Kód
# skeleton function
F <- function(x, fi0=c(0,0)) ifelse(x<=0, fi0[1] - 0.5*x, fi0[2] + 0.5*x)
# deterministic simulation
detsim <- function(n, start=0, fi0=c(0,0)) {
out <- start
for(i in 1:n) out <- append(out, F(out[i], fi0))
out
}Pri modeloch s premenlivými režimami určenými pozorovateľnou premennou sa predpokladá, že režimy, ktoré sa objavili v minulosti a súčasnosti, sú známe s istotou (i keď sa musia nájsť štatistickými metódami) a že jednotlivé režimy sú dostatočne presne popísané lienárnymi AR modelmi. Zmena autoregresných parametrov je súčasne zmenou autokorelačnej štruktúry daného stochastického procesu, ktorý generuje skúmaný časový rad.
Jedným z najznámejších predstaviteľov je trieda modelov TAR (threshold autoregressive). V nich režim, ktorý nastane v čase \(t\) je určený pozorovateľnou, indikačnou premennou \(Z_t\) (threshold variable), ktorej hodnoty sú porovnávané s tzv. prahovou hodnotou \(c\) (threshold). Formálne, 2-režimový TAR model má tvar \[ X_t = \begin{cases} \varphi_{1,0} + \varphi_{1,1}X_{t-1} + \ldots + \varphi_{1,p_1}X_{t-p_1} + \varepsilon_t & \text{ak } Z_t\leq c \\ \varphi_{2,0} + \varphi_{2,1}X_{t-1} + \ldots + \varphi_{2,p_2}X_{t-p_2} + \varepsilon_t & \text{ak } Z_t> c \end{cases} \] v kompaktnom zápise \[ X_t = \phi_1'Y_{t,1} I(Z_t\leq c) + \phi_2'Y_{t,2} I(Z_t> c) + \varepsilon_t \] kde \(\varepsilon_t\) je proces bieleho šumu, čiže \(E(\varepsilon_t)=E(\varepsilon_t|\Omega_{t-1})=0\) a \(D(\varepsilon_t)=\sigma_\epsilon^2\) pre \(t=1,\ldots,n\), ďalej \(\phi_i=(\varphi_{i,0},\ldots,\varphi_{i,p_i})'\), \(i=1,2\), je vektor autoregresných parametrov v \(i\)-tom režime, \(Y_{t,i} = (1,X_{t-1},\ldots,X_{t-p_i})'\) je vektor bázových funkcií lineárneho modelu a indikačná funkcia \(I\) je definovaná tak, že \(I(A) = 1\) ak A platí, inak sa rovná 0. Štandardne predpokladáme stĺpcové vektory, potom \(\phi_i'\) označuje transpozíciu, a teda riadkový vektor.
Indikačná (alebo prahová) premenná môže nadobúdať hodnoty sledovaného časového radu posunuté v čase o \(d\in N\) časových intervalov, t.j., \(Z_t=X_{t-d}\), alebo v podobnom zmysle hodnoty iného časového radu (exogénna premenná).
Prehľad najvplyvnejších článkov o aplikácii TAR modelov v ekonómii podáva napr. (Bruce E. Hansen 2011).
Self-exciting threshold autoregressive model je špeciálnym prípadom TAR modelu, keď indikačná premenná je endogénna, teda \(Z_t=X_{t-d}\). Dvojrežimový SETAR model v klasickom tvare \[ X_t = \begin{cases} \varphi_{1,0} + \varphi_{1,1}X_{t-1} + \ldots + \varphi_{1,p_1}X_{t-p_1} + \varepsilon_t & \text{ak } X_{t-d}\leq c \\ \varphi_{2,0} + \varphi_{2,1}X_{t-1} + \ldots + \varphi_{2,p_2}X_{t-p_2} + \varepsilon_t & \text{ak } X_{t-d}> c \end{cases} \tag{8.1}\] je pomocou indikačnej funkcie zapísaný ako \[ \begin{split} X_t &= \phi_1' Y_{t,1} I(X_{t-d}\leq c) + \phi_2' Y_{t,2} I(X_{t-d}> c) + \varepsilon_t\\ &= \phi_1' Y_{t,1} [1-I(X_{t-d}> c)] + \phi_2' Y_{t,2} I(X_{t-d}> c) + \varepsilon_t \end{split} \] V nasledujúcich podkapitolách si na príkladoch jednoduchých SETAR modelov ilustrujeme pojem ekvilibria, ďalej ukážeme zovšeobecnenie na ľubovoľný počet režimov, odhad parametrov, test linearity voči nelinearite typu SETAR, diagnostický test a predpovedanie.
Na pochopenie alebo aspoň získanie pocitu z vnútornej dynamiky viacrežimových modelov uvažujme jednoduchý 2-režimový SETAR model s hyperparametrami \(d=p_1=p_2=1\). Skeleton takého modelu je daný vzťahom \[ F(X_{t-1})=\begin{cases} \varphi_{1,0} + \varphi_{1,1}X_{t-1} & \text{ak } X_{t-1}\leq c \\ \varphi_{2,0} + \varphi_{2,1}X_{t-1} & \text{ak } X_{t-1}> c \end{cases} \] Dôležitú úlohu tu hrajú už absolútne členy \(\varphi_{1,0}, \varphi_{2,0}\). Pre ilustráciu zafixujme ostatné parametre na hodnotách \(c=0\), \(\varphi_{1,1}=-0.5\), \(\varphi_{2,1}=0.5\). V tomto jednoduchom modeli získame ekvilibrium ako priesečník skeletonu \(X_t=F(X_{t-1})\) a priamky \(X_t=X_{t-1}\).
