Kód
library(ggplot2)
library(tsibble)
library(ggtime) # needed for ggplot2 to plot tsibble correctlylibrary(ggplot2)
library(tsibble)
library(ggtime) # needed for ggplot2 to plot tsibble correctlyExponenciálne vyrovnávanie (EV) je jedna z najpopulárnejších adaptívnych metód. Vznikla ešte v 50-tych rokoch minulého storočia a používa sa na vyrovnanie (vyhladenie, angl. smoothing) aj predpovedanie hodnôt časového radu. Prakticky ide o vážený priemer všetkých minulých hodnôt s váhami, ktoré klesajú exponenciálnym tempom smerom do minulosti. Je to rýchla a spoľahlivá metóda, čo jej dáva veľkú výhodu pri nasadení v praxi, najmä z predpovedného hľadiska, na ktoré sa v nasledujúcich podkapitolách zameriame.
Kapitola je inšpirovaná najmä (Hyndman a Athanasopoulos 2018, kap. 7 a 8.10) a (Cipra 2008, kap. 9.3 a 9.4.3)
Najjednoduchšiu z metód EV (angl. simple exponential smoothing) formuloval Brown v roku 1956. Je vhodná pre časový rad bez trendu a sezónnej zložky. Uvažovaná je teda iba nenulová vyhladená úroveň \(a_t\) (angl. level). Odhad úrovne, ktorá sa v čase vyvíja, získame minimalizáciou súčtu \[ \sum_{i=0}^\infty(y_{t-i}-a_t)^2(1-\alpha)^i \ , \] kde \(\alpha\in[0,1]\) je vopred daný parameter ovplyvňujúci stupeň vyhladenia. Zderivovaním výrazu podľa \(a_t\) a zarovnaním s nulou získame odhad \(a_t\), ktorý predstavuje vyrovnanú hodnotu \(y_t\), konkrétne \[ \begin{split} \hat{y}_t &= a_t \\ \hat{y}_t &= \alpha\sum_{i=0}^\infty (1-\alpha)^i y_{t-i} \end{split} \] čo je zjavne vážený priemer s exponenciálne klesajúcimi váhami \(\alpha(1-\alpha)^i\). V praxi je však takýto vzťah nepoužiteľný a prevádza sa na rekurentný vzťah \[ \hat{y}_t=\alpha y_t + (1-\alpha) \hat{y}_{t-1}\ . \] Z neho je vidieť, že menšie hodnoty \(\alpha\) vedú k väčšiemu vyhladeniu.
