prieskumná dekompozícia adaptívnou metódou na trend, sezónnu zložku a rezíduá nie je pomocou bežných funkcií decompose/stl možná, pretože perióda sezónnej zložky je príliš vysoká. Ideme teda rovno na regresnú metódu izolácie zložiek časového radu.
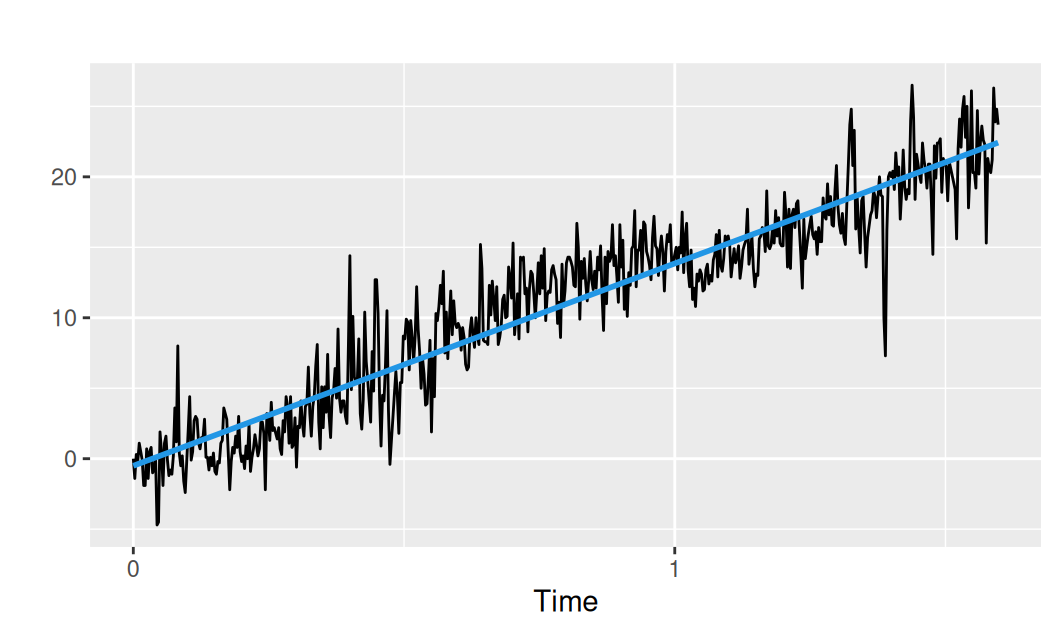
Začneme trendom. Podľa obrázku by mal stačiť lineárny trend.
fit$Tlin <- forecast::tslm(observed ~ trend, data = dat$train)
fit$Tlin |> summary() |> coef() |> round(4) Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.5413 0.1980 -2.7335 0.0065
trend 0.0393 0.0006 67.0472 0.0000Trend je zjavne štatisticky významný. Uložíme ho aj s rezíduami a zobrazíme.
dat$train$Tlin <- fitted(fit$Tlin)
dat$train$resTlin <- residuals(fit$Tlin)with(dat$train,
forecast::autoplot(observed) +
forecast::autolayer(Tlin, color = 4, linewidth = 1, show.legend = FALSE) +
ylab("")
)
Zobrazíme rezíduá po trende a ich korelogram:
with(dat$train, {
forecast::autoplot(observed - Tlin) |> print();
forecast::Acf(observed - Tlin, plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")
})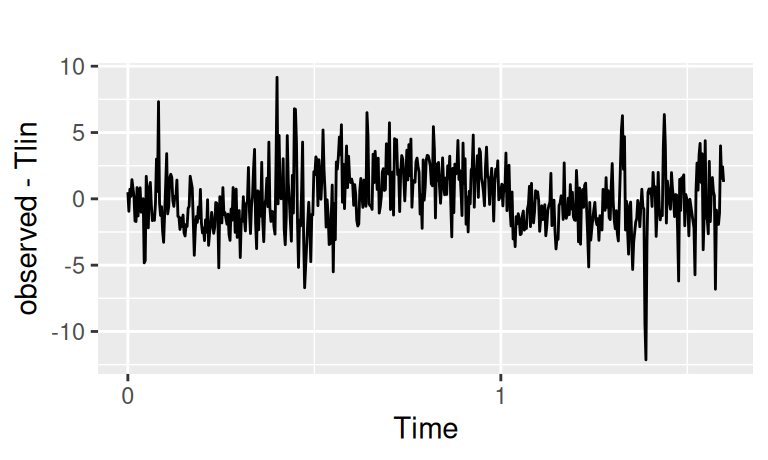
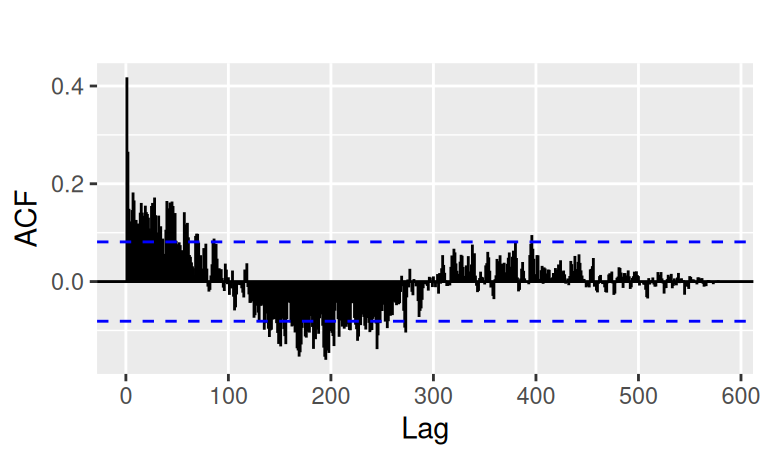
Sezónna zložka je pomerne výrazná. Vzhľadom na veľkosť periódy (365 dní) nemá zmysel ju modelovať pomocou indikačných premenných, použijeme teda harmonickú regresiu:
within(dat$train, {
Sha1 <- forecast::tslm(resTlin ~ fourier(resTlin, K = 1)) |> fitted()
Sha2 <- forecast::tslm(resTlin ~ fourier(resTlin, K = 2)) |> fitted()
}) |>
with({
(forecast::autoplot(observed - Tlin) +
forecast::autolayer(Sha1, color = 4, linewidth = 1, show.legend = FALSE) +
ggtitle("L1 = 365")
) |> print();
forecast::autoplot(observed - Tlin) +
forecast::autolayer(Sha2, color = 4, linewidth = 1, show.legend = FALSE) +
ggtitle("L1 = 365, L2 = 365/2")
})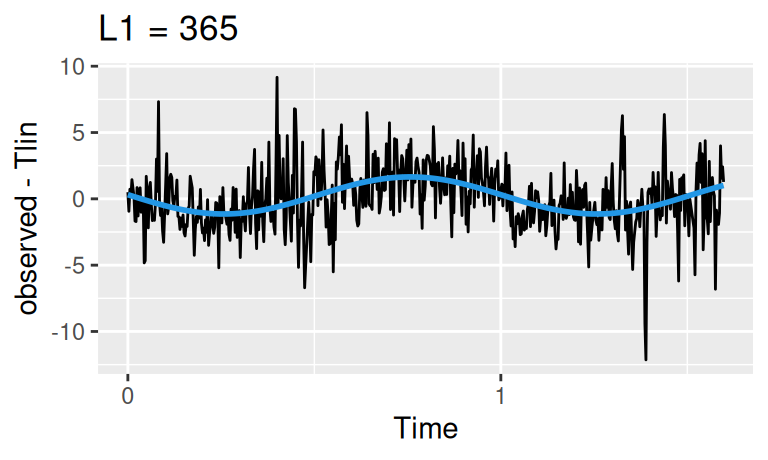
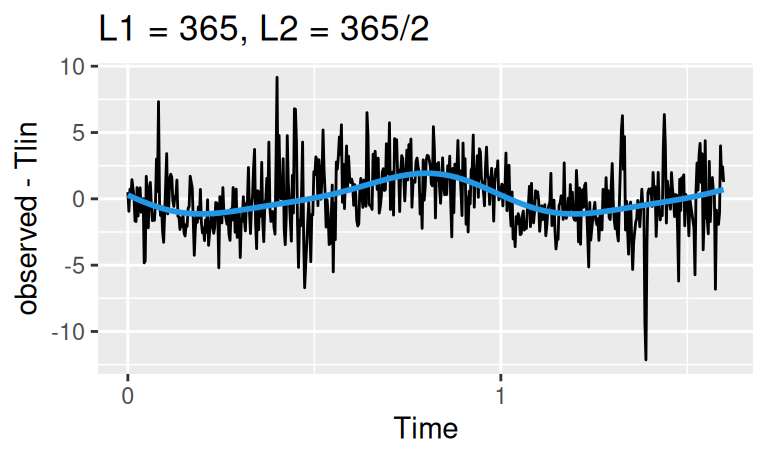
Obe krivky dobre popisujú dáta, ponecháme si tú jednoduchšiu.
fit$Sha1 <- forecast::tslm(resTlin ~ fourier(resTlin, K = 1), data = dat$train)Zdá sa, že model trendu a sezónnej zložky dobre popisuje náš časový rad a žiadna ďalšia systematická zložka sa v ňom nenachádza. Preto spektrálny obraz rezíduí by mal byť podobný spektru bieleho šumu. Balík forecast neobsahuje nástroje na spektrálnu analýzu, preto použijeme vlastný program založený na FFT.
spectrum <- fit$Sha1 |>
residuals() |>
fft() |> # rýchla fourierova transformácia
abs() |> (`^`)(2) |> (`/`)(2*pi*nrow(dat$train)) |>
head(floor(nrow(dat$train)/2+1)) |> # odstránenie redundantnej informácie
(\(x) data.frame(density = x,
omega = 2*pi*seq(0, along.with = x)/nrow(dat$train))
)() |>
transform(period = 2*pi/omega) |>
{\(x) x[order(x$density, decreasing = TRUE),]}() # dplyr::arrange(desc(density))V periodograme zvýrazníme periódy s najvyššou hustotou.
# ggplot(spectrum) + aes(x = period, y = density) +
# geom_segment(aes(xend = period, yend = 0)) +
# scale_x_log10()
ggplot(spectrum) + aes(x = period, y = density) +
geom_segment(aes(xend = period, yend = 0)) +
scale_x_continuous(breaks = spectrum$period[1:10] |> round(),
trans = "log") +
theme(axis.text.x = element_text(angle = 60, hjust = 1))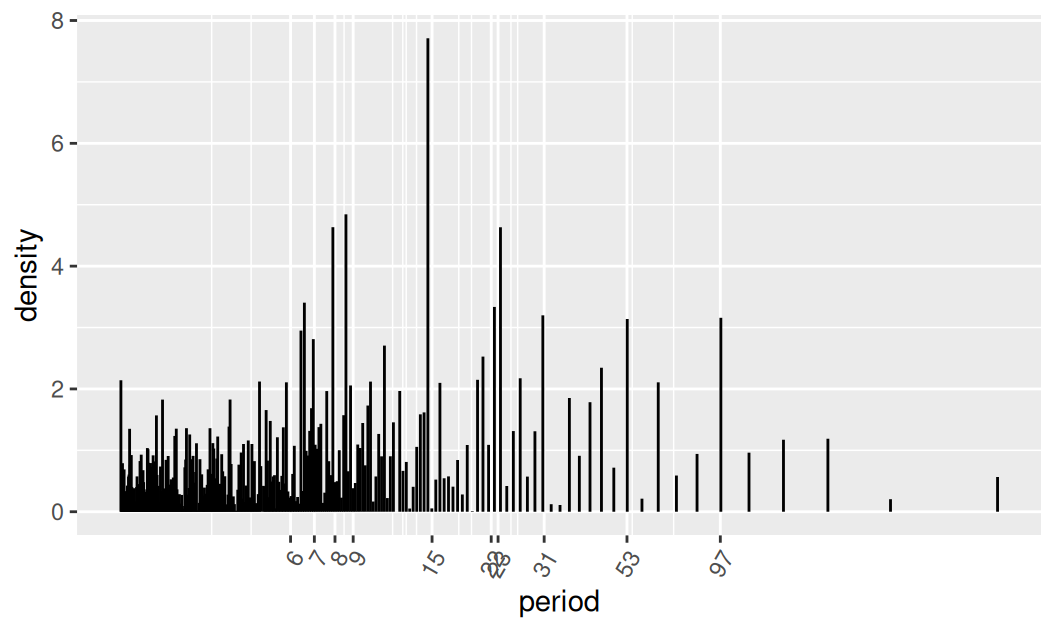
Spektrum je pomerne kompaktné, až na jeden vrchol, ktorý formálne otestujeme.
c(
period = spectrum$period[1],
density = spectrum$density[1],
test.stat = spectrum$density[1]/sum(spectrum$density),
crit.val = 1 - (0.05/nrow(spectrum))^(1/(nrow(spectrum)-1))
) |> round(3) period density test.stat crit.val
14.600 7.711 0.034 0.029 Perióda cca 15 dní by mohla súvisieť so slapovými javmi. Modelovanie harmonickou regresiou je teoreticky podobné ako pri sezónnej zložke, tu však cyklickú zložku zo subjektívneho hľadiska zanedbáme. Balík forecast na to aj tak nemá dedikované nástroje. Ak by cyklická zložka bola výraznejšia, použili by sme nástroje z Kapitola 12.
Keďže cyklickú zložku neuvažujeme, model bude obsahovať iba trend a sezónnosť.
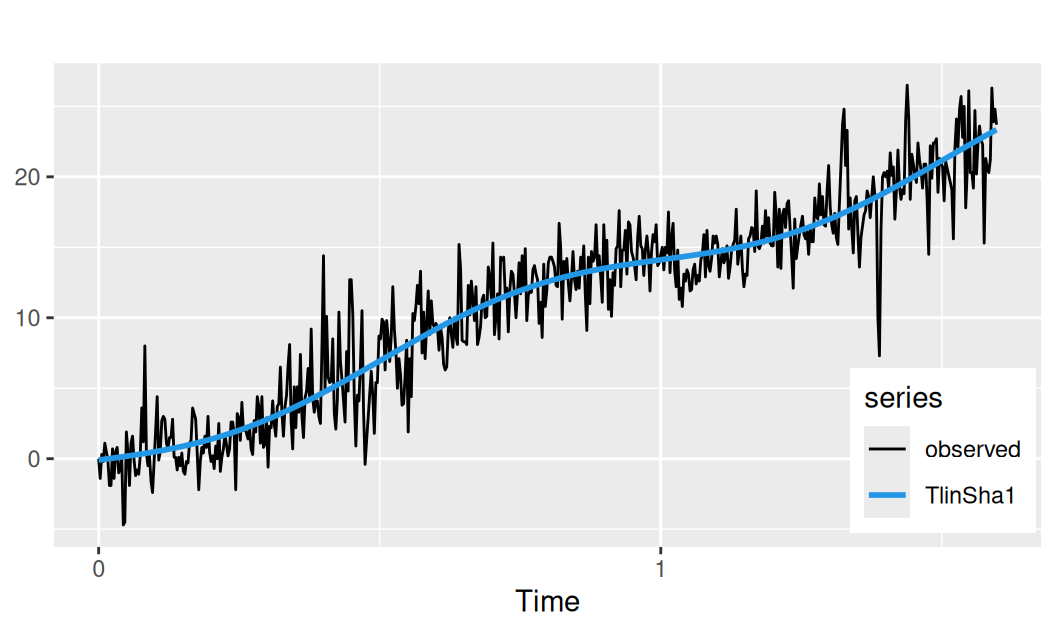
fit$TlinSha1 <- forecast::tslm(observed ~ trend + fourier(observed, K = 1),
data = dat$train)Zobrazenie:
with(dat$train, {
TlinSha1 <- fit$TlinSha1 |> fitted()
forecast::autoplot(observed, mapping = aes(color = "observed")) +
forecast::autolayer(TlinSha1, size = 1) +
scale_color_manual(values = c(1, 4), name = "series") +
theme(legend.position = "inside", legend.position.inside = c(0.9,0.2)) +
labs(y = NULL)
})
Balík forecast neposkytuje testy náhodnosti, aké boli použité v predošlej kapitole, iba základnú sadu diagnostických grafov a formálneho testu autokorelácie (typu LM).
forecast::checkresiduals(fit$TlinSha1, lag.max = 100)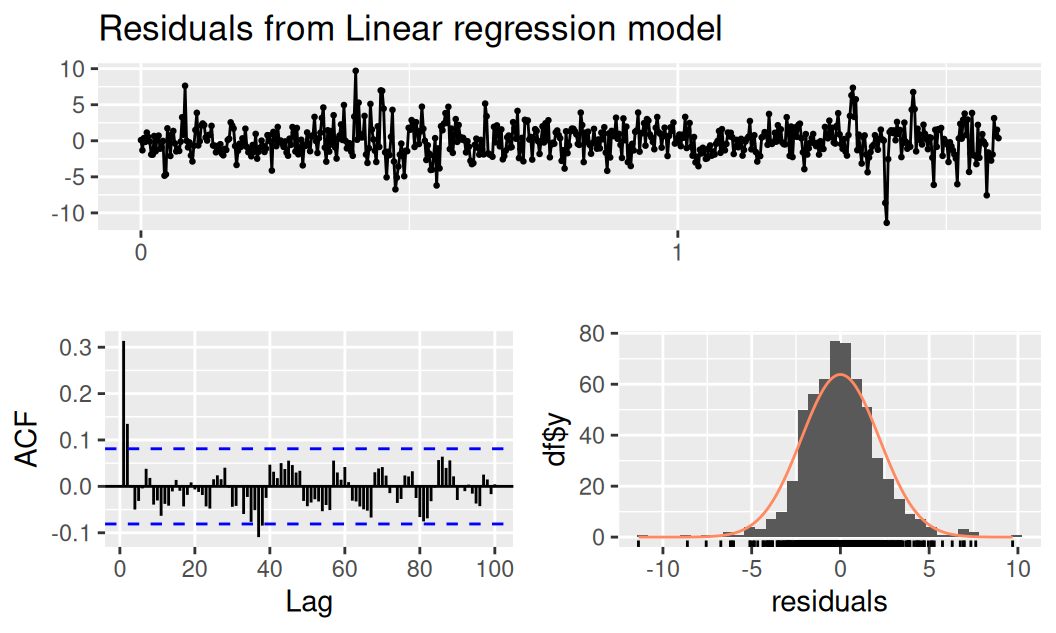
Breusch-Godfrey test for serial correlation of order up to 117
data: Residuals from Linear regression model
LM test = 138.41, df = 117, p-value = 0.08606Z nich vyplýva, že
Zvyšková korelácia síce nevychýli predpovede odhadnuté týmto modelom, no predpovedný interval bude širší. Aby sme využili aj informáciu obsiahnutú v rezíduách, je potrebné rozšíriť model systematických zložiek o lineárny model triedy ARMA.
Výpočet a uloženie rezíduí modelu systematickej zložky:
dat$train$resTlinSha1 <- residuals(fit$TlinSha1)Neparametrická identifikácia lineárneho procesu
with(dat$train, {
p1 <- forecast::Acf(resTlinSha1, lag.max = 10, plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")
p2 <- forecast::Pacf(resTlinSha1, lag.max = 10, plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")
p1 + p2
})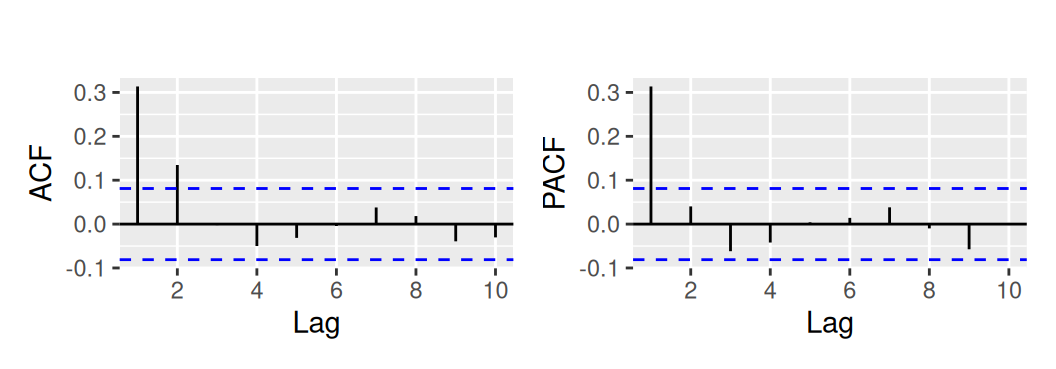
Pôjde o jednoduchý lineárny proces, buď AR(1), alebo nanajvýš MA(2) či ARMA (1,1).
fit$Rar1 <- forecast::Arima(dat$train$resTlinSha1, order = c(1,0,0), include.mean = FALSE)
fit$Rar1Series: dat$train$resTlinSha1
ARIMA(1,0,0) with zero mean
Coefficients:
ar1
0.3131
s.e. 0.0392
sigma^2 = 4.358: log likelihood = -1258.06
AIC=2520.12 AICc=2520.15 BIC=2528.86fit$Rma2 <- forecast::Arima(dat$train$resTlinSha1, order = c(0,0,2), include.mean = FALSE)
fit$Rma2Series: dat$train$resTlinSha1
ARIMA(0,0,2) with zero mean
Coefficients:
ma1 ma2
0.2968 0.1475
s.e. 0.0406 0.0413
sigma^2 = 4.347: log likelihood = -1256.81
AIC=2519.62 AICc=2519.66 BIC=2532.73Neprekvapivo má model MA(2) najnižší reziduálny rozptyl (sigma^2) a aj podľa AIC by bol považovaný za vhodnejšieho kandidáta na finálny model reziduálnej zložky. Avšak podľa striktnejšieho kritéria BIC by nám mal stačiť aj model AR(1).
Z hodnoty jediného parametra je zjavné, že AR(1) je stacionárny, ale môžeme to overiť aj funkciou. Podobne sa dá zistiť invertibilita MA(2)
forecast:::plot.Arima(fit$Rar1, type = "ar")
forecast:::plot.Arima(fit$Rma2, type = "ma")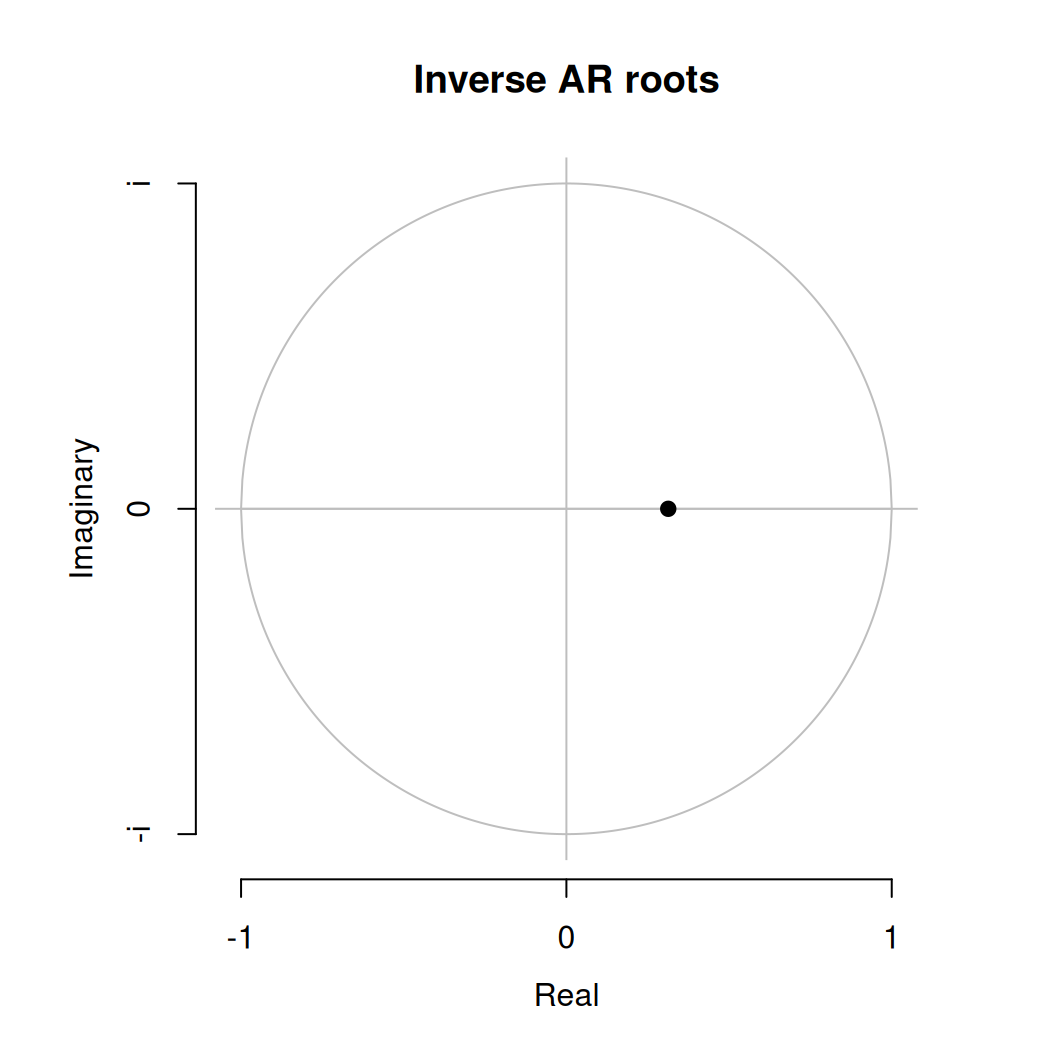
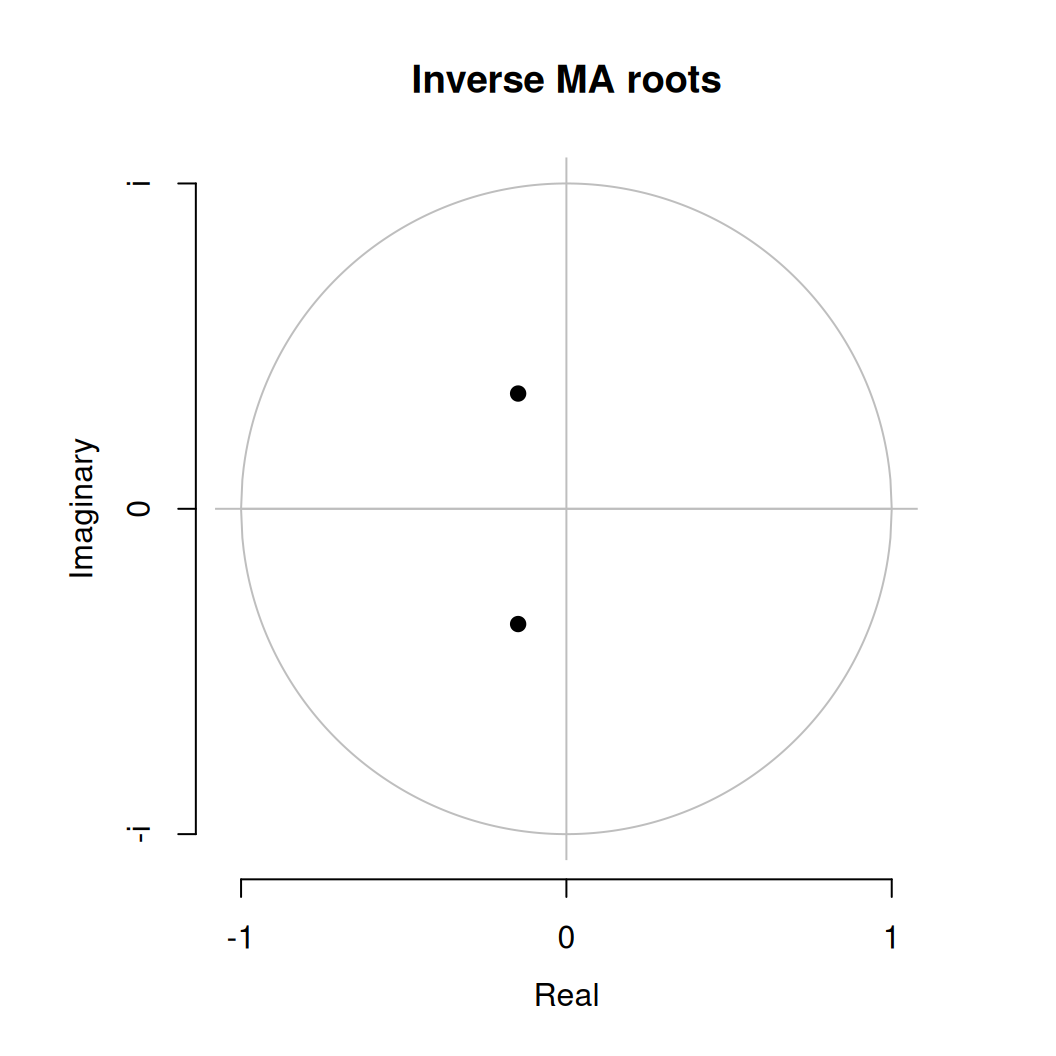
AR polynóm má jediný, reálny koreň, ktorý je zjavne väčší ako 1 (\(1/x<1\)). Podobne aj korene MA(2) polynómu sú mimo jednotkovej kružnice, takže proces je invertibilný.