# skeleton function
F <- function(x, fi0=c(0,0)) ifelse(x<=0, fi0[1] - 0.5*x, fi0[2] + 0.5*x)
# deterministic simulation
detsim <- function(n, start=0, fi0=c(0,0)) {
out <- start
for(i in 1:n) out <- append(out, F(out[i], fi0))
out
}#, a $e_t N(0,0.25^2)$
op <- par(no.readonly = TRUE)
layout(matrix(1:(4*3), 4, 3, byrow = TRUE), widths=c(3,3,2))
xt_expr <- expression(italic(x[t]))
xt1_expr <- expression(italic(x[t-1]))
skeleton <- data.frame(x=seq(-1,1,length.out=100))
# ------------- plot 1 --------------
fi0 <- c(0,0)
# stochastic simulation
sim <- -0.5
for(i in 1:200) sim <- append(sim, F(sim[i], fi0=fi0)+rnorm(1,0,0.25))
# deterministic simulation
dsim <- sapply(-1:1, detsim, n=20, fi0=fi0)
# stochastic simulation time plot
plot(sim, type="l", xlab="t", ylab=xt_expr)
title(expression(paste("a) ", phi[{10}], " = ", 0, " , ", phi[{20}], " = ", 0)), adj=0)
#title(expression(paste("a) ", phi[{10}], " = ", fi0[1], " , ", phi[{20}], " = ", fi0[2])), adj=0)
# deterministic simulation time plot
matplot(dsim, pch=20, type="b", col=2:4, xlab="t", ylab=xt_expr)
# scatter plot X_t-1 vs. X_t
skeleton$y <- F(skeleton$x, fi0=fi0)
plot(skeleton, ylim=c(-1,1), asp=1, col="purple", xlab=xt1_expr, ylab=xt_expr, pch=".", cex=2)
abline(a=0,b=1, lty="dashed", col=8)
points(sim[-length(sim)],sim[-1], pch=".", cex=2)
# ------------- plot 2 --------------
fi0 <- c(-0.3,0.1)
# stochastic simulation
sim <- -0.5
for(i in 1:200) sim <- append(sim, F(sim[i], fi0=fi0)+rnorm(1,0,0.25))
# deterministic simulation
dsim <- sapply(-1:1, detsim, n=20, fi0=fi0)
# stochastic simulation time plot
plot(sim, type="l", xlab="t", ylab=xt_expr)
title(expression(paste("b) ", phi[{10}], " = -0.3 , ", phi[{20}], " = 0.1")), adj=0)
# deterministic simulation time plot
matplot(dsim, pch=20, type="b", col=2:4, xlab="t", ylab=xt_expr)
# scatter plot X_t-1 vs. X_t
skeleton$y <- F(skeleton$x, fi0=fi0)
plot(skeleton, ylim=c(-1,1), asp=1, col="purple", xlab=xt1_expr, ylab=xt_expr, pch=".", cex=2)
abline(a=0,b=1, lty="dashed", col=8)
points(sim[-length(sim)],sim[-1], pch=".", cex=2)
# ------------- plot 3 --------------
# stochastic simulation
fi0 <- c(-0.3,-0.1)
sim <- -0.5
for(i in 1:200) sim <- append(sim, F(sim[i],fi0=fi0)+rnorm(1,0,0.25))
# deterministic simulation
dsim <- sapply(-1:1, detsim, n=20, fi0=fi0)
# stochastic simulation time plot
plot(sim, type="l", xlab="t", ylab=xt_expr)
title(expression(paste("c) ", phi[{10}], " = -0.3 , ", phi[{20}], " = -0.1")), adj=0)
# deterministic simulation time plot
matplot(dsim, pch=20, type="b", col=2:4, xlab="t", ylab=xt_expr)
# scatter plot X_t-1 vs. X_t
skeleton$y <- F(skeleton$x, fi0=fi0)
plot(skeleton, ylim=c(-1,1), asp=1, col="purple", xlab=xt1_expr, ylab=xt_expr, pch=".", cex=2)
abline(a=0,b=1, lty="dashed", col=8)
points(sim[-length(sim)],sim[-1], pch=".", cex=2)
# ------------- plot 4 --------------
fi0 <- c(0.3,-0.1)
# stochastic simulation
sim <- -0.5
for(i in 1:200) sim <- append(sim, F(sim[i],fi0=fi0)+rnorm(1,0,0.25))
# deterministic simulation
dsim <- sapply(-1:1, detsim, n=20, fi0=fi0)
# stochastic simulation time plot
plot(sim, type="l", xlab="t", ylab=xt_expr)
title(expression(paste("d) ", italic(phi[{10}]), " = 0.3 , ", phi[{20}], " = -0.1")), adj=0)
# deterministic simulation time plot
matplot(dsim, pch=20, type="b", col=2:4, xlab="t", ylab=xt_expr)
# scatter plot X_t-1 vs. X_t
skeleton$y <- F(skeleton$x, fi0=fi0)
plot(skeleton, ylim=c(-1,1), asp=1, col="purple", xlab=xt1_expr, ylab=xt_expr, pch=".", cex=2)
abline(a=0,b=1, lty="dashed", col=8)
points(sim[-length(sim)],sim[-1], pch=".", cex=2)
par(op)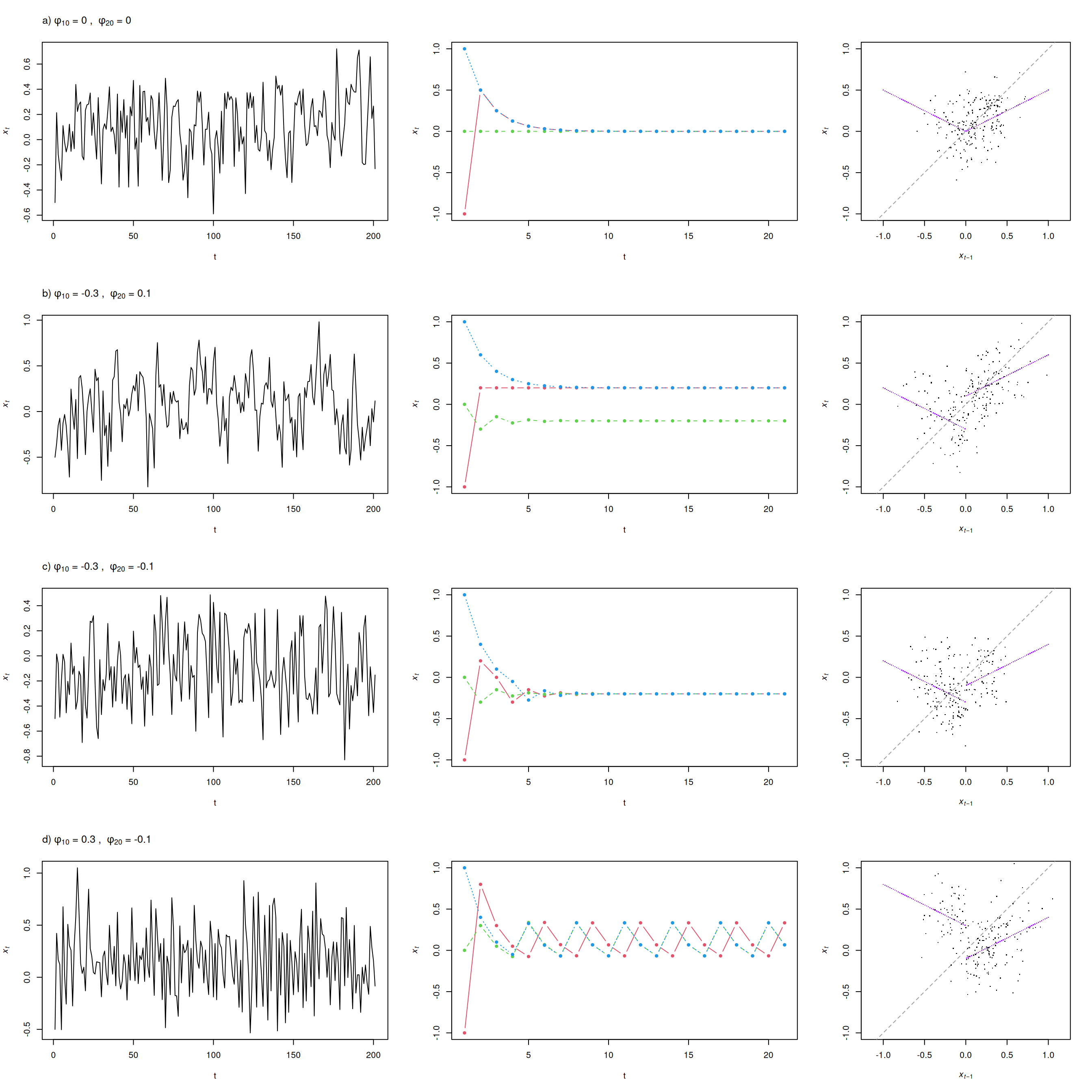