Z predpovedného hľadiska je jednokroková predpoveď váženým priemerom posledného pozorovania a predošlej predpovede \[ \hat{y}_{t+1|t}=\alpha y_t+(1-\alpha)\hat{y}_{t|t-1} \tag{6.1}\] a viackroková predpoveď je konštantná, jednoducho \[ \hat{y}_{t+h|t} = \hat{y}_{t+1|t} \ . \] Obr. 6.1 ilustruje stupeň vyhladenia a predpovede pre niektoré hodnoty parametra \(\alpha\). Ako špeciálny prípad dostaneme
# load oil production data in Saudi Arabia
oildata <- window(fpp2::oil, start=1996, end=2013) |>
tsibble::as_tsibble()
# fit SES models
fit <- oildata |>
fabletools::model(
ses1 = fable::ETS(value ~ error(method = "A") + trend(method = "N", alpha = 0.0005)),
ses2 = fable::ETS(value ~ error(method = "A") + trend(method = "N", alpha = 0.6)),
ses3 = fable::ETS(value ~ error(method = "A") + trend(method = "N"))
)
# get alpha parameters
tmp <- fit |> fabletools::tidy() |> dplyr::filter(term == "alpha") |>
dplyr::pull(estimate) |> round(2)
# show
oildata |>
ggplot() + aes(x = index) +
geom_line(aes(y = value)) + geom_point(aes(y = value)) +
(fit |> fabletools::augment() |> ggtime::autolayer(.fitted)) +
(fit |> fabletools::forecast(h = 3) |> ggtime::autolayer(level = NULL)) +
scale_color_discrete(labels = tmp, name = "alpha") +
theme(legend.position = "inside",
legend.position.inside = c(0.01, 0.99),
legend.justification.inside = c(0,1)) +
labs(y = "oil production (millions of tons",
title = "Simple exponential smoothing")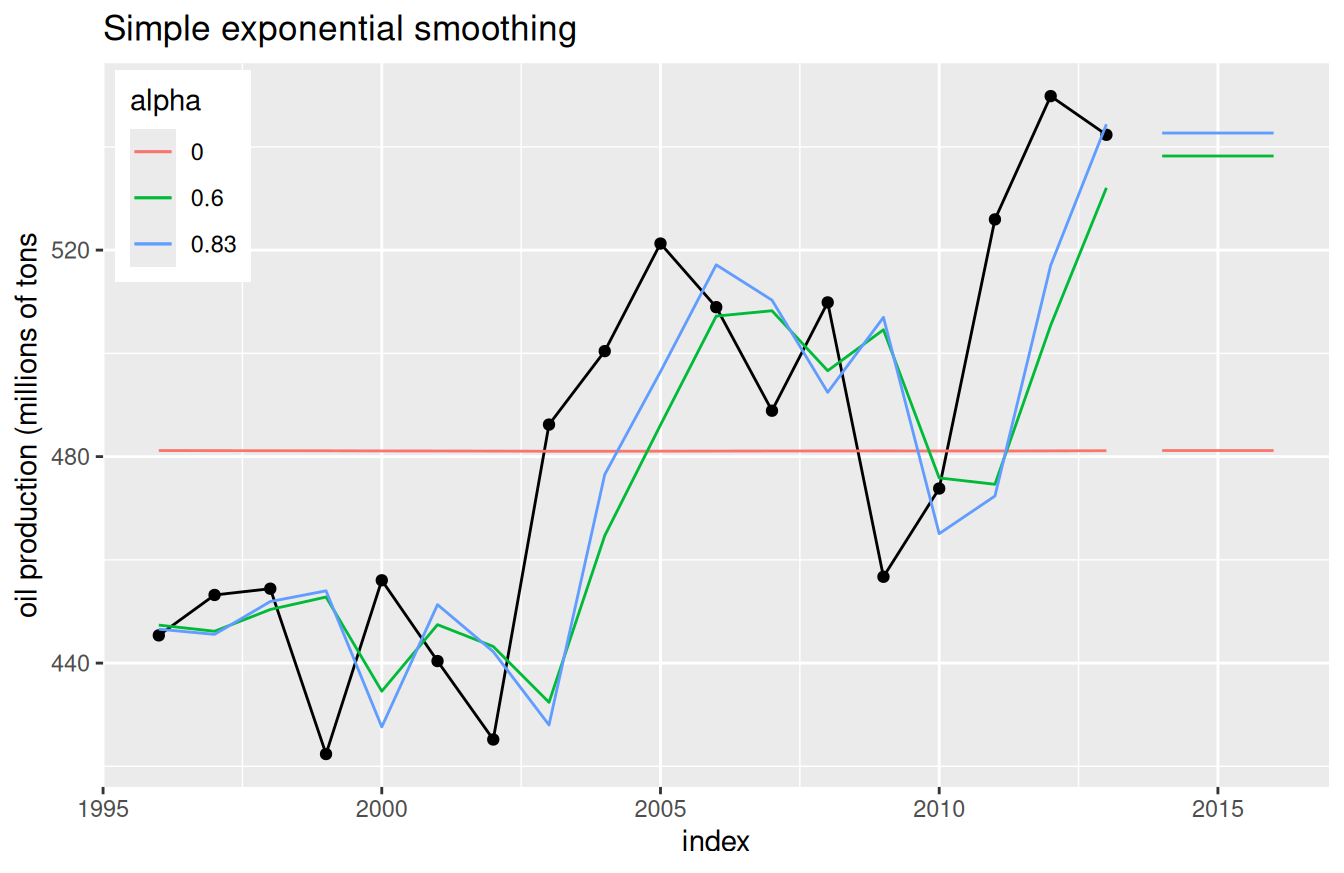
Alternatívne sa dá vzťah (6.1) pre \(h\)-krokovú predpoveď rozložiť do rovníc \[ \begin{aligned} \hat y_{t+h|t} & = a_t & \text{(predpovedanie)}\\ a_t & = \alpha y_t + (1-\alpha) a_{t-1} & \text{(vyrovnanie)} \end{aligned} \] kde, znovu, \(a_t\) predstavuje vyhladenú úroveň časového radu. Takýto komponentný tvar rovnice exponenciálneho vyhladzovania bude užitočný neskôr pre rozšírenie o systematické zložky. Úroveň môžme prepísať aj do “chybového” (angl. error correction) tvaru \[ a_t=a_{t-1}+\alpha(y_t-a_{t-1})=a_{t-1}+\alpha e_t \ , \] kde \(e_t=y_t-a_{t-1}=y_t-\hat{y}_{t|t-1}\), teda pre opravu predošlého odhadu použijeme vhodne redukovanú chybu predpovede \(e_t\).
