Schopnosť organizmu prežiť závisí od schopnosti poznávať svoje životné prostredie. Vďaka pokročilej nervovej sústave má na to ľudský druh najlepšie predpoklady. Toto prostredie so svojimi fyzikálnymi, chemickými, biologickými … i sociálnymi zákonitosťami dokážeme cez vonkajšie prejavy vnímať, po častiach analyzovať, poznatky syntetizovať a pomocou formálneho jazyka zdieľať. Niektoré javy sme schopní vyjadriť presne (napr. gravitáciu), avšak väčšinu javov iba približne. Neistota v ich popise súvisí s prepojením na iné javy – jednak je ich vzťah príliš komplexný, jednak pozorovateľnosť niektorých vysvetľujúcich javov príliš náročná.
Na základe teórie pravdepodobnosti vieme javy formálne uchopiť pomocou tzv. náhodných premenných a ich výskyt popísať rozdelením pravdepodobnosti. Nástroje matematickej štatistiky zas umožňujú využiť pozorovania hromadných javov1 na modelovanie rozdelenia pravdepodobnosti náhodných premenných. Dedukciou zo štatistických modelov je možné robiť závery o skúmanom jave, napr. odhadnúť parametre rozdelenia pravdepodobnoti, rozhodnúť o prítomnosti a povahe vzťahov medzi náhodnými premennými, predpovedať nastatie konkrétnej udalosti za určitých okolností a kvantifikovať neistotu takých záverov.
Štatistické modely sú postavené na predpokladoch. Ak tie nie sú splnené, ani závery odvodené z modelov nie sú spoľahlivé. Napríklad regresné modely predpokladajú nezávislosť rezíduí. Ak však v regresnej rovnici (a v pozorovaných údajoch) chýba významná informácia (napr. časová závislosť, príslušnosť štatistickej jednotky ku skupine, alebo priestorová geometria), v rezíduách sa to prejaví ako nenáhodný vzor, takže už nie sú nezávislé.
Systematický prístup ku popisu časovej závislosti v pozorovaných údajoch sa nazýva analýza časových radov. <prehľad kapitoly, možno i celej knihy>
1.1 Štatistické modelovanie
Vlastnosti pozorovaných objektov majú často náhodný charakter (napr. výška človeka, váha, vek, zdravotný stav …). Pozorované hodnoty týchto vlastností predstavujú v matematickej štatistike realizácie náhodných premenných.
Prieskumná analýza údajov (exploratory data analysis, EDA) – prostredníctvom nástrojov na tvorbu súhrnov a vizualizácie preberaná v rámci predmetu Softvér na analýzu údajov (1.MPM), ako aj cez oblasť popisnej štatistiky vyučovaná na predmete Štatistické metódy (2.MPM) – umožnila nahliadnuť do rozdelenia pravdepodobnosti týchto náhodných premenných.
V popisných (descriptive) i deduktívnych (inference) metódach matematickej štatistiky je dôležitým konceptom štatistické modelovanie – od aritmetického priemeru až po regresnú analýzu. Za každým štatistickým testom je nejaký model (predpoklad), napr. jednovýberový t-test pracuje s nepodmienenou strednou hodnotou náhodnej premennej, zatiaľčo dvojvýberový (nepárový) t-test je postavený na lineárnom modeli s jediným, binárnym prediktorom. Testovanie komplikovanejších štatistických hypotéz už vyžaduje explicitné definovanie modelu, ako napr. pri teste významnosti regresného koeficientu (efekt jedného z prediktorov).
Komplexnosť štatistického modelu teda môže spočívať jednak vo väčšom počte vysvetľujúcich premenných (viacnásobná regresia), ale aj špecifických podmienkach experimentu či vlastnostiach údajov, kedy premenné sú v nejakej hierarchii alebo pozorovania sú po skupinách závislé (napr. mixed-effect model).
Formálne povedané, regresná analýza je nástroj matematickej štatistiky, ktorý slúži na kvantitatívny popis vzťahu medzi premennými, konkrétne na vysvetlenie zmeny hodnôt jednej z nich pomocou zmien hodnôt ostatných premenných. Vysvetľovaná premenná (označovaná aj ako závislá premenná, regresand, efekt, či odozva, angl. response) sa v tomto kontexte často značí \(Y\) a vysvetľujúce premenné (nezávislé premenné, regresory, príčiny, či prediktory) sa značia \(X_1, X_2,\ldots,X_p\).
Regresnej analýze zvyčajne predchádza korelačná analýza, ktorá skúma symetrický vzťah medzi dvoma premennými \(X_j\) a \(Y\) a kvantifikuje ho korelačným koeficientom. Ak sa v nej zistí významný lineárny vzťah (bez záverov o kauzalite), pokračuje sa regresnou analýzou, kde je vzťah asymetrický: jedna premenná je vysvetľovaná (závislá) a ostatné sú vysvetľujúce (nezávislé). Naviac, vysvetľovaná premenná \(Y\) je náhodná, má svoje pravdepodobnostné rozdelenie, zatiaľčo vysvetľujúce premenné sú svojim spôsobom nenáhodné, totiž pri opakovanom vzorkovaní (náhodnom výbere) zachovávajú fixné hodnoty. Cieľom regresnej analýzy je znížiť veľkosť nevysvetlenej variability premennej \(Y\) využitím informácie o všetkých známych vplyvoch na ňu, formálne teda predpokladáme \(E[var(Y|X_1,...,X_m)]\leq var(Y)\).
1.1.1 Tvar regresného modelu
Regresný model sa dá symbolicky zapísať vo forme rovnice \[
Y = h(\vec{X},\vec{Z})
\tag{1.1}\] kde \(Y\) je odozva, \(h\) predstavuje neznámu funkciu, \(\vec{X} = (X_1,X_2,\ldots,X_p)\) sú pozorovateľné premenné (prediktory) a \(\vec{Z}\) je vektor všetkých skrytých (latentných) faktorov. Za pomerne silných predpokladov – že vplyv latentných premenných na \(Y\) je náhodný (nemá systematický charakter), nesúvisí so žiadnou z pozorovaných premenných \(\vec{X}\) a je aditívny ku vplyvu \(\vec{X}\) – dostaneme praktický vzťah \[
Y = f(\vec{X}) + \varepsilon
\tag{1.2}\] ktorý je základom regresnej analýzy. V ňom prvý člen s neznámou funkciou \(f\) sa niekedy označuje ako deterministický a reprezentuje podmienenú strednú hodnotu odozvy, čiže \(E(Y|\vec{X})=f(\vec{X})\). Druhý člen je náhodný, kumuluje v sebe všetky ostatné vplyvy, a vďaka centrálnej limitnej vete je často zmysluplné predpokladať jeho normalitu s nulovou strednou hodnotou.
Definičný obor (domain) funkcie \(f\) je kartézskym súčinom oboru hodnôt (range) prediktorov, čiže \(dom(f) = ran(X_1)\times ran(X_2) \times\ldots\times ran(X_p)\). V prípade kvantitatívnej premennej \(X_j\) je to najčastejšie množina všetkých reálnych čísel, \(ran(X_j) = \mathbb{R}\), alebo interval, a v prípade kvalitatívnych premenných akákoľvek konečná množina. Obor hodnôt \(ran(f)=ran(Y)\) je najčastejšie \(\mathbb{R}\).
Spôsob odhadu neznámej funkcie \(f\) závisí od konečného použitia modelu, množstva pozorovaní a výkonnosti počítača. Ak je model určený iba na predpovedanie, pozorovaní je dostatok a ani výpočtové zdroje nie sú výrazne obmedzené, potom je možné použiť flexibilnejší, čiže neparametrický odhad (založený napr. na jadrových funkciách). V ostatných prípadoch sa používa parametrický prístup, v ktorom je model zaťažený zjednodušujúcimi predpokladmi (o tvare matematickej funkcie a o rozdelení náhodného člena). Nedostatok flexibility oproti neparametrickému prístupu vyvažuje lepšia interpretovateľnosť, vďaka ktorej môže byť model použitý na lepšie pochopenie mechanizmu, ktorý generoval pozorované údaje. Na parametrický odhad funkcie \(f\) sa vo všeobecnosti využíva metóda nelineárnych najmenších štvorcov (angl. nonlinear least squares, NLS) alebo metóda maximálnej vierohodnosti (angl. maximum likelihood, ML).
Problémom triedy regresných modelov v tvare (1.2) je výpočtová náročnosť odhadu. Pretože metódy NLS aj ML sú iteratívne, konvergencia riešenia závisí od počiatočnej podmienky, a ani nájdenie globálneho extrému (najlepšieho riešenia) nie je zaručené. Preto sa v praxi pre triedu parametrických funkcií \(f\) zavádza ďalší zjednodušujúci predpoklad – linearita v parametroch. Výsledná trieda modelov je ešte stále dostatočne flexibilná na aproximáciu väčšiny regresných vzťahov, no zároveň na odhad parametrov umožňuje použiť elegantnú a výpočtovo efektívnu metódu najmenších štvorcov (angl. ordinary least square, OLS).
Parametrický regresný model vo všeobecnom tvare (1.2) sa zjednoduší aditívnym rozkladom funkcie \(f\) na bázové funkcie \(f_k\colon dom(f)\to ran(f)\), kde \(k=1,2,\ldots,m\), ktoré transformujú vplyv jednotlivých prediktorov na odozvu. Taký regresný model lineárny v parametroch má potom tvar \[
Y = \beta_1f_1(\vec{X}) + \beta_2f_2(\vec{X}) + \ldots + \beta_mf_m(\vec{X}) + \varepsilon.
\tag{1.3}\] Transformácie vplyvu prediktorov jednotlivými bázovými funkciami, čiže \(f_k(\vec{X})\), budeme nazývať regresory. Linearita modelu v parametroch znamená, že podmienená stredná hodnota odozvy sa dá vyjadriť ako lineárna kombinácia regresorov.
Zápis (1.3) zatiaľ predstavuje celú parametrickú triedu lineárnych modelov. Na vybudovanie konkrétneho modelu sú potrebné dva kroky:
identifikácia modelu, t.j. voľba bázových funkcií,
odhad parametrov \(\beta_j\).
Linearita v parametroch umožňuje model upraviť do skalárneho súčinu vektora parametrov \(\boldsymbol\beta\) a vektora bázových funkcií \(\mathbf{f}(\vec{X})\), \[
\begin{split}
Y &= (\beta_1, \beta_2, \ldots, \beta_m)\cdot\Big(f_1(\vec{X}), f_2(\vec{X}), \ldots, f_m(\vec{X})\Big) + \varepsilon \\
&= \boldsymbol\beta\cdot\mathbf{f}(\vec{X}) + \varepsilon
\end{split}
\tag{1.4}\] čo výrazne uľahčuje odhad parametrov.
1.1.2 Identifikácia modelu
Prvá bázová funkcia sa najčastejšie volí ako konštantná, čiže \(f_1(\vec{X})=1\), potom prvý člen \(\beta_1\cdot 1\) v regresnej rovnici sa nazýva absolútny člen alebo priesečník (angl. intercept), pretože predstavuje hodnotu odozvy v prípade nulovej veľkosti všetkých ostatných členov (priesečník plochy funkcie \(f\) s osou \(Y\)). Bázové funkcie zvyčajne nezávisia od všetkých premenných naraz: každá z nich je konštantná vo všetkých premenných okrem jednej, v ktorej má tvar závislý od typu tejto premennej.
Ak je vysvetľujúca premenná kvantitatívna, rez bázovej funkcie sa často volí v tvare
Kvalitatívna premenná nemôže do regresnej rovnice vstúpiť priamo, a tak bázové funkcie slúžia na jej kódovanie, čiže prevod do číselnej reprezentácie. Najčastejšie sa zvolí jedna hodnota premennej \(X_j\) ako referenčná, napr. \(a_1\in ran(X_j)\), a nastatie ostatných hodnôt \(\{a_2,\ldots,a_q\}=ran(X_j)\setminus a_1\) je indikované \((q-1)\) bázovými funkciami \(f_{k+\ell}(\vec{X})=\mathbf{1}_{\{a_{2+\ell}\}}(X_j)\) pre \(\ell=0,1,\ldots,q-2\). Tzv. indikačná funkcia je definovaná predpisom \[
\mathbf{1}_A(x) = \begin{cases} 1 & \quad x\in A \\ 0 & \quad x\notin A \end{cases}
\] kde \(A\) je množina. Takéto kódovanie umožní interpretovať každý parameter \(\beta_{k+\ell}\) ako rozdiel (kontrast) v strednej hodnote odozvy pre situáciu \(X_j=a_{2+\ell}\) oproti situácii \(X_j=a_1\).
Indikačná funkcia sa dá použiť aj pri spojitých premenných, kedy množina \(A\) predstavuje interval.
