10 MSW
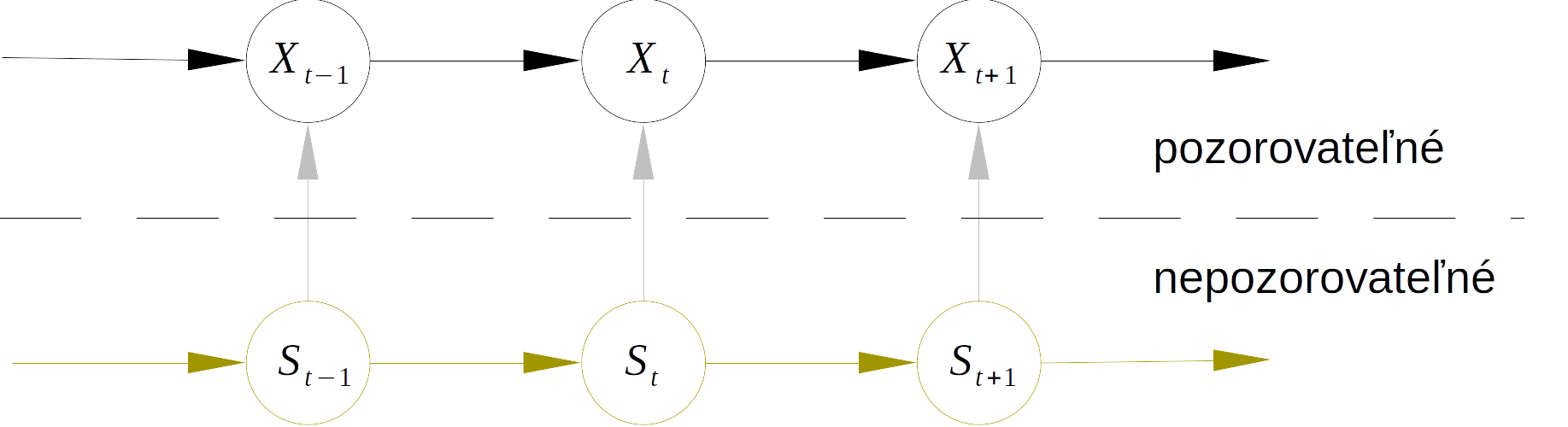
V dosiaľ predstavených nelineárnych modeloch boli režimy určené veľkosťou pozorovateľnej veličiny, či už jednoznačne (TAR) alebo neostro prostredníctvom váhy prechodovej funkcie (STAR). V tejto kapitole je predstavená trieda modelov s AR v každom režime, tzw. Markow switching AR modely (MSW) \[ X_t = \begin{cases} \varphi_{1,0} + \varphi_{1,1}X_{t-1} + \ldots + \varphi_{1,p_1}X_{t-p_1} + \varepsilon_t & \text{ak } S_{t}=1 \\ \vdots & \\ \varphi_{m,0} + \varphi_{m,1}X_{t-1} + \ldots + \varphi_{m,p_2}X_{t-p_2} + \varepsilon_t & \text{ak } S_{t}=m \end{cases} \] alebo skrátene \[ X_t=\varphi_{S_t,0} + \varphi_{S_t,1}X_{t-1} + \ldots + \varphi_{S_t,p_1}X_{t-p_1} + \varepsilon_t \quad \text{pre}\quad S_t=1,\ldots,m \] ktoré predpokladajú, že nastatie konkrétneho režimu (stavovej premennej \(S_t\)) sa riadi nepozorovateľným stochastickým procesom \(\{S_t\}\), konkrétne Markovovským procesom diskrétneho stavu (discrete state Markov process, tiež nazývaný Markovovský reťazec). To znamená, že nastatiu režimu možno iba priradiť určitú pravdepodobnosť, a to na základe odhadu z pozorovania časového radu \(\{x_t\}\). Obr. 10.1 ilustruje MSW proces schematicky.