Na rozdiel od regresie, kde na odhad metódou najmenších štvorcov možno použiť nástroje lineárnej algebry, parameter \(\alpha\) sa odhaduje nelineárnou minimalizáciou štvorcov rezíduí.
V roku 1957 Holt navrhol zovšeobecnenie jednoduchého EV tak, aby umožňovalo okrem vyrovnania úrovne aj vyrovnanie smernice trendu \[ \begin{aligned} \hat y_{t+h|t} & = a_t + h b_t & \text{(predpovedanie)}\\ a_t & = \alpha y_t + (1-\alpha) (a_{t-1}+b_{t-1}) & \text{(vyrovnanie úrovne)}\\ b_t & = \beta^* (a_t-a_{t-1}) + (1-\beta^*) b_{t-1} & \text{(vyrovnanie trendu)} \end{aligned} \] (nazývané aj dvojité EV), kde opäť \(a_t\) značí odhad úrovne časového radu v čase \(t\) s vyrovnávacím parametrom \(\alpha\), ďalej \(b_t\) je odhad (smernice) trendu a \(\beta^*\) jeho asociovaný vyrovnávací parameter \(\beta^*\in[0,1]\). Posledná rovnica ukazuje, že aktuálny odhad trendu je váženým priemerom aktuálneho rozdielu úrovní a predošlého odhadu trendu \(b_{t-1}\). Viackroková predpoveď už nie je konštantná, ale sleduje vývoj trendu, je lineárnou funkciou horizontu \(h\).
V praxi sa často ukazuje (zvlášť pre dlhodobé predpovede), že trend je treba tlmiť (angl. damped trend). Metóda sa stala veľmi obľúbenou najmä v automatizácii predpovedí a používa tlmiaci parameter \(\phi\in[0,1]\), takže \[ \begin{split} \hat y_{t+h|t} & = a_t + (\phi+\phi^2+\ldots + \phi^h) b_t \\ a_t & = \alpha y_t + (1-\alpha) (a_{t-1}+\phi b_{t-1}) \\ b_t & = \beta^* (a_t-a_{t-1}) + (1-\beta^*) \phi b_{t-1} \end{split} \] pričom \(\phi=1\) vedie k Holtovej metóde. Pre menšie hodnoty \(\phi\) to znamená, že krátkodobé predpovede nasledujú lineárny trend, zatiaľčo dlhodobé predpovede sú konštatné. Prakticky sa väčšinou volí \(0.8<\phi<0.98\).
Ak namiesto rozdielu v úrovni časového radu definujeme trend \(b_t\) ako podiel (index rastu, growth rate), dostávame multiplikatívnu modifikáciu Holtovej metódy \[ \begin{split} \hat y_{t+h|t} & = a_t b_t^h \\ a_t & = \alpha y_t + (1-\alpha) a_{t-1}b_{t-1} \\ b_t & = \beta^* \left(\frac{a_t}{a_{t-1}}\right) + (1-\beta^*) b_{t-1} \end{split} \] kde trend už nie je lineárny ale exponenciálny. Všetky tri typy trendov ilustruje Obr. 6.2.