Synergia vplyvov viacerých prediktorov sa najčastejšie modeluje ich súčinom. Ak sú prediktory kvantitatívne, tak priamo, napr. \(f_k(\vec{X})=X_i\,\cdot X_j\), kde \(i\neq j\), ale ak kvalitatívne, tak v kombinácii s indikačnou funkciou, \(f_{k+\ell}(\vec{X})=X_i\,\cdot\mathbf{1}_{a_{2+\ell}}(X_j)\).
Špeciálny prípad tvorí tzv. lineárny regresný model, kedy \(m=p+1\) a \(f_{j+1}(\vec{X})=X_j\) pre \(j=1,\ldots,p\). Jeho rovnica je v známom tvare \[
Y = \beta_1 + \beta_2X_1 + \ldots + \beta_{p+1}X_p + \varepsilon
\] a parameter \(\beta_{j+1}\) sa interpretuje ako reakcia (prírastok) odozvy na jednotkovú zmenu prediktoru \(X_j\), pričom hodnoty ostatných prediktorov zostávajú nezmenené. V prípade lineárneho regresného modelu sa formálna indexácia parametrov často začína od nuly.
Bázovými funkciami je možné aproximovať takmer akúkoľvek formu nelineárneho vzťahu medzi odozvou a prediktormi. Niekedy však z hľadiska efektívnosti a interpretovateľnosti modelu je lepšie zamerať snahu na výber účinnej transformácie odozvy namiesto transformácie prediktorov. Dostávame rozšírenie triedy (1.3) – alebo medzistupeň zjednodušovania (1.1) smerom ku (1.3) – ktoré zachováva linearitu modelu v parametroch a aditivitu s náhodným členom, teda \[
g(Y) = \beta_1f_1(\vec{X}) + \beta_2f_2(\vec{X}) + \ldots + \beta_mf_m(\vec{X}) + \varepsilon
\] kde \(g\colon \mathbb{R}\to\mathbb{R}\) je striktne monotónna funkcia. Jej tvar sa určuje ešte pred odhadom parametrov, napríklad tak, aby bola dosiahnutá symetria podmieneného rozdelenia pravdepodobnosti novej odozvy \(g(Y)\) alebo konštantný rozptyl súboru pozorovaní.
Voľba bázových funkcií je do značnej miery subjektívna. Odzrkadľuje výsledky prieskumnej analýzy údajov, zameranie regresnej analýzy aj skúsenosti odborníka. Bežným postupom je (1.) navrhnúť niekoľko kandidátskych tried modelov, (2.) po odhade vyhodnotiť ich predikčné schopnosti a (3.) vybrať najlepší s prihliadnutím na konečné využitie – predpovedný, inferenčný alebo interpretačný účel.
1.1.3 Odhad parametrov
Na odhad parametrov regresného modelu je potrebný súbor pozorovaných údajov. Označme \(i\)-te pozorovanie odozvy ako \(y_i\) a \(j\)-teho prediktoru ako \(x_{ij}\), pričom \(i=1,\ldots,n\). Po dosadení do rovnice modelu (1.3) dostávame sústavu regresných rovníc\[
y_i = \beta_1f_1(\vec{x_i}) + \beta_2f_2(\vec{x_i}) + \ldots + \beta_mf_m(\vec{x_i}) + \varepsilon_i, \qquad i=1,\ldots,n,
\] kde \(\vec{x_i}=(x_{i1},\ldots,x_{ip})\) a člen \(\varepsilon_i\) predstavuje \(i\)-te rezíduum modelu. Rezíduum v sebe integruje súhrn vplyvov, ktoré v modeli nie sú explicitne uvedené, napr. nepozorovateľné veličiny, chyby merania veličín, nesprávna voľba regresného vzťahu či nepredvídateľné udalosti.
S využitím vektorového zápisu (1.4) dostávame regresné rovnice v maticovom tvare \[
\mathbf{y} = \mathbf{X} \boldsymbol{\beta} + \boldsymbol{\varepsilon},
\] kde \[
\mathbf{y} = \begin{pmatrix} y_1 \\ y_2 \\ \vdots \\ y_n \end{pmatrix}, \quad
\mathbf{X} = \begin{pmatrix}
f_1(\vec{x_1}) & f_2(\vec{x_1}) & \cdots & f_m(\vec{x_1}) \\
f_1(\vec{x_2}) & f_2(\vec{x_2}) & & f_m(\vec{x_2}) \\
\vdots & & \ddots & \\
f_1(\vec{x_n}) & f_2(\vec{x_n}) & & f_m(\vec{x_n})
\end{pmatrix}, \quad
\boldsymbol{\beta} = \begin{pmatrix} \beta_1 \\ \beta_2 \\ \vdots \\ \beta_m \end{pmatrix}, \quad
\boldsymbol{\varepsilon} = \begin{pmatrix} \varepsilon_1 \\ \varepsilon_2 \\ \vdots \\ \varepsilon_n \end{pmatrix}.
\] Matica \(\mathbf{X}\) má rozmer \(n\times m\) a nazýva sa regresná matica alebo matica plánu (angl. design matrix, model matrix).
Na odhad parametrov lineárneho modelu sa používajú rôzne prístupy, napr. metóda maximálnej vierohodnosti či metóda momentov, najčastejšia je to ale metóda najmenších štvorcov (angl. ordinary least squares method, OLS), ktorá v prípade normálne rozdeleného reziduálneho člena koinciduje s metódou ML. Princíp metódy najmenších štvorcov spočíva v minimalizácii súčtu štvorcov rezíduí (angl. residual sum of squares, RSS) \[
RSS(\boldsymbol\beta)=\sum_{i=1}^n \varepsilon_i^2 = \sum_{i=1}^n (y_i-\mathbf{X}_{i\cdot}\boldsymbol{\beta})^2 = (\mathbf{y}-\mathbf{X}\boldsymbol{\beta})'(\mathbf{y}-\mathbf{X}\boldsymbol{\beta}),
\] kde \(\mathbf{X}_{i\cdot}\) je \(i\)-ty riadok regresnej matice. Minimum funkcie je v bode, kde sa gradient RSS rovná nulovému vektoru, z toho úpravou cez systém tzv. normálnych rovníc, za podmienky existencie inverzie matice \(\mathbf{X}'\mathbf{X}\) dostávame vzťah pre odhad \(\hat{\boldsymbol{\beta}}\), formálne \[
\begin{split}
\frac{\partial SSR(\boldsymbol\beta)}{\partial\boldsymbol\beta}=\sum_{i=1}^n 2(y_i-\mathbf{X}_{i\cdot}\boldsymbol{\beta})(-1)\mathbf{X}_{i\cdot}'=
-2\mathbf{X}'\mathbf{y} + 2 \mathbf{X}'\mathbf{X} \boldsymbol\beta & \\
-2\mathbf{X}'\mathbf{y} + 2 \mathbf{X}'\mathbf{X} \hat{\boldsymbol\beta} & = \boldsymbol{0} \\
(\mathbf{X}'\mathbf{X})\hat{\boldsymbol\beta} & = \mathbf{X}'\mathbf{y} \\
\hat{\boldsymbol\beta} & = (\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'\mathbf{y}
\end{split}
\] Potom podmienené stredné hodnoty odozvy pri pozorovaných hodnotách regresorov (pri iných hodnotách už ide o predikciu) sa vypočíta zo vzťahu \(E(Y|\mathbf{X}) = \hat{\mathbf{y}} = \mathbf{X} \hat{\boldsymbol\beta}\) a odhad rezíduí pomocou \(\hat{\boldsymbol{\varepsilon}} = \mathbf{y} - \hat{\mathbf{y}}\).
Okrem parametrov \(\beta\) obsahuje regresný model ešte jeden neznámy parameter a tým je rozptyl reziduálnej zložky \(\sigma_\varepsilon^2\). Jeho odhad sa vypočíta pomocou vzťahu \[
\hat{\sigma}_\varepsilon^2 = \frac{\hat{\boldsymbol{\varepsilon}}'\hat{\boldsymbol{\varepsilon}}}{n-m},
\] okrem toho je však dôležité odhadnúť i kovariančnú maticu odhadu neznámych parametrov \(\boldsymbol\beta\), \[
\hat{\boldsymbol\Sigma}_{\beta} = \hat\sigma_\varepsilon^2(\mathbf{X}'\mathbf{X})^{-1}
\] pretože pomocou prvkov na jej diagonále, \(\hat\sigma_{\beta_j}^2=(\hat{\boldsymbol\Sigma}_{\beta})_{jj}\), sa dá testovať štatistická hypotéza o významnosti parametra \(\beta_j\) a tak aj o významnosti vplyvu vysvetľujúcej premennej \(X_j\) na odozvu, konkrétne testovacou štatistikou \(\frac{\hat\beta_j}{\hat\sigma_{\beta_j}}\sim t(n-m)\).
1.1.4 Predpoklady
Aby sme sa mohli spoľahnúť na dobré vlastnosti odhadu metódou najmenších štvorcov (napr. nestrannosť, konzistentnosť a výdatnosť), regresný model musí spĺňať niekoľko predpokladov:
Model je primeranou aproximáciou reality, teda napr. vzťah medzi \(Y\) a regresormi je skutočne lineárny.
Stredná hodnota reziduálnej zložky je nulová, \(E(\boldsymbol{\varepsilon})=\mathbf{0}\).
Inak sú odhady systematicky vychýlené (napr. ak sa vynechá absolútny člen).
Rozptyl reziduálnej zložky je konštantný a jej hodnoty v rôznych okamihoch pozorovania sú navzájom nekorelované, \(var(\boldsymbol{\varepsilon})=\sigma_\varepsilon^2\mathbf{I}\).
V opačnom prípade je odhad nevýdatný, dáta obsahujú viac informácie, než model dokáže zúžitkovať.
Regresory (v rovnakom okamihu) nekorelujú s reziduálnou zložkou, \(E(\mathbf{X}'\boldsymbol{\varepsilon})=\mathbf{0}\).
Inak je odhad nekonzistentný.
Podmienka normality rezíduí, \(\boldsymbol{\varepsilon}\sim N(\mathbf{0},\sigma^2\mathbf{I})\).
Je užitočná najmä pri testovaní parametrov a pri konštrukcii predpovedí.
Predpoklad konštantného rozptylu sa označuje aj ako homoskedasticita, jeho porušenie potom ako heteroskedasticita a tá sa rieši prevažne použitím vhodnej transformácie odozvy, zavedením váh do odhadu parametrov, alebo pomocou špeciálnych nelineárnych modelov, napr. GARCH.
Nežiadúci vplyv nesplnenia normality sa dá napraviť napr. vhodnou transformáciou odozvy, ďalej použitím robustných metód odhadu, ktoré sú necitlivé na typ rozdelenia, alebo explicitným modelovaním extrémnych hodnôt, ktoré sú niekedy príčinou zamietnutej normality, a to pomocou indikačných bázových funkcií.
Autokorelovanosť rezíduí je v analýze časových radov častý jav, dôvody môžu byť rôzne. V modeli napr. chýbajú regresory, ktorých časové rady vykazujú autokorelovanosť a tá sa preto presunie do reziduálnej zložky. Alebo medzi regresory mali byť zaradené (časovo) posunuté hodnoty vysvetľovanej premennej (niekedy aj vysvetľujúcich), teda model má nedostatočne špecifikovanú dynamiku. Alebo regresný vzťah je v skutočnosti nelineárny a teda použitá lineárna funkcia ho neaproximuje dostatočne dobre.
TipPríklad (CO2)
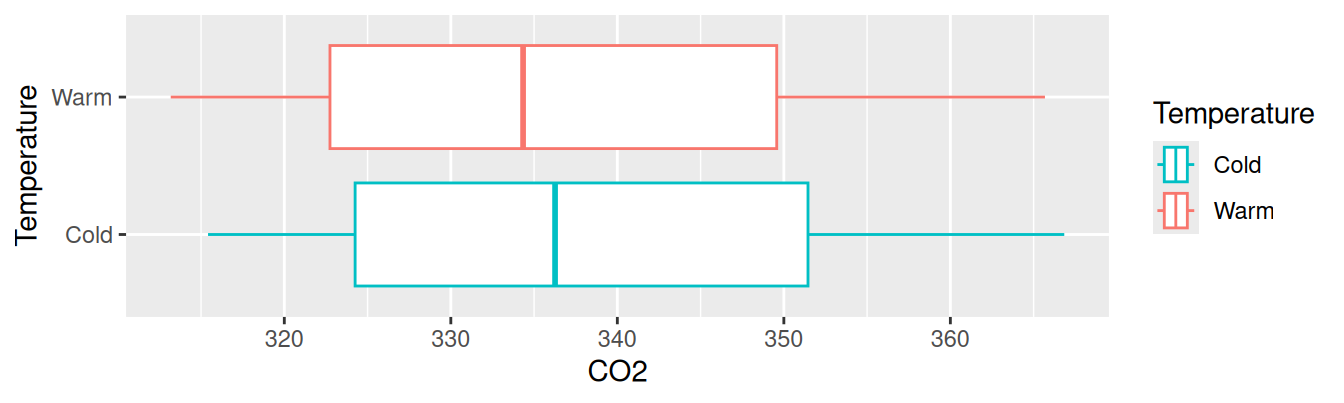
Dataset co2 z balíku datasets obsahuje 468 mesačných pozorovaní atmosférickej koncentrácie CO2 (v jednotkách ppm) na hawajskej sopke Mauna Loa medzi rokmi 1959 a 1997. Na začiatok predpokladajme, že zmena koncentrácie sa dá priamo vysvetliť zmenou teploty. Hoci dlhodobé merania teploty nie sú k dispozícii, od meteorologickej služby vieme, že mesiace jún až november sú teplejšie ako ročný priemer (26°C). Vytvoríme teda premennú Temperature, ktorá hodnotou “Warm” indikuje vyššie teploty a “Cold” nižšie.
