Kód
dat <- fun <- fit <- list()
# kontajnery:
# dat - na súbory údajov, zväčša v tabuľkovej podobe
# fun - na všetky definované funkcie
# fit - na objekty odhadnutých modelovV tejto praktickej kapitole budú využívané iba základné nástroje systému R, teda výlučne bez použitia špecializovaného balíku forecast a systému balíkov tidyverts. Preto je potrebné na úvod definovať pomocné funkcie, ktoré neskôr uľahčia analýzu časových radov.
Aby prostredie objektov nebolo zahltené mnohými položkami, zavedieme tri základné kontajnery:
dat <- fun <- fit <- list()
# kontajnery:
# dat - na súbory údajov, zväčša v tabuľkovej podobe
# fun - na všetky definované funkcie
# fit - na objekty odhadnutých modelovSpektrálna hustota
# Spektrálna hustota konverziou autokovariancií alebo priamym odhadom z časového radu
# Argumenty:
# omega - vektor uhlových frekvencií,
# acov - vektor covariancií pre posuny k=1,...m
# data - numerický vektor dĺžky n (n>m) pre ktorý sa hľadá spektrum (ak nie je dané acov)
# Výstup: numerický vektor.
fun$SpecDens <- Vectorize(
FUN = function(omega, acov = NULL, data = NULL) {
if(is.null(acov)) {
if(is.null(data)) {
stop("Please provide either vector of autocovariance function values or time series data.")
}
else acov <- acf(data, lag.max=length(data), type="covariance", plot=FALSE)$acf[,,1]
}
k <- seq(to=length(acov)-1)
( acov[1] + 2*sum(acov[-1]*cos(k*omega)) ) / (2*pi)
},
vectorize.args = "omega"
)ACF a PACF
# Spojenie ACF a PACF do jedného grafu.
# Argumenty:
# x - numerický vektor, pre ktorý sa ACF počíta,
# lag.max - najvyššie posunutie
# Výstup: graf.
fun$AcfPacf <- function(x, lag.max = NULL) {
if (is.null(lag.max))
lag.max <- floor(10 * log10(length(x)))
acf(x, lag.max = lag.max, ylab="(P)ACF", main="", lwd=2)
parc <- pacf(x, lag.max = lag.max, plot=F)
points(parc$lag+0.2/4, parc$acf, col="red", type = "h", lwd=2)
legend("topright", legend=c("ACF","PACF"), col = c("black","red"), lty=c(1,1), lwd=2)
}Long AR
# Odhad parametrov ARMA pomocou Long AR metódy.
# Argumenty:
# x - numerický vektor časového radu,
# p,q - stupne ARMA,
# k - stupeň AR, z ktorého sa získa odhad rezíduí (šumu),
# z - vektor rezíduí (šumu). Ak nie je daný, bude odhadnutý z AR(k) modelu.
# Výstup: objekt triedy 'lm'.
fun$LongAR <- function(x, p, q, k, z = NULL) {
if(is.null(z))
z <- ar.ols(x, aic=F, order.max=k)$resid # získame rezíduá z AR
z[is.na(z)] <- 0 # nahradíme chýbajúce hodnoty zo začiatku
xzlag <- c(
lapply(0:p, function(i) stats::lag(x, -i)),
lapply(0:q, function(i) stats::lag(z, -i))
)
names(xzlag) <- c(paste0("x",0:p), paste0("z",0:q)) # oznacenie premennych
xzlag <- do.call(function(...) ts.intersect(..., dframe=T), xzlag) # urezanie prekrytu
lm(x0 ~ . - z0, xzlag, na.action=NULL, singular.ok=F, y=T)
# alebo pomocou externého balíku:
# library(dynlm)
# dynlm(x ~ L(x, 1:p) + L(z, 1:q))
# Výstupom oboch riešení je štandardný objekt lineárneho modelu triedy *lm*.
}Informačné kritériá
# Informačné kritériá pre 3 triedy modelov.
# Argumenty:
# model - objekt triedy 'ar', 'Arima' alebo 'lm',
# type - typ informačného kritéria.
# Výstup: hodnota AIC alebo BIC.
fun$InfCrit <- function(model, type = c("AIC","BIC")) {
if(class(model)=="ar") {
n <- model$n.used
sig2 <- model$var.pred
pq <- sum(model$order)
}
if(class(model)=="Arima") {
n <- model$nobs
sig2 <- model$sigma2
pq <- sum(model$arma[1:2])
}
if("lm" %in% class(model)) {
n <- length(model$residuals)
sig2 <- var(model$residuals)
pq <- sum(attr(model$terms,"order"))
}
switch(type[1],
AIC = log(sig2) + pq*2/n,
BIC = log(sig2) + pq*log(n)/n
)
}Hannan-Rissanenova procedúra
# Hannan-Rissanenova procedúra pre odhad moelu ARMA
# Argumenty:
# x - numerický vektor časového radu,
# pmax, qmax - hranice stupňov ARMA,
# kmax - strop pre určenie stupňa AR, z ktorého sa odhadnú rezíduá (šum),
# N_bestmodels - počet najlepších modelov, ktoré funkcia vráti ako objekty 'lm'.
# Výstup: zoznam s modelmi a vektorom BIC.
fun$HannanRissanen <- function(x, pmax, qmax, kmax, N_bestmodels=1) {
krange <- pmax:kmax; names(krange) <- krange # názvy sa zídu na identifikáciu ...
tmp <- sapply(krange, function(y) fun$InfCrit( ar(x, aic=F, order.max = y) ))
k <- as.numeric(names(sort(tmp)[1])) # ... rádu AR s najmenším AIC
resid <- ar(x, aic=F, order.max = k)$resid
models <- list() # sem budeme ukladať kandidátov
for(p in 0:pmax) {
for(q in 0:qmax) { # ARMA(0,0) pre kontrolu aj pre jednoduchosť programu
models[[paste(p,q,sep=",")]] <- fun$LongAR(x, p = p, q = q, z = resid)
}
}
#' výpočet BIC pre každý kandidátsky model
bic <- rbind(varBIC = sapply(models, function(x) fun$InfCrit(x, type="BIC")),
likBIC = sapply(models, function(x) BIC(x))
)
ord <- order(bic[1,]) # zoradenie podľa BIC
list(models = models[ord][1:N_bestmodels], # i keď modely tu nebudeme potrebovať
BIC=bic[,ord]
)
}Metóda funkcie fitted pre model triedy Arima
# Funkcia pre výpočet stedných hodnôt podľa modelu. Štandardná funkcia stats::fitted totiž nemá metódu pre model triedy 'arima'. Tú implementuje až balík forecast.
# Argument: model - objekt triedy 'Arima'.
# Výstup: numerický vektor.
fun$fitted.arima <- function(model) {
eval(model$call$x) - model$residuals
}Predpovedanie zo spoločného modelu systematických zložiek a náhodnej zložky:
# Výpočet jednokrokových alebo viackrokových bodových predpovedí.
# Argumenty:
# model - objekt triedy 'Arima'
# newxreg - matica plánu statickej časti modelu pre validačné obdobie
# valid - validačná vzorka (numerický vektor)
# n.ahead - max.horizont viackrokovej predpovede (ak nevyplýva z rozmeru newxreg)
# Výstup: numerický vektor.
fun$Forecast <- function(model, newxreg = NULL, valid = NULL, n.ahead = NULL) {
# myembed() rozširuje embed() o možnosť dimension=0, kedy vráti maticu s nulovým počtom stĺpcov
myembed <- function(x, dimension) embed(c(NA,x), dimension+1)[,-dimension-1, drop=F]
# ošetrenie prítomnosti systematickej zložky:
xreg <- eval(model$call$xreg)
if( !is.null(xreg) ) {
if(is.null(newxreg))
stop("Chýba 'newxreg'.")
if(ncol(xreg) != ncol(newxreg))
stop("'xreg' a 'newxreg' nemajú rovnaký počet stĺpcov")
if(nrow(newxreg) != length(valid) && !is.null(valid))
stop("'newxreg' a 'valid' nemajú rovnakú dĺžku (=počet predpovedí).")
isSyst <- TRUE
} else {
isSyst <- FALSE
}
nT <- model$nobs
obs <- c(eval(model$call$x), valid)
eps <- model$residuals |> c() # šumová zložka bude dopĺňaná
p <- model$arma[1]; q <- model$arma[2] # model$call$order
parARMA <- head(model$coef, (p+q))
# predpoveď systematickej (t.j. nestacionárnej) zložky:
if(isSyst) {
if(p+q==0) { # veľmi zriedkavý prípad
parSyst <- model$coef
} else {
parSyst <- tail(model$coef, -(p+q))
}
sysT <- xreg %*% parSyst |> c()
sysV <- newxreg %*% parSyst |> c() #|> ts() |> `tsp<-`(tsp(valid))
} else {
sysT <- 0
sysV <- NULL
}
# výpočet reziduálnej (t.j. stacionárnej) zložky:
if(is.null(valid)) {
res <- obs - sysT
} else {
res <- obs - c(sysT, sysV)
}
# predpovede reziduálnej zložky
pred <- res # budeme stavať nad trénovacou vzorkou (jej stac.časťou)
if(is.null(valid)) { # t.j. ak nie je daná validačná vzorka
# a) viackroková
if(is.null(n.ahead) && is.null(newxreg))
stop("Pri viackrokových predpovediach aspoň jedno z 'n.ahead' a 'newxreg' musí byť dané")
if(isSyst) {
if(is.null(n.ahead)) {
nP <- length(sysV) # ak n.ahead nie je dané
} else {
nP <- min(length(sysV), n.ahead) # ak je dané newregx aj n.ahead
}
} else {
nP <- n.ahead
}
for(t in nT+(1:nP)) {
pred[t] <- cbind(myembed(tail(pred,p), p), # AR časť modelu
myembed(tail(eps,q), q) # MA časť
) %*% parARMA |> c()
eps[t] <- 0
}
} else { # t.j. ak je argument 'valid' daný
# b) jednokroková
if(isSyst) {
nP <- min(length(sysV), length(valid)) # skrátenie dĺžky podľa dostupnosti vstupov
} else {
nP <- length(valid)
}
for(t in nT+(1:nP)) {
pred[t] <- cbind(res |> head(t-1) |> tail(p) |> myembed(p), # AR
# head-tail subsetting kvôli možnosti p=0
myembed(tail(eps,q), q) # MA
) %*% parARMA |> c()
eps[t] <- res[t] - pred[t]
}
}
# výsledná predpoveď je súčtom predpovedí reziduálnej a systematickej zložky:
tail(pred, nP) + if(is.null(sysV)) 0 else head(sysV,nP)
}Naivné predpovede:
# Výpočet bodových a intervalových naivných predpovedí.
# Argumenty:
# x - numerický vektor; trénovacia vzorka pre viackrokové, celý rad pre 1-krokové
# h - horizont predpovede,
# type - typ predpovede: viackroková (multi) alebo jednokroková (1-step)
# seasonal - indikátor sezónnej predpovede, FALSE znamená jednoduchú naivnú
# prob - pravdepodobnosť predpovedného intervalu
# period - sezónna perióda v jednotkách časového kroku, napr. 4, 12, 24, 52
# Výstup: data frame so strednou hodnotou, dolnou a hornou hranicou intervalu.
fun$Naive <- function(x, h, type = c("multi", "1-step"), seasonal = FALSE,
prob = 0.95, period = NULL) {
if(isTRUE(seasonal)) { # pri sezónne naivnej treba zistiť periódu
if(is.null(period)) period <- frequency(x)
} else { # pri jednoduchej naivnej je perióda akoby rovná 1
period <- 1
}
n <- length(x)
s2 <- x |> diff(lag = period) |> (`^`)(2) |> mean()
alpha <- 1-prob
r <- qnorm(1-alpha/2)*sqrt(s2*(1:h))
switch(type[1],
"multi" = data.frame(mean = rep(tail(x, period), length.out = h)) |>
transform(lo = mean - r,
up = mean + r
),
"1-step" = data.frame(mean = x |> tail(h+period) |> head(-period)) |>
transform(lo = mean - r[1],
up = mean + r[1]
)
)
}Stredné predpovedné chyby
# Stredné predpovedné chyby.
# Argument:
# x - dvojstĺpcová matica predpovedaných a pozorovaných hodnôt
# Výstup: numerický vektor.
fun$MeanForecastError <- function(x) { # x = cbind(predicted, real)
er <- x[,2] - x[,1] # predpovedné chyby
c(ME = mean(er), # stredná chyba (mean error)
MSE = mean(er^2), # stredná kvadratická
RMSE = sqrt(mean(er^2)), # odmocnina z MSE
MAE = mean(abs(er)), # stredná absolútna
MAPE = mean(abs(er/x[,2])) * 100, # absolútna percentuálna
sMAPE = mean(abs(er/(x[,1]+x[,2])*2)) * 100, # symetrická
MASE = mean(abs(er / mean(abs(diff(x[,2]))))) # škálovaná, nonseasonal
)
}Načítanie údajov:
dat$all <- "data/Poloha_denne.dat" |> # zdrojový súbor údajov
read.table(header=T, skip = 1) # načítanie, vynechaný riadok obsahuje popis
head(dat$all) deň poloha
1 1 0.0
2 2 -1.4
3 3 0.3
4 4 -0.2
5 5 1.1
6 6 0.5Dáta predstavujú denné pozorovania polohy v milimetroch pomocou GPS na permanentnej monitorovacej stanici po dobu 2 rokov. Konkrétne ide o severnú zložku topocentrického súradnicového systému s počiatkom v polohe z prvého dňa merania.
Vypočítame základnú číselnú charakteristiku časového radu, rozdelíme ho na trénovaciu a validačnú vzorku približne v pomere 80% ku 20% a zobrazíme:
# popisná štatistika
c("length","min","max","median","mean","sd") |>
sapply(function(x) eval(call(x, dat$all$poloha))) |>
round(2)length min max median mean sd
730.00 -4.70 32.40 14.30 13.97 8.81 # rozdelenie
n <- nrow(dat$all)
nT <- round(n * 0.80, -2)
nV <- n - nT
c(n = n, nT = nT, nV = nV) n nT nV
730 600 130 dat <- split(dat$all, dat$all$deň > nT) |> # rozdeľ do dvoch data.frame
setNames(c("train","valid")) |> # nastav názov
c(dat) # pripoj ku objektu dat
# zobrazenie
plot(poloha ~ deň, dat$all, type="n") # definuj vykreslovaciu oblasť ale nekresli
lines(poloha ~ deň, dat$train)
lines(poloha ~ deň, dat$valid, col = 2)
legend("bottomright", legend=c("trénovacia časť", "validačná časť"),
lty = 1, col = c(1,2))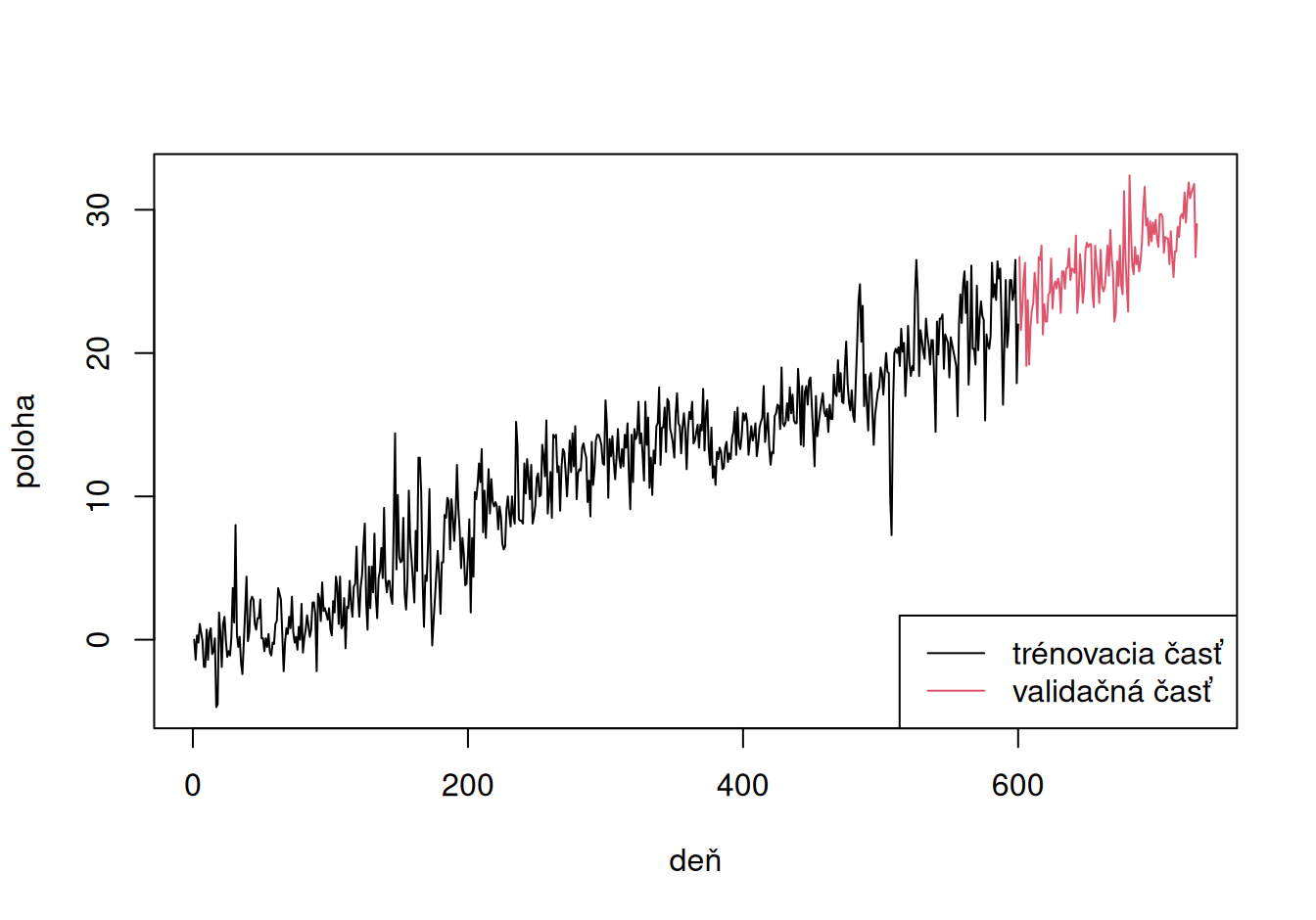
Na trénovacej vzorke identifikujeme a odhadneme modely jednotlivých zložiek stochastického procesu a pomocou validačnej posúdime presnosť predpovedí.
Na grafe trénovacej vzorky je vidieť výrazný lineárny trend, čo zodpovedá skúsenosti s dlhodobým pohybom eurázijskej litosférickej dosky. Okrem trendu sa zdá byť prítomná dlhoperiodická (sezónna) fluktuácia, tá však bude zjavnejšia po odstránení trendu. Nakoniec, veľmi výrazné sú krátkoperiodické fluktuácie, ktoré tvoria rezidálnu zložku.
Aby sme z časového radu odstránili trend, odhadneme jeho lineárny regresný model.
fit$TreLin <- lm(poloha ~ deň, dat$train)
fit$TreLin |> coef()(Intercept) deň
-0.55322148 0.03938898 Sklon trendovej priamky prezrádza pohyb bodu približne 0.04 mm/deň alebo 14.4 mm/rok smerom na sever (analyzujeme iba pohyb pozdĺž poludníkov, nie rovnobežiek).
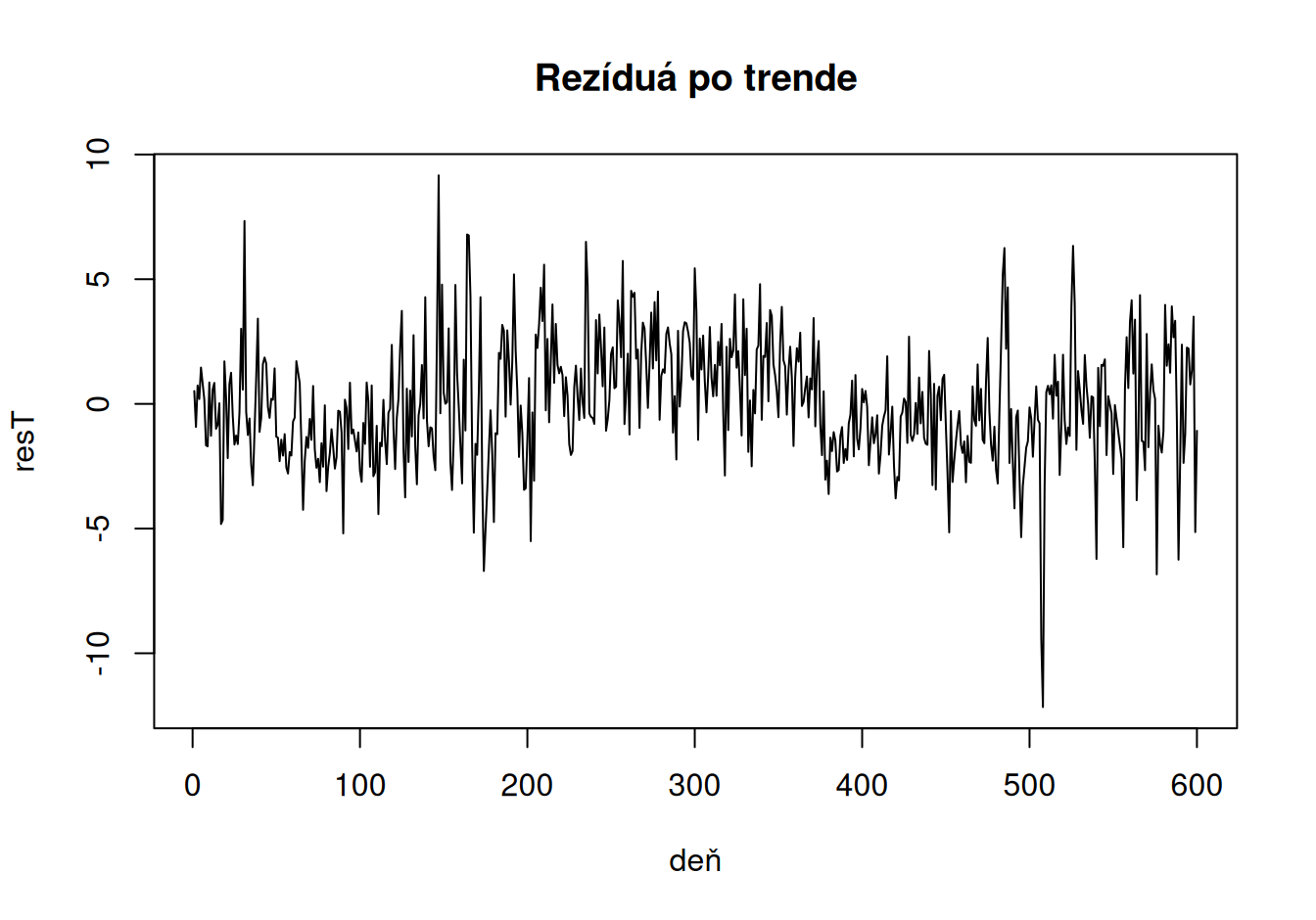
V tomto prípade nemá zmysel uvažovať iný typ trendovej funkcie, pretože zakrivenie badateľné z grafu pripisujeme sezonalite. Aby sme ju vyšetrili, vypočítame a uložíme odhadnuté hodnoty trendu a jeho rezíduá.
dat$train$TreLin <- fit$TreLin$fitted.values
dat$train$resT <- fit$TreLin$residuals
plot(poloha ~ deň, dat$train, main = "Trend", type = "l")
lines(TreLin ~ deň, dat$train, col = 4, lwd = 2)
plot(resT ~ deň, dat$train, main = "Rezíduá po trende", type = "l")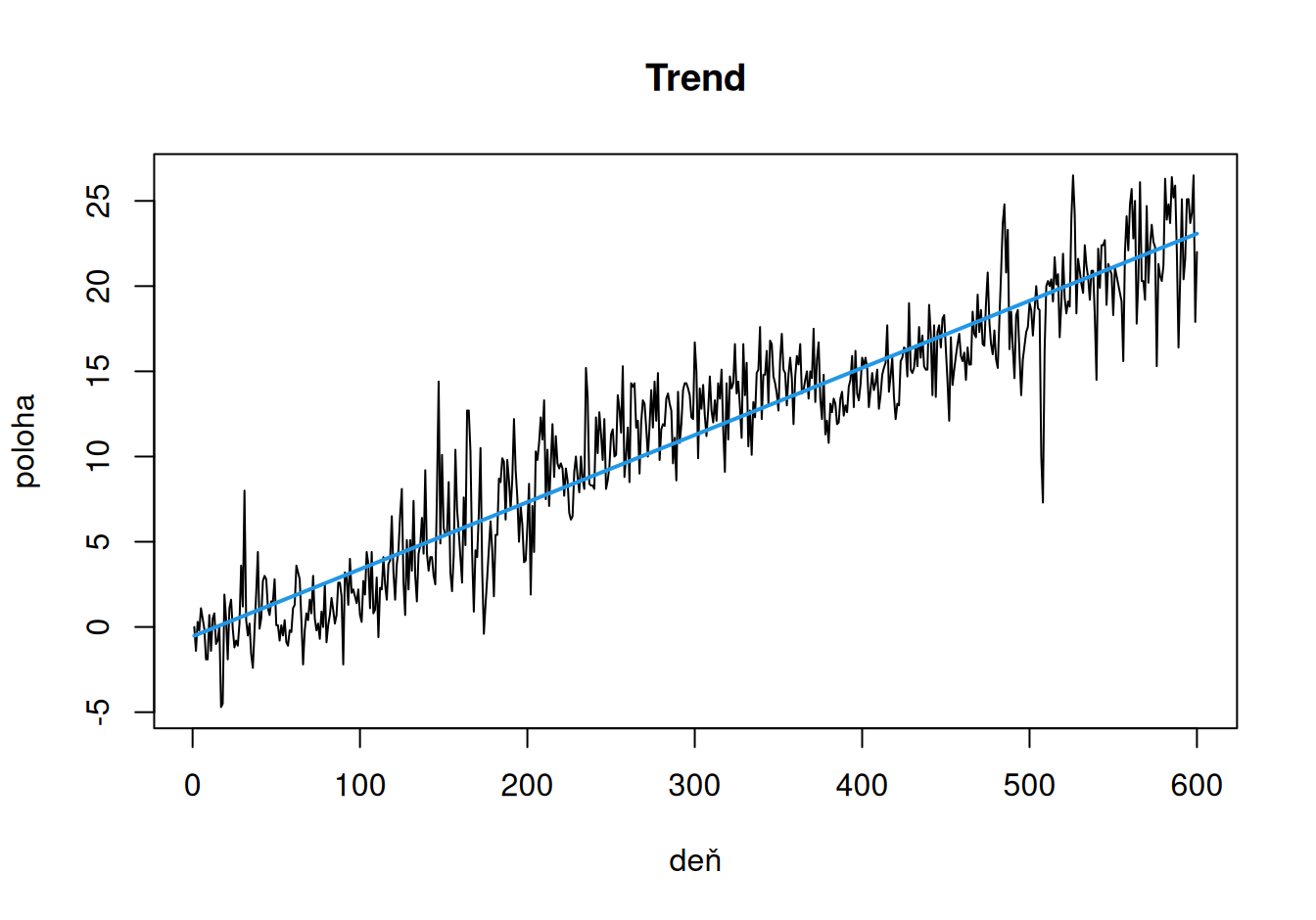
Autokorelačnou funkciou odhalíme periodicitu:
acf(dat$train$resT, lag.max = 400)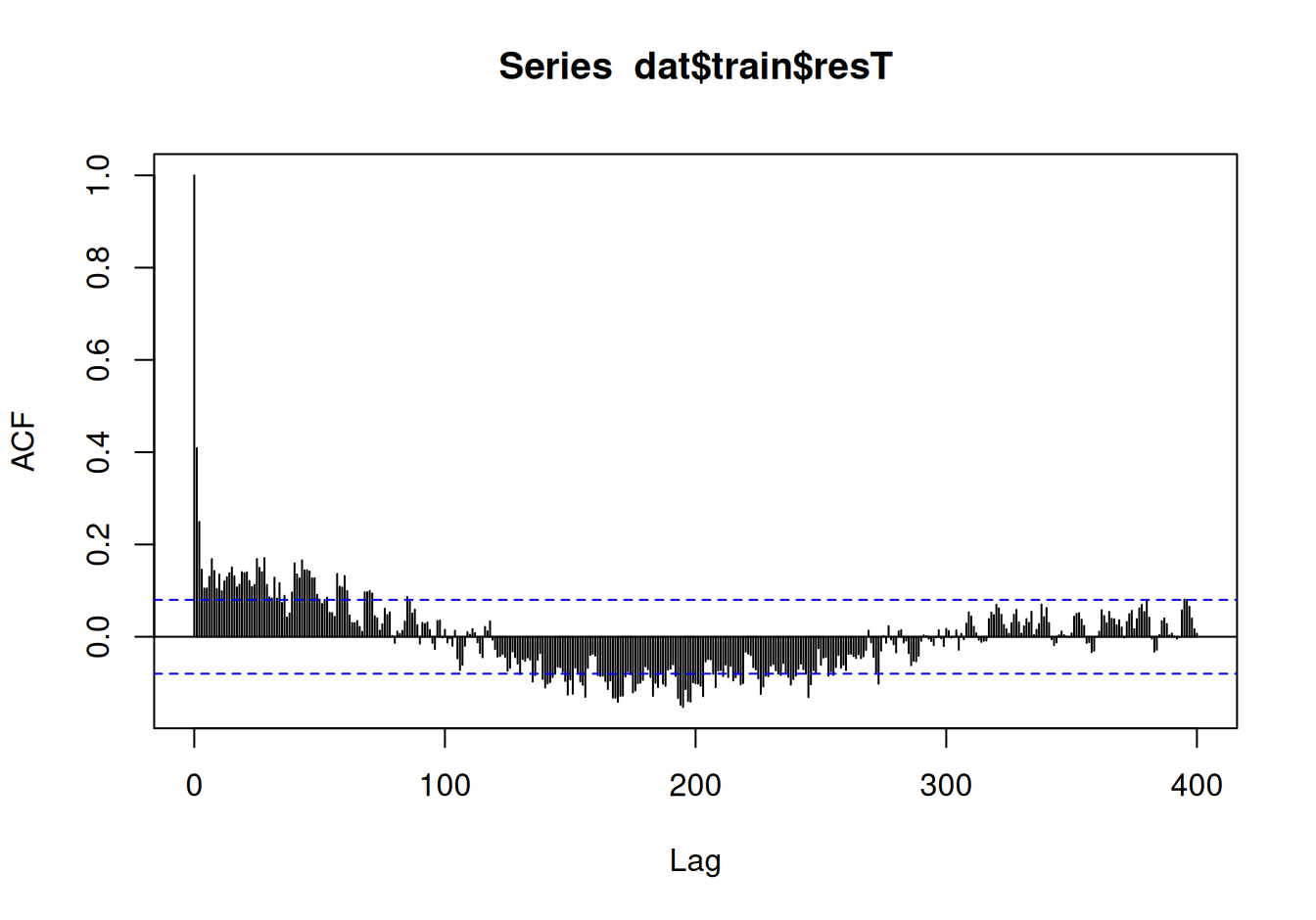
Hoci okolo posunu 365 dní nevidieť výrazné maximum, sezónnu periódu je badať vďaka minimu v jej polovici, teda okolo posunu 183 dní. Vzhľadom na veľkú periodu je rozumné zvoliť model používajúci trigonometrické funkcie.
# odhad modelu
fit$SeaCos <- lm(resT ~ cos(2*pi*deň/365) + sin(2*pi*deň/365), dat$train)
# výpočet amplitúdy z parametrov modelu
tmp <- fit$SeaCos |> coef() |> print() (Intercept) cos(2 * pi * deň/365) sin(2 * pi * deň/365)
0.2186103 0.1094559 -1.3465139 sqrt(tmp[2]^2 + tmp[3]^2) |> round(1) |> setNames("amplitúda")amplitúda
1.4 Poloha počas roka fluktuuje nanajvýš 1.4 mm okolo trendu.
dat$train$SeaCos <- fit$SeaCos$fitted.values
dat$train$resTS <- fit$SeaCos$residuals
plot(resT ~ deň, dat$train, main = "Sezónna zložka", type = "l")
lines(SeaCos ~ deň, dat$train, col = 4, lwd = 2)
plot(resTS ~ deň, dat$train, main = "Rezíduá po trende a sezónnej zložke", type = "l")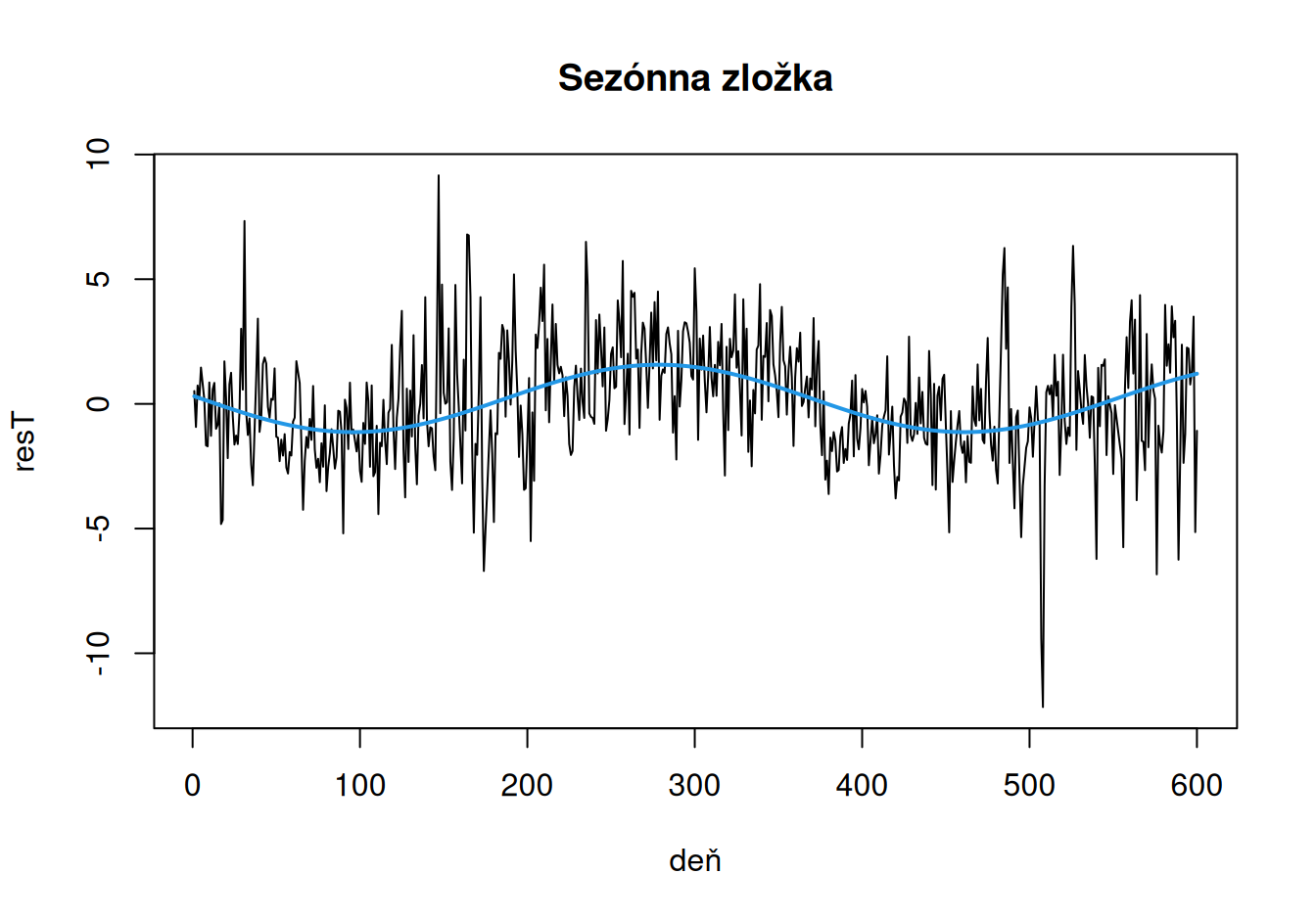
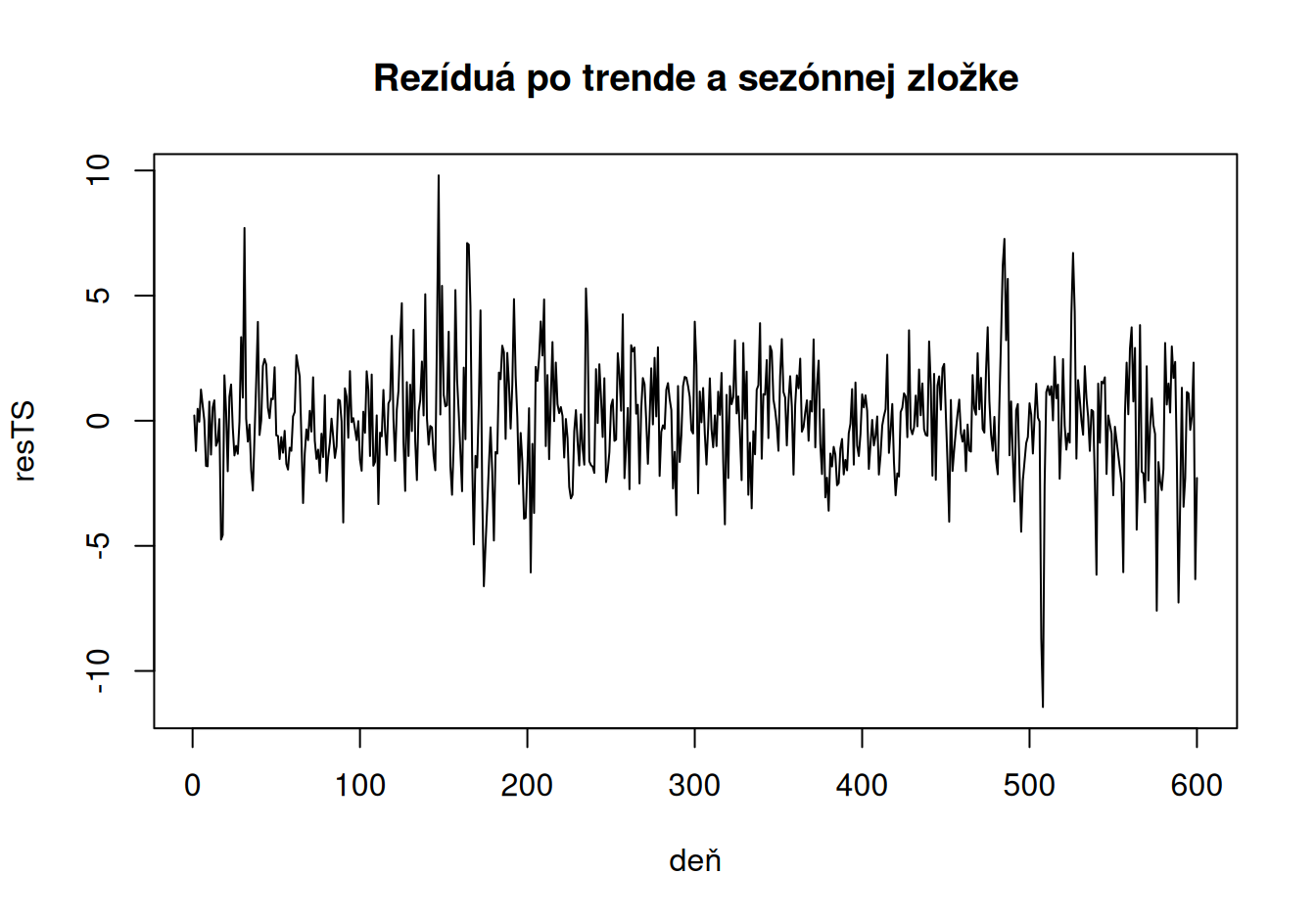
Zdá sa, že rezíduá po odstránení trendu a sezónnej zložky už neobsahujú systematické zložky, no pred formálnymi testami predsa ešte časový rad vyšetríme v spektrálnej oblasti na prítomnosť cyklickej zložky.