# load air passengers data in Australia
airdata <- window(fpp2::ausair, start=1990, end=2016) |>
tsibble::as_tsibble()
# fit Holt models
fit <- airdata |>
fabletools::model(
holt1 = fable::ETS(value ~ trend(method = "A", alpha = 0.8, beta = 0.2)),
holt2 = fable::ETS(value ~ trend(method = "Ad", alpha = 0.8, beta = 0.2, phi = 0.9)),
holt3 = fable::ETS(value ~ trend(method = "M", alpha = 0.8, beta = 0.2))
)
# show
set.seed(12) # multiplicative trend will come from simulation
airdata |>
ggplot() + aes(x = index) +
geom_line(aes(y = value)) + geom_point(aes(y = value)) +
(fit |> fabletools::augment() |> autolayer(.fitted)) +
(fit |>
fabletools::forecast(h = 10, times = 100) |> # `times` for multiplicative trend
autolayer(level = NULL)
) +
scale_color_discrete(labels = c("linear", "damped", "exponential"), name = "Trend") +
theme(legend.position = "inside",
legend.position.inside = c(0.01, 0.99),
legend.justification.inside = c(0,1)) +
labs(y = "number of passengers (millions)",
title = "Exponential smoothing with trend")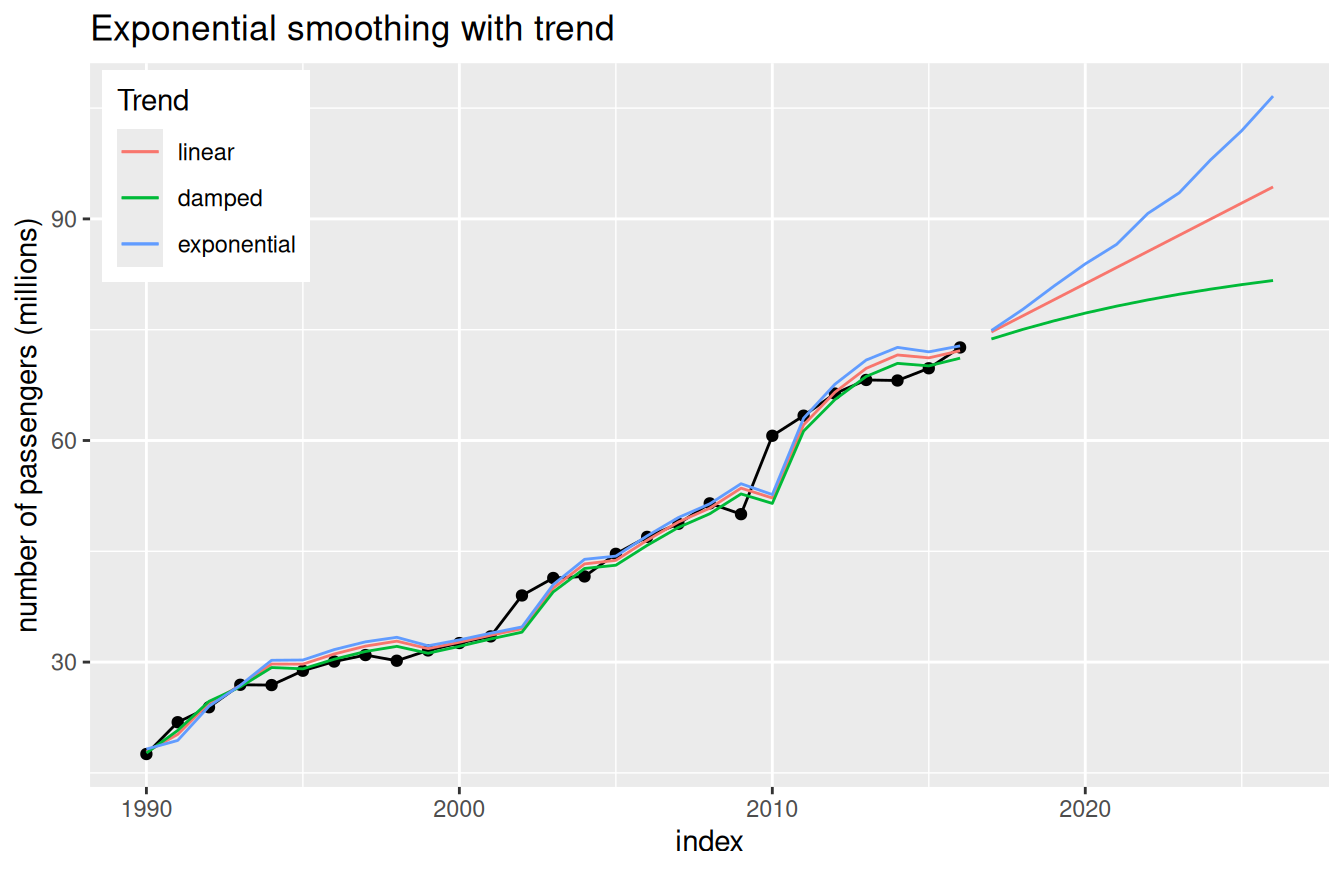