Z prieskumnej analýzy pomocou krabicového grafu nič nenasvedčuje tomu, že by sa koncentrácia CO2 mala meniť s teplotou. Zhodu stredných hodnôt v oboch skupinách formálne otestujeme pomocou t-testu (čiže na základe lineárneho regresného modelu s binárnym prediktorom).
Kód
fit <-lm(CO2 ~ Temperature, dat)summary(fit)
Call:
lm(formula = CO2 ~ Temperature, data = dat)
Residuals:
Min 1Q Median 3Q Max
-23.000 -13.669 -1.774 13.498 29.500
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 337.9266 0.9777 345.617 <2e-16 ***
TemperatureWarm -1.7462 1.3827 -1.263 0.207
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 14.96 on 466 degrees of freedom
Multiple R-squared: 0.003411, Adjusted R-squared: 0.001272
F-statistic: 1.595 on 1 and 466 DF, p-value: 0.2073
Nulovú hypotézu o rovnosti podmienených stredných hodnôt nemožno na hladine významnosti 5% s týmto modelom zamietnuť (p-value 0.207). Avšak ani spoľahlivosť modelu sme zatiaľ nijak nevyhodnotili.
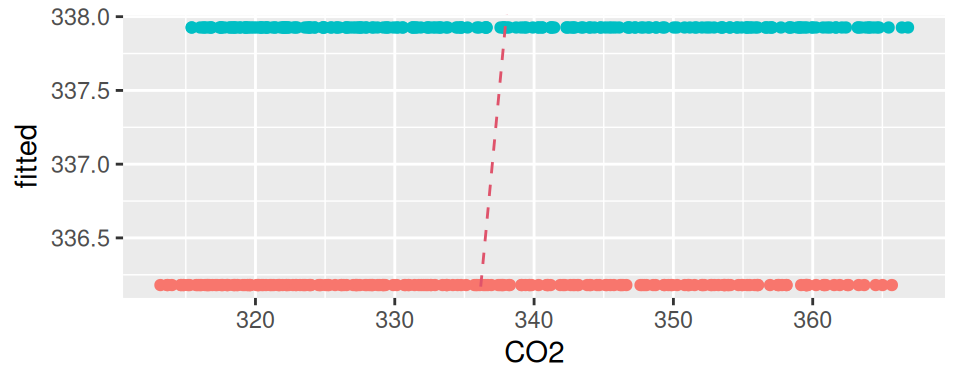
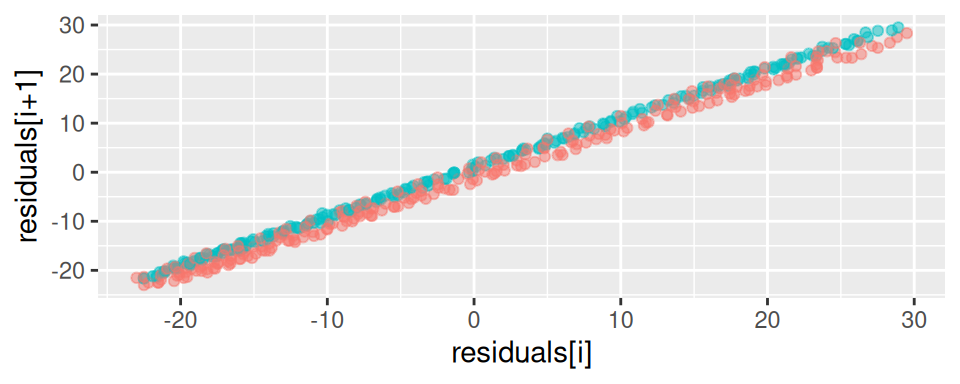
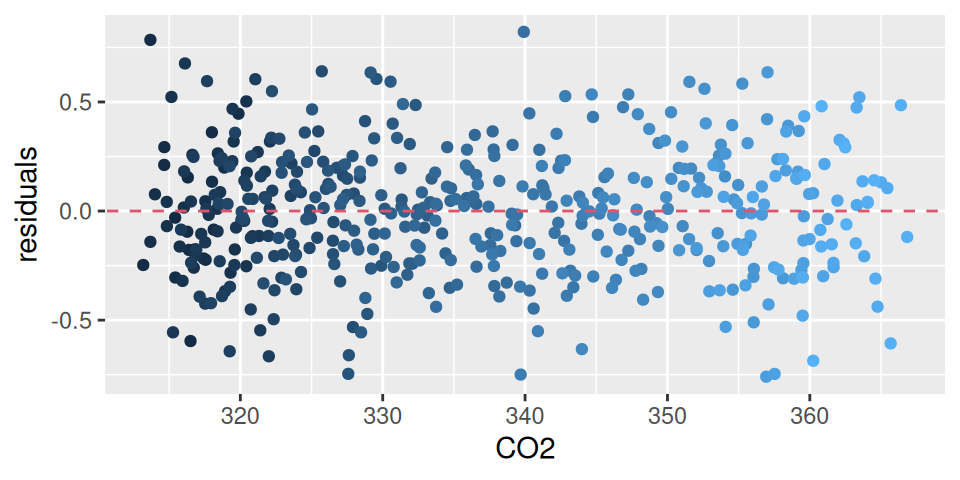
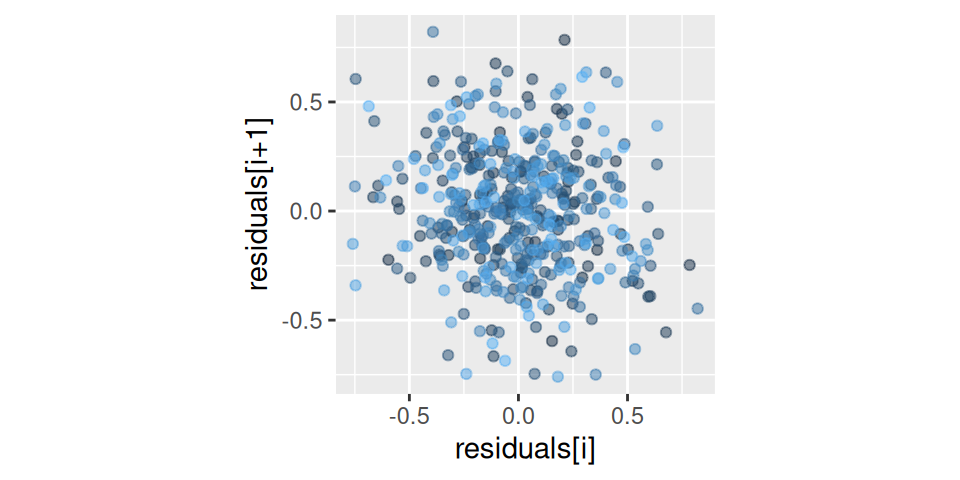
Na posúdenie popisnej schopnosti funkcie použijeme bodový graf pozorovaných a predikovaných hodnôt (saturovaný model by mal body na červenej prerušovanej čiare), a na odhalenie korelovanosti šumovej zložky poslúži bodový graf susedných dvojíc hodnôt rezíduí (nekorelované rezíduá vytvoria kruhové mračno bodov).
Kód
fitdat <- dat |> dplyr::mutate(fitted = fit$fitted.values,residuals = fit$residuals,residlag1 =c(tail(residuals,-1), NA) )# dplyr::summarise(fitdat, cor = cor(residuals, residlag1, use = "complete.obs"))ggplot(fitdat) +aes(x = CO2, y = fitted, color = Temperature) +geom_point(show.legend =FALSE) +scale_color_Temperature() +geom_abline(slope =1, linetype =2, color =2)#ggplot(fitdat) + aes(x = fitted, y = residuals) + geom_point()ggplot(fitdat) +aes(x = residuals, y = residlag1, color = Temperature) +geom_point(alpha =0.5, show.legend =FALSE) +scale_color_Temperature() +labs(x ="residuals[i]", y ="residuals[i+1]")#with(fitdat, cor(residuals, residlag1, use = "complete.obs"))
(a)
(b)
Obrázok 1.1: Diagnostické grafy pre model CO2 s indikátorom teploty
Z Obr. 1.1 (a) vidieť, že model popisuje dáta veľmi zle (tomu napovedal už aj koeficient determinácie R2=0.003). Podobne z Obr. 1.1 (b) vidieť silnú korelovanosť rezíduí (ρ=0.997).
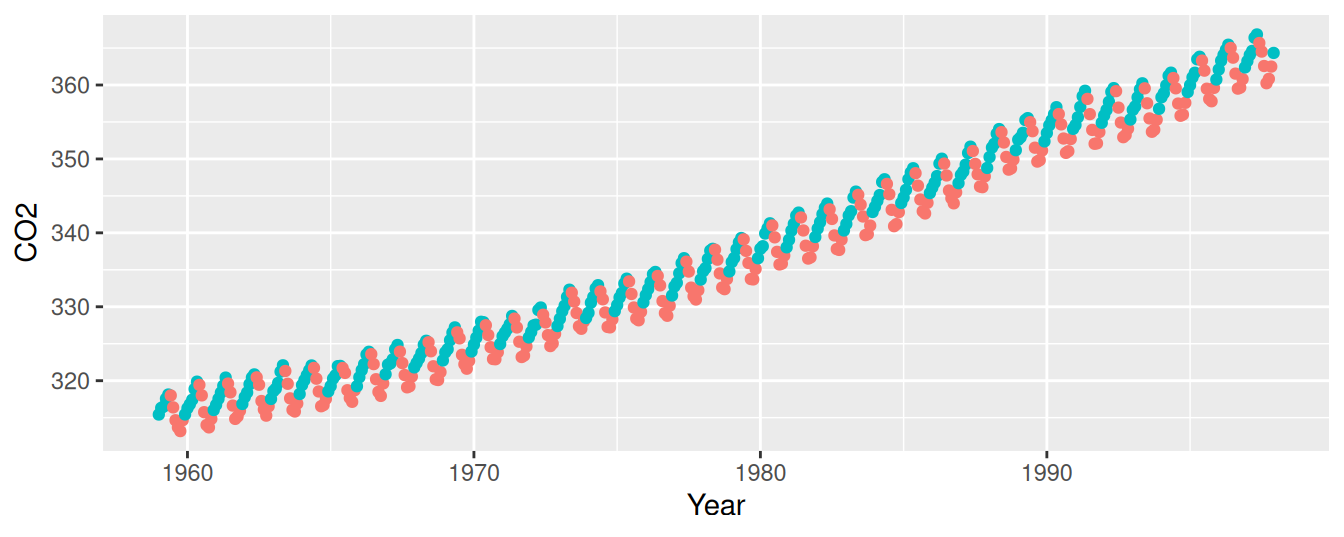
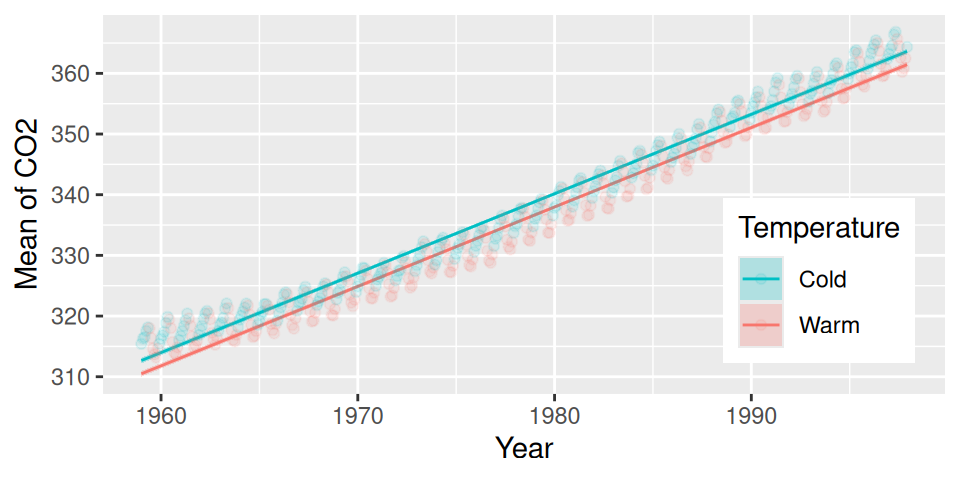
Čo je príčinou nespoľahlivosti nášho prvého modelu? Odpoveď bude zjavná pri pohľade na graf pozorovaní zoradených chronologicky (Obr. 1.2).