Na Obr. 8.1 sú zobrazené postupne graf stochastickej simulácie (skeleton \(+\) šum), deterministickej simulácie (iba skeleton) a spolu v grafe \(X_{t-1}\) oproti \(X_t\). Prvý riadok (a) zodpovedá modelu s absolútnymi členmi \(\varphi_{1,0}=\varphi_{2,0}=0\), vidno tam jediné a stabilné ekvilibrium \(x^*=0\), ale stredná hodnota časového radu nie je 0, kôli zápornému \(\varphi_{1,1}\) (a pri \(\varepsilon_t=0\) stochastický proces opúšťa dolný režim hneď v ďaľšom časovom kroku, zatiaľčo v dôsledku \(0<\varphi_{2,1}\) proces má tendenciu zotrvať v hornom režime dlhšie, i keď je tlačený ku nule (\(\varphi_{2,1}<1\)). Časový rad tak bude v priemere nadobúdať kladné hodnoty, teda \(E(X_t)>0\).
Skeleton druhého modelu (b) na Obr. 8.1 má dva priesečníky so 45° priamkou, model tak má ekvilibriá \(x^*_1=-0.2\) a \(x^*_2=0.2\), a obe sú zjavne stabilné (absolútne členy \(\varphi_{i,0}\) AR modelov ležia každý vo svojom režime).
Model zobrazený na Obr. 8.1 c) má jediné stabilné ekvilibrium \(x^*=-0.2\). Všimnime si, že stredná hodnota AR modelu horného režimu je záporná (to, že sa rovná práve -0.2, nie je dôležité), takže ak v ňom časový rad začne, je priťahovaný dolným režimom. A pretože stredná hodnota dolného režimu je tiež záporná, je atraktorom celého modelu.
Posledný model (d) nemá žiadne ekvilibrium, stredné hodnoty jednotlivých AR modelov ležia v inom režime, časový rad si tak “nemá kde oddýchnuť”. No aj tak má model jeden atraktor, a tým je hraničný cyklus (limit cycle), konkrétne tri body uzavretej trajektórie \(x^*_1=0.0667\), \(x^*_2=-0.0667\) a \(x^*_3=0.3333\). Posledný model je príkladom toho, že nelineárny proces môže obsahovať endogénnu dynamiku (t.j., fluktuuje aj bez náhodných vzruchov).
Niekedy dva režimy nestačia, to si v rámci výstavby modelu s premenlivými režimami väčšinou overujeme pri diagnostických testoch. Rozšírenie 2-režimového SETAR do \(m\)-režimov je najjednoduchšie v tvare
\[
X_t = \varphi_{i,0} + \varphi_{i,1}X_{t-1} + \ldots + \varphi_{i,p_i}X_{t-p_i} + \varepsilon_t \quad\text{ak}\quad c_{i-1}<X_{t-d}\leq c_i
\] či pomocou indikačnej funkcie v maticovom zápise \[
\begin{split}
X_t = \phi_1' Y_{t,1} [1-I(Z_t>c_1)] + \phi_2' Y_{t,2} I(Z_t>c_1)[1-I(Z_t>c_2)] + \ldots \\ +\ \phi_m' Y_{t,m} I(Z_t>c_{m-1}) + \varepsilon_t
\end{split}
\tag{8.2}\] pre \(i=1,\ldots,m\) a \(-\infty=c_0<c_1<\ldots<c_m=\infty\).
Iný spôsob rozšírenia o ďalšie režimy ponúka tzv. Nested TAR (vnorený, NeTAR), v ktorom sú režimy určené kombináciou viacerých premenných, napr. \[ X_t = \begin{cases} \varphi_{1,0} + \varphi_{1,1}X_{t-1} & \text{ak } X_{t-1}\leq c_1 \text{ a } X_{t-2}\leq c_2 \\ \varphi_{2,0} + \varphi_{2,1}X_{t-1} & \text{ak } X_{t-1}\leq c_1 \text{ a } X_{t-2}>c_2 \\ \varphi_{3,0} + \varphi_{3,1}X_{t-1} & \text{ak } X_{t-1} > c_1 \text{ a } X_{t-2}\leq c_2 \\ \varphi_{4,0} + \varphi_{4,1}X_{t-1} & \text{ak } X_{t-1} > c_1 \text{ a } X_{t-2} > c_2 \end{cases} \]
Dôležitou súčasťou špecifikácie modelu s premenlivými režimami je identifikácia stupňa autoregresných modelov v jednotlivých režimov. Jeden z prístupov, ktoré sa bežne používajú, jednoducho identifikuje stupeň lineárneho AR modelu (pomocou parciaálnej autokorelčnej funkcie) a stotžní ho so stupňom v oboch režimoch. To je riskantný predpoklad, pretože na jednej strane niektoré nelineárne modely môžu vykazovať nulovú autokoreláciu vo všetkych časových posunoch a na druhú stranu aj relatívne jednoduché nelineárne modely môžu mať komplikovanú autokorelačnú štruktúru, ktorú pokryjú len AR modely vyšších rádov. Napríklad tzv. znamienkový model \(X_t=sign(X_{t-1})+\varepsilon_t\), kde \(sign(x)=1\) ak \(x>0\) a \(sign(x)=-1\) ak \(x<0\), má vlastnosti modelov s dlhou pamäťou. Alebo, hoci pre simulované časové rady prvých troch modelov z Obr. 1 väčšinou minimalizáciou AIC dostaneme korektný rád \(p=1\), pre SETAR model d) je AIC minimálne pri ráde \(p=4\).