V roku 1960 navrhol Holtov žiak Winters také rozšírenie, ktoré popri lokálne lineárnom trende adaptívne zohľadňuje aj sezónnosť s periódou \(L\) (trojité EV).
Aditívny variant má tvar \[ \begin{aligned} \hat y_{t+h|t} & = a_t + h b_t + c_{t+h-L(\lfloor(h-1)/L\rfloor+1)} & \text{(predpovedanie)}\\ a_t & = \alpha (y_t-c_{t-L}) + (1-\alpha) (a_{t-1}+b_{t-1}) & \text{(vyr. úrovne)}\\ b_t & = \beta^* (a_t-a_{t-1}) + (1-\beta^*) b_{t-1} & \text{(vyr. trendu)} \\ c_t & = \gamma (y_t-a_{t-1}-b_{t-1}) + (1-\gamma) c_{t-L} & \text{(vyr. sezónnej úrovne)} \end{aligned} \] kde \(\lfloor\cdot\rfloor\) značí celočíselnú časť a vyhladzovací parameter sezónnosti má obmedzenie \(0\leq\gamma\leq1-\alpha\). Používa sa vtedy, keď sezónne variácie sú približne konštantné.
Naproti tomu multiplikatívna HW metóda \[ \begin{split} \hat y_{t+h|t} & = (a_t + h b_t) c_{t+h-L(\lfloor(h-1)/L\rfloor+1)}\\ a_t & = \alpha (\frac{y_t}{c_{t-L}}) + (1-\alpha) (a_{t-1}+b_{t-1})\\ b_t & = \beta^* (a_t-a_{t-1}) + (1-\beta^*) b_{t-1} \\ c_t & = \gamma \frac{y_t}{a_{t-1}+b_{t-1}} + (1-\gamma) c_{t-L} \end{split} \] sa hodí v prípade, že amplitúda sezónnej zložky sa mení proporčne k úrovni časového radu, pozri Obr. 6.3.