Kód
dat |>ggplot() +aes(x = Year, y = CO2, color = Temperature) +geom_point(show.legend =FALSE) +scale_color_Temperature()
Obrázok 1.2: Časový rad koncentrácie CO2
Medziročný rast úrovne CO2 je výraznejší než sezónne výkyvy.
Ak teda chceme ukázať súvis s teplotou, musíme do modelu zahrnúť aj predpoklad globálneho oteplovania, nepriamo sprostredkovaný kvantitatívnou časovou premennou Year.
Kód
fit <-lm(CO2 ~ Temperature + Year, dat)#fit <- lm(CO2 ~ Temperature + splines::ns(Year,df = 3), dat)summary(fit)
Call:
lm(formula = CO2 ~ Temperature + Year, data = dat)
Residuals:
Min 1Q Median 3Q Max
-4.9462 -1.8854 -0.2033 1.5590 7.0830
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.252e+03 1.935e+01 -116.386 <2e-16 ***
TemperatureWarm -2.183e+00 2.202e-01 -9.912 <2e-16 ***
Year 1.309e+00 9.778e-03 133.858 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.381 on 465 degrees of freedom
Multiple R-squared: 0.9748, Adjusted R-squared: 0.9747
F-statistic: 8990 on 2 and 465 DF, p-value: < 2.2e-16
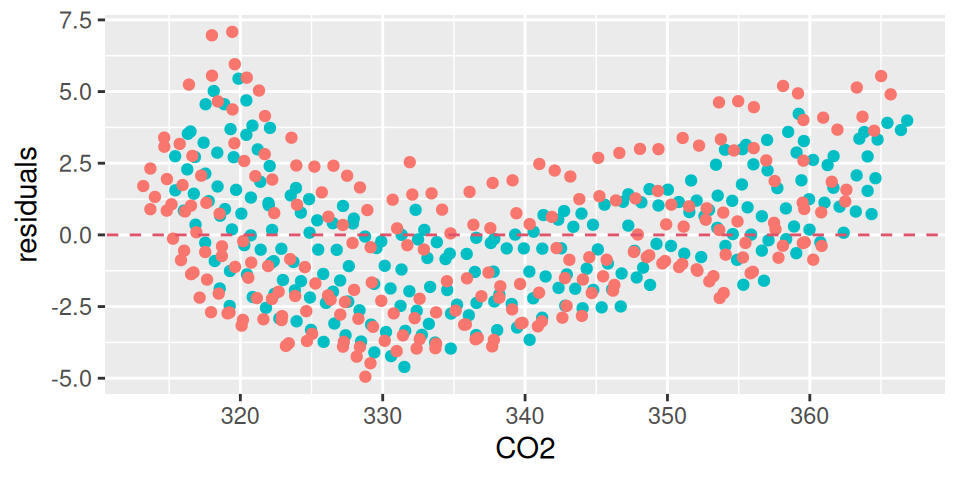
Popisná schopnosť modelu vyjadrená koeficientom determinácie vďaka efektu dlhodobej zmeny dramaticky vzrástla, čo zároveň pomohlo určiť sezónny vplyv teploty o celý rád presnejšie (SE=0.22), takže tentoraz sa už javí ako štatisticky významný (p-hodnota \(\approx 0\)). Jeho efekt je na Obr. 1.3 (a) zobrazený ako konštantný posun vplyvom premennej Temperature pri ľubovoľnej hodnote Year.
Kód
fit |> modelbased::estimate_means(by =c("Year","Temperature")) |>plot() +geom_point(aes(x = Year, y = CO2, color = Temperature), data = dat, alpha =0.1) +scale_color_Temperature() +theme(legend.position ="inside", legend.position.inside =c(0.85,0.3))fitdat <- dat |> dplyr::mutate(residuals = fit$residuals,residlag1 =c(tail(residuals,-1), NA) )ggplot(fitdat) +aes(x = CO2, y = residuals, color = Temperature) +geom_point(show.legend =FALSE) +geom_abline(slope =0, linetype =2, color =2) +scale_color_Temperature()
(a) Predikcie
(b) Rezíduá
Obrázok 1.3: Modelu koncentrácie CO2 s pridaným časovým indexom.
Model však stále nemá splnené predpoklady. Jednak je funkcia systematicky (mierne) vychýlená od pozorovaní – nesymetrické usporiadanie rezíduí okolo nuly na Obr. 1.3 (b) – jednak sú rezíduá silno korelované (ρ=0.858).
Asymetria sa dá riešiť vhodnými bázovými funkciami v smere premennej Year. Rezíduá však budú stále silno korelované, najviac s tými, ktoré sú posunuté o 1 a 12 časových krokov (mesiacov), a do významnej miery aj pri ďalších časových posunoch. Pritom posun 12 mesiacov súvisí s obmedzením teploty na dve hodnoty v roku. Riešením je zaviesť do modelu reprezentáciu teploty s vyšším rozlíšením – kvalitatívnu premennu s hodnotami pre každý mesiac (Month). Potom sezónny vzorec z rezíduí prakticky zmizne. V modeli však nesmú vystupovať obe premenné (Temperature a Month) súčasne, pretože sú úplne kolineárne (jedna sa dá vyjadriť pomocou druhej) a model by tak bol neodhadnuteľný.
Kód
alias(CO2 ~ Month + Temperature + Year, dat)
Model :
CO2 ~ Month + Temperature + Year
Complete :
(Intercept) Month2 Month3 Month4 Month5 Month6 Month7 Month8
TemperatureWarm 0 0 0 0 0 1 1 1
Month9 Month10 Month11 Month12 Year
TemperatureWarm 1 1 1 0 0
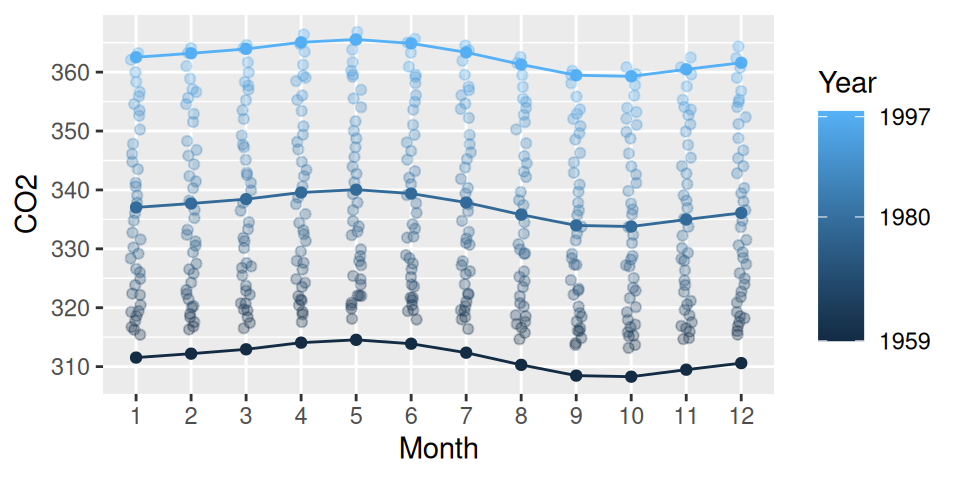
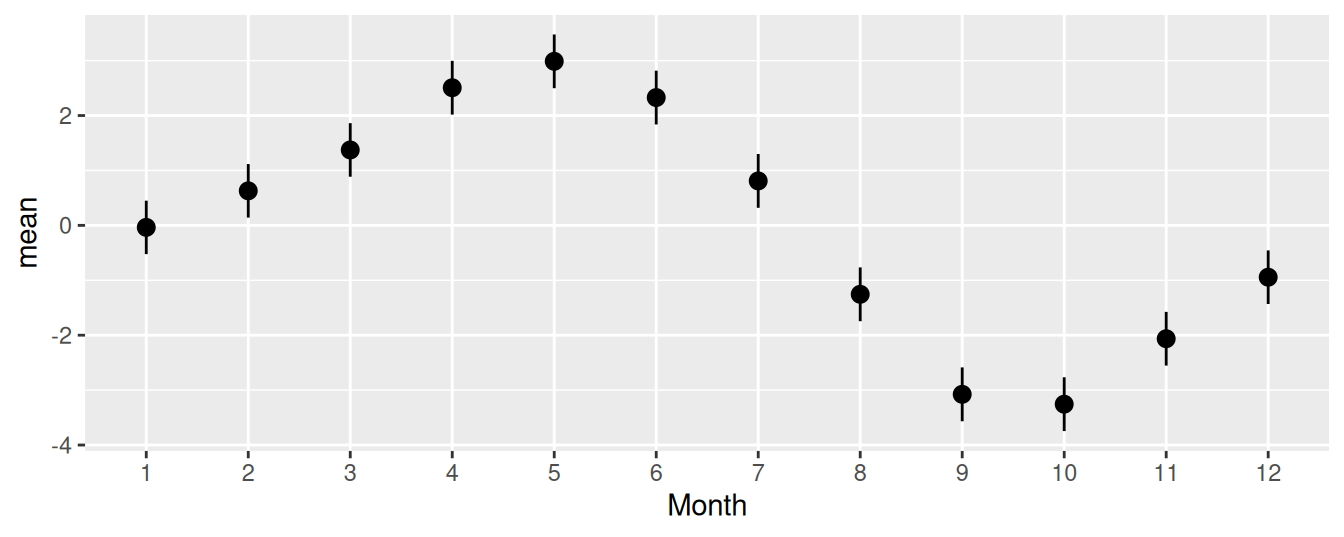
Vytvoríme teda model, kde Month nahradí premennú Temperature a zobrazíme marginálne efekty prediktorov i rezíduá.
fit |> modelbased::estimate_means(by =c("Month", "Year"), length =3) |># plot() + ggplot() +aes(x = Month, y = Mean, group = Year) +geom_line(aes(color = Year)) +geom_point(aes(color = Year)) +geom_jitter(aes(x = Month, y = CO2, color = Year), data = dat, alpha =0.3, width =0.1) +scale_color_gradient(breaks =c(1959, 1980, 1997)) +labs(y ="CO2")fitdat <- dat |> dplyr::mutate(residuals = fit$residuals,residlag1 =c(tail(residuals,-1), NA) )ggplot(fitdat) +aes(x = CO2, y = residuals, color = Year) +geom_point(show.legend =FALSE) +geom_abline(slope =0, linetype =2, color =2)#with(fitdat, cor(residuals, residlag1, use = "complete.obs"))
(a) Predikcie
(b) Rezíduá
Obrázok 1.4: Model CO2 s podrobnejšou sezonalitou.
Nový prediktor pomohol vysvetliť približne polovicu variability rezíduí predošlého modelu. Tým sa zároveň
zvýraznila systematická odchýlka rezíduí od nulovej strednej hodnoty naznačená už v rezíduách predošlého modelu – porovnaj Obr. 1.4 (b) s Obr. 1.3 (b) – takže sa zosilnila aj ich korelácia s posunutými hodnotami (ρ=0.915),
ukázal mierny nesúlad reality a našej prvotnej predstavy o tom, ako teplota súvisí s koncentráciou.
Pôvodne sme chceli testovať rozdiel koncentrácie medzi obdobiami s najvyššou a najnižšou teplotou (čiže vplyv teploty na CO2 v tom istom ročnom období). Na obrázku predikcií modelu – Obr. 1.4 (a) – však vidno, že koncentrácia CO2 dosahuje maximum v máji a minimum v septembri, takže priebeh nemá pravidelný sínusový tvar. Naproti tomu teplota (podľa informácií zo stránky meteoslužby) sa mení pravidelne, pričom kulminuje v auguste až septembri a minimum má vo februári až v marci). Hoci druhý model naznačuje negatívnu koreláciu, priamy vzťah medzi koncentráciou a teplotou nie je jednoznačný a nemá zmysel počítať s ním pri ďalšej aproximácii (ani keby boli dostupné priame záznamy teploty).
V tomto prípade je výhodnejšie modelovať koncentráciu CO2 ako časový rad, a to metódami, ktoré si predstavíme v ďalších kapitolách. Z nich sme už prakticky aplikovali rozklad (dekompozíciu) na trend (zastúpenú premennou Year), sezónnu zložku (Month) a reziduálnu zložku. Ak by sme chceli dotiahnuť príklad s koncentráciou CO2 do konca, čiže až ku modelu, ktorý má splnené všetky predpoklady, museli by sme zapojiť vhodnejšie bázové funkcie na flexibilnejší popis dlhodobého vývoja a pridať dynamický model reziduálnej zložky.