Alternatívny prístup využíva informačné kritériá prispôsobené modelom s premenlivými režimami, \[ \begin{split} AIC(p_1,\ldots,p_m) &= \sum_{i=1}^m n_i\ln\hat{\sigma}_i^2 + 2(p_i+1) \\ BIC(p_1,\ldots,p_m) &= \sum_{i=1}^m n_i\ln\hat{\sigma}_i^2 + (p_i+1)\ln n_i \end{split} \] kde \(\hat{\sigma}_i^2\) je odhad reziduálneho rozptylu a \(n_i\) počet pozorovaní v \(i\)-tom režime. Minimalizáciou AIC alebo BIC vyberieme vhodné stupne \(p_1,\ldots,p_m\).
Uvažujme 2-režimový SETAR model (8.1). Parametre \(\phi_i\), \(c\), \(\sigma_{\varepsilon}^2\) sa dajú pohodlne odhadnúť podmienenou metódou najmenších štvorcov (v prípade normality šumu je odhad totožný s metódou maximálnej vierohodnosti) spolu s oneskorením \(d\) v nasledujúcej procedúre pozostávajúcej z niekoľkých vnorených cyklov:
Výpočtovo úspornejší spôsob identifikácie stupňov AR modelu v rámci odhadovacej procedúry je nahradiť cykly pre \(p_1,p_2\) jediným cyklom pre \(p=1,\ldots,p_{max}\), potom \(p_1,p_2\) určíme z odhadov autoregresných koeficientov: tie, ktorých hodnota je rádovo porovnateľná alebo menšia ako ich štandardná chyba, položíme rovné nule. Štandardné chyby odhadov autoregresných parametrov určíme odmocnením diagonálnych prvkov kovariančnej matice \(\hat{\Sigma}_{\phi}(\hat{c})=\hat{\sigma}_{\varepsilon}^2(\hat{c})\left(\sum_{t=k+1}^nY_t(\hat{c})\cdot Y_t(\hat{c})'\right)^{-1}\).
# stochastic simulation
set.seed(3)
sim <- rnorm(1,0,0.25)
for(i in 1:200) sim <- append(sim, F(sim[i], fi0=c(-0.3,0.1)) + rnorm(1,0,0.25))
IndikFun <- function(x, c) ifelse(x>c,1,0)
Yt <- function(x, t, p) c(1, x[(t-1):(t-p)])
Xt <- function(x, t, p, d, c, z=x) { # z is the thresshold variable, presently not used
I <- IndikFun(z[t-d], c)
Y <- Yt(x, t, p)
c( (1-I)*Y, I*Y )
}
LRtestatSETAR <- function(x, p, d, c, c_hat) {
n <- length(x)
var <- function(c) {
X <- t(sapply((p+1):n, function(t) rbind(Xt(x, t, p, d, c)) ))
covmat <- solve(t(X) %*% X)
par <- covmat %*% t(X) %*% x[-(1:p)]
sqresid <- (x[-(1:p)] - X %*% par)^2
sum(sqresid)/(n-p)
}
var_c_hat <- var(c_hat)
sapply(c, function(x) n * (var(x) - var_c_hat) / var_c_hat)
}
c_ran <- quantile(sim, c(0.1,0.9))
c_seq <- seq(c_ran[1], c_ran[2], length.out = 200)
LRval <- LRtestatSETAR(sim, p=1, d=1, c = c_seq, c_hat=0)
LRcrit <- round(-2*log(1-sqrt(0.95)), 2)
c_int <- range(c_seq[LRval<LRcrit], na.rm=T)
plot(c_seq, LRval, type="l", ylab="LR", xlab="c")
abline(h=LRcrit, lty="dashed")
abline(v=c_int, lty="dotted")
text(x = c_ran[2] - 0.9*diff(c_ran), y=0.8*LRcrit, labels=c(paste("crit =", LRcrit)))
text(x = c_int, y=0.98*max(LRval), labels=paste(round(c_int,2)), pos=c(2,4))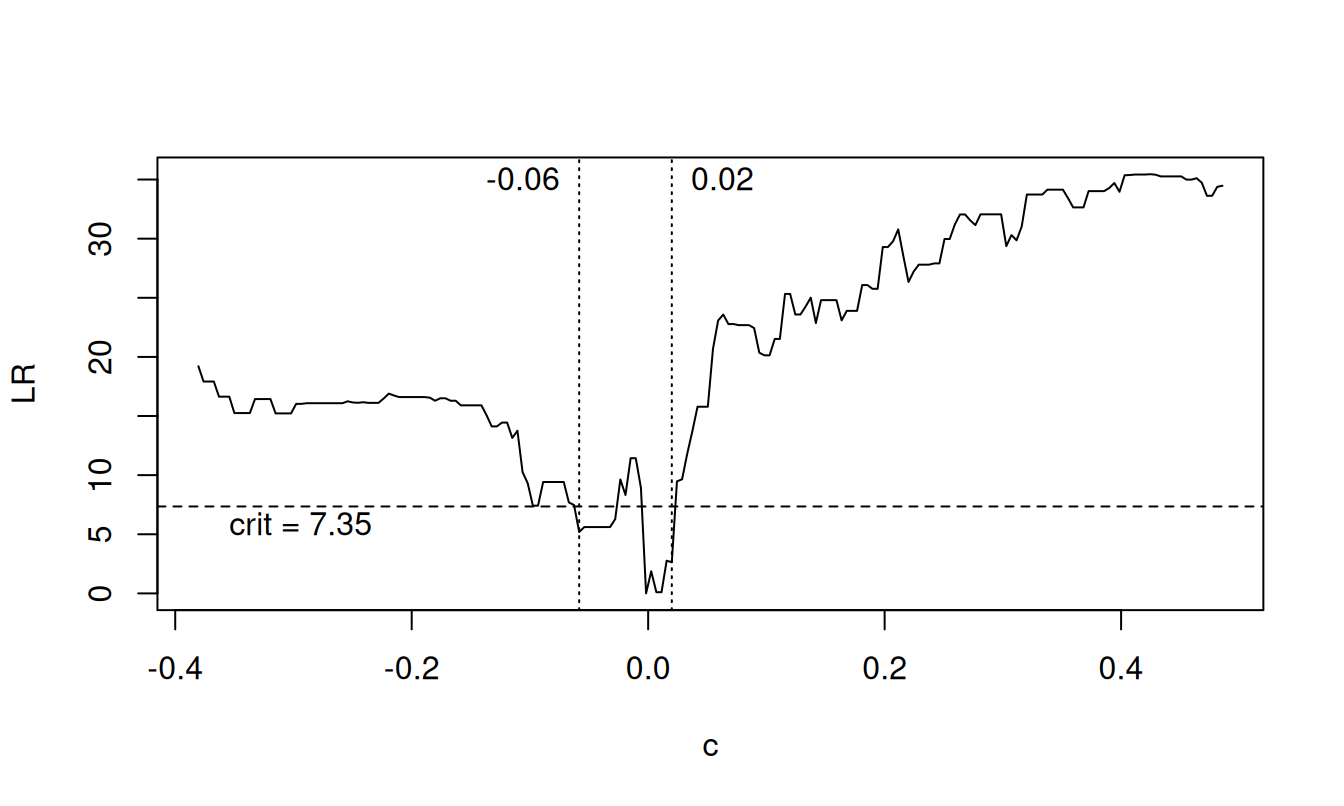
Intervalový odhad prahovej hodnoty sa dá určiť napríklad porovaním tzv. LR testovacej štatistiky (podrobnejšie v časti o testovaní linearity) \(LR(c)=n\left( \frac{\hat{\sigma}_{\varepsilon}^2(c)-\hat{\sigma}_{\varepsilon}^2(\hat{c})} {\hat{\sigma}_{\varepsilon}^2(\hat{c})} \right)\) s asymptotickým rozdelením daným distribučnou funkciou \(P(LR(c)<x)=H(x)=(1-e^{-x/2})^2\) (Bruce E. Hansen 1996), pričom množina \(\hat{\mathcal{C}}_p=\{c\colon LR(c)\leq H^{-1}(p)\}\) predstavuje oblasť, v ktorej sa s pravdepodobnosťou \(p\) nachádza skutočná hodnota parametra \(c\), a \(H^{-1}\) značí kvantilovú funkciu. Príklad určenia takejto oblasti pre simulovaný časový rad z modelu (b) na Obr. 8.1 ilustruje Obr. 8.2.