Transformáciu z časovej do spektrálnej domény zabezpečí diskrétna Fourierova transformácia, z ktorej určíme power spektrum a vhodne orezané ho vykreslíme ako periodogram. Posledný graf má x-ovú os znázornenú prehľadnejšie v logaritmickej mierke.
spec <- data.frame(fft = fft(dat$train$resTS)) # fast fourier transform
head(spec$fft) |> round(2)[1] 0.00+ 0.00i -60.29-31.23i -33.82+ 8.66i -68.47+ 6.17i 53.72-41.65i
[6] 26.35-33.26ispec$power <- abs(spec$fft)^2/(2*pi*nT) # spektrálna hustota (power spec)
spec$power |> head() |> round(2) [1] 0.00 1.22 0.32 1.25 1.23 0.48spec$omega <- 2*pi*seq(0, nT-1) / nT # fourierove frekvencie v intervale [0,2pi)plot(spec$power, xlab="j", ylab="spektrálna hustota", type="h")
spec <- spec |> head(floor(nT/2)) # kvôli symetrii stačí prvá polovica
plot(power ~ omega, spec, type="h", ylab="")
spec$period <- 2*pi / spec$omega # periódy
plot(power ~ period, spec, type="h", ylab="")
plot(power ~ period, spec, log="x", type="h", ylab="")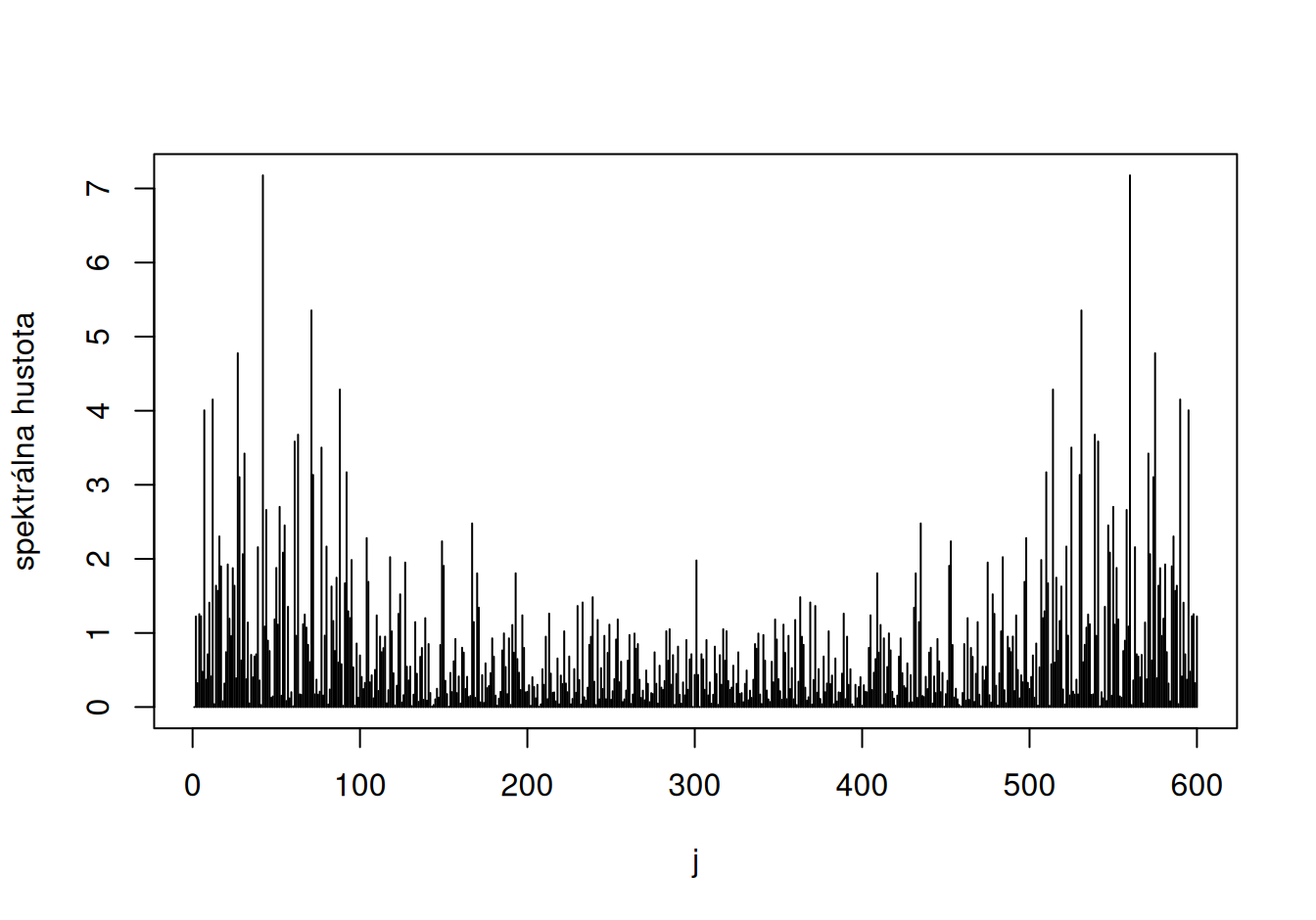
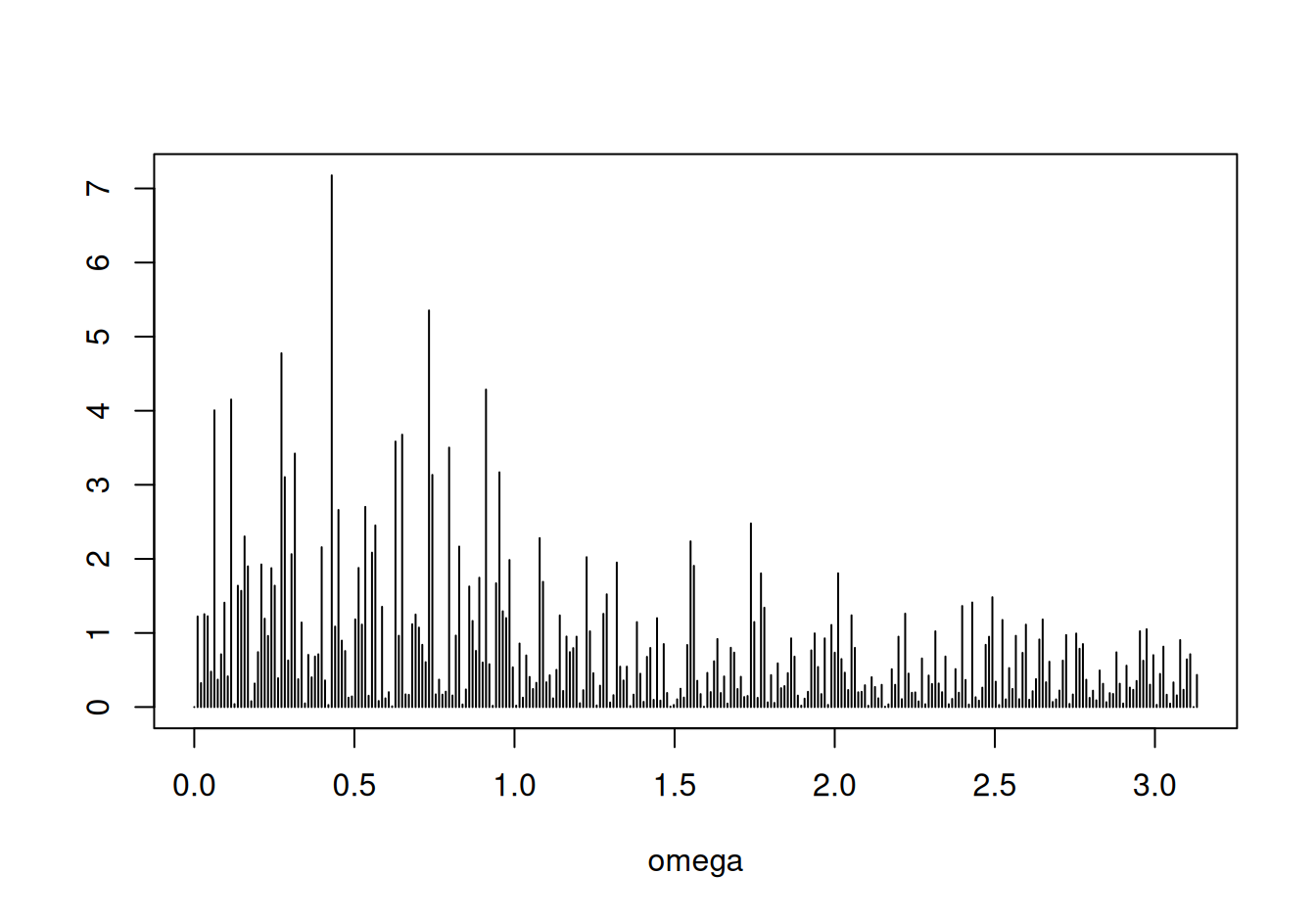
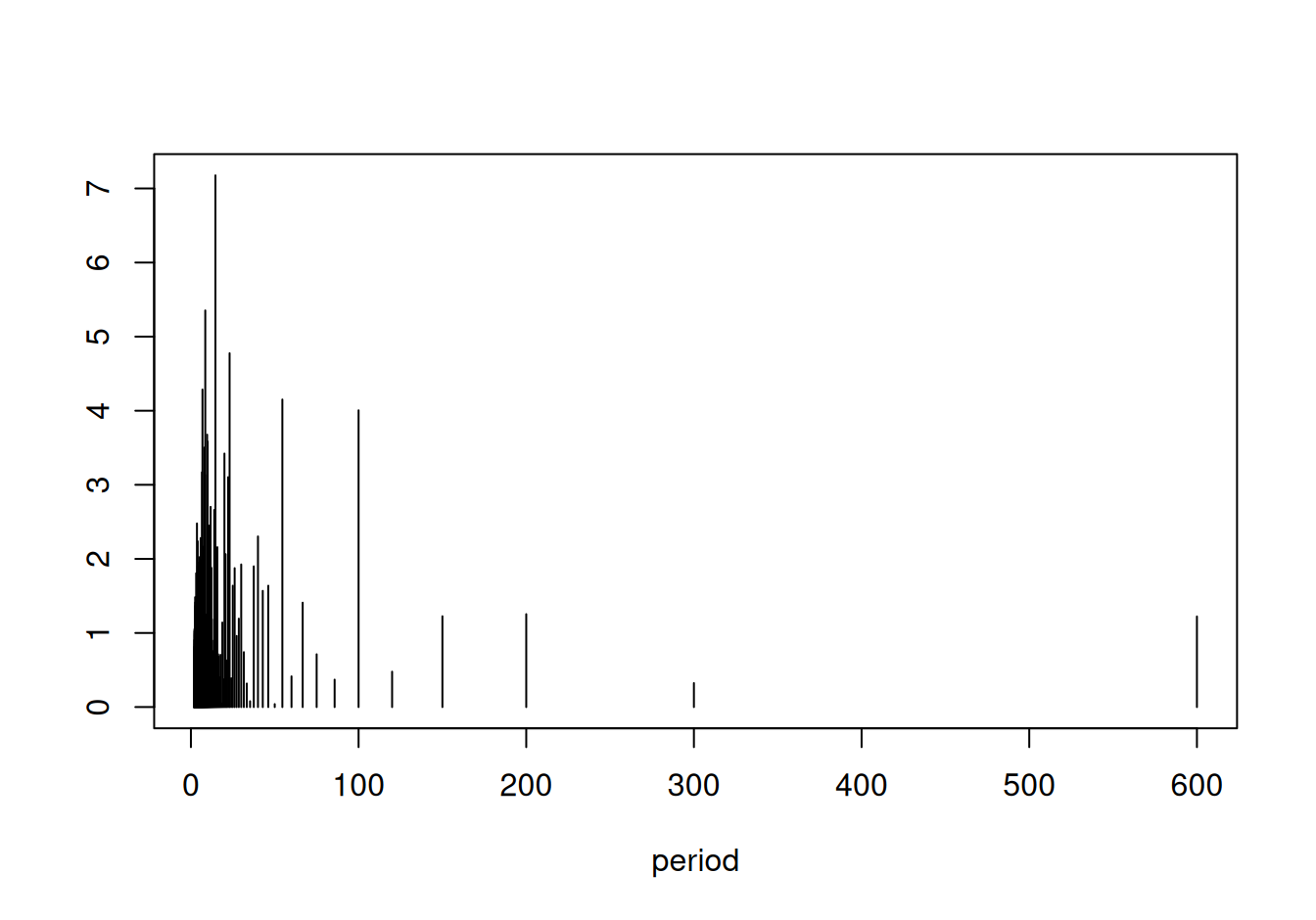
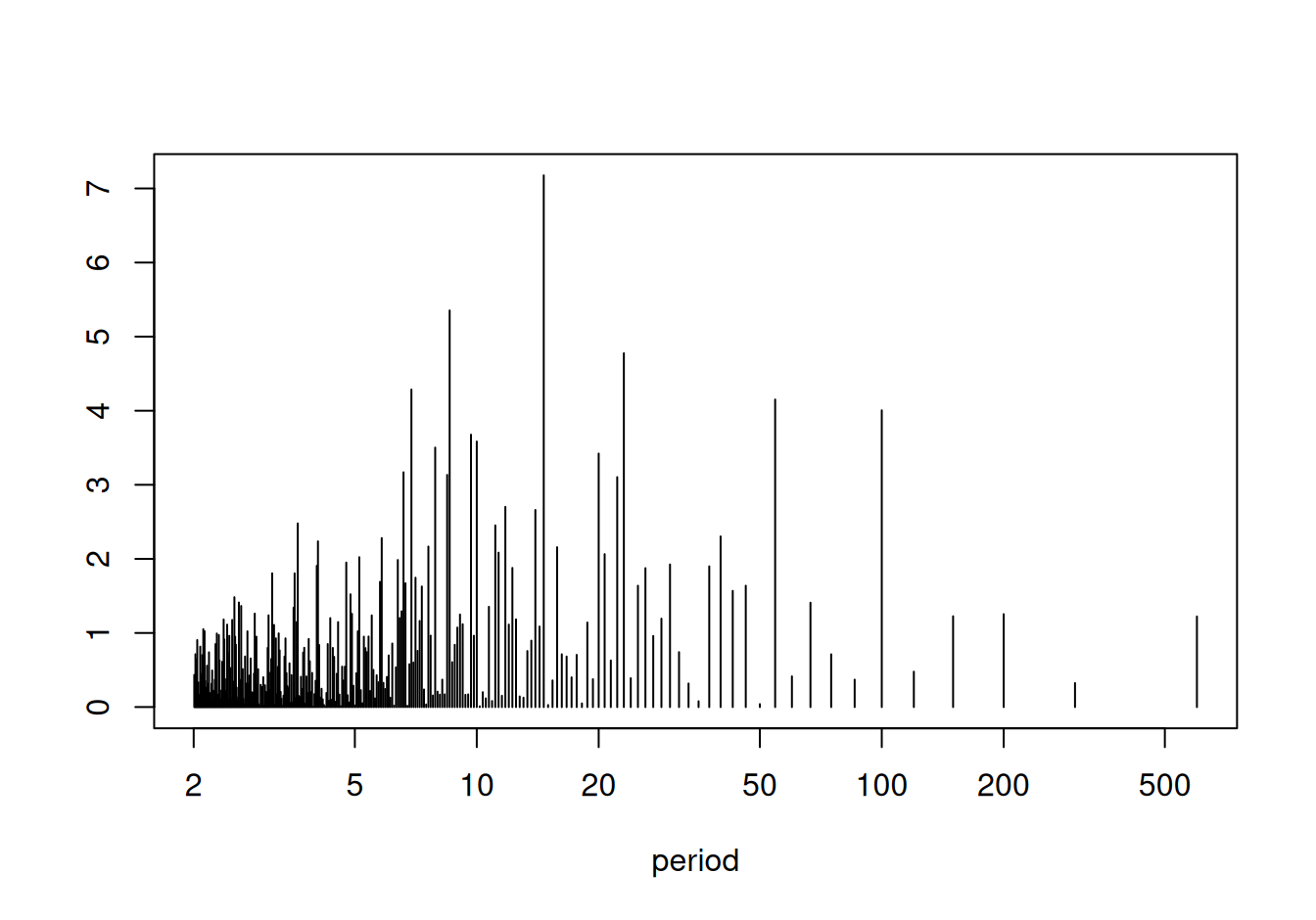
Vypíšeme frekvencie/periódy s najväčšou spektrálnou hustotou:
spec <- spec[order(spec$power, decreasing=T),] # zoradenie podľa veľkosti histoty
spec |> head() fft power omega period
42 113.69421-118.86577i 7.176680 0.42935100 14.634146
71 -38.11955-136.84970i 5.353161 0.73303829 8.571429
27 104.75353- 83.84730i 4.775623 0.27227136 23.076923
88 116.00616+ 51.94780i 4.285513 0.91106187 6.896552
12 -41.90120+117.86833i 4.150934 0.11519173 54.545455
7 -107.04184- 60.34409i 4.005231 0.06283185 100.000000Fisherovým testom zisíme, že najsilnejšia zložka s periódou 14.6dní je na hladine významnosti 5% štatisticky významná. Jej pôvod je však nejasný a subjektívne sa zdá byť málo výrazná, takže ju zanedbáme.
c(
perióda = spec$period[1],
test.štat = spec$power[1]/sum(spec$power),
krit.hod = 1 - (0.05/nrow(spec))^(1/(nrow(spec)-1))
) |> round(3) perióda test.štat krit.hod
14.634 0.030 0.029 Postupné modelovanie systematických zložiek je vhodné pre ich identifikáciu, nakoniec však treba odhadnúť ich spoločný model a vypočítať reziduálnu zložku.
fit$Syst <- lm(poloha ~ deň + cos(2*pi*deň/365) + sin(2*pi*deň/365), dat$train)
dat$train$resSyst <- fit$Syst$residualsAk je reziduálna zložka realizáciou bieleho šumu, môže sa použiť na vysvetlenie skúmaného procesu a/alebo predpovedanie budúcich hodnôt.
Náhodnosť rezíduí vyšetríme šiestimi testami:
Manuálny výpočet:
local({
U <- dat$train$resSyst # pre jednoduchosť zápisu
KH <- read.table("data/dw025d.htm", header = T, skip = 4) # kritické hodnoty
c(DW = sum(diff(U)^2)/sum(U^2),
d = with(KH, { # with() vytvori lokalne prostredie a pripoji KH
Tlev <- unique(T);
Tlev <- Tlev[which.min(abs(length(U)-unique(Tlev)))]; # zistenie T najbližšieho ku n
ind <- which(T==Tlev & K==4); # K=4 je počet parametrov modelu systematických zložiek
c(L=dL[ind], U=dU[ind], L4=4-dL[ind], U4=4-dU[ind])
})
)
}) DW d.L d.U d.L4 d.U4
1.378827 1.830270 1.850340 2.169730 2.149660 Testovacia štatistika DW je menšia ako dolná kritická oblasť, preto je dôvod zamietnuť H0, reziduá sú pravdepodobne autokorelované (v posune o jednu časovú jednotku). Záver potvrdzuje aj výsledok dosiahnutý pomocou funkcie z balíku car, keď \(p\)-hodnota je menšia ako 0.05:
car::durbinWatsonTest(fit$Syst) lag Autocorrelation D-W Statistic p-value
1 0.3098189 1.378827 0
Alternative hypothesis: rho != 0Zobrazíme ACF a vypíšeme posuny, pri ktorých prekračuje približný pás nulovosti:
which(abs(acf(dat$train$resSyst)$acf[-1]) > 2/sqrt(nT))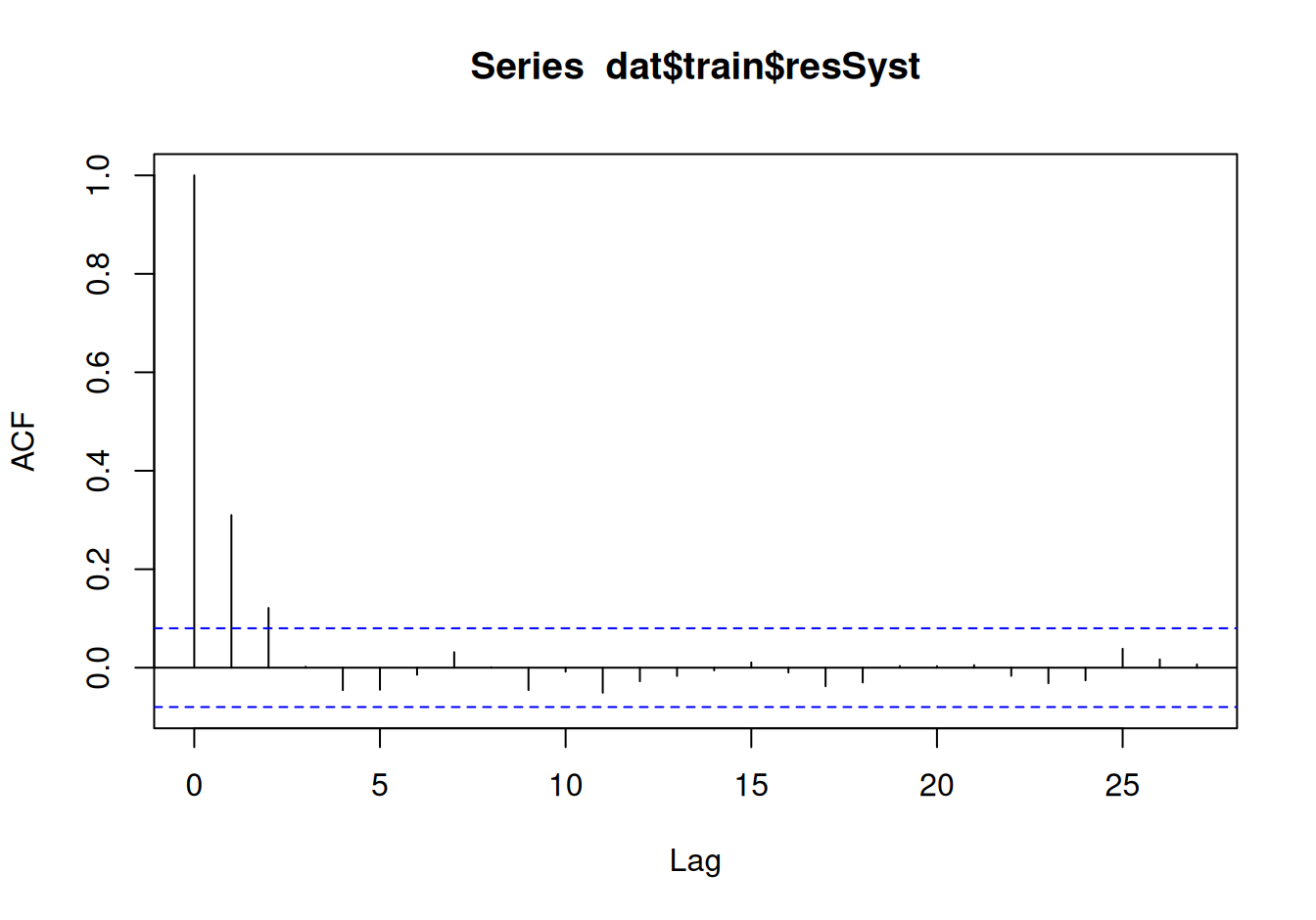
[1] 1 2Aj tento test naznačuje, že rezíduá sú autokorelované.
Test si všíma nezvyčajný počet (kladných) znamienok diferencií. Ak je ich málo, v časovom rade prevládajú poklesy, ak príliš veľa, tak prevládajú sekvencie s rastúcim trendom.
local({
U <- dat$train$resSyst # pre jednoduchosť zápisu
U <- U[c(T, !diff(U)==0)] # odstránenie po sebe idúcich duplicitných hodnôt
n_ <- length(U)
P <- sum(diff(U) > 0) # počet kladných znamienok
TStat <- (P - (n_-1)/2) / sqrt((n_+1)/12) # normovanie
c(TStat = TStat,
q = qnorm(c(L=0.025, H=0.975), mean=0, sd=1),
p.hodnota = pnorm(TStat)*2 # 2x pretože dvojstranný test
) |>
round(4)
}) TStat q.L q.H p.hodnota
-1.6250 -1.9600 1.9600 0.1042 Výsledok manuálnych výpočtov je v zhode so vstavanou funkciou balíku randtest.
randtests::difference.sign.test(dat$train$resSyst)
Difference Sign Test
data: dat$train$resSyst
statistic = -1.625, n = 600, p-value = 0.1042
alternative hypothesis: nonrandomnessRezíduá teda sú teda (z tohto pohľadu) pravdepodobne náhodné.
Jednou z mier konkordancie je Spearmanov korelačný koeficient, ukážeme si manuálny výpočet:
local({
U_rank <- rank(unique(dat$train$resSyst)) # duplicitné hodnoty sú vylúčené
n_ <- length(U_rank)
rho <- 1 - sum( ((1:n_)-U_rank)^2 )*6/n_/(n_^2-1)
# alternativne rho <- cor(1:n_, U_, method = ("spearman"))
c(TStat = rho * sqrt(n_-1),
q = qnorm(c(L=0.025, H=0.975))
)
# iné riešenie:
c(TStat = rho * sqrt( (n_-2)/(1-rho^2) ),
q = qt(c(L=0.025, H=0.975), df=n_-2)
)
}) TStat q.L q.H
1.010223 -1.963939 1.963939 V balíku randtests je k dispozícii test pomocou Kendalovej poradovej štatistiky:
randtests::rank.test(dat$train$resSyst)
Mann-Kendall Rank Test
data: dat$train$resSyst
statistic = 0.95411, n = 600, p-value = 0.34
alternative hypothesis: trendOba testy naznačujú náhodnosť rezíduí.
Manuálny výpočet a vstavaný test:
local({
U <- dat$train$resSyst # pre jednoduchosť zápisu
U <- U[c(T, !diff(U)==0)] # odstránenie po sebe idúcich duplicitných hodnôt
n_ <- length(U)
U1 <- U[-c(n_-1,n_)]
U2 <- U[-c(1,n_)]
U3 <- U[-c(1,2)]
M <- sum( (U1 < U2 & U2 > U3) | (U1 > U2 & U2 < U3) )
c(TStat = (M - 2*(n_-2)/3) / sqrt((16*n_-29)/90),
q = qnorm(c(L=0.025, H=0.975), mean=0, sd=1)
) |>
round(4)
}) TStat q.L q.H
-2.295 -1.960 1.960 randtests::turning.point.test(dat$train$resSyst)
Turning Point Test
data: dat$train$resSyst
statistic = -2.295, n = 600, p-value = 0.02173
alternative hypothesis: non randomnessRezíduá nie sú náhodné, zrejme stále obsahujú periodické fluktuácie.
Test je známy aj ako “Wald-Wolfowitz Runs Test”, je založený na počte skupín nad a pod mediánom:
local({
U <- dat$train$resSyst
U <- U - median(U)
U <- U[U!=0]
M <- U>0
m <- sum(M)
P <- sum(diff(M)>0) + sum(diff(M)<0) + 1
c(TStat = (P - (m+1)) / sqrt(m*(m-1)/(2*m-1)),
q = qnorm(c(L=0.025, H=0.975), mean=0, sd=1)
)
}) TStat q.L q.H
-4.821356 -1.959964 1.959964 randtests::runs.test(dat$train$resSyst)
Runs Test
data: dat$train$resSyst
statistic = -4.8214, runs = 242, n1 = 300, n2 = 300, n = 600, p-value =
1.426e-06
alternative hypothesis: nonrandomnessAj tento test indikuje zvyškové fluktuácie dlho-periodického charakteru (pretože počet skupín je výrazne nižší, než by bol pri bielom šume).
Z testov náhodnosti sme sa dozvedeli, že reziduálna zložka je ešte korelovaná, budeme ju teda modelovať lineárnymi dynamickými modelmi stacionárnych procesov ARMA. Na tvorbu autoregresných modelov už základné nástroje v systéme R vyžadujú časový rad uložený v dátovom type ts, čo je numerický vektor s atribútmi o začiatku, konci a vzorovacej frekvencii (za prirodzenú časovú jednotku). V našom prípade časový rad nie je zasadený do konkrétneho roku, preto konverziu odbavíme čo najjednoduchšie:
dat$train$resSyst <- ts(dat$train$resSyst, end = nT)Identifikáciu ARMA procesov skúsime najprv neparametricky, pomocou ACF a PACF:
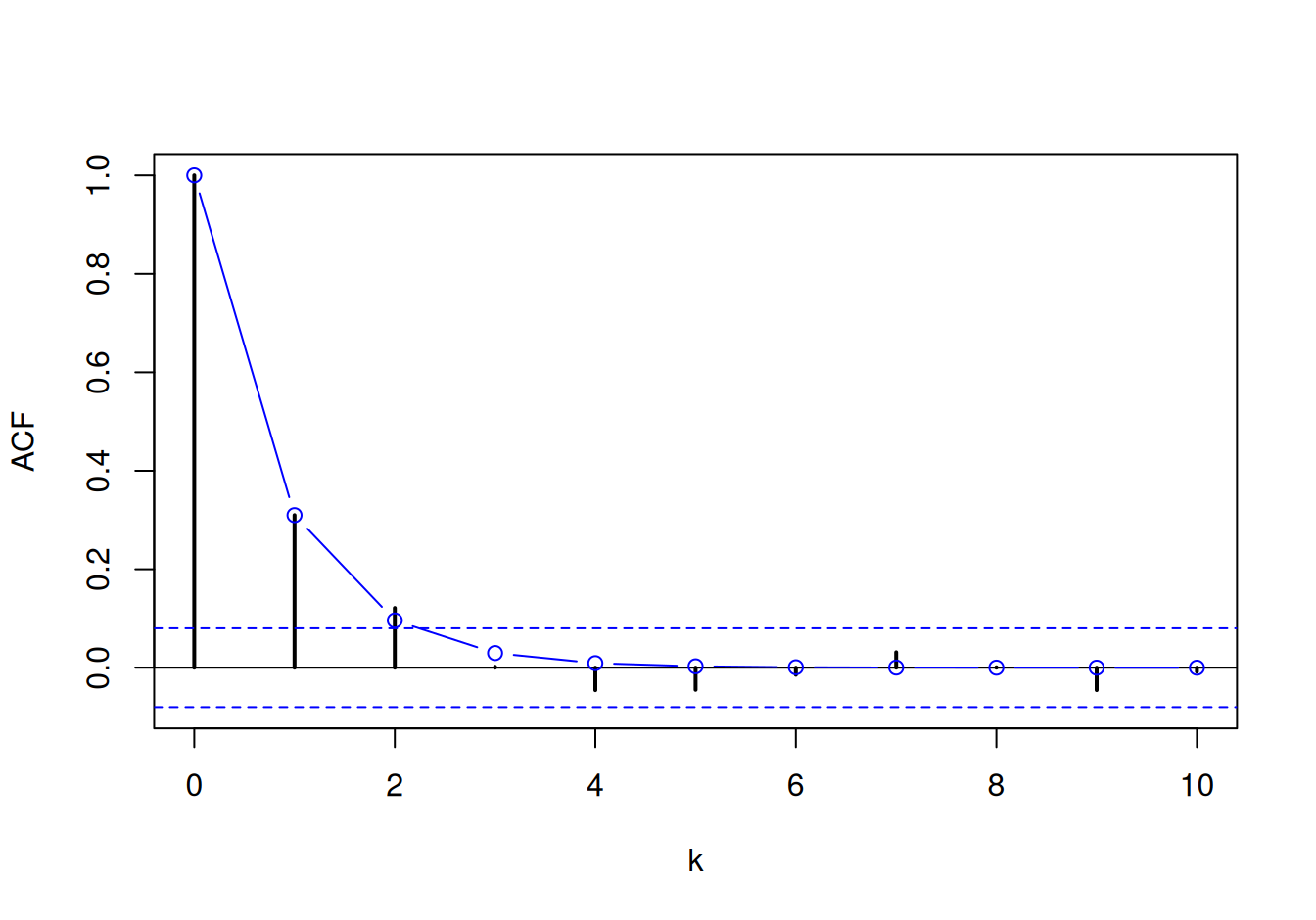
acf(dat$train$resSyst, lag.max = 10)
pacf(dat$train$resSyst, lag.max = 10)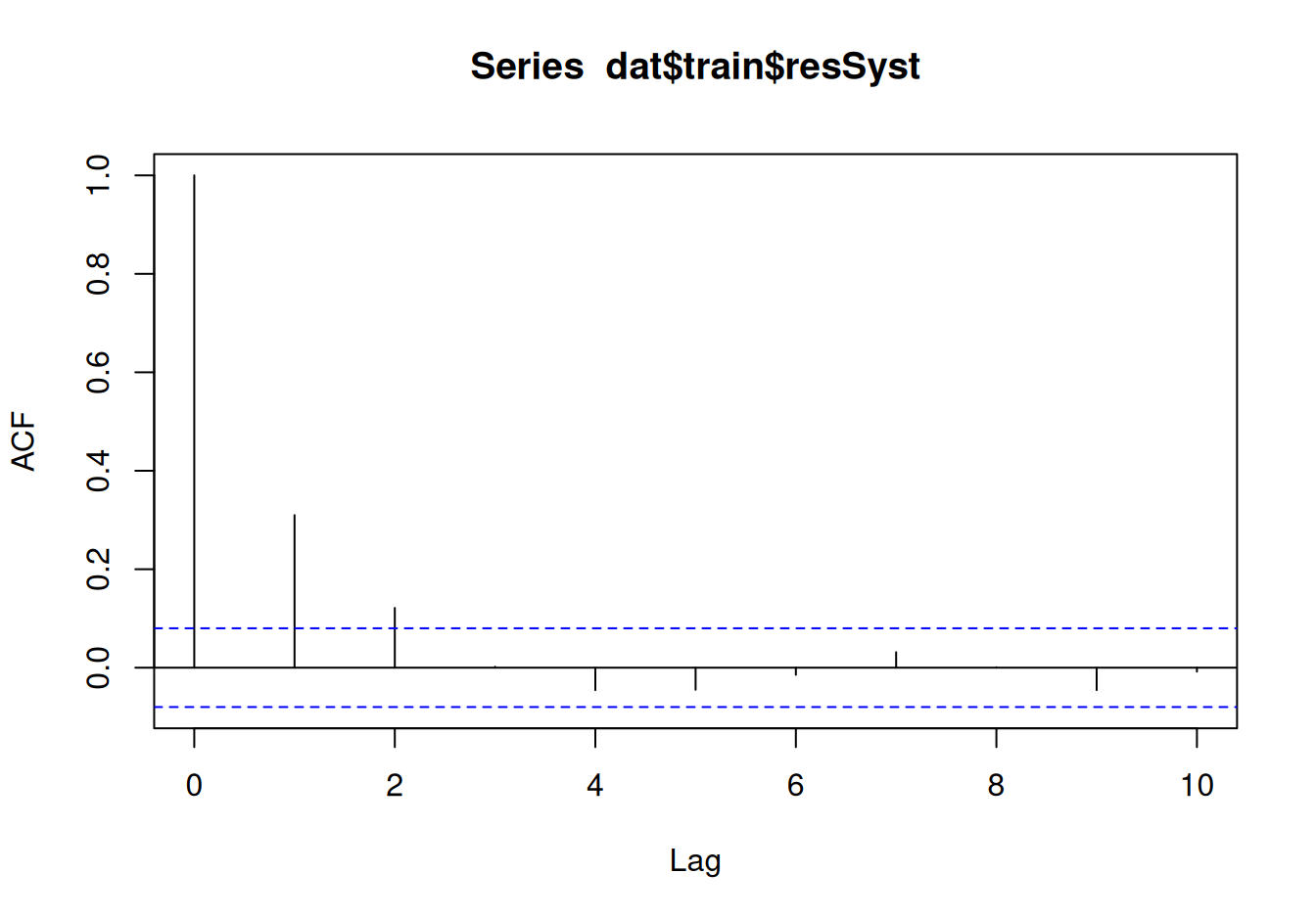
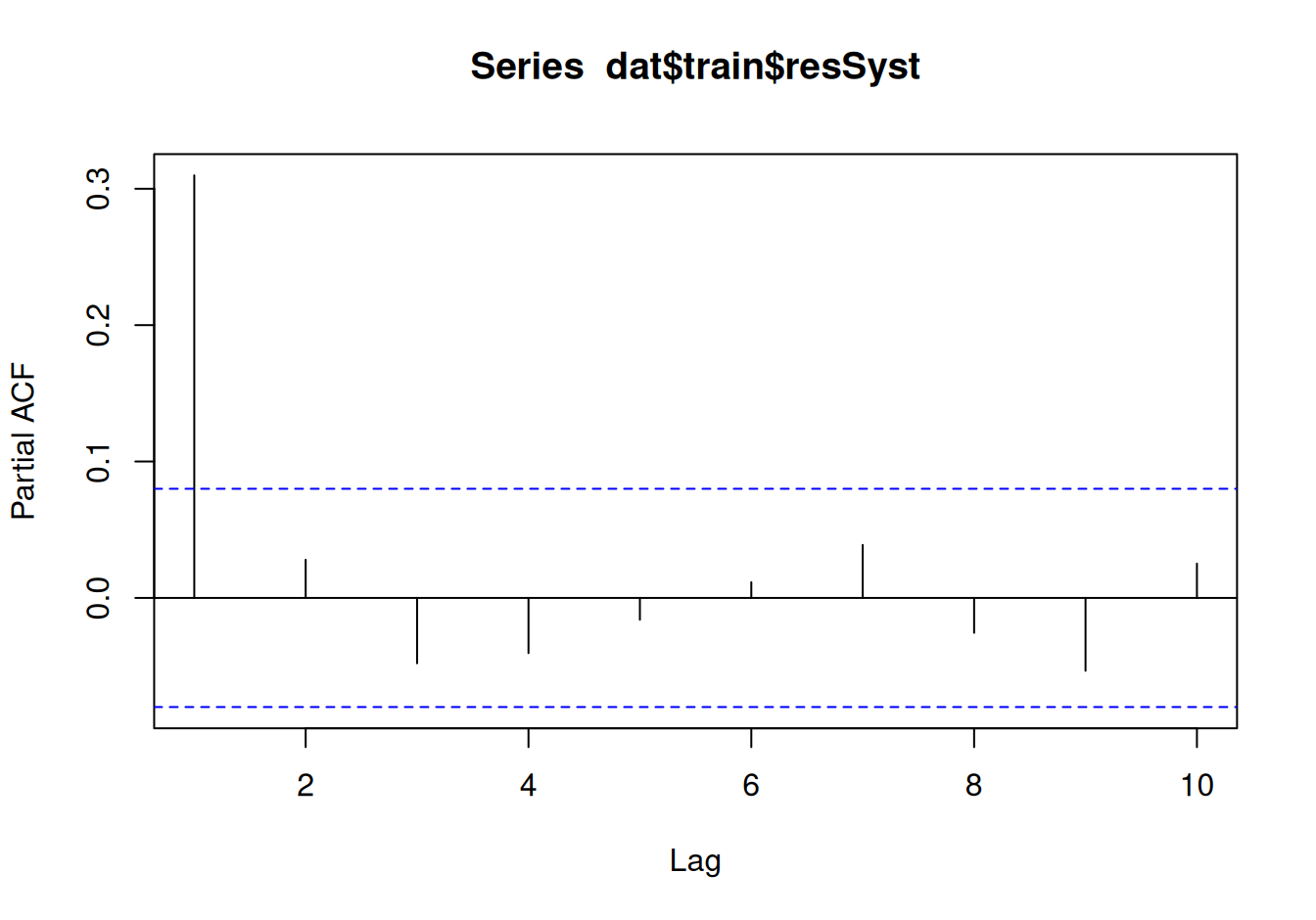
ACF klesá rýchlo ku nule, no PACF ešte rýchlejšie, preto ako vhodného kandidáta navrhneme model AR(1).
Parametrickú identifikáciu modelov z triedy AR pomocou AIC ponúka funkcia ar, ktorá pre každý stupeň poskytne rozdiel AIC od najlepšieho modelu. V triede AR je na základe AIC identifikovaný model AR(1):
ar(dat$train$resSyst, order.max = 5)$aic |>
plot(x = 0:5, xlab="p", ylab="dAIC", type="b")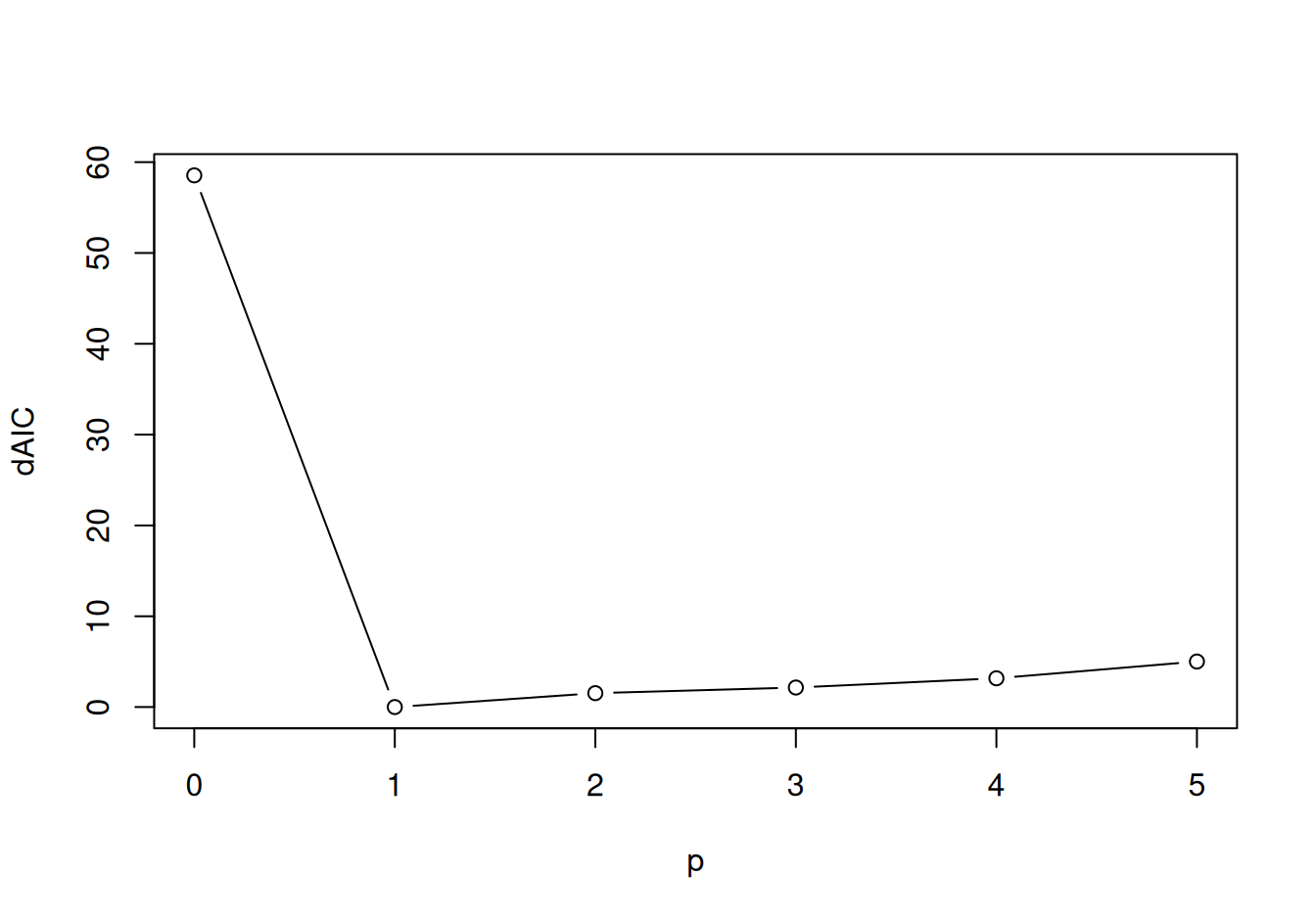
Funkciou ar sa dajú odhadnúť parametre modelu AR(p) bez absolútneho člena pomocou metód Yule-Walker, Burg, OLS (najmenších štvorcov) alebo MLE (maximálnej vierohodnosti).
Na odhad modelu ARMA(p,q) – aj s absolútnym členom – slúži funkcia arima, metódy zahŕňajú CSS (minimalizáciu súčtu štvorcov), MLE (maximalizáciu vierohodnosti) alebo kombináciu. Odhadneme najprv identifikovaný model AR(1) – parametre a ich štandardné chyby:
fit$ResAR <- arima(dat$train$resSyst, order = c(1,0,0))
cbind(par = coef(fit$ResAR), se = sqrt(diag(vcov(fit$ResAR)))) |> round(4) par se
ar1 0.3098 0.0388
intercept -0.0017 0.1250Model AR(1) môžeme na základe AIC porovnať aj s alternatívnym modelom zo širšej triedy, napr. ARMA(1,2).
sapply(list("AR(1)" = fit$ResAR,
"ARMA(1,2)" = arima(dat$train$resSyst, order = c(1,0,2))),
AIC) AR(1) ARMA(1,2)
2607.985 2610.329 Podľa AIC by sme vybrali AR(1).
Na porovnanie modelov ARMA do určitého stupňa (parametrickú identifikáciu) nám poslúži automatizovaná procedúra. Keďže má zmysel uvažovať stupne menšie, nanajvýš rovné trom, stačí použiť metódu hrubej sily (odhadnúť model pre každú kombináciu \(p\) a \(q\) nezávisle).
tmp <- expand.grid(p = 0:3, q = 0:3) |>
transform(BIC = mapply(
FUN = function(x,y) BIC(arima(dat$train$resSyst, order = c(x, 0, y))),
p, q
)
)
plot(tmp$BIC, xlab = "p,q", ylab = "BIC", main = "ARMA(p,q)",
xaxt="n", type="b")
axis(1, at = 1:nrow(tmp), labels = paste(tmp$p, tmp$q, sep=","), las=2) # popis 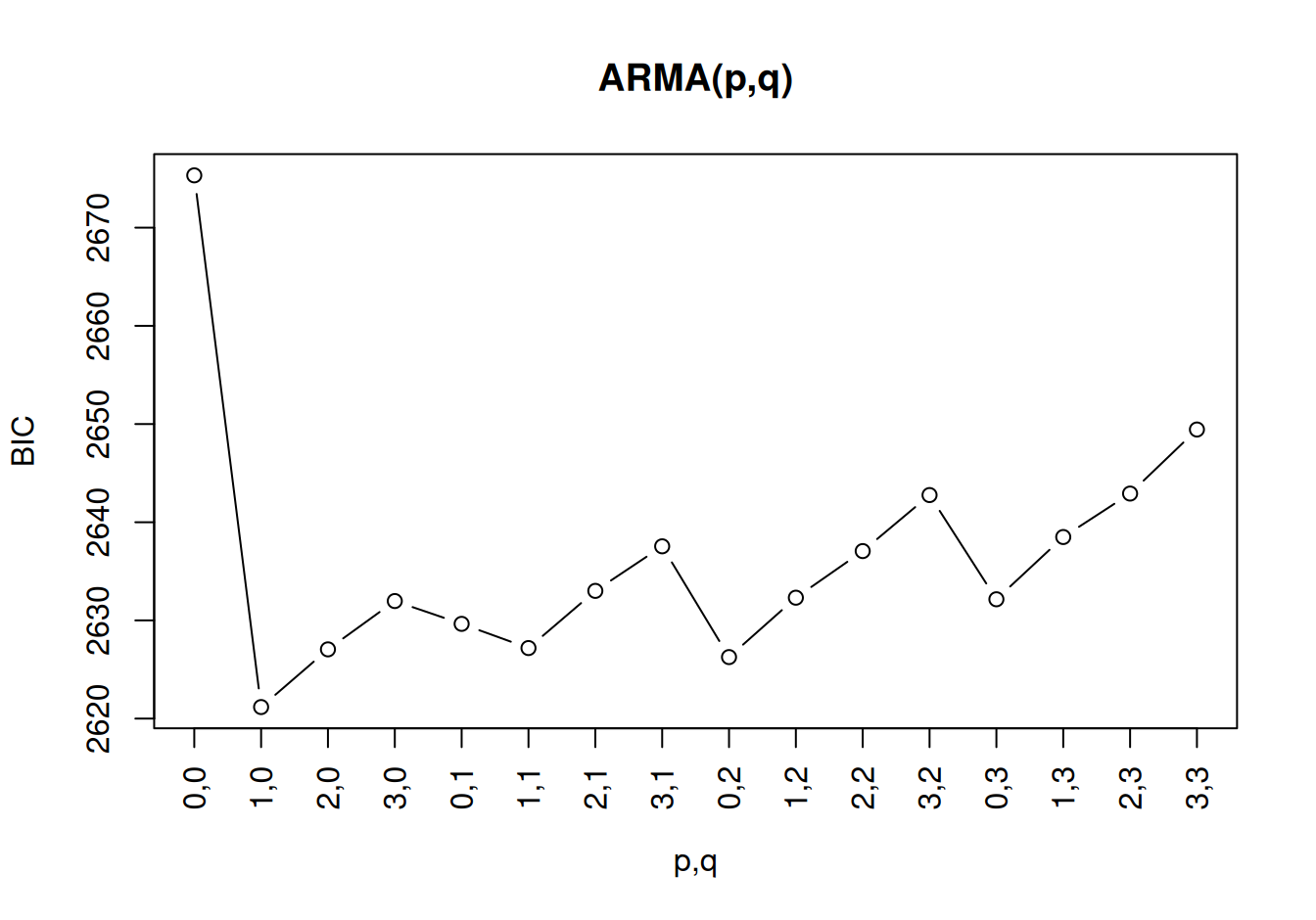
Najlepší model podľa HR procedúry je ARMA(1,0). Ako zástupcu širšej triedy ARMA ním formálne nahradíme už uložený AR(1), i keď je s ním totožný.
fit$ResAR <- NULL
fit$ResARMA <- arima(dat$train$resSyst, order = c(1,0,0))Videli sme, že hodnota autoregresného parametra je menšia ako 1, takže náš model AR(1) je stacionárny.