# load air passengers data in Australia
passdata <- datasets::AirPassengers |>
tsibble::as_tsibble()
# fit HW models
fit <- passdata |>
fabletools::model(
hw1 = fable::ETS(value ~ trend("A") + season("A")),
hw2 = fable::ETS(value ~ trend("A") + season("M"))
)
# show
passdata |>
ggplot() + aes(x = index) +
geom_line(aes(y = value)) + geom_point(aes(y = value)) +
(fit |> fabletools::augment() |> autolayer(.fitted)) +
(fit |>
fabletools::forecast(h = 3*12) |>
autolayer(level = NULL)
) +
scale_color_discrete(labels = c("additive", "multiplicative"), name = "Seasonality") +
theme(legend.position = "inside",
legend.position.inside = c(0.01, 0.99),
legend.justification.inside = c(0,1)) +
labs(y = "number of passengers (thousands)",
title = "Exponential smoothing with trend and seasonality")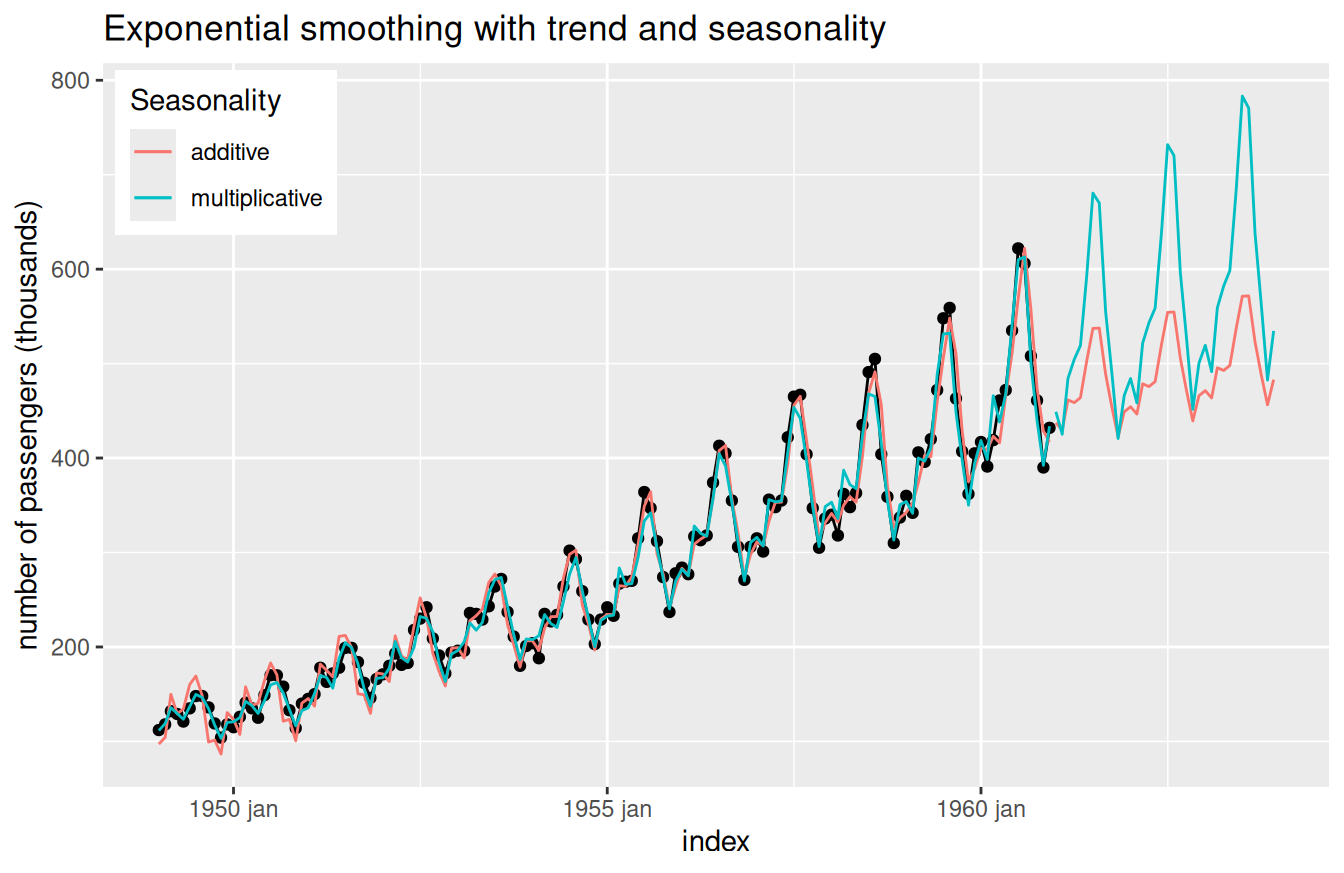
Samozrejme, HW metódu (aditívnu či multiplikatívnu) je možné rozšíriť aj o tlmený trend, podrobnosti sa dajú nájsť v (Hyndman a Athanasopoulos 2018, kap. 7.4)
Metódy z predošlej podkapitoly sú schopné generovať bodové predpovede, avšak nie intervalové. V tejto kapitole si ukážeme ich rozšírenie na plnohodnotné štatistické modely, ktoré sú schopné generovať celé rozdelenie pravdepodobnosti predpovedí.