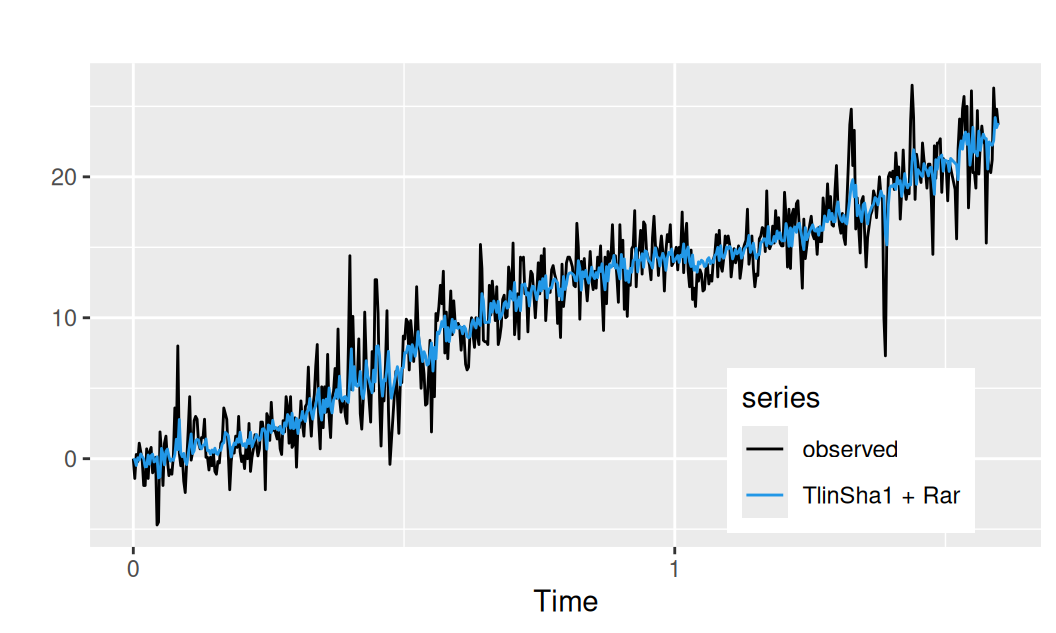
Jeden model nakoniec zobrazíme:
with(dat$train, {
Rar <- fitted(fit$Rar1)
TlinSha1 <- fitted(fit$TlinSha1)
forecast::autoplot(observed, mapping = aes(color = "observed")) +
forecast::autolayer(TlinSha1 + Rar) +
scale_color_manual(values = c(1, 4), name = "series") +
theme(legend.position = "inside", legend.position.inside = c(0.8,0.2)) +
ylab("")
})
Vytvorenie jediného dekompozičného modelu je potrebné jednak pre správne odhady parametrov modelov jednotlivých zložiek, jednak pre jednoduchý výpočet predpovedí.
Odhad zabezpečí funkcia Arima, treba jej len dodať maticu plánu modelu systematických zložiek. Hoci sa takáto regresná matica dá vytiahnuť z výstupu funkcie tslm, nie je to tak pohodlné ako z klasickej funkcie lm a navyše – čo je horšie – nebude sa dať extrapolovať pri predpovedaní. Preto bude treba definovať rovnicu modelu znovu a klasickým spôsobom (nie symbolickými regresormi ako trend). Absolútny člen (intercept) tu vynecháme, pretože neskôr bude funkciou Arima doplnený automaticky. Kvôli nekompatibilite funkcie fourier s klasickým spôsobom konštrukcie matice plánu pre validačné obdobie túto rozdelíme na dve časti, aby sa dala použiť aj neskôr, pri predpovediach.
# fit$Syst$model[-1] |> as.matrix() # extraction of model matrix from tslm
# function to construct design matrix for linear trend to be inserted into dynamic model during estimation or forecasting
# in: data - data.frame containing 'time' variable with tsp of 'observed'
# out: matrix, dim(out) = (nrow(data), 1)
make_Xreg_trend <- function(data) {
model.matrix(~ -1 + time, data = data)
}
# example use
# make_Xreg_trend(dat$train) |> head(3)
# make_Xreg_trend(dat$valid) |> head(3)
# function to construct design matrix from forecast::fourier()
# in: data - data.frame, training sample
# h - integer, forecasting horizon
# NULL if training sample Xreg needed
# out: matrix, nrow(data)x2 or hx2
make_Xreg_fourier <- function(data, h = NULL) {
forecast::fourier(data$observed, K = 1, h = h)
}
# example use
# make_Xreg_fourier(dat$train) |> head(3)
# make_Xreg_fourier(dat$train, h = 3)
cbind(make_Xreg_trend(dat$train), make_Xreg_fourier(dat$train)) |>
head(3) time S1-365 C1-365
1 0.000000000 0.01721336 0.9998518
2 0.002739726 0.03442161 0.9994074
3 0.005479452 0.05161967 0.9986668Keď je pripravená konštrukcia matice plánu, môžeme ju použiť v odhade spoločného modelu.
fit$TlinSha1Rar1 <- forecast::Arima(
dat$train$observed,
order = c(1, 0, 0),
xreg = cbind(make_Xreg_trend(dat$train), make_Xreg_fourier(dat$train))
)
fit$TlinSha1Rar1Series: dat$train$observed
Regression with ARIMA(1,0,0) errors
Coefficients:
ar1 intercept time S1-365 C1-365
0.3130 -0.1322 14.2112 -1.4017 0.0606
s.e. 0.0392 0.2586 0.2795 0.1891 0.1789
sigma^2 = 4.388: log likelihood = -1258.06
AIC=2528.12 AICc=2528.27 BIC=2554.34Základné diagnostické nástroje sú podobné ako pre model systematických zložiek, líšia sa iba v teste nulovosti ACF.
fit$TlinSha1Rar1 |>
forecast::checkresiduals()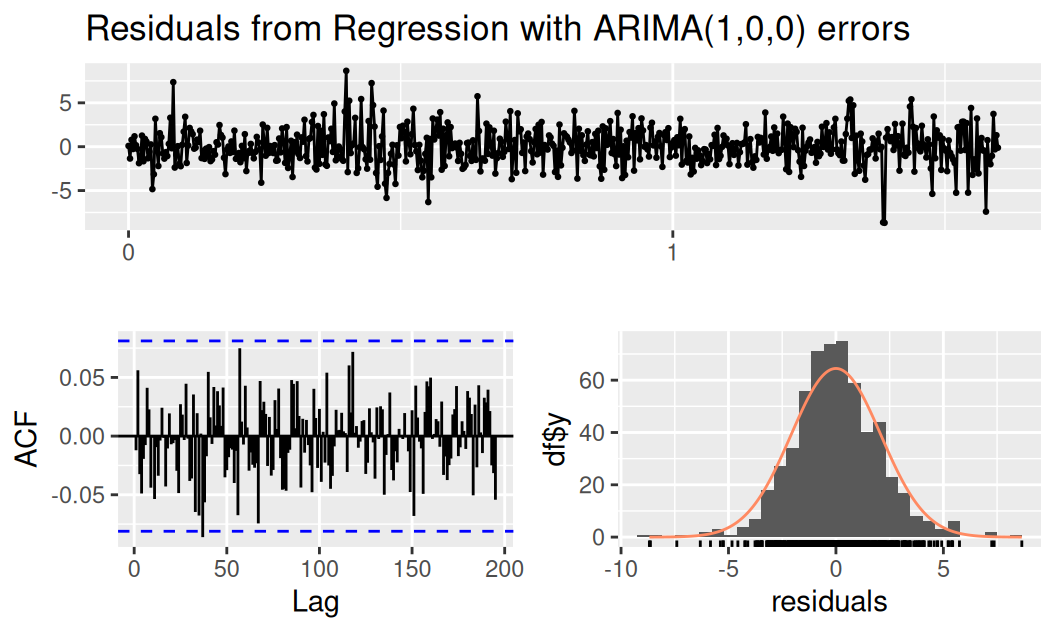
Ljung-Box test
data: Residuals from Regression with ARIMA(1,0,0) errors
Q* = 84.345, df = 116, p-value = 0.9881
Model df: 1. Total lags used: 117# fit$TlinSha1Rar1 |> residuals() |>
# Box.test(lag = 10)
# fit$TlinSha1Rar1 |> residuals() |>
# Box.test(lag = 10, type = "Ljung-Box", fitdf = 1 + 2 + 1)Vidíme už prakticky gaussovsky rozdelený biely šum. Avšak formálny test normality toto zdanie vyvracia:
fit$TlinSha1Rar1 |> residuals() |> tseries::jarque.bera.test()
Jarque Bera Test
data: residuals(fit$TlinSha1Rar1)
X-squared = 71.699, df = 2, p-value = 2.22e-16Testov heteroskedasticity je viacero, pozri napr. funkcie TSA::McLeod.Li.test, lmtest::bptest, alebo funkcie balíka olsrr.
Viackrokové predpovede sú najjednoduchšie. Najprv si pripravíme objekty triedy forecast.
dat$valid.fore <- list(
multi = list(
# naive forecast is the same as random walk (without drift) forecast
naive = forecast::naive(dat$train$observed, h = nrow(dat$valid)),
# argument newdata supplies the time variable in static model
Tlin = fit$Tlin |> forecast::forecast(h = nrow(dat$valid)),
TlinSha1 = fit$TlinSha1 |>
forecast::forecast(
newdata = data.frame(make_Xreg_fourier(dat$train, h = nrow(dat$valid)))
),
# xreg supply the regressors explicitly
TlinSha1Ar1 = fit$TlinSha1Rar1 |>
forecast::forecast(
xreg = cbind(make_Xreg_trend(dat$valid),
make_Xreg_fourier(dat$train, h = nrow(dat$valid))
)
)
))Zobrazenie bodových predpovedí v kontexte celého časového radu:
p <- list()
# overview
p$observed <- forecast::autoplot(dat$train$observed) +
forecast::autolayer(dat$valid$observed, color = "gray60") +
labs(y = "")
p$observed +
forecast::autolayer(fore$multi$naive, series = "naive", PI = FALSE) +
forecast::autolayer(fore$multi$Tlin, series = "Tlin", PI = FALSE) +
forecast::autolayer(fore$multi$TlinSha1, series = "TlinSha1", PI = FALSE) +
scale_color_manual(values = c(naive = 3, Tlin = 2, TlinSha1 = 4),
name = "model")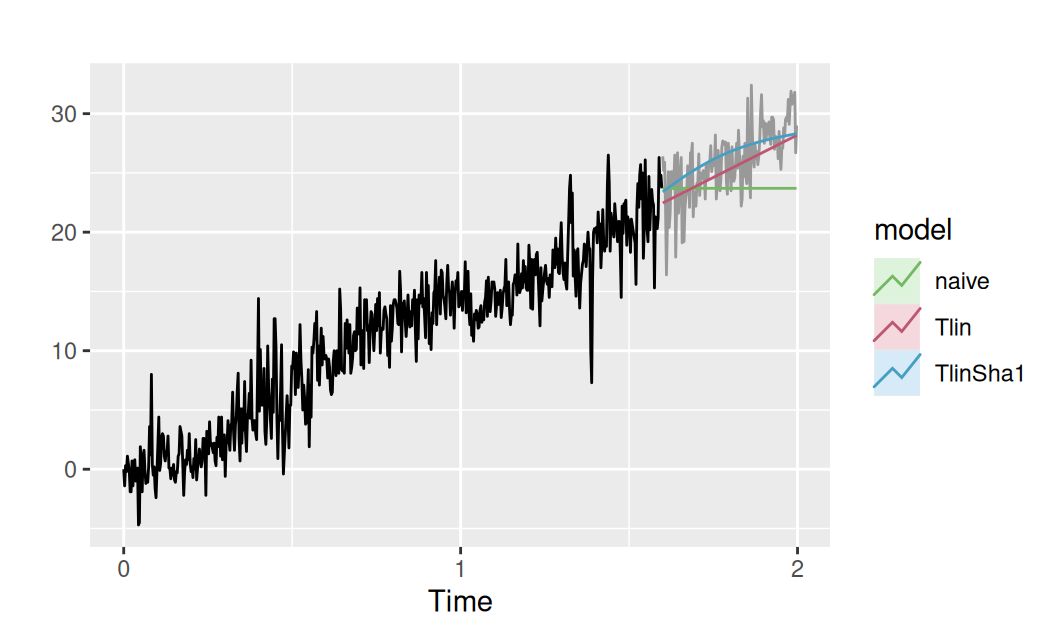
Podrobnejší záber na bodové a intervalové predpovede jednotlivých modelov:
# detailed
p$observed_cut <- p$observed +
coord_cartesian(xlim = c(1.5, 2), ylim = c(10, 35)) +
scale_x_continuous(n.breaks = 2)
p$naive <- p$observed_cut + forecast::autolayer(fore$multi$naive, alpha = 0.5) + labs(subtitle = "Naive (last observed)", x = "")
p$Tlin <- p$observed_cut +
forecast::autolayer(fore$multi$Tlin, alpha = 0.5) +
labs(subtitle = "Linear trend", x = "")
p$TlinSha1 <- p$observed_cut +
forecast::autolayer(fore$multi$TlinSha1, alpha = 0.5) +
labs(subtitle = "Trend and seasonality")
p$TlinSha1Ar1 <- p$observed_cut +
forecast::autolayer(fore$multi$TlinSha1Ar1, alpha = 0.5) +
labs(subtitle = "Trend, seasonality, AR(1)")
(p$naive | p$Tlin) / (p$TlinSha1 | p$TlinSha1Ar1) +
plot_annotation(title = 'Multistep forecast with 95% prediction intervals')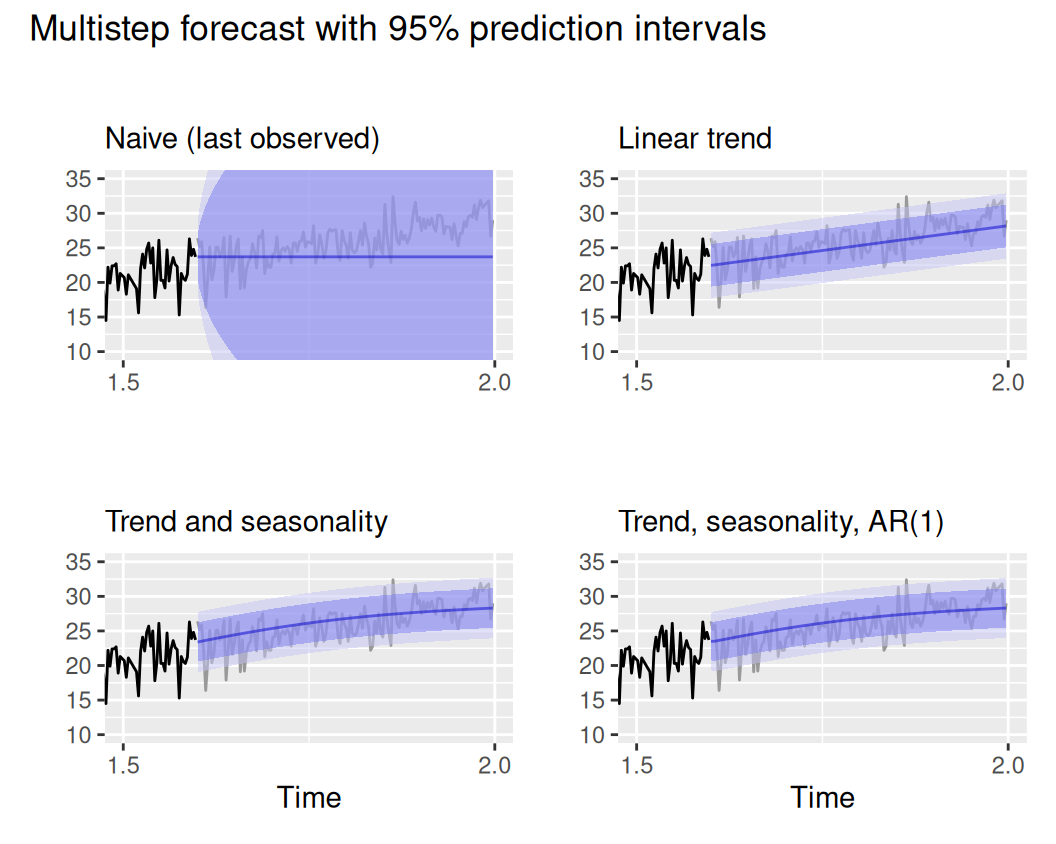
Výsledok plného, dynamického modelu (obr. vpravo dolu) je takmer totožný s predpoveďami statického modelu. To preto, že model reziduálnej zložky má krátku pamäť, vplyv AR(1) rýchlo odznie. Pri jedno-krokových predpovediach bude rozdiel viditeľnejší. Tie sú pre statický model rovnaké ako viackrokové.
Pre výpočet jedno-krokových predpovedí z plného modelu je potrebné aplikovať už-odhadnutý model na celý časový rad (trénovaciu a validačnú časť spolu) pomocou funkcie forecast::arima a s využitím jej argumentu model.
Zároveň platí, že jedno-krokové predpovede statických modelov sú totožné s viackrokovými, preto ich tu neuvádzame.
# naive (random walk) forecast
fore$one$naive <- data.frame(
mean = dat$all$observed |> tail(nrow(dat$valid)+1) |> head(-1) |> lag(k = -1)
) |>
with({
sdev <- dat$train$observed |> diff() |> sd() # random walk, no drift
data.frame(mean = mean,
lower = mean - 2*sdev,
upper = mean + 2*sdev)
})
# full model forecast
fore$one$TlinSha1Ar1 <- data.frame(
mean = forecast::Arima(
dat$all$observed,
xreg = cbind(make_Xreg_trend(dat$all), make_Xreg_fourier(dat$all)),
model = fit$TlinSha1Rar1
) |>
fitted() |>
window(start = start(dat$valid$observed))
) |>
transform(lower = mean - 2*sqrt(fit$TlinSha1Rar1$sigma2),
upper = mean + 2*sqrt(fit$TlinSha1Rar1$sigma2)
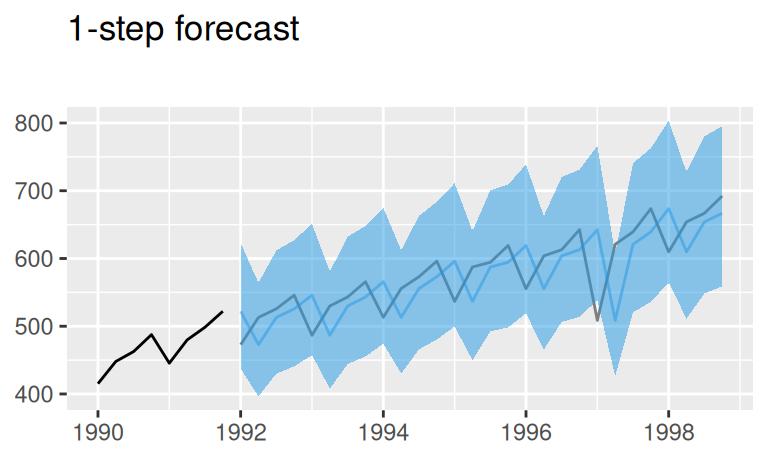
)p$naive_1 <- p$observed_cut +
forecast::autolayer(fore$one$naive$mean, color = 4) +
geom_ribbon(dat = fore$one$naive,
mapping = aes(x = time(mean), ymin = lower, ymax = upper),
fill = 4, alpha = 0.2, inherit.aes = FALSE) +
ggtitle("Naive (last observed)")
p$TlinSha1Ar1_1 <- p$observed_cut +
forecast::autolayer(fore$one$TlinSha1Ar1$mean, color = 4) +
geom_ribbon(dat = fore$one$TlinSha1Ar1,
mapping = aes(x = time(mean), ymin = lower, ymax = upper),
fill = 4, alpha = 0.2, inherit.aes = FALSE) +
ggtitle("Trend, seasonality, AR(1)")
(p$naive_1 / p$TlinSha1Ar1_1) +
plot_annotation(title = '1-step point forecasts with 95% prediction intervals')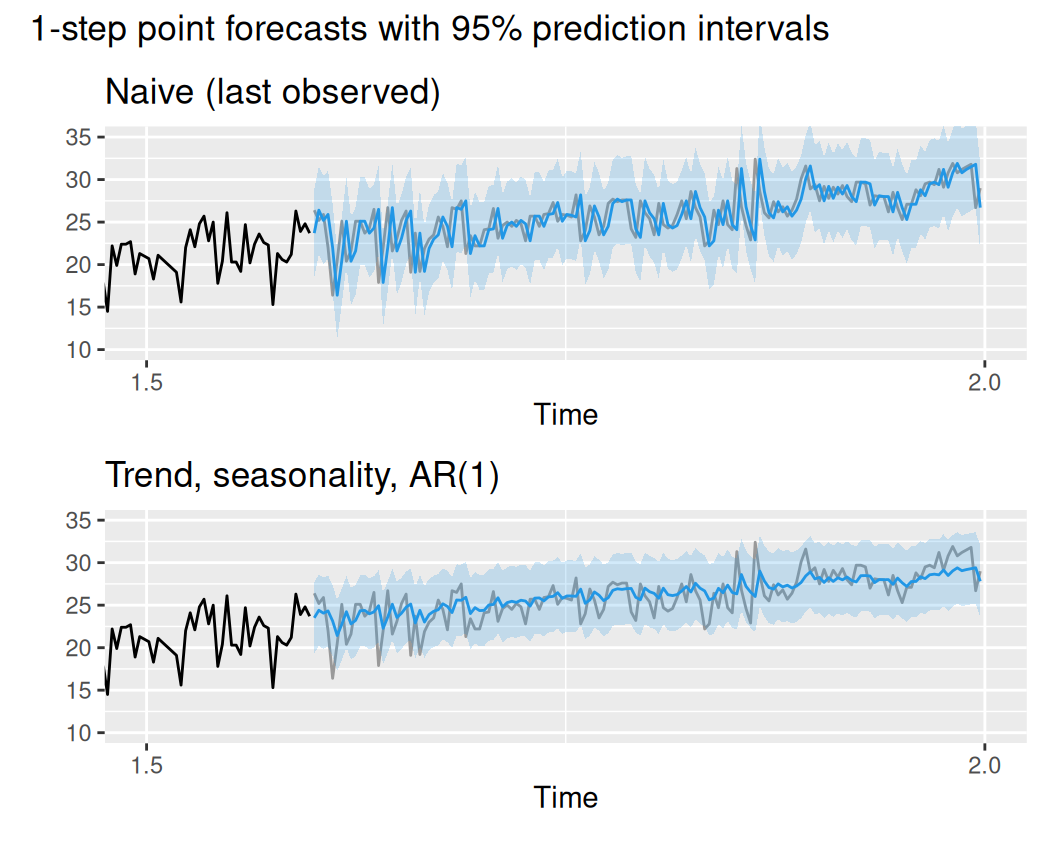
Presnosť predpovedí má zmysel porovnávať len zvlášť pre jedno-krokové predpovede a zvlášť pre viackrokové.
list(
multi = fore$multi |>
lapply(forecast::accuracy, x = dat$valid$observed) |>
lapply(round, digits = 2) |>
lapply(tibble::as_tibble, rownames = "Set") |>
dplyr::bind_rows(.id = "model")
,
one = fore$one |>
lapply(function(y) forecast::accuracy(y$mean, x = dat$valid$observed)) |>
lapply(round, digits = 2) |>
lapply(tibble::as_tibble, rownames = "Set") |>
dplyr::bind_rows(.id = "model")
) |>
lapply(as.data.frame)$multi
model Set ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
1 naive Training set 0.04 2.58 1.97 -Inf Inf 0.14 -0.37 NA
2 naive Test set 2.31 3.69 3.04 7.66 11.32 0.22 0.58 1.27
3 Tlin Training set 0.00 2.39 1.85 NaN Inf 0.13 0.42 NA
4 Tlin Test set 0.69 2.18 1.76 1.89 6.87 0.13 0.19 0.79
5 TlinSha1 Training set 0.00 2.20 1.63 NaN Inf 0.12 0.31 NA
6 TlinSha1 Test set -0.44 2.21 1.75 -2.60 7.14 0.12 0.26 0.83
7 TlinSha1Ar1 Training set 0.00 2.09 1.57 NaN Inf 0.11 -0.01 NA
8 TlinSha1Ar1 Test set -0.44 2.21 1.75 -2.61 7.14 0.12 0.26 0.83
$one
model Set ME RMSE MAE MPE MAPE ACF1 Theil's U
1 naive Test set 0.04 2.62 1.97 -0.45 7.95 -0.37 1.00
2 TlinSha1Ar1 Test set -0.30 2.11 1.62 -1.98 6.60 -0.05 0.78Z popisného hľadiska je najpresnejší (RMSE = 2.09) plný model, s lineárnym trendom, jednou harmonickou sezónnou zložkou a autoregresným modelom stupňa 1. Ten sa však neukázal ako najlepší na predpovedanie, kde ho z hľadiska kvadratickej chyby predbehol (RMSE = 2.18) jednoduchší model, iba s lineárnym trendom.
Čiastočne je to aj prítomnosťou extrémnych hodnôt na začiatku validačného obdobia, pretože z hľadiska MAE je sezónny model tesne lepší. Môže ísť aj o náhodu v dôsledku zmeny v stochastickom procese vo validačnej časti, čomu nasvedčuje nižšia popisná (RMSE = 2.39) než predpovedná presnosť (RMSE = 2.09) modelu lineárneho trendu. Inak by sme túto prevahu jednoduchšieho modelu museli pripísať nevhodne zvolenému modelu sezónnej zložky.
Na jedno-krokových predpovediach sa ukázala sila dynamického modelu, ktorý prekonáva všetky statické modely. Tu je dobre vidieť, že pri krátkodobých predpovediach má model reziduálnej zložky veľký zmysel.
# clear containers
dat <- fit <- list()
# load data
dat$all <- "data/HDP_kvart.dat" |> # zdrojový súbor údajov
read.table(header=T, skip = 1) |> # načítanie, vynechaný riadok obsahuje popis
setNames(c("time", "observed"))
# n <- nrow(dat$all)
head(dat$all) time observed
1 1964.00 49.00
2 1964.25 54.48
3 1964.50 60.38
4 1964.75 62.88
5 1965.00 52.09
6 1965.25 59.35Časový rad predstavuje kvartálne záznamy hrubého domáceho produktu (HDP) jednej európskej krajiny v rokoch 1964–1998 v jednotkách miliárd EUR. Trénovacia vzorka končí 1991 Q4, validačná začína 1992 Q1.
Aby sme mohli pracovať s balíkom forecast, uložíme časový rad ako vektor typu ts so začiatkom start = c(1964, 1), a samplovacou frekvenciou frequency = 4, aby zodpovedali prirodzenému časovému obdobiu (perióde sezónnej zložky).
# check for consistency of time indices
#dat$all$time |> diff() |> range() |> diff() # should be zero
# create ts object, set beginning and sample frequency
dat$all$observed <- ts(dat$all$observed, start = c(1964, 1), frequency = 4)
# check visually
# dat$all$observed |> forecast::autoplot() + ylab("observed")
# make separate samples
dat$train <- data.frame(observed = window(dat$all$observed, end = c(1991, 4)))
dat$valid <- data.frame(observed = window(dat$all$observed, start = c(1992, 1)))
# make time index (in dat$all it should be the same as the existing time variable)
dat <- lapply(dat, function(x) within(x, {
time <- stats::time(observed)
}))Zobrazenie:
list(train = dat$train$observed,
valid = dat$valid$observed) |>
with({
ggplot() + forecast::autolayer(train) + autolayer(valid) +
scale_color_manual(values = c(train = 1, valid = 2)) +
guides(color = guide_legend(title = "sample")) +
theme(legend.position = "inside",
legend.position.inside = c(0.99, 0.01),
legend.justification = c("right","bottom")) +
labs(x = "year", y = "observed")
})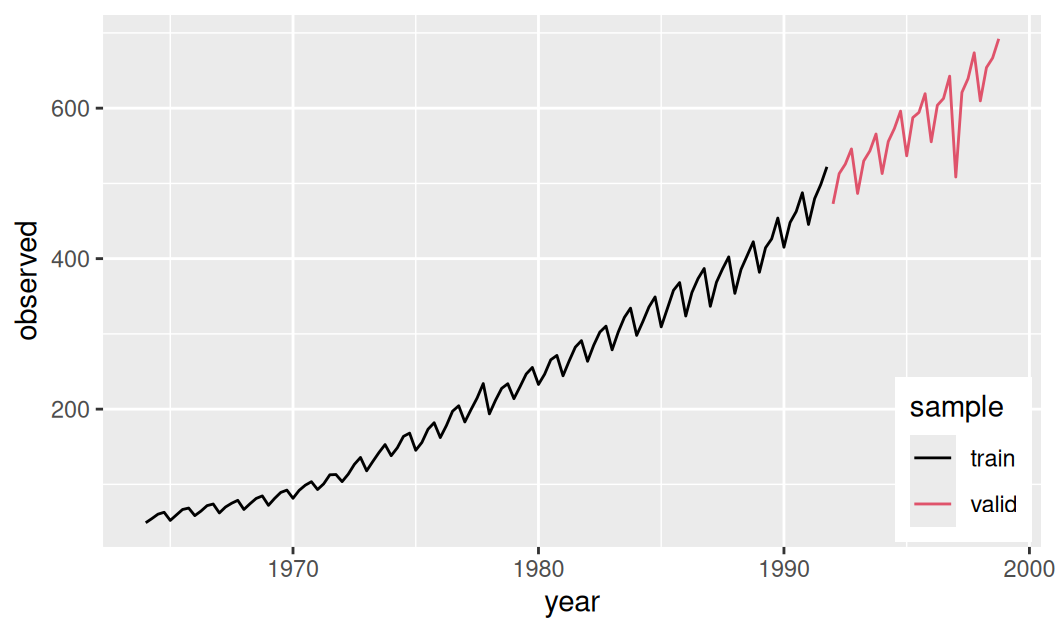
Časový rad je zjavne okrem strednej hodnoty nestacionárny aj v rozptyle.