# Pre komplexnejšie modely sa dá stacionarita a invertibilita overiť:
# arima(dat$train$resSyst, order = c(2,0,3))$coef[1:2] |>
# append(values=1, after=0) |> polyroot() |> Mod()
# arima(dat$train$resSyst, order = c(2,0,3))$coef[2+(1:3)] |>
# append(values=1, after=0) |> polyroot() |> Mod()Zdá sa, že aj jeho autokorelačná štruktúra sa zhoduje s výberovou ACF a PACF:
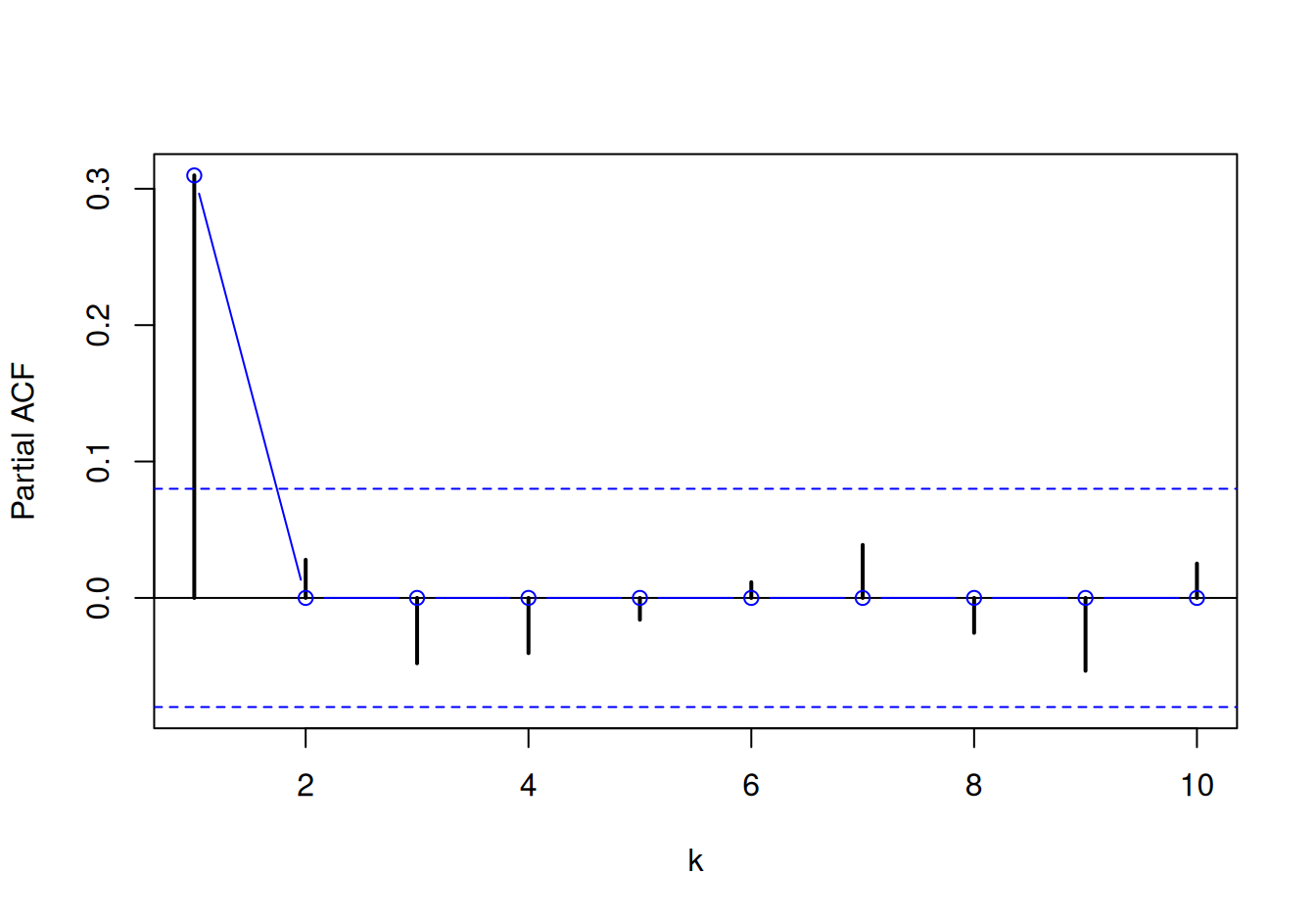
with(fit$ResARMA, {
kmax <- 10
ar <- coef[grep("ar",names(coef))] # extrakcia AR parametrov
ma <- coef[grep("ma",names(coef))] # a MA parametrov (formálne, lebo teraz žiadne nie sú)
acf(dat$train$resSyst, lag.max = kmax, lwd=2, main="", xlab = "k")
lines(0:kmax, ARMAacf(ar, ma, lag.max=kmax), type="b", col="blue")
pacf(dat$train$resSyst, lag.max = kmax, lwd=2, main="", xlab = "k")
lines(1:kmax, ARMAacf(ar, ma, lag.max=kmax, pacf=TRUE), type="b", col="blue")
})
Rezíduá modelu sú nekorelované, čo možno testovať spolu pre viac posunov. Tiež vyzerajú byť normálne rozdelené.
sapply(1:10, function(x) Box.test(fit$ResARMA$residuals, lag=x)$p.value) |>
plot(type="b", ylim=c(0,1), xlab="maximálny posun", ylab="p-value", main="Box-Pierce test")
abline(h=0.05, lty="dotted") # hladina významnosti
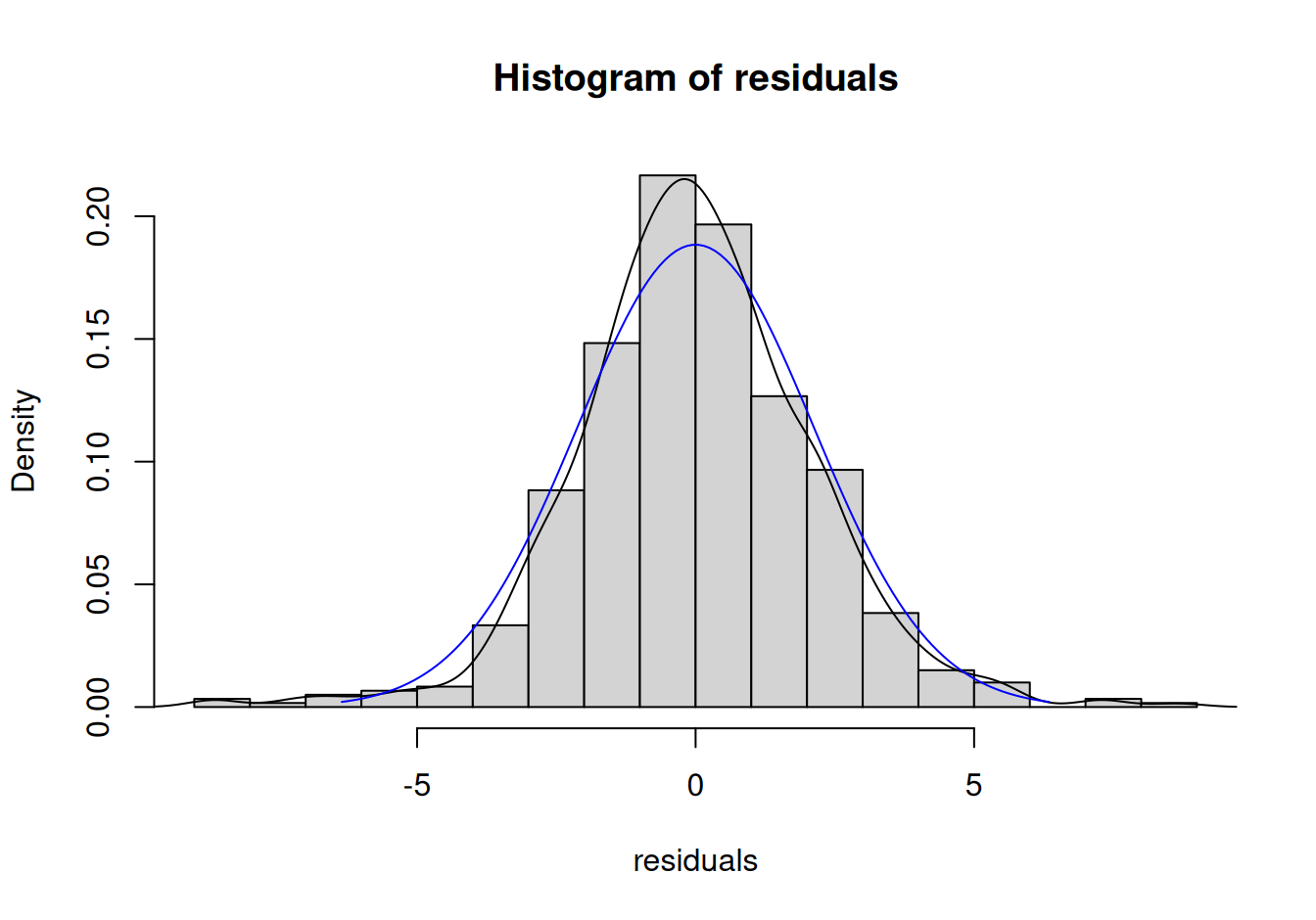
with(fit$ResARMA, {
sdev <- sd(residuals)
xrange <- seq(from=-3*sdev, to=3*sdev, by=0.1)
hist(residuals, breaks=20, freq=F)
lines(density(residuals)) # smoothed empirical density
lines(x = xrange, y = dnorm(xrange, mean=mean(residuals), sd=sdev), col="blue")
})
tseries::jarque.bera.test(fit$ResARMA$residuals)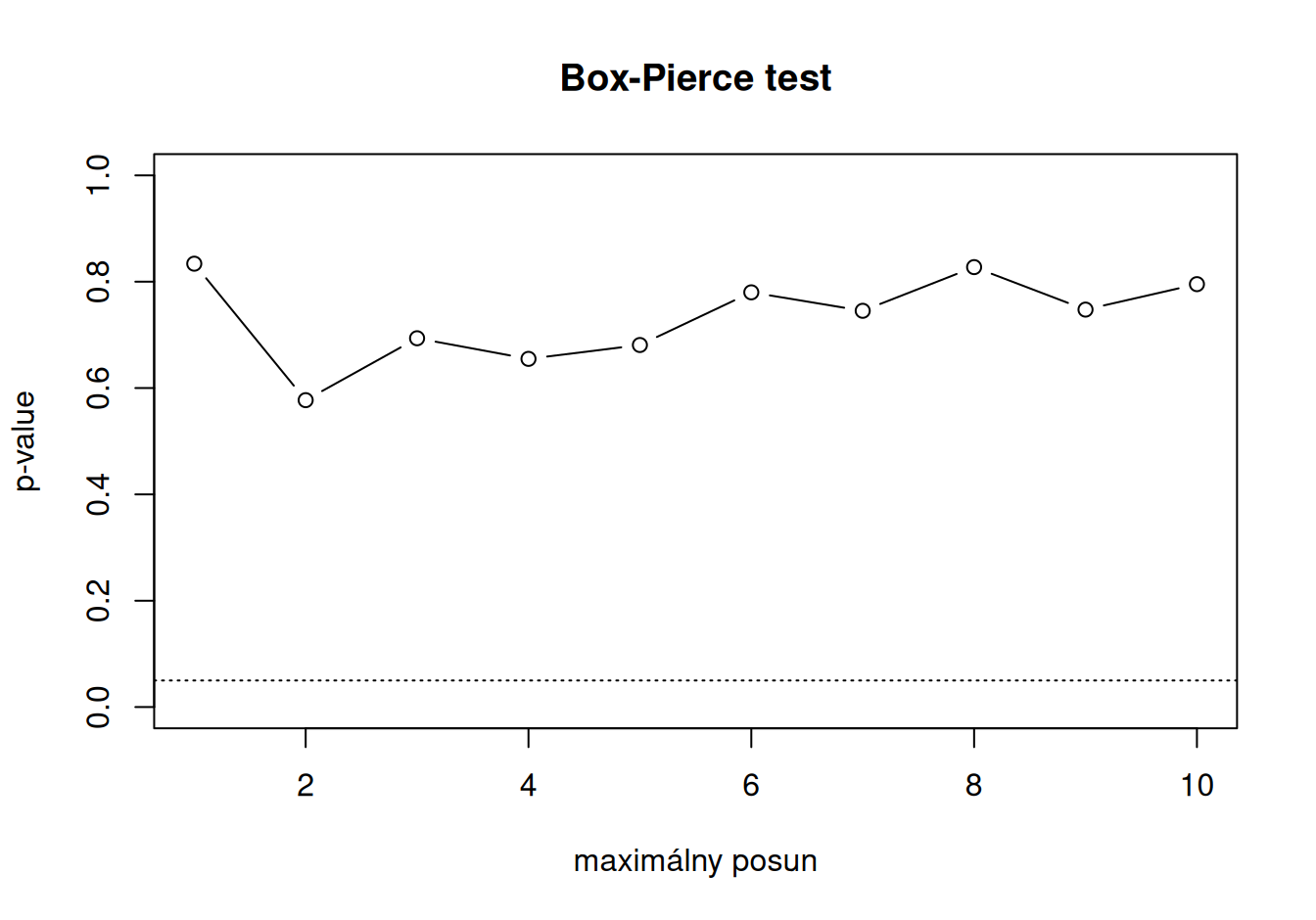
Jarque Bera Test
data: fit$ResARMA$residuals
X-squared = 73.344, df = 2, p-value < 2.2e-16Lenže na základe JB testu nulovú hypotézu o normalite musíme zamietnuť, zrejme má rozdelenie rezíduí hrubšie chvosty. Treba s tým počítať pri konštrukcii intervalových predpovedí.
Heteroskedasticitu vyšetríme White-ovým testom a autokorelačnou funkciou štvorcov rezíduí.
local({
eps2 <- fit$ResARMA$residuals^2
ar <- ar(eps2)
w <- ar$order
t1 <- max(w, fit$ResARMA$arma[1:2])
RSSe <- ar$resid^2 |> tail(-t1) |> sum()
RSSt <- (eps2-mean(eps2))^2 |> tail(-t1) |> sum()
WT <- length(eps2) * (1-RSSe/RSSt)
c(test.stat = WT,
q.95 = qchisq(0.95, df = w+1),
p.hodnota = pchisq(WT, df = w+1, lower.tail = F)
)
}) |>
round(4)test.stat q.95 p.hodnota
75.3018 36.4150 0.0000 # testy heteroskedasticity pomocou balíkov:
# skedastic::white_lm(tmp$models[[1]])
# aTSA::arch.test(fit$ResARMA)
# lmtest::bptest(tmp$models[[1]])
# car::ncvTest(tmp$models[[1]])
pacf(fit$ResARMA$residuals^2)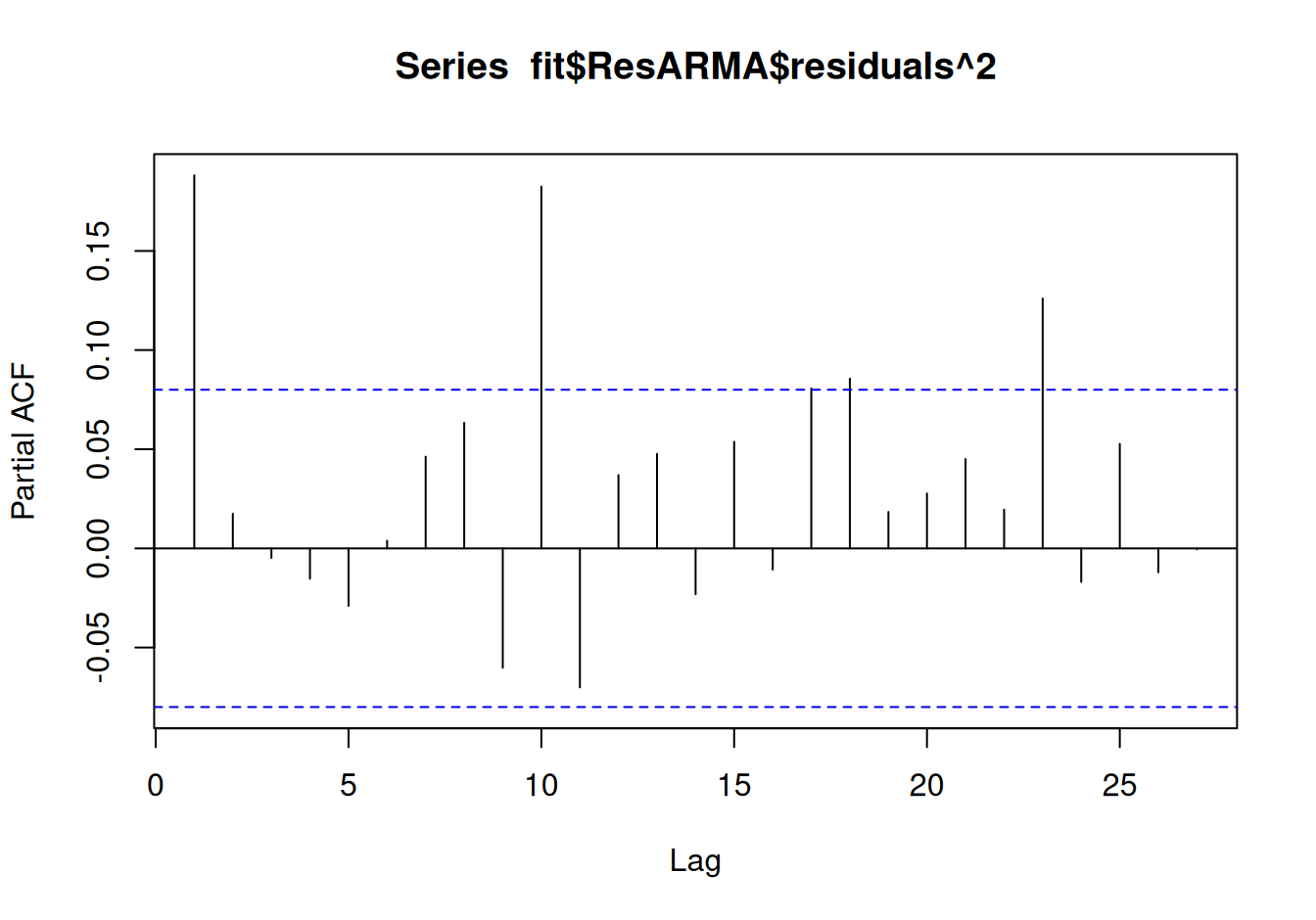
Rezíduá zrejme majú premenlivý rozptyl, takže AR(1) nie je úplne ideálny, ale pravdepodobne je najlepší v triede lineárnych modelov.
Postupne sme teda identifikovali lineárny trend, pravidelnú sínusoidovú sezonalitu a proces AR(1) generujúci autokoreláciu v reziduálnej zložke.
Odhad statickej (model systematických zložiek) a dynamickej časti (model reziduálnej zložky) spolu v jednom modeli zabezpečí funkcia arima, ktorej treba vopred pripraviť regresnú maticu (maticu plánu) pre statickú časť. Naproti tomu kvôli dynamickej časti musí mať časový rad polohy atribúty dátového typu ts.
# konverzia na ts
dat$train$poloha <- ts(dat$train$poloha, end = nT)
# príprava bázových funkcií a z nich matice plánu
fun$BasisSyst <- function(t) c(
Abs = 1,
Tlin = t,
Ssin = sin(2*pi*t/365),
Scos = cos(2*pi*t/365)
)
regX <- list()
regX$train <- dat$train$deň |> sapply(fun$BasisSyst) |> t()
head(regX$train) Abs Tlin Ssin Scos
[1,] 1 1 0.01721336 0.9998518
[2,] 1 2 0.03442161 0.9994074
[3,] 1 3 0.05161967 0.9986668
[4,] 1 4 0.06880243 0.9976303
[5,] 1 5 0.08596480 0.9962982
[6,] 1 6 0.10310170 0.9946708# odhad modelu
fit$All <- arima(dat$train$poloha, # dáta
order = c(1,0,0), # špecif. dynamickej časti
xreg = regX$train, # špecif. statickej časti
include.mean = F # regX už obsahuje absolútny člen
)K vyhodnoteniu predpovedí nie je potrebné mať validačnú vzorku vo forme ts, ale uľahčí to vykreslenie.
dat$valid$poloha <- ts(dat$valid$poloha, start = nT + 1)Výpočet viackrokových predpovedí (forecast) je technicky jednoduchší ako výpočet jednokrokových.
# naivné predpovede
dat$valid$forNaive <- ts(dat$train$poloha[nT], start = nT+1, end = nT+nV)
tmp <- diff(dat$train$poloha)^2 |> mean() # reziduálny rozptyl
dat$valid <- dat$valid |>
transform(
forNaiveLo = forNaive - 2*sqrt(tmp*(1:nV)),
forNaiveUp = forNaive + 2*sqrt(tmp*(1:nV))
)
# viackrokové
regX$valid <- dat$valid$deň |>
sapply(fun$BasisSyst) |> t()
tmp <- predict(fit$All, n.ahead = nV, newxreg = regX$valid)
dat$valid <- dat$valid |>
transform(
forMulti = tmp$pred, # stredná hodnota
# približné hranice predp. intervalu za predpokladu normality:
# (štandardná chyba je bez uváženia presnosti modelu)
forMultiLo = tmp$pred - 2*tmp$se,
forMultiUp = tmp$pred + 2*tmp$se
)
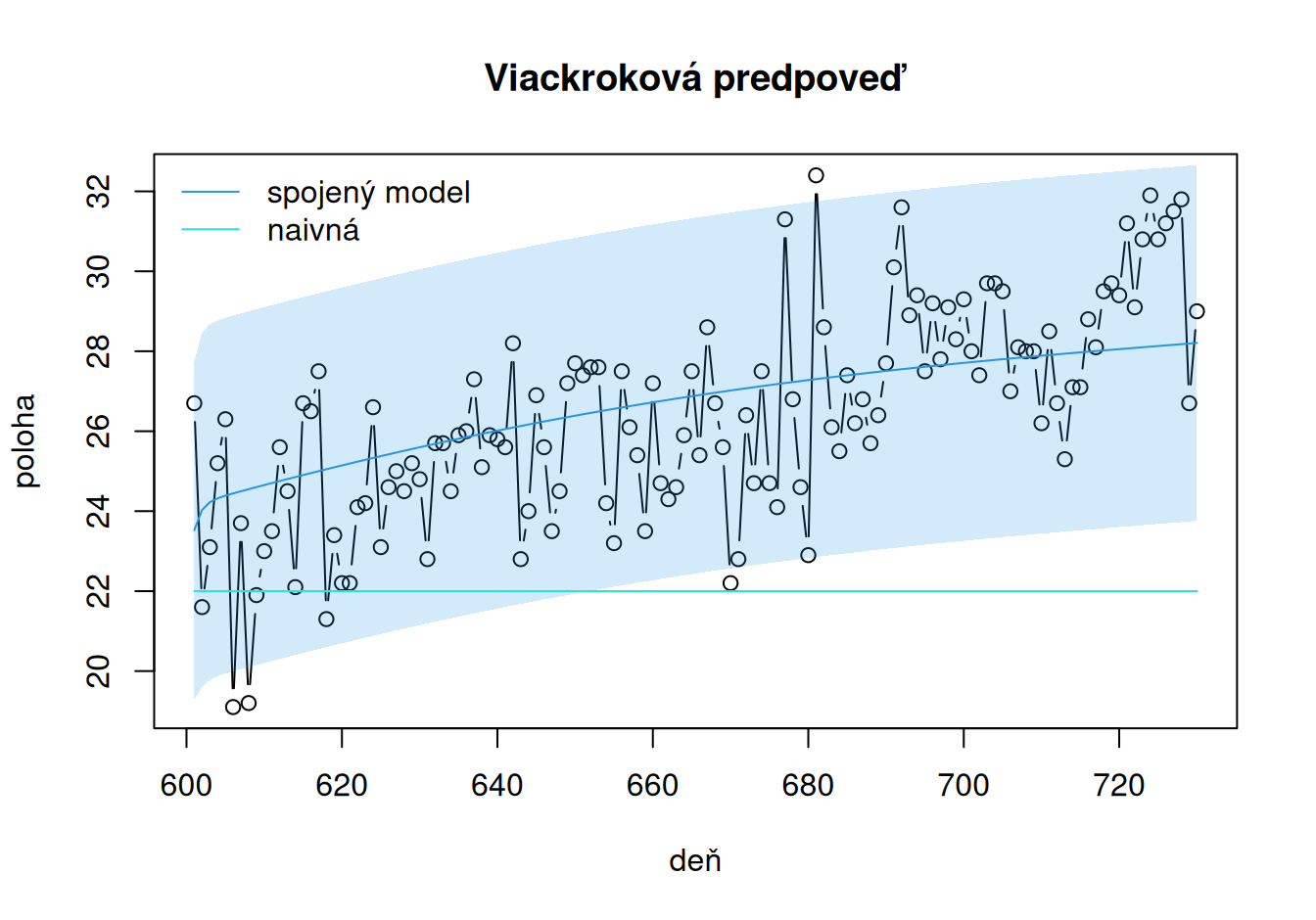
with(dat$valid, {
plot(poloha, type="b", xlab = "deň", main = "Viackroková predpoveď")
lines(forMulti, col=4)
day <- time(poloha)
polygon(x = c(day, rev(day)), y = c(forMultiLo, rev(forMultiUp)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forNaive, col=5)
legend("topleft", c("spojený model", "naivná"), col = c(4,5), lty = 1, bty="n")
})
Jednokrokové predpovede sú komplikovanejšie, pretože pre ne v základných nástrojoch R nie je k dispozícii funkcia. Preto sme vytvorili funkciu fun$Forecast (pozri časť Pomocné funkcie), ktorá môže poslúžiť aj ako ilustrácia princípu konštrukcie jedno- a viac-krokových predpovedí.
Jej prvým argumentom je model (výstup z funkcie stat::arima), druhým matica plánu pre obdobie po poslednom zázname trénovacej vzorky. Tieto dva argumenty stačia na konštrukciu viackrokových predpovedí. Ak by model neobsahoval statickú časť, horizont predpovede sa dá zadať aj štvrtým argumentom n.ahead. (Ak sú dané oba, za horizont je považovaná najmenšia hodnota z n.ahead a počtu riadkov matice plánu newxreg.)
Pre konštrukciu jednokrokových predpovedí je potrebná validačná vzorka v treťom argumente valid.
Pretože nám prítomnosť systematickej zložky a rozhodnutie o type predpovedí (jedno a viac-krokové) delia priestor možností na 4 oblasti, funkcia obsahuje explicitné if-else podmienky, doplnené o kontrolu kompatibility argumentov.
Funkcia ignoruje atribúty ts objektov, aj výstup je iba obyčajný numerický vektor predpovedí.
Najprv si overíme zhodu viackrokových predpovedí našej funkcie s výstupom vstavanej funkcie predict, potom vypočítame a zobrazíme jednokrokové predpovede.
# porovnanie viackrokových
fun$Forecast(fit$All, newxreg = regX$valid) |> head() |>
rbind(head(dat$valid$forMulti)) [,1] [,2] [,3] [,4] [,5] [,6]
[1,] 23.52173 24.03013 24.2244 24.32115 24.38747 24.44413
[2,] 23.52173 24.03013 24.2244 24.32115 24.38747 24.44413# výpočet jednokrokových
tmp <- list(
pred = fun$Forecast(fit$All, newxreg = regX$valid, valid = dat$valid$poloha) |>
ts() |> 'tsp<-'(tsp(dat$valid$poloha)) # ts pre ľahšie zobrazenie
)
tmp$se <- fit$All$sigma2 |> sqrt() # SE rezíduí modelu
# uloženie
dat$valid <- dat$valid |>
transform(
forOnestep = tmp$pred, # stredná hodnota
# približné hranice predp. intervalu za predpokladu normality:
# (štandardná chyba je bez uváženia presnosti modelu)
forOnestepLo = tmp$pred - 2*tmp$se,
forOnestepUp = tmp$pred + 2*tmp$se
)
# zobrazenie
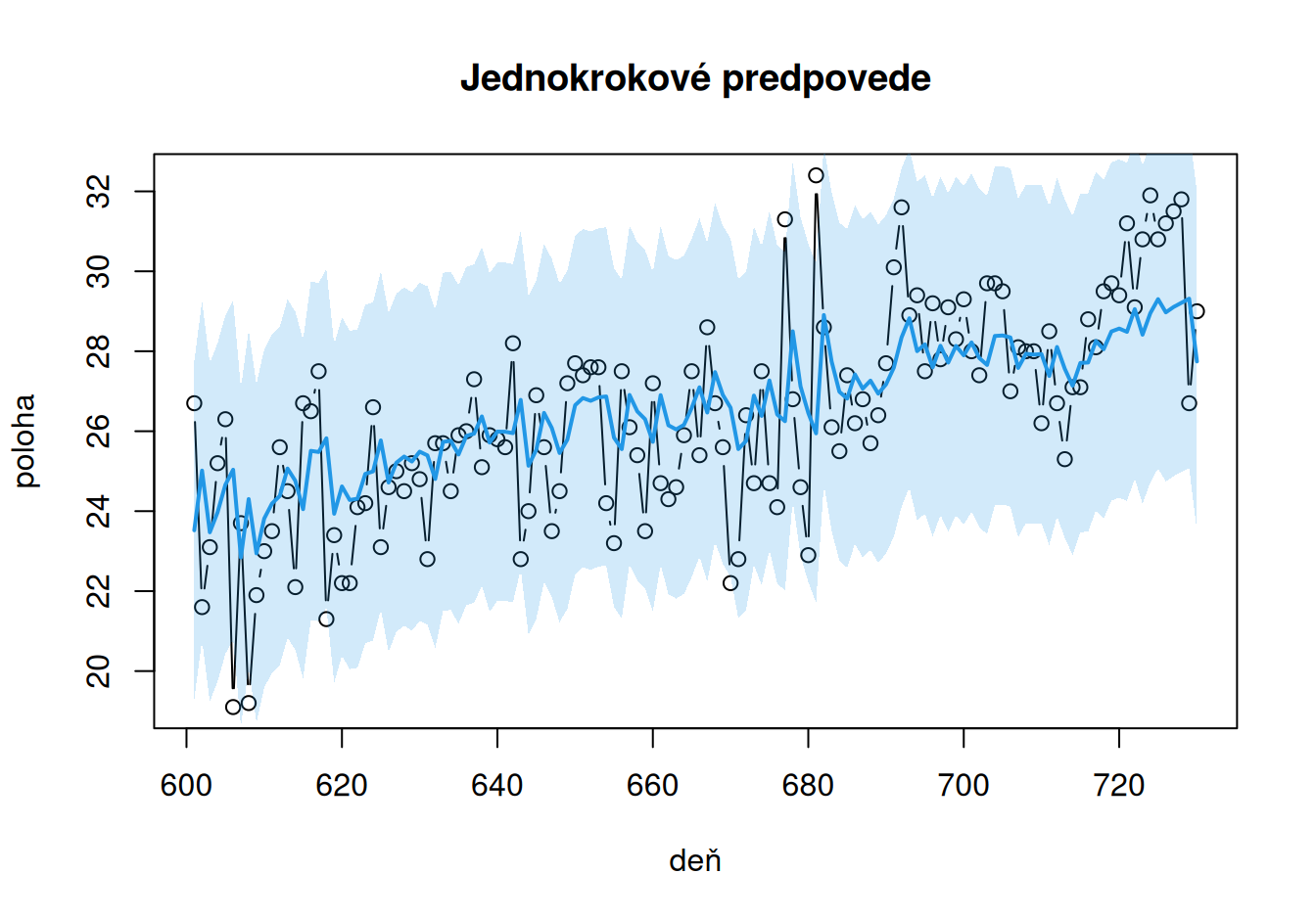
with(dat$valid, {
plot(poloha, type="b", xlab = "deň", main = "Jednokrokové predpovede")
lines(forOnestep, col=4, lwd=2)
day <- time(poloha)
polygon(x = c(day, rev(day)), y = c(forOnestepLo, rev(forOnestepUp)),
col = adjustcolor(4, alpha.f=0.2), border = F)
})
Presnosť predpovedí posúdime aj numericky, pomocou stredných predpovedných chýb.
with(dat$valid, list(Naivné = cbind(forNaive, poloha),
Viackrokové = cbind(forMulti, poloha),
Jednokrokové = cbind(forOnestep, poloha)
)) |>
sapply(fun$MeanForecastError) |> t() |> round(2) ME MSE RMSE MAE MAPE sMAPE MASE
Naivné 4.38 26.16 5.11 4.48 16.27 18.05 2.48
Viackrokové -0.26 4.23 2.06 1.65 6.44 6.30 0.91
Jednokrokové -0.18 3.86 1.96 1.53 6.00 5.89 0.85Jednokrokové predpovede sú prirodzene najpresnejšie, pretože pri ich výpočte je použíté najväčšie množstvo informácií. Náš model je však relatívne dobrý aj na dlhodobé predpovede, pretože za jednokrokovými zaostávajú iba minimálne, a oproti naivným predpovediam sú podstatne presnejšie.
Nakoniec celkový pohľad na časový rad a model:
ts.plot(dat$train$poloha, dat$valid$poloha,
gpars = list(col = c(
grey(0.5),
rgb(1,0,0, alpha=0.5)
)),
ylab = "poloha", xlab = "deň")
lines(fun$fitted.arima(fit$All), col=4)
lines(dat$valid$forMulti, col = 4, lty=2, lwd=2)
legend("bottomright",
legend=c("trénovacia vzorka", "validačná vzorka", "model", "predpoveď"),
lty = c(1,1,1,2), col = c(1,2,4,4), lwd = c(1,1,1,2), bty="n")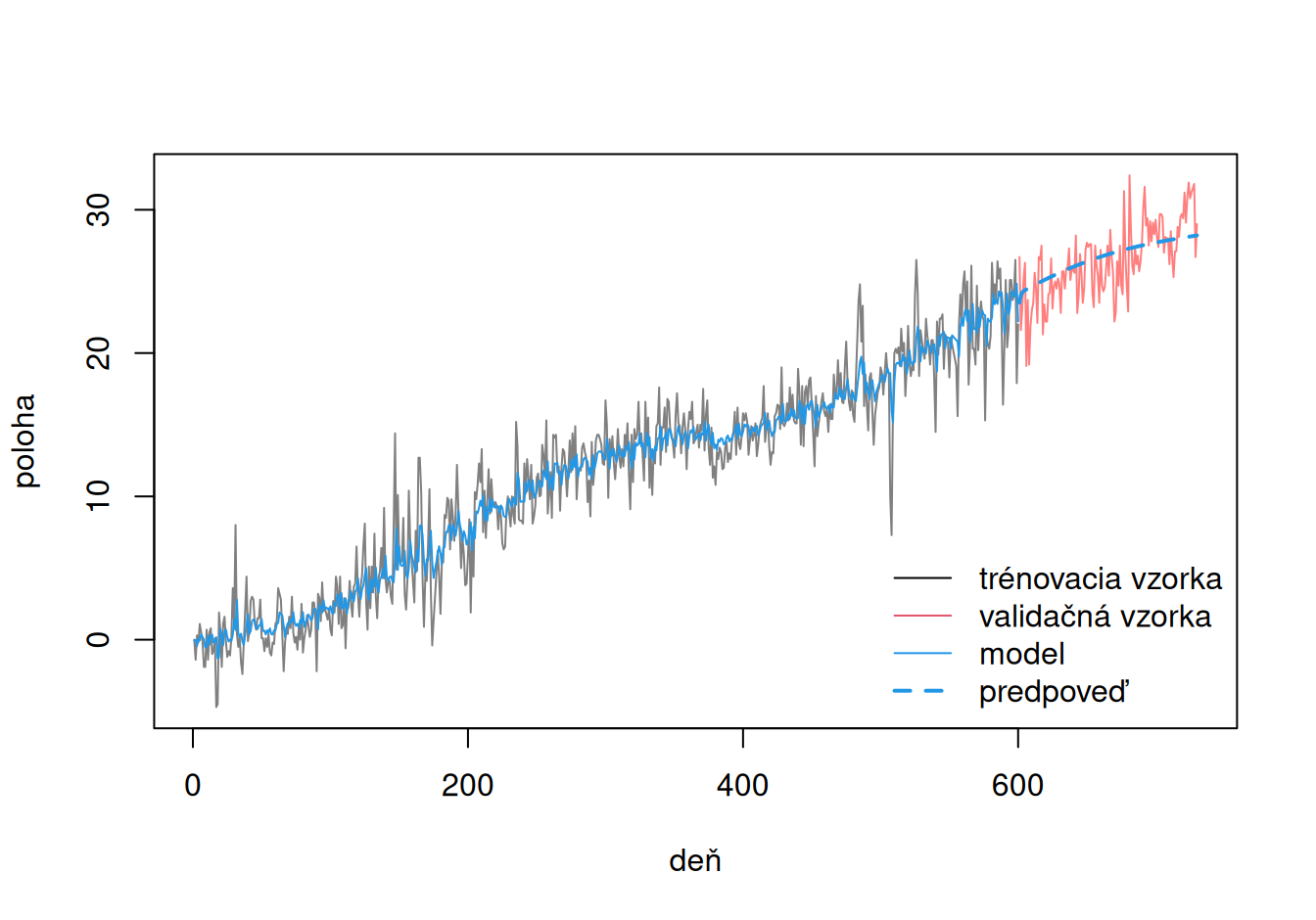
Pred ďalšou štúdiou vyčistíme pracovné prostredie. Vďaka puzdreniu do príslušných objektov je to jednoduché.
rm(dat, fit, regX, spec, n, nT, nV, tmp)
fun$BasisSyst <- NULLObnovenie kontajnerov (okrem fun, ktorý obsahuje všeobecne použiteľné funkcie):
dat <- fit <- list()Načítanie a zobrazenie údajov.
dat$all <- "data/HDP_kvart.dat" |> # zdrojový súbor údajov
read.table(header=T, skip = 1) # načítanie, vynechaný riadok obsahuje popis
head(dat$all) rok HDP
1 1964.00 49.00
2 1964.25 54.48
3 1964.50 60.38
4 1964.75 62.88
5 1965.00 52.09
6 1965.25 59.35# rozdeľ do dvoch data.frame a pripoj ku objektu dat
dat[c("train","valid")] <- dat$all |>
split(dat$all$rok >= 1992)
# zisti dĺžku vzoriek a ulož do jedného objektu
n <- lapply(dat, nrow)
unlist(n) all train valid
140 112 28 # zobrazenie
plot(HDP ~ rok, dat$all, type="n") # definuj vykreslovaciu oblasť ale nekresli
lines(HDP ~ rok, dat$train)
lines(HDP ~ rok, dat$valid, col = 2)
legend("bottomright", legend=c("trénovacia časť", "validačná časť"),
lty = 1, col = c(1,2))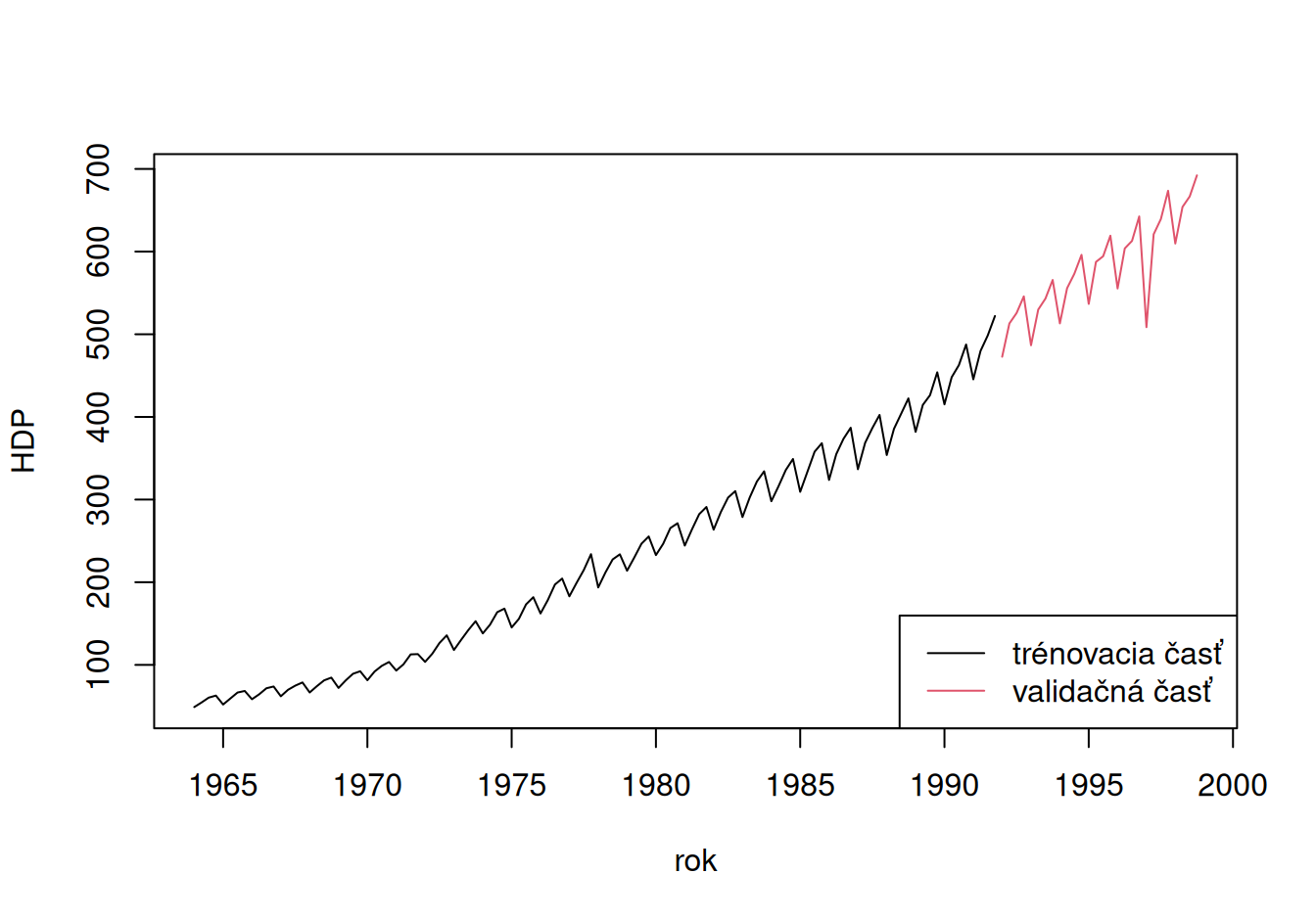
# konverzia na ts
dat$train$HDP <- ts(dat$train$HDP, start = c(1964, 1), frequency = 4)
dat$valid$HDP <- ts(dat$valid$HDP, start = c(1992, 1), frequency = 4)Časový rad predstavuje kvartálne záznamy hrubého domáceho produktu (HDP) jednej európskej krajiny v rokoch 1964–1998 v jednotkách miliárd EUR. Trénovacia vzorka končí 1991 Q4, validačná začína 1992 Q1.