Pre úplnosť, hoci autoregresné parametre majú asymptoticky normálne rozdelenie, kedy napr. 95% interval spoľahlivosti zodpovedá rozsahu \(\hat{\varphi}_{j,i}\pm 1.95\hat{\sigma}_{\varphi_{j,i}}\), pre časové rady bežnej dĺžky je podľa (Bruce E. Hansen 1996) realistickejšie uvažovať zjednotenie takýchto intervalov parametra \(\hat{\varphi}(c)_{j,i}\) pre všetky \(c\in\hat{\mathcal{C}}_p\).
Keď už máme optimálny odhad rádu AR, oneskorenia a parametrov, môžeme testovať linearitu oproti nelinearite typu SETAR. Odporúča sa urobiť tento test pre niekoľko najlepších modelov, ktoré sme dostali z odhadovacej procedúry.
Zásadnou otázkou pri konštrukcii modelov s premenlivými režimami je tá, či dynamické chovanie časového radu indikuje viacrežimovosť alebo nie. Odpoveď môžeme získať štatistickým porovnaním “kvality” lineárneho modelu a modelu s viacerými režimami. Postup spočíva v testovaní hypotézy \(H_0\), že vhodný je lineárny model. Alternatívnou hypotézou \(H_1\) je, že vhodný model má viac režimov.
Problém štatistických testov v prípade všetkých typov viacrežimových modelov je, že pri testovaní nulovej hypotézy je identifikovaných menej parametrov ako pri alternatívnej hypotéze, tzn. že nelineárne modely obsahujú aj parametre, ktoré sa nevyskytujú pri lineárnych a ani ohraničujúcimi podmienkami na tieto parametre nemôžeme lineárne modely získať. V prípade 2-režimového TAR modelu je takým parametrom prahová hodnota \(c\). Dôsledkom existencie týchto prebytočných parametrov je, že testovacie štatistiky majú neštandardné rozdelenia pravdepodobnosti, ktoré sa často ani nedajú vyjadriť analyticky a preto je nutné kritické hodnoty (kvantily) získať pomocou simulačných metód.1
Konkrétne pri procese s premenlivými režimami a ostrým prechodom medzi režimami, TAR (teda aj SETAR), testujeme hypotézu \(H_0\colon\phi_1=\phi_2\) (linearita procesu) oproti alternatívnej hypotéze \(H_1\colon\phi_1\neq\phi_2\).
Najprv sa odhadnú parametre (s absolútnymi členmi) AR aj 2-režimového SETAR modelu. Reziduálny rozptyl pri nulovej hypotéze (t.j. lineárneho modelu) ponesie označenie \(\hat{\sigma}_L^2\) a pri alternatívnej \(\hat{\sigma}_{NL}^2\). Testovacia štatistika LR-testu (Likelihood Ratio) je (ako štatistika F-testu) daná vzťahom \[ LR(\hat{c})=n\ \frac{\hat{\sigma}_L^2-\hat{\sigma}_{NL}^2(\hat{c})}{\hat{\sigma}_{NL}^2(\hat{c})} \] a teda je nepriamo úmerná reziduálnemu rozptylu nelineárneho modelu. Štatistika \(LR\) by mala pre presne danú prahovú hodnotu \(c\) asymptoticky \(\chi^2\)-rozdelenie s \(\max_i(p_i)+1\) stupňami voľnosti, my sme však hodnotu \(\hat{c}\) určili minimalizáciou reziduálneho rozptylu (pre dané \(p_i,d\)), a tak \(LR(\hat{c})=\sup_cLR(c)\), preto jej rozdelenie pravdepodobnosti nie je štandardné.
Hansen (Bruce E. Hansen 1996) odvodil asymptotické rozdelenie za určitých predpokladov, ak však nie sú splnené, treba použiť simulačnú procedúru, pozostávajúcu z \(N\) opakovaní nasledujúcich krokov cyklu:
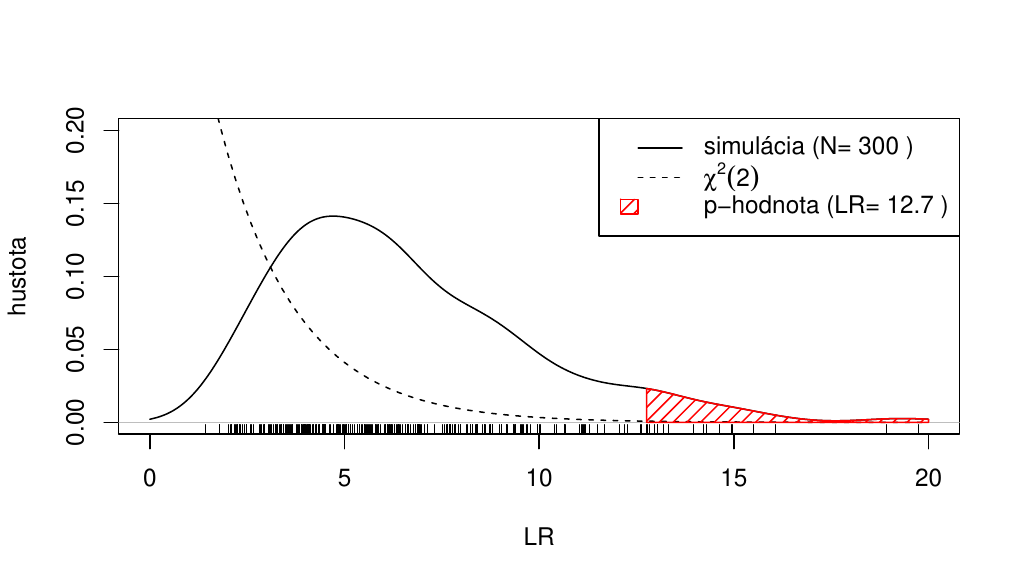
Potom distribučnú funkciu možno pre dostatočne veľké \(N\) aproximovať vzťahom \(P(LR(\hat{c})\leq x)=\frac1N\sum_{i=1}^NI\left(\widetilde{LR}^{(i)}\leq x\right)\) teda \(p\)-hodnota LR testu linearity sa jednoducho vypočíta ako percento hodnôt \(\widetilde{LR}^{(i)}\) presahujúcich hodnotu \(LR(\hat{c})\).