Na prvotný, prieskumný rozklad použijeme adaptívnu metódu dekompozície, konkrétne iteratívnou aplikácou metódy LOESS.
dat$train$observed |>
stl(s.window = 4) |>
forecast::autoplot()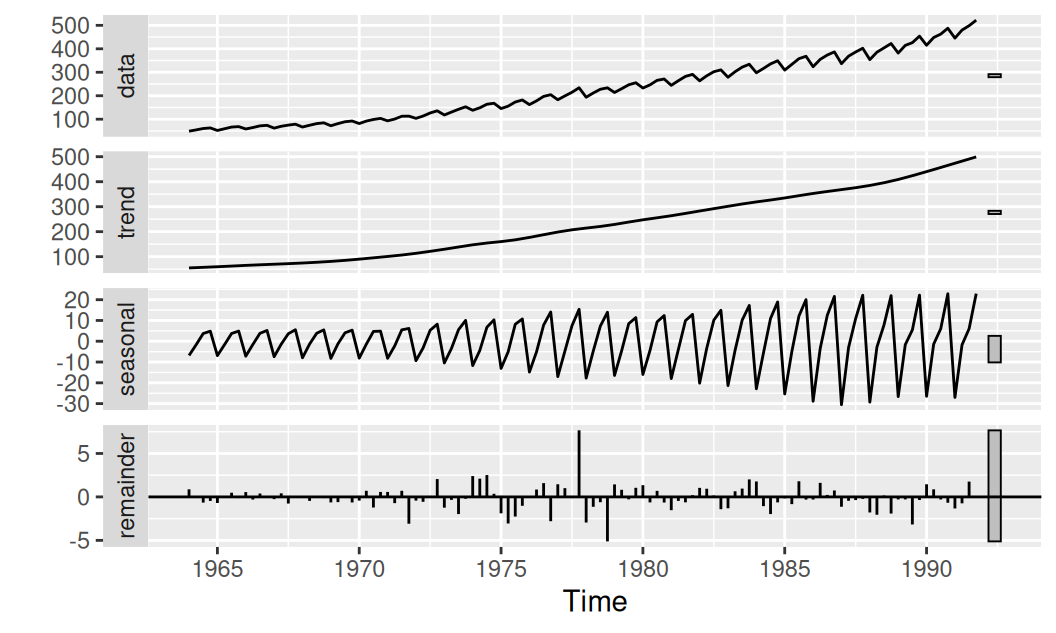
Vidíme rastúci trend (v mld EUR) a výraznú sezónnu zložku s nepravidelne rastúcou amplitúdou. Šum tiež nie je homoskedastický.
Izolovaný trend pripomína exponenciálnu funkciu. Pretože však rozptyl rastie so strednou hodnotou, časový rad stacionarizujeme logaritmom (lambda = 0) takže aj exponenciálny trend bude v novej mierke lineárny (prediktor trend v rovnici funkcie tslm).
fit$Tlin <- forecast::tslm(observed ~ trend, data = dat$train, lambda = 0)
dat$train$Tlin <- fit$Tlin |> fitted()
with(dat$train, {
p1 <- forecast::autoplot(observed) +
forecast::autolayer(Tlin, color = 4, linewidth = 1, show.legend = FALSE) +
labs(subtitle = "linear trend in log scale", y = NULL) + scale_y_log10()
p2 <- forecast::autoplot(observed) +
forecast::autolayer(Tlin, color = 4, linewidth = 1, show.legend = FALSE) +
ylab(NULL)
p1 + p2
})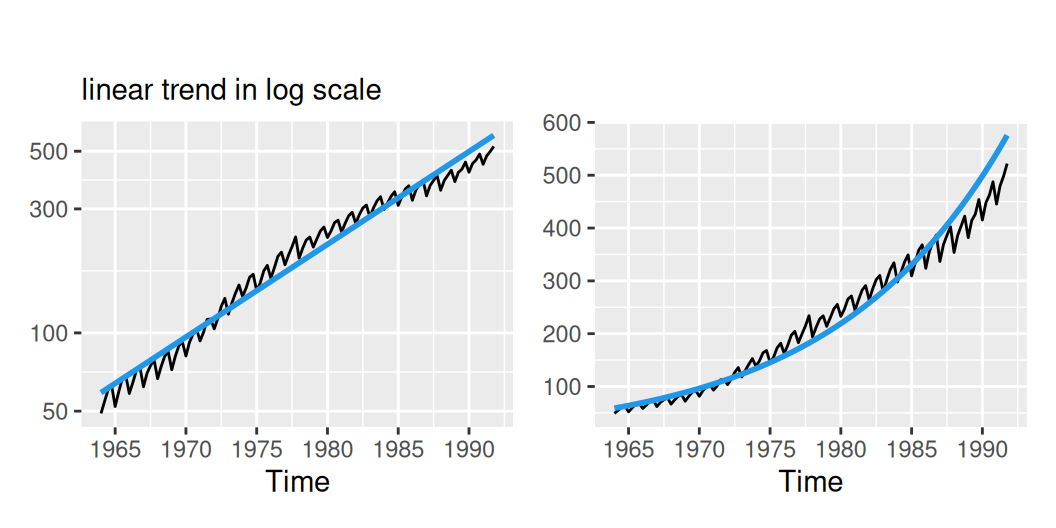
Exponenciálny trend ponecháva ešte priestor pre zlepšenie, ktorý je azda možné vyplniť modelom cyklickej zložky s dlhou periódou, avšak skúsime aj alternatívne modely trendu, napr.
df), alebo uzly.fit$Tqua <- forecast::tslm(observed ~ time + I(time^2), #
data = dat$train,
lambda = 0)
fit$Tns <- forecast::tslm(observed ~ splines::ns(time, df = 10), #
data = dat$train,
lambda = 0)
dat$train$Tqua <- fit$Tqua |> fitted()
dat$train$Tns <- fit$Tns |> fitted()# quadratic
forecast::autoplot(dat$train$observed) +
forecast::autolayer(dat$train$Tqua, color = 4, linewidth = 1, show.legend = FALSE) +
labs(subtitle = "quadratic trend in log scale", y = NULL) + scale_y_log10()
forecast::autoplot(dat$train$observed) +
forecast::autolayer(dat$train$Tqua, color = 4, linewidth = 1, show.legend = FALSE) +
ylab(NULL)
# natural spline
forecast::autoplot(dat$train$observed) +
forecast::autolayer(dat$train$Tns, color = 4, linewidth = 1, show.legend = FALSE) +
labs(subtitle = "natural spline in log scale", y = NULL) + scale_y_log10()
forecast::autoplot(dat$train$observed) +
forecast::autolayer(dat$train$Tns, color = 4, linewidth = 1, show.legend = FALSE) +
ylab(NULL)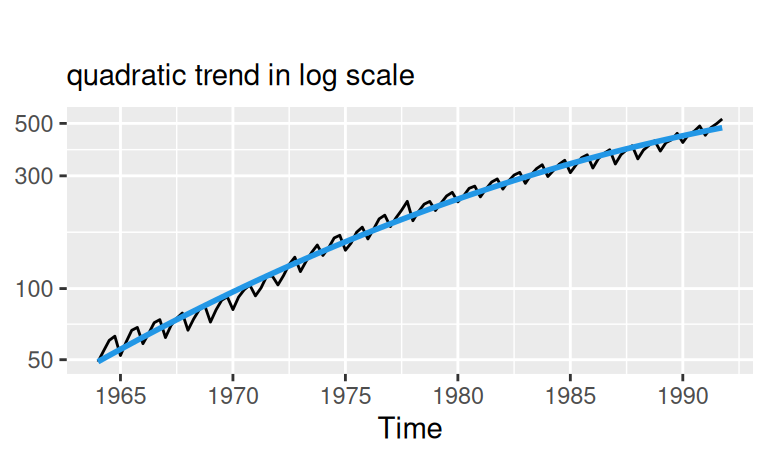
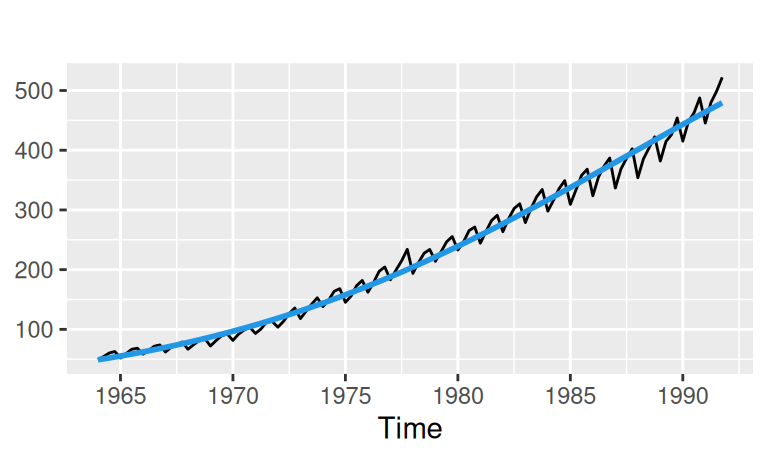
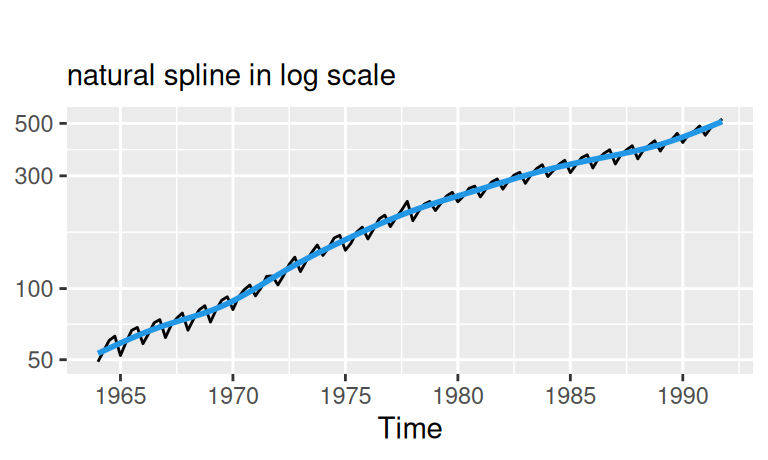
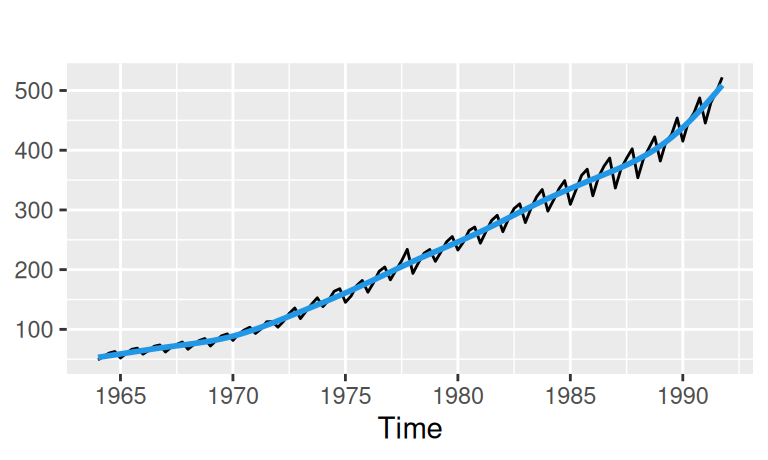
Prirodzene, oba nelineárne trendy popisujú trénovaciu vzorku lepšie ako lineárny. Kvadratický zachytáva najmä spomalovanie rastu, zatiaľčo prirodzený splajn pri desiatich stupňoch voľnosti popisuje aj zvyšné dlhoperiodické výchylky. Budú však lepšie aj v predpovednej schopnosti? Uvidíme.
Rezíduá v pôvodnej mierke (pre jeden z modelov na nasledujúcom obrázku vľavo) pre ďalšie modelovanie nemajú veľký význam, preto aj funkcia residuals z modelu vytiahne rezíduá v transformovanej mierke (obr. vpravo).
dat$train$resTns <- residuals(fit$Tns)
with(dat$train, autoplot(observed - Tns))
with(dat$train, autoplot(resTns))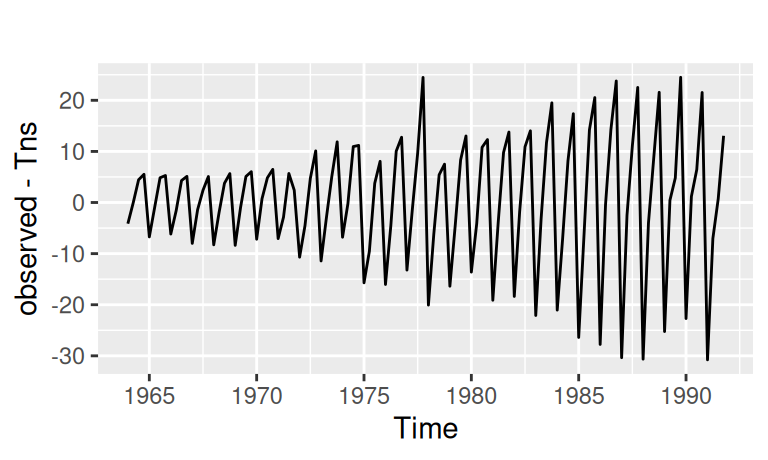
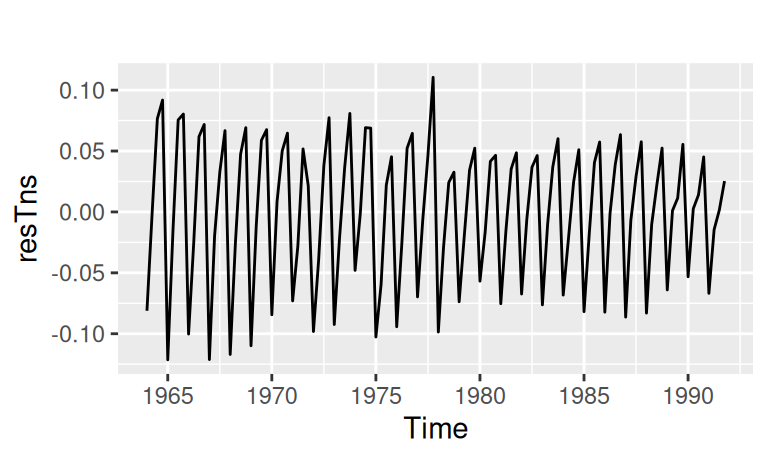
Dáta majú pomerne silnú sezónnu zložku. Jej perióda je 4 kvartály.
fit$Sind <- forecast::tslm(resTns ~ season, data = dat$train)
dat$train$Sind <- fit$Sind |> fitted()
with(dat$train, {
p1 <- forecast::autoplot(log(observed) - log(Tns)) +
forecast::autolayer(Sind, color = 4, linewidth = 1, show.legend = FALSE) +
labs(title = "model: Sind")
p2 <- forecast::autoplot(observed) +
forecast::autolayer(Tns*exp(Sind), color = 4, linewidth = 1, show.legend = FALSE) +
labs(title = "model: Tns * exp(Sind)")
p1 / p2
})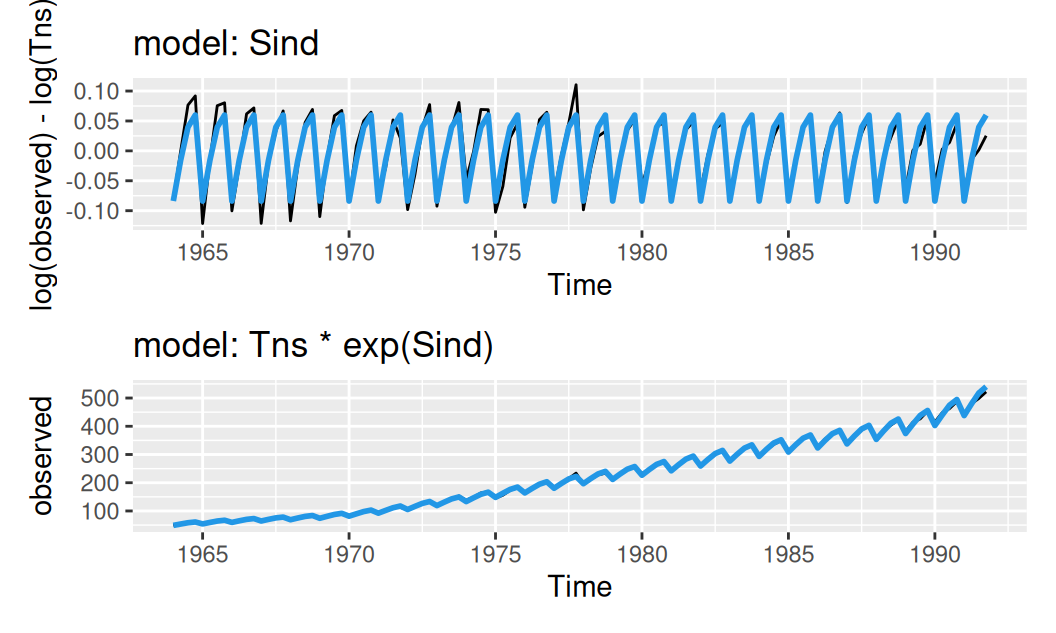
Na hornom obrázku je vidieť, že sezónny model s konštantnou aplitúdou nedokáže celkom dobre popísať takýto časový rad rezíduí. Keďže amplitúda sa mení monotónne, ide o dôsledok neoptimálnej stacionarizácie v rozptyle. Preto pri spoločnom odhade všetkých zložiek navrhneme všetky modely okrem jedného so všeobecnou, Box-Coxovou transformáciou. Jedine modelu s lineárnou funkciou pre zachovanie interpretovateľnosti ponecháme logaritmus.
Pre interpretačné účely treba ešte zobraziť model sezónnosti počas celej jednej periódy. Zaujímavé môže byť spolu so strednou hodnotou zobraziť aj rezíduá v jednotlivých sezónach.
dat$train |>
transform(Q = cycle(Sind)) |>
ggplot() + aes(x = Q) +
geom_line(aes(y = exp(Sind))) +
geom_hline(yintercept = 1, linetype = 2) +
geom_jitter(aes(y = observed/Tns), width = 0.1)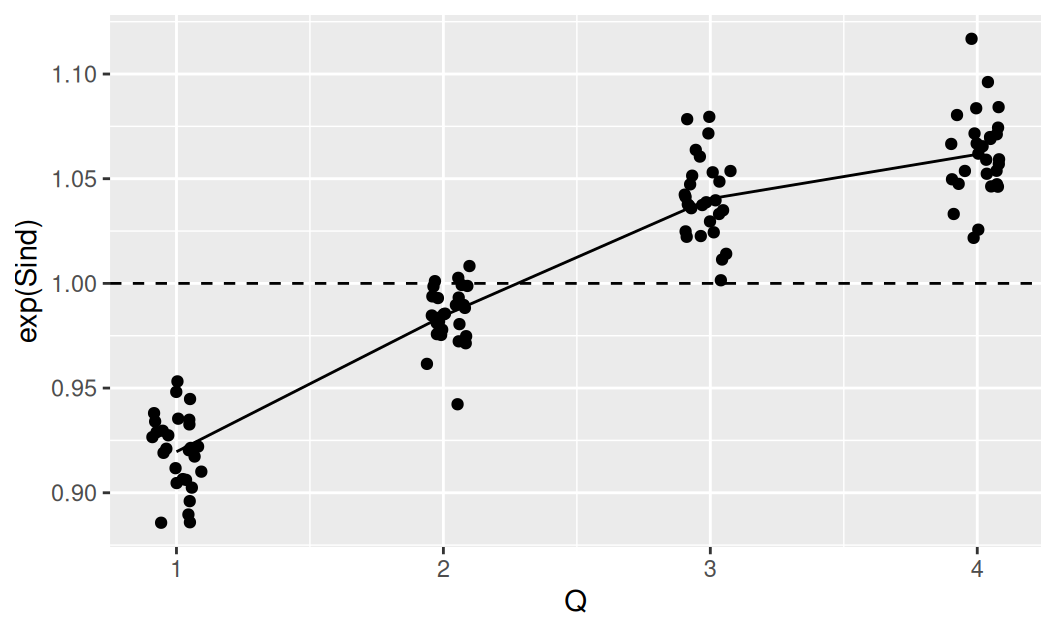
Model sezónnej zložky znižuje strednú hodnotu v prvom kvartáli o 8% (čiže ide o 92% hodnoty trendu), atď.
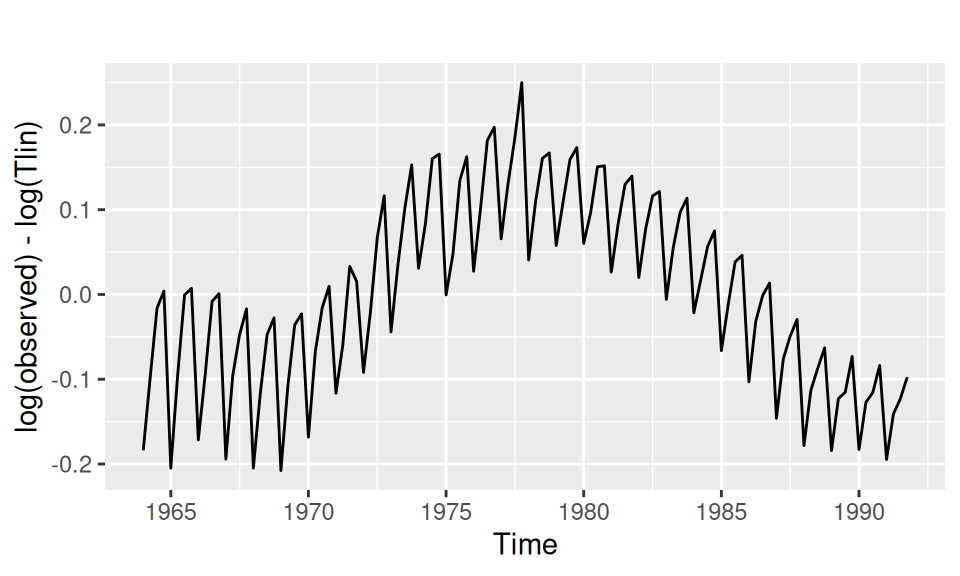
Vrátime sa ku rezíduám lineárneho (čiže v pôvodnej mierke exponenciálneho) trendu, odhadneme spektrum a harmonický regresný model.
with(dat$train, {
forecast::autoplot(log(observed) - log(Tlin)) |> print()
lomb::lsp(log(observed) - log(Tlin), type = "period", ofac = 20, main = "")
})
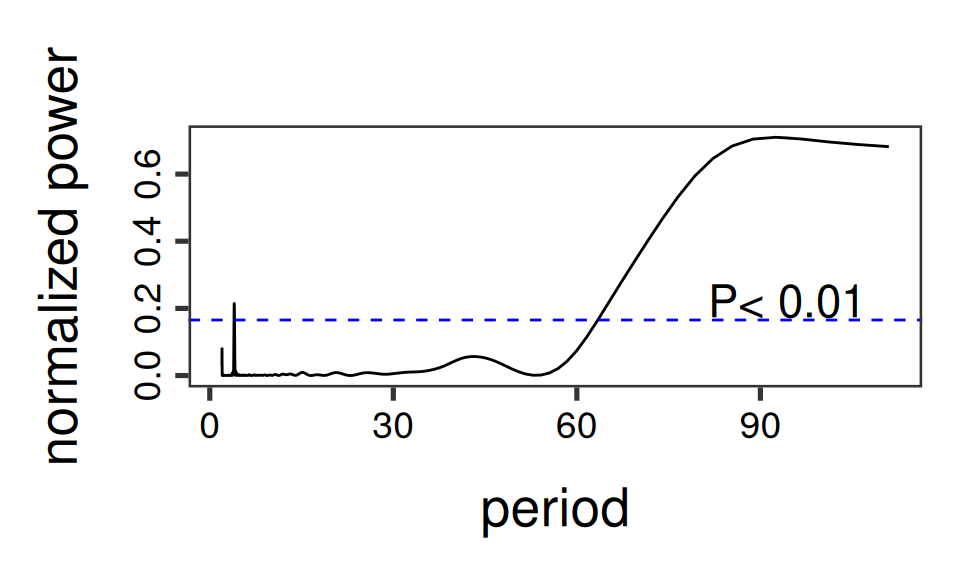
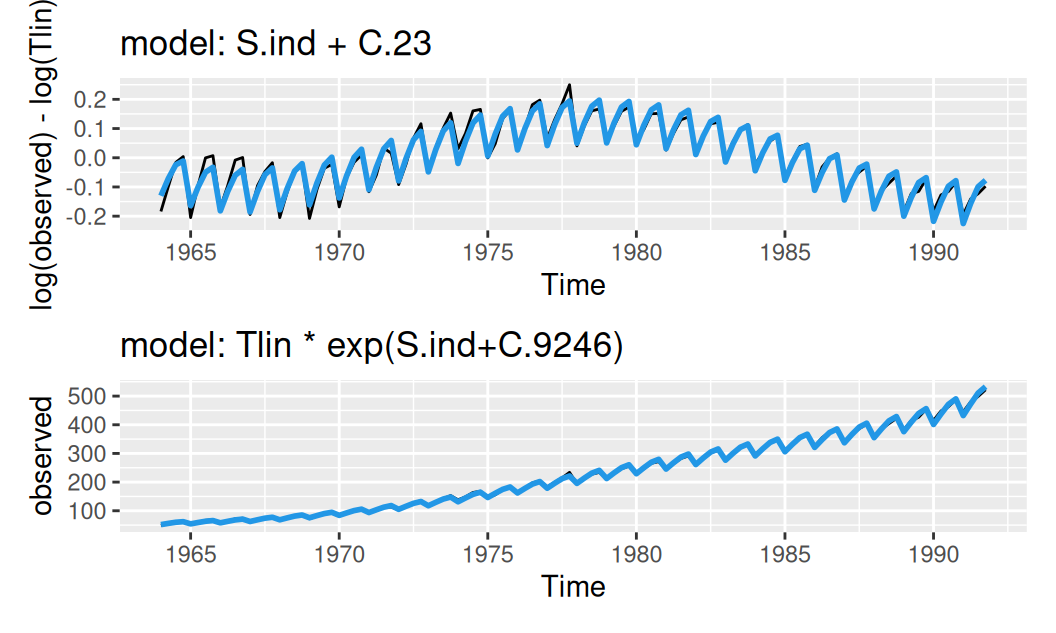
Rezíduá javia známky krátko-periodickej (sezónnej) i dlho-periodickej (cyklickej) zložky, čo potvrdzuje aj periodogram. K základnej perióde cyklickej zložky \(L= 23Y= 92Q\) použijeme v regresii aj polovičnú periódu.
dat$train$TlinResSindC23 <- dat$train |>
transform(resTlin = log(observed) - log(Tlin)) |>
forecast::tslm(resTlin ~ season +
I(cos(2*pi*time/92)) + I(sin(2*pi*time/92)) +
I(cos(2*pi*time/46)) + I(sin(2*pi*time/46)),
data = _) |>
fitted()
with(dat$train, {
p1 <- forecast::autoplot(log(observed) - log(Tlin)) +
forecast::autolayer(TlinResSindC23, color = 4, linewidth = 1, show.legend = FALSE) +
labs(title = "model: S.ind + C.23")
p2 <- forecast::autoplot(observed) +
forecast::autolayer(Tlin*exp(TlinResSindC23), color = 4, linewidth = 1, show.legend = FALSE) +
labs(title = "model: Tlin * exp(S.ind+C.9246)")
p1 / p2
})
Rezíduá ostatných modelov ponecháme bez popisu cyklickou zložkou, i keď ešte pri kvadratickom trende by sme detekovali významnú periódu 64 kvartálov (16 rokov). Ponecháme ho ako jediný predpovedný model, ktorý popisuje iba dve najvýraznejšie systematické zložky: trend a sezónnosť, aj za cenu autokorelovaných rezíduí. Zároveň poslúži ako ilustračný príklad pri detekcii nenáhodnosti rezíduí.
Uvažujeme tri dekompozičné regresné modely, vo všetkých je sezónnosť vyjadrená indikačnými premennými:
fit$logTlinSindC23 <- forecast::tslm(
observed ~ trend + season +
I(cos(2*pi*time/92)) + I(sin(2*pi*time/92)) +
I(cos(2*pi*time/46)) + I(sin(2*pi*time/46)),
data = dat$train,
lambda = 0)
fit$bcTquaSind <- forecast::tslm(
observed ~ time + I(time^2) + season,
data = dat$train,
lambda = "auto")
fit$bcTnsSind <- forecast::tslm(
observed ~ splines::ns(time, df = 10) + season,
data = dat$train,
lambda = "auto")Zvyčajne stačí vizuálna kontrola rezíduí modelu systematických zložiek na zistenie prítomnosti zvyškovej autokorelácie (a prípadne približný obraz o tvare rozdelenia).
Formálne môžeme vykonať aj testy náhodnosti.