Na prvotnú analýzu poslúži adaptívna metóda dekompozície. Porovnáme aditívny a multiplikatívny prístup.
dat$train$HDP |> decompose() |> plot()
dat$train$HDP |> decompose(type="multiplicative") |> plot()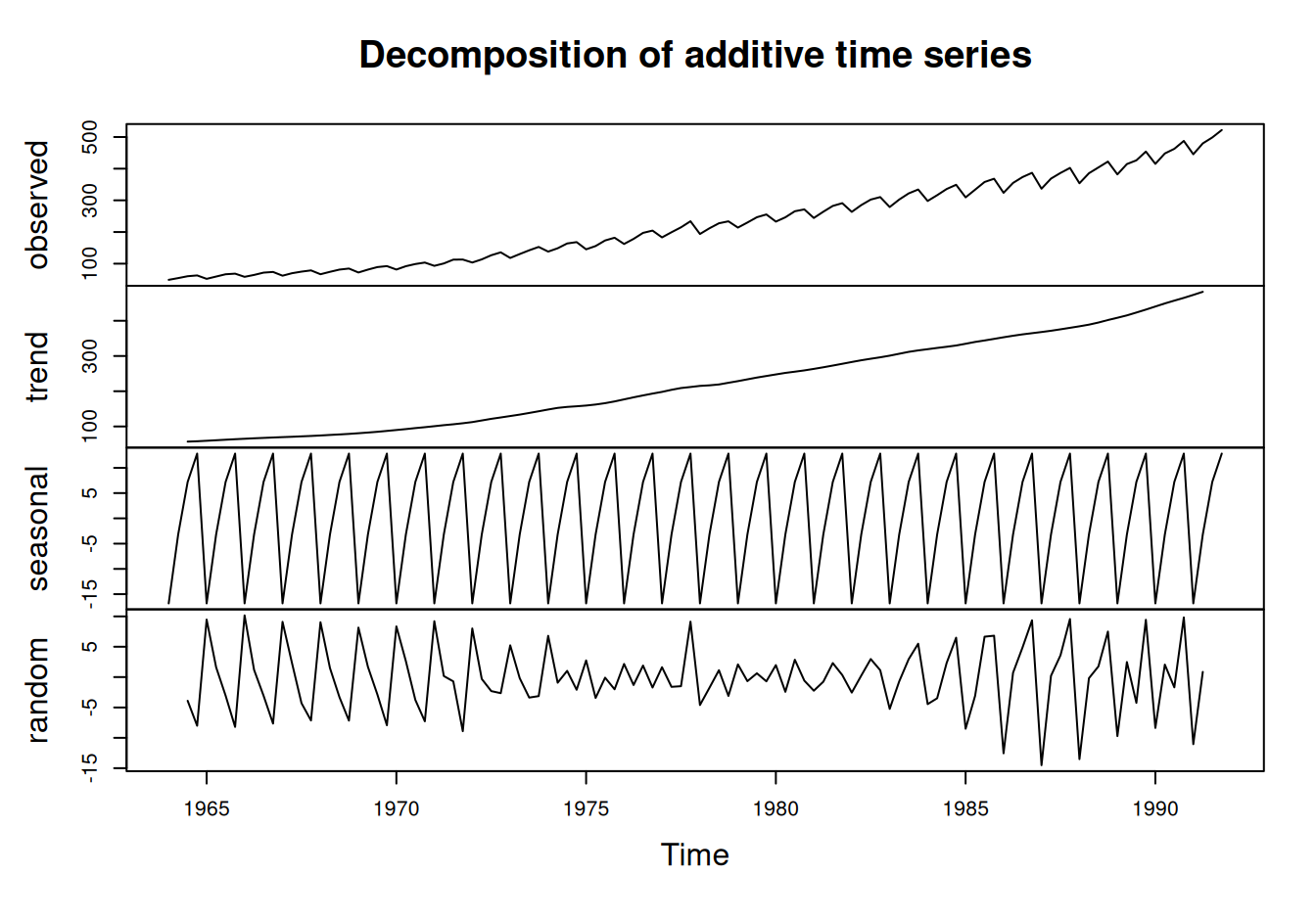
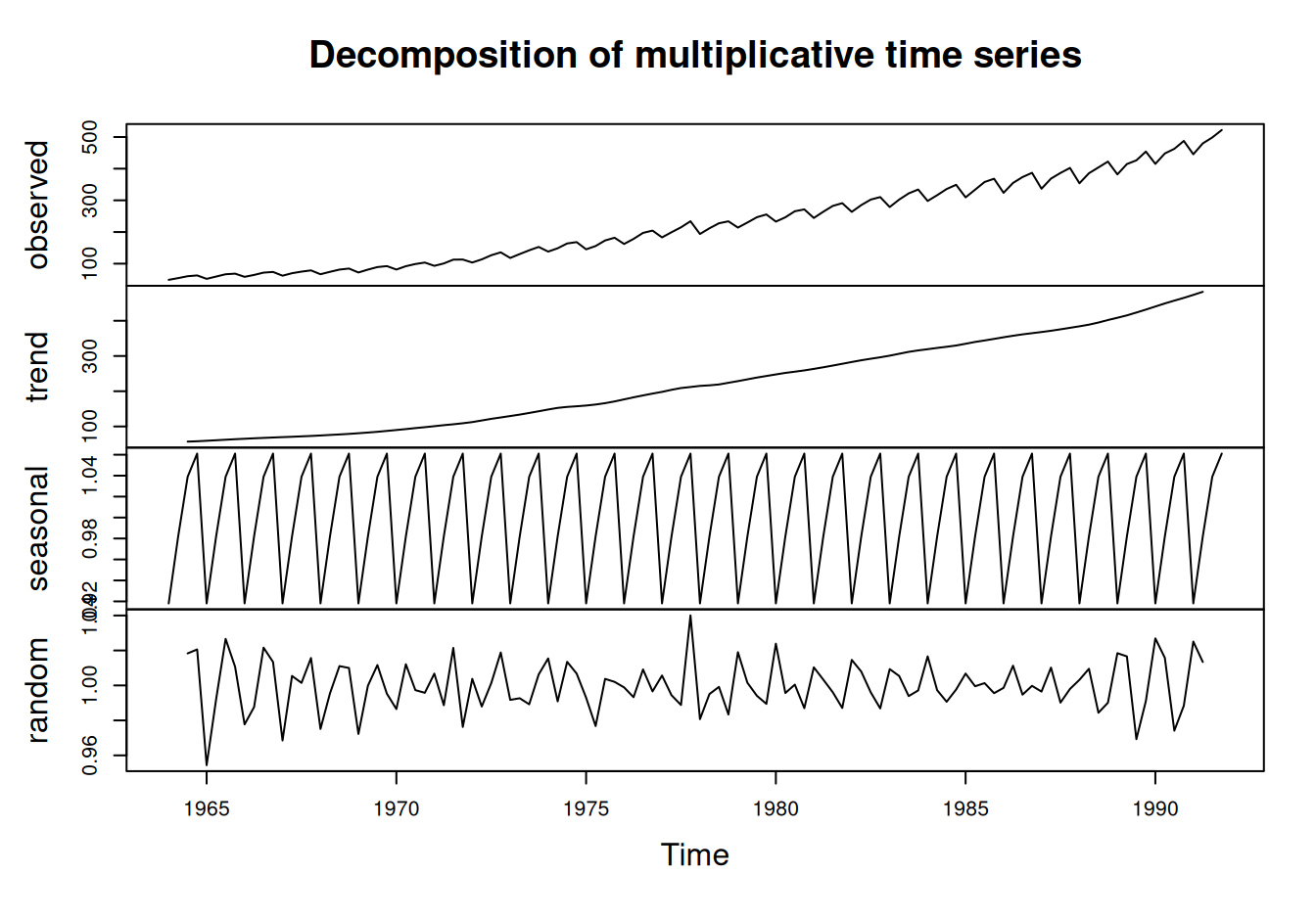
Vidíme rastúci trend a výraznú sezónnu zložku. Pretože rezíduá v prvom prípade sú zatažené sezonalitou a majú premenlivý rozptyl oveľa výraznejšie ako je tomu v druhom prípade, volíme multiplikatívnu dekompozíciu. V nej jedine trend bude v mld EUR, ostatné sú bezrozmerné.
Zdá sa, že hospodárstvo krajiny rastie exponenciálnym tempom. Modelovanie však bude jednoduchšie v logaritmickej mierke ako lineárny trend, inak by sme boli odkázaní na nelineárnu regresiu.
# model
fit$TreExp <- lm(log(HDP) ~ rok, dat$train)
tmp <- fit$TreExp |> coef() |> print() (Intercept) rok
-157.26677821 0.08214992 # stredné hodnoty (v pôvodnej mierke)
dat$train$TreExp <- fit$TreExp |> fitted() |>
exp() |>
ts() |> `tsp<-`(tsp(dat$train$HDP))# graf v logaritmickej a pôvodnej mierke
with(dat$train, {
plot(log(HDP), type = "l")
lines(log(TreExp), col = 4, lwd = 2)
plot(HDP, type = "l")
lines(TreExp, col = 4, lwd = 2)
})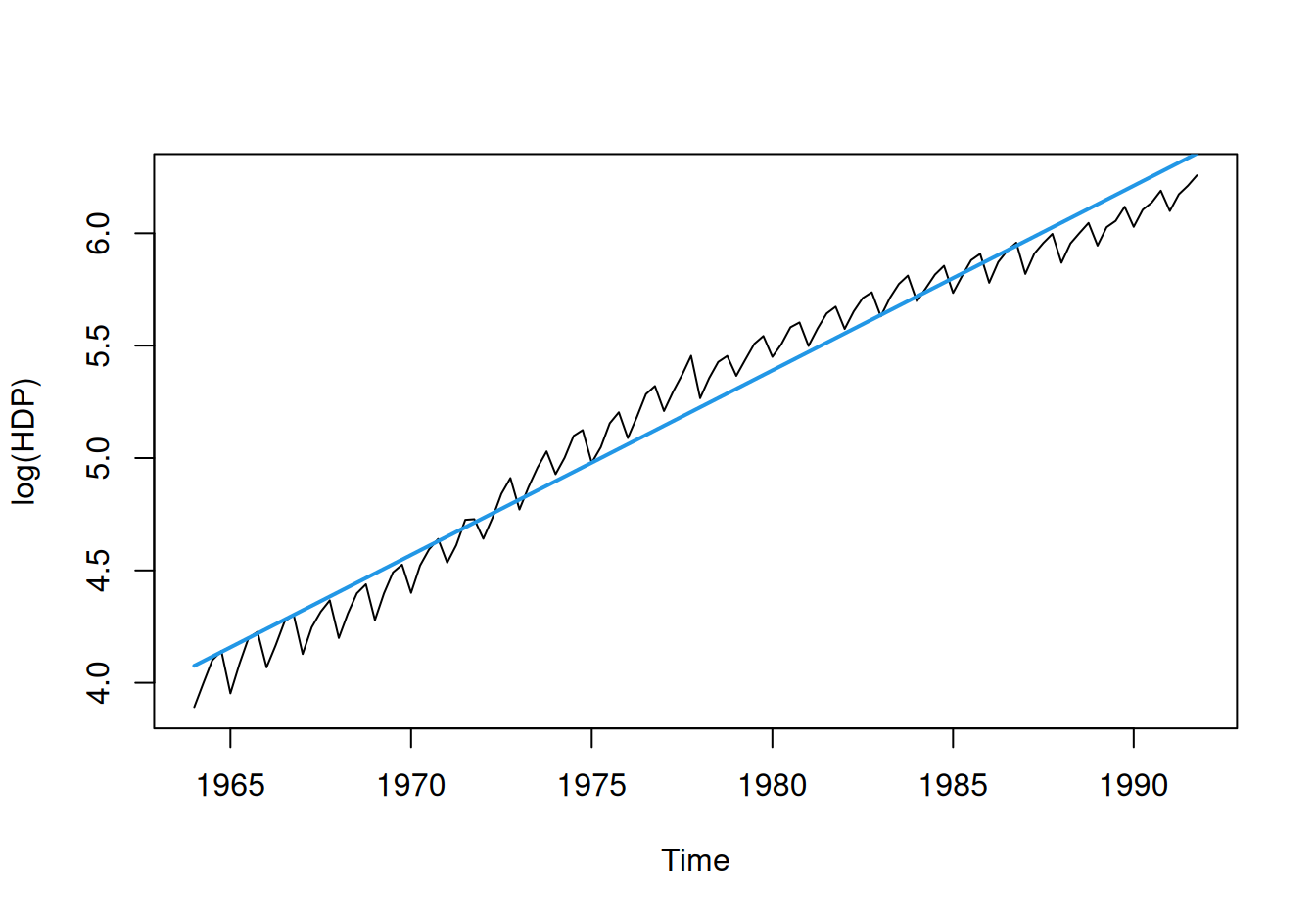
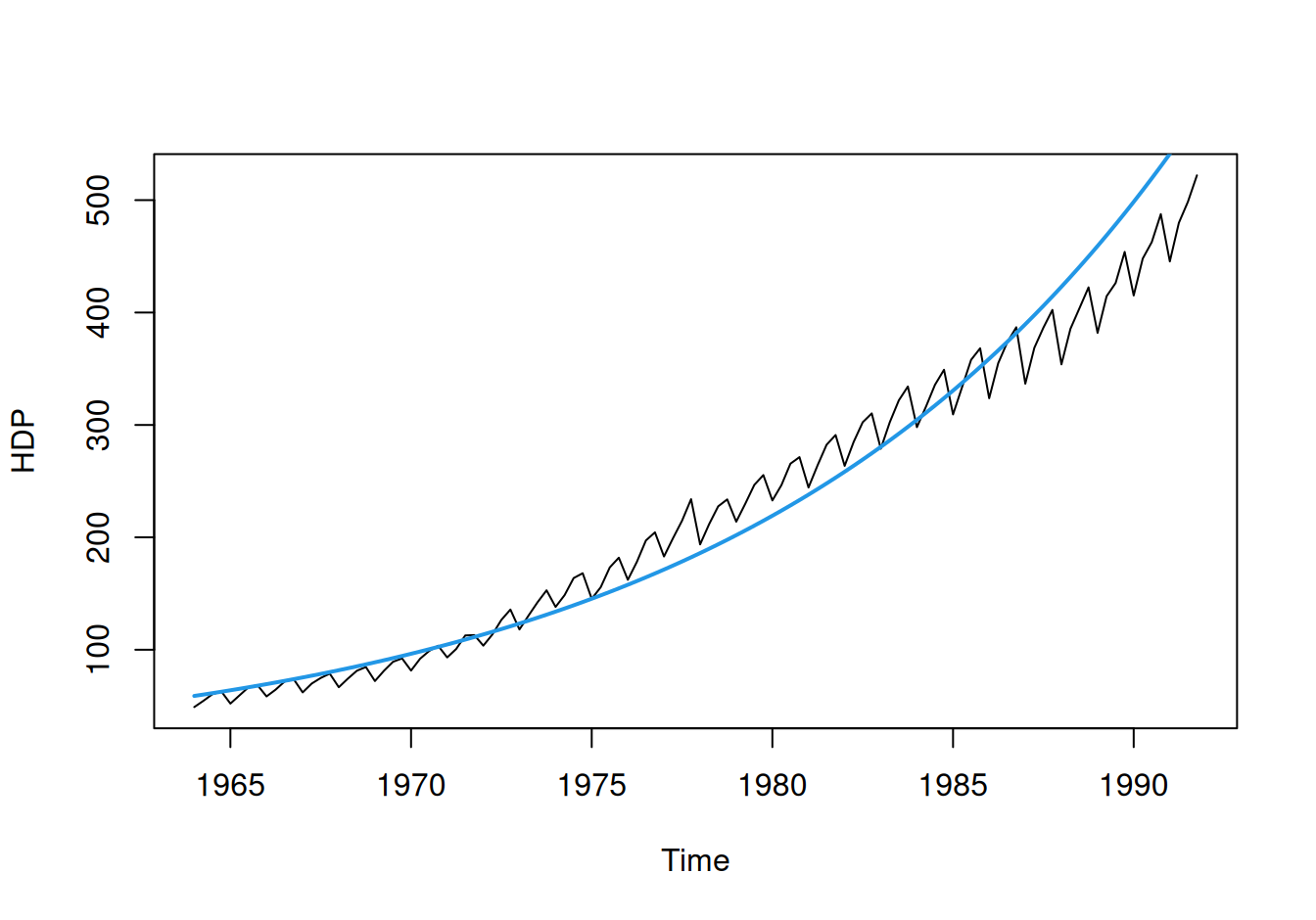
V priemere (podľa modelu) teda HDP rástlo ročným tempom \((e^{0.08215}-1)=8.56\%\), to znamená na začiatku sledovaného obdobia medziročne o 5 a na konci (v roku 1991) o 45.4 mld EUR.
Nakoniec výpočet rezíduí ako podielu časového radu a trendu.
dat$train$resT <- dat$train$HDP / dat$train$TreExpwith(dat$train, {
plot(resT)
acf(resT)
})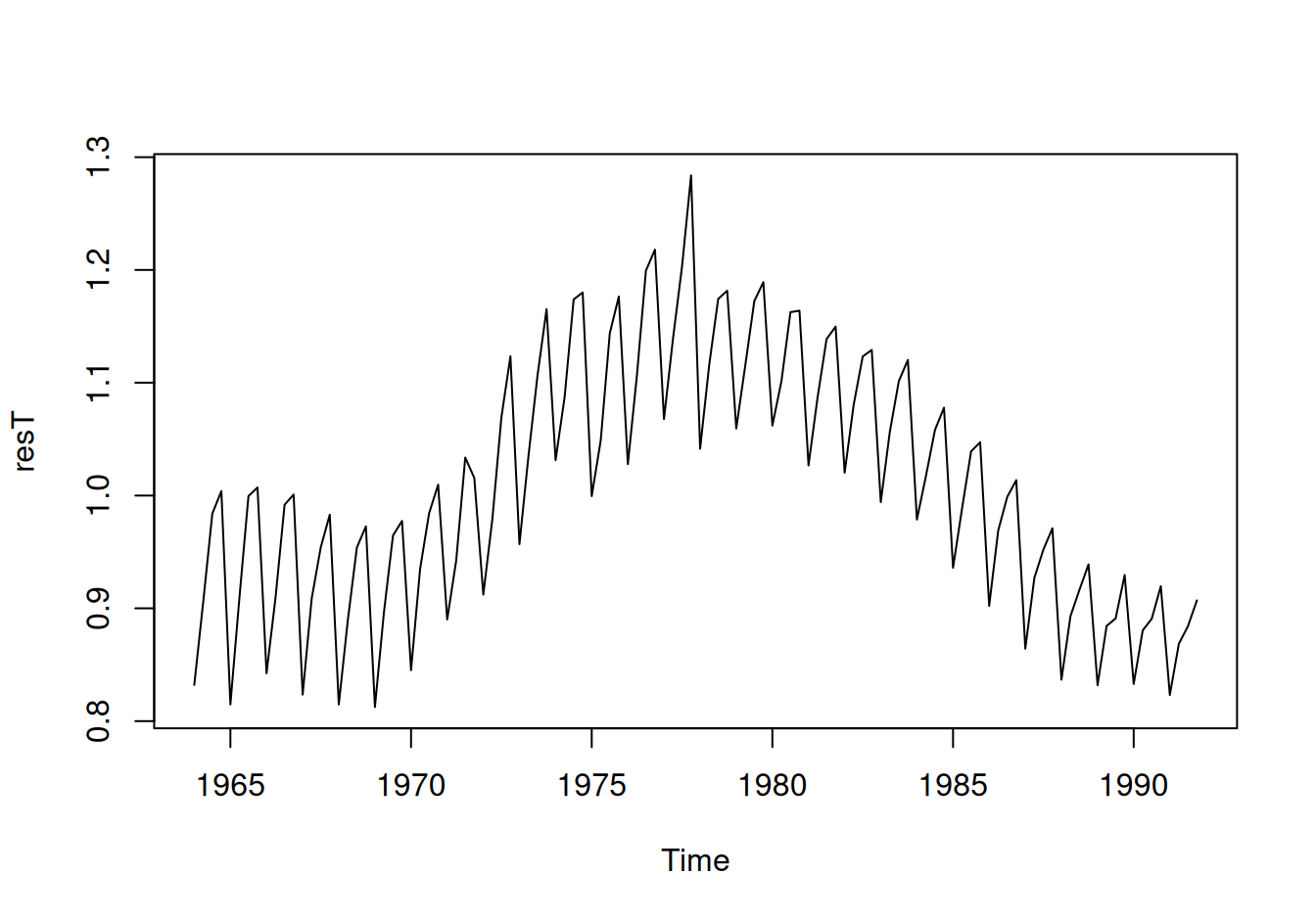
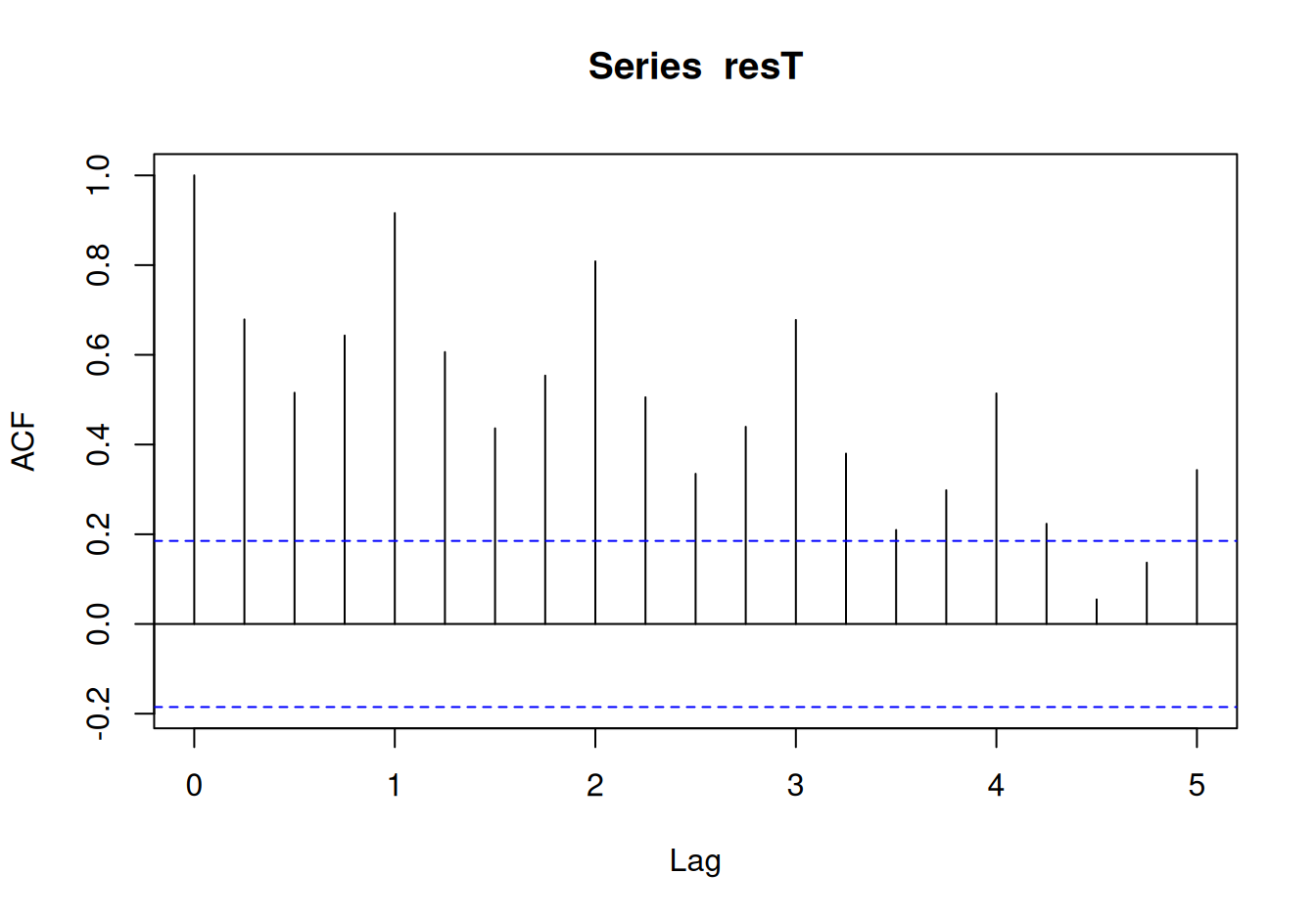
Rezíduá po trende sú ešte výrazne nestacionárne, vidno to aj z grafu ACF, sezónna perióda je 1 rok. Vzhľadom na nízku vzorkovaciu frekvenciu je počet sezón malý (L = 4 kvartály), preto budeme sezónnosť modelovať pomocou indikačných funkcií. Do súboru údajov pridáme premennú Q indikujúcu kvartál.
dat$train$Q <- factor(((dat$train$rok %% 1) * 4) + 1)
# dat$train$Q <- dat$train$rok |> lubridate::date_decimal() |> lubridate::quarter()
fit$SeaInd <- lm(resT ~ Q, dat$train)
fit$SeaInd
Call:
lm(formula = resT ~ Q, data = dat$train)
Coefficients:
(Intercept) Q2 Q3 Q4
0.92431 0.06418 0.12088 0.14198 dat$train$SeaInd <- fit$SeaInd |> fitted() |>
ts() |> `tsp<-`(tsp(dat$train$HDP))with(dat$train, {
plot(resT)
lines(SeaInd, col = 4, lwd = 2)
plot(1:4, SeaInd[1:4], xaxt="n", xlab="kvartál", ylab = "Sezónna zložka", type = "b", col = 4)
axis(1, at = 1:4, labels = 1:4)
})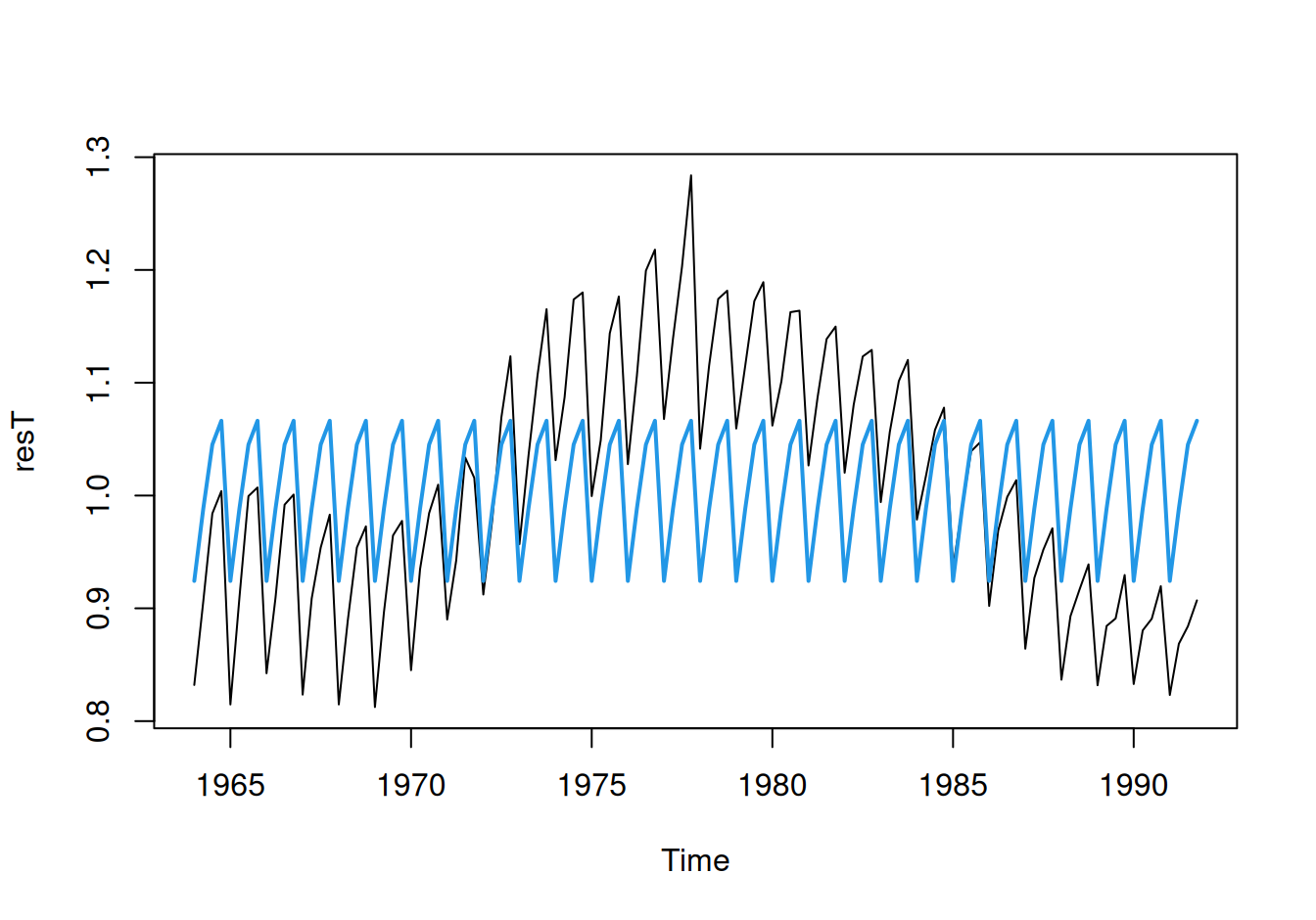
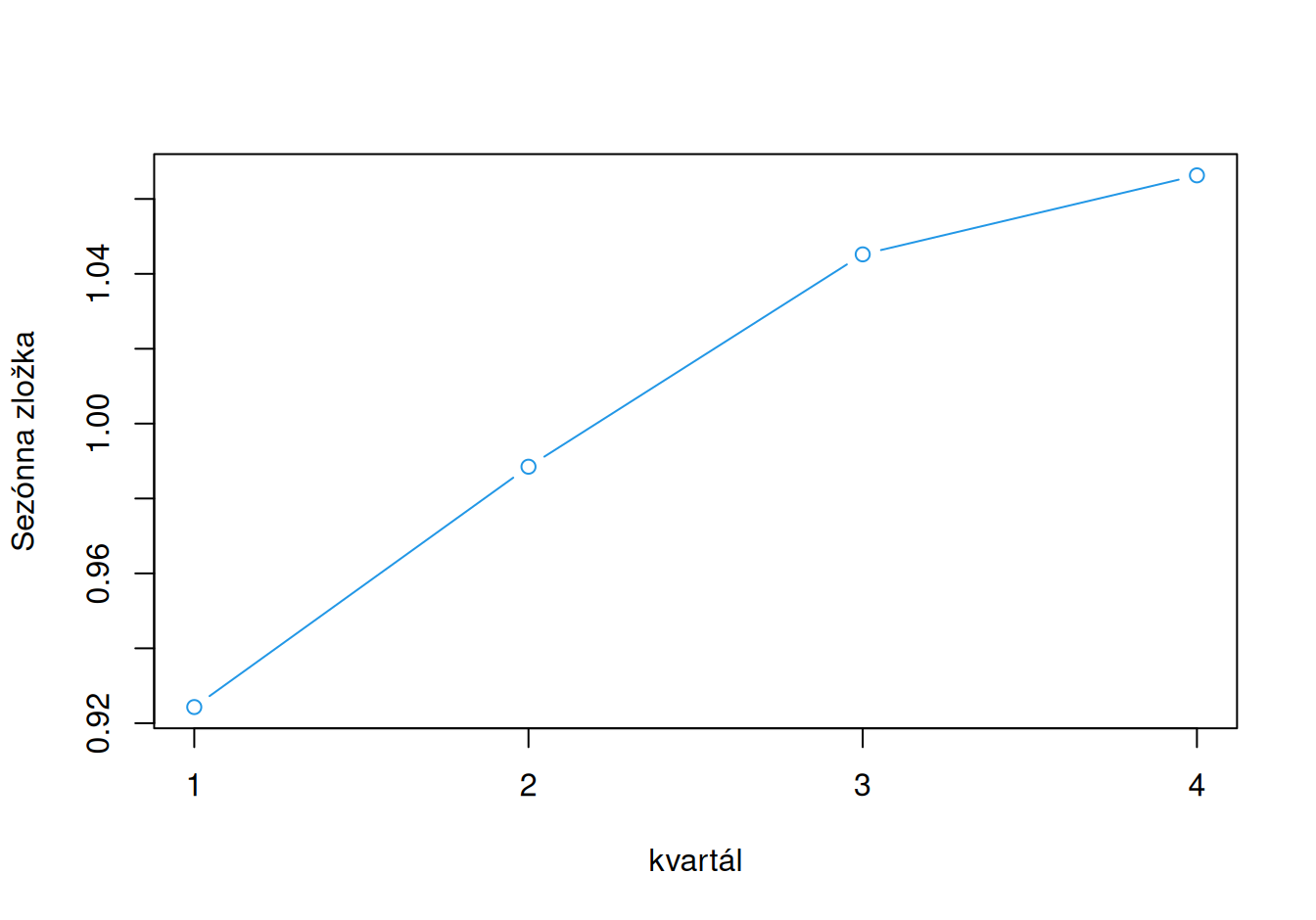
Hodnota HDP v prvom kvartáli dosahuje iba asi \(92.4\%\) hodnoty dlhodobého vývoja (trendu), zato v poslednom kvartáli ju presahuje o \((0.924 + 0.142 - 1) = 6.6\%\).
Vypočítame rezíduá po modeli sezónnej zložky a zobrazíme ich v časovej i spektrálnej doméne.
# výpočet
dat$train$resTS <- dat$train$resT / dat$train$SeaInd
# zobrazenie
with(dat$train, plot(resTS))
tmp <- dat$train$resTS |>
c() |> # odstránenie atribútov ts
fft() |> # fourierova transformácia
abs() |> (`^`)(2) |> (`/`)(2*pi*n$train) |> # normovanie na power spektrum
head(floor(n$train/2 + 1)) |> # odstránenie duplicít
data.frame() |> setNames("hustota") # umiestnenie do zoznamu
tmp$perióda <- n$train / seq(0, along.with = tmp$hustota)
plot(hustota ~ I(perióda/4), data = tmp[-1,], xlab="perióda (roky)",
type="h", log="x")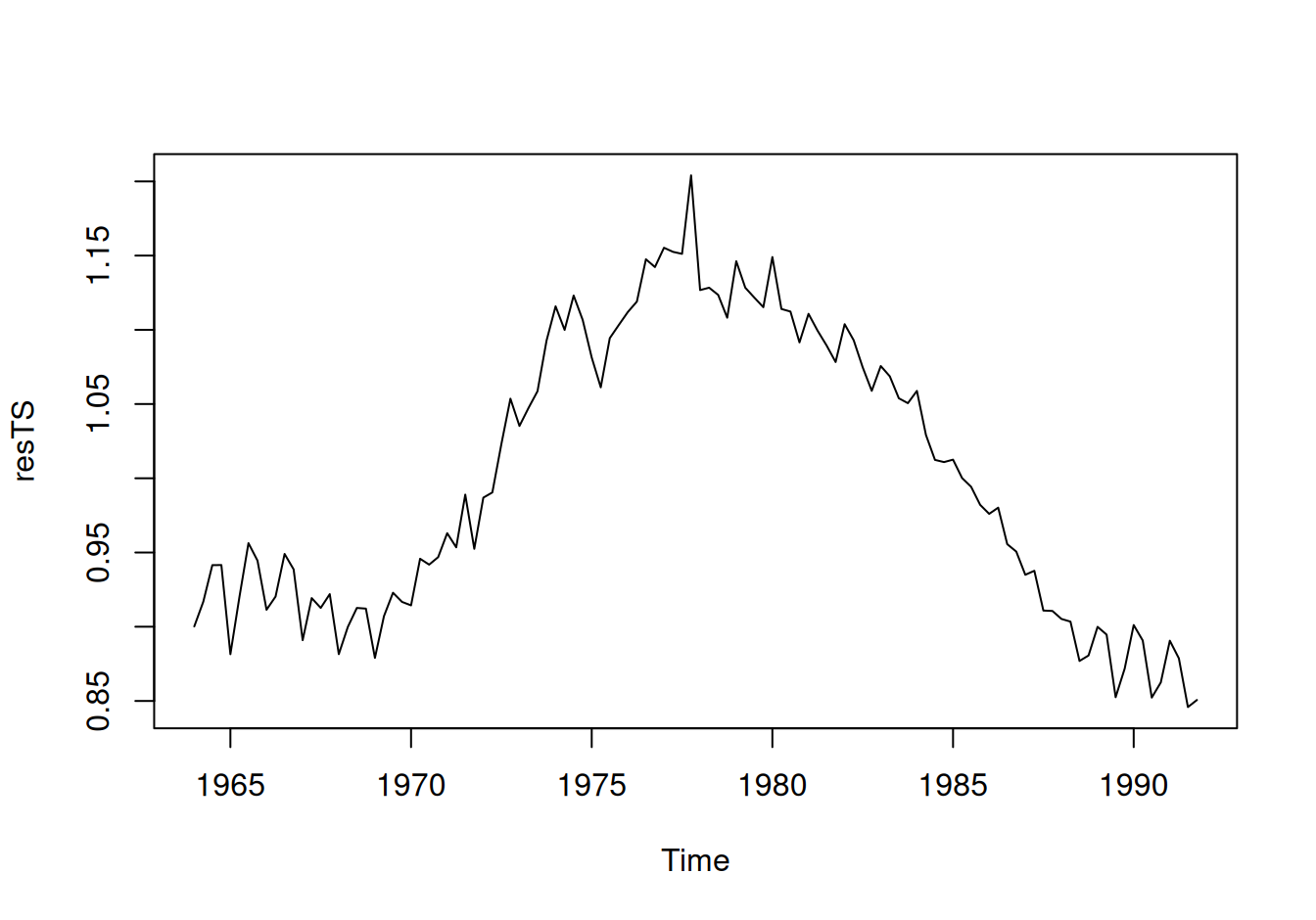
# zoradenie podľa hustoty
tmp <- tmp[order(tmp$hustota, decreasing = TRUE), ]
head(tmp, 3) hustota perióda
1 17.825353626 Inf
2 0.073992818 112.00000
4 0.002080989 37.33333Najvýznamnejšie sú dlhoperiodické zložky (prvá frekvencia diskrétneho spektra sa zo zjavných dôvodov nedá zobraziť do grafu s periódami na osi x). Môžeme zobraziť výsledky testu významnosti.
tmp |>
transform(TestŠtat = NA, KritHod = NA) |>
within({
m <- length(hustota)
for(i in 1:m) {
TestŠtat[i] <- hustota[i] / sum(hustota[i:m])
KritHod[i] <- 1 - (0.05/(m-i+1))^(1/(m-i))
if(TestŠtat[i] < KritHod[i]) break
}
rm(i,m)
}) |>
head(5) hustota perióda TestŠtat KritHod
1 1.782535e+01 Inf 0.9954739 0.1181141
2 7.399282e-02 112.000000 0.9129794 0.1198440
4 2.080989e-03 37.333333 0.2950658 0.1216292
3 1.719400e-03 56.000000 0.3458419 0.1234724
28 3.475316e-04 4.148148 0.1068592 0.1253767Keďže na tomto konci spektra sú diskrétne periódy zastúpené riedko, väčší zmysel má odhadnúť spojité spektrum. Vytvorili sme funkciu spektrálnej hustoty fun$SpecDens (pozri Pomocné funkcie), ktorej prvý argument je uhlová frekvencia \(\omega\), druhým je vektor autokovoariancií. Ak ten nie je funkcii poskytnutý, autokovariancie sa vypočítajú z dát v treťom argumente. Potom stupeň vyhladenia spektrálnej hustoty závisí od maximálneho posunu lag.max.
# autokovariancie pre rôzne lag.max
tmp <- c(
acf5y = 10*log10(n$train), # lagmax = 20 kvartálov = 5 rokov
acf28y = n$train # lagmax = 112 kvartálov = 28 rokov
) |>
lapply(acf, x = dat$train$resTS, type="covariance", plot=FALSE) |>
lapply(getElement, name = "acf") |>
lapply(as.numeric)
# zobrazenie spektrálnej hustoty pre oba sety ACF
tmpx <- seq(from = 5, to = 30, by = 0.1) # rozsah v rokoch
plot(tmpx, fun$SpecDens(2*pi / (4*tmpx), acov = tmp$acf28y), type="l")
plot(tmpx, fun$SpecDens(2*pi / (4*tmpx), acov = tmp$acf5y), type="l")
# alternatívne pomocou Lomb-Scargle periodogramu:
# (s argumentom times je citlivý na vyhladenie - ofac)
# lomb::lsp(dat$train$resTS, times = dat$train$rok, type = "period", ofac = 12)
# hľadanie extrémov v intervaloch
list(c(20,25),
c(10,13)
) |>
sapply(function(x) {
argmax <- optimize(fun$SpecDens,
interval = 2*pi / 4 / rev(x),
data = dat$train$resTS,
maximum = TRUE
)$maximum
2*pi/(4*argmax) # konverzia na periódu v rokoch
})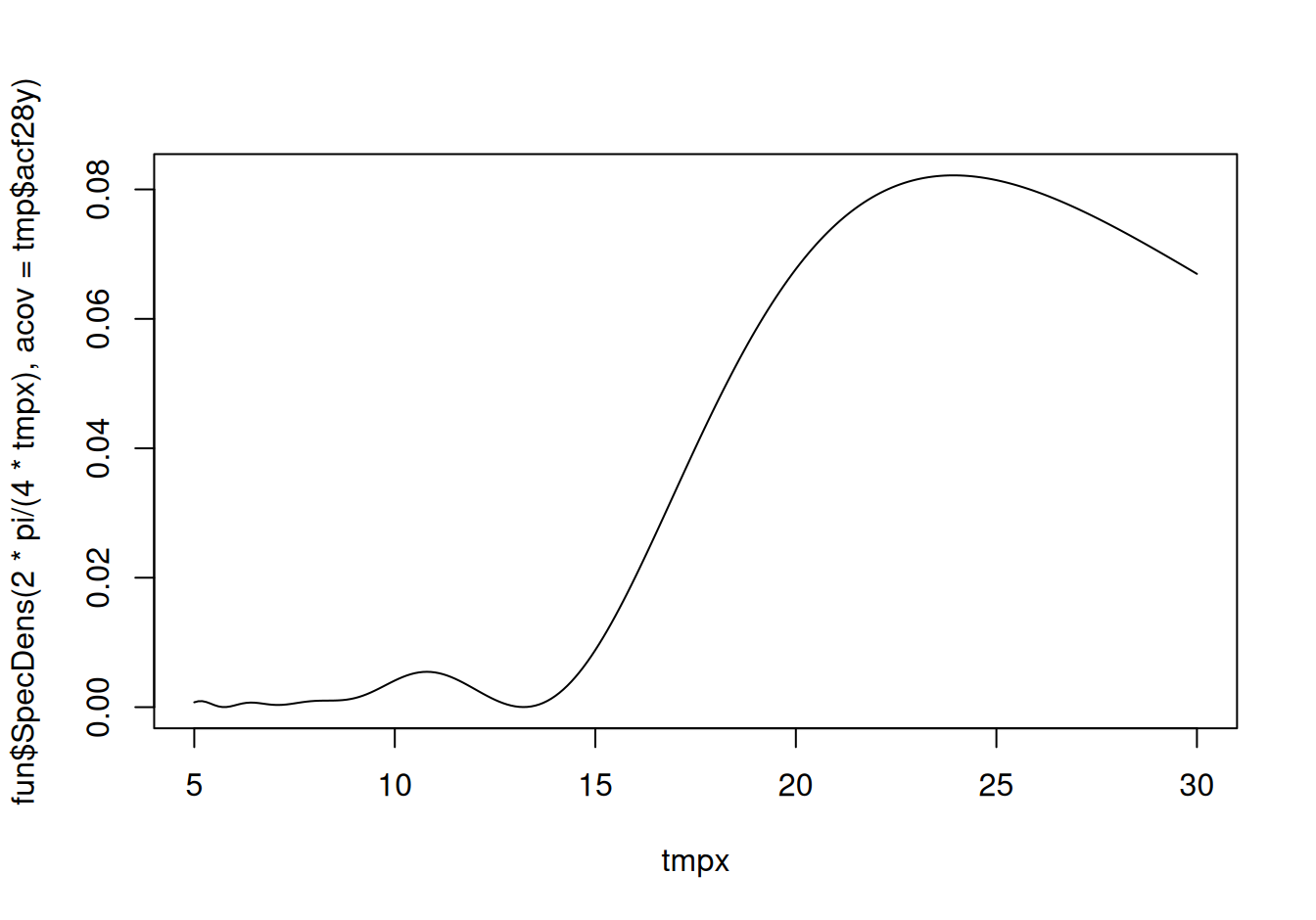
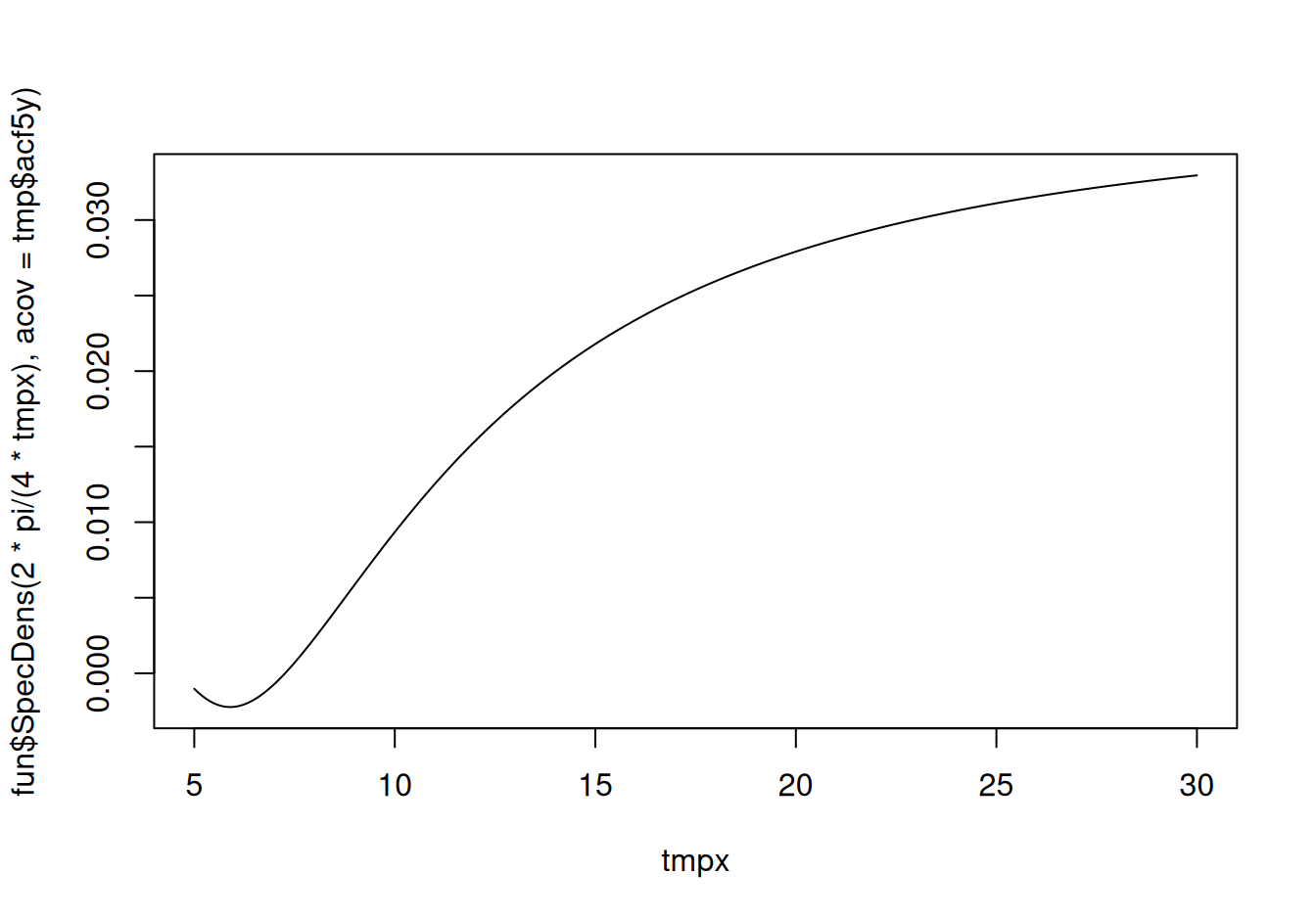
[1] 23.92853 10.80138Nájdené periódy zodpovedajú významným Fourierovým frekvenciám, skúsime teda obe zahrnúť do modelu.