Obr. 8.3 znázorňuje odhad hustoty rozdelenia pravdepodobnosti testovaciej štatistiky zo simulovaných hodnôt \(\widetilde{LR}^{(i)}\), \(i,\ldots,300\), ďalej ilustráciu p-hodnoty testu (pre LR štatistiku odhadhnutú zo skutočných pozorovaní) a nakoniec - pre porovnanie - hustotu \(\chi^2\) rozdelenia s 2 stupňami voľnosti.
Ak je simulačný prístup kôli výpočtovej náročnosti v praxi nevhodný, alternatívou k LR testu môže byť test typu LM (Lagrange multipliers), ktorý bol v kontexte modelov s premenlivými režimami danými pozorovateľnou premennou odvodený primárne pre modely STAR, no ukázalo sa, že nestráca svoju silu ani pri rýchlejšom prechode medzi režimami (hoci je nižšia než pri LR teste). Postup je nasledovný:
Ďalšie testy linearity v kontexte SETAR (a nelineárnych modelov všeobecne) sú prehľadne zhrnuté v (De Gooijer 2017, Chapter 5).
Podobne ako pri lineárnych nodeloch, aj v prípade viacrežimových modelov spočíva diagnostická kontrola hlavne v posúdení rezíduí. Niektoré testy používané pri lineárnych modeloch môžeme použiť aj tu (napr. Jarque-Berra test normality), iné však nie (napr. Ljung-Boxov test autokorelácie nemá známe asymptotické rozdelenie pri platnosti nulovej hypotézy). Najčastejšie sa používajú 2 typy testov:
k nim všeobecnou alternatívou je BDS test.
Ku diagnostickým nástrojom okrem testov patrí napr. kontrola stochastických či deterministických simulácií procesu, stacionarita AR modelu v jednotlivých režimoch, aj tzv. analýza odozvy impulzu (impulse response), o nej bližšie v (Franses a Van Dijk 2000, Chapter 3.6).
Uvažujme všeobecný nelineárny autoregresný model stupňa \(p\) \[ X_t=F(Y_t;\theta)+\varepsilon_t \] kde skeleton \(F\) je aspoň dvakrát spojite diferencovateľná funkcia prediktorov \(Y_t=(1,x_{t-1},\ldots,x_{t-p})\) s parametrami \(\theta\). Na testovanie autokorelácie \(q\)-teho stupňa rezíduí \(\varepsilon_t\) sa používa LM test s testovacou štatistikou \(LM=nR^2\), kde \(R^2\) je koeficient determinácie z regresie \(\hat\varepsilon_t\) na \(\partial F(Y_t;\theta)/\partial\theta\) a \((\hat\varepsilon_{t-1},\ldots,\hat\varepsilon_{t-q})\). Ak platí nulová hypotéza o nekorelovanosti rezíduí, \(LM\) má \(\chi^2\) rozdelenie s \(q\) stupňami voľnosti. Problém je, že skeleton SETAR modelu je nespojitá funkcia, preto LM test nemožno aplikovať priamo. Dá sa však použiť aproximácia LSTAR modelom, keď parameter vyhladenia nastavíme tak vysoko, že prechod medzi režimami je prakticky skokovitý. Podrobnosti neskôr.
Dôležitou otázku pri použití viacrežimových modelov je, či daný model dostatočne popisuje všetky zdroje nelinearity v skúmanom časovom rade. Jednou z možností je použiť test ostávajúcej nelinearity, ktorý v kontexte viacrežimových modelov napr. ku nulovej hypotéze o vhodnosti dvojrežimového modelu prirodzene stavia alternatívnu hypotézu o prítomnosti tretieho režimu. Jednoduchý postup ponúka napr. (Bruce E. Hansen 1999) v ktorom rozdelenie testovacej štatistiky \(LR=n\ \frac{\hat{\sigma}_{SETAR2}^2-\hat{\sigma}_{SETAR3}^3}{\hat{\sigma}_{SETAR3}^2}\) sa získa bootstrap simuláciou, konkrétne vygenerovaním \(N\) časových radov dĺžky \(n\) (ako šumovú zložku použijeme náhodný výber z rezíduí 2-režimového SETAR modelu, ktorý reprezentuje nulovú hypotézu) a odhadom dvoj a trojrežimového SETAR modelu pre každý z radov. Výsledný náhodný výber z rozdelenia pravdepodobnosti testovacej štatistiky za predpokladu platnosti nulovej hypotézy (vhodný je SETAR2) použijeme na výpočet p-hodnoty testu, rovnako ako pri restovani linearity.
Ako spomína napr. (Zivot a Wang 2006, Chapter 18.2), test vyvinutý autormi Broock, Dechert a Scheinkman (Broock et al. 1996) je pre svoju univerzálnosť jedným z najúspešnejších testov nelinearity a detekcie nevhodnej špecifikácie modelu. Hoci pôvodná motivácia bolo testovať nulovú hypotézu o nezávislosti a homogenite rozdelenia rezíduí (i.i.d.) pre účely detekcie tzv. nenáhodnej chaotickej dynamiky 2, ďalšie štúdie ukázali silu testu v prípade širokého rozsahu lineárnych a nelineárnych alternatív.