Každý taký štatistický model sa skladá z
Preto sa označujú ako stavové modely (angl. state space models).
Pre každú metódu exponenciálneho vyhladzovania (jednoduché, trendové a sezónne) rozlišujeme dva modely: s aditívnymi a s multiplikatívnymi chybami. Preto budeme stavové štatistické modely EV jednotne označovať ako ETS(\(\cdot,\cdot,\cdot\)) – podľa iniciál angl. pojmov Error, Trend a Season. Každej zložke zodpovedá jeden argument v zátvorke:
Spomeňme si na chybový (error correction) zápis rovnice vyrovnávania \[ a_t=a_{t-1} + \alpha e_t \quad \text{kde }\quad e_t=y_t-a_{t-1}=y_t-\hat{y}_{t|t-1} \] je rezíduum v čase \(t\). Ak je \(e_t\) záporné, potom \(y_t<\hat{y}_{t|t-1}\) a \(a_{t-1}\) bolo nadhodnotené, takže nová úroveň \(a_t\) je upravená smerom nadol (v rozsahu závislom od \(\alpha\)).
Z chybovej rovnice môžme písať \(y_t=a_{t-1}+e_t\), čiže pozorovanie je reprezentované súčtom predošlej úrovne a chyby, čo sa dá previesť na stavový model, no najprv treba definovať rozdelenie pravdepobnosti chyby \(e_t\). Pre model s aditívnymi chybami predpokladáme normálne rozdelený biely šum \(e_t=\varepsilon_t\sim NID(0,\sigma_{\varepsilon}^2)\), teda “(N)ormally and (I)ndependently (D)istributed”. Potom rovnice modelu \[ \begin{aligned} y_t &= a_{t-1}+\varepsilon_t & \text{(rovnica pozorovania)} \\ a_t &= a_{t-1}+\alpha\varepsilon_t & \text{(stavová rovnica)} \end{aligned} \] spolu s rozdelením \(\varepsilon_t\) plne charakterizujú štatistický model stojaci za jednoduchým exponenciálnym vyrovnávaním, označený ETS(A,N,N). Z prvej rovnice vidno, že pozorovanie \(y_t\) je lineárnou funkciou (predpovedateľnej) úrovne \(a_{t-1}\) a (nepredpovedateľnej) šumovej zložky \(\varepsilon_t\), zatiaľčo druhá rovnica ukazuje vývoj stavu (tu iba úrovne) v čase. Ak \(\alpha=0\), stav sa nemení, opačný extrém \(\alpha=1\) vedie k náhodnej prechádzke \(y_t=y_{t-1}+\varepsilon_t\).
Podobne možno definovať model s chybami jednokrokovej predpovede ako relatívnymi chybami \[ \varepsilon_t = \frac{e_t}{\hat{y}_{t|t-1}} = \frac{y_t-\hat{y}_{t|t-1}}{\hat{y}_{t|t-1}}, \] kde \(\varepsilon_t\sim NID(0,\sigma_\varepsilon^2)\). Nahradením predpovede vyhladenou úrovňou, \(\hat{y}_{t|t-1}=a_{t-1}\) vznikne prvá rovnica stavového modelu ETS(M,N,N), obe rovnice tak budú \[ \begin{aligned} y_t &= a_{t-1}(1+\varepsilon_t)\\ a_t &= a_{t-1}(1+\alpha\varepsilon_t). \end{aligned} \]
Ak \(\varepsilon_t = y_t - a_{t-1} - b_{t-1} \sim NID(0,\sigma_\varepsilon^2)\) potom dostávame ETS(A,A,N) model s rovnicami \[ \begin{aligned} y_t &= a_{t-1}+ b_{t-1} + \varepsilon_t \\ a_t &= a_{t-1} + b_{t-1} + \alpha\varepsilon_t \\ b_t &= b_{t-1} + \beta\varepsilon_t, \end{aligned} \] kde \(\beta=\alpha\beta^*\in[0,1]\) pre porovnanie s klasickým Holtovým modelom.