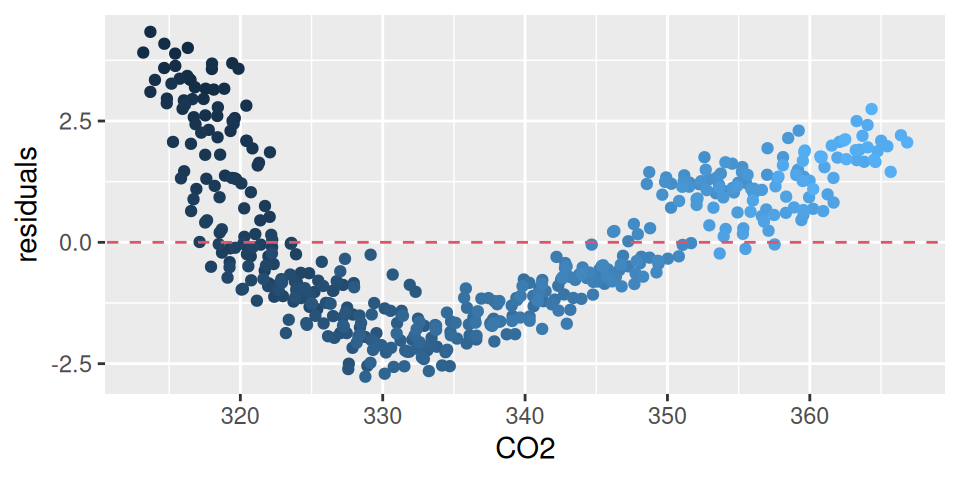
Na Obr. 1.5 sú zobrazené rezíduá modelu, v ktorom trend je popísaný prirodzeným splajnom s 3 stupňami voľnosti a korelácia reziduálnej zložky zas autoregresným členom prvého stupňa.
Kód
fit <-lm(CO2 ~ Month + splines::ns(Year, df =3), dat)# fit |> modelbased::estimate_means("Year") |> plot()# fit |> residuals() |> plot()fit1 <-arima(dat$CO2, order =c(1,0,0), xreg =model.matrix(fit), include.mean =FALSE)fitdat <- dat |> dplyr::mutate(residuals =as.numeric(fit1$residuals),residlag1 =c(tail(residuals,-1), NA) ) |> tidyr::drop_na()ggplot(fitdat) +aes(x = CO2, y = residuals, color = Year) +geom_point(show.legend =FALSE) +geom_abline(slope =0, linetype =2, color =2)ggplot(fitdat) +aes(x = residuals, y = residlag1, color = Year) +geom_point(alpha =0.5, show.legend =FALSE) +labs(x ="residuals[i]", y ="residuals[i+1]") +coord_fixed(ratio =1)
(a)
(b)
Obrázok 1.5: Rezíduá úplného modelu časového radu CO2.
Rezíduá sú náhodné rozdelené okolo nuly, bez sériovej korelácie, normálne rozdelené (p-hodnota Shapiro-Wilkovho testu p=0.671) naznačujú spoľahlivosť modelu. Môžeme ho teda použiť na testovanie hypotéz, napr. o významnosti konkrétneho efektu alebo nejakej jeho vlastnosti. Obr. 1.6 znázorňuje sezónny efekt izolovaný od ostatných vplyvov.
Tu len pre ilustráciu otestujeme hypotézu, že koncentrácia CO2 na jar a v prvej polovici leta je v priemere významne vyššia ako po zvyšok roka, čiže ak \(\beta_2,\ldots,\beta_{12}\) predstavujú rozdiely CO2 v jednotlivých mesiacoch oproti januáru, potom H0: \((\beta_3+\ldots+\beta_7)/5 = (0+\beta_2+\beta_8+\ldots\beta_{12})/7\). Prakticky to znamená vypočítať testovaciu štatistiku \[
TS = \frac{\mathbf{c}'\boldsymbol\beta}{\sqrt{\mathbf{c}'\boldsymbol\Sigma_\beta\mathbf{c}}}
\] kde \(\mathbf{c}=(0,-1/7,1/5,1/5,1/5,1/5,1/5,-1/7,-1/7,-1/7,-1/7,-1/7)'\), a porovnať s 95% kvantilom Studentovho t-rozdelenia so stupňami voľnosti rezíduí.
V našom prípade je zamietnutie H0 jednoznačné, priemerná koncentrácia vo svojom širšom vrchole je výrazne vyššia než v ostatnom období.
Príklad (CO2) demonštruje dôležitosť kontroly predpokladov pre spoľahlivosť štatistickej inferencie a načrtáva niektoré riešenia situácie, keď predpoklady zvolených modelov nie sú splnené a chýbajúcu informáciu nedokážeme doplniť inak (napr. z exogénnych náhodných premenných) než z deterministickej časovej premennej alebo z predošlých pozorovaní. V nasledujúcej podkapitole nás čaká ukážka súborov časovo zoradených pozorovaní (časových radov), ktorých črty sa v praxi vyskytujú pomerne často. Sú podobné ako koncentrácia CO2, ale každý sa v niečom líši. V ďalších podkapitolách je potom predstavený teoretický rámec analýzy časových radov a metódy ich modelovania.
1.2 Praktické ukážky časových radov
Dôležitosť analýzy časových radov dokumentujú aplikácie v odlišných vedeckých oblastiach, napr.
v ekonómii sme nepretržite vystavení denným cenovým kurzom na burze či mesačnej miere nezamestnanosti,
sociálne vedy skúmajú populačné ukazovatele ako pôrodnosť alebo zápisy do škôl,
epidemiológovia sa zaujímajú o vývoj počtu nakazených pozorovanom v nejakom období,
v medicíne pravidelný záznam krvného tlaku môže pomôcť vo vyhodnotení účinnosti liekov na vysoký krvný tlak,
časové záznamy mozgových vĺn nástrojmi magnetickej rezonancie poslúžia v skúmaní reakcií mozgu na stimuláciu za rôznych podmienok daných experimentom.
Prvým krokom každej analýzy časového radu by malo byť starostlivé preskúmanie zaznamenaných údajov pomocou grafického znázornenia (s časovou premennou na horizontálnej osi), ktoré nás často navedie na voľbu vhodnej metódy, ako informáciu v dátach analyzovať a štatisticky zosumarizovať.
Skúmanie časových radov rozličnej povahy vyvoláva rozličné otázky. Hoci sa tu všetky nedajú obsiahnuť, môžeme si aspoň niektoré priblížiť na príkladoch.
TipPríklad (globálne oteplovanie)
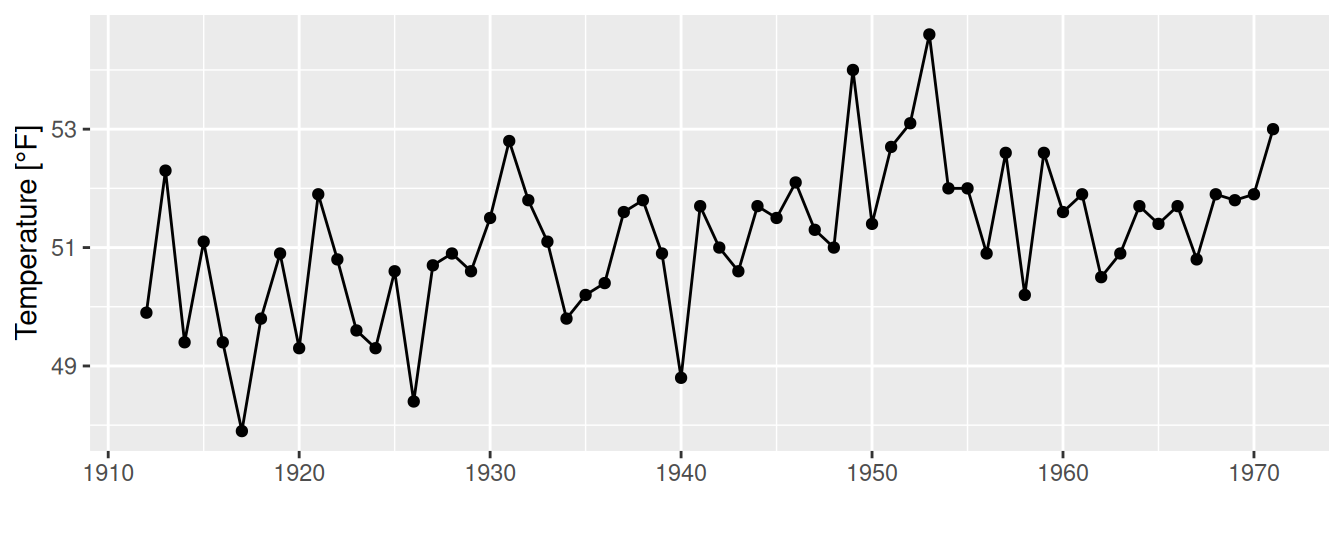
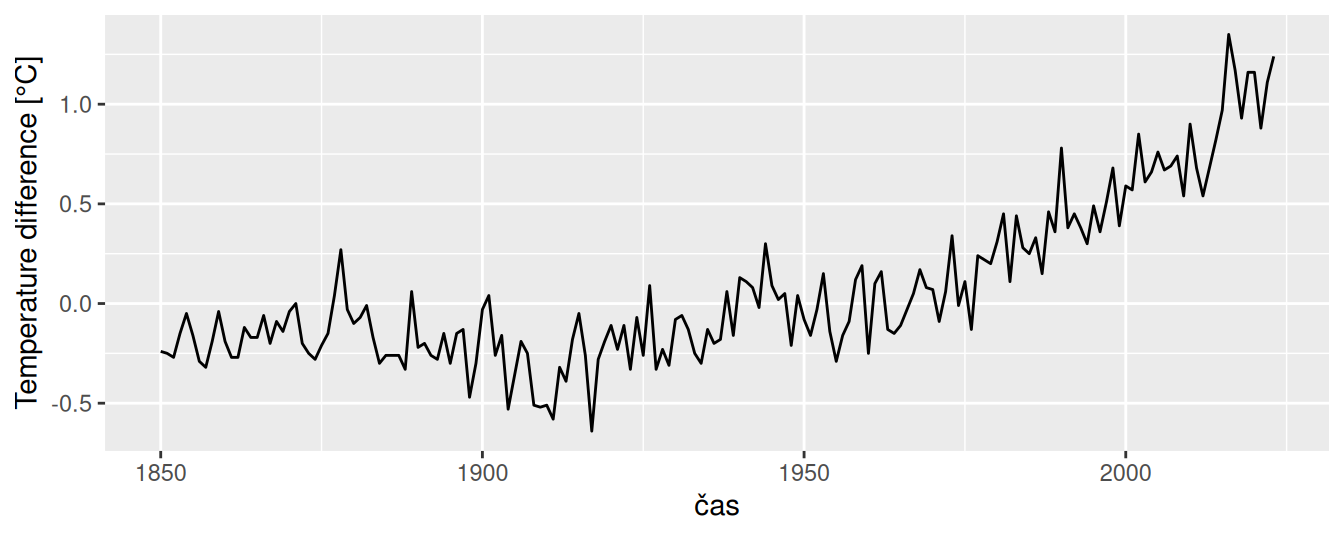
Obr. 1.7 (a) znázorňuje časový vývoj priemerných ročných teplôt zaznamenávaných v období rokov 1912 až 1971 v meste New Haven v USA v stupňoch Fahrenheita. Najprv si treba dať pozor na fyzikálne jednotky a zvážiť ich transformáciu do mierky, ktorá je typická pre náš región (stupne Celzia). Ďalej si môžeme všimnúť pozvoľný nárast v úrovni teploty (trend), no nemôžeme z neho spoľahlivo usudzovať o globálnom otepľovaní, pretože jednak ide o lokálne záznamy, jednak je na to 60-ročné obdobie pomerne krátke.
Značne inú informáciu poskytne časový rad globálneho indexu teploty (na súši a v oceánoch) na Obr. 1.7 (b) počítaného ročne v období od 1880 do 2015, čo je prakticky odchýlka od priemeru za obdobie 1951-1980, udávaná v stotinách stupňa Celzia. V druhej polovici je zjavný pozitívny trend, ktorý bol použitý ako argument v prospech hypotézy o globálnom otepľovaní. Otázky vyvoláva dočasné zvýšenie nárastu okolo roku 1940 a hlavne strmý nárast po 1970 (rast rozdielov znamená zrýchlenie). Je celkový trend prirodzený, alebo spôsobený ľudskou činnosťou?