Hlavná myšlienka testu tkvie v korelačnom integrále ako miere opakovaného výskytu nejakých vzorcov v časovom rade, teda \[ C(q,r)=\frac{2}{n_q(n_q-1)}\mathop{\sum\sum}\limits_{p+1\leq s<t\leq n_q} I(||\hat{z}_{t,q}-\hat{z}_{s,q}||\leq r \hat{\sigma}_\varepsilon) \] kde
Korelačným integrálom tak odhadujeme pravdepodobnosť, že ľubovoľné dva \(q\)-rozmerné body sú navzájom vzdialené najviac \(r \hat{\sigma}_\varepsilon\). Ak je proces \(\{\varepsilon_t\}\) i.i.d (tvrdenie \(H_0\)), potom \(C(q,r)\) by sa v limitnom prípade malo rovnať \(C(1,r)^q\), preto testovacia štatistika BDS testu je postavená ako podiel \[ BDS=\frac{\sqrt{n}\Big(C(q,r)-C(1,r)^q\Big)}{\sigma(q,r)} \] kde \(\sigma(q,r)\) je štandardná odchýlka člena v čitateli (jej odhad je podrobne uvedený v spomínanej literatúre), a rozdelenie pravdepodobnosti \(BDS\) konverguje k \(N(0,1)\).
Ak diagnostické testy (najmä test ostávajúcej nelinearity) zamietli nulovú hypotézu, teda že 2-režimový SETAR model je postačujúci, je prirodzené skúsiť pridať ďalší režim a odhadnúť 3-režimový SETAR, zvolený podľa povahy skúmaného procesu, v najjednoduchšom prípade model (8.2) s \(m=3\). V odhadovacej procedúre vychádzame z predpokladu, že oproti 2-režimovému ostáva zachovaná iba indikačná premenná, teda hyperparameter \(d\):
Okrem popisu dynamiky časového radu je častým dôvodom jeho modelovania aj výpočet predpovedí, a to bodových aj intervalových. Avšak v porovnaní s lineárnymi modelmi je ich konštrukcia výrazne náročnejšia.
Vo všeobecnosti, \(h\)-kroková bodová predpoveď z nelineárneho modelu \(X_t=F(\Omega_{t-1})+\varepsilon_t\) je z pohľadu kritéria najmenších štvorcov daná ako podmienená stredná hodnota \(\hat X_{t+h|t}=E(X_{t+h}|\Omega_t)\). Pre horizont \(h=1\) je predpoveď totožná s predpoveďou z lineárneho modelu, teda \[
\hat X_{t+1|t} = E[F(\Omega_t)+\varepsilon_{t+1}|\Omega_t] = F(\Omega_t)
\] pretože \(E(\varepsilon_{t+1}|\Omega_t)=0\). Výpočet sa však skomplikuje už pri 2-krokovej predpovedi \[
\begin{split}
\hat X_{t+2|t} &= E(X_{t+2}|\Omega_t) = E[F(\Omega_{t+1})+\varepsilon_{t+2}|\Omega_t] = E[F(\{\ldots,F(\Omega_t)+\varepsilon_{t+1}\})|\Omega_t] \\
&= \int_{-\infty}^\infty F(\{\ldots,\hat X_{t+1|t}+\varepsilon\})dG(\varepsilon)
\end{split}
\tag{8.3}\] kde \(G\) je distribučná funkcia šumu \(\{\varepsilon_t\}\). Vo všeobecnosti totiž poradie lineárneho operátora strednej hodnoty a nelineárneho operátora nemožno zameniť, a ak to urobíme, t.j., ak zanedbáme náhodný člen \(\varepsilon_{t+1}\),
\[
E[F(\Omega_{t+1})|\Omega_t] \neq F(\{\ldots,E[X_{t+1}|\Omega_t]\}) = F(\{\ldots,\hat X_{t+1|t}\})=\hat X_{t+2|t}^{(n)}
\] dostávame vychýlený odhad \(X_{t+2}\), tzv. naivnú predpoveď \(\hat X_{t+2|t}^{(n)}\).
Nevychýlený odhad \(\hat X_{t+2|t}\) pomocou vzťahu (8.3) s Riemann–Stieltjesovým integrálom, prepísaným do tvaru Riemanovho integrálu (za podmienky absolútne spojitej distribučnej funkcie \(G\) s hustotou \(g\)) \[ \hat X_{t+2|t} = \int_{-\infty}^\infty F(\{\ldots,\hat X_{t+1|t}+\varepsilon\})g(\varepsilon)d\varepsilon, \] vo všeobecnosti nie je známy v explicitnom analytickom tvare (bez integrálu), takže je ho potrebné aproximovať technikami numerického integrovania. Navyše v praxi ani rozdelenie šumu nemusí byť známe a často sa predpokladá normálne rozdelenie.
V tomto zmysle \(h\)-krokovú predpoveď dostaneme z hustoty združeného rozdelenia pravdepodobnosti náhodného vektora \((X_{t+1},\ldots,X_{t+h})\) podmieneného pozorovaniami \(\Omega_t\) odintegrovaním všetkých premenných okrem \(X_{t+h}\). To už je značne zložité pre \(h>2\).
Preto sa používajú alternatívne prístupy viac-krokovej predpovede, a to také, ktoré aproximujú podmienenú strednú hodnotu ako v (8.3), najmä metódy Monte Carlo a bootstrap. Základom je rekurentný vzťah \[ \hat X_{t+h|t} = \frac1N\sum_{i=1}^N F(\{x_1,\ldots,x_t,\hat X_{t+1|t}+\tilde\varepsilon_{t+1}^{(i)},\ldots,\hat X_{t+h-1|t}+\tilde\varepsilon_{t+h-1}^{(i)}\}) = \frac1N\sum_{i=1}^N \hat X_{t+h|t}^{(i)} \] pre nejaké veľké \(N\), kde \(\tilde\varepsilon^{(i)}\) sú v prípade Monte Carlo prístupu náhodne generované z predpokladaného rozdelenia pravdepodobnosti reziduálnej zložky, a v prípade bootstrap náhodne vybrané (s opakovaním) z časového radu rezíduí daného nelineárneho modelu.
Výpočtovo aj implementačne jednoduchšou metódou je modifikácia rekurentného vzťahu využívajúca stochastickú simuláciu trajektórie procesu (process path), konkrétne \[ \hat X_{t+h|t} = \frac1N\sum_{i=1}^N F(\{x_1,\ldots,x_t,\hat X_{t+1|t}^{(i)}+\tilde\varepsilon_{t+1}^{(i)},\ldots,\hat X_{t+h-1|t}^{(i)}+\tilde\varepsilon_{t+h-1}^{(i)}\}) \] kde \(\hat X_{t+k|t}^{(i)}=F(\{x_1,\ldots,x_t,\hat X_{t+1|t}^{(i)}+\tilde\varepsilon_{t+1}^{(i)},\ldots,\hat X_{t+k-1|t}^{(i)}+\tilde\varepsilon_{t+h-1}^{(i)}\})\), \(k=1,\ldots,h-1\), kedy sa jednoducho vygeneruje \(N\) trajektórií s počiatočnými hodnotami \(x_1,\ldots,x_t\) a pre konkrétne \(h\) sa simulované realizácie procesu spriemerujú.