Súčasťou diagnostickej kontroly je súhrnný (Breusch-Godfrey) test nulovosti ACF aj grafy rezíduí, ACF a histogram.
forecast::checkresiduals(fit$logTlinSindC23)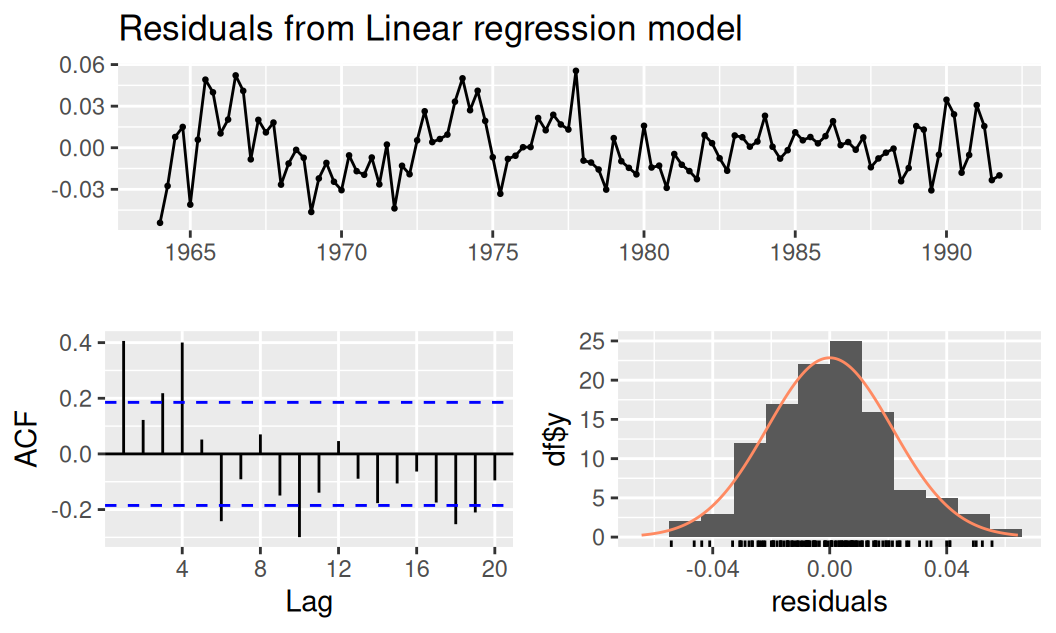
Breusch-Godfrey test for serial correlation of order up to 12
data: Residuals from Linear regression model
LM test = 46.85, df = 12, p-value = 4.949e-06fit$logTlinSindC23 |> car::durbinWatsonTest() lag Autocorrelation D-W Statistic p-value
1 0.4060793 1.122544 0
Alternative hypothesis: rho != 0fit$logTlinSindC23 |> residuals() |> randtests::difference.sign.test()
Difference Sign Test
data: residuals(fit$logTlinSindC23)
statistic = 0.16294, n = 112, p-value = 0.8706
alternative hypothesis: nonrandomnessfit$logTlinSindC23 |> residuals() |> randtests::rank.test()
Mann-Kendall Rank Test
data: residuals(fit$logTlinSindC23)
statistic = 0.11567, n = 112, p-value = 0.9079
alternative hypothesis: trendfit$logTlinSindC23 |> residuals() |> randtests::turning.point.test()
Turning Point Test
data: residuals(fit$logTlinSindC23)
statistic = -1.6569, n = 112, p-value = 0.09754
alternative hypothesis: non randomnessfit$logTlinSindC23 |> residuals() |> randtests::runs.test()
Runs Test
data: residuals(fit$logTlinSindC23)
statistic = -4.9358, runs = 31, n1 = 56, n2 = 56, n = 112, p-value =
7.981e-07
alternative hypothesis: nonrandomnessAutokorelácia je zjavne ešte nenulová, no trend ani periodické zložky by rezíduá už nemali obsahovať.
forecast::checkresiduals(fit$bcTquaSind)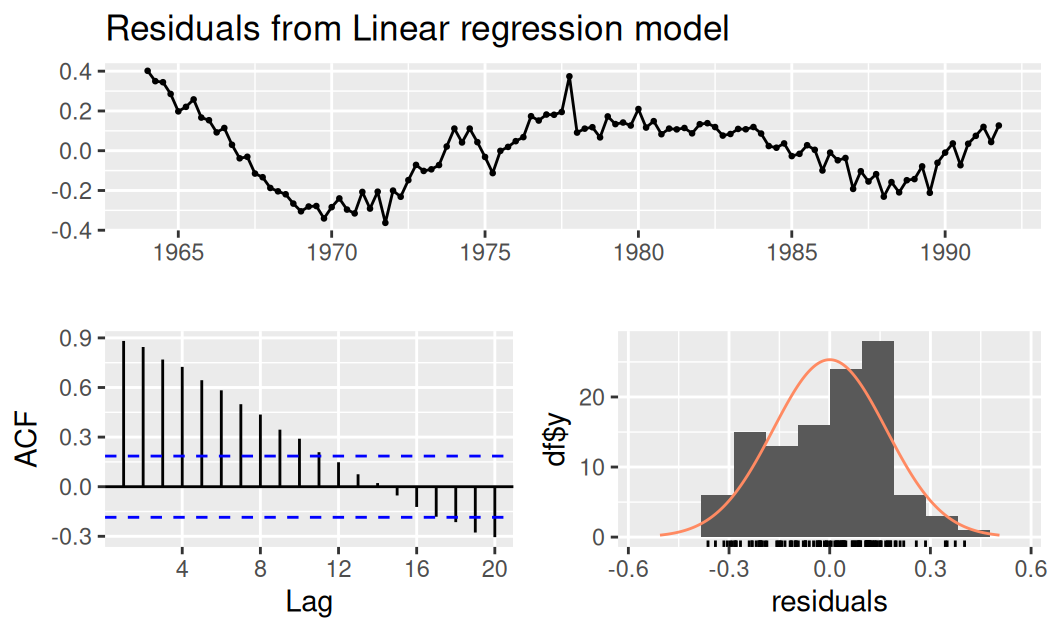
Breusch-Godfrey test for serial correlation of order up to 9
data: Residuals from Linear regression model
LM test = 91.168, df = 9, p-value = 9.487e-16fit$bcTquaSind |>
(\(x) c(
DurbinWatson = lmtest::dwtest(x)$p.value,
BreuchGodfrey = lmtest::bgtest(x, order = 16)$p.value,
DifferenceSign = randtests::difference.sign.test(resid(x))$p.value,
Rank = randtests::rank.test(resid(x))$p.value,
TurningPoint = randtests::turning.point.test(resid(x))$p.value,
Runs = randtests::runs.test(resid(x))$p.value
))() |>
round(4) DurbinWatson BreuchGodfrey DifferenceSign Rank TurningPoint
0.0000 0.0000 0.6250 0.5362 0.3275
Runs
0.0000 Je pochopitelné, že prvé dva zamietajú hypotézu o nulovosti autokorelácií, takisto ako ďalšie dva, ktoré sú citlivé na trend, nezamietajú náhodnosť rezíduí. Z posledných dvoch iba runs test (založený na počte skupín okolo mediánu) detekuje prítomnosť systematickej fluktuácie.
forecast::checkresiduals(fit$bcTnsSind, test = FALSE)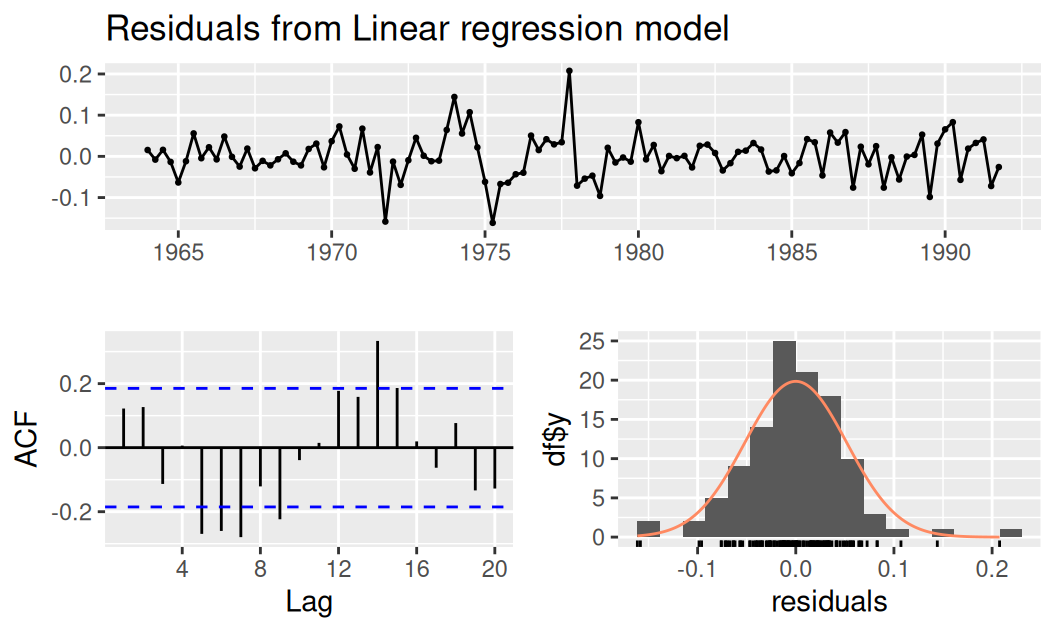
fit$bcTnsSind |>
(\(x) c(
DurbinWatson = lmtest::dwtest(x)$p.value,
BreuchGodfrey = lmtest::bgtest(x, order = 16)$p.value,
DifferenceSign = randtests::difference.sign.test(resid(x))$p.value,
Rank = randtests::rank.test(resid(x))$p.value,
TurningPoint = randtests::turning.point.test(resid(x))$p.value,
Runs = randtests::runs.test(resid(x))$p.value
))() |>
round(4) DurbinWatson BreuchGodfrey DifferenceSign Rank TurningPoint
0.0115 0.0000 0.0145 0.8015 0.7065
Runs
0.8494 Prekvapivo Difference sign test indikuje prítomnosť trendu, pričom vizuálne v rezíduách nič také nebadať. Ostatné testy podľa očakávania zamietajú prítomnosť systematických zložiek a nezamietajú autokorelovanosť rezíduí.
Výpočet a uloženie rezíduí modelu systematickej zložky
dat$train$res_logTlinSindC23 <- residuals(fit$logTlinSindC23)
dat$train$res_bcTnsSind <- residuals(fit$bcTnsSind)Neparametrická identifikácia lineárneho procesu pre rezíduá prvého modelu
with(dat$train, {
p1 <- forecast::Acf(res_logTlinSindC23, plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")
p2 <- forecast::Pacf(res_logTlinSindC23, plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")
p1 + p2
})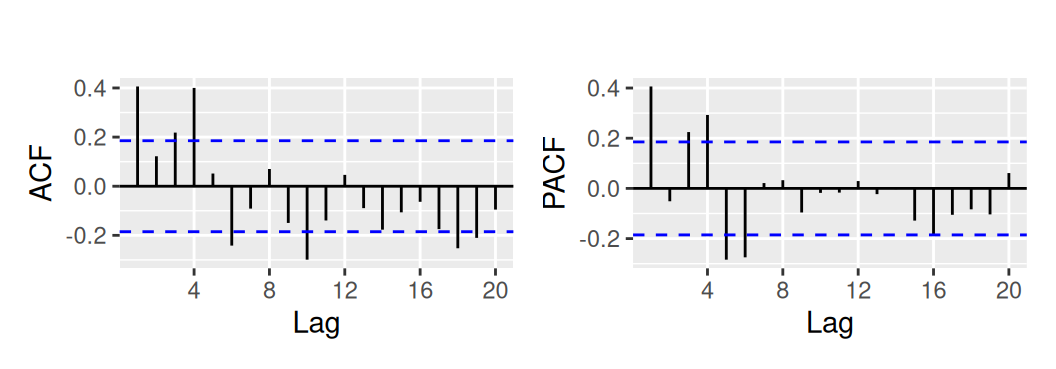
Nie je celkom zjavné, o aký lineárny proces by mohlo ísť. Náš tip bude AR(1) alebo MA(4), avšak skúsime ešte aj automatickú procedúru pomocou funkcie auto.arima.
list(ar1 = forecast::Arima(dat$train$res_logTlinSindC23,
order = c(1,0,0), include.mean = FALSE),
ma4 = forecast::Arima(dat$train$res_logTlinSindC23,
order = c(0,0,4), include.mean = FALSE)
) |>
sapply(BIC) ar1 ma4
-555.9614 -558.5509 dat$train |>
with(forecast::auto.arima(res_logTlinSindC23))Series: res_logTlinSindC23
ARIMA(1,0,0)(1,0,0)[4] with zero mean
Coefficients:
ar1 sar1
0.4391 0.4579
s.e. 0.0857 0.0886
sigma^2 = 0.0003073: log likelihood = 294.39
AIC=-582.79 AICc=-582.57 BIC=-574.63Zdá sa, že automat vybral model s nižším BIC než modely, ktoré sme identifikovali manuálne. Keby sme však vo finálnom modeli použili ARMA(1,1) alebo AR(1), v rezíduách by pretrvala výrazná sezónna autokorelácia. To môže byť dôsledok nedokonale vystihnutého statického modelu system. zožiek, ale kľudne aj stochastickej povahy sezónnosti. Zahrnieme ju v spoločnom modeli prostredníctvom MA(4).
Pri rezíduách druhého modelu systematických zložiek (s prirodzeným splajnom) identifikácia nie je o nič jednoduchšia.
with(dat$train, {
p1 <- forecast::Acf(res_bcTnsSind, plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")
p2 <- forecast::Pacf(res_bcTnsSind, plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")
p1 + p2
})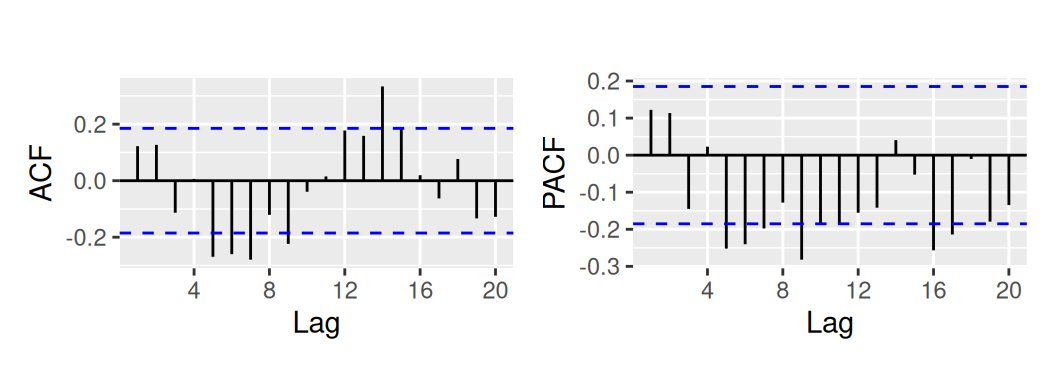
Presah cez pásy nulovosti zvádza zvoliť vysoký stupeň lineárneho procesu, no uprednostníme radšej jednoduchší variant, bez modelu reziduálnej zložky. K rovnakému záveru prišla aj procedúra na automatickú parametrickú identifikáciu.
forecast::auto.arima(dat$train$res_bcTnsSind, ic = "bic")Series: dat$train$res_bcTnsSind
ARIMA(0,0,0) with zero mean
sigma^2 = 0.002671: log likelihood = 172.9
AIC=-343.81 AICc=-343.77 BIC=-341.09Model s flexibilnejším trendom a sezónnosťou teda už nevyžaduje ďalšie rozširovanie.
Vytvorenie jediného dekompozičného modelu je potrebné jednak pre správne odhady parametrov modelov jednotlivých zložiek, jednak pre jednoduchý výpočet predpovedí.
Odhad zabezpečí funkcia Arima, treba jej len dodať maticu plánu modelu systematických zložiek. Hoci sa takáto regresná matica dá vytiahnuť z výstupu funkcie tslm, nie je to tak priamočiare ako z klasickej funkcie lm a navyše – čo je horšie – nebude sa dať extrapolovať pri predpovedaní. Preto bude treba definovať rovnicu modelu znovu a klasickým spôsobom (nie pomocnými regresormi ako trend či fourier). Absolútny člen pre celý model (intercept) tu nevynecháme, pretože inak by aj tak bol explicitne zahrnutý v sezónnej časti (t.j. aj pre prvý kvartál).
Uvažujeme iba prvý variant (reziduálnu zložku druhého statického modelu sme sa rozhodli považovať za nekorelovanú).
make_Xreg_TlinSindC23 <- function(data) {
"~ time + as.factor(cycle(time)) +
I(cos(2*pi*time/92)) + I(sin(2*pi*time/92)) +
I(cos(2*pi*time/46)) + I(sin(2*pi*time/46))" |>
as.formula() |>
model.matrix(data = data)
# inclusion of intercept automatically excludes first level of seasonal factor
}
make_Xreg_TlinSindC23(dat$train) |> head() |> `colnames<-`(NULL) |> round(4) [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
1 1 1964.00 0 0 0 -0.5767 0.8170 -0.3349 -0.9423
2 1 1964.25 1 0 0 -0.5905 0.8070 -0.3025 -0.9531
3 1 1964.50 0 1 0 -0.6042 0.7968 -0.2698 -0.9629
4 1 1964.75 0 0 1 -0.6178 0.7864 -0.2368 -0.9716
5 1 1965.00 0 0 0 -0.6311 0.7757 -0.2035 -0.9791
6 1 1965.25 1 0 0 -0.6442 0.7648 -0.1699 -0.9855Pripravenú funkciu na konštrukciu matice plánu použijeme v odhade spoločného modelu. Pozor si treba dať už len na duplicitné zaradenie absolútneho člena. Tu pre zmenu oproti predošlej časti budeme používať absolútny člen z matice plánu.
fit$logTlinSindC23Rma4 <- forecast::Arima(
dat$train$observed,
order = c(0, 0, 4),
xreg = make_Xreg_TlinSindC23(dat$train),
include.mean = FALSE,
lambda = 0
)
fit$logTlinSindC23Rma4Series: dat$train$observed
Regression with ARIMA(0,0,4) errors
Box Cox transformation: lambda= 0
Coefficients:
ma1 ma2 ma3 ma4 (Intercept) time
0.2973 0.1547 0.1686 0.3923 -211.4981 0.1106
s.e. 0.0858 0.1048 0.1111 0.0825 366.2836 0.1852
as.factor(cycle(time))2 as.factor(cycle(time))3 as.factor(cycle(time))4
0.0688 0.1247 0.1457
s.e. 0.0055 0.0059 0.0056
I(cos(2 * pi * time/92)) I(sin(2 * pi * time/92))
3.0567 0.8014
s.e. 0.2052 3.8075
I(cos(2 * pi * time/46)) I(sin(2 * pi * time/46))
1.1423 0.2274
s.e. 0.0704 0.5591
sigma^2 = 0.0003622: log likelihood = 291.32
AIC=-554.63 AICc=-550.3 BIC=-516.57Základné diagnostické nástroje sú podobné ako pre model systematických zložiek, líšia sa iba v teste nulovosti ACF.
fit$logTlinSindC23Rma4 |>
forecast::checkresiduals()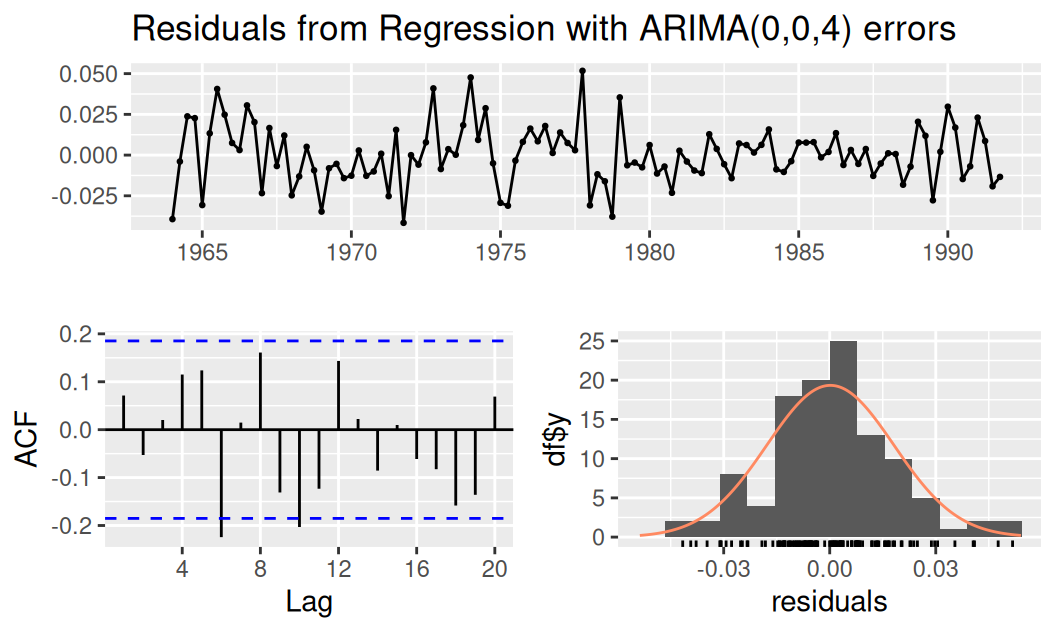
Ljung-Box test
data: Residuals from Regression with ARIMA(0,0,4) errors
Q* = 13.611, df = 4, p-value = 0.008645
Model df: 4. Total lags used: 8ACF je nulová a vidíme prakticky gaussovsky rozdelený biely šum. Normalitu rezíduí prvého modelu nezamieta ani formálny test:
fit$logTlinSindC23Rma4 |> residuals() |> tseries::jarque.bera.test()
Jarque Bera Test
data: residuals(fit$logTlinSindC23Rma4)
X-squared = 1.6037, df = 2, p-value = 0.4485Pri druhom to už neplatí:
fit$bcTnsSind |> residuals() |> tseries::jarque.bera.test()
Jarque Bera Test
data: residuals(fit$bcTnsSind)
X-squared = 31.428, df = 2, p-value = 1.498e-07Testov heteroskedasticity je viacero, pozri napr. funkcie TSA::TSA::McLeod.Li.test, lmtest::bptest, alebo funkcie balíka olsrr.
Na rozdiel od predošlého príkladu bude kapitola pre zmenu vrstvená podľa postupu (nie podľa typu predpovedí): najprv výpočet predpovedí a ich presnosti, potom zobrazenie výsledkov. Pre podrobnosti k niektorým krokom pozri Sekcia 13.1.1.9.
Jednokrokové predpovede modelov bez reziduálnej zložky sú totožné s viackrokovými predpoveďami.
Naivná predpoveď kvôli intervalovému odhadu vyžaduje voľbu transformačného parametra. Tu použijeme jednoducho iba logaritmus (lambda = 0).
fore <- list(
# multi-step forecast
multi = list(
# naive forecast is the same as random walk (without drift) forecast
naive = forecast::naive(dat$train$observed, h = nrow(dat$valid), lambda = 0),
# argument newdata supplies the time variable in static model
logTlinSindC23 = fit$logTlinSindC23 |> forecast::forecast(newdata = dat$valid),
bcTquaSind = fit$bcTquaSind |> forecast::forecast(newdata = dat$valid),
bcTnsSind = fit$bcTnsSind |> forecast::forecast(newdata = dat$valid),
# xreg supply the regressors explicitly
logTlinSindC23Rma4 = fit$logTlinSindC23Rma4 |>
forecast::forecast(xreg = make_Xreg_TlinSindC23(dat$valid))
),
# 1-step-ahead forecast, prediction interval is calculated in transformed scale
one = list(
# naive (last observed)
naive = data.frame(
mean = dat$all$observed |> log() |> tail(nrow(dat$valid)+1) |> head(-1) |> lag(k = -1)
) |>
with({