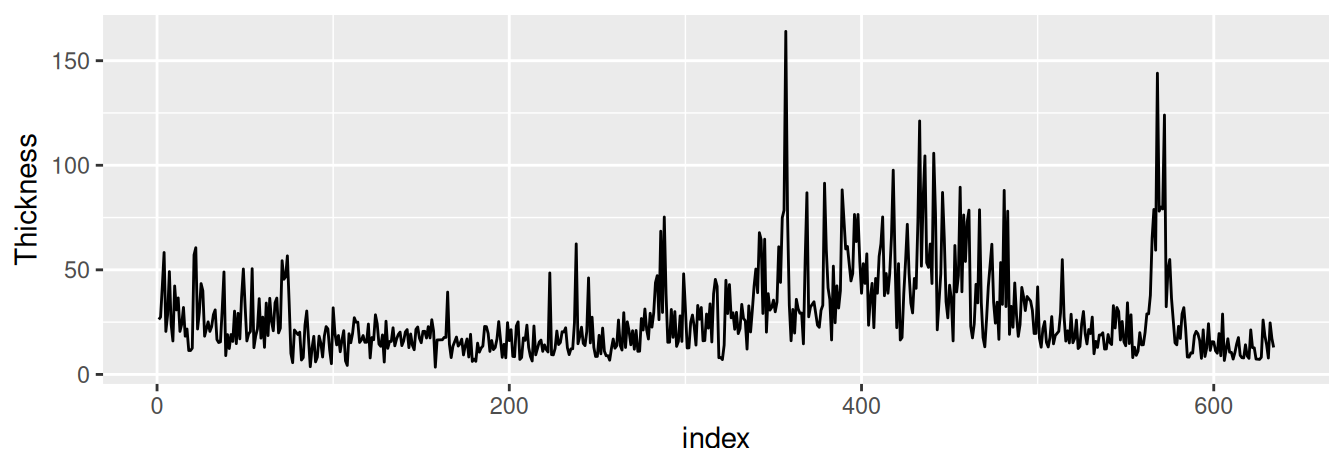
Ak sa na to chceme pozrieť ešte z väčšieho odstupu, priame merania teploty už nebudú k dispozícii, no pomerne spoľahlivým indikátorom vývoja globálnej teploty môže byť hrúbka nánosov piesku a prachu odkrytých v ľadovci (ktorá s teplotou rastie) zobrazená na Obr. 1.8. Vrstvy boli hromadené počas 634 rokov pred približne 12000 rokmi. Zdá sa, že podobné zmeny teploty v priebehu storočí neboli nezvyčajné, zdanlivý trend tak môže byť súčasťou cyklu. Otázka však teraz je, do akej miery je za súčasnú zmenu zodpovedný človek.
Kód
nhtemp |> broom::tidy() |>ggplot() +aes(x = index, y = value) +geom_line() +geom_point() +labs(x ="", y ="Temperature [°F]")astsa::gtemp_both |> broom::tidy() |>ggplot() +aes(x = index, y = value) +geom_line() +labs(x ="čas", y ="Temperature difference [°C]")
(a) Absolútne hodnoty teploty v lokalite New Haven
(b) Teplotné odchýlky od priemeru na globálnej úrovni
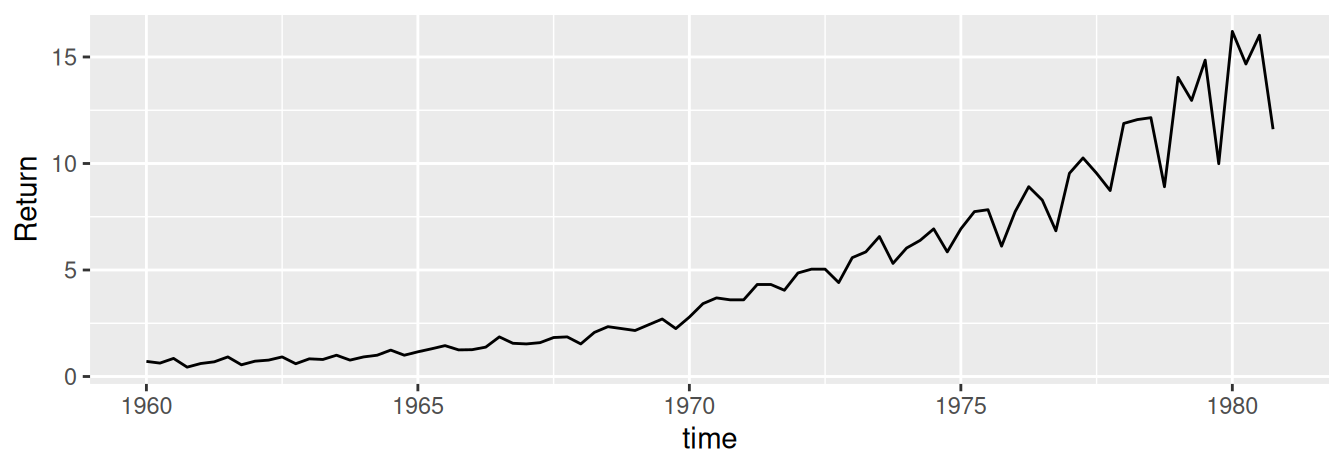
Štvrťročné výnosy (angl. returns) na akciu americkej spoločnosti Johnson and Johnson za obdobie 21 rokov (84 pozorovaní) na Obr. 1.9 odhaľujú postupne narastajúci trend (zrýchľujúci rast) a pravidelné výkyvy (fluktuácie), ktorých magnitúda sa medziročne zväčšuje spolu so strednou hodnotou.
Kód
JohnsonJohnson |> broom::tidy() |>ggplot() +aes(x = index, y = value) +geom_line() +labs(x ="time", y ="Return")
Obrázok 1.9: Štvrťročné výnosy na akciu spoločnosti Johnson and Johnson
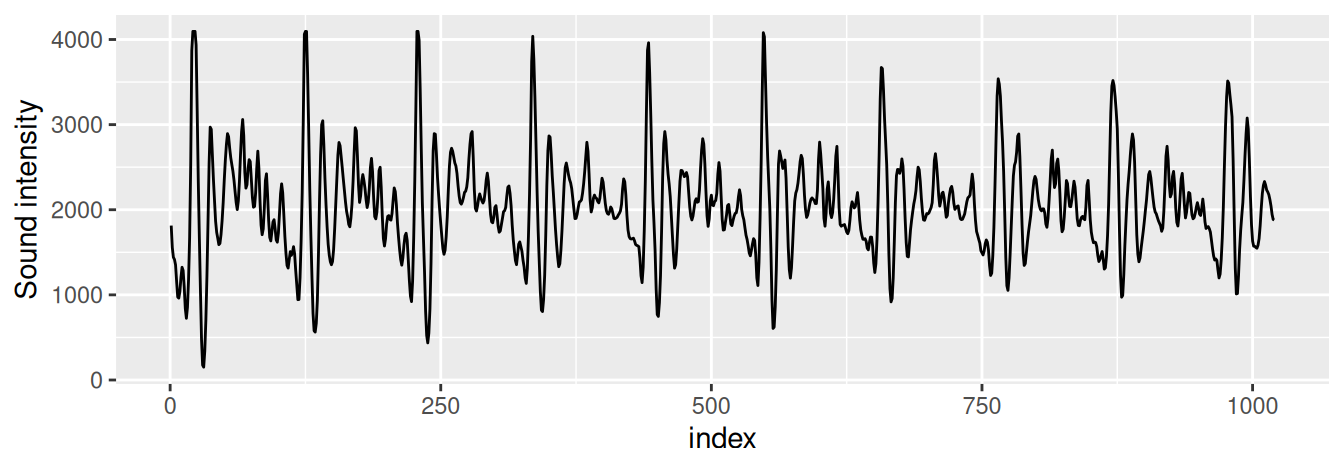
TipPríklad (hlasový záznam)
Hlasový záznam (aaahhh) dĺžky 0.1s v 1020 časových bodoch na Obr. 1.10 ukazuje pravidelnú periodickú povahu signálu pri rozochvení hlasiviek. Analýza takých záznamov je potrebná v projektoch pre automatické rozpoznávanie reči. Spektrálnou analýzou sa vytvorí odtlačok hlásky a porovnáva sa s odtlačkami z databázy.
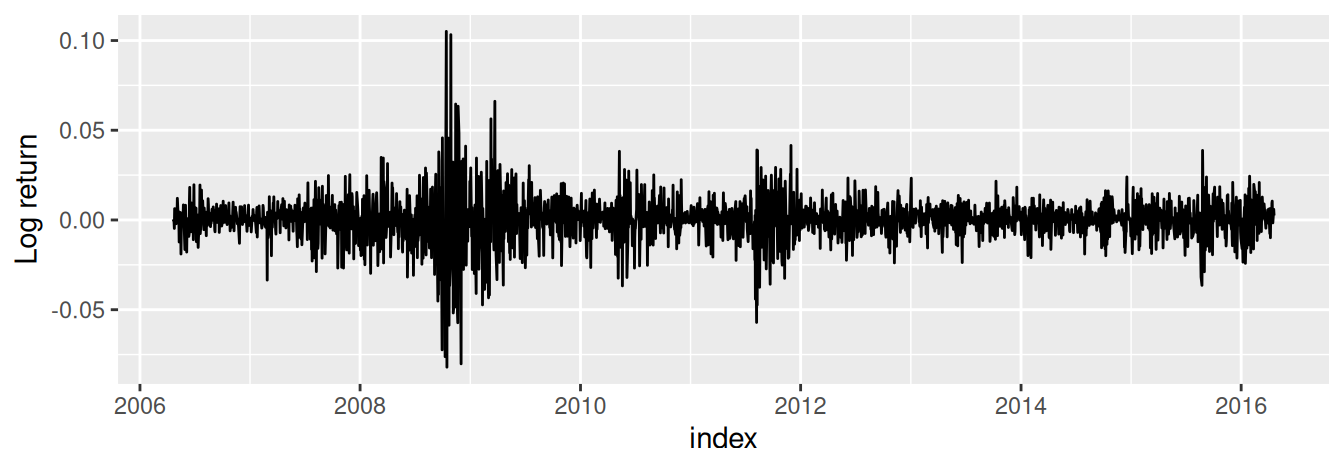
Finančný časový rad denných výnosov (percentuálnej zmeny) Dow Jonesovho priemyselného indexu od 20.4.2006 do 20.4.2016 na Obr. 1.11 je príkladom radu s nepravidelným časovým krokom (záznamy sú iba z pracovných dní), stredná hodnota je typicky ustálená okolo nuly a obdobia vysokej volatility (premenlivosti) tvoria zhluky, najväčší z nich ukazuje na finančnú krízu z roku 2008. Cielom analýzy takýchto radov spočíva práve v predvídaní budúcej volatility, napr. pomocou modelov GARCH, čo však už presahuje záber tohoto kurzu.
Azda i z uvedených príkladov vyplýva, že hlavnou úlohou analýzy časových radov je
pochopiť mechanizmus, ktorý generuje pozorované údaje. Konkrétne to znamená nájsť (vytvoriť) dobrý model a vedieť ho interpretovať. Často však býva cieľom aj (alebo len)
predpovedať budúce hodnoty.
Aby sme dokázali naplniť ciele analýzy, je potrebné uchopiť pojem časového radu formálne.
Časový rad tvoria hodnoty, ktoré sú pozorované a zaznamenávané postupne v čase, t.j. sú chronologicky usporiadané. Interval medzi jednotlivými pozorovaniami pritom nemusí byť rovnaký. Nepravidelné č.r. (irregular) môžu vyžadovať špeciálne metódy analýzy, my budeme predpokladať konštantný časový interval medzi jednotlivými pozorovaniami (napr. hodina, deň,…). Časový rad teda tvorí množina pozorovaní \(\{y_1, y_2, ..., y_n\}\) a budeme ďalej predpokladať \(y_t\in \mathbb{R}\), \(t=1,\ldots,n\). Celkový počet hodnôt \(n\) nazývame dĺžka časového radu.
Aby sme časový rad zasadili do teoretického rámca matematickej štatistiky, predpokladáme, že jeho generujúci mechanizmus je náhodný, a že časový rad \(\{y_1, y_2, ..., y_n\}\) je jedna realizácia stochastického procesu \(\{Y_1, Y_2, ..., Y_n\}\), kde každá \(Y_t\) je náhodná premenná so svojím rozdelením pravdepodobnosti a \(y_t\) je jedna hodnota tejto náhodnej premennej.
Formálne je stochastický proces definovaný ako v čase usporiadaný rad náhodných premenných \(\{Y(s,t)| s\in \mathcal{S}, t\in \mathcal{T}\}\), kde \(\mathcal{S}\) je výberový priestor a \(\mathcal{T}\) je indexový rad. Pre každé \(t\in \mathcal{T}\) je \(Y(\cdot,t)\) náhodná premenná definovaná na výberovom priestore \(\mathcal{S}\). Pre každé \(s\in \mathcal{S}\) je \(Y(s, \cdot)\) realizácia stochastického procesu definovaná na indexovom rade \(\mathcal{T}\), t.j. usporiadaný rad čísiel, z ktorých každé zodpovedá jednej hodnote indexového radu. V ďalšom budeme predpokladať, že \(\mathcal{T}\in \{0, \pm 1, \pm 2, ...\}\), t.j. stochastický proces nie je spojitý.