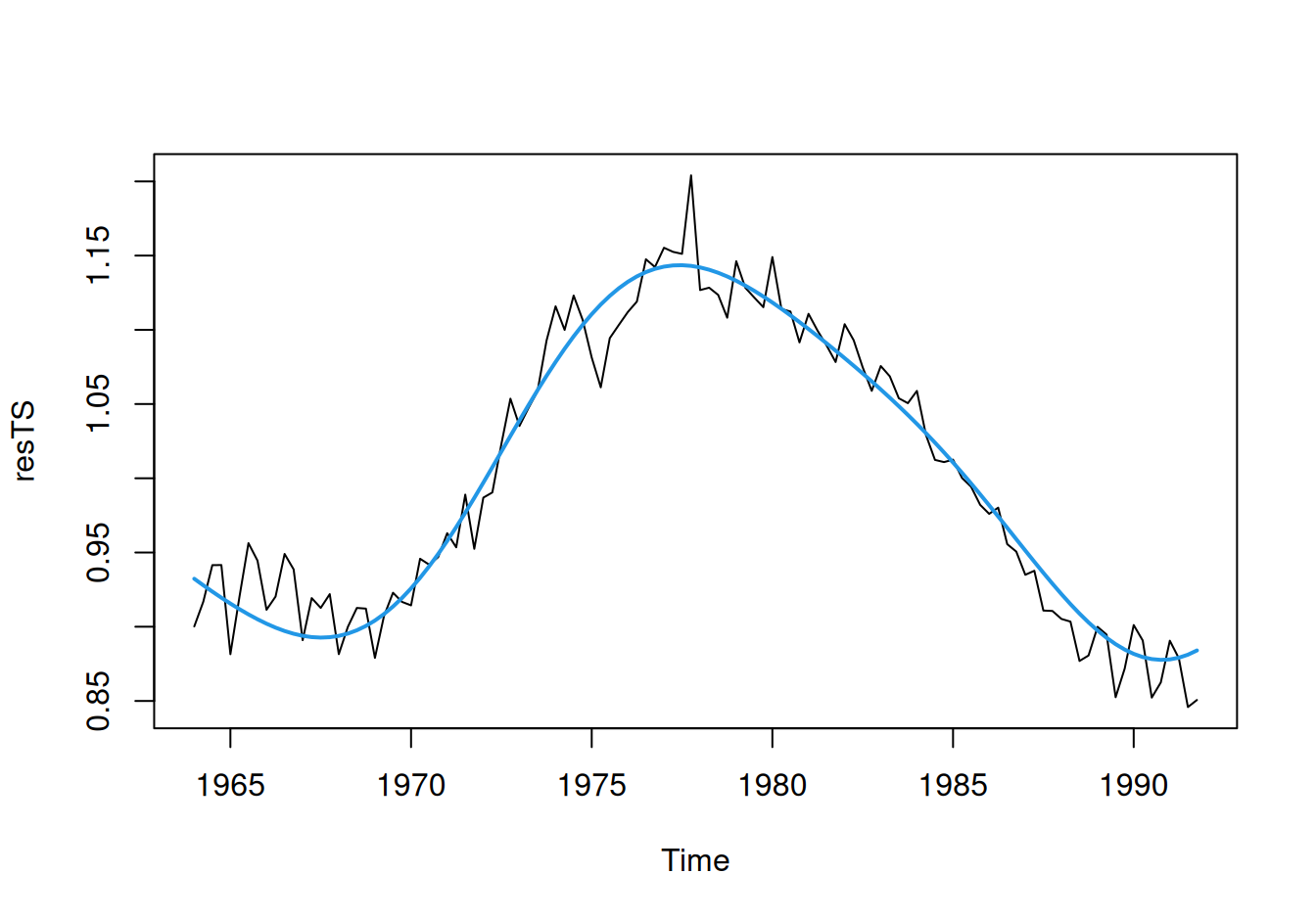
# odhad modelu
fit$Cyc2411 <- lm(resTS ~ cos(2*pi*rok/23.9) + sin(2*pi*rok/23.9) +
cos(2*pi*rok/10.8) + sin(2*pi*rok/10.8),
data = dat$train)
# amplitúdy zodpovedajúce jednotlivým periódam
fit$Cyc2411$coefficients[-1] |> # výber parametrov okrem absol.člena
split(rep(c(24,11), each=2)) |> # rozdelenie po zložkách
sapply(norm, type="2") |> # výpočet amplitúdy (L2 normy)
round(3) 11 24
0.016 0.126 # stredné hodnoty
dat$train$Cyc2411 <- fit$Cyc2411 |> fitted() |>
ts() |> `tsp<-`(tsp(dat$train$HDP))
# zobrazenie
with(dat$train, {
plot(resTS)
lines(Cyc2411, col = 4, lwd = 2)
})
Pôvod zložiek nepravidelných cyklických fluktuácií býva zvyčajne nejasný a pri dlhších periódach sa nemusí zopakovať (čo indikuje nedostatočne vystihnutý trend), preto v ďalšej časti, pri vytvorení spoločného modelu systematických zložiek pridáme alternatívny model so zložitejším trendom a bez cyklickej zložky.
Štandardný lineárny model je aditívny, preto časový rad budeme modelovať transformovaný – v logaritmickej mierke. Jednotlivé zložky sa potom dajú získať spätnou transformáciou.
# odhad modelu
# Závislosť od premennej Q nahradíme definovaním bázovej funkcie, ušetrí to prácu
# pri konštrukcii matice plánu spoločného modelu systematických a náhodnej zložky.
fit$SystTlinC <- lm(log(HDP) ~
rok + # trend
factor(((rok %% 1) * 4) + 1) + # sezónnosť
cos(2*pi*rok/23.9) + sin(2*pi*rok/23.9) +
cos(2*pi*rok/10.8) + sin(2*pi*rok/10.8), # cykl.
dat$train)
# uloženie rezíduí
dat$train$resSystTlinC <- fit$SystTlinC$residuals |>
ts() |> 'tsp<-'(tsp(dat$train$HDP))
# extrakcia zložiek modelu a zobrazenie
tmp <- fit$SystTlinC |> predict(type = "terms")
with(data.frame(rok = dat$train$rok,
trend = tmp[,1],
sez = tmp[,2],
cykl = rowSums(tmp[,3:6]),
rez = dat$train$resSystTlinC
),
{
# graf zložiek
plot(trend ~ rok, type = "l", ylab="")
lines(sez ~ rok)
lines(cykl ~ rok)
# intenzita zložiek
cat("Intenzita systematických zložiek: \n")
rezvar <- var(rez)
(1 - rezvar/c(trend = var(trend + rez),
sezónnosť = var(sez + rez),
cykl.zložka = var(cykl + rez)
)
) |> round(2)
}
)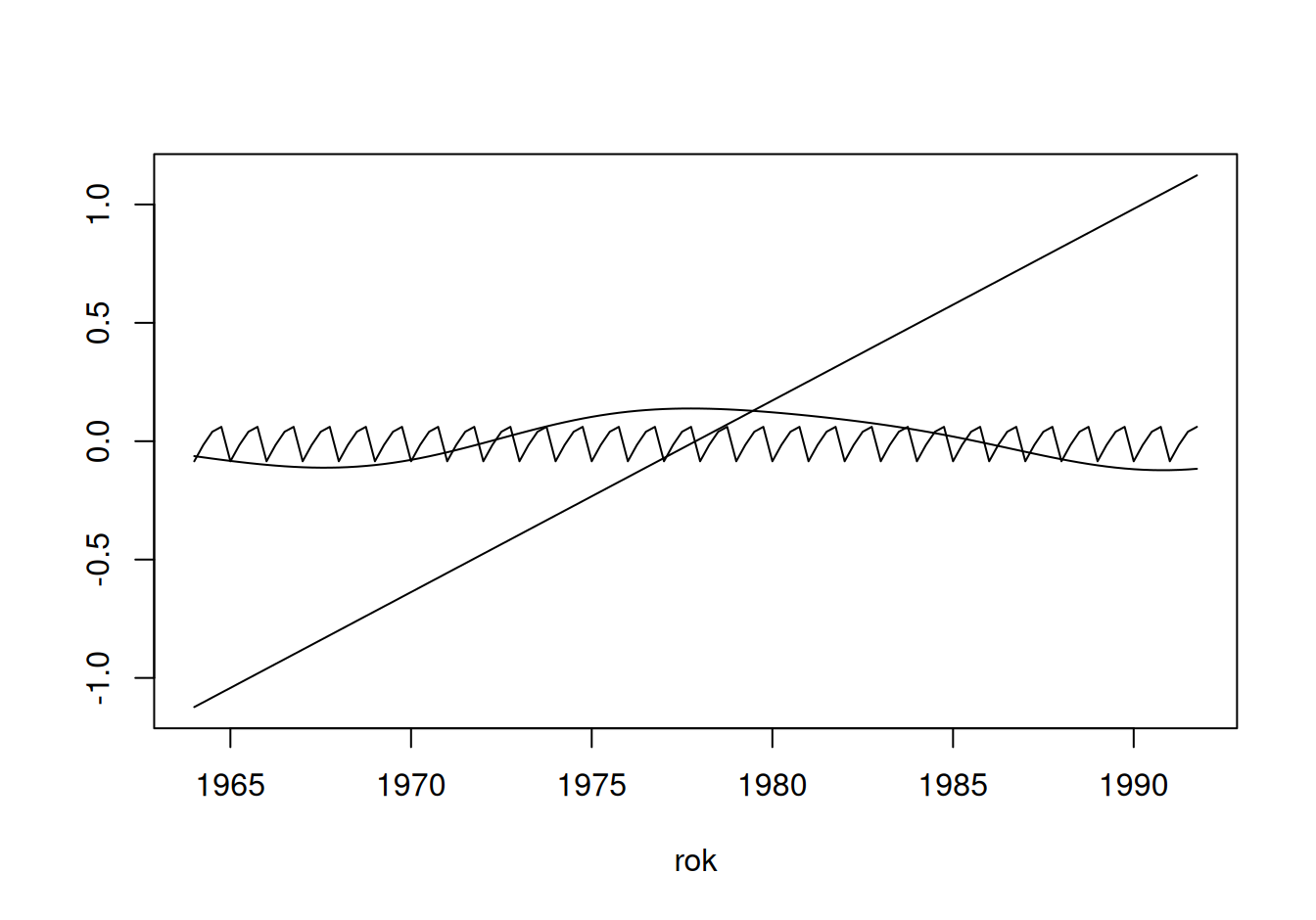
Intenzita systematických zložiek: trend sezónnosť cykl.zložka
1.00 0.90 0.96 # poskladanie do jednej krivky a superpozícia s pozorovaniami
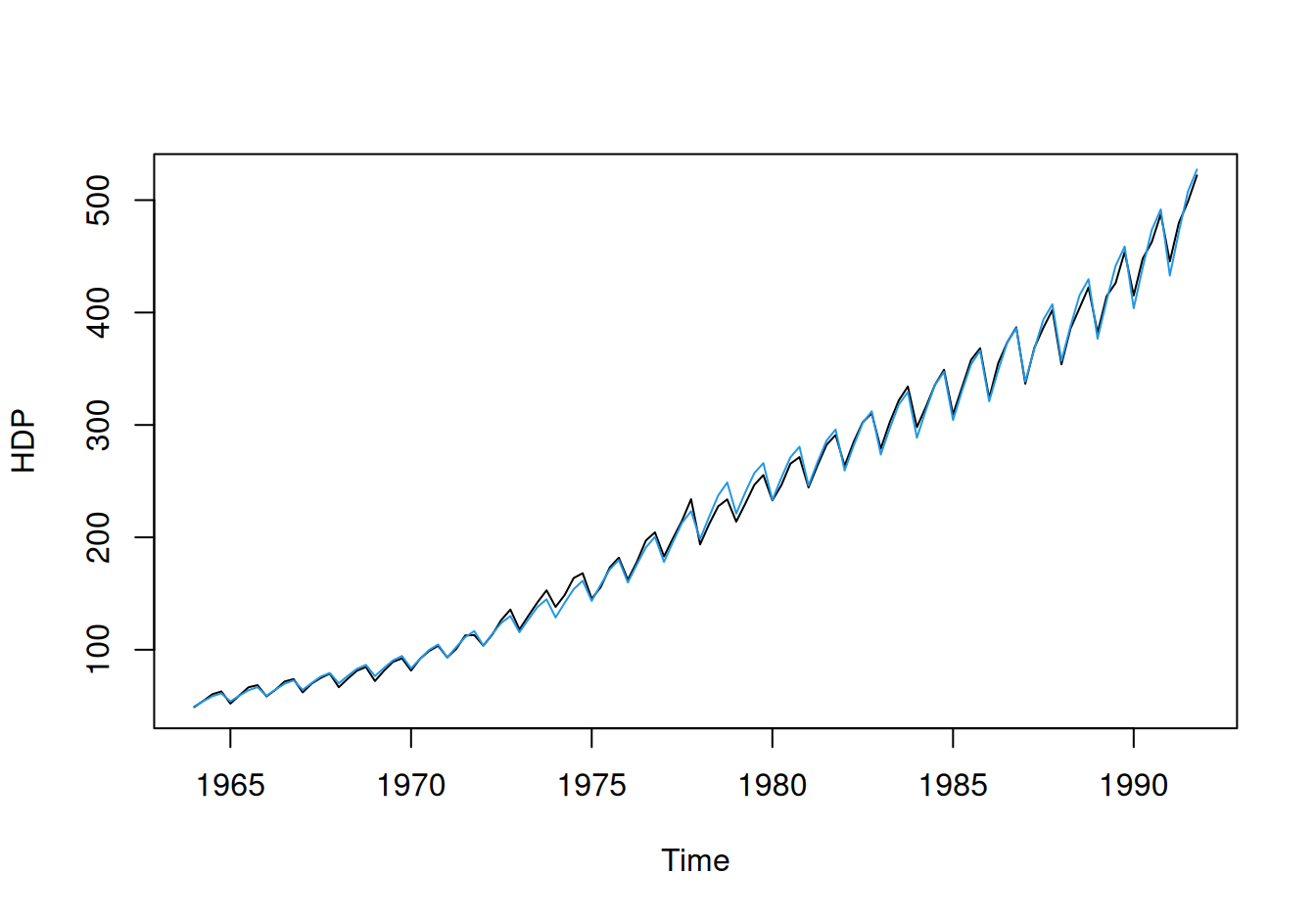
plot(c(HDP) ~ rok, dat$train, type = "l", ylab = "HDP")
(rowSums(tmp) + attr(tmp, "constant") ) |>
exp() |>
lines(x = dat$train$rok, col = 4)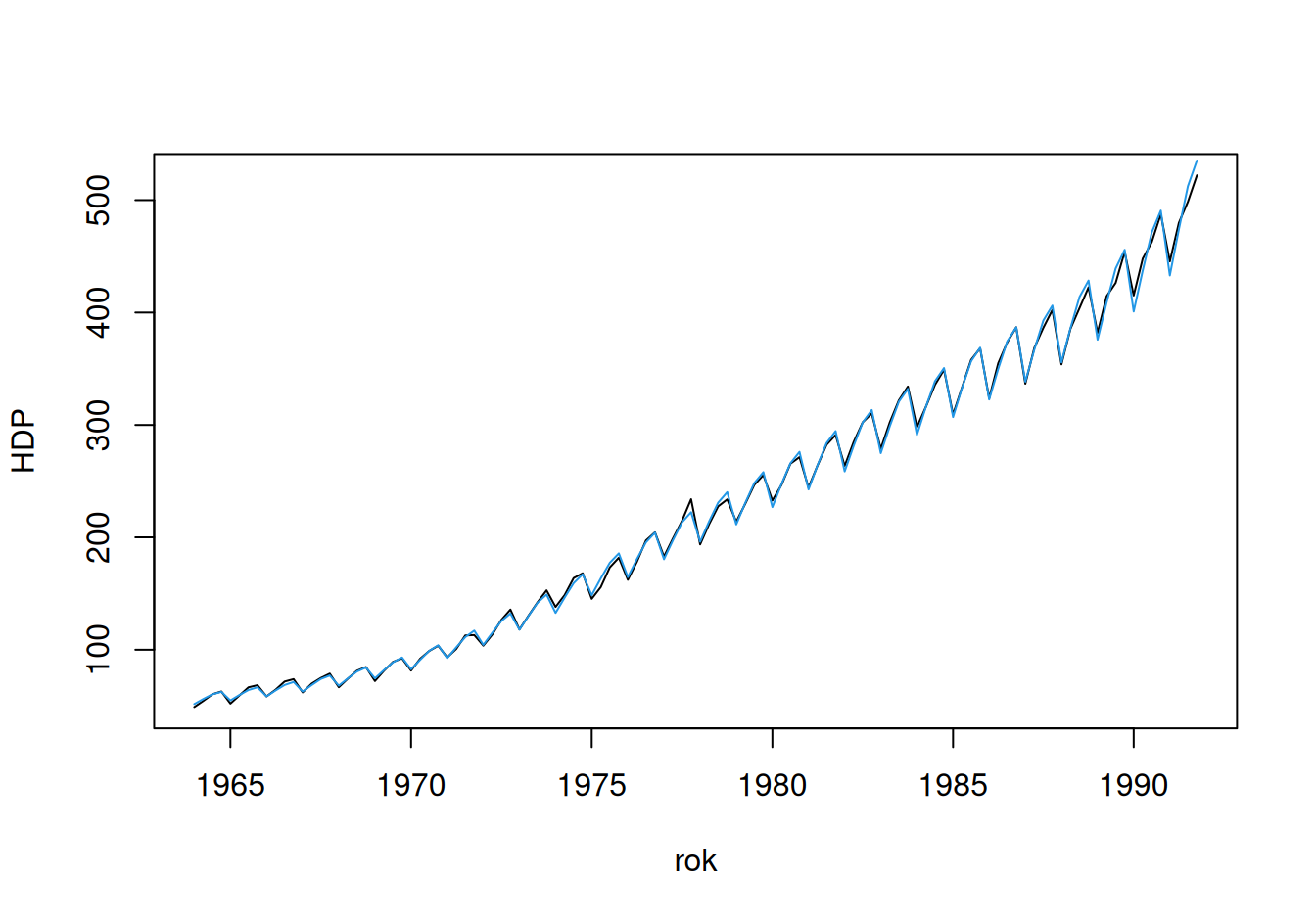
Okrem modelu so zložkami odhalenými v predošlej analýze postavíme aj model s lineárnym lomeným (t.j. po častiach lineárnym) trendom. Uzly (lomové body) identifikujeme približne – z grafu rezíduí po lineárnom trende a sezónnej zložke – ako roky 1970, 1979 a 1989. Podrobnejšie sa téme venuje tzv. detekcia zmien v časových radoch (angl. changepoint detection).
# lineárny lomený trend (lineárny splajn pomocou jednej triedy bázových funkcií)
fit$SystTpwl <- lm(
log(HDP) ~
rok + pmax(0, rok - 1970) + pmax(0, rok - 1979) + pmax(0, rok - 1989) + # trend
factor(((rok %% 1) * 4) + 1), # sezónnosť
dat$train)
dat$train$resSystTpwl <- fit$SystTpwl$residuals |>
ts() |> 'tsp<-'(tsp(dat$train$HDP))
# Riešenie pomocou B-spline z balíku splines, nevýhoda je v ťažšej interpretácii
# parametrov, pretože používa iné bázové funkcie:
# fit$SystTpwl <- lm(
# log(HDP) ~
# splines::bs(rok, knots = c(1970, 1979, 1989), degree = 1) + # trend
# Q, # sezónnosť
# dat$train)
# zobrazenie
with(dat$train, {
plot(HDP)
fit$SystTpwl |> fitted() |> exp() |>
ts() |> 'tsp<-'(tsp(HDP)) |>
lines(col = 4)
})
# Optimalizácia bodov zmeny pomocou balíku segmented:
# tmp <- lm(log(HDP) ~ rok + Q, dat$train) |>
# segmented::segmented( seg.Z = ~ rok, psi = c(1970, 1979, 1989))
# tmp$psi # odhadnuté roky, v ktorých malo prísť ku zmene
# plot(c(log(HDP)) ~ rok, dat$train, type = "l")
# plot(tmp, col=4, add=T)Model síce má ešte rezervy v popise radu v polovici obdobia (to by šlo vyriešiť pridaním jedného uzla), no zároveň dáva väčšiu nádej, že predpovede budú v súlade s realitou, keďže prihliada na vývoj po poslednej zmene (v roku 1989).
V rámci interpretácie modelu zistíme tempo rastu v jednotlivých obdobiach.
fit$SystTpwl$coefficients |>
(`[`)(2:5) |> # výber parametrov zodpovedajúcich trendu
cumsum() |> exp() |> round(3) |> # sklony jednotlivých segmentov sú prírastkové
setNames(c("do 1970", "do 1979", "do 1989", "po 1989"))do 1970 do 1979 do 1989 po 1989
1.091 1.114 1.055 1.072 Model teda predpokladá, že (ak sa nič nezmení) HDP bude naďalej medziročne rásť o 7,2%.
Zobrazíme rezíduá z oboch modelov a ich (parciálne) autokorelačné funkcie.
# zobrazenie
with(dat$train, {
# rezíduá
plot(resSystTlinC, type = "l")
plot(resSystTpwl, type = "l")
# acf/pacf
fun$AcfPacf(resSystTlinC)
fun$AcfPacf(resSystTpwl)
})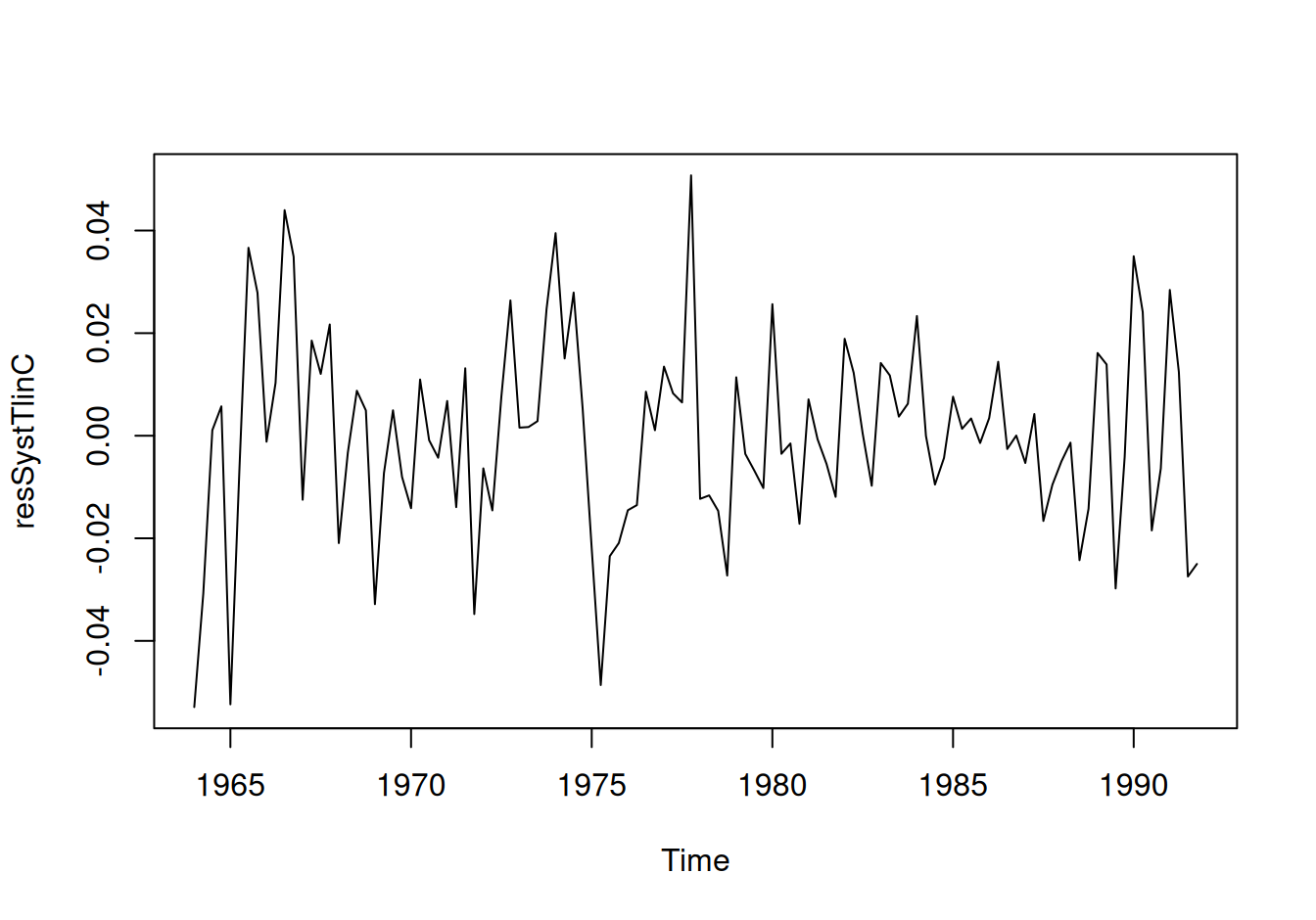
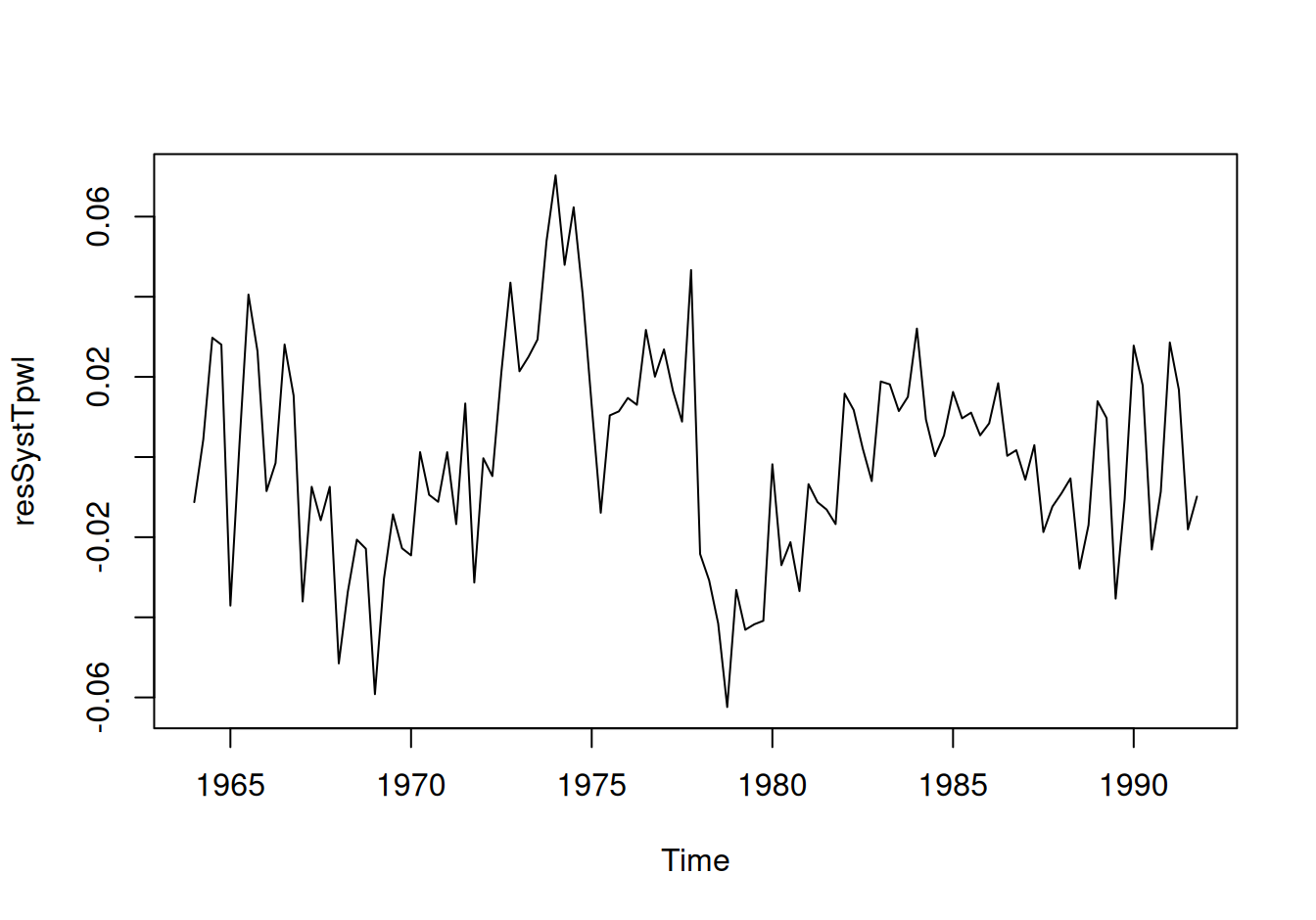
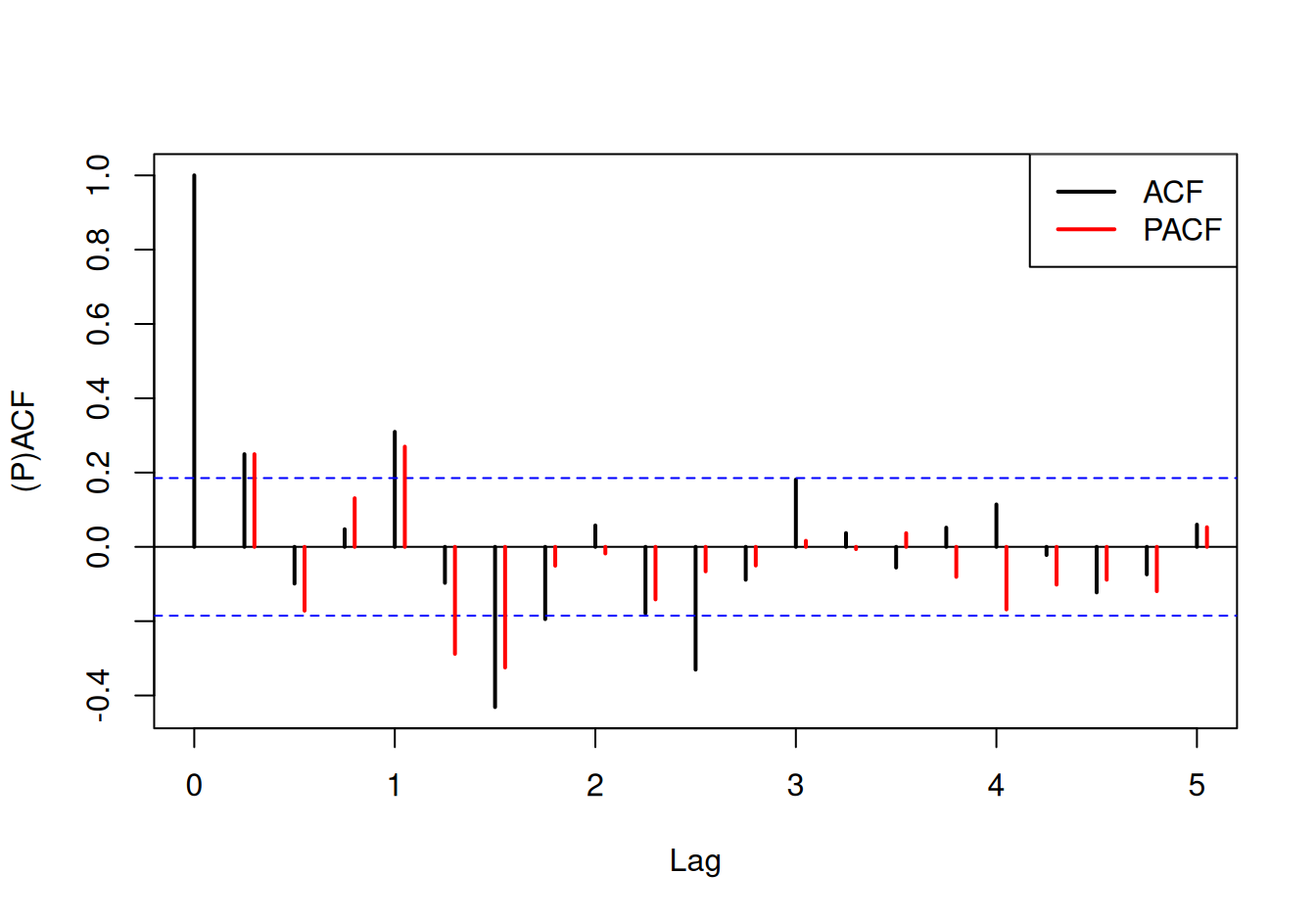
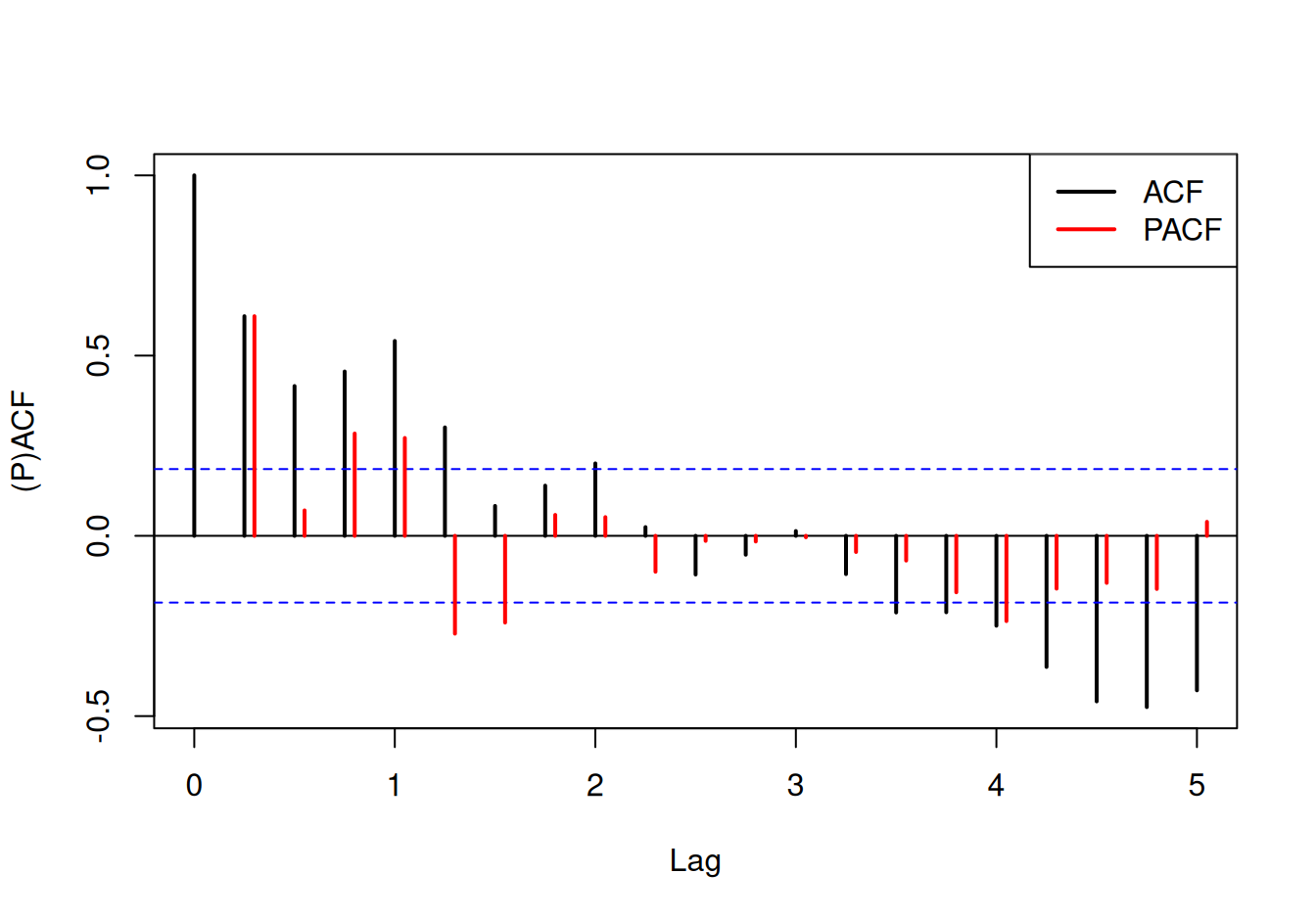
Zdá sa, že rezíduá druhého modelu sú šte zaťažené nejakým systematickým vplyvom. Situáciu by pravdepodobne zlepšila citlivejšia voľba počtu a umiestnenia uzlov lomeného trendu (ideálne podľa skutočných udalostí, ktoré zásadne ovplyvnili ekonomický vývoj krajiny). Ponecháme ho však v tomto tvare ako alternatívu pre porovnanie predpovedných schopností.
Stupne ARMA procesu sú v oboch prípadoch nejednoznačné, možno bude stačiť AR(1). Voľbu ponecháme na parametrickú identifikáciu v rámci Hannan-Rissanenovej procedúry. Vzhľadom na vysoké maximálne hodnoty stupňov \(p\) a \(q\) by metóda hrubej sily bola časovo náročná. Výstupom sú hodnoty BIC vypočítané dvoma spôsobmi: pomocou rozptylu rezíduí a pomocou funkcie vierohodnosti.
# Identifikácia pre rezíduá po modeli s lineárnym trendom a cyklickou zložkou:
tmp <- fun$HannanRissanen(dat$train$resSystTlinC, pmax = 6, qmax = 6, kmax = 10)
plot(scale(tmp$BIC["varBIC",]), xlab="p,q", ylab="normované BIC", main="ARMA(p,q) pre resSystTlinC",
xaxt="n", type="b") # naše BIC vypočítané z reziduálneho rozptylu
points(scale(tmp$BIC["likBIC",]), col="blue", type="b") # vstavané BIC z vierohodnosti
axis(1, at=1:ncol(tmp$BIC), labels=colnames(tmp$BIC), las=2, cex.axis=0.6) # zobrazenie popisov
# Identifikácia pre rezíduá po modeli s po častiach lineárnym trendom:
tmp <- fun$HannanRissanen(dat$train$resSystTpwl, pmax = 6, qmax = 6, kmax = 8)
plot(scale(tmp$BIC["varBIC",]), xlab="p,q", ylab="normované BIC", main="ARMA(p,q) pre resSystTpwl",
xaxt="n", type="b") # naše BIC vypočítané z reziduálneho rozptylu
points(scale(tmp$BIC["likBIC",]), col="blue", type="b") # vstavané BIC z vierohodnosti
axis(1, at=1:ncol(tmp$BIC), labels=colnames(tmp$BIC), las=2, cex.axis=0.6) # zobrazenie popisov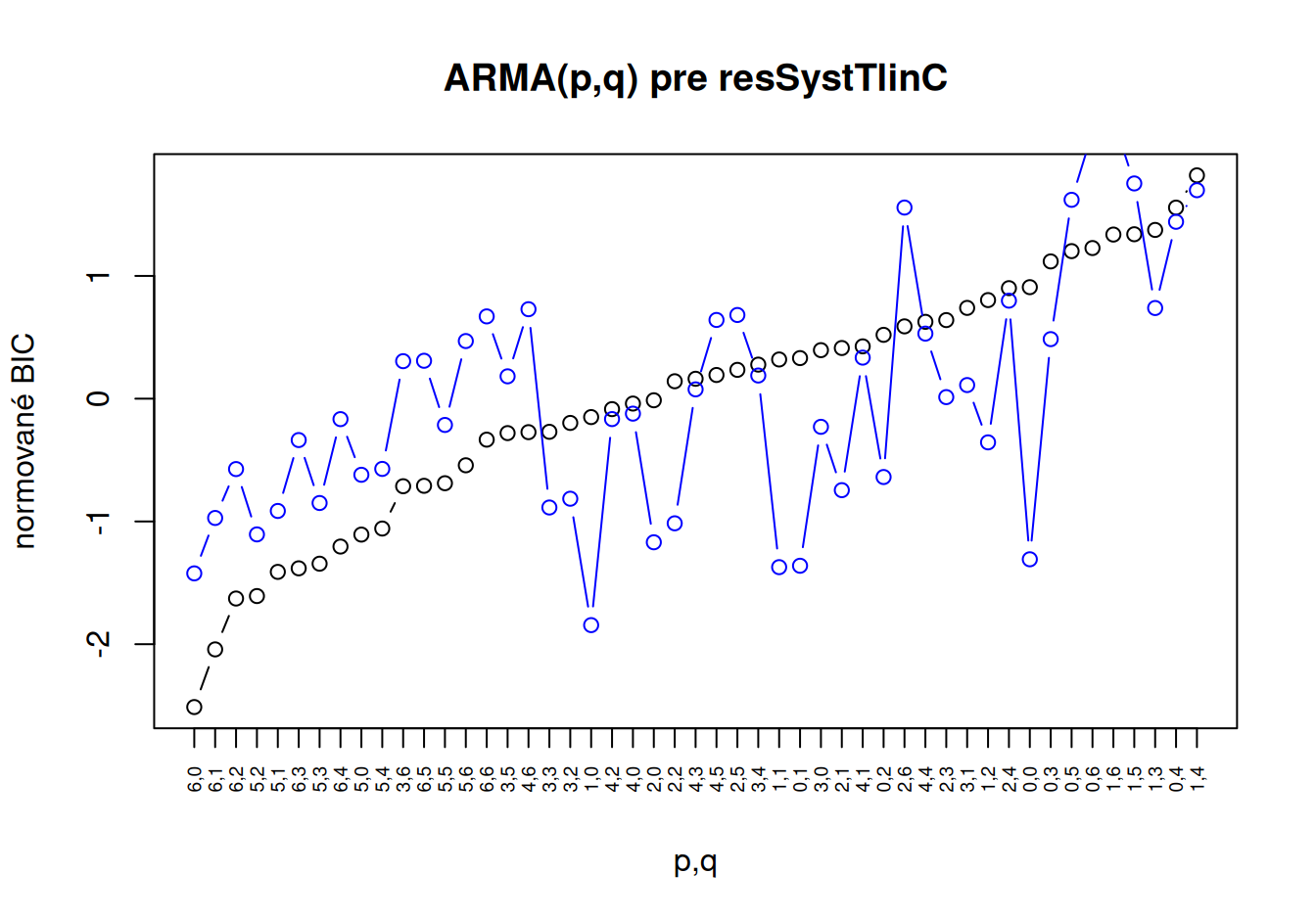
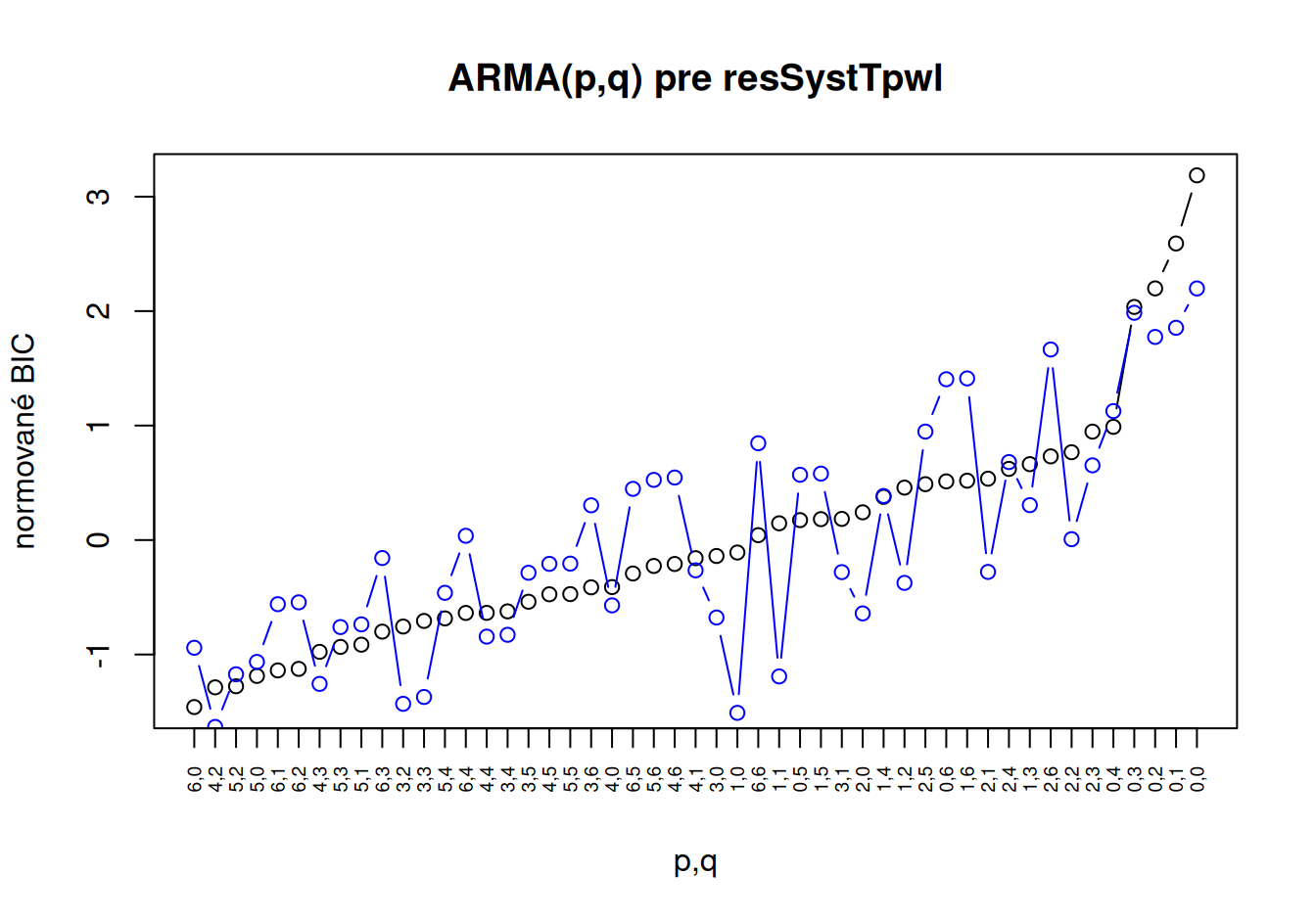
V oboch prípadoch sa ako vhodné ukazujú modely AR(1) alebo AR(6), v druhom prípade do úvahy prichádza ešte i ARMA(4,2).