sdev <- dat$train$observed |> log() |> diff() |> sd() # random walk, no drift
data.frame(mean = mean,
lower = mean - 2*sdev,
upper = mean + 2*sdev) |>
dplyr::mutate(across(everything(), exp))
}),
# model of systematic and random components
logTlinSindC23Rma4 = data.frame(
mean = forecast::Arima(dat$all$observed,
xreg = make_Xreg_TlinSindC23(dat$all),
model = fit$logTlinSindC23Rma4
) |>
fitted() |>
window(start = start(dat$valid$observed))
) |>
dplyr::mutate(
# code generalized for any lambda (here model$lambda = 0, log-transform)
mean = forecast::BoxCox(mean, lambda = fit$logTlinSindC23Rma4$lambda),
lower = mean - 2*sqrt(fit$logTlinSindC23Rma4$sigma2),
upper = mean + 2*sqrt(fit$logTlinSindC23Rma4$sigma2),
across(everything(),
.fns = ~forecast::InvBoxCox(.x, lambda = fit$logTlinSindC23Rma4$lambda))
)
)
)Presnosť
accu <- list(
multi = fore$multi |>
lapply(forecast::accuracy, x = dat$valid$observed) |>
lapply(round, digits = 2) |>
lapply(tibble::as_tibble, rownames = "Set") |>
dplyr::bind_rows(.id = "model")
,
one = fore$one |>
lapply(function(y) forecast::accuracy(y$mean, x = dat$valid$observed)) |>
lapply(round, digits = 2) |>
lapply(tibble::as_tibble, rownames = "Set") |>
dplyr::bind_rows(.id = "model")
) |>
lapply(as.data.frame)Preddefinovanie základu grafov, trénovacia a validačná vzorka:
p <- list()
p$observed <- forecast::autoplot(dat$train$observed) +
forecast::autolayer(dat$valid$observed, color = "gray50") +
labs(y = NULL)
p$observed_cut <-
forecast::autoplot(window(dat$train$observed, start = c(1990,1))) +
forecast::autolayer(dat$valid$observed, color = "gray50") +
labs(y = NULL)Predpovede v kontexte celého časového radu:
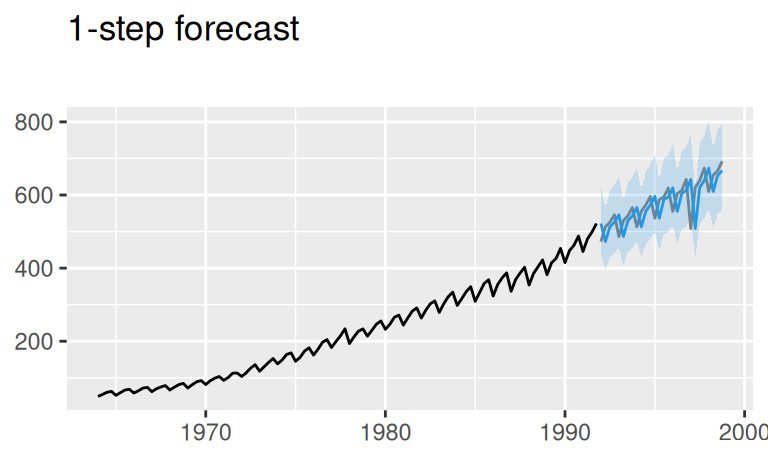
# naive
p$observed +
forecast::autolayer(fore$multi$naive, alpha = 0.5) +
labs(title = "Multi-step forecast", x = NULL,
subtitle = "Naive")
p$observed +
forecast::autolayer(fore$one$naive$mean, color = 4) +
geom_ribbon(dat = fore$one$naive,
mapping = aes(x = time(mean), ymin = lower, ymax = upper),
fill = 4, alpha = 0.2, inherit.aes = FALSE) +
labs(title = "1-step forecast", x = NULL,
subtitle = "")
# logTlinSindC23
p$observed +
forecast::autolayer(fore$multi$logTlinSindC23, alpha = 0.5) +
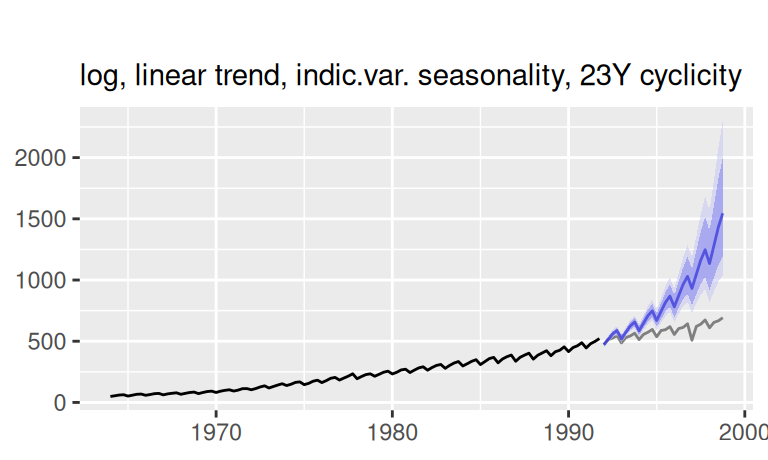
labs(x = NULL, subtitle = "log, linear trend, indic.var. seasonality, 23Y cyclicity")
p$observed +
forecast::autolayer(fore$multi$logTlinSindC23, color = 4) +
labs(x = NULL, subtitle = "")
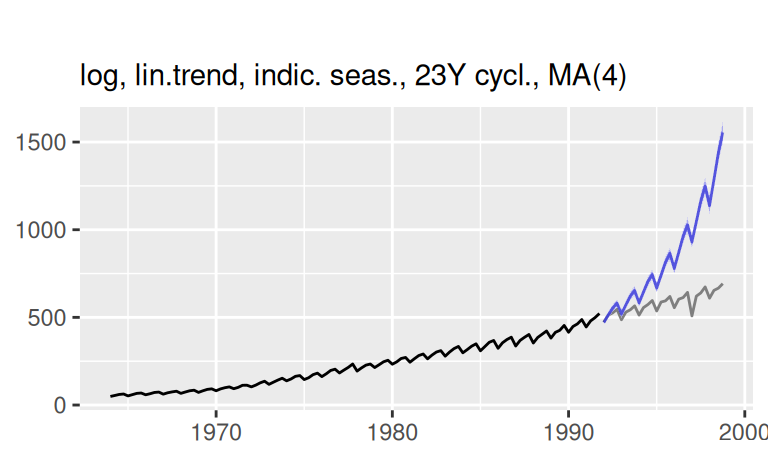
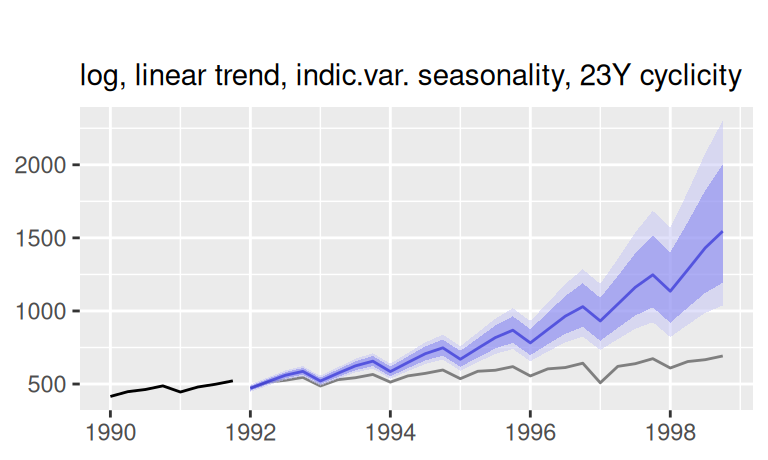
# logTlinSindC23Rma4
p$observed +
forecast::autolayer(fore$multi$logTlinSindC23Rma4, alpha = 0.5) +
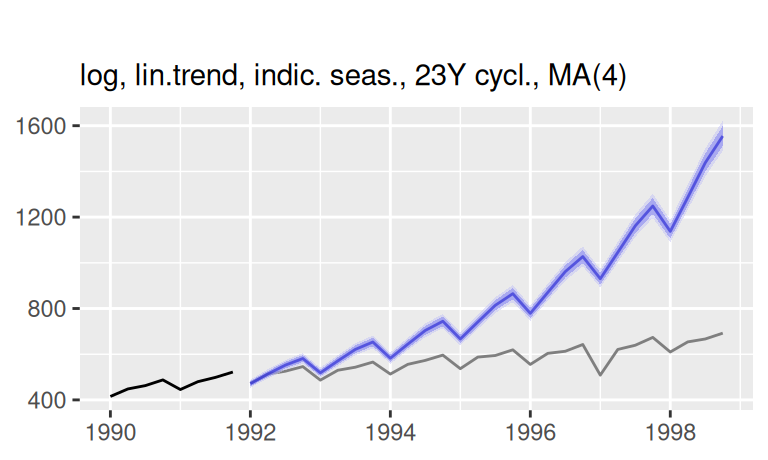
labs(x = NULL, subtitle = "log, lin.trend, indic. seas., 23Y cycl., MA(4)")
p$observed +
forecast::autolayer(fore$one$logTlinSindC23Rma4$mean, color = 4) +
geom_ribbon(dat = fore$one$logTlinSindC23Rma4,
mapping = aes(x = time(mean), ymin = lower, ymax = upper),
fill = 4, alpha = 0.2, inherit.aes = FALSE) +
labs(x = NULL, subtitle = "")
# bcTquaSind
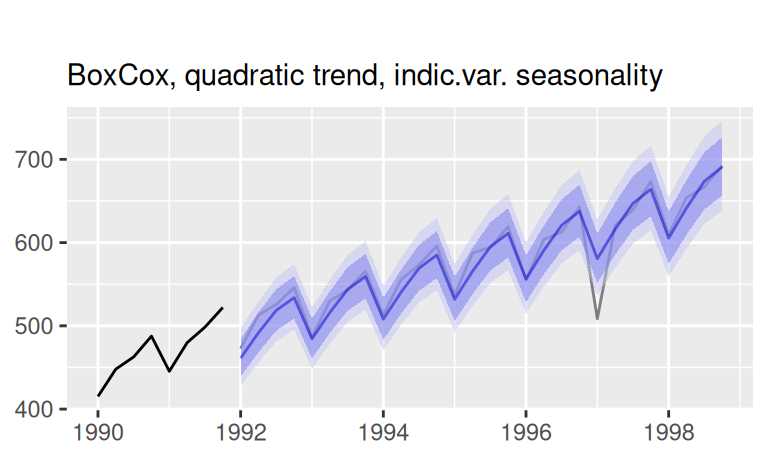
p$observed +
forecast::autolayer(fore$multi$bcTquaSind, alpha = 0.3) +
labs(x = NULL, subtitle = "BoxCox, quad.trend, indic.var. seasonality")
p$observed +
forecast::autolayer(fore$multi$bcTquaSind, color = 4, alpha = 0.3) +
labs(x = NULL, subtitle = "")
# bcTnsSind
p$observed +
forecast::autolayer(fore$multi$bcTnsSind, alpha = 0.5) +
labs(x = NULL, subtitle = "BoxCox, natural spline, indic.var. seasonality")
p$observed +
forecast::autolayer(fore$multi$bcTnsSind, color = 4) +
labs(x = NULL, subtitle = "")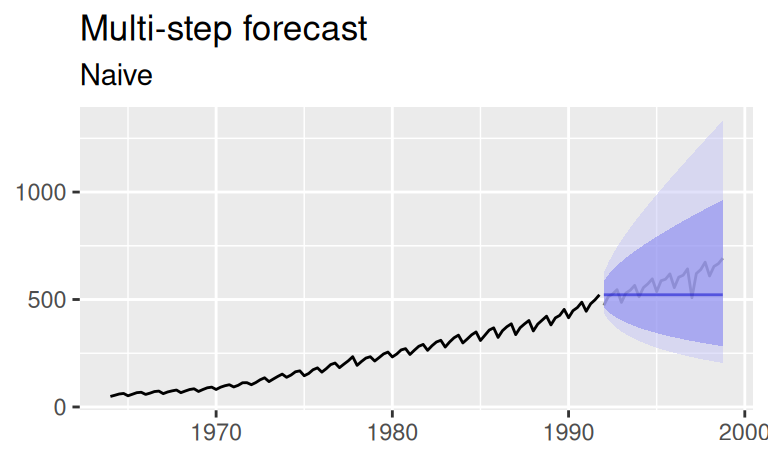
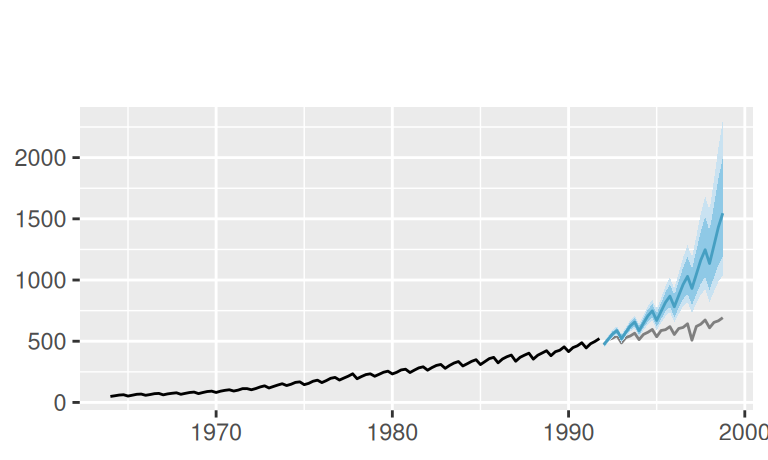
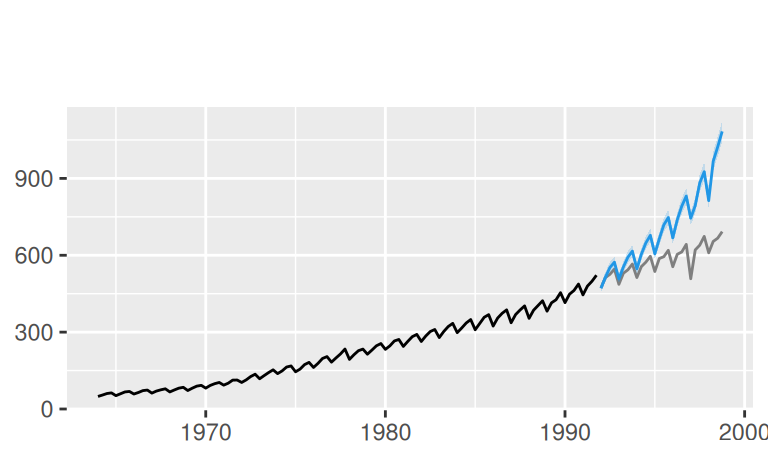
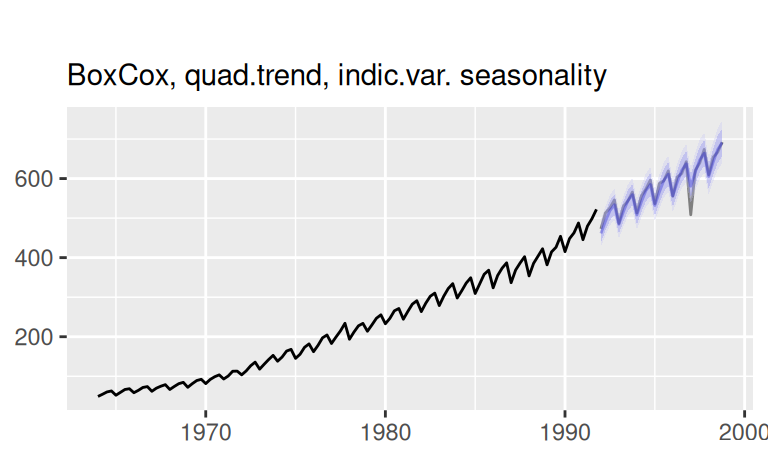
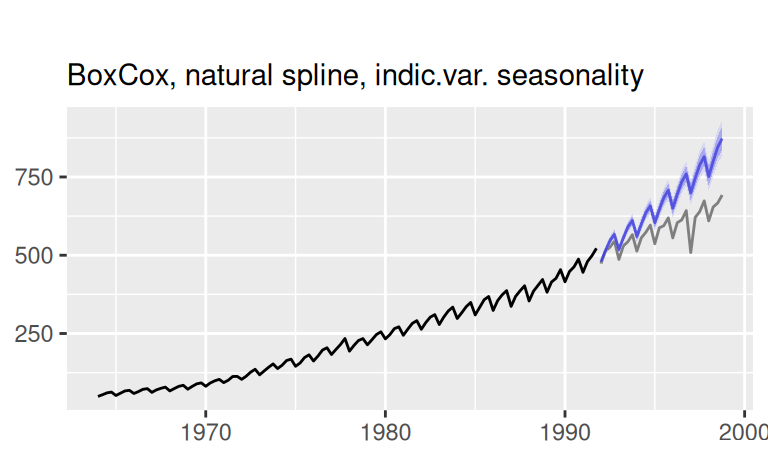
Detailný pohľad na predpovede:
# naive
p$observed_cut +
forecast::autolayer(fore$multi$naive, alpha = 0.5) +
labs(title = "Multi-step forecast", x = NULL,
subtitle = "Naive")
p$observed_cut +
geom_ribbon(dat = fore$one$naive,
mapping = aes(x = time(mean), ymin = lower, ymax = upper),
fill = 4, alpha = 0.5, inherit.aes = FALSE) +
forecast::autolayer(fore$one$naive$mean, color = 4, alpha = 0.5) +
labs(title = "1-step forecast", x = NULL,
subtitle = "")
# logTlinSindC23
p$observed_cut +
forecast::autolayer(fore$multi$logTlinSindC23, alpha = 0.5) +
labs(x = NULL, subtitle = "log, linear trend, indic.var. seasonality, 23Y cyclicity")
p$observed_cut +
forecast::autolayer(fore$multi$logTlinSindC23, color = 4, alpha = 0.5) +
labs(x = NULL, subtitle = "")
# logTlinSindC23Rma4
p$observed_cut +
forecast::autolayer(fore$multi$logTlinSindC23Rma4, alpha = 0.5) +
labs(x = NULL, subtitle = "log, lin.trend, indic. seas., 23Y cycl., MA(4)")
p$observed_cut +
geom_ribbon(dat = fore$one$logTlinSindC23Rma4,
mapping = aes(x = time(mean), ymin = lower, ymax = upper),
fill = 4, alpha = 0.5, inherit.aes = FALSE) +
forecast::autolayer(fore$one$logTlinSindC23Rma4$mean, color = 4, alpha = 0.5) +
labs(x = NULL, subtitle = "")
# bcTquaSind
p$observed_cut +
forecast::autolayer(fore$multi$bcTquaSind, alpha = 0.5) +
labs(x = NULL, subtitle = "BoxCox, quadratic trend, indic.var. seasonality")
p$observed_cut +
forecast::autolayer(fore$multi$bcTquaSind, color = 4, alpha = 0.5) +
labs(x = NULL, subtitle = "")
# bcTnsSind
p$observed_cut +
forecast::autolayer(fore$multi$bcTquaSind, alpha = 0.5) +
labs(x = NULL, subtitle = "BoxCox, natural spline, indic.var. seasonality")
p$observed_cut +
forecast::autolayer(fore$multi$bcTquaSind, color = 4, alpha = 0.5) +
labs(x = NULL, subtitle = "")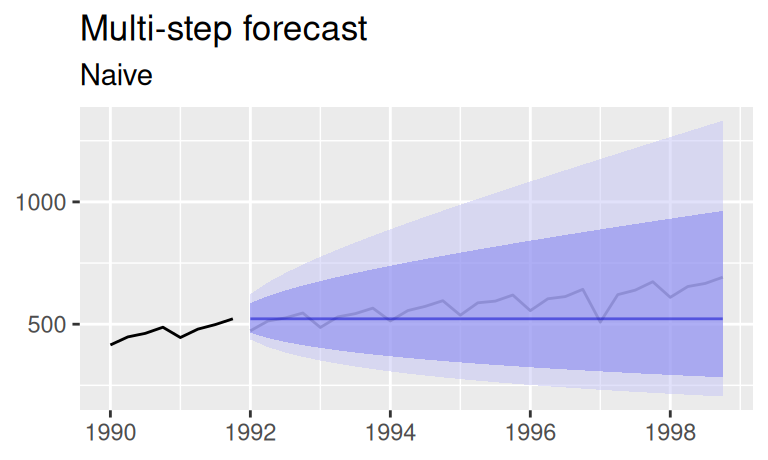
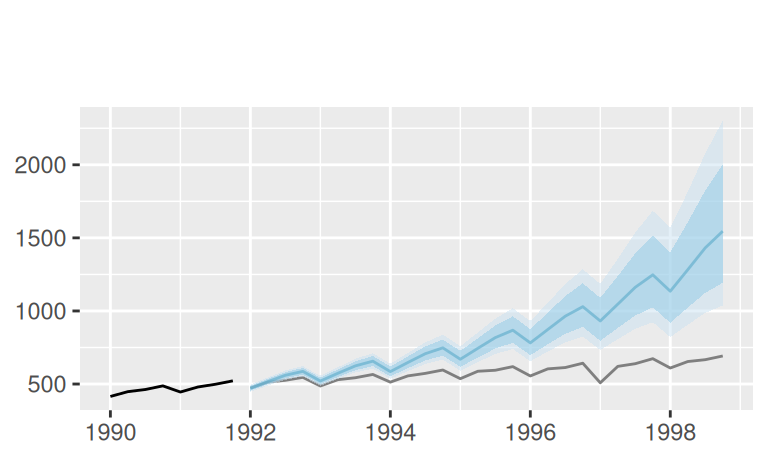
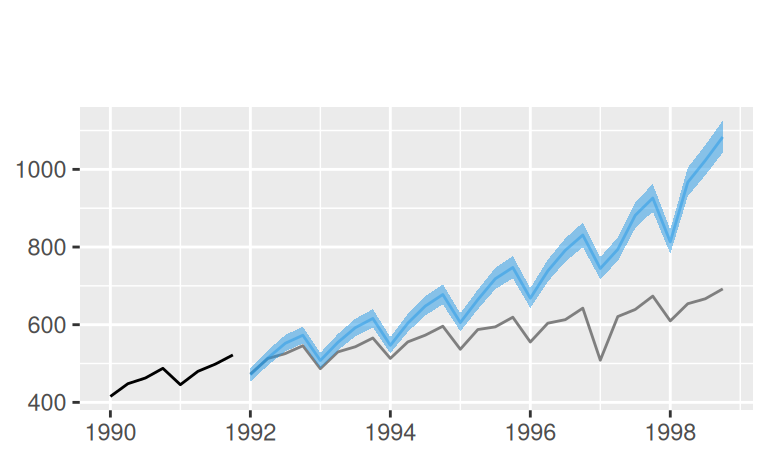
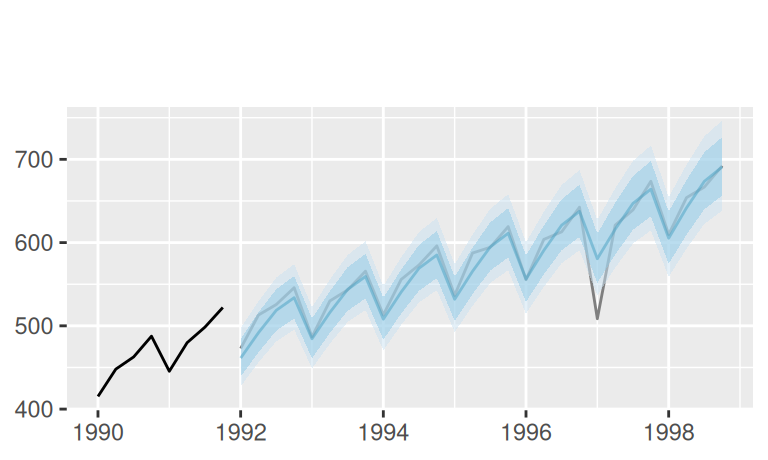
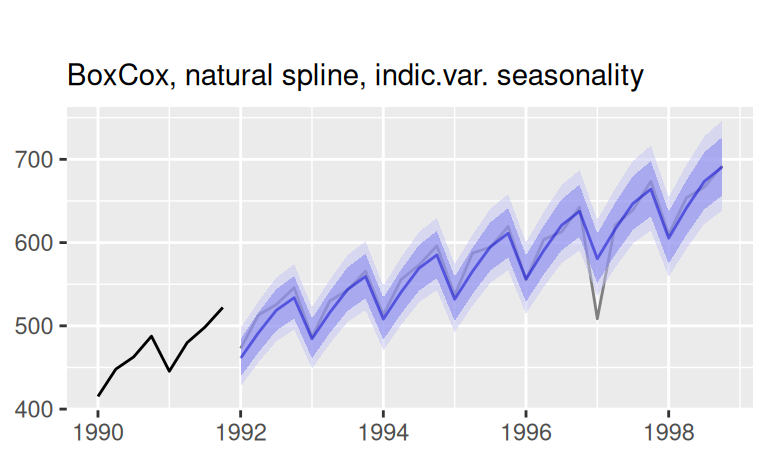
Presnosť viackrokových predpovedí:
accu$multi |>
dplyr::select(model, Set, RMSE, MPE) |>
dplyr::arrange(desc(Set)) model Set RMSE MPE
1 naive Training set 19.93 1.72
2 logTlinSindC23 Training set 4.57 -0.02
3 bcTquaSind Training set 7.77 -0.14
4 bcTnsSind Training set 3.05 -0.01
5 logTlinSindC23Rma4 Training set 3.86 0.00
6 naive Test set 81.81 9.08
7 logTlinSindC23 Test set 357.31 -43.26
8 bcTquaSind Test set 16.71 0.58
9 bcTnsSind Test set 101.46 -14.22
10 logTlinSindC23Rma4 Test set 358.05 -42.96Presnosť jednokrokových predpovedí:
accu$one |>
dplyr::select(model, Set, RMSE, MPE) model Set RMSE MPE
1 naive Test set 49.69 0.62
2 logTlinSindC23Rma4 Test set 168.13 -21.01Lineárna funkcia (spolu s dlhoperiodickou harmonickou funkciou) aj prirodzený kubický splajn zjavne nevystihli trend vývoja HDP po roku 1991. Vystihol ho iba kvadratický trend, ktorého voľbou sme do predpovedí pridali predpoklad tlmenia rastu.
Regresný dekompozičný prístup predpokladá deterministický charakter nestacionarity, takže k rozkladu používa statické modely systematických zložiek. Ak je však trend alebo sezónnosť stochastickej povahy, na popis časového radu sú vhodnejšie integrované zmiešané modely ARIMA.
V prvom kroku pripravíme dáta (poupratujeme objekty z predošlej časti) a znovu ich vykreslíme.
dat <- dat |> # keep only time index and response variable
lapply(`[`, c("observed", "time")) # subset(dat, select = ...) drops ts class
list(train = dat$train$observed,
valid = dat$valid$observed) |>
with({
ggplot() + forecast::autolayer(train) + autolayer(valid) +
scale_color_manual(values = c(train = 1, valid = 2)) +
guides(color = guide_legend(title = "sample")) +
theme(legend.position = "inside",
legend.position.inside = c(0.99, 0.01),
legend.justification = c("right","bottom")) +
labs(x = "year", y = "observed")
})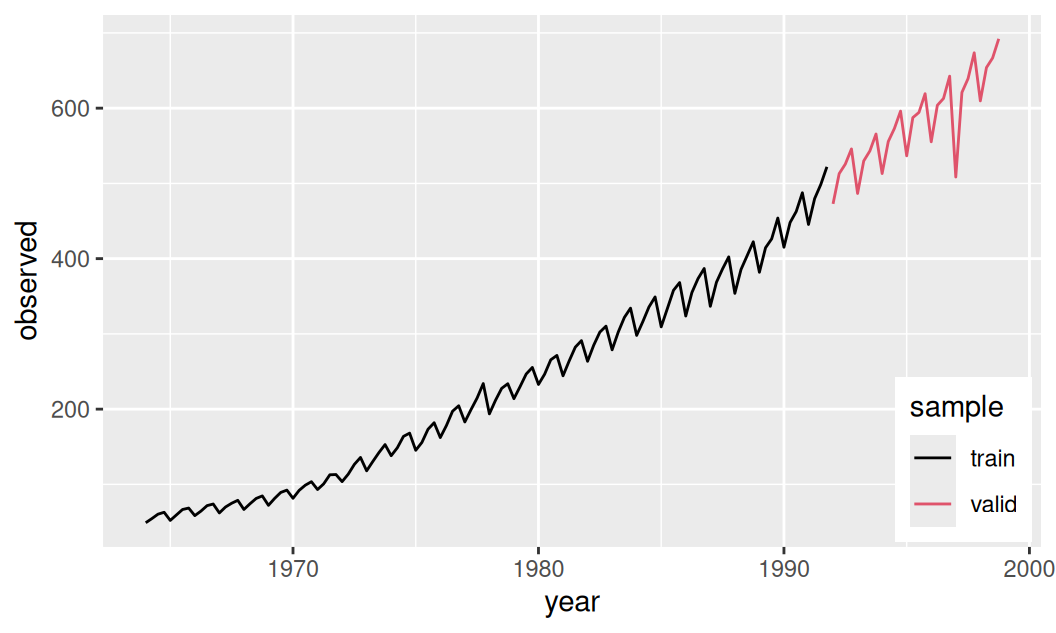
Z grafu trénovacej vzorky sa dá vytušiť deterministický trend, pravdepodobne iba lineárny avšak s niekoľkými náhodnými zmenami v sklone, a sezónna zložka zvyšujúca svoju amplitúdu v závislosti od strednej hodnoty časového radu. Navrhneme niekoľko modelov SARIMA, ktoré by mohli byť vhodné na popis trénovacej vzorky ale nie príliš zložité, aby nezlyhali v predpovediach.
Výstavba modelu prebehne v nasledujúcich krokoch:
Najprv určíme optimálnu hodnotu parametra Box-Cox transformácie a časový rad stacionarizujeme v rozptyle.
# Box-Cox transformation parameter
dat$train$observed |> forecast::BoxCox.lambda()[1] 0.2544449# temporary data container
tdata <- list()
# BC transformation
tdata$bc <- dat$train$observed |> forecast::BoxCox(0.254)Vyhladenie a testy:
# smothing needed for stationarity test
tdata$bcNoseas <- tdata$bc |> forecast::ma(order = 4)
tdata$Tlin <- tdata |> as.data.frame() |> # tslm require data frame
forecast::tslm(bc ~ trend, data = _) |> fitted()
autoplot(tdata$bc) +
forecast::autolayer(tdata$bcNoseas, color = 2) +
forecast::autolayer(tdata$Tlin, color = 4)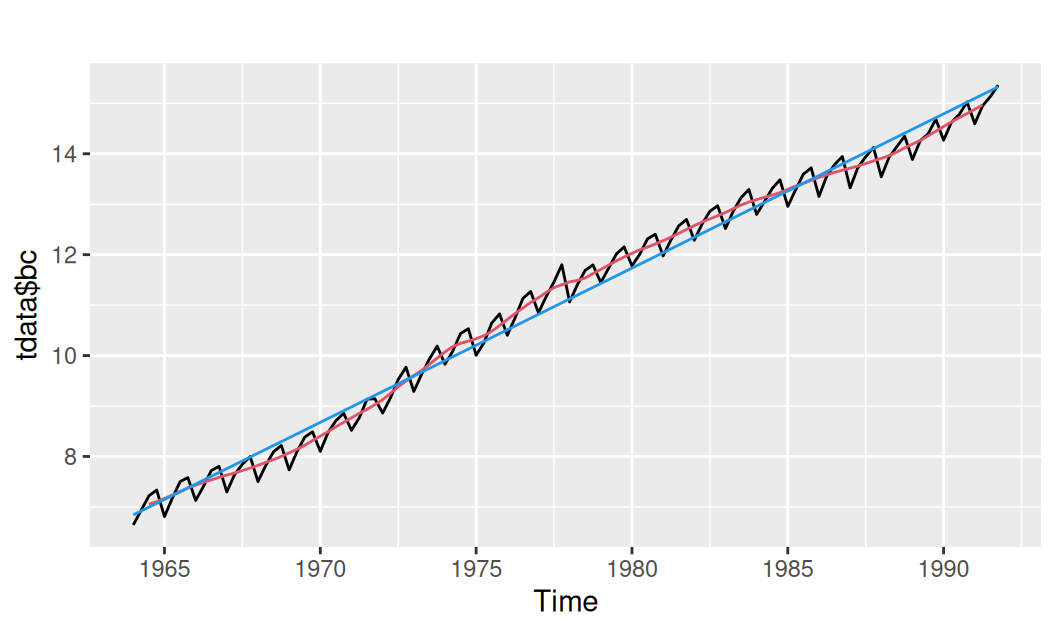
# Augmented Dickey-Fuller test for unit root
tdata |>
with(bcNoseas - Tlin) |>
na.omit() |>
tseries::adf.test()
Augmented Dickey-Fuller Test
data: na.omit(with(tdata, bcNoseas - Tlin))
Dickey-Fuller = -1.2798, Lag order = 4, p-value = 0.8754
alternative hypothesis: stationary# KPSS test for stationarity
tdata |>
with(bcNoseas - Tlin) |>
na.omit() |>
tseries::kpss.test()
KPSS Test for Level Stationarity
data: na.omit(with(tdata, bcNoseas - Tlin))
KPSS Level = 0.44396, Truncation lag parameter = 4, p-value = 0.0582ADF test nezamieta nulovú hypotézu o prítomnosti jednotkového koreňa. Naopak, KPSS na hl.významnosti 5% nezamieta nul.hypotézu o stacionarite, avšak p-hodnota je blízko 5%, preto túto dilemu uzavtrieme v prospech hypotézy o prítomnosti stochastického trendu.
Detrendovanie a diferencovanie:
tdata$bcDtr <- tdata$bc - tdata$Tlin
tdata$bcDtrDif4 <- tdata$bcDtr |> diff(lag = 4)
tdata$bcDtrDif4Dif1 <- tdata$bcDtrDif4 |> diff()
tdata[c("bc", "bcDtr", "bcDtrDif4", "bcDtrDif4Dif1")] |>
do.call(what = ts.union) |>
forecast::autoplot(facet = T) + labs(y = NULL)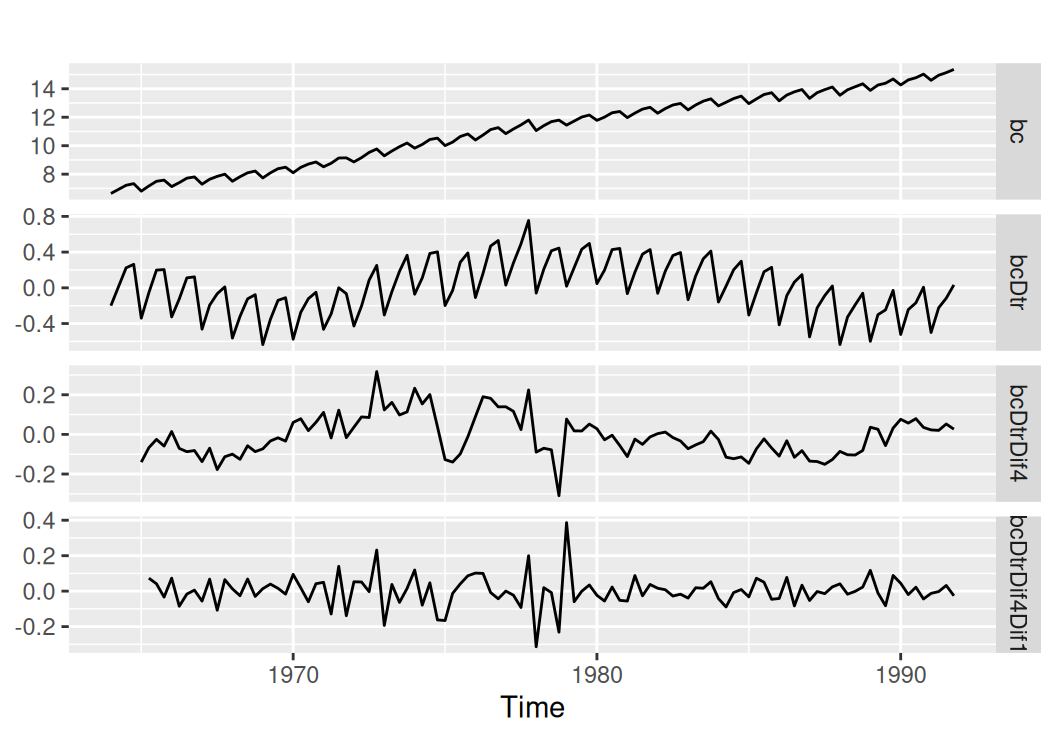
Detrendovanie aj sezónne diferencie výrazne prispeli ku stacionarizácii časového radu. O tom, či sú potrebné aj jednoduché diferencie, môžeme polemizovať, v ich prospech hovorí aj ďalší pokles variancie, v neprospech zas zamietnutie nulovej hypotézy o prítomnosti jednotkového koreňa Phillips-Perron testom.
tdata[c("bc", "bcDtr", "bcDtrDif4", "bcDtrDif4Dif1")] |> sapply(var) |> round(3) bc bcDtr bcDtrDif4 bcDtrDif4Dif1
6.251 0.090 0.010 0.007 tseries::pp.test(tdata$bcDtrDif4)
Phillips-Perron Unit Root Test
data: tdata$bcDtrDif4
Dickey-Fuller Z(alpha) = -39.446, Truncation lag parameter = 4, p-value
= 0.01
alternative hypothesis: stationaryBudeme teda uvažovať dva varianty:
Nasleduje neparametrická identifikácia ARMA procesu.