Hoci pre jednoduchosť pracujeme s nespojitými procesmi, diskrétny časový rad sa bežne zobrazuje grafom, v ktorom sú susedné hodnoty pospájané čiarou, aby sa tak aspoň vizuálne rekonštruoval hypotetický spojitý proces. Napokon, aproximácia spojitého procesu diskrétnym radom je mnoho krát daná konkrétnou metódou zberu údajov (vzorkovacie limity) či cieľom analýzy (voľba mierky a rozsahu). Aj analytické postupy vyžadujú diskrétne hodnoty, aby boli vôbec uskutočniteľné na počítačoch, ktoré sú obmedzené na digitálne výpočty.
V záujme jednoduchosti zápisu, tak ako je bežné aj v literatúre o analýze časových radov, už ďalej v texte nebudeme rozlišovať medzi náhodnou premennou a jej realizáciou, a aj stochastický proces označíme iba ako \(\{y_t\}_{t\in \mathcal{T}}\). Veríme, že konkrétny význam bude vždy zrejmý z kontextu.
1.3.1 Charakteristiky stochastického procesu
Zásadná vizuálna charakteristika odlišujúca jednotlivé zobrazené časové rady (napr. tie ilustračné v úvode kapitoly) je ich stupeň “plynulosti” (alebo hladkosti). Jedno možné vysvetlenie existencie tejto plynulosti je to, že hodnota v čase \(t\), čiže \(y_t\), nejako závisí od minulých hodnôt \(y_{t-1}\), \(y_{t-2}\), \(\ldots\). Tento model správania vyjadruje základný smer úvahy, ako generovať realisticky vyzerajúce časové rady, čo si ukážeme v kapitole o modeloch reziduálnej zložky.
Ako je v štatistike bežné pri náhodnom vektore, tak aj tu: úplný popis správania sa časového radu vyžaduje určenie združeného rozdelenia náhodných premenných, zatiaľčo úspornejší popis si vystačí s prvými a druhými momentami (stredná hodnota, variancia, kovariancia) a to ako funkciami času.
Združené rozdelenie je najčastejšie reprezentované združenou distribučnou funkciou \(F\), ktorá je definovaná ako pravdepodobnosť súčasného neprekročenia určitých konštantých hodnôt \(c_1, \ldots, c_n\), teda \[
F(c_1, \ldots, c_n) = \Pr(y_1\leq c_1, \ldots, y_n\leq c_n)
\] Naneštastie, tá sa nedá vyjadriť práve najjednoduchšie, iba ak by šlo o dobre známe, normálne rozdelenie. I tak je však manipulácia so združeným rozdelením nepraktická. Naštastie sa dá rozložiť na jednorozmerné marginálne rozdelenia – zastúpené distribučnou funkciou \(F_t(y) = \Pr(y_t\leq y)\) – a na normované združené rozdelenie, zastúpené tzv. kopulou\(C\colon [0,1]^n\to[0,1]\), ktorá reprezentuje výhradne vzťah medzi náhodnými premennými, takže \[
F(c_1, \ldots, c_n) = C(F_1(c_1), \ldots, F_n(c_n)).
\] Marginálne, t.j. okrajové rozdelenie pravdepodobnosti je zodpovedné za osobité chovanie náhodnej premennej, teda bez ohľadu na jej vzťah ku ostatným premenným. Pripomeňme, že okrem distribučnej funkcie je marginálne rozdelenie jednoznačne definované aj hustotou \(f_t(y) = \frac{\partial F_t(y)}{\partial y}\). Pomocou hustoty je definovaný operátor strednej (očakávanej, “expected”) hodnoty \(E(y_t)=\int_{-\infty}^{\infty} y f_t(y)dy\).
Stochastický proces môžeme opísať pomocou jeho charakteristík:
stredná hodnota (prvý začiatočný moment) \(\mu_t=E(y_t)\)
Autokovariancia vyjadruje mieru lineárnej závislosti, to znamená, že nulová autokovariancia nemusí znamenať úplnú nezávislosť (iba ak by združené rozdelenie oboch premenných bolo dvojrozmerné normálne). Veľmi hladké časové rady vykazujú autokovarianciu, ktorá je vysoká aj medzi navzájom vzdialenými časovými bodmi, zatiaľčo premenlivým radom s narastajúcim časovým odstupom autokovariancia klesá k nule. Je jasné, že \(\gamma_{t,t} = \sigma_t^2\). Z uvedených charakteristík jedine autokorelácia má určitý nárok zastupovať závislostnú štruktúru (kopulu \(C\)), no v plnej miere to platí iba ak \(F\) reprezentuje združené normálne rozdelenie.
1.3.2 Stacionarita
Špeciálnym prípadom stochastických procesov sú stacionárne stochastické procesy. Rozlišujeme striktnú a slabú stacionaritu.
Stochastický proces sa nazýva striktne stacionárny, ak pre akúkoľvek konečnú indexovú časť \(\{t_1, t_2, ..., t_n\}\in \mathcal{T}\) a ľubovoľné \(k\in \mathbb{R}\), pričom aj \(t_i+k\in \mathbb{R}\), \(i=1,2,...n\), platí \[
Pr(y_{t_1}\leq c_1,\dots,y_{t_n}\leq c_n) = Pr(y_{t_1+k}\leq c_1,\dots,y_{t_n+k}\leq c_n).
\] To znamená, že pravdepodobnostné chovanie daného stochastického procesu je invariantné v čase.
Pretože silná stacionarita sa v praxi veľmi ťažko overuje, nahrádza sa slabou (kovariančnou) stacionaritou. Vtedy pre stochastický proces platí, že
stredná hodnota je konštantná, \(\mu_t = \mu\), \(\forall t\in \mathcal{T}\),
rozptyl sa nemení, \(\sigma_t^2 = \sigma^2\), \(\forall t\in \mathcal{T}\) (táto vlastnosť sa nazýva aj homoskedasticita),
kovariancia \(\gamma_{t,t+k}\) je len funkciou posunutia\(k\) (angl. lag), nezávisí od absolútnej polohy \(t\) na časovej osi.
Preto v prípade stacionárnych stochastických procesov má zmysel zaviesť označenie \(\gamma(k)=cov(y_t,y_{t-k})\) pre tzv. autokovariančnú funkciu (a analogicky i pre autokorelačnú funkciu).
Zjavne platí, že silná stacionarita implikuje slabú, no naopak to platí iba v prípade normálneho rozdelenia.
Stacionárne stochastické procesy (a časové rady) môžeme charakterizovať pomocou výberových momentov:
výberový priemer (odhad strednej hodnoty \(\mu\)) \(\hat{\mu}=\frac 1n\sum_{t=1}^n y_t\)
výberová autokovariančná2 funkcia \(\hat\gamma(k)=\frac 1n\sum_{t=k+1}^n (y_t-\hat{\mu})(y_{t-k}-\hat{\mu})\)
výberová autokorelačná funkcia \(\hat\rho(k) = \frac{\hat\gamma(k)}{\hat\gamma(0)}\)
Stacionárny stochastický proces sa nazýva centrovaný, ak \(\mu=0\). Každý stacionárny stochastický proces \(\{y_t\}_{\forall t}\) môžeme transformáciou \(y_t=(y_t-\mu)\) upraviť na centrovaný \(\{y_t\}_{\forall t}\).
Autokovariančná a autokorelačná funkcia (ACF) stacionárneho stochastického procesu majú nasledujúce vlastnosti:
\(\rho(0)=1\)
\(|\gamma(k)|\leq\gamma(0)\), preto aj \(|\rho(k)|\leq1\)
\(\gamma(k)=\gamma(-k)\), čiže \(\rho(k)=\rho(-k)\) pre všetky \(k\), funkcie sú teda symetrické okolo \(k=0\). Preto býva ACF vyjadrovaná len pre \(k>0\).
Graf autokorelačnej funkcie sa nazýva korelogram.
1.3.3 Proces bieleho šumu
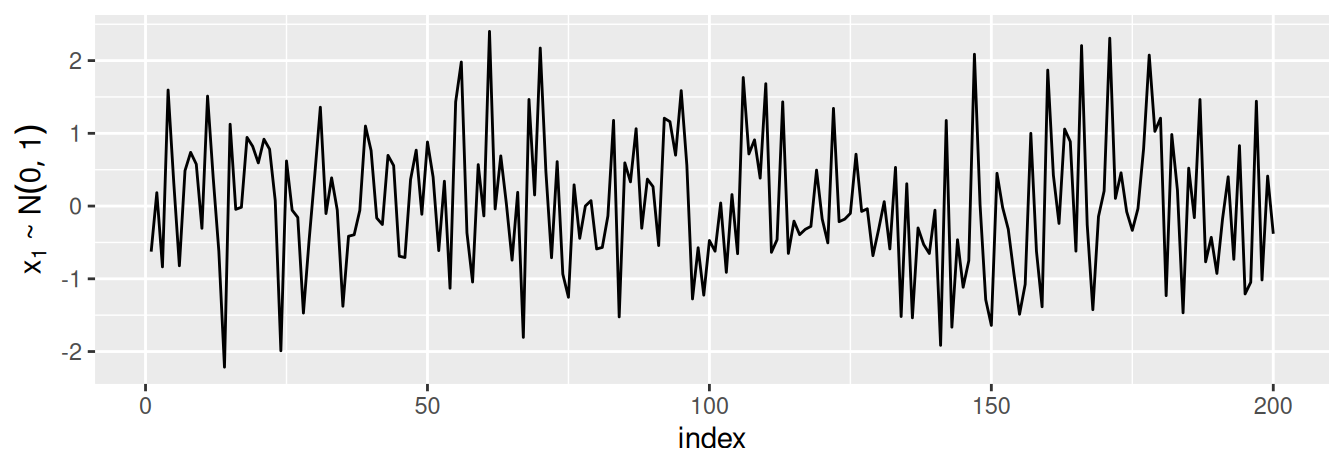
Náhodný proces \(\{\varepsilon_t\}_t\in\mathcal{T}\) tvorený nekorelovanými náhodnými premennými rovnakého pravdepodobnostného rozdelenia s konštantnou strednou hodnotou \(E(\varepsilon_t)=\mu\) (obyčajne nulovou), konštantným rozptylom \(var(\varepsilon_t)=\sigma^2\) a \(\gamma(k)=0\), \(\forall k\neq0\), nazývame proces bieleho šumu (white noise). Z tejto definície vyplýva, že proces bieleho šumu je stacionárny s \(\rho(0)=1\) a \(\rho(k)=0\), \(\forall k\neq0\).
Kód
set.seed(1)data.frame(index =1:200, value =rnorm(200)) |>ggplot() +aes(x = index, y = value) +geom_line() +labs(y =expression(paste(x[1], " ~ ",N(0,1))))
Obrázok 1.12: Jedna realizácia procesu gaussovského bieleho šumu, \(y_i\sim N(0,1)\).
Graf bieleho šumu ako na Obr. 1.12 môže pripomínať niektoré pozorované časové rady, ale nie je dosť plynulý na to, aby slúžil ako ich model. Ten však z bieleho šumu môže vychádzať. Keby sa stochastické správanie všetkých časových radov dalo vyjadriť pomocou modelu bieleho šumu, stačili by nám klasické štatistické metódy. Kĺzavé priemery a filtrovanie, či autoregresný model sú dve cesty, ako zaviesť sériovú koreláciu a väčšiu plynulosť do modelu časového radu. Budeme sa im neskôr venovať.