Intervalová predpoveď z lineárneho modelu je zvyčajne nejaký interval symetrický okolo bodovej predpovede, čo je dôsledkom predpokladu, že podmienené rozdelenie \(g(X_{t+h}|\Omega_t)\) je normálne (ak je predpoklad normality šumovej zložky) so strednou hodnotou \(\hat X_{t+h|t}\). To neplatí pre nelineárne modely, rozdelenie môže byť nesymetrické a dokonca multimodálne (obsahujúce viacero modusov). S týmto na zreteli treba voliť aj metódu konštrukcie \(100(1-\alpha)\%\) intervalovej predpovede (\(IP_\alpha\)). V zásade sú tieto tri:
set.seed(1)
dat <- c(
rnorm(500, 1, 1),
rnorm(250,-3,1)
)
yHDR <- 0.08
dens <- density(dat)
xHDR <- dens$x[order(abs(dens$y-yHDR))][1:10][!duplicated(round(dens$x[order(abs(dens$y-yHDR))][1:10],0))]
#xHDR <- c(-4.11, -1.93, -0.82, 2.68) #sort(dens$x[order(abs(dens$y-yHDR))][1:10])
plot(dens, main="", ylab="hustota", xlab=expression(X[paste("t+h|t")]))
rug(dat)
abline(h=yHDR, lty="dashed")
segments(x0=xHDR, y0=0, x1=xHDR, y1=yHDR, lty="dotted")
text(x=-7,y=yHDR+0.01, labels = expression(g[alpha]))
points(mean(dat), dens$y[which.min(abs(dens$x-mean(dat)))], pch=16)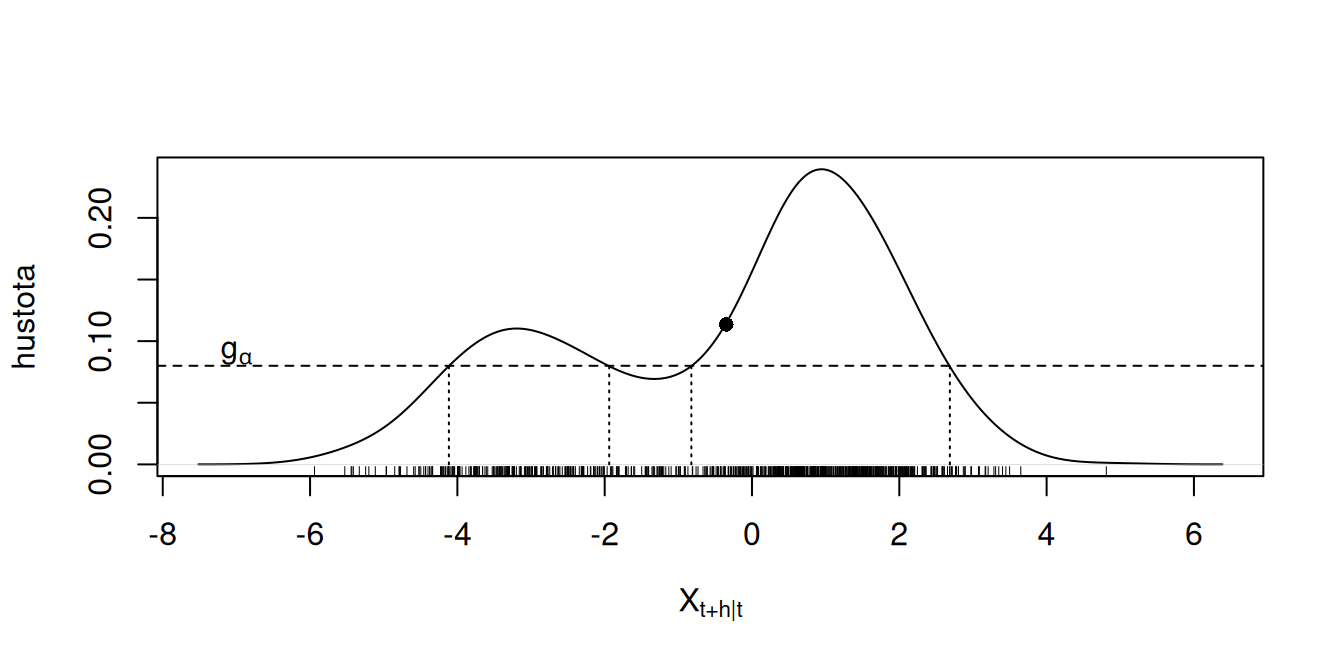
Pre symetrické a unimodálne rozdelenia dávajú tieto tri metódy totožný výsledok, preto stačí použiť výpočtovo najjednoduchšiu – prvú metódu. Pre nesymetrické unimodálne je prirodzenou voľbou \(IP^Q\), a pre multimodálne rozdelenia zas HDR metóda, ktorá dáva najužšiu predpovednú oblasť.
Ak je bodová predpoveď výsledkom jednej zo spomínaných simulačných prístupov (MC alebo bootstap), je aj výpočet intervalovej predpovede z posledných dvoch metód pomerne priamočiara. Interval \(IP_\alpha^Q\) tvoria výberové kvantily zo simulovaných predpovedí \(\{\hat X_{t+h|t}^{(i)}\}_{i=1,\ldots,N}\), ktorých hustotu je navyše pri HDR potrebné vyhladiť vhodnou adaptívnou funkciou (tzv. kernel density estimate). Tu je potrebné poznamenať, že hoci týmto spôsobom vystihneme neistotu v určení šumovej zložky (a v mnohých aplikáciách to stačí), zároveň však zanedbávame variabilitu v odhade parametrov modelu. Náš predpovedný interval je tak užší než ten skutočný. Riešenie ponúka napr. algoritmus (De Gooijer 2017, Algorithm 10.1), v ktorom sa v každom \(i\)-tom kroku simulácie najprv z časového radu \(\{\hat X_t + \tilde\varepsilon_t^{(i)}\}_{t=1,\ldots,n}\) nanovo odhadne model a následne sa jeho skeleton použije na výpočet predikcie \(\hat X_{t+h|t}^{(i)}\).
Pri simuláciách sa z hypotetického lineárneho modelu vygeneruje veľa (tisíce) umelých časových radov, pre každý z nich sa odhadnú parametre lineárneho a nelineárneho modelu a vypočíta hodnota testovacej štatistiky. Všetky hodnoty spolu tvoria náhodný výber, z ktorého je jednoduché získať výberové kvantily či približne vypočítať p-hodnotu.↩︎
Voľne povedané, časový rad vyzerá náhodne, pritom však je výsledkom nelineárneho deterministického procesu↩︎
Oblasť chápeme ako zjednotenie (aj disjunktných) intervalov.↩︎