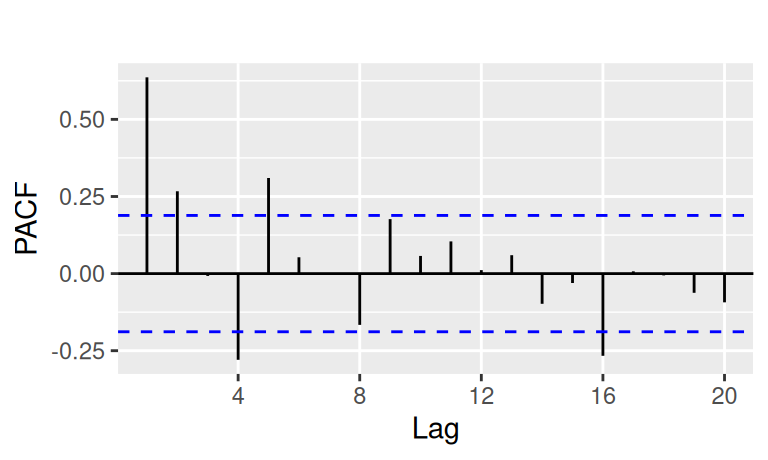
tdata$bcDtrDif4 |> forecast::Acf(plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")
tdata$bcDtrDif4 |> forecast::Pacf(plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")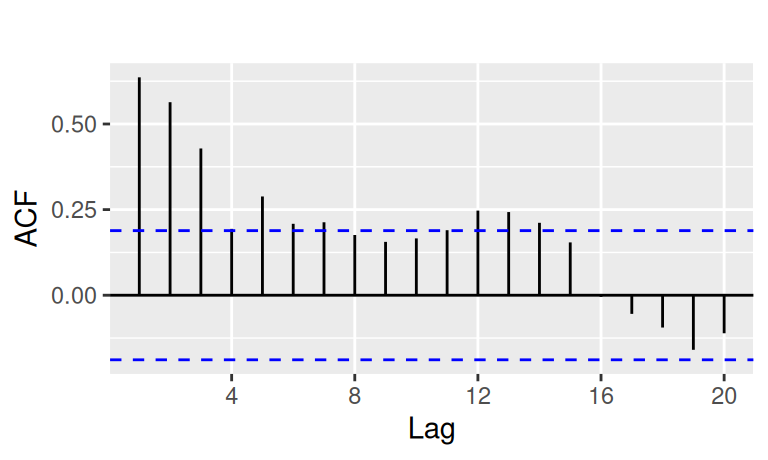
tdata$bcDtrDif4Dif1 |> forecast::Acf(plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")
tdata$bcDtrDif4Dif1 |> forecast::Pacf(plot = FALSE) |>
forecast::autoplot(show.legend = FALSE) + ggtitle("")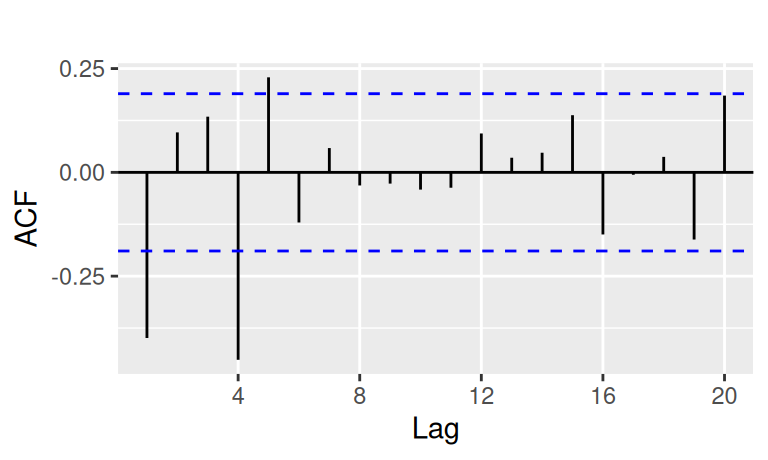
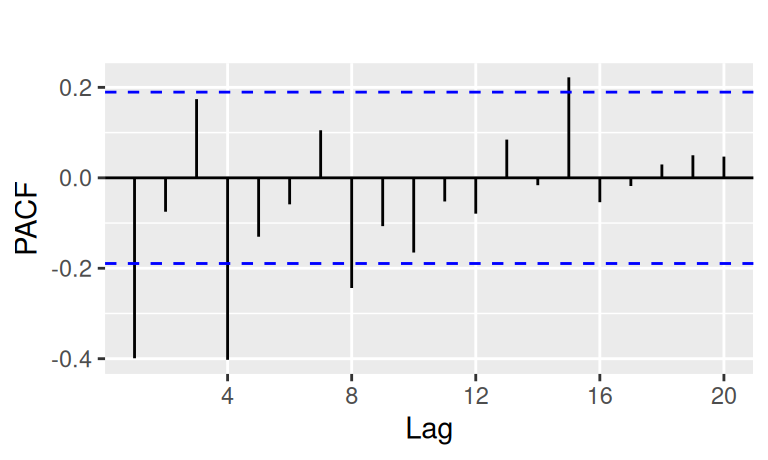
Aby sme zhrnuli predošlé informácie, model by mal obsahovať
# design matrix of linear trend without intercept
make_Xreg <- function(data) {
"~ - 1 + time " |>
as.formula() |>
model.matrix(data = data)
}
# estimation
fit <- list(
"ARIMA(2,0,0)(1,1,0)[4]drift" = forecast::Arima(
dat$train$observed, lambda = "auto",
order = c(2,0,0), seasonal = c(1,1,0),
include.drift = TRUE),
"ARIMA(1,1,0)(1,1,0)[4]ext" = forecast::Arima(
dat$train$observed, lambda = "auto",
order = c(1,1,0), seasonal = c(1,1,0),
include.drift = FALSE, xreg = make_Xreg(dat$train))
)
fit$`ARIMA(2,0,0)(0,1,1)[4]drift` <- dat$train$observed |>
forecast::auto.arima(lambda = "auto")
fit$`ARIMA(0,1,0)(0,1,0)[4]` <- forecast::Arima(
dat$train$observed, lambda = "auto",
order = c(0,1,0), seasonal = c(0,1,0),
include.drift = FALSE)
fit |> sapply(BIC) |> cbind(BIC = _) BIC
ARIMA(2,0,0)(1,1,0)[4]drift -247.5091
ARIMA(1,1,0)(1,1,0)[4]ext -244.3940
ARIMA(2,0,0)(0,1,1)[4]drift -255.5557
ARIMA(0,1,0)(0,1,0)[4] -215.7668Neprekvapivo, automaticky identifikovaný model (ARIMA(2,0,0)(0,1,1)[4] s driftom) má najlepšie BIC. Treba však poznamenať, že algoritmus nehľadal medzi kandidátmi s externe dodaným lineárnym trendom. Ak ho necháme hľadať, výsledný model ARIMA(1,0,1)(1,0,0)[4] s deterministickým lineárnym trendom bude mať pomerne výrazne vyššie BIC (-221.87), bez ohľadu na použitý test stacionarity. Môžeme si ho zo zvedavosti uložiť na neskôr – pre konštrukciu predpovedí a záverečné porovnanie presnosti.
fit$`ARIMA(1,0,1)(1,0,0)[4]ext` <- dat$train$observed |>
forecast::auto.arima(lambda = "auto", xreg = make_Xreg(dat$train))Posledným súťažiacim modelom nech je ARIMA(0,0,0)(0,1,0)[4] s jediným parametrom na odhadnutie: driftom. Taký model zrejme nebude môcť úspešne konkurovať v jedno-krokových predpovediach, no vo viac-krokových by sa mal vyrovnať obom uvažovaným modelom, ktoré majú \(d=0\) a \(D=1\). Je analógiou statického modelu lineárneho trendu a sezónnosti pomocou indikačných bázových funkcií z predošlej časti o dekompozícii.
fit$`ARIMA(0,0,0)(0,1,0)[4]drift` <- forecast::Arima(
dat$train$observed, lambda = "auto",
order = c(0,0,0), seasonal = c(0,1,0),
include.drift = TRUE)Ako základný (baseline) model – bez parametrov a slúžiaci na porovnanie – použijeme model ARIMA(0,0,0)(0,1,0)[4] (samozrejme bez driftu), ktorý sa nazýva aj sezónne naivný.
fit$`ARIMA(0,0,0)(0,1,0)[4]` <- forecast::Arima(
dat$train$observed, lambda = "auto",
order = c(0,1,0), seasonal = c(0,1,0),
include.drift = FALSE)Teraz vypočítame predpovede. Viackrokové pomocou funkcie forecast, jednokrokové pomocou funkcie Arima.
# container
fore <- list()
# multistep
fore$multi <- fit |>
lapply(function(obj) forecast::forecast(
object = obj,
h = nrow(dat$valid),
xreg = if("drift" %in% names(obj$coef)) NULL else make_Xreg(dat$valid)
))
# one-step
fore$one <- fit |>
lapply(function(obj) forecast::Arima(
y = dat$all$observed,
xreg = if("drift" %in% names(obj$coef)) NULL else make_Xreg(dat$all),
model = obj
)) |>
lapply(function(obj) {
mean <- obj |> fitted() |> window(start = start(dat$valid$observed))
se <- sqrt(obj$sigma2)
data.frame(mean = mean,
lower = mean - 2*sqrt(se),
upper = mean + 2*sqrt(se))
})Zobrazíme viackrokové predpovede
p <- list()
# overview
p$observed <- forecast::autoplot(dat$train$observed) +
forecast::autolayer(dat$valid$observed, color = "gray50") +
labs(y = "")
# detailed
p$observed_cut <- p$observed +
coord_cartesian(xlim = c(1990, 1999), ylim = c(400, 820))
p$observed_cut +
forecast::autolayer(fore$multi$`ARIMA(0,0,0)(0,1,0)[4]`,
series = "ARIMA(0,0,0)(0,1,0)[4]", PI = FALSE) +
forecast::autolayer(fore$multi$`ARIMA(0,0,0)(0,1,0)[4]drift`,
series = "ARIMA(0,0,0)(0,1,0)[4]drift", PI = FALSE) +
forecast::autolayer(fore$multi$`ARIMA(0,1,0)(0,1,0)[4]`,
series = "ARIMA(0,1,0)(0,1,0)[4]", PI = FALSE) +
forecast::autolayer(fore$multi$`ARIMA(1,0,1)(1,0,0)[4]ext`,
series = "ARIMA(1,0,1)(1,0,0)[4]ext", PI = FALSE) +
forecast::autolayer(fore$multi$`ARIMA(2,0,0)(0,1,1)[4]drift`,
series = "ARIMA(2,0,0)(0,1,1)[4]drift", PI = FALSE) +
forecast::autolayer(fore$multi$`ARIMA(1,1,0)(1,1,0)[4]ext`,
series = "ARIMA(1,1,0)(1,1,0)[4]ext", PI = FALSE) +
forecast::autolayer(fore$multi$`ARIMA(2,0,0)(1,1,0)[4]drift`,
series = "ARIMA(2,0,0)(1,1,0)[4]drift", PI = FALSE) +
guides(color = guide_legend(title = "model")) +
theme(legend.position = "inside", legend.position.inside = c(0.01,0.99),
legend.justification.inside = c(0,1)) +
labs(title = "Multi-step forecasts")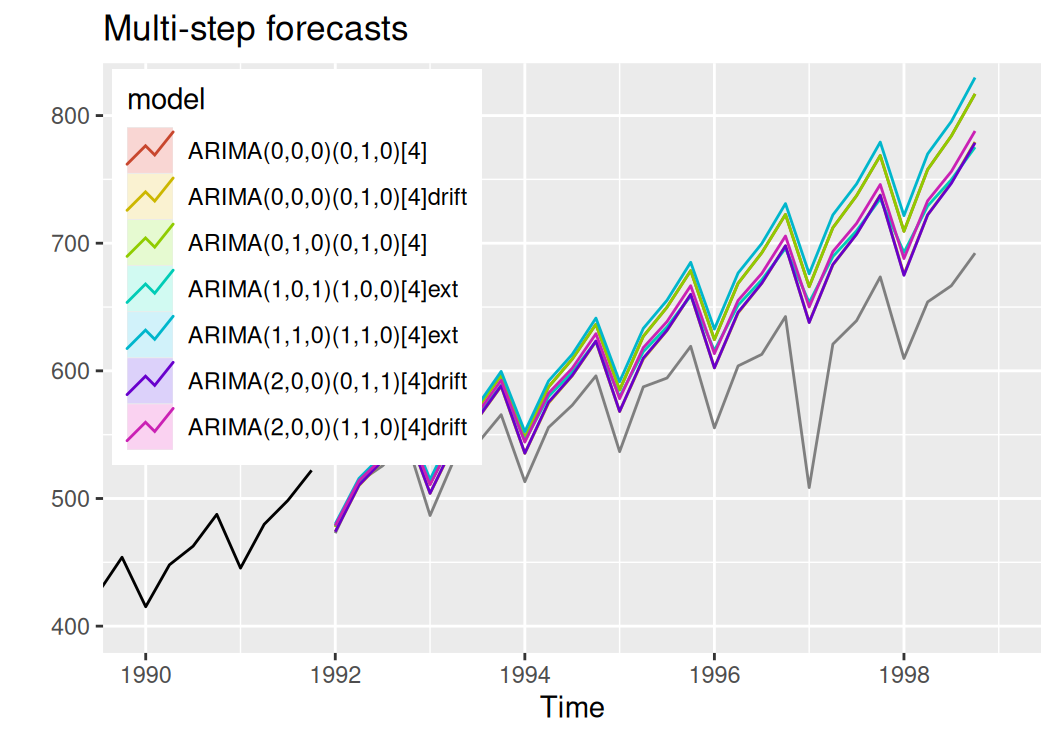
Všetky modely sa od skutočného radu vychyľujú rovnakým smerom, to znamená, že sme trend nevystihli úplne dobre.
fore$multi |>
lapply(forecast::accuracy, x = dat$valid$observed) |>
lapply(round, digits = 2) |>
lapply(tibble::as_tibble, rownames = "Set") |>
dplyr::bind_rows(.id = "model") |>
dplyr::arrange(Set, model) |>
as.data.frame() model Set ME RMSE MAE MPE MAPE
1 ARIMA(0,0,0)(0,1,0)[4] Test set -59.10 71.21 59.10 -9.86 9.86
2 ARIMA(0,0,0)(0,1,0)[4]drift Test set -40.30 50.21 40.51 -6.73 6.77
3 ARIMA(0,1,0)(0,1,0)[4] Test set -59.10 71.21 59.10 -9.86 9.86
4 ARIMA(1,0,1)(1,0,0)[4]ext Test set -44.86 54.71 44.86 -7.56 7.56
5 ARIMA(1,1,0)(1,1,0)[4]ext Test set -65.59 78.45 65.59 -10.94 10.94
6 ARIMA(2,0,0)(0,1,1)[4]drift Test set -40.41 50.15 40.59 -6.75 6.79
7 ARIMA(2,0,0)(1,1,0)[4]drift Test set -47.93 57.56 47.93 -8.04 8.04
8 ARIMA(0,0,0)(0,1,0)[4] Training set 0.03 4.41 2.93 0.03 1.54
9 ARIMA(0,0,0)(0,1,0)[4]drift Training set -0.26 5.41 4.18 -0.01 2.12
10 ARIMA(0,1,0)(0,1,0)[4] Training set 0.03 4.41 2.93 0.03 1.54
11 ARIMA(1,0,1)(1,0,0)[4]ext Training set 0.05 3.89 2.78 0.04 1.50
12 ARIMA(1,1,0)(1,1,0)[4]ext Training set 0.11 3.86 2.69 0.08 1.33
13 ARIMA(2,0,0)(0,1,1)[4]drift Training set 0.03 3.69 2.61 0.05 1.28
14 ARIMA(2,0,0)(1,1,0)[4]drift Training set 0.04 3.74 2.63 0.04 1.31
MASE ACF1 Theil's U
1 3.71 0.78 1.36
2 2.54 0.70 0.95
3 3.71 0.78 1.36
4 2.82 0.64 1.04
5 4.12 0.80 1.50
6 2.55 0.70 0.95
7 3.01 0.72 1.10
8 0.18 -0.38 NA
9 0.26 0.65 NA
10 0.18 -0.38 NA
11 0.17 -0.02 NA
12 0.17 -0.01 NA
13 0.16 -0.02 NA
14 0.17 0.01 NAZdá sa, že najlepší pomer “cena/výkon” v schopnosti predpovedať na viac krokov dopredu má sezónne integrovaný model s driftom a bez ARMA parametrov (ARIMA(0,0,0)(0,1,0)[4]drift).
p$observed +
forecast::autolayer(fore$multi$`ARIMA(0,0,0)(0,1,0)[4]drift`,
PI = TRUE, alpha = 0.5) +
labs(title = "Multi-step forecasts from ARIMA(0,0,0)(0,1,0)[4]drift model")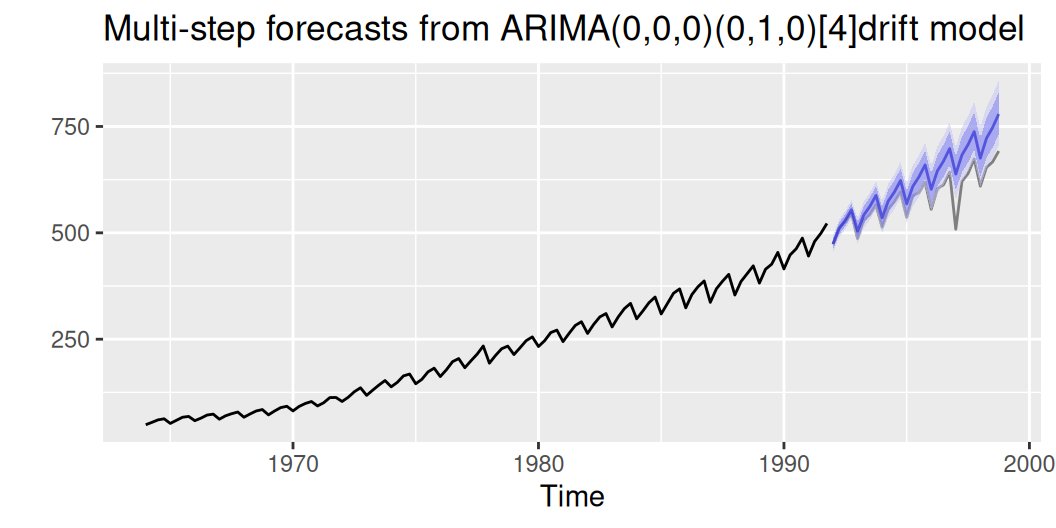
Validačná vzorka spočiatku leží vo vnútri a neskôr aspoň na okraji 95% predpovedného intervalu, takže s modelom môžeme byť relatívne spokojní.
Teraz sa pozrieme na jednokrokové predpovede.
fore$one |>
lapply(within, expr = {
time <- time(mean)
}) |>
dplyr::bind_rows(.id = "model") |>
ggplot() + aes(x = time) +
geom_line(aes(y = mean, color = model)) +
# geom_ribbon(aes(ymin = lower, ymax = upper, fill = model)) +
geom_line(aes(y = observed), data = dat$valid) +
facet_wrap(vars(model), ncol = 2)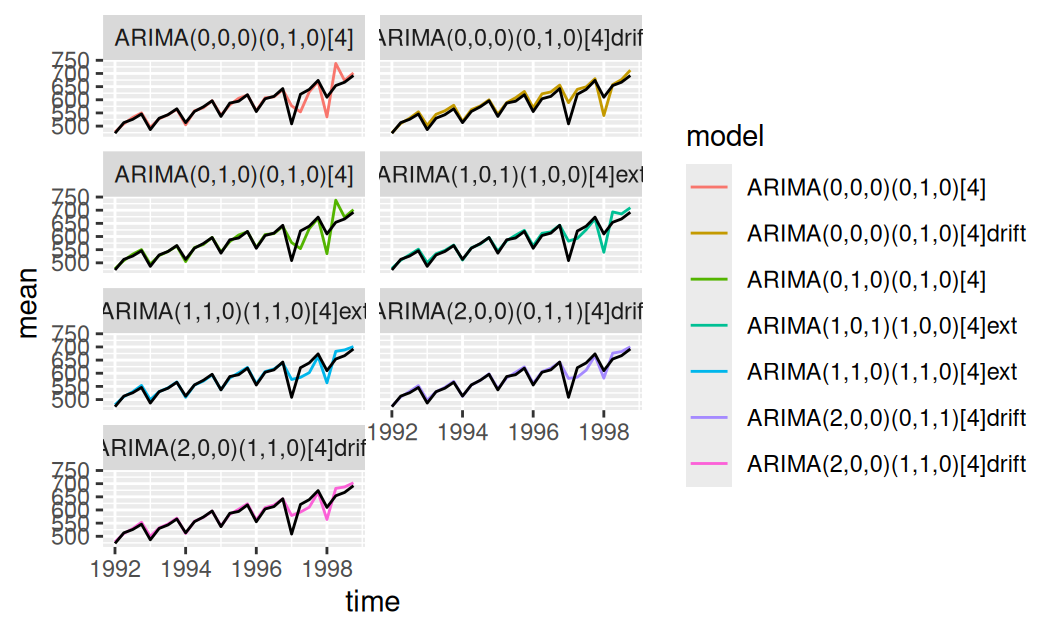
fore$one |>
lapply(function(y) forecast::accuracy(y$mean, x = dat$valid$observed)) |>
lapply(round, digits = 2) |>
lapply(tibble::as_tibble, rownames = "Set") |>
dplyr::bind_rows(.id = "model") |>
as.data.frame() model Set ME RMSE MAE MPE MAPE ACF1
1 ARIMA(2,0,0)(1,1,0)[4]drift Test set -2.91 19.49 11.55 -0.59 1.99 -0.12
2 ARIMA(1,1,0)(1,1,0)[4]ext Test set -1.16 20.21 11.93 -0.30 2.04 -0.08
3 ARIMA(2,0,0)(0,1,1)[4]drift Test set -2.66 18.25 10.46 -0.55 1.81 -0.16
4 ARIMA(0,1,0)(0,1,0)[4] Test set -1.02 28.39 14.55 -0.24 2.47 -0.43
5 ARIMA(1,0,1)(1,0,0)[4]ext Test set -3.88 22.57 13.04 -0.75 2.25 -0.21
6 ARIMA(0,0,0)(0,1,0)[4]drift Test set -9.49 22.99 14.68 -1.71 2.56 0.17
7 ARIMA(0,0,0)(0,1,0)[4] Test set -1.02 28.39 14.55 -0.24 2.47 -0.43
Theil's U
1 0.37
2 0.38
3 0.35
4 0.55
5 0.42
6 0.43
7 0.55Podľa viacerých metrík je na jednokrokové predpovede najvhodnejší model ARIMA(2,0,0)(0,1,1)[4] s driftom. Štatisticky (na hladine významnosti 5%) však jeho náskok nie je významný, a to nielen pred druhým najlepším modelom, ale ani pred najhorším, ako ukazuje nasledujúci test.
local({
ferrors1 <- dat$valid$observed - fore$one$`ARIMA(2,0,0)(0,1,1)[4]drift`$mean
ferrors2 <- dat$valid$observed - fore$one$`ARIMA(0,1,0)(0,1,0)[4]`$mean
forecast::dm.test(ferrors1, ferrors2, alternative = "less")
})
Diebold-Mariano Test
data: ferrors1ferrors2
DM = -1.544, Forecast horizon = 1, Loss function power = 2, p-value =
0.06711
alternative hypothesis: lessModel ARIMA(2,0,0)(0,1,1)[4] s driftom sa ukázal ako najlepší nielen na popisné účely ale aj na 1-krokové a viackrokové predpovede. Medzi modelmi sú však skôr menej výrazné rozdiely, takže sa na ich súčasné poradie pri predpovedaní do ďalšej budúcnosti nemôžeme veľmi spoľahnúť.
Azda z týchto výsledkov bude po porovnaní s predpovednou presnosťou dekompozičných modelov možné dedukovať, či je náš časový rad skôr stochasticky alebo naopak deterministicky nestacionárny.
Druhým typom dynamického modelu nestacionárnych časových radov je stavový model exponenciálneho vyrovnávania, ETS.
fit <- list()Identifikácia procesu je postavená viac na vizuálnom rozpoznaní charakteru časového radu než na nejakom ustálenom postupe. Súčasťou je aj detekcia nestacionarity v rozptyle.
dat <- dat |> # keep only time index and response variable
lapply(`[`, c("observed", "time")) # subset(dat, select = ...) drops ts class
list(train = dat$train$observed,
valid = dat$valid$observed) |>
with({
ggplot() + forecast::autolayer(train) + autolayer(valid) +
scale_color_manual(values = c(train = 1, valid = 2)) +
guides(color = guide_legend(title = "sample")) +
theme(legend.position = "inside",
legend.position.inside = c(0.99, 0.01),
legend.justification = c("right","bottom")) +
labs(x = "year", y = "observed")
})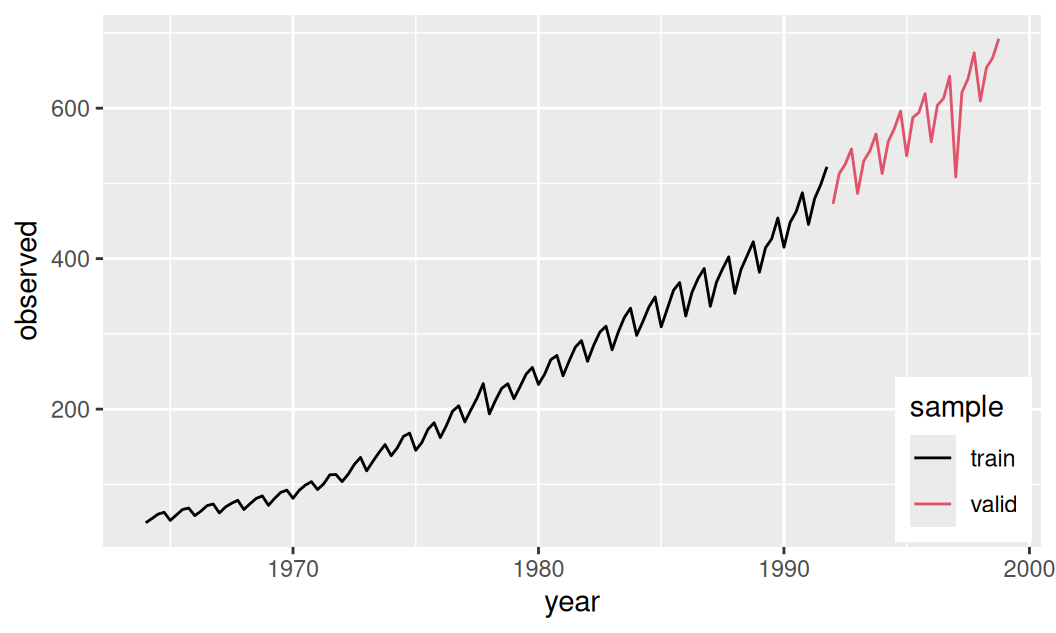
Rozptyl (trénovacej vzorky) rastie so strednou hodnotou, preto chybová zložka bude pravdepodobne multiplikatívna. Časový rad obsahuje výrazný deterministický trend a nezdá sa, že by mal byť tlmený, ale ani explozívny, takže vhodným typom bude obyčajný aditívny. Sezónna zložka má vzhľadom na dĺžku radu malú periódu a jej amplitúda rastie so strednou hodnotou, takže bude rozumné zvoliť multiplikatívny typ.
Ku zvolenému typu ETS modelu s odhadnutými parametramie (MAMest) postavíme zopár ďalších kandidátov na porovnanie:
- plne aditívny ETS model na dátach po Box-Coxovej transformácii (bcAAA), - ETS(M,A,M) s fixnými parametrami blízkymi nule (MAMsmo), takže iba počiatočné stavy sú odhadnuté
fit$MAMest <- dat$train$observed |> forecast::ets(model = "MAM")
fit$bcAAA <- dat$train$observed |> forecast::ets(model = "AAA", lambda = "auto")
fit$MAMsmo <- dat$train$observed |>
forecast::ets(model = "MAM", alpha = 0.01, beta = 0.01, gamma = 0.01)Kvantitatívne ukazovatele popisnej schopnosti modelov:
fit |>
lapply(forecast::accuracy) |>
lapply(round, 2) |>
lapply(as.data.frame) |>
dplyr::bind_rows(.id = "model") model ME RMSE MAE MPE MAPE MASE ACF1
Training set...1 MAMest 0.50 3.92 2.86 0.29 1.38 0.18 0.06
Training set...2 bcAAA 0.08 3.83 2.80 0.07 1.29 0.18 -0.06
Training set...3 MAMsmo 5.52 14.60 10.73 3.57 5.36 0.67 0.88Parametrická identifikácia na základe informačného kritéria vedie k najviac preferovanému kandidátovi z predošlej, neparametrickej identifikácie:
dat$train$observed |> forecast::ets(model = "ZZZ", ic = "bic")ETS(M,A,M)
Call:
forecast::ets(y = dat$train$observed, model = "ZZZ", ic = "bic")
Smoothing parameters:
alpha = 0.4432
beta = 0.1028
gamma = 0.2602
Initial states:
l = 53.9398
b = 1.2384
s = 1.0756 1.0573 0.9732 0.8938
sigma: 0.0191
AIC AICc BIC
819.6418 821.4065 844.1083 Vyhladenie trendu a sezónnej zložky je silné, to značí stabilitu procesu (počas trénovacieho obdobia).
Pozrime sa, ako sa modelom bude dariť v predpovedaní.
Podobne ako v predošlých triedach modelov i tu ich vhodnosť posúdime z hľadiska predpovedať dlhodobo a tiež krátkodobo.
Výpočet viac-krokových predpovedí opäť zabezpečuje generická funckia forecast s metódou pre modely ETS definovanou balíkom forecast.