Keďže je reziduálna zložka oproti systematickým zložkám subtílna (ich intenzita je vysoká), voľba jej modelu veľmi neovplyvní predpovednú schopnosť spoločného modelu. Preto by nebolo chybou zvoliť iba ten najjednoduchší a teda i šahšie interpretovateľný model AR(1). My budeme pre ilustráciu pokračovať s dvoma alternatívami pri každom reziduálnom rade.
fit$Res <- list(
TlinC = list(
ARMA10 = arima(dat$train$resSystTlinC, order = c(1,0,0)),
ARMA60 = arima(dat$train$resSystTlinC, order = c(6,0,0))
),
Tpwl = list(
ARMA10 = arima(dat$train$resSystTpwl, order = c(1,0,0)),
ARMA42 = arima(dat$train$resSystTpwl, order = c(4,0,2))
)
)Z diagnostiky preveríme stacionaritu (vzdialenosťou koreňov AR polynómu od [0,0] v komplexnej rovine), autokoreláciu (Box-Pierce testom) a normalitu rezíduí (Shapiro testom).
local({
for(i in names(fit$Res)) {
cat(i,"\n ----- \n")
for(j in names(fit$Res[[i]])) {
cat(j,"\n")
model <- fit$Res[[i]][[j]]
cat("stacionarita: ",
coef(model) |> head(model$arma[1]) |> append(values=1, after=0) |> polyroot() |> Mod() |> round(2),
"\n")
cat("nekorelovanosť: ",
sapply(1:11, function(x) Box.test(model$residuals, lag=x)$p.value) |> round(3),
"\n")
cat("normalita: ",
shapiro.test(model$residuals)$p.value |> round(3), " ",
tseries::jarque.bera.test(model$residuals)$p.value |> round(3),
"\n")
}
cat("\n")
}
})TlinC
-----
ARMA10
stacionarita: 3.7
nekorelovanosť: 0.767 0.117 0.231 0.001 0.001 0 0 0 0 0 0
normalita: 0.351 0.232
ARMA60
stacionarita: 1.1 1.08 1.08 1.1 1.25 1.34
nekorelovanosť: 0.885 0.922 0.935 0.71 0.827 0.704 0.802 0.862 0.744 0.53 0.405
normalita: 0.027 0.131
Tpwl
-----
ARMA10
stacionarita: 1.65
nekorelovanosť: 0.681 0.422 0.516 0 0 0 0 0 0 0 0
normalita: 0.025 0.183
ARMA42
stacionarita: 1.24 0.88 1.24 2.17
nekorelovanosť: 0.639 0.552 0.746 0.827 0.913 0.936 0.966 0.984 0.968 0.973 0.985
normalita: 0.091 0.062 Vidíme, že po AR(1) modeloch zostávajú rezíduá korelované od posunu 4. Normalitu na hladine významnosti 2% nezamietame ani pri jednom modeli. Stacionarita nie je splnená iba pri modeli ARMA(4,2), existuje pri ňom riziko explozívnosti, čo nie je vlastnosť vhodná pre predpovedanie.
Na odhad spoločného modelu systematických a náhodnej zložky opäť použijeme funkciu stats::arima, konštrukciu regresnej matice si však tentokrát uľahčíme jej prevzatím zo spoločného modelu systematických zložiek.
fit$All <- list(
TlinC_ARMA60 = arima(log(dat$train$HDP),
order = fit$Res$TlinC$ARMA60$arma[c(1,6,2)], # c(6,0,0)
xreg = model.matrix(fit$SystTlinC),
include.mean = FALSE
),
Tpwl_ARMA42 = arima(log(dat$train$HDP),
order = fit$Res$Tpwl$ARMA42$arma[c(1,6,2)], # c(4,0,2)
xreg = model.matrix(fit$SystTpwl),
include.mean = FALSE
)
)
# uloženie stredných hodnôt
dat$train[paste0("All_", names(fit$All))] <- fit$All |>
lapply(fun$fitted.arima) |>
lapply(exp) |>
as.data.frame() Začneme viackrokovými predpoveďami.
# naivná predpoveď
dat$valid$forMulti_Naive <- dat$train$HDP |>
tail(1) |> rep(length.out = n$valid) |>
ts() |> `tsp<-`(tsp(dat$valid$HDP))
tmp <- dat$train$HDP |> log() |> diff() |> (`^`)(2) |> mean() # reziduálny rozptyl
dat$valid <- dat$valid |>
transform(
forMultiLo_Naive = exp( log(forMulti_Naive) - 2*sqrt(tmp*(1:n$valid)) ),
forMultiUp_Naive = exp( log(forMulti_Naive) + 2*sqrt(tmp*(1:n$valid)) )
)
# sezónne naivná
dat$valid$forMulti_SNaive <- dat$train$HDP |>
tail(4) |> rep(length.out = n$valid) |>
ts() |> `tsp<-`(tsp(dat$valid$HDP))
tmp <- dat$train$HDP |> log() |> diff(lag = 4) |> (`^`)(2) |> mean() # reziduálny rozptyl
dat$valid <- dat$valid |>
transform(
forMultiLo_SNaive = exp( log(forMulti_SNaive) - 2*sqrt(tmp*(1:n$valid)) ),
forMultiUp_SNaive = exp( log(forMulti_SNaive) + 2*sqrt(tmp*(1:n$valid)) )
)
# z našich modelov
# Regresnú maticu vypočítame pomocou model.matrix z modelu syst.zložiek a validačnej vzorky.
tmp <- predict(fit$All$TlinC_ARMA60,
n.ahead = n$valid,
newxreg = model.matrix(fit$SystTlinC, data = dat$valid)
)
dat$valid <- dat$valid |>
transform(
forMulti_TlinC_ARMA60 = exp( tmp$pred ), # stredná hodnota
forMultiLo_TlinC_ARMA60 = exp( tmp$pred - 2*tmp$se ),
forMultiUp_TlinC_ARMA60 = exp( tmp$pred + 2*tmp$se )
)
tmp <- predict(fit$All$Tpwl_ARMA42,
n.ahead = n$valid,
newxreg = model.matrix(fit$SystTpwl, data = dat$valid)
)
dat$valid <- dat$valid |>
transform(
forMulti_Tpwl_ARMA42 = exp( tmp$pred ), # stredná hodnota
forMultiLo_Tpwl_ARMA42 = exp( tmp$pred - 2*tmp$se ),
forMultiUp_Tpwl_ARMA42 = exp( tmp$pred + 2*tmp$se )
)
with(dat$valid, {
# prvý model a naivná predpoveď
plot(HDP, type="b", xlab = "rok", main = "Viackroková predpoveď",
ylim = c(min(HDP,forMultiLo_Naive,forMultiLo_TlinC_ARMA60),
max(HDP,forMultiUp_Naive,forMultiUp_TlinC_ARMA60))
)
lines(forMulti_TlinC_ARMA60, col=4)
year <- time(HDP)
polygon(x = c(year, rev(year)),
y = c(forMultiLo_TlinC_ARMA60, rev(forMultiUp_TlinC_ARMA60)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forMulti_Naive, col=6)
lines(forMultiLo_Naive, col=6, lty="dashed")
lines(forMultiUp_Naive, col=6, lty="dashed")
legend("topleft", c("TlinC_ARMA60", "naivná"), col = c(4,6), lty = 1, bty="n")
# druhý model a sezónna naivná predpoveď
plot(HDP, type="b", xlab = "rok", main = "Viackroková predpoveď",
ylim = c(min(HDP,forMultiLo_SNaive,forMultiLo_Tpwl_ARMA42),
max(HDP,forMultiLo_SNaive,forMultiUp_Tpwl_ARMA42))
)
lines(forMulti_Tpwl_ARMA42, col=4)
year <- time(HDP)
polygon(x = c(year, rev(year)),
y = c(forMultiLo_Tpwl_ARMA42, rev(forMultiUp_Tpwl_ARMA42)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forMulti_SNaive, col=6)
lines(forMultiLo_SNaive, col=6, lty="dashed")
lines(forMultiUp_SNaive, col=6, lty="dashed")
legend("topleft", c("Tpwl_ARMA42", "sezónna naivná"), col = c(4,6), lty = 1, bty="n")
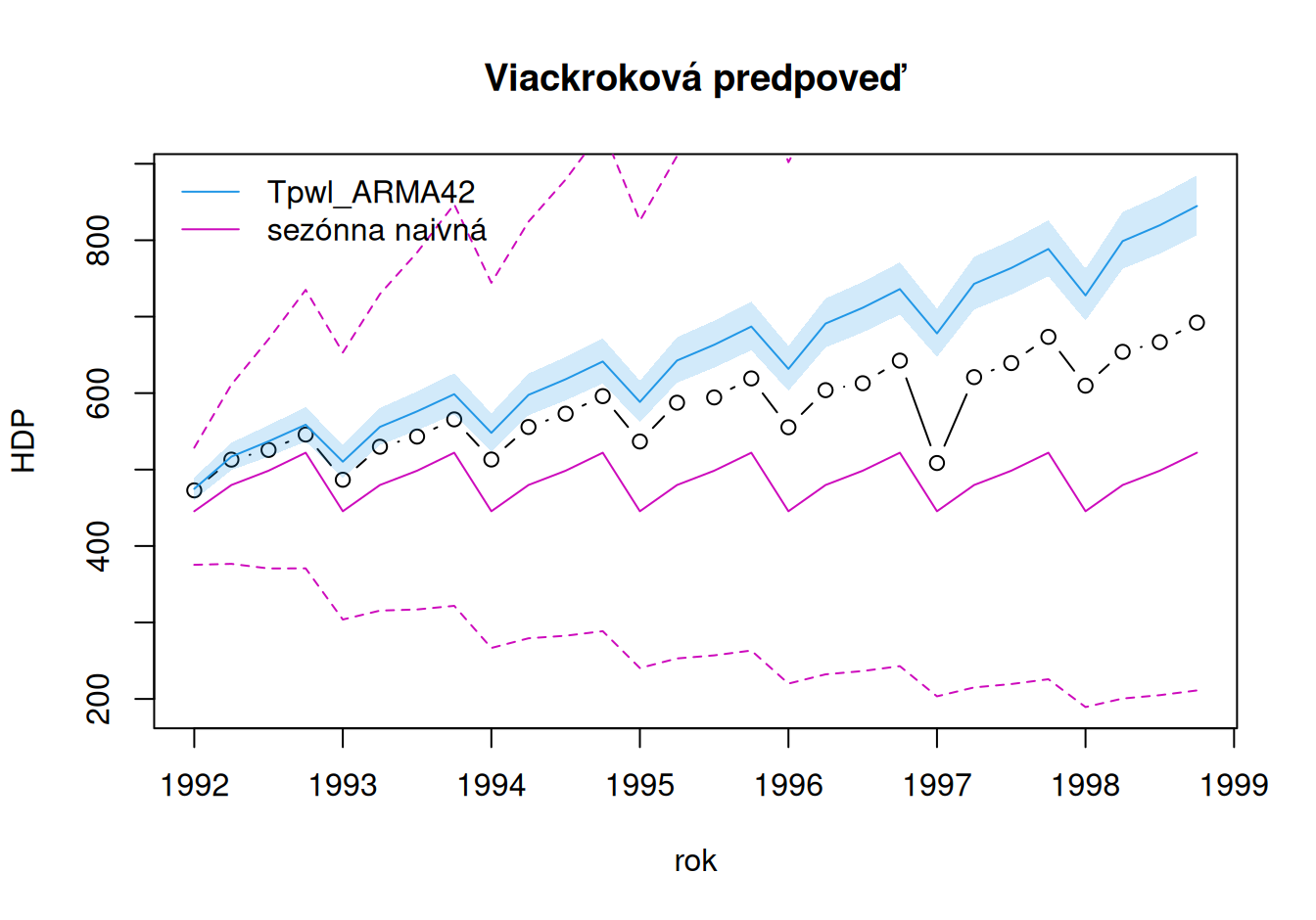
})
# numerické porovnanie
with(dat$valid, list(Naivné = cbind(forMulti_Naive, HDP),
"Sezónne naivné" = cbind(forMulti_SNaive, HDP),
TlinC_ARMA60 = cbind(forMulti_TlinC_ARMA60, HDP),
Tpwl_ARMA42 = cbind(forMulti_Tpwl_ARMA42, HDP)
)) |>
sapply(fun$MeanForecastError) |> t() |> round(2)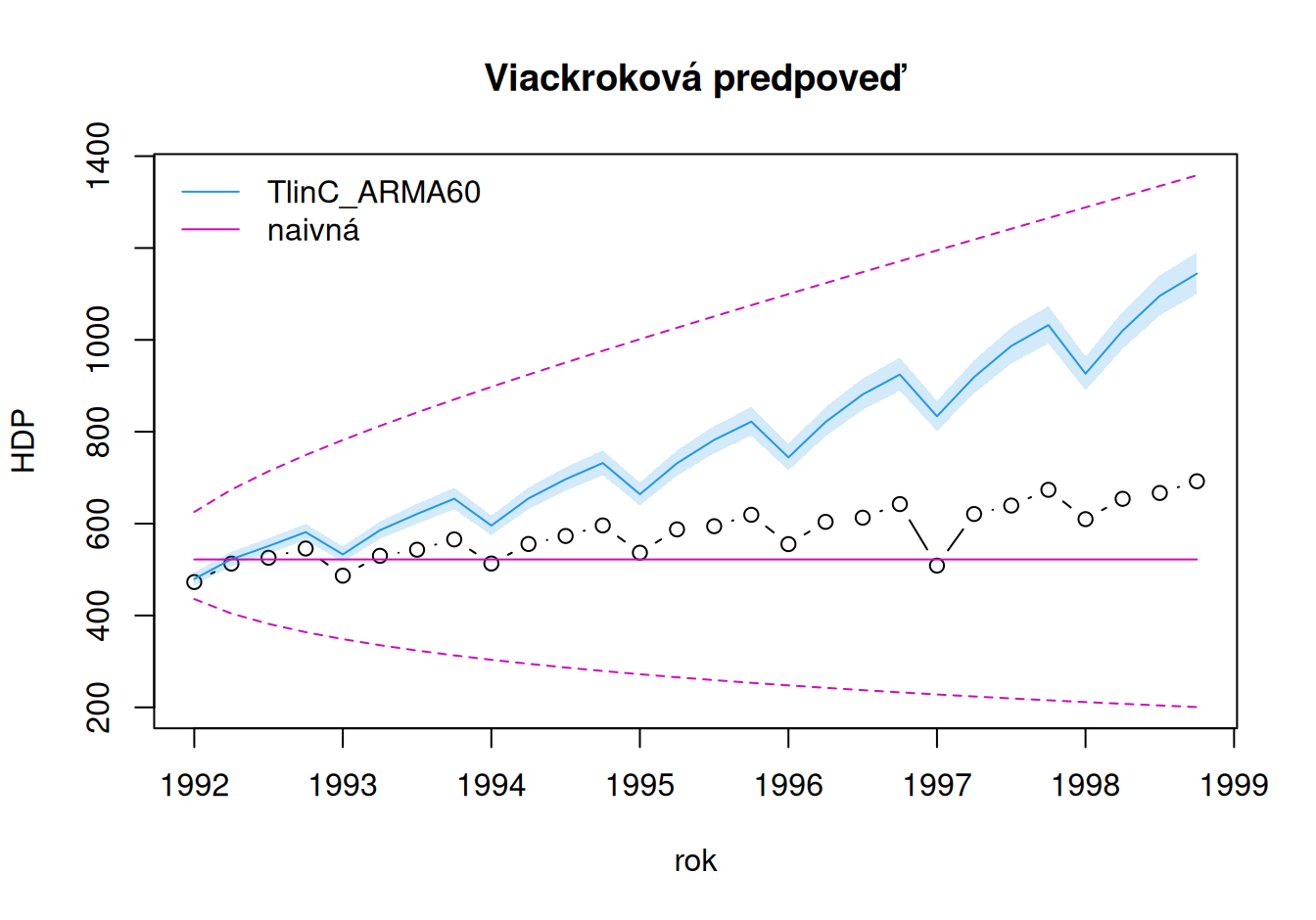
ME MSE RMSE MAE MAPE sMAPE MASE
Naivné 57.88 6693.60 81.81 66.17 10.78 11.63 1.65
Sezónne naivné 93.47 10981.59 104.79 93.47 15.56 17.17 2.33
TlinC_ARMA60 -189.25 53081.86 230.40 189.25 31.09 25.62 4.71
Tpwl_ARMA42 -71.85 7559.78 86.95 71.85 11.91 10.99 1.79Je vidieť, že voľba trendu má zásadný vplyv na úspešnosť predpovedí. Prvý model dobre neodhadol vývoj po poslednej zmene, preto sú jeho predpovede dokonca horšie ako naivná predpoveď.
Teraz vypočítame jednokrokové predpovede.
# naivná predpoveď
dat$valid$forOne_Naive <- dat$all$HDP[((n$train+1):n$all)-1] |>
ts() |> `tsp<-`(tsp(dat$valid$HDP))
tmp <- dat$train$HDP |> log() |> diff() |> (`^`)(2) |> mean() # reziduálny rozptyl
dat$valid <- dat$valid |>
transform(
forOneLo_Naive = exp( log(forOne_Naive) - 2*sqrt(tmp) ),
forOneUp_Naive = exp( log(forOne_Naive) + 2*sqrt(tmp) )
)
dat$valid$forOne_SNaive <- dat$all$HDP[((n$train+1):n$all)-4] |>
ts() |> `tsp<-`(tsp(dat$valid$HDP))
tmp <- dat$train$HDP |> log() |> diff(lag = 4) |> (`^`)(2) |> mean() # reziduálny rozptyl
dat$valid <- dat$valid |>
transform(
forOneLo_SNaive = exp( log(forOne_SNaive) - 2*sqrt(tmp) ),
forOneUp_SNaive = exp( log(forOne_SNaive) + 2*sqrt(tmp) )
)
# naše modely
tmp <- list(
pred = fun$Forecast(fit$All$TlinC_ARMA60,
newxreg = model.matrix(fit$SystTlinC, data = dat$valid),
valid = log(dat$valid$HDP)
) |> ts() |> 'tsp<-'(tsp(dat$valid$HDP)),
se = fit$All$TlinC_ARMA60$sigma2 |> sqrt() # SE rezíduí modelu
)
dat$valid <- dat$valid |>
transform(
forOne_TlinC_ARMA60 = exp( tmp$pred ), # stredná hodnota
forOneLo_TlinC_ARMA60 = exp( tmp$pred - 2*tmp$se ),
forOneUp_TlinC_ARMA60 = exp( tmp$pred + 2*tmp$se )
)
tmp <- list(
pred = fun$Forecast(fit$All$Tpwl_ARMA42,
newxreg = model.matrix(fit$SystTpwl, data = dat$valid),
valid = log(dat$valid$HDP)
) |> ts() |> 'tsp<-'(tsp(dat$valid$HDP)),
se = fit$All$Tpwl_ARMA42$sigma2 |> sqrt() # SE rezíduí modelu
)
dat$valid <- dat$valid |>
transform(
forOne_Tpwl_ARMA42 = exp( tmp$pred ), # stredná hodnota
forOneLo_Tpwl_ARMA42 = exp( tmp$pred - 2*tmp$se ),
forOneUp_Tpwl_ARMA42 = exp( tmp$pred + 2*tmp$se )
)
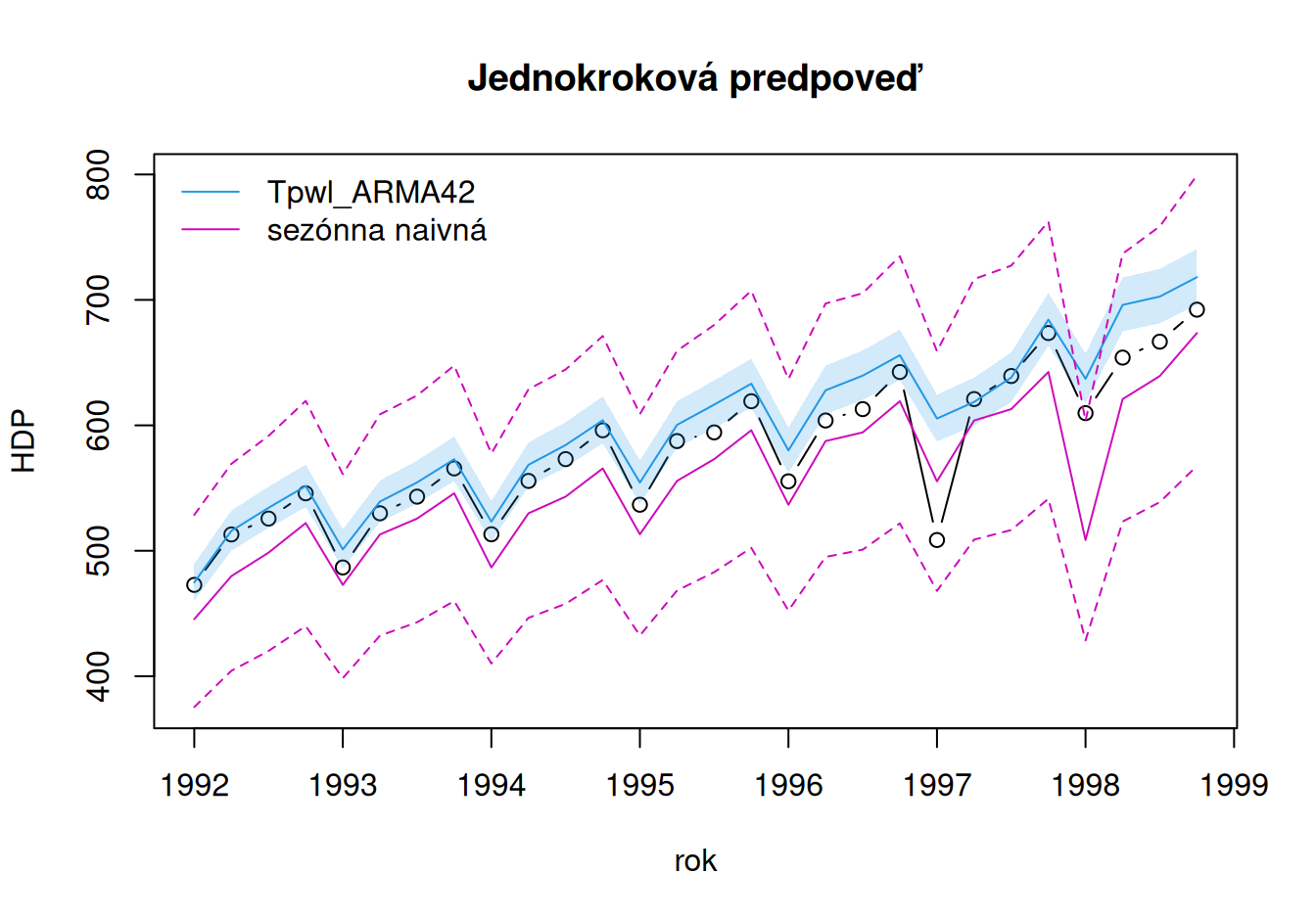
# zobrazenie
with(dat$valid, {
# prvý model a naivná predpoveď
plot(HDP, type="b", xlab = "rok", main = "Jednokroková predpoveď",
ylim = c(min(HDP,forOneLo_Naive,forOneLo_TlinC_ARMA60),
max(HDP,forOneUp_Naive,forOneUp_TlinC_ARMA60))
)
lines(forOne_TlinC_ARMA60, col=4)
year <- time(HDP)
polygon(x = c(year, rev(year)),
y = c(forOneLo_TlinC_ARMA60, rev(forOneUp_TlinC_ARMA60)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forOne_Naive, col=6)
lines(forOneLo_Naive, col=6, lty="dashed")
lines(forOneUp_Naive, col=6, lty="dashed")
legend("topleft", c("TlinC_ARMA60", "naivná"), col = c(4,6), lty = 1, bty="n")
# druhý model a sezónna naivná predpoveď
plot(HDP, type="b", xlab = "rok", main = "Jednokroková predpoveď",
ylim = c(min(HDP,forOneLo_SNaive,forOneLo_Tpwl_ARMA42),
max(HDP,forOneUp_SNaive,forOneUp_Tpwl_ARMA42))
)
lines(forOne_Tpwl_ARMA42, col=4)
year <- time(HDP)
polygon(x = c(year, rev(year)),
y = c(forOneLo_Tpwl_ARMA42, rev(forOneUp_Tpwl_ARMA42)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forOne_SNaive, col=6)
lines(forOneLo_SNaive, col=6, lty="dashed")
lines(forOneUp_SNaive, col=6, lty="dashed")
legend("topleft", c("Tpwl_ARMA42", "sezónna naivná"), col = c(4,6), lty = 1, bty="n")
})
# numerické porovnanie
with(dat$valid, list(Naivné = cbind(forOne_Naive, HDP),
"Sezónne naivné" = cbind(forOne_SNaive, HDP),
TlinC_ARMA60 = cbind(forOne_TlinC_ARMA60, HDP),
Tpwl_ARMA42 = cbind(forOne_Tpwl_ARMA42, HDP)
)) |>
sapply(fun$MeanForecastError) |> t() |> round(2)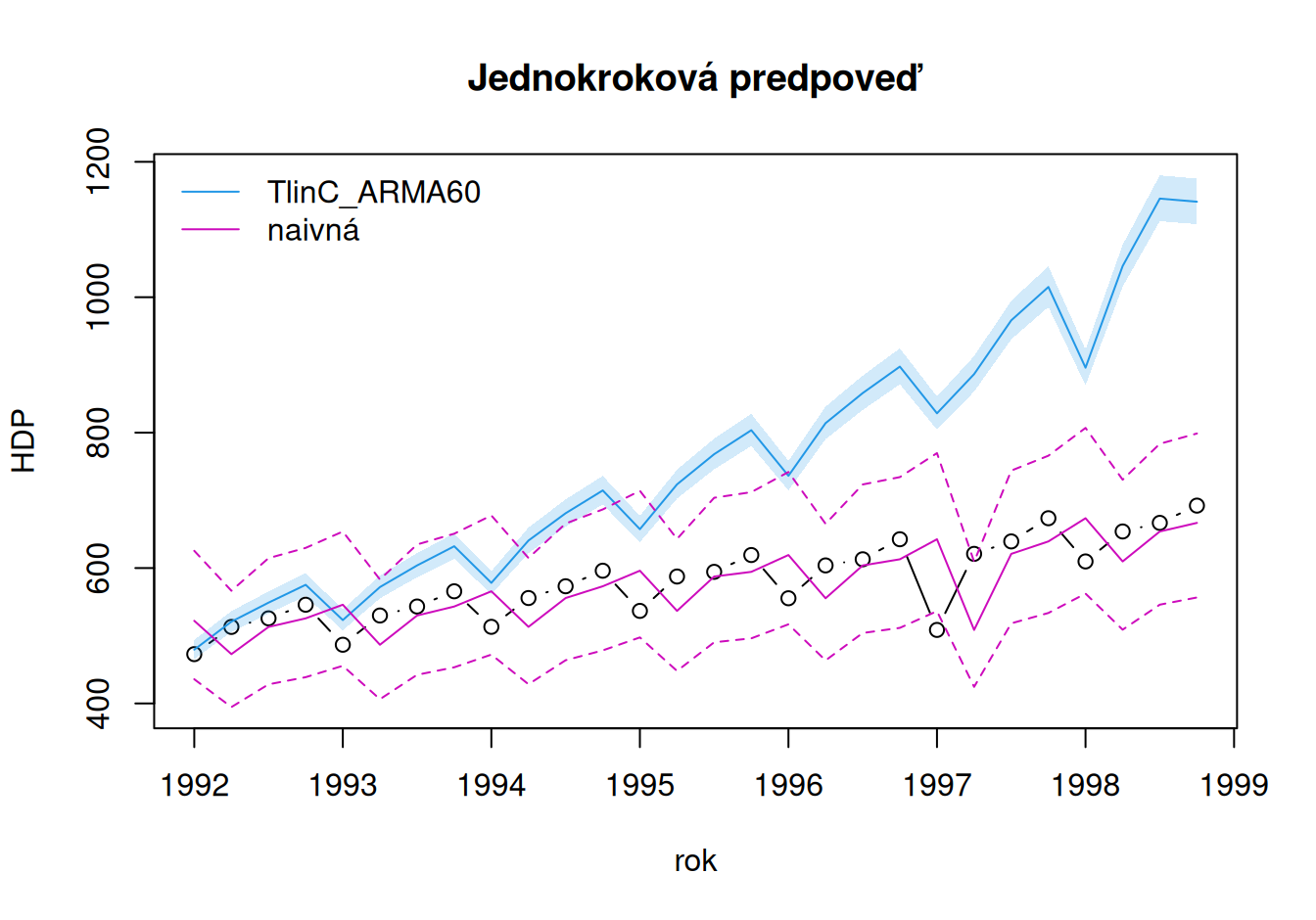
ME MSE RMSE MAE MAPE sMAPE MASE
Naivné 6.08 2468.60 49.69 40.49 7.20 7.13 1.01
Sezónne naivné 24.17 1004.99 31.70 27.51 4.77 4.90 0.68
TlinC_ARMA60 -179.13 50434.52 224.58 179.13 29.31 24.19 4.46
Tpwl_ARMA42 -17.66 652.68 25.55 17.91 3.10 3.00 0.45Presnosť jednokrokových predpovedí trpí nedostatočnou flexibilitou statickej časti modelu, čo dokáže dynamický model reziduálnej zložky kompenzovať iba zčasti (a najlepše ten nestacionárny). Predpovedné intervaly opäť nevystihujú neistotu v určení našich modelov.
# prvý model
ts.plot(dat$train$HDP, dat$valid$HDP,
gpars = list(
col = c(grey(0.5), rgb(1,0,0, alpha=0.5)),
ylim = c(0,1000),
ylab = "HDP", xlab = "rok")
)
lines(dat$train$All_TlinC_ARMA60, col=4)
lines(dat$valid$forMulti_TlinC_ARMA60, col = 4, lty=2, lwd=1)
legend("topleft",
legend=c("trénovacia vzorka", "validačná vzorka", "model", "predpoveď"),
lty = c(1,1,1,2), col = c(1,2,4,4), lwd = c(1,1,1,1), bty="n")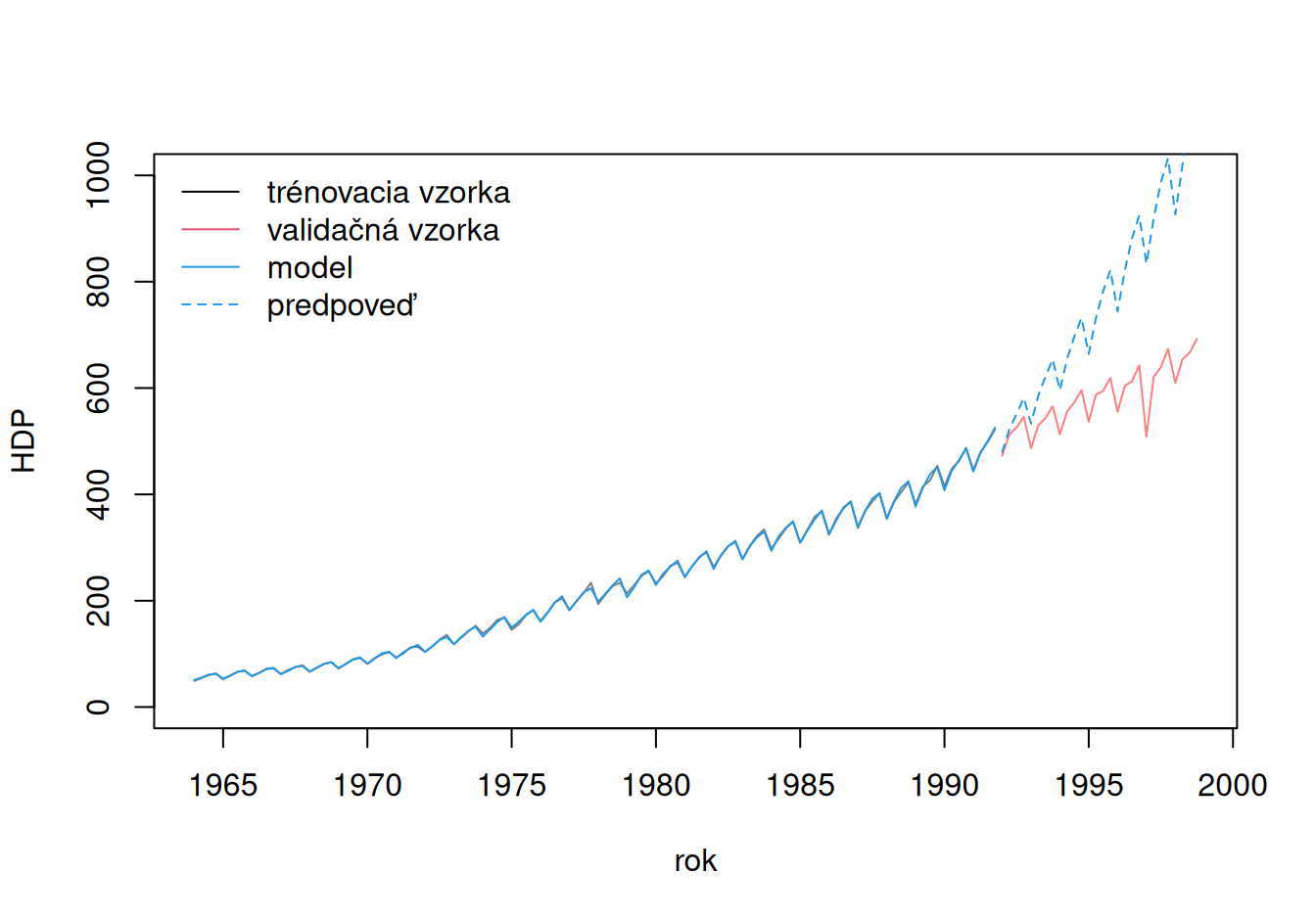
# druhý model
ts.plot(dat$train$HDP, dat$valid$HDP,
gpars = list(
col = c(grey(0.5), rgb(1,0,0, alpha=0.5)),
ylim = c(0,800),
ylab = "HDP", xlab = "rok")
)
lines(dat$train$All_Tpwl_ARMA42, col=4)
lines(dat$valid$forMulti_Tpwl_ARMA42, col = 4, lty=2, lwd=1)
legend("topleft",
legend=c("trénovacia vzorka", "validačná vzorka", "model", "predpoveď"),
lty = c(1,1,1,2), col = c(1,2,4,4), lwd = c(1,1,1,1), bty="n")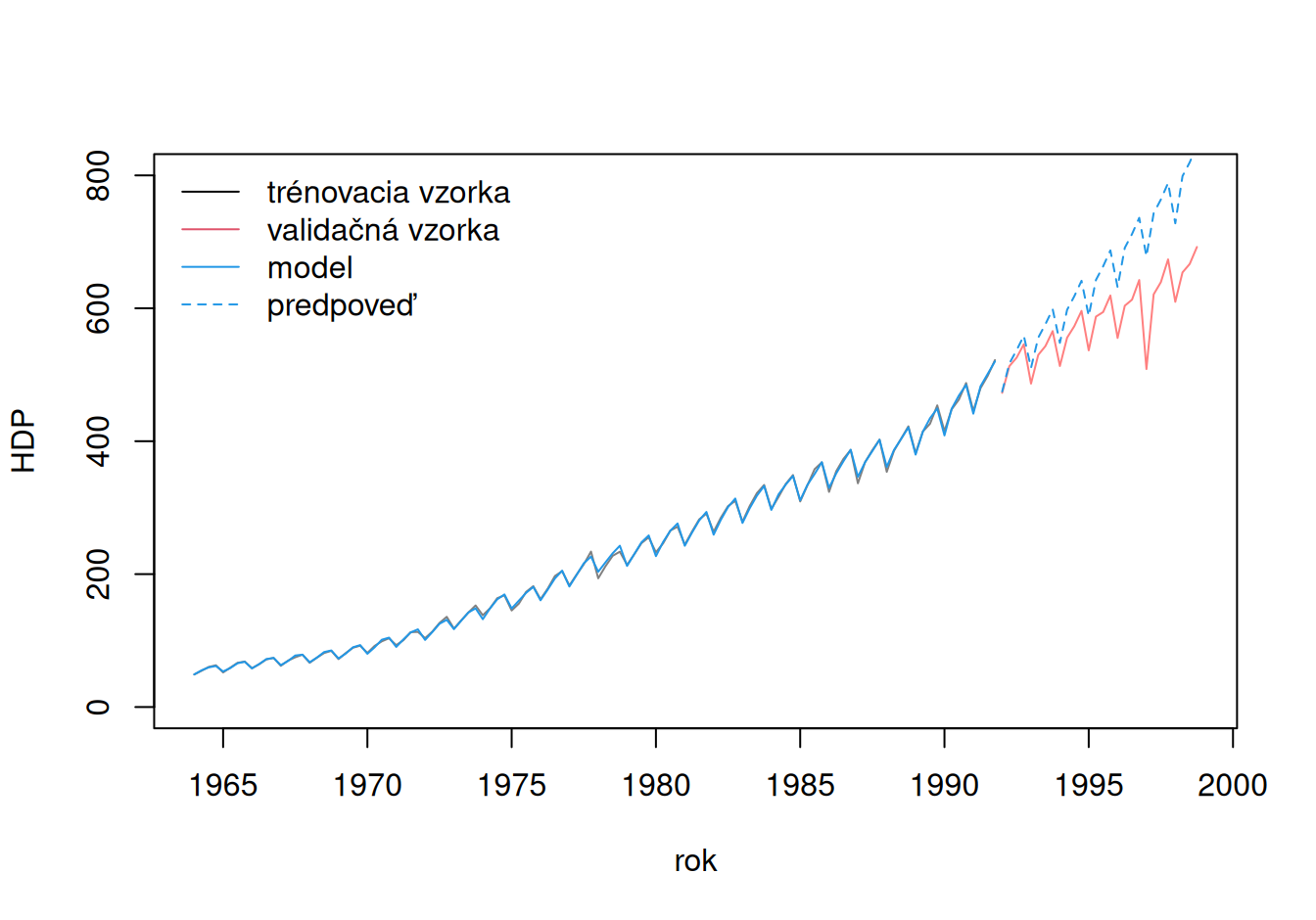
Z celkového pohľadu je zrejmé, že, hoci oba modely popisujú trénovaciu vzorku dobre, ani jeden nevystihol ďalší vývoj stochastického procesu, oba ho nadhodnotili.
V prípade prvého modelu sa voľba exponenciálneho trendu (lineárneho v logaritmickej mierke) ukázala ako príliš optimistická prognóza rastu ekonomiky. Tá bola zjavne po roku 1990 ešte viac tlmená, takže predpoklad cyklickej fluktuácie okolo exponenciálneho trendu sa ukázal ako mylný.
Toto tlmenie rastu HDP nevystihol ani druhý model, ale vďaka postrehnutiu vývoja ku koncu trénovacej zložky bol schopný podstatne realistickejšej predpovede.