PoznámkaIlustrácia (autokorelácia)
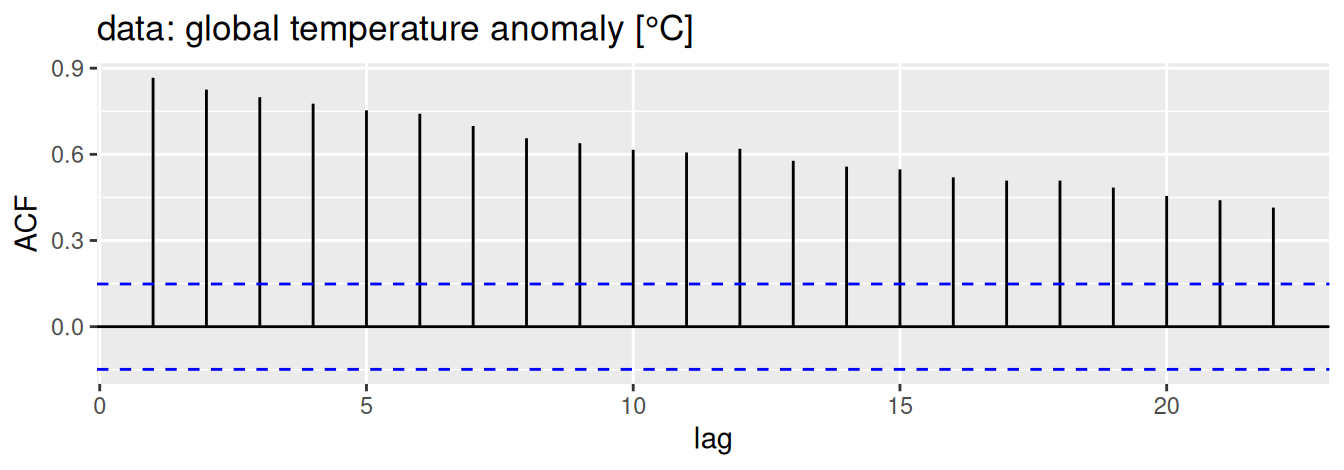
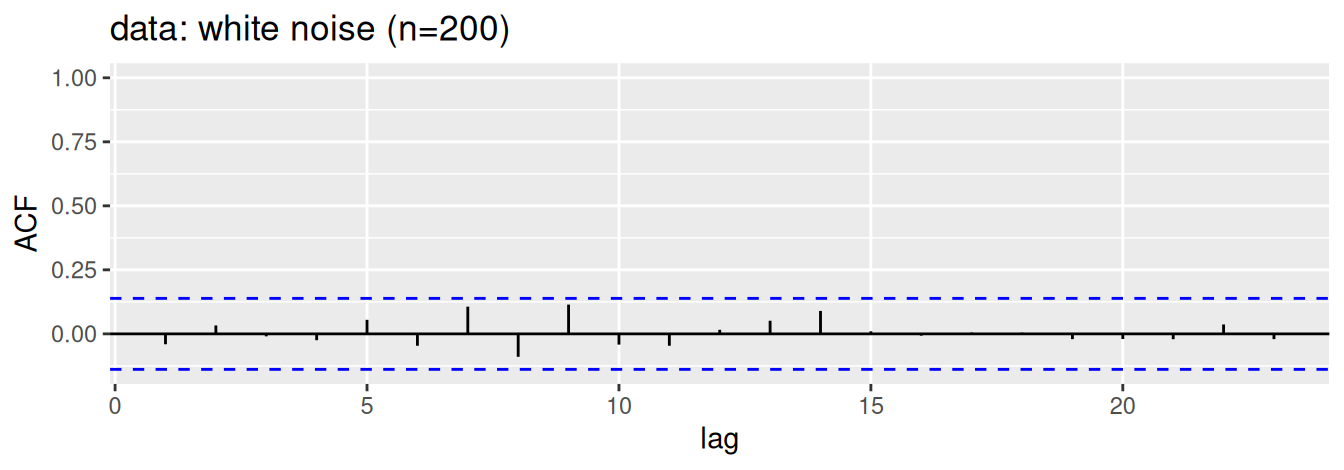
Pre porovnanie, na Obr. 1.13 je zobrazená autokorelačná funkcia (ACF) pre časový rad (a) teplotných odchýlok z prvého príkladu na Obr. 1.7 (b) a (b) bieleho šumu. V korelograme nestacionárneho časového radu vidieť vysoké hodnoty ACF ktoré iba pozvoľna klesajú k nule, zatiaľčo autokorelácie bieleho šumu sú všetky blízke nule (prirodzene okrem \(\hat\rho(0)=1\)).
Kód
astsa::gtemp_both |>acf(plot =FALSE) |> forecast::autoplot() +# feasts::autoplot does not work here (surprisingly)labs(x ="lag", title ="data: global temperature anomaly [°C]")set.seed(1)rnorm(200) |>acf(plot =FALSE) |> feasts::autoplot() +labs(x ="lag", title ="data: white noise (n=200)") +expand_limits(y =1)
(a)
(b)
Obrázok 1.13: Príklady autokorelačnej funkcie.
Pás s čiarkovanými hranicami na grafe autokorelačnej funkcie nám pomáha určiť, ako blízko musia byť hodnoty výberovej ACF k nule, aby sme časový rad mohli považovať za biely šum. Vychádza z aproximácie asymptotického rozdelenia odhadu ACF bieleho šumu s nulovou strednou hodnotou pre ľubovoľný posun, \[
\hat\rho(k)\sim N\left(0,\sqrt\frac1n\right)
\] Ak teda chceme na hladine významnosti \(\alpha\) rozhodnúť o hypotéze H0: \(\rho(k)=0\) pre zvolený posun \(k\), porovnáme hodnotu testovacej štatistiky \(\hat\rho(k)\) s kritickou hodnotou \(\sqrt{\frac1n}z_{1-\frac\alpha2}\), kde \(z_p\) je \(p\)-kvantil normovaného normálneho rozdelenia3. Hladina významnosti sa najčastejšie volí \(\alpha=5\%\), potom pre kvantil \(z_{1-\frac\alpha2}\) platí \(z_{0.975}=1.96\approx2\).
1.4 Modelovanie
Pochopenie mechanizmu, ktorý generoval časový rad, je ako rozpletať príbehy ukryté v dátach, ktoré sa menia v čase. Vhodným formálnym nosičom týchto príbehov je štatistický model. V ňom môže byť vyjadrený vzťah aktuálnej hodnoty stochastického procesu ku
náhodným a deterministickým premenným, konkrétne
minulým a súčasným hodnotám
vlastného (endogénneho) alebo cudzích (exogénnych) procesov,
pozorovateľných alebo nepozorovateľných procesov,
stochastického procesu i deterministického indexu.
1.4.1 Triedenie
Existuje množstvo prístupov ku modelovaniu časových radov, metódy môžu byť kategorizované na
- parametrické a neparametrické,
- lineárne a nelineárne,
- v časovej a frekvenčnej oblasti,
- tradičné štatistické a metódy strojového/hbokého učenia,
- jedno a viacrozmerné,
- popisné, predikčné, kauzálne a špeciálne (napr. na detekciu anomálií).
Ich voľba v praxi závisí od povahy časového radu, ktorý obsahuje
takmer vždy šum,
pomerne často
trend,
sezónnosť,
občas
dlho a krátko-periodické cykly, ktoré nesúvisia so sezónnosťou,
náhle zmeny v strednej hodnote dôsledkom izolovaných udalostí – dočasné alebo trvalé,
štrukturálne zmeny v parametroch modelu, napr. trendu, sezónnosti, alebo zmeny dĺžky a aplitúdy cyklov, kolísanie volatility
kalendárne efekty – premenlivý počet dní v mesiaci, víkendy, sviatky,
autokorelácia s dlhou alebo krátkou pamäťou,
nelineárna dynamika – zmeny režimov vplyvom prekročenia prahu alebo v dôsledku nepozorovateľných procesov, asymetria vo vývoji.
Metódy modelovania možno zaradiť do nasledujúcich skupín, v praxi sa veľmi často kombinujú, preto je medzi viacerými ťažké definovať hranice:
dekompozícia – cieľom je rozložiť časový rad na interpretovateľné zložky (trend, sezónnosť, … a rezíduá),
regresná analýza – globálne i lokálne, eventuélne s exogénnymi premennými,
exponenciálne vyhladzovanie – budúcnosť je najviac podobná nedávnej minulosti,
state-space – modelovanie nepozorovateľného procesu na základe jeho zašumeného obrazu,
strojové učenie a hlboké učenie – samoučiacia čierna skrinka,
viacrežimové modely.
1.4.2 Zameranie učebnice
Táto učebnica nemá ambíciu venovať sa všetkým spomenutým metódam či prístupom.
A. V prvej časti sa zameriame na tradičné, lineárne jednorozmerné štatistické metódy. V praxi sú – pre svoju jednoduchosť, interpretovateľnosť a pomerne dobré predpovedné schopnosti – stále veľmi často používané:
dekompozícia – primárne aditívny rozklad na systematické zložky (stacionarizácia v strednej hodnote) a reziduálnu zložku – a modelovanie zložiek,
integrovaný proces – stacionarizácia v strednej hodnote je dosiahnutá diferenciami, modelovanie je dynamické (iba pomocou minulých hodnôt odozvy a šumu),
exponenciálne vyhladzovanie – vážený priemer minulých hodnôt odozvy, pričom trend a sezónnosť sa chápu ako skryté procesy a sú vyhladzované súbežne.
B. V druhej časti zacielime na nelinearitu v časových radoch,
jednak tých stacionárnych prostredníctvom štatistických viacrežimových modelov,
ale aj modelovaním nestacionárnych časových radov pomocou univerzálnej metódy strojového učenia – doprednej umelej neurónovej siete.
1.4.3 Postup
Postup výstavby modelu pre väčšinu nestacionárnych časových radov spočíva v nasledujúcich krokoch:
rozdelenie časového radu na trénovaciu a validačnú časť – v pomere prvých približne 70%–80% ku posledným 30%–20% pozorovaniam;
zhodnotenie povahy časového radu z grafu - identifikácia nestacionarity a zložiek;
stacionarizácia v rozptyle – ak rozptyl rastie so strednou hodnotou, potom vhodnou transformáciou sa zväčša dá stabilizovať a tak výrazne zjednodušiť matematické vyjadrenie podmienenej strednej hodnoty;
stacionarizácia v strednej hodnote modelom systematických zložiek (dekompozícia), diferenciami (integrované procesy) alebo voľbou adaptívnej metódy;
detekcia a modelovanie autokorelácie v reziduálnej zložke – zobrazenie autokorelačnej funkcie, identifikácia lineárneho procesu a odhad parametrov;
vyhodnotenie predpovednej schopnosti oproti základnému modelu alebo iným alternatívam.
1.4.4 Stacionarizácia v rozptyle transformáciou
Na izolovanie variability, ktorá sa mení so strednou hodnotou, sa používa trieda mocninových transformácií, z ktorej najznámejšia podtrieda je Box-Cox transformácia.
Dvojparametrická Box-Cox transformácia je definovaná vzťahom \[
g(x)=\begin{cases}
\frac{(x+c)^\lambda-1}\lambda & \text{pre } \lambda\neq0\\
\ln{(x+c)} & \text{pre } \lambda=0,
\end{cases}
\] kde \(x>-c\). Jej špeciálnymi prípadmi sú logaritmická (\(\lambda=0\)), odmocninová (\(\lambda=0.5\)), prevrátená (recipročná, \(\lambda=-1\)), a klasická mocninová (\(\lambda\in\mathbb{N}\)) transformácia.
Odhad parametrov (úroveň \(c\), exponent \(\lambda\)) je možný viacerými metódami, napr. maximálnej vierohodnosti alebo guerrerovou.
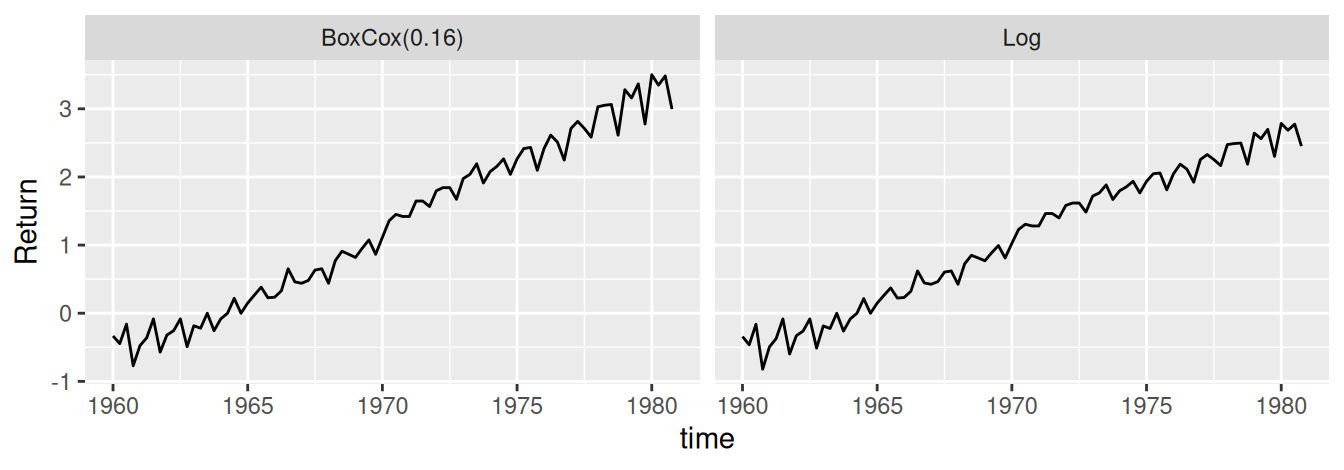
Obrázok nižšie ilustruje použitie Box-Coxovej transformácie štvrťročného časového radu výnosov z Obr. 1.9, najprv s odhadom parametra \(\hat\lambda=0.16\) (vľavo), potom so zvoleným parametrom \(\lambda = 0\) (vpravo).