# container
fore <- list()
# multistep
fore$multi <- fit |>
lapply(function(obj) forecast::forecast(
object = obj,
h = nrow(dat$valid))
)Zobrazenie viac-krokových predpovedí
p <- list()
# overview
p$observed <- forecast::autoplot(dat$train$observed) +
forecast::autolayer(dat$valid$observed, color = "gray50") +
labs(y = "")
# detailed
p$observed_cut <- p$observed +
coord_cartesian(xlim = c(1990, 1999), ylim = c(400, 820))
p$observed_cut +
forecast::autolayer(fore$multi$MAMest, series = "ETS(M,A,M)", PI = FALSE) +
forecast::autolayer(fore$multi$bcAAA, series = "ETS(A,A,A), BoxCox", PI = FALSE) +
forecast::autolayer(fore$multi$MAMsmo, series = "ETS(M,A,M), smooth", PI = FALSE) +
guides(color = guide_legend(title = "model")) +
theme(legend.position = "inside", legend.position.inside = c(0.01,0.99),
legend.justification.inside = c(0,1)) +
labs(title = "Multi-step forecasts")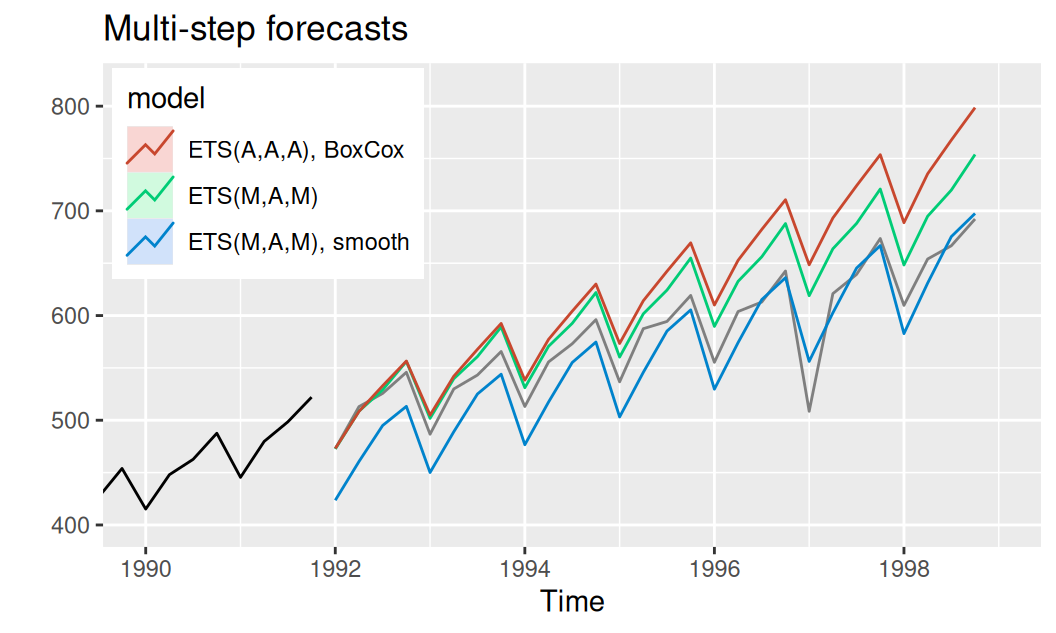
Presnosť viac-krokových predpovedí:
fore$multi |>
lapply(forecast::accuracy, x = dat$valid$observed) |>
lapply(round, digits = 2) |>
lapply(tibble::as_tibble, rownames = "Set") |>
dplyr::bind_rows(.id = "model") |>
dplyr::arrange(Set, model) |>
as.data.frame() model Set ME RMSE MAE MPE MAPE MASE ACF1 Theil's U
1 MAMest Test set -30.43 37.89 30.75 -5.12 5.18 1.93 0.58 0.72
2 MAMsmo Test set 20.04 28.87 25.05 3.65 4.57 1.57 0.37 0.59
3 bcAAA Test set -48.37 59.66 48.69 -8.05 8.11 3.06 0.74 1.13
4 MAMest Training set 0.50 3.92 2.86 0.29 1.38 0.18 0.06 NA
5 MAMsmo Training set 5.52 14.60 10.73 3.57 5.36 0.67 0.88 NA
6 bcAAA Training set 0.08 3.83 2.80 0.07 1.29 0.18 -0.06 NAJedno-krokové predpovede sa analogicky ku ARIMA vypočítajú s uvážením pozorovaných hodnôt namiesto predpovedaných, tu pomocou funkcie ets a argumentu model.
# one-step
fore$one <- fit |>
lapply(function(obj) forecast::ets(
y = dat$all$observed,
model = obj, # keep all parameters estimated on training set
use.initial.values = TRUE # including initial values
)) |>
lapply(function(obj) {
mean <- obj |> fitted() |> window(start = start(dat$valid$observed))
se <- sqrt(obj$sigma2)
data.frame(mean = mean,
lower = mean - 2*sqrt(se),
upper = mean + 2*sqrt(se))
})fore$one |>
lapply(within, expr = {
time <- time(mean)
}) |>
dplyr::bind_rows(.id = "model") |>
ggplot() + aes(x = time) +
geom_line(aes(y = mean, color = model)) +
# geom_ribbon(aes(ymin = lower, ymax = upper, fill = model)) +
geom_line(aes(y = observed), data = dat$valid) +
facet_wrap(vars(model), ncol = 2)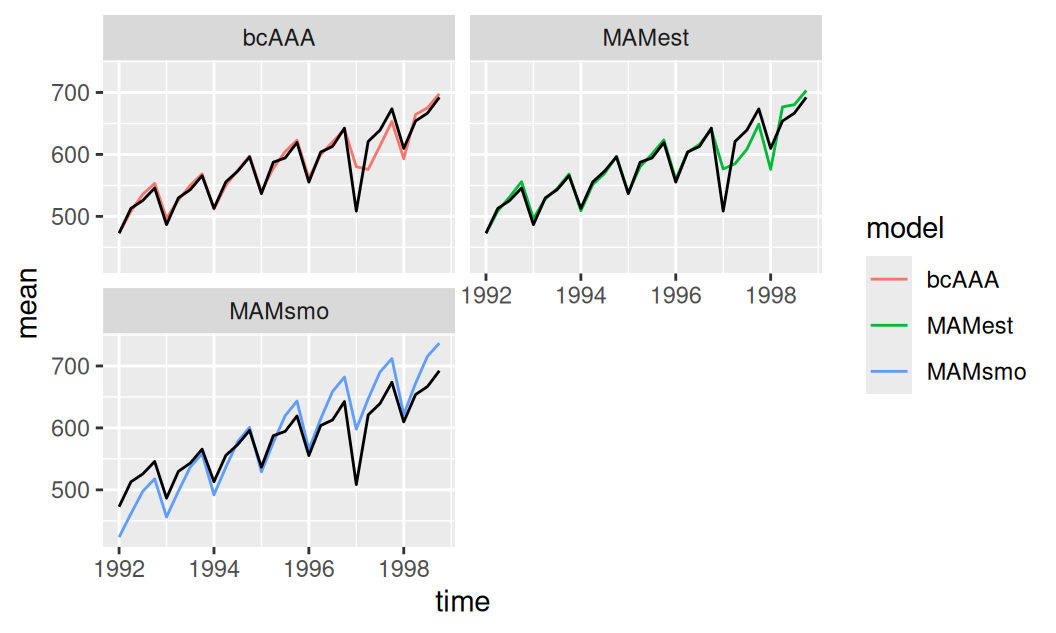
Zo zobrazených jedno-krokových predpovedí je vidieť že oba odhadnuté modely, ETS(M,A,M) aj ETS(A,A,A) s Box-Coxovou transformáciou si počínajú rovnako dobre. To potvrdzuje i tabuľka stredných predpovedných chýb:
fore$one |>
lapply(function(y) forecast::accuracy(y$mean, x = dat$valid$observed)) |>
lapply(round, digits = 2) |>
lapply(tibble::as_tibble, rownames = "Set") |>
dplyr::bind_rows(.id = "model") |>
as.data.frame() model Set ME RMSE MAE MPE MAPE ACF1 Theil's U
1 MAMest Test set -0.49 18.80 11.40 -0.18 1.95 -0.01 0.36
2 bcAAA Test set -1.07 18.36 10.95 -0.30 1.90 -0.16 0.36
3 MAMsmo Test set -7.21 34.04 28.05 -0.87 4.91 0.70 0.65Celkovo je teda ETS(M,A,M) najlepším z uvažovaných modelov.
fit$MAMest$states[,c("l","b","s1")] |>
forecast::autoplot(facets = TRUE)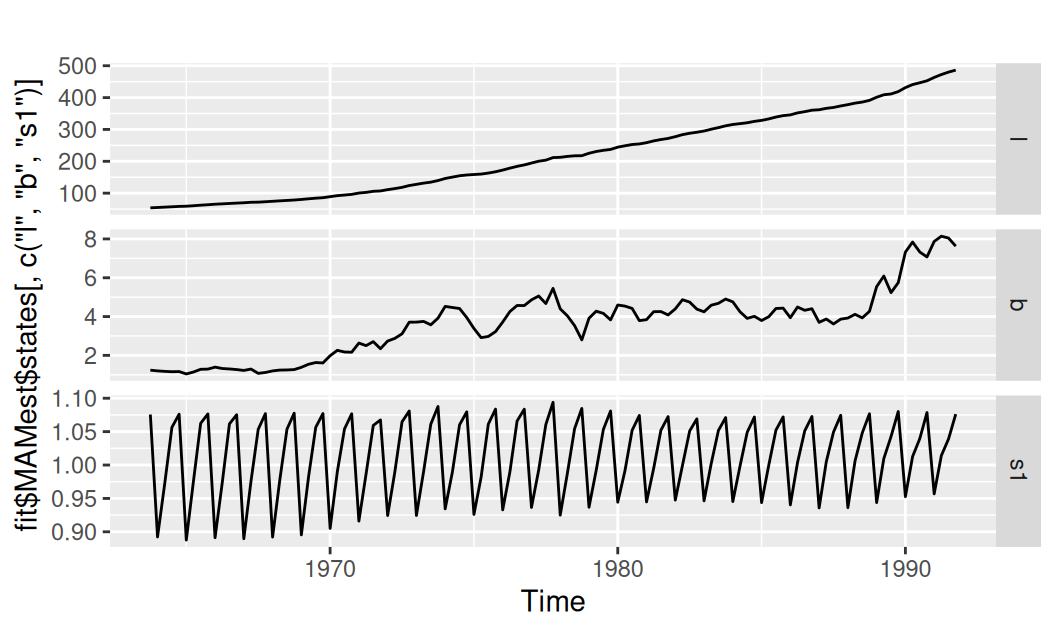
Ak sa pozrieme na vývoj jeho stavov, vidíme, že
# clear containers
dat <- fit <- fore <- accu <- p <- list()
# load data
dat$all <- "data/Nehody_mesacne.dat" |> # source file
read.table(header=F, skip = 1) |> # loading data, skip description line
setNames(c("year", "month", "day", "observed")) |> # add header
tidyr::unite("date", year, month, day, sep = "-") |>
dplyr::mutate( # create ts object, set beginning and sample frequency
observed = ts(observed, start = c(2010,1), end = c(2015,12), frequency = 12)
)
str(dat$all)'data.frame': 72 obs. of 2 variables:
$ date : chr "2010-1-1" "2010-2-1" "2010-3-1" "2010-4-1" ...
$ observed: Time-Series from 2010 to 2016: 1820 1594 1743 1637 1812 1753 1862 1844 1730 1980 ...Záznamy tvorí počet dopravných nehôd za mesiac na Slovensku v rokoch 2010-2015. V januári roku 2011 došlo k zmene metodiky evidencie nehodovosti. Posledný rok vyhradíme pre validáciu.
# make separate samples
dat$train <- data.frame(observed = window(dat$all$observed, end = c(2014, 12)))
dat$valid <- data.frame(observed = window(dat$all$observed, start = c(2015, 01)))
# make time index (in dat$all it should be the same as the existing time variable)
dat <- lapply(dat, function(x) within(x, {
time <- stats::time(observed)
}))
# display
list(train = dat$train$observed,
valid = dat$valid$observed) |>
with({
ggplot() + forecast::autolayer(train) + autolayer(valid) +
scale_color_manual(values = c(train = 1, valid = 2)) +
guides(color = guide_legend(title = "sample")) +
theme(legend.position = "inside", legend.position.inside = c(0.99, 0.99),
legend.justification = c("right","top")) +
labs(x = "year", y = "observed")
})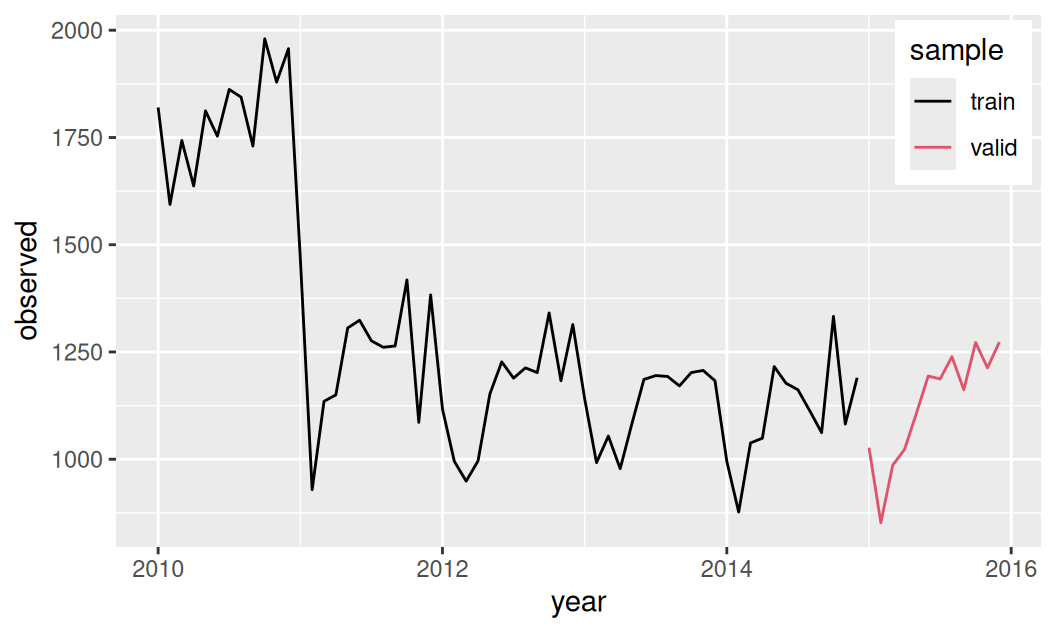
Časový rad má na prelome rokov výrazný štrukturálny zlom, inak vykazuje známky konštantného trendu a sezónnosti.
dat$train$observed |>
decompose() |>
forecast::autoplot()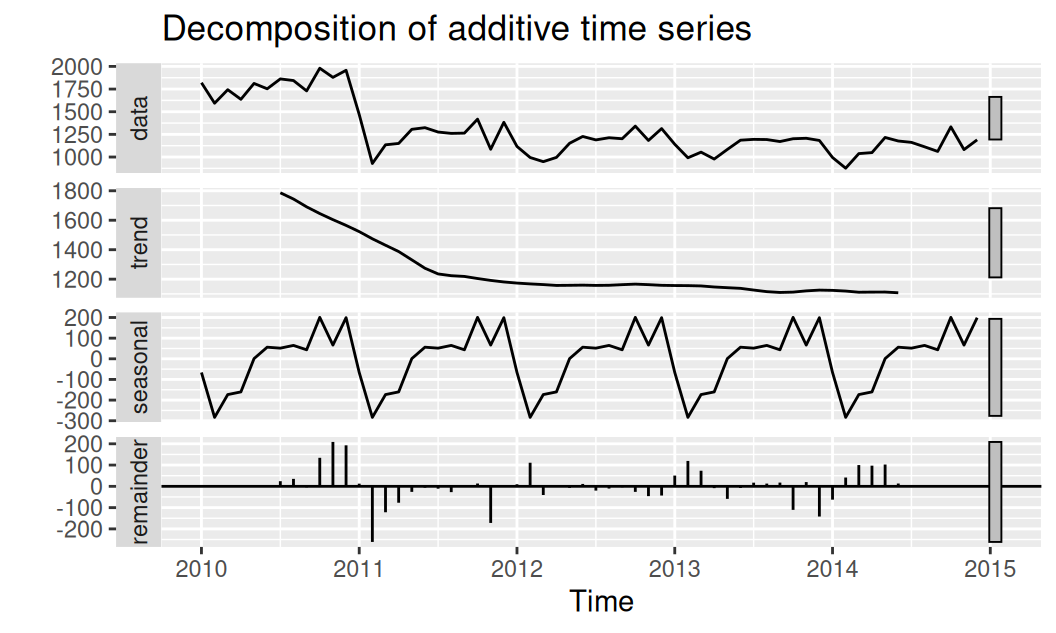
Prieskumná dekompozícia odhalila pomerne pravidelnú sezónnu zložku a homoskedastické rezíduá.
Pred tým, ako sa pustíme do modelovania systematických zložiek regresnou analýzou, definujme funkcie, ktoré konvertujú obyčajný vektor na dátový typ ts s atribútom tsp pre trénovacie a validačné obdobie. To nám v súčinnosti s funkciou stats::lm neskôr umožní vyhnúť sa použitiu funkcie forecast:tslm. Tá síce uľahčuje modelovanie jednoduchších typov trendu a sezónnosti, ale komplikuje ďalšie využitie modelu.
# convenience fuctions
ts_train <- function(x) `tsp<-`(ts(x), tsp(dat$train$observed))
ts_valid <- function(x) `tsp<-`(ts(x), tsp(dat$valid$observed))Priamou náhradou za pomocné členy trend a season v rovnici (formuli) funkcie tslm budú
time, ktorý zastupuje vektor časových indexov pozorovaného časového radu observed s jeho tsp atribútom,Pri spoločnom modelovaní trendu a sezónnosti je potom v rovnici výhodné používať jedinú premennú (tu v kapitole nazvanú time), ktorá predstavuje vektor explicitných hodnôt časových indexov s rovnakou informáciou kódovanou implicitne v jeho tsp atribúte. Vďaka tomu je potom aj predpovedanie technicky veľmi jednoduché.
Vyskúšame dva druhy po-častiach-lineárneho trendu:
fit$Tdc <- lm(observed ~ ifelse(time < 2011, 0, 1), data = dat$train)
fit$Tcls <- lm(observed ~
# time + # if starting with nonconstant trend
pmax(0, time - 2010.917) +
pmax(0, time - 2011.083),
data = dat$train)
dat$train$Tdc <- fit$Tdc |> fitted() |> ts_train()
dat$train$Tcls <- fit$Tcls |> fitted() |> ts_train()forecast::autoplot(dat$train$observed) +
forecast::autolayer(dat$train$Tdc) +
forecast::autolayer(dat$train$Tcls) +
scale_color_discrete(name = "Trend", labels = c("discontinuous constant", "constant-linear spline")) +
theme(legend.position = "inside",
legend.position.inside = c(0.98,0.98),
legend.justification = c("right","top")
) +
labs(y = NULL)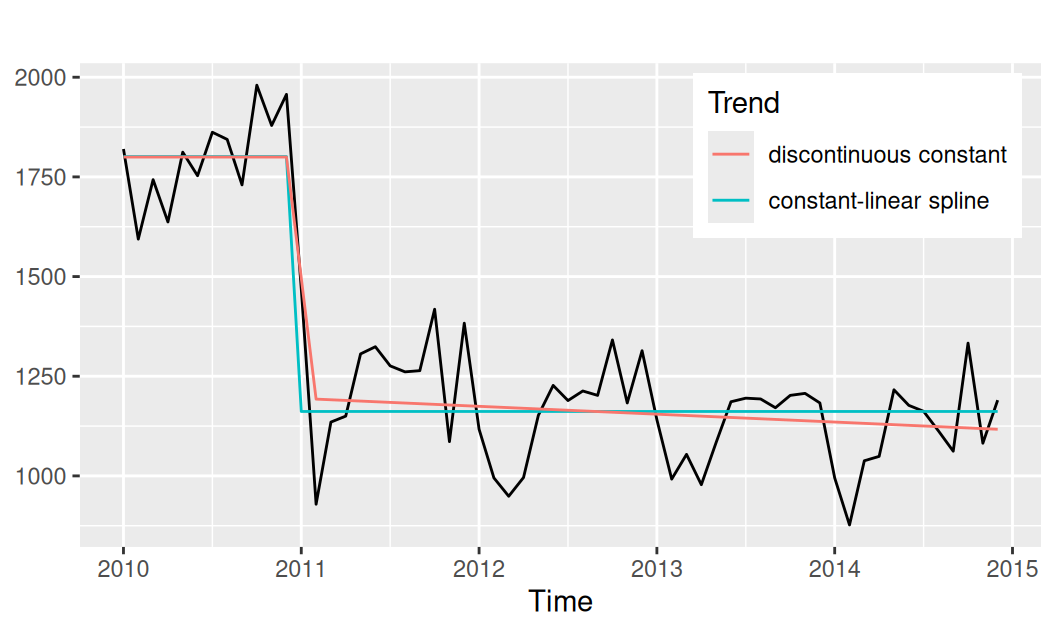
Zobrazenie časových radov pomocou funkcií forecast::autoplot/autolayer je veľmi pohodlné, ale oproti ‘tidy’ prístupu balíku ggplot2 aj pomerne obmedzujúce, napr. v prípade, že by sme chceli nespojitý trend na predošlom obrázku zobraziť bez spojnice dvoch jeho segmentov.
Skúsime regresný model s indikačnými premennými aj harmonickú regresiu. K harmonickej regresii predtým vytvoríme funkciu harmonic na konštrukciu matice plánu. Tá bude používať externý časový prediktor – na rozdiel od funkcie forecast::fourier (s ktorou by bolo potrebné konštruovať maticu plánu spoločného modelu oddelene, tak ako v prvej časti tejto kapitoly).
# function to construct design matrix for harmonic wave
# in: time - numeric vector, deterministic predictor
# period - numeric vector, periods in the same units as time
# out: matrix of size c(length(time)x(2*length(period))
harmonic <- function(time, period = 1) {
basis <- function(p) cbind(cos(2*pi*time/p), sin(2*pi*time/p))
lapply(period, basis) |>
do.call(what = cbind) |>
(`colnames<-`)(paste0(c("cos", "sin"), rep(signif(period,3), each=2)))
}
# example use
# harmonic(1:7, c(7, 7/2))
dat$train <- dat$train |>
dplyr::mutate(resTcls = observed - Tcls)
fit$Sind <- lm(resTcls ~ forecast::seasonaldummy(time), dat$train)
fit$Shar <- lm(resTcls ~ harmonic(time, c(1, 1/2)), dat$train)forecast::autoplot(dat$train$resTcls) +
forecast::autolayer(fit$Shar |> fitted() |> ts_train()) +
forecast::autolayer(fit$Sind |> fitted() |> ts_train()) +
scale_color_discrete(name = "Seasonality", labels = c("harmonic", "indicator")) +
theme(legend.position = "inside", legend.position.inside = c(0.98,0.02),
legend.justification = c("right","bottom")
)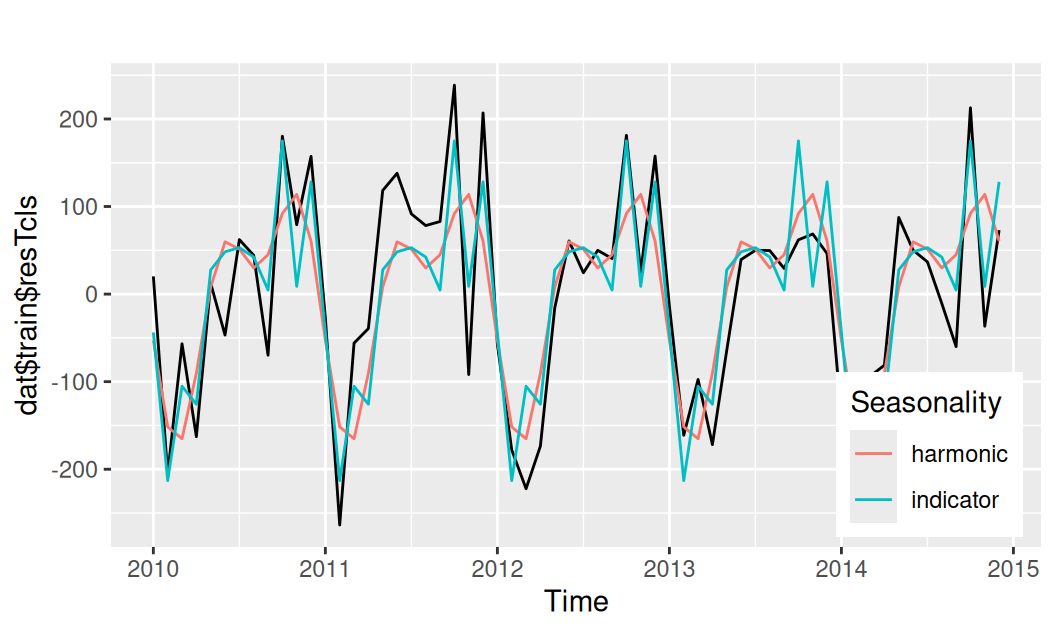
Model sezónnosti pomocou indikačných premenných lepšie pokrýva ostré vrcholy. To by sa u harmonického modelu dalo zariadiť tiež – zvýšením počtu harm.zložiek, napr. \(K=5\) – ale model by bol potom ešte horšie interpretovateľný, ponecháme si ho teda v jednoduchej podobe, možno bude lepšie predpovedať.
with(dat$train, {
TSresiduals <- resTcls - ts_train(fitted(fit$Sind))
forecast::autoplot(TSresiduals) |> print()
lomb::lsp(TSresiduals, type = "period", ofac = 20, main = "")
})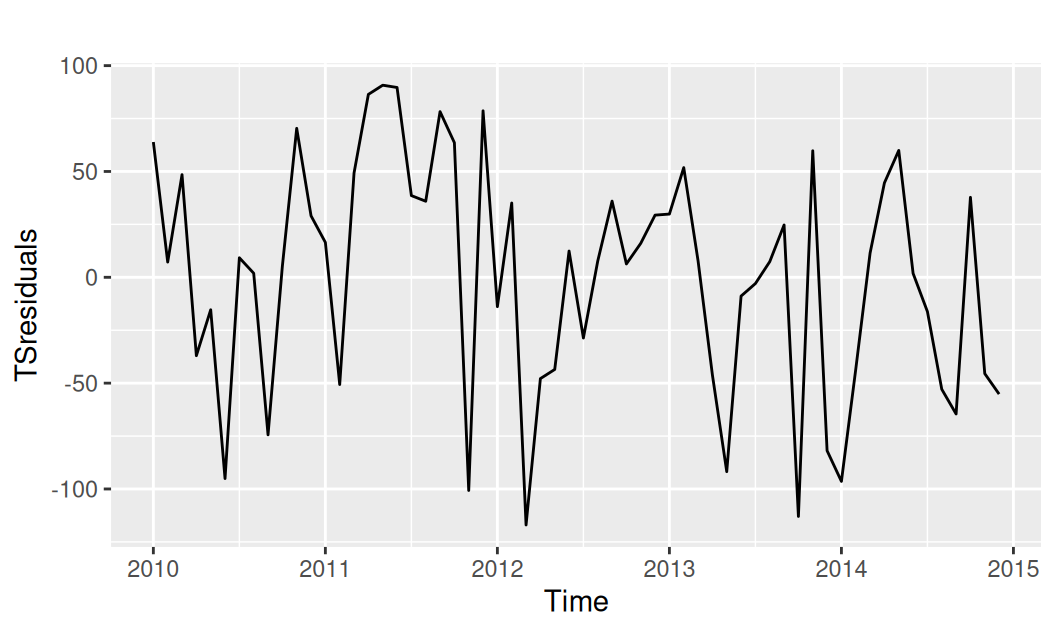
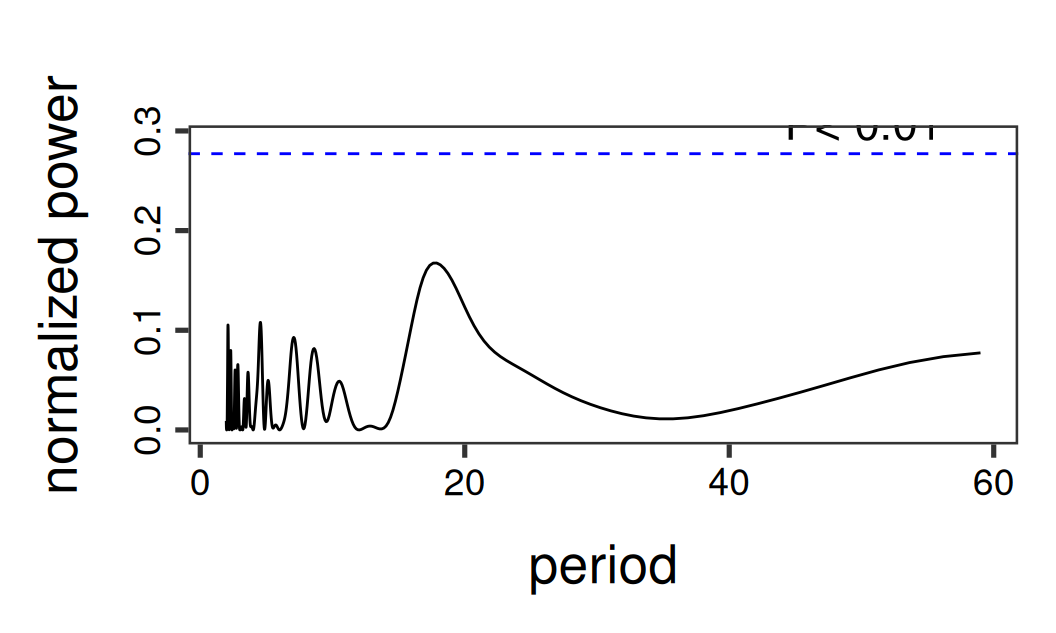
V rezíduách po modeli Sind už nezostáva žiaden periodický signál. Iba v periodograme rezíduí modelu Shar (ak by sme ho vykreslili) by bol detekovaný ultra-krátko-periodický signál (\(L=12/5=2.4\)) ako pozostatok sezónnej zložky.
V rámci cyklickej zložky teda nebudeme nič modelovať.
Momentálne máme ako kandidátov dva submodely trendu a dva submodely sezónnosti. Pre zjednodušenie nebudeme uvažovať všetky 4 kombinácie, ale vyberieme iba dve, najednoduchší a najzložitejší model:
fit$TdcShar <- lm(observed ~
ifelse(time < 2011, 0, 1) + # constant trend
harmonic(time, period = c(1, 1/2)), # seasonality
dat$train)
fit$TclsSind <- lm( observed ~
pmax(0, time - 2010.9) + pmax(0, time - 2011.1) + # Tcls
forecast::seasonaldummy(time), # Sind
dat$train)K nim pre ilustráciu ďalších typov nespojitých alebo lomených trendov doplníme
fit$TdlShar <- lm(
observed ~
time + # global slope
ifelse(time < 2011, 0, 1) + # intercept increment for second period
harmonic(time, period = c(1, 1/2)), # seasonality
dat$train)
fit$TlsShar <- lm(
observed ~ 1 +
time + # slope for first period
pmax(0, time - 2010.9) + pmax(0, time - 2011.1) + # slope increments
harmonic(time, period = c(1, 1/2)), # seasonality
dat$train)Všetky 4 modely majú podobnú popisnú schopnosť, najlepšiu má samozrejme najkomplexnejší model (so sezónnosťou danou 11 indikačnými premennými).
fit[c("TdcShar", "TclsSind", "TdlShar", "TlsShar")] |>
lapply(broom::glance) |>
dplyr::bind_rows(.id = "model") |>
dplyr::select(model, sigma, adj.r.squared, BIC)# A tibble: 4 × 4
model sigma adj.r.squared BIC
<chr> <dbl> <dbl> <dbl>
1 TdcShar 99.0 0.881 744.
2 TclsSind 61.2 0.955 710.
3 TdlShar 87.7 0.907 732.
4 TlsShar 82.7 0.917 728.Je dôležité si uvedomiť, že odhad lineárneho splajnu (s premenlivým sklonom jednotlivých segmentov) je spoľahlivejší v jednom modeli spolu s ostatnými zložkami, (tu budeme uvažovať iba so systematickými zložkami). Inak bude veľmi závisieť od dĺžky segmentov splajnu.