# obnovenie kontajnerov
dat <- fit <- list()Načítanie, rozdelenie a zobrazenie údajov.
dat$all <- "data/Nehody_mesacne.dat" |> # zdrojový súbor údajov
read.table(header=F, skip = 1) |> # načítanie, vynechaný riadok obsahuje popis
setNames(c("rok", "mesiac", "deň", "nehody")) |> # doplnenie hlavičky
transform(rok = rok + (mesiac-1)/12, # rok v desatinnom formáte
mesiac = factor(mesiac), # bude treba v modeli sezónnej zložky
deň = NULL # vymazanie stĺpca
)
head(dat$all) rok mesiac nehody
1 2010.000 1 1820
2 2010.083 2 1594
3 2010.167 3 1743
4 2010.250 4 1637
5 2010.333 5 1812
6 2010.417 6 1753# rozdeľ do dvoch data.frame a pripoj ku objektu dat
dat[c("train","valid")] <- dat$all |>
split(dat$all$rok >= 2015)
# zisti dĺžku vzoriek a ulož do jedného objektu
n <- lapply(dat, nrow)
unlist(n) all train valid
72 60 12 # zobrazenie
plot(nehody ~ rok, dat$all, type="n") # definuj vykreslovaciu oblasť ale nekresli
lines(nehody ~ rok, dat$train, type = "b")
lines(nehody ~ rok, dat$valid, col = 2, type = "b")
legend("topright", legend=c("trénovacia časť", "validačná časť"),
lty = 1, col = c(1,2))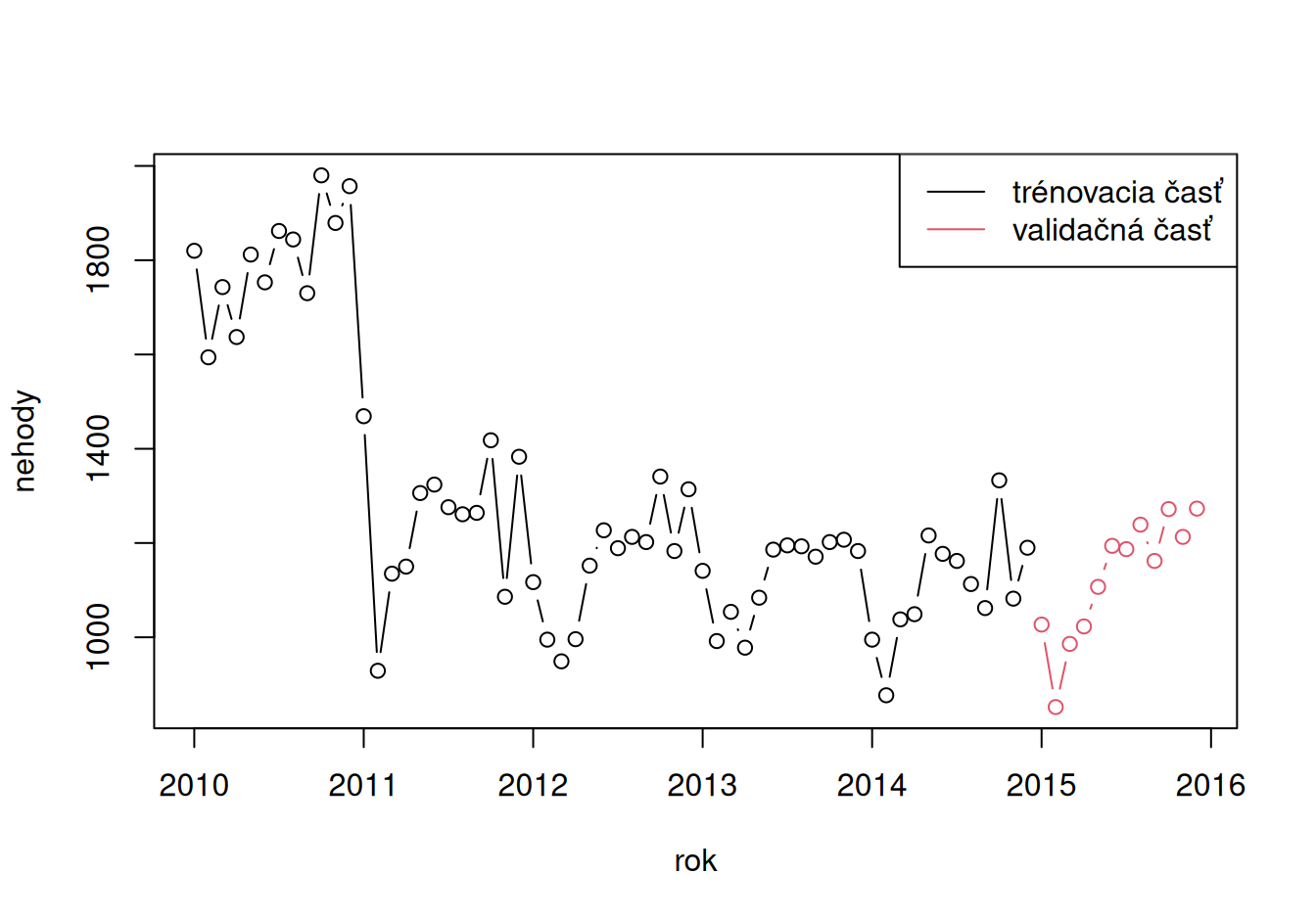
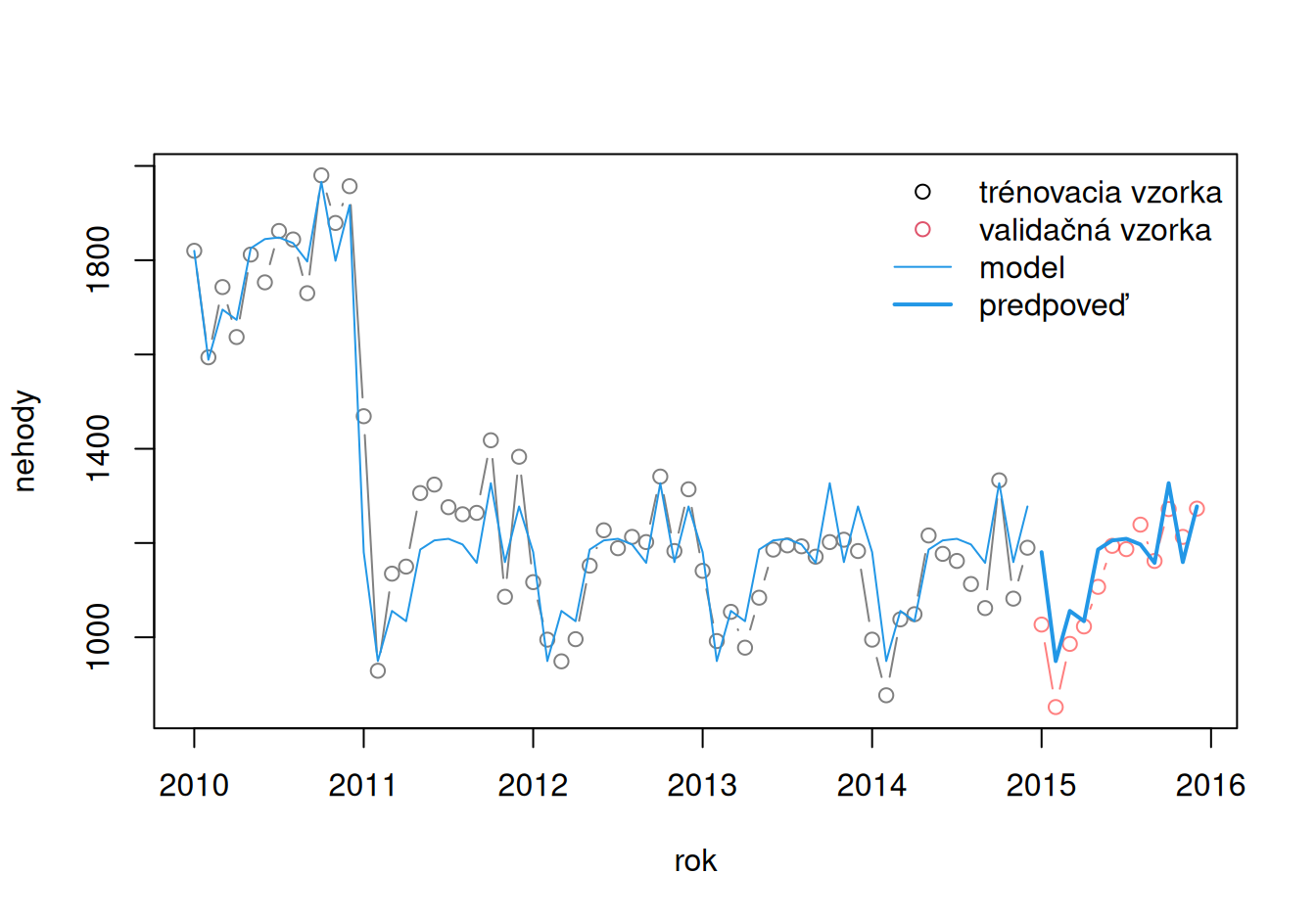
Záznamy tvorí počet dopravných nehôd za mesiac na Slovensku v rokoch 2010-2015. Posledný rok je vyhradený pre validáciu.
dat$train$nehody |>
ts(frequency = 12, start = 2010) |> # funkcie stl aj decompose vyžadujú ts
stl(s.window = 12) |>
plot()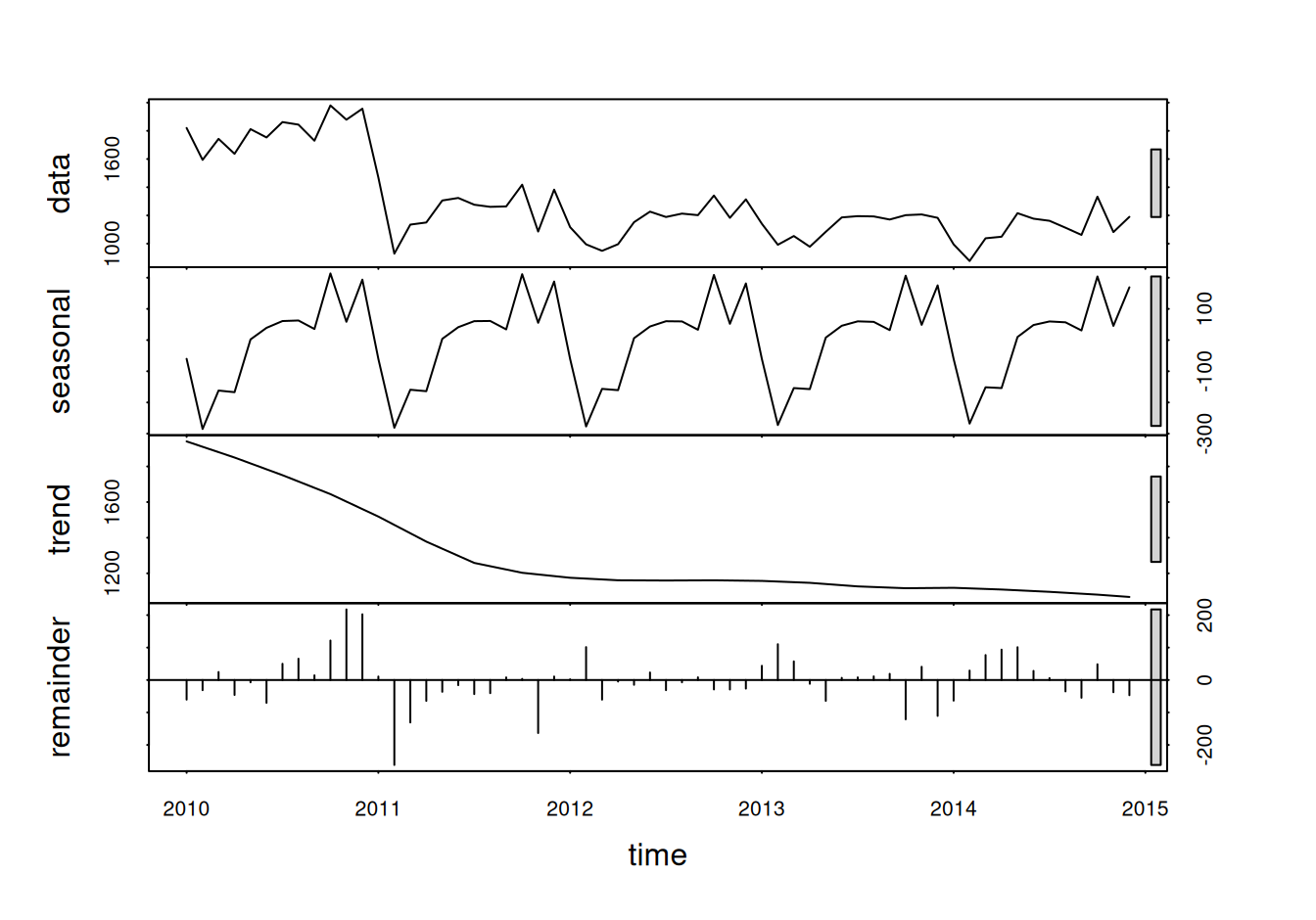
Predbežná dekompozícia ukazuje významnú sezónnu zložku a trend.
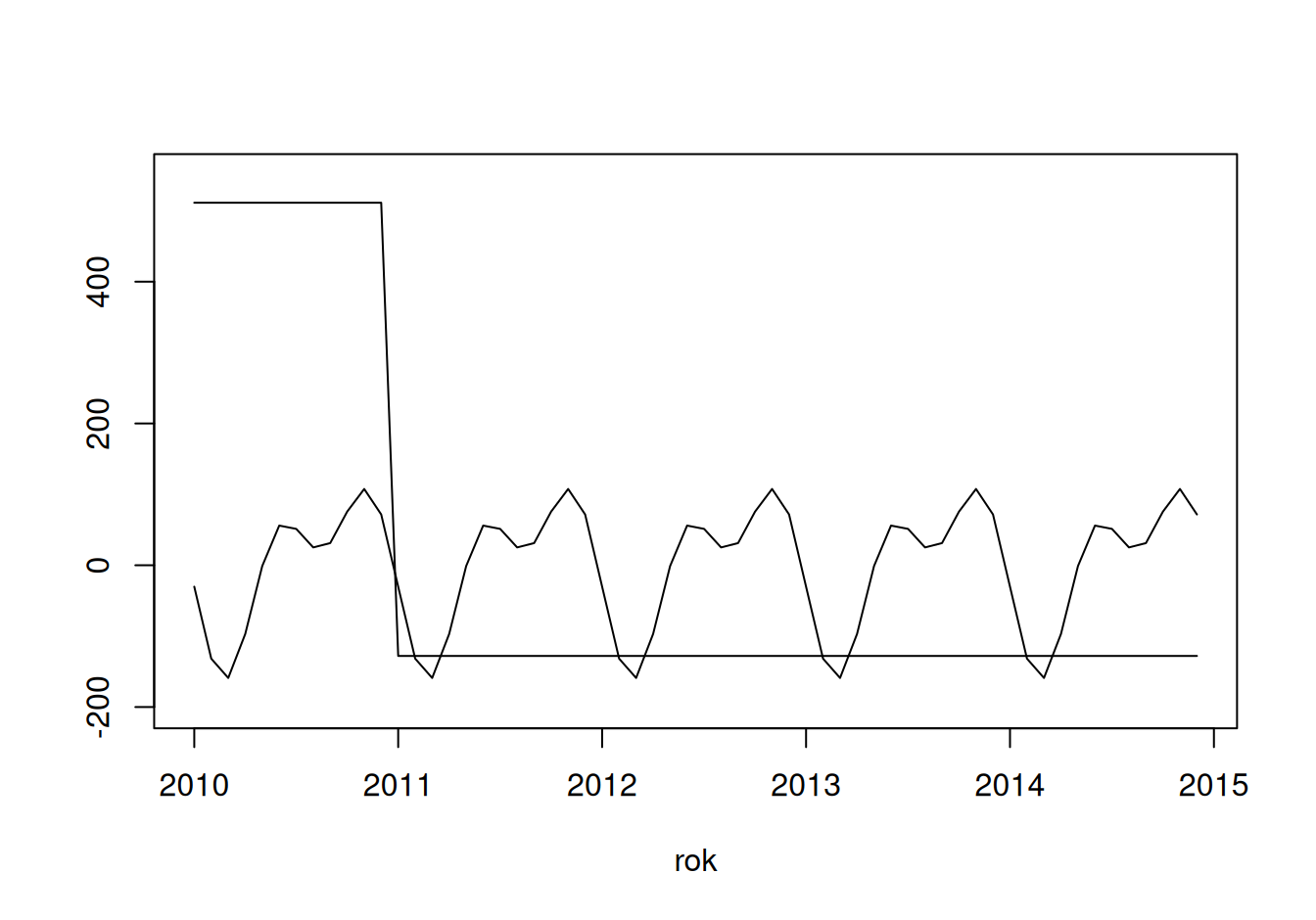
Hladká funkcia sa na trend nehodí, pretože okolo prelomu rokov 2010 a 2011 necháva veľké rezíduá. Vzhľadom na rýchly pokles počtu nehôd (žiaľ iba v dôsledku zmeny v klasifikácii) použijeme nespojitý, po častiach lineárny trend. Keďže je náš časový rad pomerne krátky, trend pred zmenou v 2011 budeme radšej dočasne považovať za konštantý, než aby ho zásadne skreslila sezonalita. Potom v spoločnom modeli sklon prvého segmentu trendu “zapneme”.
# model
fit$TreDisc <- lm(nehody ~
# rok + # keby sme chceli nenulový sklon aj pred 2011
ifelse(rok < 2011, 0, 1) + # spôsobí nespojitosť (discontinuity)
pmax(0, rok - 2011.0), # zmena sklonu
data = dat$train)
tmp <- fit$TreDisc |> coef() |> print() (Intercept) ifelse(rok < 2011, 0, 1) pmax(0, rok - 2011)
1800.91667 -583.38690 -28.53647 # stredné hodnoty
dat$train$TreDisc <- fit$TreDisc |> fitted()
# graf nespojitého trendu
plot(nehody ~ rok, dat$train, type = "b", main = "Model trendu")
lines(TreDisc ~ rok, dat$train, subset = rok<2011, col = 4, lwd = 2)
lines(TreDisc ~ rok, dat$train, subset = rok>=2011, col = 4, lwd = 2)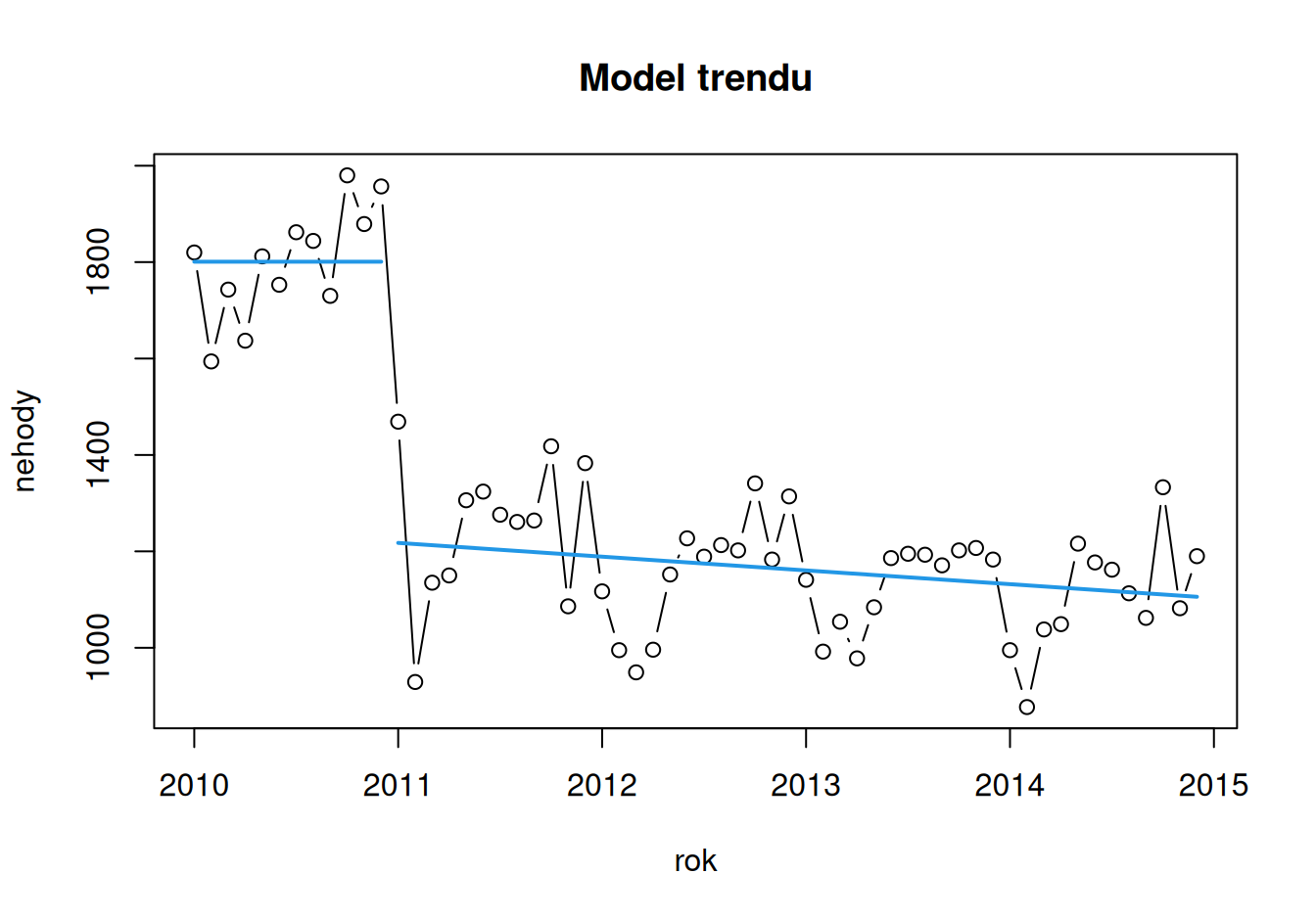
Od roku 2011 je teda stredný ročný úbytok 28 nehôd.
# rezíduá po trende
dat$train$resT <- dat$train$nehody - dat$train$TreDisc
# model sezónnej zložky
fit$SeaInd <- lm(resT ~ mesiac, dat$train)
fit$SeaCos <- lm(resT ~
cos(2*pi*rok/1) + sin(2*pi*rok/1) +
cos(2*pi*rok/(1/2)) + sin(2*pi*rok/(1/2)),
dat$train)
cat("Parametre modelov sezónnosti:\n")Parametre modelov sezónnosti:fit$SeaInd |> coef() |> round(1)(Intercept) mesiac2 mesiac3 mesiac4 mesiac5 mesiac6
8.4 -229.1 -120.8 -140.7 13.2 34.5
mesiac7 mesiac8 mesiac9 mesiac10 mesiac11 mesiac12
39.8 29.7 -7.4 163.5 -2.0 117.9 fit$SeaCos |> coef() |> round(1) (Intercept) cos(2 * pi * rok/1) sin(2 * pi * rok/1)
0.0 -42.7 -93.4
cos(2 * pi * rok/(1/2)) sin(2 * pi * rok/(1/2))
8.7 -70.9 cat("Amplitúdy zložiek spojitého modelu:\n")Amplitúdy zložiek spojitého modelu:fit$SeaCos |> coef() |> tail(-1) |> # bez absol.člena
split(rep(c(1,"1/2"), each=2)) |> # rozdelenie po zložkách
sapply(norm, type="2") |> # L2 norma
round(1) 1 1/2
102.7 71.4 # stredné hodnoty
dat$train$SeaInd <- fit$SeaInd |> fitted()
dat$train$SeaCos <- fit$SeaCos |> fitted()# zobrazenie
with(dat$train, {
# celé trénovacie obdobie
plot(resT ~ rok, main = "Model sezónnej zložky", type = "b",
ylim = c(-350,250))
lines(SeaInd ~ rok, type = "s", col = 4)
lines(SeaCos ~ rok, col = 4, lty = 2)
legend("bottomleft", c("Pozorované", "Nespojitý (Ind)", "Spojitý (Cos)"),
lty = c(0,1,2), pch = c(1,NA,NA), lwd = c(1), col = c(1, 4, 4),
horiz = T)
# jedna perióda
plot(SeaInd ~ mesiac, subset = rok<2011, # iba jedna perióda, všetky sú rovnaké
ylab = "nehody", main = "Model sezónnej zložky",
medcol = 4, boxcol = 4 # čiarky sú vlastne degenerované krabicové grafy
)
points(SeaCos[1:12], type = "b", col = 4, pch = 20)
legend("topleft", c("Nespojitý (Ind)", "Spojitý (Cos)"),
lty = c(1,0), pch = c(NA,20), lwd = c(3,1), col = 4)
})
# rezíduá
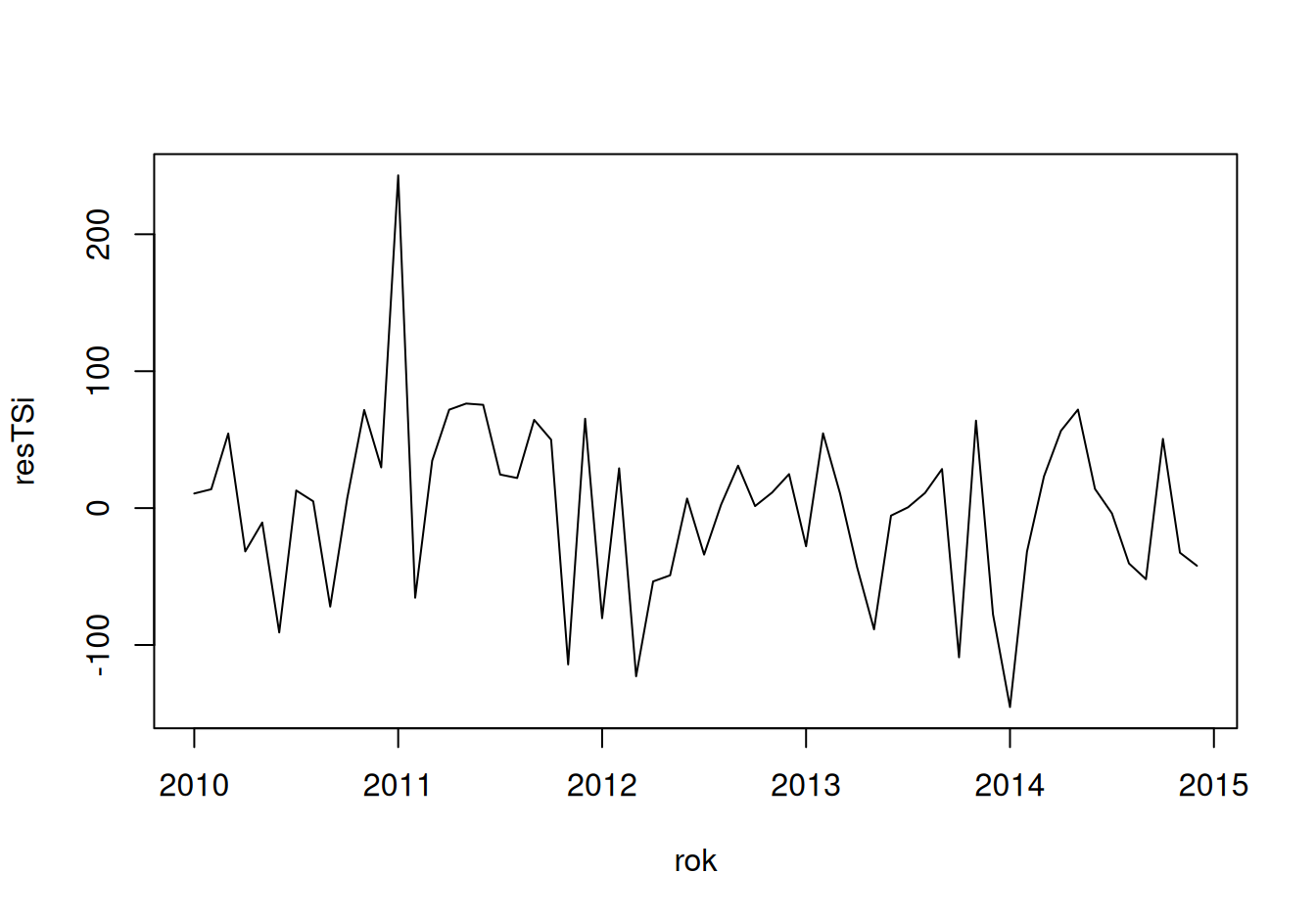
dat$train$resTSi <- fit$SeaInd |> residuals()
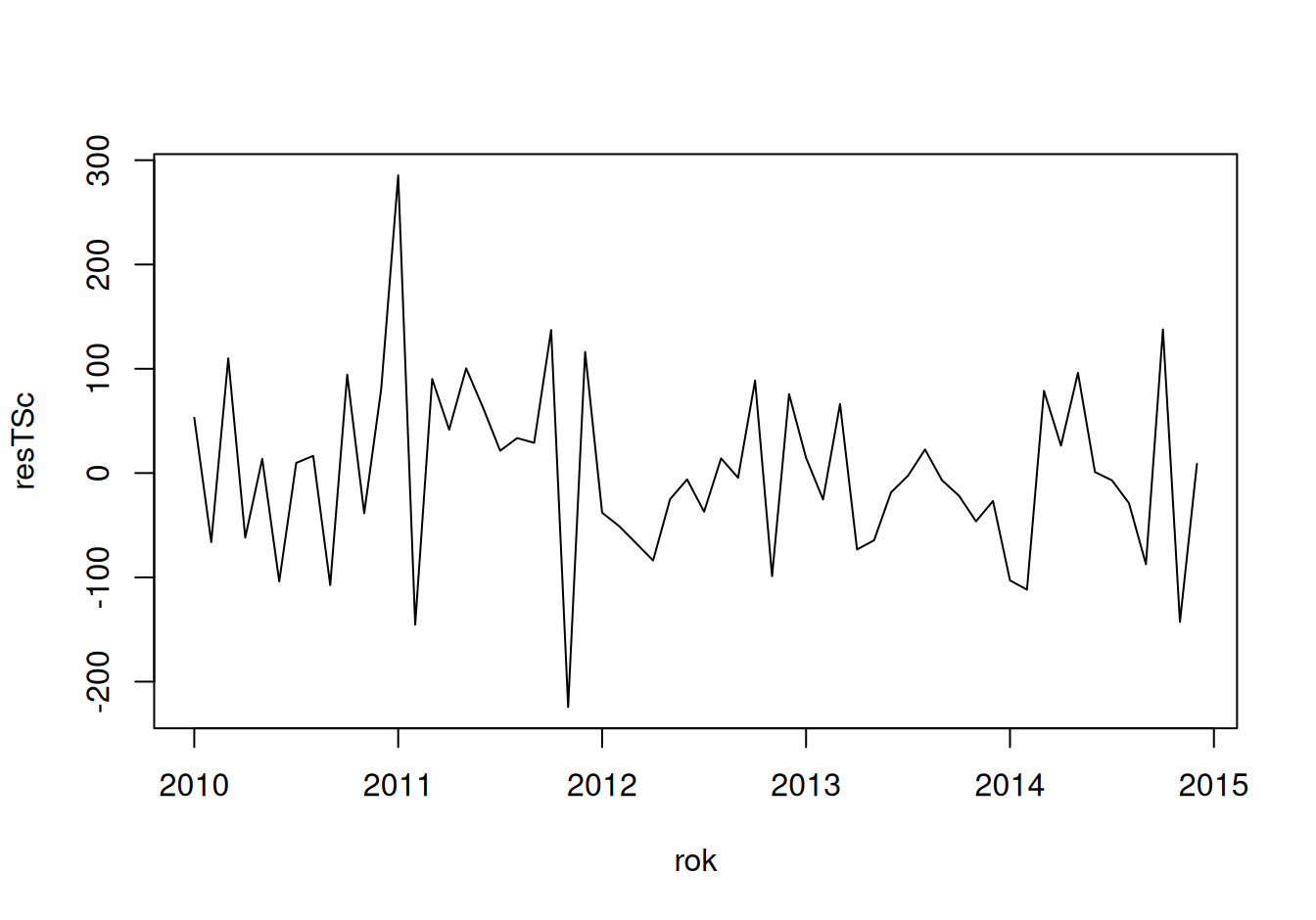
dat$train$resTSc <- fit$SeaCos |> residuals()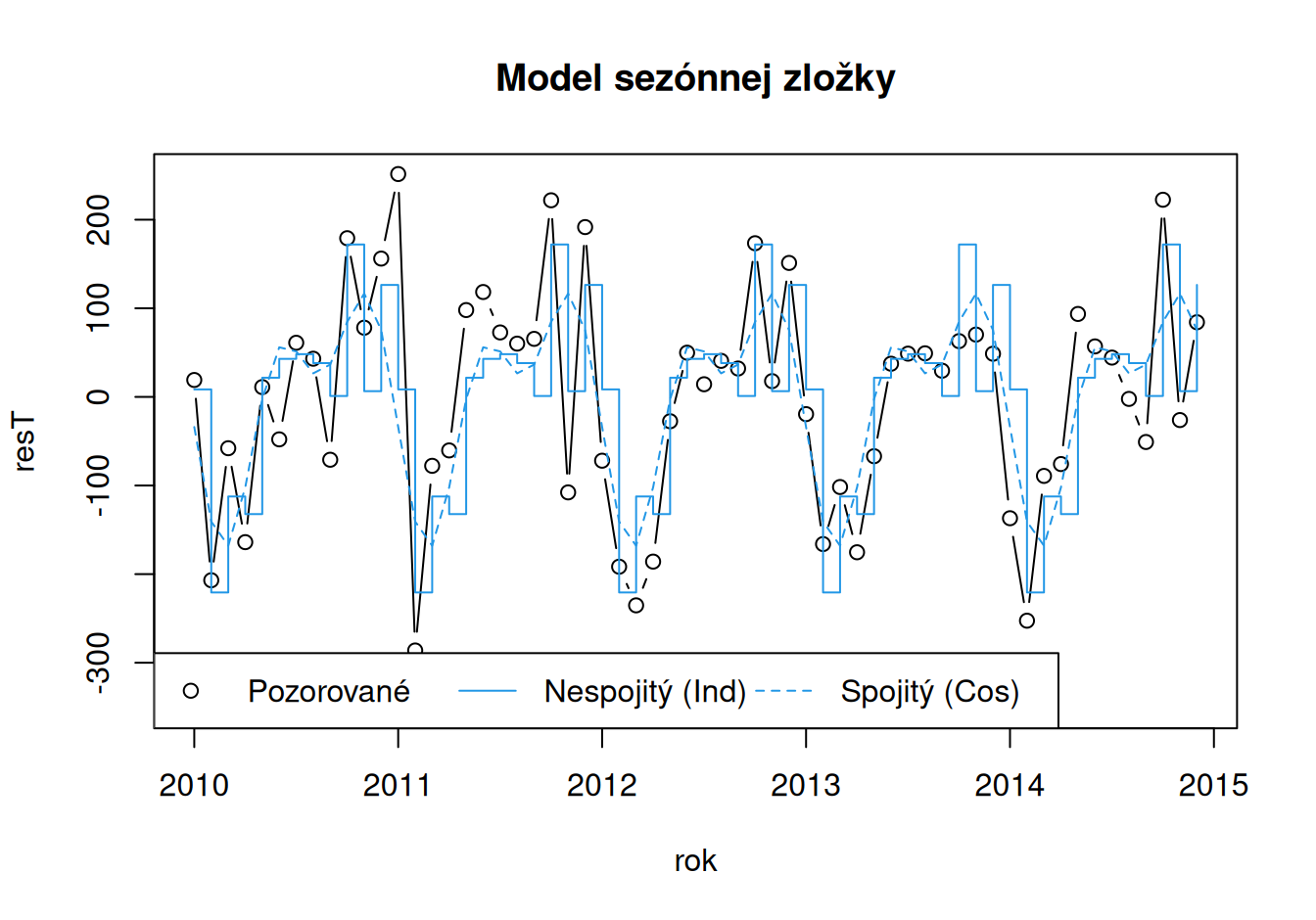
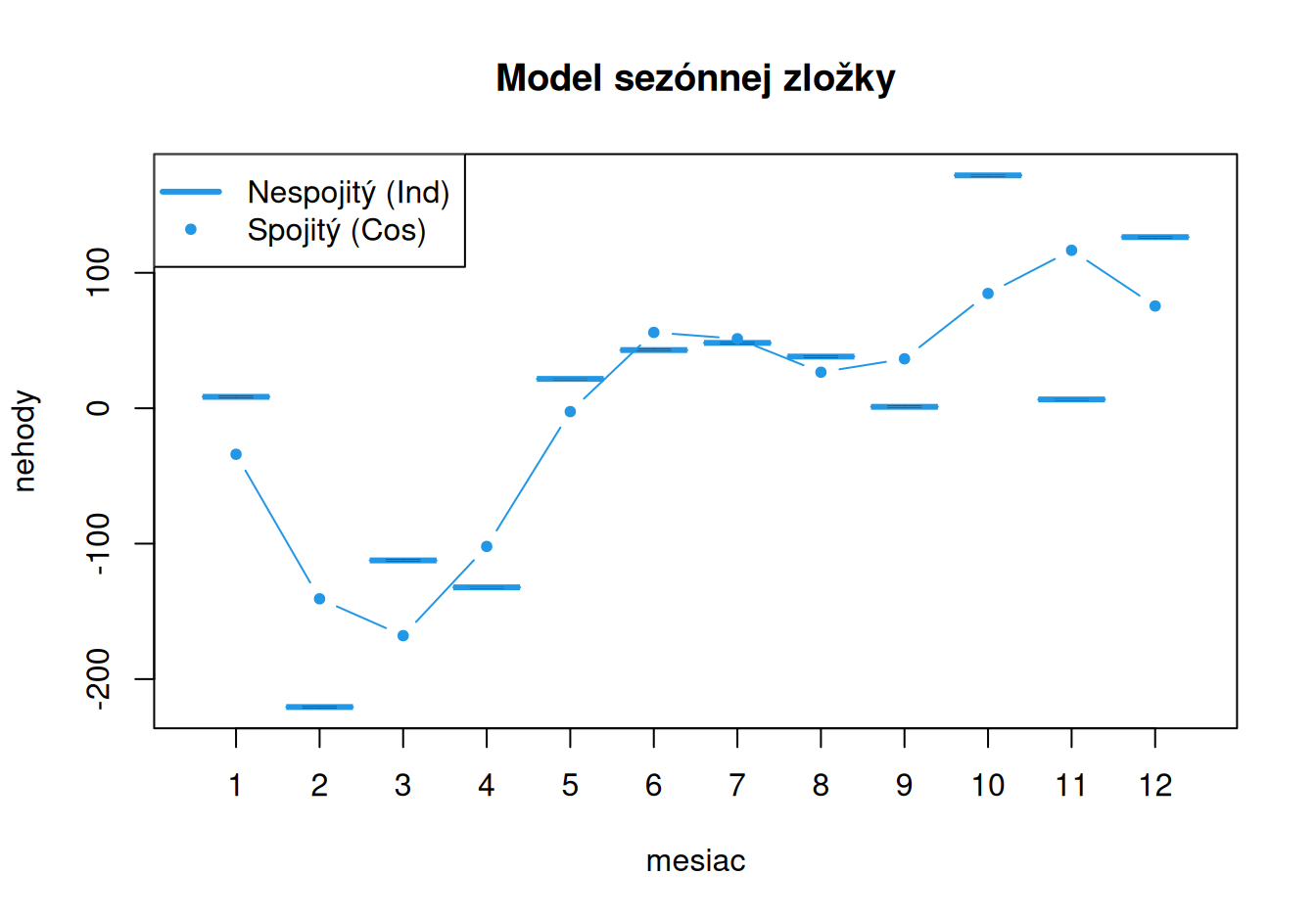
Nespojitý model sezónnej zložky konštruovaný pomocou indikačných bázových funkcií má ľahko interpretovateľné parametre aj popisuje sezóny priebeh časového radu presnejšie. Najmenšiu hodnotu dosahuje vo februári (\(8-229=-221\) nehôd), najväčšiu v októbri (\(8+164=172\) nehôd).
Výhodou modelu kombinujúceho dve harmonické vlny (s ročnou a polročnou periódou) je úspornosť, pretože si na popis 12 sezón vystačí iba s 5 parametrami. Jeho dve zložky s amplitúdami 103 a 71 nehôd majú svoje spoločné interferenčné maximum na konci zimy a minimum v lete.
Na konci uvidíme, ako si poradia vo validačnom období.
Teraz zobrazíme spektrum rezíduí oboch modelov:
with(dat$train, {
PowSpec <- function(x) {
n <- length(x)
x |> fft() |> abs() |> (`^`)(2) |> (`/`)(2*pi*n) |> head(floor(n/2 + 1))
}
hustota <- data.frame(resTSi = PowSpec(resTSi),
resTSc = PowSpec(resTSc))
hustota$perióda <- n$train / seq(0, length.out = nrow(hustota))
plot(resTSi ~ perióda, data = hustota[-1,], xlab="perióda (mesiace)",
ylab = "spektrum resTSi", type="h", log="x")
plot(resTSc ~ perióda, data = hustota[-1,], xlab="perióda (mesiace)",
ylab = "spektrum resTSi", type="h", log="x")
# formálny test
# c(TS = hustota$resTSc |> sort(decreasing = T) |> (\(x) x[1]/sum(x))(),
# CV = 1 - (0.05/(nrow(hustota)+1))^(1/nrow(hustota))
# )
})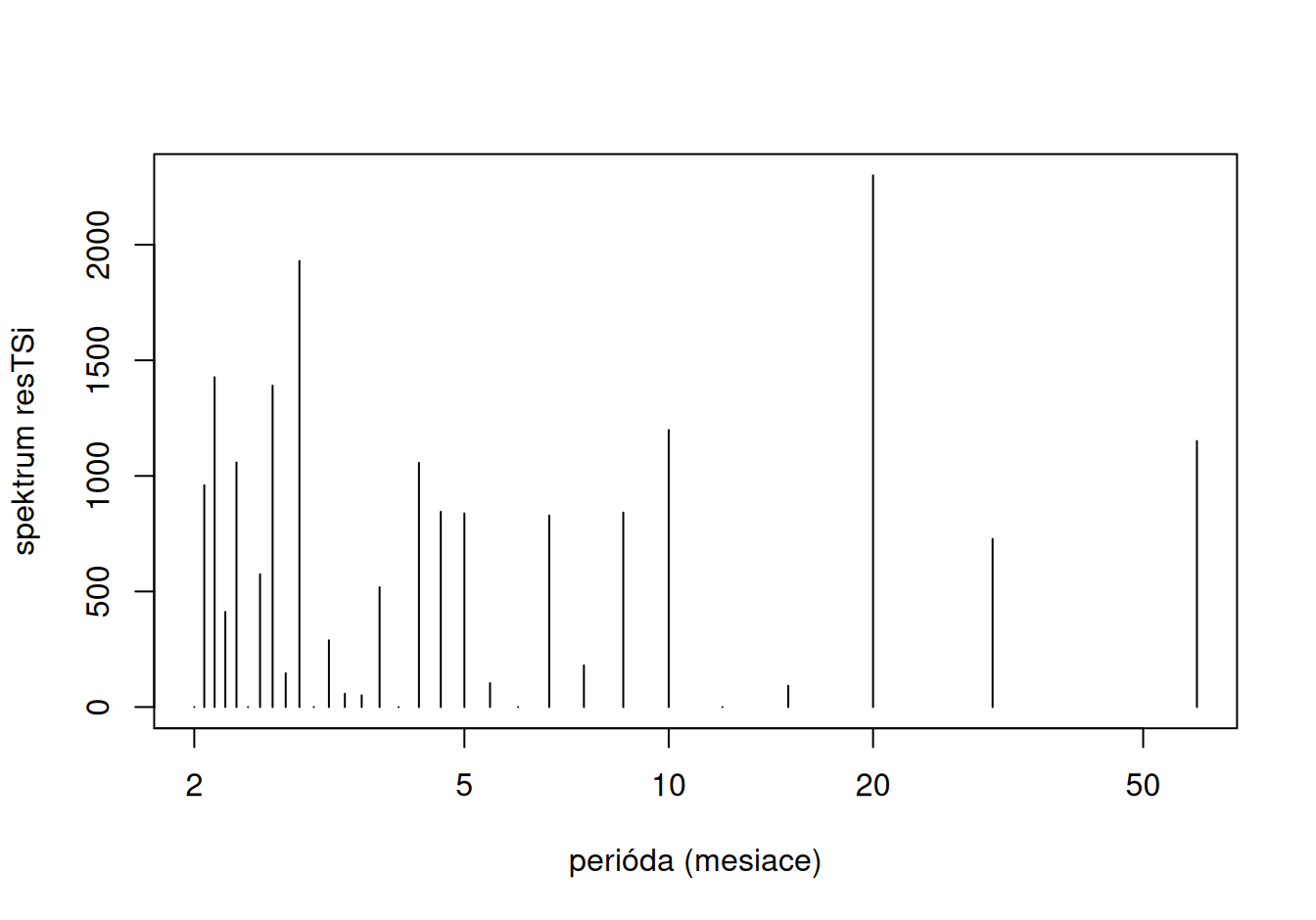
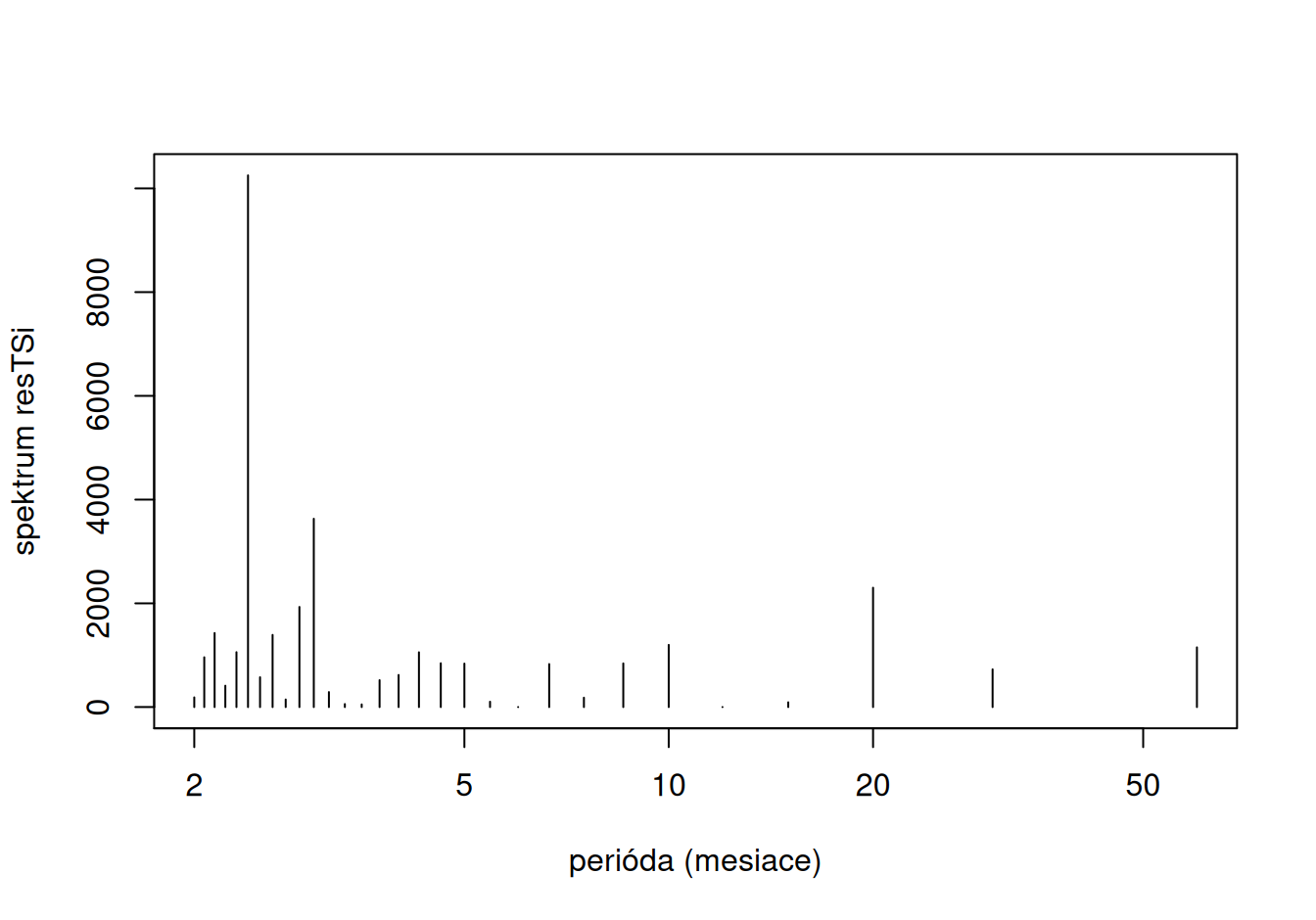
V rezíduách spojitého modelu je významná jedna krátkoperiodická zložka, ktorú ale v záujme jednoduchosti modelu zanedbáme. Oba časové rady tak budeme považovať za realizáciu procesu bez cyklickej zložky.