Podobne by sme mohli pokračovať s ďalšími stavovými modelmi metód exponenciálneho vyrovnávania, ich rovnice sa dajú nájsť zhrnuté v (Hyndman a Athanasopoulos 2018, Tab. 7.7).
Na identifikáciu modelov v rámci triedy ETS môžu byť rovnako ako pri SARIMA použité informačné kritéria
pričom \(k\) je, ako obyčajne, počet parametrov modelu a \(n\) dĺžka trénovacej vzorky.
Alternatívou ku odhadu parametrov pomocou minimalizácie štvorcov odchýlok je maximalizácia “vierohodnosti” (pravdepodobnosti, že pozorovania vzišli z daného modelu). Pre modely s aditívnou chybou dávajú obe metódy rovnaký výsledok. V prípade ETS modelov odhadované sú parametre vyhladenia \(\alpha,\beta,\gamma\) a počiatočné stavy \(a_0,b_0,c_0,\ldots,c_{-L+1}\)
Viackrokové bodové predpovede dostaneme iteračným aplikovaním rekurentných rovníc stavového modelu pre \(t=n+1,\ldots,n+h\) a položením \(\varepsilon_t=0\) pre \(t>n\). Prirodzene, sú identické s bodovými predpoveďami zodpovedajúcej metódy EV. Z pravdepodobnostného hľadiska ide vo všeobecnosti o medián \(X_{t+h|t}\), ktorý v prípade aditívnych zložiek a normálne rozdelených chýb je totožný so strednou hodnotou.
Intervalové predpovede sa pre väčšinu ETS modelov konštruujú ako \(y_{n+h|n}\mp q_{\alpha/2}\sigma_h\), kde \(q_p\) je opäť \(p\)-kvantil normovaného normálneho rozdelenia a predpovedná smerodajná odchýlka \(\sigma_h\) sa pre každý model vypočíta z iného vzťahu, pozri (Hyndman a Athanasopoulos 2018, Tab. 7.8). Ak vzťah nie je známy, interval je určovaný z percentilov simulovaných budúcich trajektórií procesu.
Zatiaľčo všetky lineárne modely EV sú špeciálnym prípadom triedy SARIMA, nelineárne tam nemajú svoj náprotivok. Na druhej strane, žiaden stacionárny SARIMA nemôže byť ETS, pretože všetky ETS sú nestacionárne: tie sezónne a/alebo s netlmeným trendom majú dva jednotkové korene (musia byť 2-krát diferencované na dosiahnutie stacionarity), ostatné majú jeden jednotkový koreň. Tab. 6.1 obsahuje zodpovedajúce si modely oboch tried.
| ETS model | SARIMA modely | Parametre |
|---|---|---|
| ETS(A,N,N) | ARIMA(0,1,1) | \(\theta_1=\alpha-1\) |
| ETS(A,A,N) | ARIMA(0,2,2) | \(\theta_1=\alpha+\beta-2\), \(\theta_2=\alpha-1\) |
| ETS(A,Ad,N) | ARIMA(1,1,2) | \(\phi_1=\phi\), \(\theta_1 = \alpha+\phi(\beta-1)-1\), \(\theta_2=(1-\alpha)\phi\) |
| ETS(A,N,A) | SARIMA\((0,1,L)(0,1,0)_L\) | |
| ETS(A,A,A) | SARIMA\((0,1,L+1)(0,1,0)_L\) | |
| ETS(A,Ad,A) | SARIMA\((0,1,L+1)(0,1,0)_L\) |