Pre extrakciu marginálneho efektu si vytvoríme jednoduchú funkciu …
# function to extract and sum fitted values corresponding to the specified terms of formula
# in: fit - output of lm()
# ind - integer vector, indices of model components (equation terms)
# const - logical value, should constant (intercept) be included?
# out: vector of fitted values
sum_terms_fitted <- function(fit, ind, const = TRUE) {
terms <- predict(fit, type = "terms", terms = ind)
rowSums(terms) + as.numeric(const)*attr(terms, "constant")
}… a použijeme na zobrazenie trendov z jednotlivých modelov.
forecast::autoplot(dat$train$observed) +
autolayer(fit$TdcShar |> sum_terms_fitted(1) |> ts_train(), series = "TdcShar") +
autolayer(fit$TclsSind |> sum_terms_fitted(1:2) |> ts_train(), series = "TclsSind") +
autolayer(fit$TdlShar |> sum_terms_fitted(1:2) |> ts_train(), series = "TdlShar") +
autolayer(fit$TlsShar |> sum_terms_fitted(1:3) |> ts_train(), series = "TlsShar") +
scale_color_discrete(
name = "Trend",
labels = c(TdcShar="discontinuous constant", # relabel
TclsSind = "constant-linear spline",
TdlShar = "discontinuous linear",
TlsShar = "linear spline"),
breaks = c("TdcShar", "TclsSind", "TdlShar", "TlsShar") # define order
) +
theme(legend.position = "inside",
legend.position.inside = c(0.98,0.98),
legend.justification = c("right","top")
)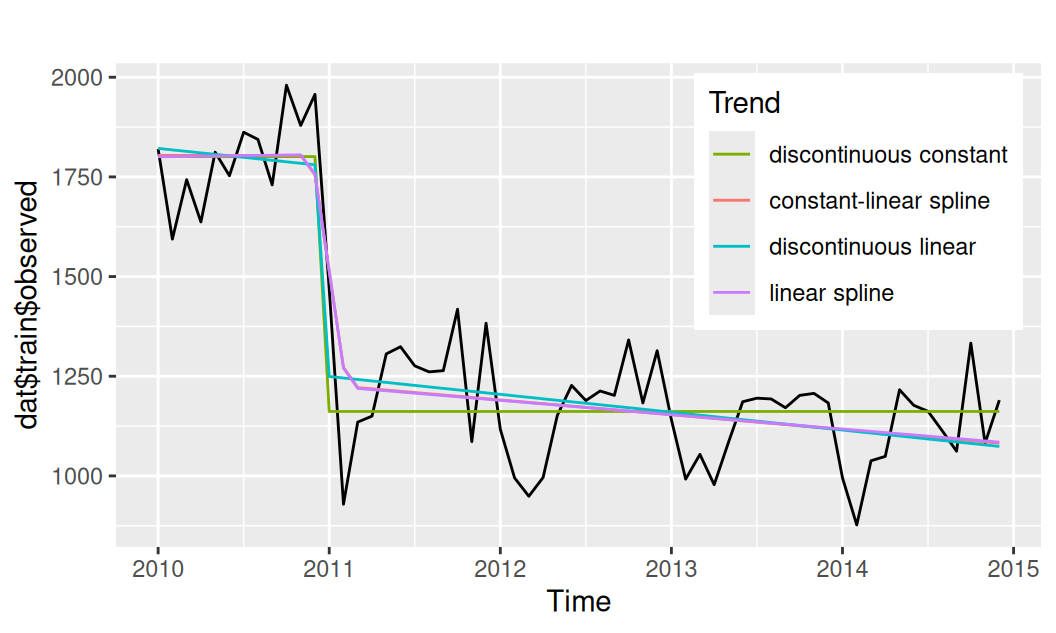
Všetky nie-konštantné trendy majú v druhej časti veľmi podobný sklon (druhý so štvrtým sa vizuálne prekrývajú), preto pre predpovedné účely ponecháme iba pôvodné dva modely. Zo všetkých si však pre interpretáciu ilustračne vypočítame parametre jednotlivých segmentov.
(TdcShar)
odhady parametrov:
fit$TdcShar$coefficients[1:2] (Intercept) ifelse(time < 2011, 0, 1)
1800.9167 -639.2708 rovnica modelu:
\[ y = \begin{cases} 1801 & t<2011\\ 1162 & t \geq 2011 \end{cases} \]
(TclsSind)
fit$TclsSind$coefficients[1:3] (Intercept) pmax(0, time - 2010.9) pmax(0, time - 2011.1)
1947.777 -2899.420 2862.295 \[ y = \begin{cases} 1757 & t<2010.9\\ 5.83216\times 10^{6} - 2899.4\ t & 2010.9 \leq t < 2011.1 \\ 7.5789\times 10^{4} -37.1\ t & 2011.1 \leq t \end{cases} \]
(TdlShar)
fit$TdlShar$coefficients[1:3] (Intercept) time ifelse(time < 2011, 0, 1)
91819.69478 -44.77525 -527.33270 \[ y = \begin{cases} 91820 - 44.8\ t & t<2011 \\ 9.1292\times 10^{4} - 44.8\ t & 2011 \leq t \end{cases} \]
(TlsShar)
fit$TlsShar$coefficients[1:4] (Intercept) time pmax(0, time - 2010.9)
-9820.965562 5.781832 -2924.970764
pmax(0, time - 2011.1)
2883.247379 \[ y = \begin{cases} -9821 + 5.8\ t & t<2010.9\\ 5.872061\times 10^{6} -2919.2\ t & 2010.9 \leq t < 2011.1 \\ 7.3658\times 10^{4} -35.9\ t & 2011.1 \leq t \end{cases} \]
Modely trendu sú si veľmi podobné, preto aj odhad sezónnej časti bude pre danú parametrickú triedu veľmi podobný. Pri interpretácii sa preto obmedzíme iba na prvé dva modely. Najprv ich zobrazíme graficky, potom analyticky.
data.frame(
month = month.abb[cycle(dat$train$observed)] |> forcats::as_factor(),
harmonic = fit$TdcShar |> sum_terms_fitted(2, FALSE),
indicator = fit$TclsSind |> sum_terms_fitted(3, FALSE)
) |>
head(12) |>
tidyr::pivot_longer(harmonic:indicator, names_to = "model", values_to = "value") |>
ggplot() + aes(x = month, y = value, color = model, group = model) +
geom_line() 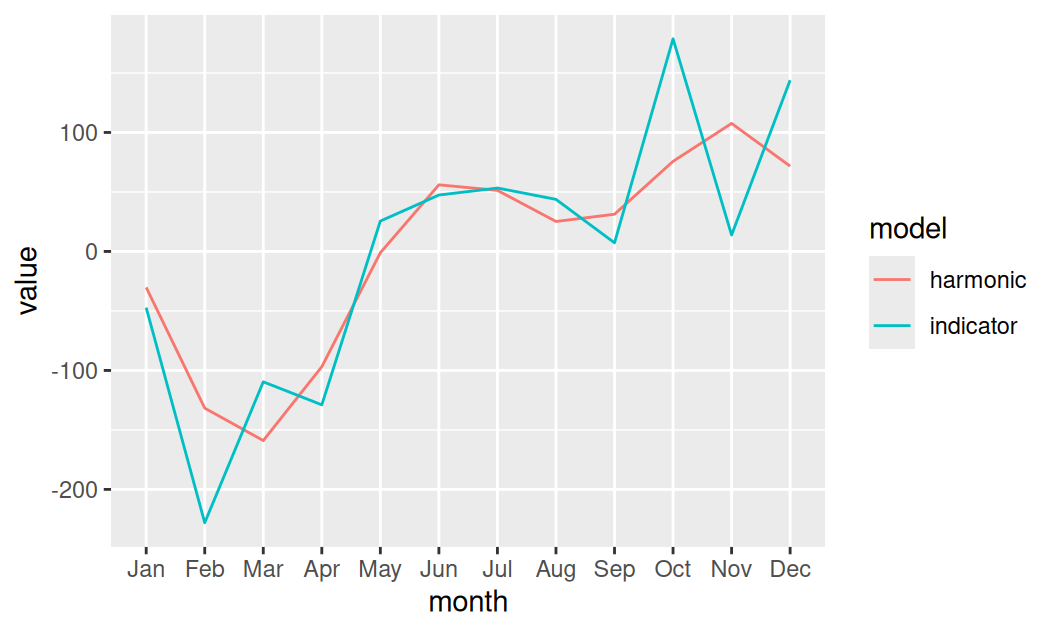
Komplexnejší model má minimum vo februári a maximum v októbri, jednoduchší o mesiac neskôr. Môže to súvisieť s kumuláciou sviatočných vodičov na cestách a s určitou zotrvačnosťou ľudského správania: v zime sú na cestách najmä tí skúsenejší, na jar sa postupne osmelujú aj ostatní vodiči. Na jeseň a začiatku zimy ešte zo zotrvačnosti jazdia ako za ideálnych podmienok (mnohí na letných plneumatikách) a iba pomaly si zvykajú na zhoršené podmienky (vlhkosť a mráz). Rozdiel medzi sezónami je až 400 nehôd.
Jednoduchší model:
fit$TdcShar |> residuals() |> forecast::checkresiduals()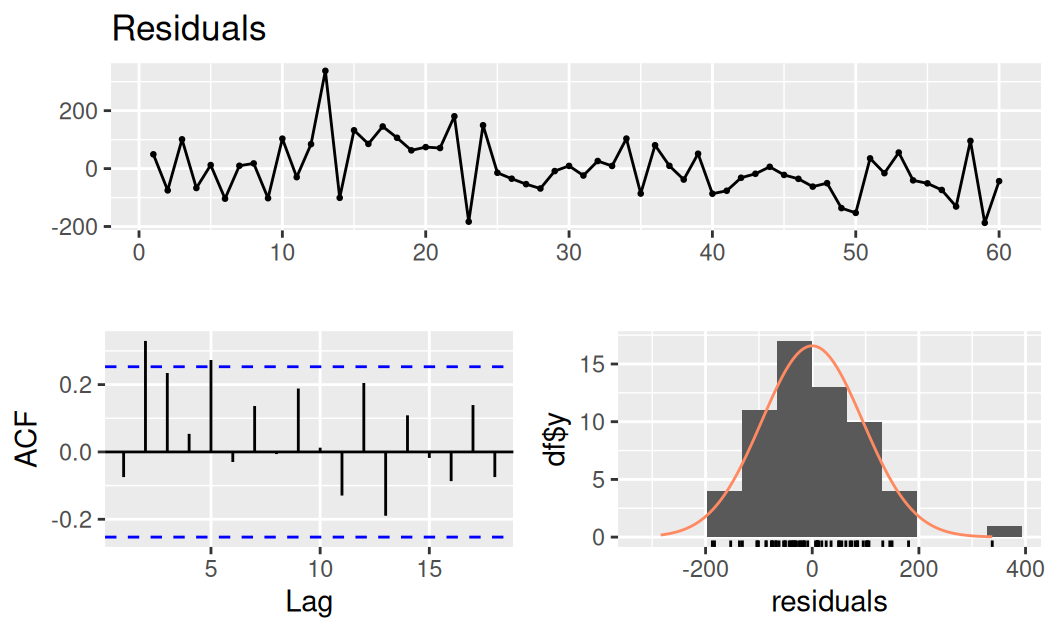
Ljung-Box test
data: Residuals
Q* = 20.113, df = 10, p-value = 0.0282
Model df: 0. Total lags used: 10Komplexnejší model:
fit$TclsSind |> residuals() |> forecast::checkresiduals() 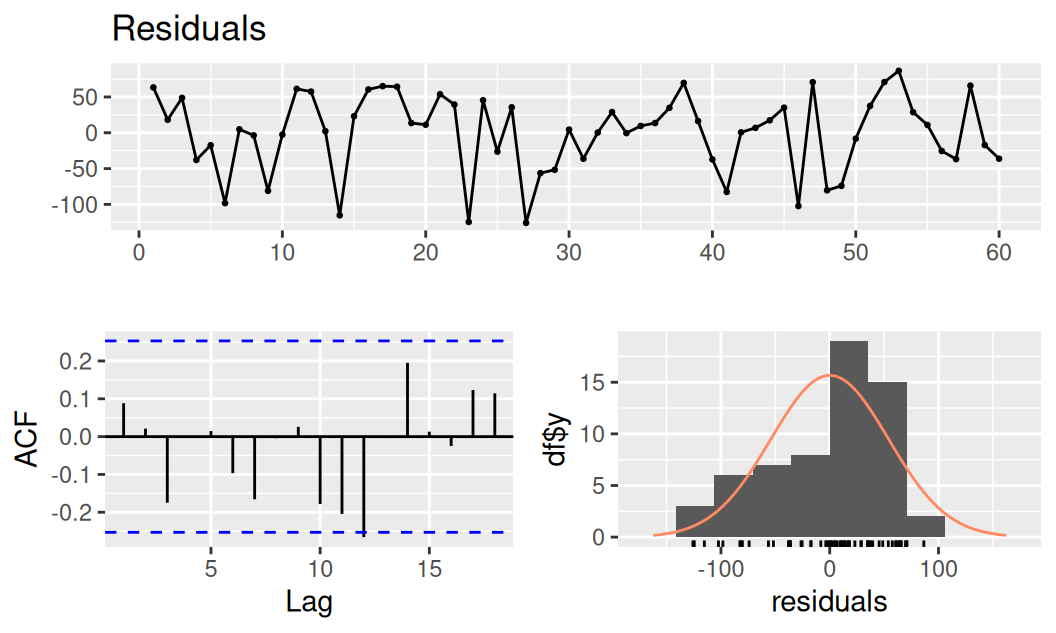
Ljung-Box test
data: Residuals
Q* = 7.5016, df = 10, p-value = 0.6774
Model df: 0. Total lags used: 10Zdá sa, že rezíduá jednoduchšieho modelu (na rozdiel od komplexnejšieho) sú ešte stále autokorelované, hoci iba veľmi mierne. Riešením je buď upraviť model systematických zložiek, alebo pridať model reziduálnej zložky (AR stupňa 1 by pravdepodobne stačil).
Identifikáciu a odhad ARMA modelu reziduálnej zložky (po modeli nespojitého trendu a harmonickej sezónnosti) necháme na parametrickú, Hyndman-Khandahar procedúru.
K tomu je potrebná aj regresná matica modelu systematických zložiek (vďaka lm je jej získanie z modelu jednoduché). Z matice vynecháme absolútny člen (intercept), inak by bolo nutné nastaviť argument allowmean na hodnotu FALSE.
fit$TdcSharRar3 <- forecast::auto.arima(
dat$train$observed,
xreg = model.matrix(fit$TdcShar)[,-1], # remove intercept or set allowmean = FALSE
stationary = TRUE,
ic = "aicc"
)
fit$TdcSharRar3Series: dat$train$observed
Regression with ARIMA(3,0,0) errors
Coefficients:
ar1 ar2 ar3 intercept ifelse(time < 2011, 0, 1)
-0.1479 0.3630 0.3334 1780.5623 -617.5893
s.e. 0.1228 0.1212 0.1287 42.1482 45.3812
harmonic(time, period = c(1, 1/2))cos1
-43.0052
s.e. 13.7087
harmonic(time, period = c(1, 1/2))sin1
-90.7811
s.e. 14.3724
harmonic(time, period = c(1, 1/2))cos0.5
8.8513
s.e. 9.6808
harmonic(time, period = c(1, 1/2))sin0.5
-69.9009
s.e. 9.7635
sigma^2 = 8147: log likelihood = -350.73
AIC=721.47 AICc=725.96 BIC=742.41Automatická procedúra našla ARMA(3,0) ako model s najmenším korigovaným AIC. Jeho rezíduá sú už nekorelované:
fit$TdcSharRar3 |>
forecast::checkresiduals()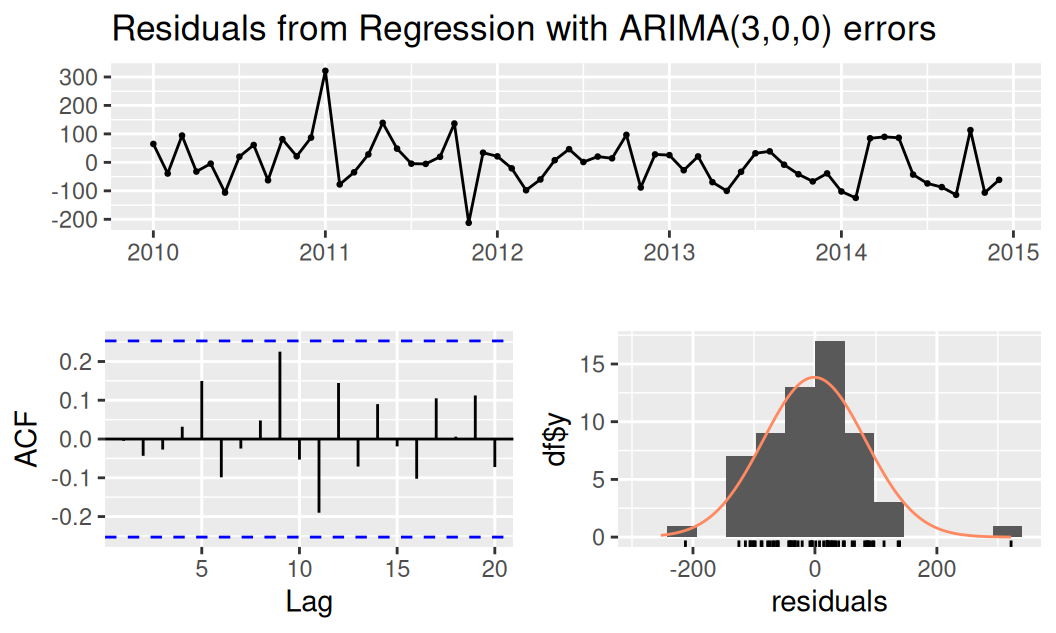
Ljung-Box test
data: Residuals from Regression with ARIMA(3,0,0) errors
Q* = 10.906, df = 9, p-value = 0.2822
Model df: 3. Total lags used: 12Vypočítame viac-krokové aj jedno-krokové predpovede. V prípade modelov bez reziduálnej zložky sú totožné.
fore <- list(
# multi-step forecast
multi = list(
# naive forecast is the same as random walk (without drift) forecast
naive = forecast::naive(dat$train$observed, h = nrow(dat$valid), lambda = 0),
# argument newdata supplies the time variable in static model
TclsSind = fit$TclsSind |>
forecast::forecast(newdata = dat$valid) |> # refused by forecast::autoplot
cbind.data.frame(dat$valid["time"]),
# xreg supply the regressors explicitly
TdcSharRar3 = fit$TdcSharRar3 |>
forecast::forecast(xreg = model.matrix(fit$TdcShar, data = dat$valid)[,-1])
),
# 1-step-ahead forecast, prediction interval is calculated in transformed scale
one = list(
# naive (last observed)
naive = data.frame(
mean = dat$all$observed |> tail(nrow(dat$valid)+1) |> head(-1) |> lag(k = -1)
) |>
with({
sdev <- dat$train$observed |> diff() |> sd() # random walk, no drift
data.frame(mean = mean,
lower = mean - 2*sdev,
upper = mean + 2*sdev)
}),
# model of systematic and random components
TdcSharRar3 = data.frame(
mean = forecast::Arima(dat$all$observed,
xreg = model.matrix(fit$TdcShar, data = dat$all)[,-1],
model = fit$TdcSharRar3
) |>
fitted() |>
window(start = start(dat$valid$observed))
) |>
dplyr::mutate(
lower = mean - 2*sqrt(fit$TdcSharRar3$sigma2),
upper = mean + 2*sqrt(fit$TdcSharRar3$sigma2)
)
)
)Zobrazíme validačnú vzorku spolu s bodovými a intervalovými viac-krokovými predpoveďami. Zvyčajne na to stačí použiť funkcie autoplot a autolayer, avšak výstup funkcie forecast v prípade modelu odhadnutého pomocou lm nie je plne kompatibilný, preto jednotlivé zložky grafu zobrazíme manuálne funkciami balíku ggplot, podobne ako pri jedno-krokových predpovediach.
p <- list()
p$observed_cut <-
forecast::autoplot(window(dat$train$observed, start = c(2014,1))) +
forecast::autolayer(dat$valid$observed, color = "gray50") +
labs(y = NULL)
# naive
p$observed_cut +
forecast::autolayer(fore$multi$naive, alpha = 0.5) +
labs(title = "Multi-step forecast", x = NULL,
subtitle = "Naive")
p$observed_cut +
geom_ribbon(dat = fore$one$naive,
mapping = aes(x = time(mean), ymin = lower, ymax = upper),
fill = 4, alpha = 0.5, inherit.aes = FALSE) +
forecast::autolayer(fore$one$naive$mean, color = 4, alpha = 0.5) +
labs(title = "1-step forecast", x = NULL,
subtitle = "")
# TclsSind
p$observed_cut +
geom_line(aes(x = time, y = `Point Forecast`),
data = fore$multi$TclsSind,
color = "blue") +
geom_ribbon(aes(x = time, ymin = `Lo 80`, ymax = `Hi 80`),
data = fore$multi$TclsSind,
fill = "blue", alpha = 0.2, inherit.aes = FALSE) +
geom_ribbon(aes(x = time, ymin = `Lo 95`, ymax = `Hi 95`),
data = fore$multi$TclsSind,
fill = "blue", alpha = 0.1, inherit.aes = FALSE) +
labs(x = NULL, subtitle = "const-linear trend, indic.var. seasonality")
p$observed_cut +
geom_line(aes(x = time, y = `Point Forecast`),
data = fore$multi$TclsSind,
color = 4) +
geom_ribbon(aes(x = time, ymin = `Lo 95`, ymax = `Hi 95`),
data = fore$multi$TclsSind,
fill = 4, alpha = 0.5, inherit.aes = FALSE) +
labs(x = NULL, subtitle = "")
# TdcSharRar3
p$observed_cut +
forecast::autolayer(fore$multi$TdcSharRar3, alpha = 0.5) +
labs(x = NULL, subtitle = "disc. constant trend, harmonic seasonality, AR(3)")
p$observed_cut +
geom_ribbon(dat = fore$one$TdcSharRar3,
mapping = aes(x = time(mean), ymin = lower, ymax = upper),
fill = 4, alpha = 0.5, inherit.aes = FALSE) +
forecast::autolayer(fore$one$TdcSharRar3$mean, color = 4, alpha = 0.5) +
labs(x = NULL, subtitle = "")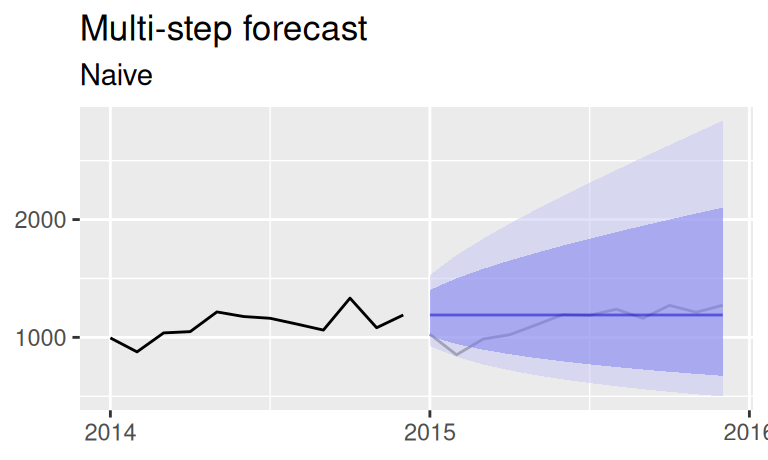
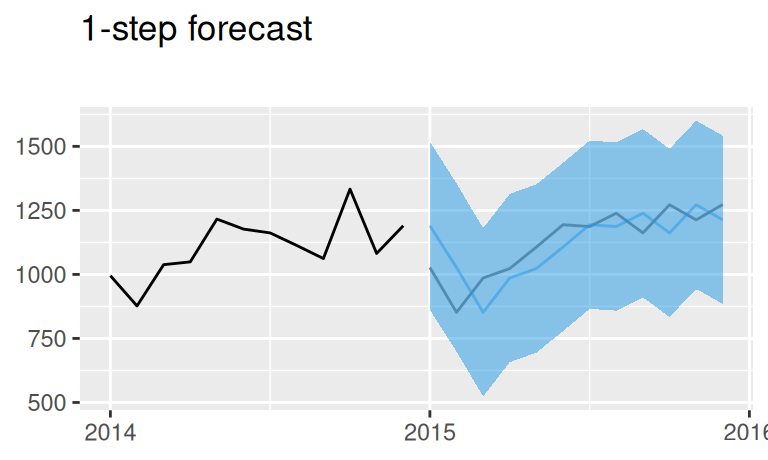
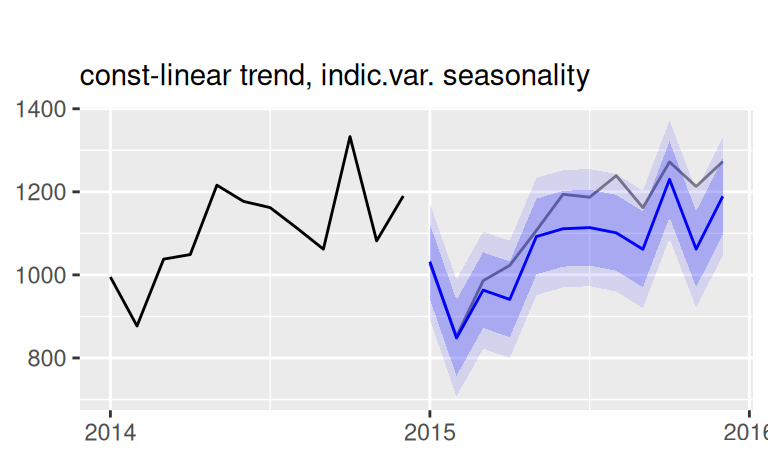
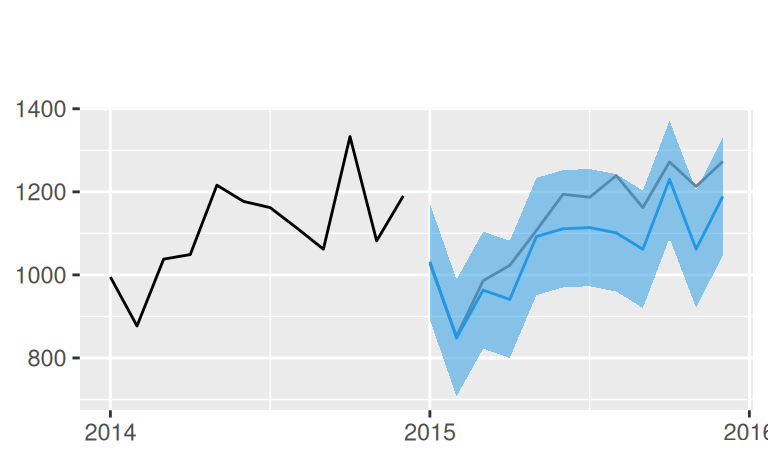
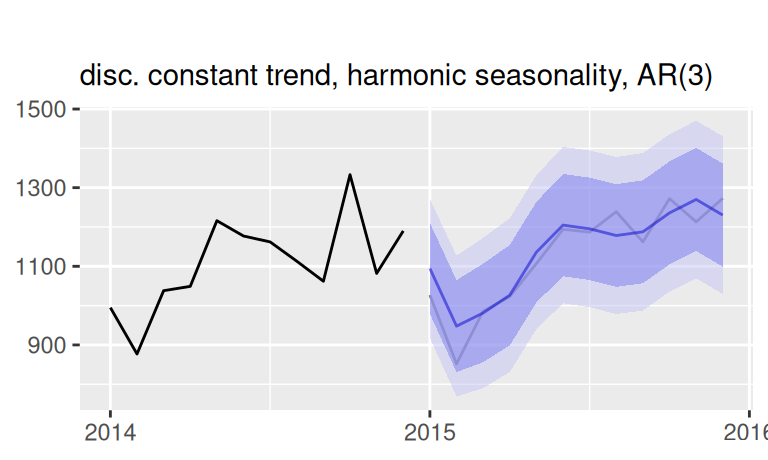
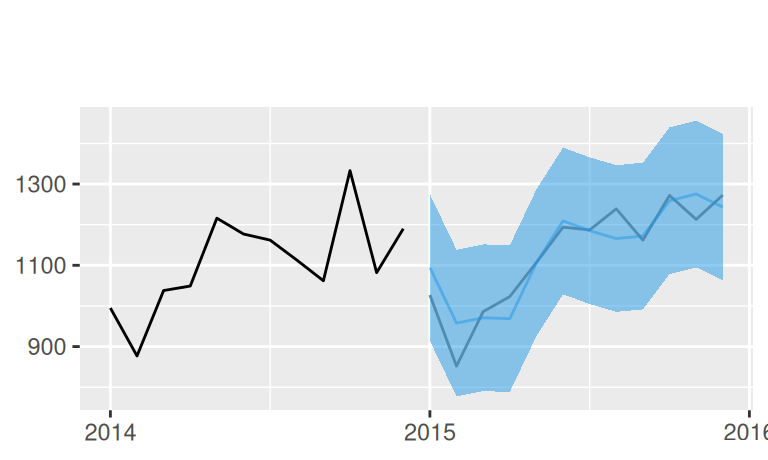
Predpovede zo všetkých našich modelov sú lepšie ako naivná predpoveď, model s lineárnym posledným segmentom trochu podhodnotil ďalší vývoj nehodovosti.