V rámci diagnostiky vyšetríme autokorelácie a normalitu.
with(dat$train, {
# vizuálne vyšetrenie rezíduí
plot(resTSi ~ rok, type = "l")
plot(resTSc ~ rok, type = "l")
# vyšetrenie autokorelácií
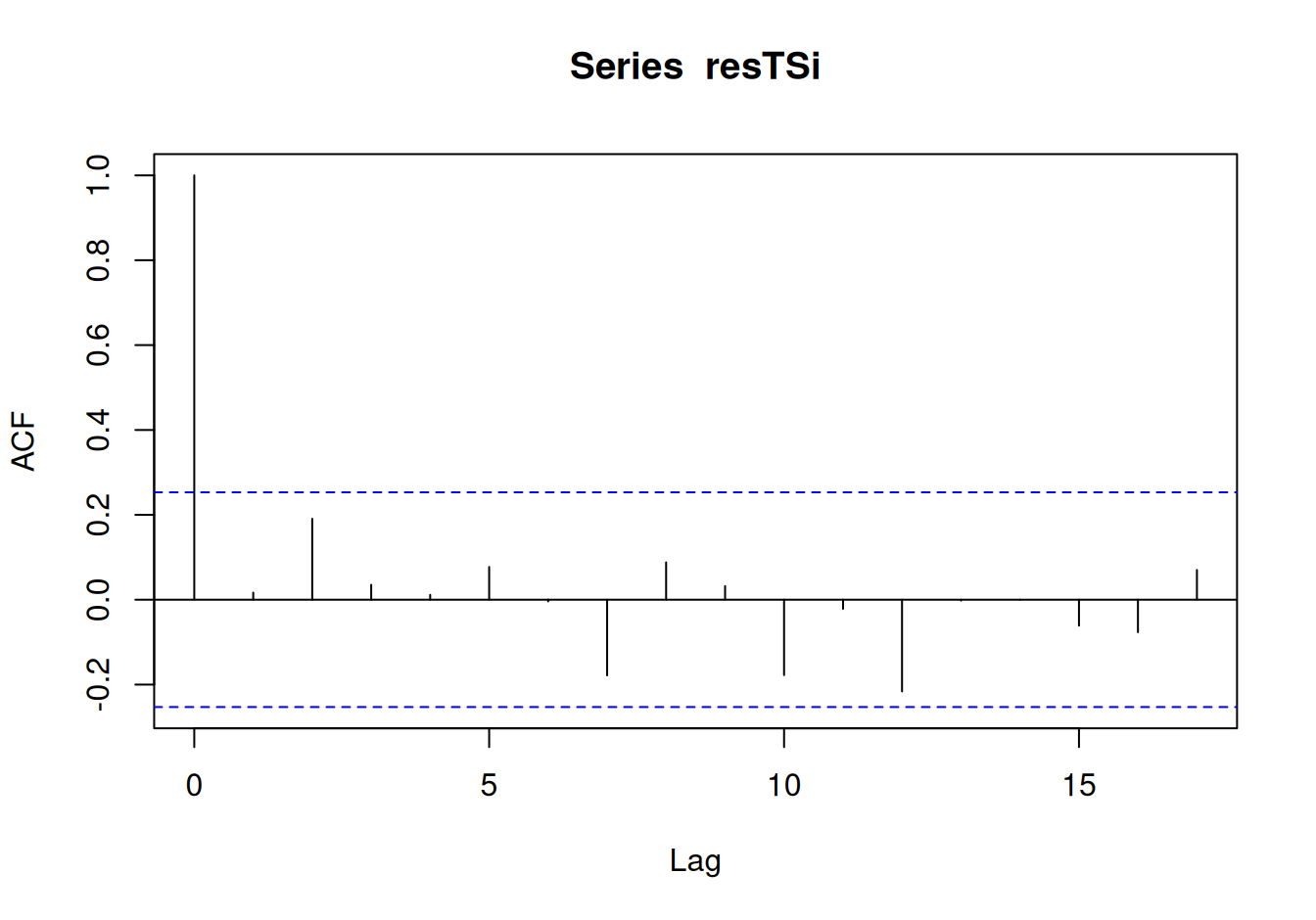
acf(resTSi)
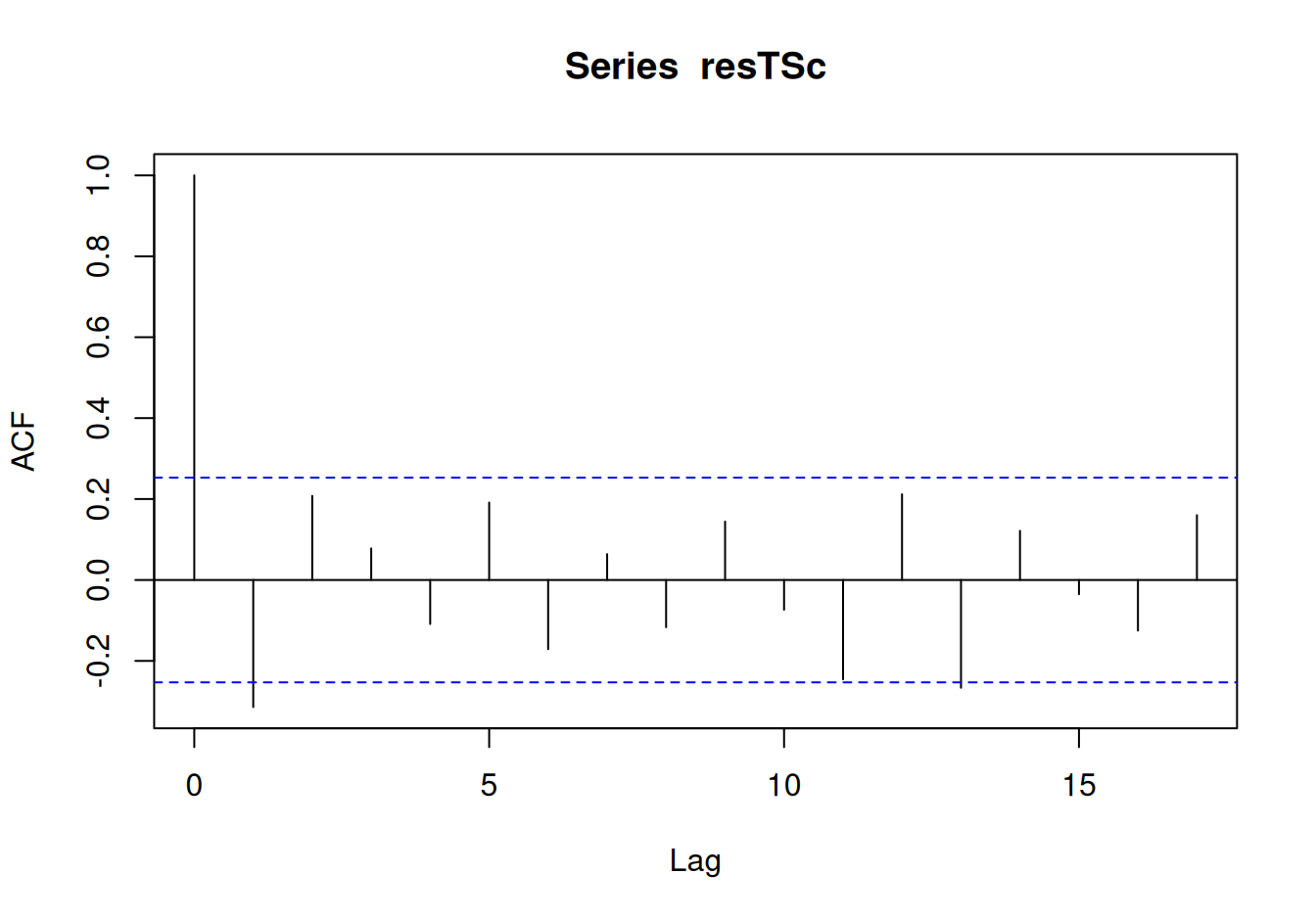
acf(resTSc)
# normalita
cat("P-hodnoty testu normality: \n")
c(resTSi = shapiro.test(resTSi)$p.value,
resTSc = shapiro.test(resTSc)$p.value
) |> round(3)
})
P-hodnoty testu normality: resTSi resTSc
0.007 0.386 Prekvapivo práve lepšie popisujúci model nemá normálne rozdelené rezíduá. Treba na to pamätať pri intervalových predpovediach. Ešte dôležitý a zaujímavý fakt je ten, že rezíduálna zložka už prakticky nie je korelovaná, čiže nie je čo ďalej modelovať a môžeme pristúpiť k odhadu spoločného modelu a k predpovediam. Predpovede tak stačí konštruovať priamo zo spoločného modelu systematických zložiek.
Do regresnej rovnice v spoločnom modeli zahrnieme aj člen rok, ktorým umožníme trendu mať pred rokom 2011 nenulový sklon.
# odhad spoločného modelu systematických zložiek
fit$All <- list(
TlinSind = lm(nehody ~
rok + ifelse(rok < 2011, 0, 1) + pmax(0, rok - 2011) + # trend
mesiac, # sezónnosť
dat$train),
TlinScos = lm(nehody ~
rok + ifelse(rok < 2011, 0, 1) + pmax(0, rok - 2011) + # trend
cos(2*pi*rok) + sin(2*pi*rok) + # ročná zložka sezónnosti
cos(2*pi*rok/0.5) + sin(2*pi*rok/0.5), # polročná zložka
dat$train)
)
# Na analýzu trendu postačí aj model s jednoduchšou sezónnosťou.
fit$All$TlinScos |> summary() |> coef() |> round(3) Estimate Std. Error t value Pr(>|t|)
(Intercept) -7022.568 194936.029 -0.036 0.971
rok 4.389 96.961 0.045 0.964
ifelse(rok < 2011, 0, 1) -553.640 65.307 -8.477 0.000
pmax(0, rok - 2011) -49.329 96.624 -0.511 0.612
cos(2 * pi * rok) -43.690 16.222 -2.693 0.009
sin(2 * pi * rok) -97.208 17.522 -5.548 0.000
cos(2 * pi * rok/0.5) 7.644 16.222 0.471 0.639
sin(2 * pi * rok/0.5) -72.670 16.429 -4.423 0.000Trend sa teda skladá z dvoch priamok, \(y=4.4x-7023\) a \(y=(4.4-49.3)x+(-7023-554)=-44.9x-7577\). Odhady sklonov oboch priamok však príliš veľkú štandardnú chybu, než aby sa dali považovať za nenulové. Preto má zmysel uvažovať ešte jednoduchší model – model s nespojitým ale konštantným trendom.
# odhad
fit$All$TconScos <- lm(
nehody ~
ifelse(rok < 2011, 0, 1) + # konštantný a nespojitý trend
cos(2*pi*rok) + sin(2*pi*rok) + # ročná zložka sezónnosti
cos(2*pi*rok/0.5) + sin(2*pi*rok/0.5), # polročná zložka
dat$train
)
# prvé dva parametre
fit$All$TconScos |> coef() |> head(2) |> round(3) (Intercept) ifelse(rok < 2011, 0, 1)
1800.917 -639.271 # zobrazenie zložiek
tmp <- fit$All$TconScos |> predict(type = "terms")
with(data.frame(rok = dat$train$rok,
trend = tmp[,1],
sez = rowSums(tmp[,2:5]),
rez = fit$All$TconScos |> resid()
),
{
# graf zložiek
plot(trend ~ rok, type = "l", ylab="", ylim = c(-200, 550), main="")
lines(sez ~ rok)
# intenzita zložiek
cat("Intenzita systematických zložiek: \n")
rezvar <- var(rez)
(1 - rezvar/c(trend = var(trend + rez),
sezónnosť = var(sez + rez)
)
) |> round(2)
}
)
Intenzita systematických zložiek: trend sezónnosť
0.88 0.44 Podľa tohto najjednoduchšieho modelu bola stredná nehodovosť pred rokom 2011 približne 1800 nehôd a počnúc ním o 640 nižšia, čiže cca 1160 nehôd. Samozrejme vďaka konštantnosti trendu si to vieme vypočítať aj ako aritmetický priemer v jednotlivých obdobiach:
dat$train |>
transform(obdobie = ifelse(rok < 2011, "pred 2011", "od 2011")) |>
aggregate(nehody ~ obdobie, data = _, FUN = mean) obdobie nehody
1 od 2011 1161.646
2 pred 2011 1800.917Podobne odhadneme aj model s konštantným trendom a s nespojitou sezónnosťou.
fit$All$TconSind <- lm(
nehody ~
ifelse(rok < 2011, 0, 1) + # konštantný a nespojitý trend
mesiac, # sezónnosť
dat$train
)Keďže ide o statické modely, jednokrokové a viackrokové predpovede sú totožné.
# predpoveď
dat$valid[paste0("forMulti",c("","Lo","Up"),"_TlinSind")] <-
fit$All$TlinSind |>
predict(newdata = dat$valid, interval = "prediction") |>
as.data.frame()
dat$valid[paste0("forMulti",c("","Lo","Up"),"_TlinScos")] <-
fit$All$TlinScos |>
predict(newdata = dat$valid, interval = "prediction") |>
as.data.frame()
dat$valid[paste0("forMulti",c("","Lo","Up"),"_TconSind")] <-
fit$All$TconSind |>
predict(newdata = dat$valid, interval = "prediction") |>
as.data.frame()
dat$valid[paste0("forMulti",c("","Lo","Up"),"_TconScos")] <-
fit$All$TconScos |>
predict(newdata = dat$valid, interval = "prediction") |>
as.data.frame()
# naivná predpoveď
dat$valid$forMulti_Naive <- dat$train$nehody |>
tail(1) |> rep(length.out = n$valid)
tmp <- dat$train$nehody |> diff() |> (`^`)(2) |> mean() # reziduálny rozptyl
dat$valid <- dat$valid |>
transform(
forMultiLo_Naive = forMulti_Naive - 2*sqrt(tmp*(1:n$valid)),
forMultiUp_Naive = forMulti_Naive + 2*sqrt(tmp*(1:n$valid))
)
# sezónne naivná
dat$valid$forMulti_SNaive <- dat$train$nehody |>
tail(12) |> rep(length.out = n$valid)
tmp <- dat$train$nehody |> diff(lag = 12) |> (`^`)(2) |> mean() # reziduálny rozptyl
dat$valid <- dat$valid |>
transform(
forMultiLo_SNaive = forMulti_SNaive - 2*sqrt(tmp*(1:n$valid)),
forMultiUp_SNaive = forMulti_SNaive + 2*sqrt(tmp*(1:n$valid))
)
# zobrazenie
with(dat$valid, {
# model s lin.trendom a indikačnými bázovými funkciami v sez.časti
plot(nehody ~ rok, type="b",
main = "Predpoveď s lin.trendom a nespoj.sez.zl.",
ylim = c(min(nehody,forMulti_TlinSind), max(nehody,forMultiUp_TlinSind))
)
polygon(x = c(rok, rev(rok)),
y = c(forMultiLo_TlinSind, rev(forMultiUp_TlinSind)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forMulti_TlinSind ~ rok, col = 4)
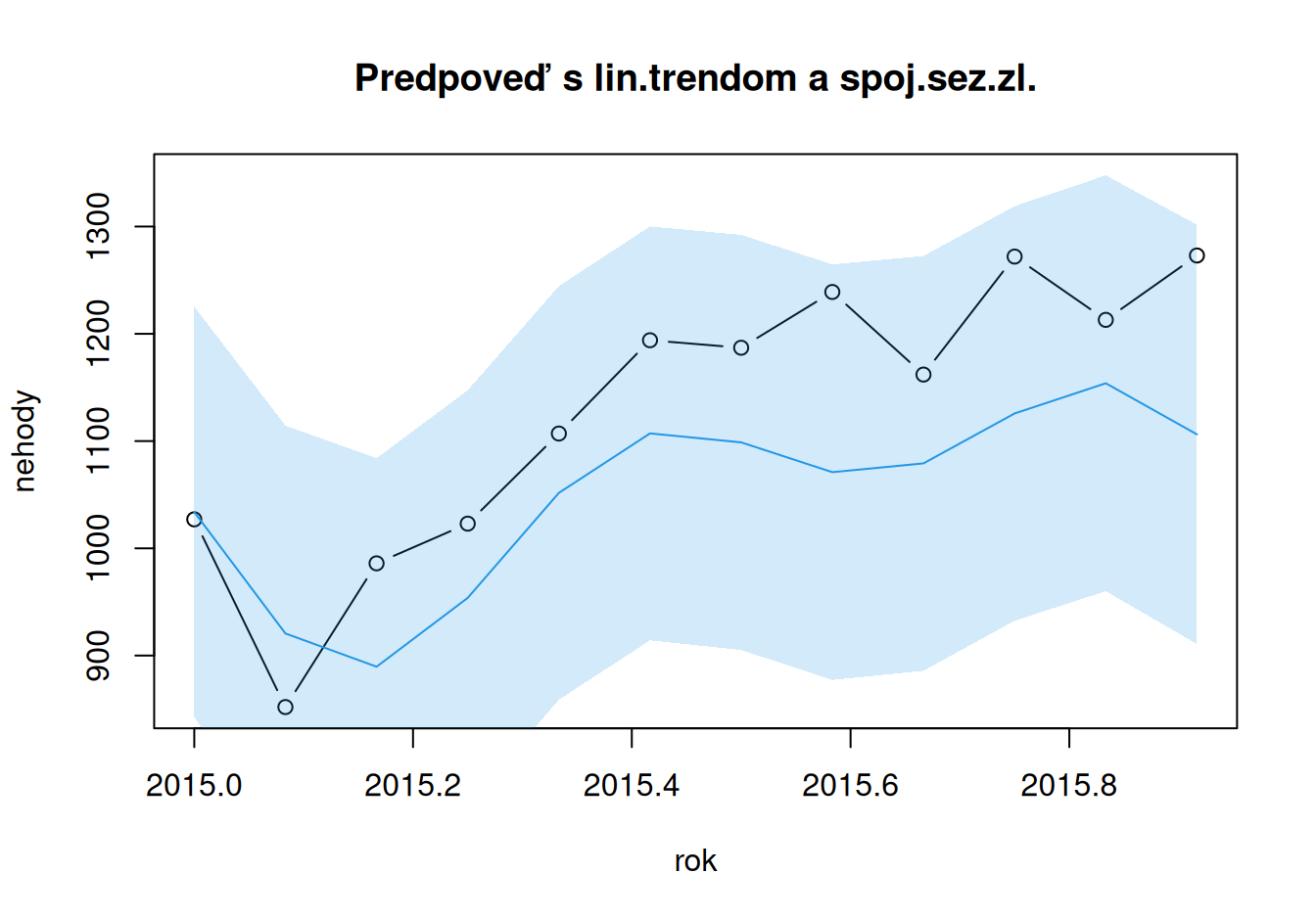
# model s lin.trendom a trig. bázovými funkciami v sez.časti
plot(nehody ~ rok, type="b",
main = "Predpoveď s lin.trendom a spoj.sez.zl.",
ylim = c(min(nehody,forMulti_TlinScos), max(nehody,forMultiUp_TlinScos))
)
polygon(x = c(rok, rev(rok)),
y = c(forMultiLo_TlinScos, rev(forMultiUp_TlinScos)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forMulti_TlinScos ~ rok, col = 4)
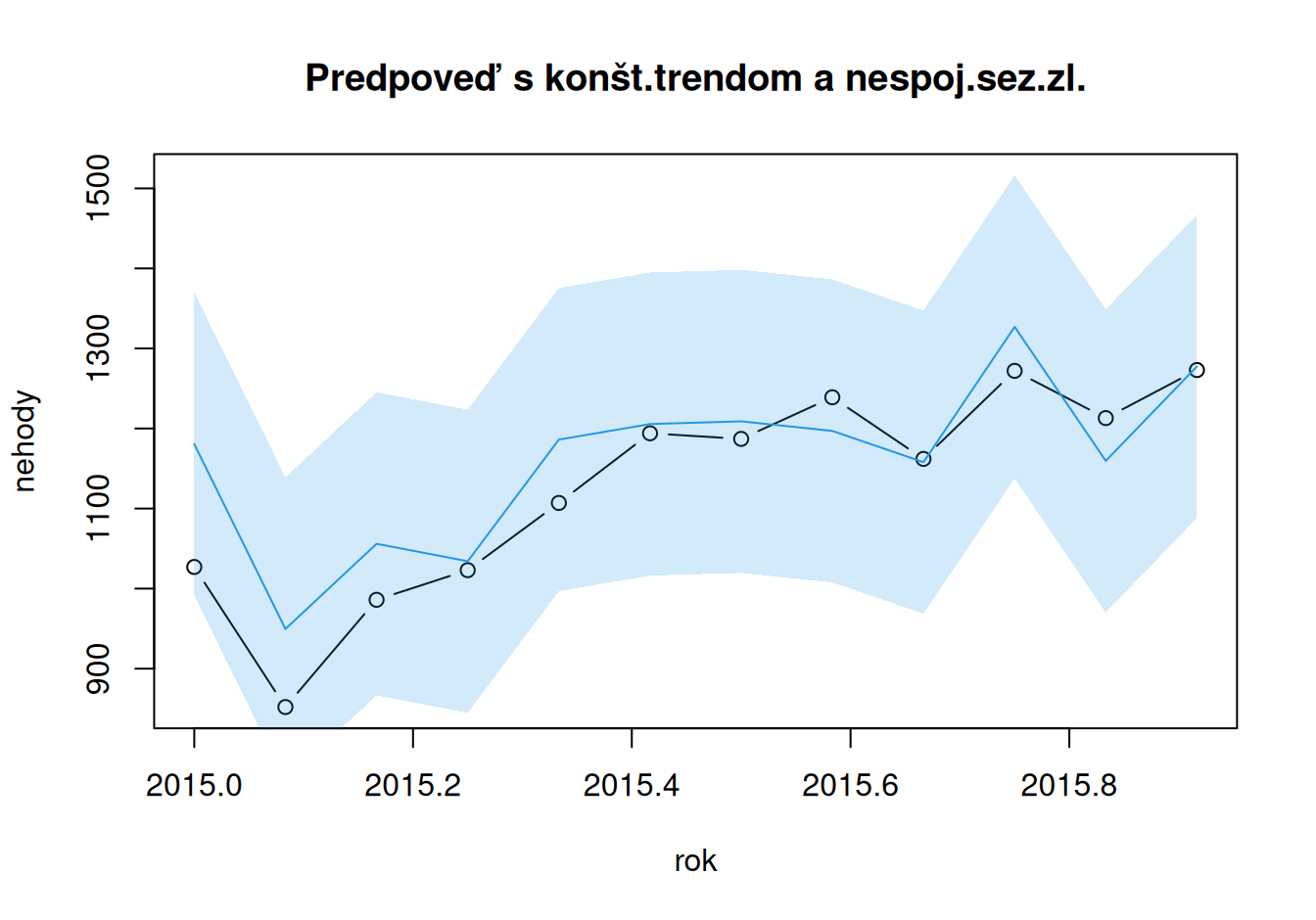
# model s konšt.trendom a indikačnými bázovými funkciami v sez.časti
plot(nehody ~ rok, type="b",
main = "Predpoveď s konšt.trendom a nespoj.sez.zl.",
ylim = c(min(nehody,forMulti_TconSind), max(nehody,forMultiUp_TconSind))
)
polygon(x = c(rok, rev(rok)),
y = c(forMultiLo_TconSind, rev(forMultiUp_TconSind)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forMulti_TconSind ~ rok, col = 4)
# model s konšt.trendom a trig. bázovými funkciami v sez.časti
plot(nehody ~ rok, type="b",
main = "Predpoveď s konšt.trendom a spoj.sez.zl.",
ylim = c(min(nehody,forMulti_TconScos), max(nehody,forMultiUp_TconScos))
)
polygon(x = c(rok, rev(rok)),
y = c(forMultiLo_TconScos, rev(forMultiUp_TconScos)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forMulti_TconScos ~ rok, col = 4)
# naivná predpoveď
plot(nehody ~ rok, type="b",
main = "Naivná predpoveď",
ylim = c(min(nehody,forMultiLo_Naive), max(nehody,forMultiUp_Naive))
)
polygon(x = c(rok, rev(rok)),
y = c(forMultiLo_Naive, rev(forMultiUp_Naive)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forMulti_Naive ~ rok, col = 4)
# sezónne naivná predpoveď
plot(nehody ~ rok, type="b",
main = "Sezónna naivná predpoveď",
ylim = c(min(nehody,forMultiLo_SNaive), max(nehody,forMultiUp_SNaive))
)
polygon(x = c(rok, rev(rok)),
y = c(forMultiLo_SNaive, rev(forMultiUp_SNaive)),
col = adjustcolor(4, alpha.f=0.2), border = F)
lines(forMulti_SNaive ~ rok, col = 4)
})
# numerické porovnanie
with(dat$valid, list(Naivné = cbind(forMulti_Naive, nehody),
"Sezónne naivné" = cbind(forMulti_SNaive, nehody),
TlinSind = cbind(forMulti_TlinSind, nehody),
TlinScos = cbind(forMulti_TlinScos, nehody),
TconSind = cbind(forMulti_TconSind, nehody),
TconScos = cbind(forMulti_TconScos, nehody)
)) |>
sapply(fun$MeanForecastError) |> t() |> round(2)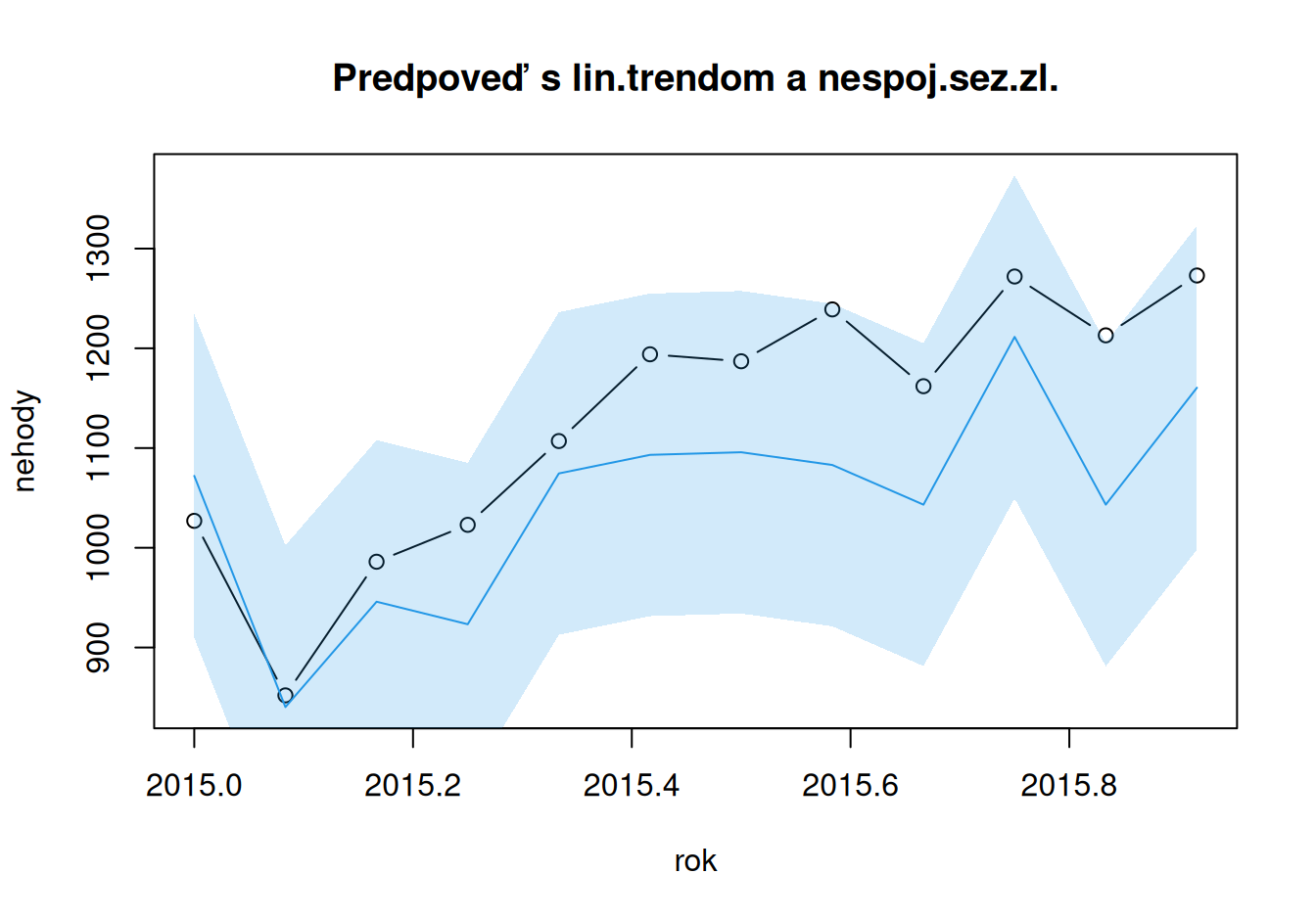
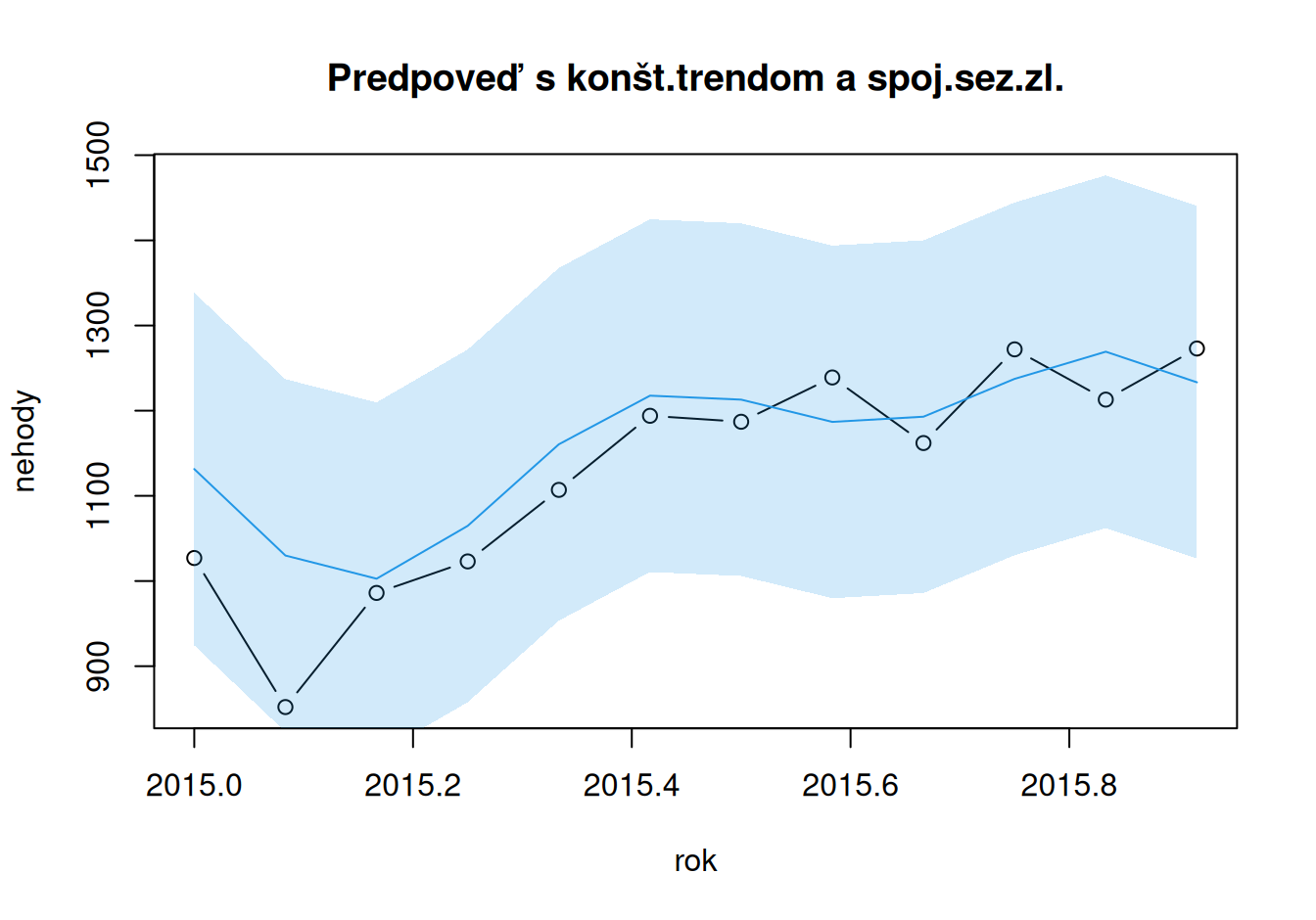
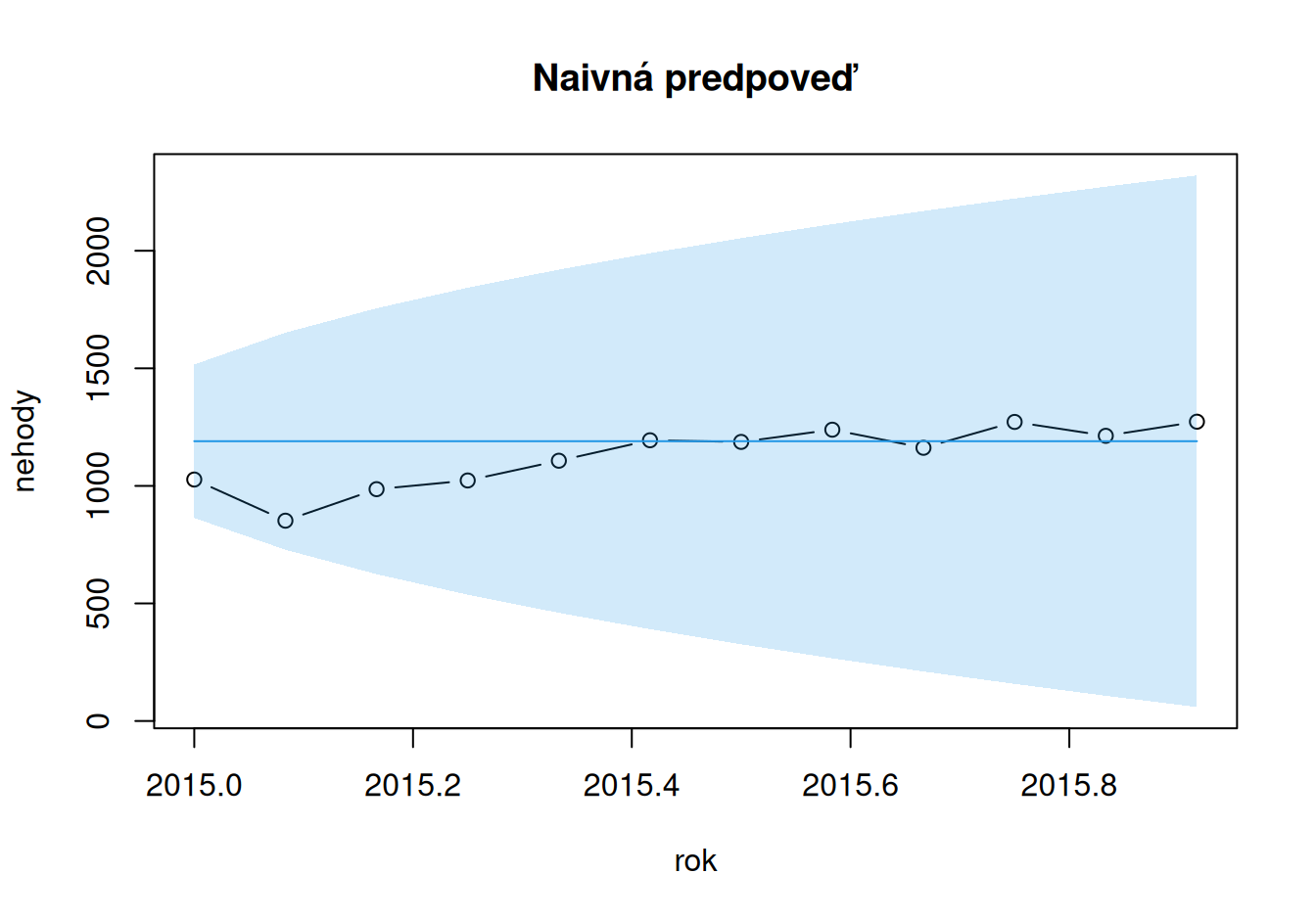
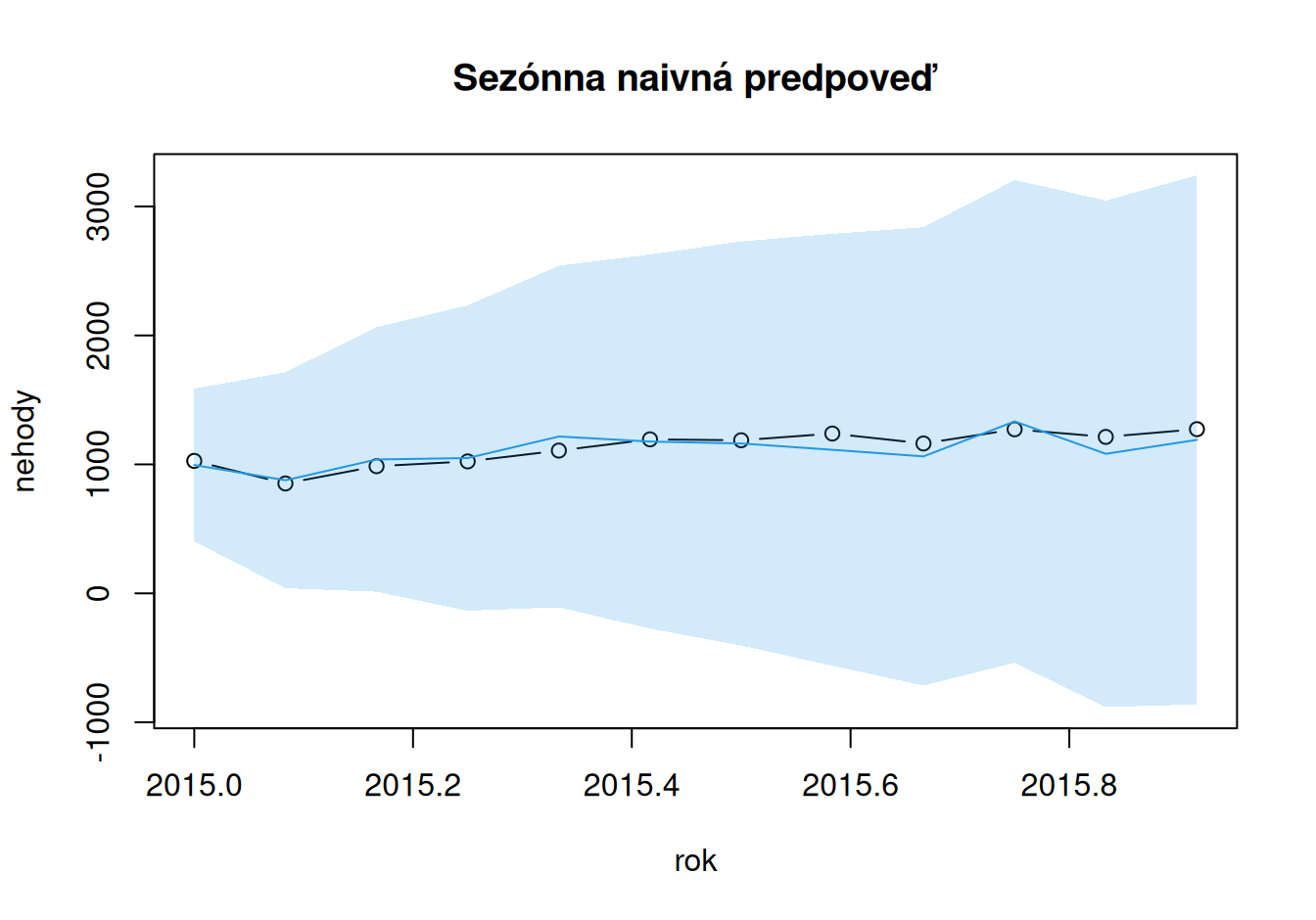
ME MSE RMSE MAE MAPE sMAPE MASE
Naivné -62.08 19546.58 139.81 102.25 10.16 9.27 1.28
Sezónne naivné 20.08 5955.92 77.17 65.58 5.68 5.77 0.82
TlinSind 79.04 9735.84 98.67 86.55 7.42 7.77 1.08
TlinScos 78.62 10416.10 102.06 91.20 7.93 8.27 1.14
TconSind -33.73 4389.10 66.25 50.32 4.78 4.61 0.63
TconScos -33.73 4859.08 69.71 54.81 5.27 5.04 0.68Na predpovediach sa ukázalo, že všeobecný lineárny trend je príliš komplikovaný na popis vývoja nehodovosti a stačí konštantný trend. Zároveň však na popis sezónnosti je potrebný zložitejší model – s parametrom pre každú sezónu.
Nevhodnosť všeobecného lineárneho trendu je vidieť aj na horšej presnosti oproti modelu sezónnych naivných predpovedí. Tie sú, mimochodom, najrovnomernejšie usporiadané predpovede okolo pozorovaných hodnôt (nízka stredná chyba ME).
plot(nehody ~ rok, data = dat$all, type = "n")
lines(nehody ~ rok, data = dat$train, col = grey(0.5), type = "b")
lines(nehody ~ rok, data = dat$valid, col = rgb(1,0,0, alpha=0.5), type = "b")
lines(fit$All$TconSind$fitted.values ~ dat$train$rok, col = 4)
lines(forMulti_TconSind ~ rok, data = dat$valid, col = 4, lwd = 2)
legend("topright",
legend=c("trénovacia vzorka", "validačná vzorka", "model", "predpoveď"),
lty = c(NA,NA,1,1), col = c(1,2,4,4), lwd = c(NA,NA,1,2), pch = c(1,1,NA,NA),
bty="n")