10.1 Diskrétny Markovovský proces
Markovovský reťazec (1. rádu) zatrieďuje stav sveta \(S_t\) v ľubovoľnom čase \(t\) do niekoľkých diskrétnych režimov. Tento stav sa medzi režimami prepína na základe (iba) svojej predošlej hodnoty a prechodových pravdepodobností \[ Pr(S_t=j|S_{t-1}=i,S_{t-2}=k,\ldots) = Pr(S_t=j|S_{t-1}=i) = p_{ij}, \qquad i,j,k=1,\ldots,m, \] teda zjavne a) systém môže v každom čase nadobúdať niektorý z režimov \(1,\ldots,m\), b) môže prechádzať z jedného režimu do druhého (aj toho istého) s určitou pravdepodobnosťou, c) táto pravdopodobnosť nezávisí od času \(t\) (vlastnosť časovej homogenity) a d) pre prechodové pravdepodobnosti platí \(0\leq p_{ij}\leq 1\) a \(\sum_{j=1}^m p_{ij}=1\), pričom sa zapisujú do tzv. matice prechodových pravdepodobností (transition matrix) 1 \[ P=\left(\begin{matrix} p_{11} & \ldots & p_{1m} \\ \vdots & \ddots & \vdots \\ p_{m1} & \ldots & p_{mm} \\ \end{matrix}\right) \]
Označme vektor nepodmienených (počiatočných) pravdepodobností \(\pi_t=\Big(Pr(S_t=1),\ldots,Pr(S_t=m)\Big)'\), potom pravdepodobnosť každého z režimov v nasledujúcom časovom kroku bude \(\pi_{t+1}=P'\pi_t\). Pre stacionárny Markovovský reťazec existuje tzv. vektor ergodických pravdepodobností \(\pi\) taký, že \[ \pi=P'\pi. \] Markovovský reťazec sa nazýva ergodický, ak je možné dostať sa z každého stavu do ľubovoľného stavu, nie nevyhnutne v jednom kroku. Z poslednej rovnice vyplýva, že \(\pi\) je vlastný vektor matice \(P'\) (zodpovedajúci vlastnému číslu \(\lambda=1\)) pričom samozrejme \(1_m\cdot \pi=1\), kde \(1_m=(1,1\ldots,1)'\) má rozmer \(m\times1\). Vypočíta sa pomocou vzťahu \[ \pi=(A'A)^{-1}A'e_{m+1}, \qquad \text{kde}\qquad A=\left(\begin{matrix} P'-I_m \\ 1_m' \end{matrix}\right) \tag{10.1}\] a jednotkový vektor \(e_{m+1}\) je \((m+1)\)-vý stĺpec jednotkovej matice \(I_{m+1}\). Posledná rovnica v sústave rovníc \(A\pi=e_{m+1}\) je zjavne podmienka kladená na pravdepodobnosti, \(\sum_{j=1}^mPr(S_t=j)=1\).
Ilustrujúc proces na príklade z (Zivot a Wang 2006), stav ekonomiky \(S_t\) môže byť klasifikovaný ako “v recesii” (\(S_t=1\)) alebo ako “rastúca” (\(S_t=2\)). Zo štvrťročných pozorovaní reálneho HDP Spojených štátov amerických od 1952 po 1994 je odhad matice prechodových pravdepodobností \[ P=\left(\begin{matrix} 47\% & 53\% \\ 5\% & 95\% \end{matrix}\right) \] z ktorej vyplýva, že ak ekonomika rastie, je vysoká pravdepodobnosť (95%), že naďalej bude rásť. Naopak, ak je v recesii, je 53% šanca, že sa z recesie dostane. To podporuje všeobecný poznatok, že upadnutie do recesie býva rýchle, zatiaľčo zotavenie sa z nej býva relatívne pomalé. Vypočítané ergodické pravdepodobnosti \(\pi=(0.086,0.914)\) prezrádzajú 9% nepodmienenú pravdepodobnosť, že ekonomika je v recesii, a 91%, že rastie.. Prechodové pravdepodobnosti môžu byť použité aj na výpočet priemernej doby zotrvania stavu v jednotlivých režimoch, napr. priemerná doba trvania recesie je \(\frac{1}{1-p_{11}}=2\) kvartály, čo sa zhoduje so zvyčajnou definíciou recesie ako poklesu reálneho HDP počas dvoch po-sebe-idúcich kvartálov.
10.2 Odhad parametrov
Pri Markow switching AR modeloch je potrebné odhadnúť:
- počet režimov \(m\),
- rozdelenie pravdepodobnosti prechodu z jedného režimu do druhého, \(P\), pričom predpokladáme ergodický proces, takže \(p_{ij}>0\),
- autoregresné parametre \(\Phi_i\) v jednotlivých režimoch a reziduálny rozptyl \(\sigma^2_\varepsilon\),
- ergodické pravdepodobnosti \(\pi\),
- postupnosť stavov \(\mathcal{S}=\{S_t\}_{t=1}^n\), ktorá maximalizuje \(Pr(\Omega_n,\mathcal{S}|P,\pi)\). Odhadujú sa tri typy pravdepodobností (predikovaná, filtrovaná, vyhladená), s ktorými nastane režim \(i\) v čase \(t\), pričom sa zakaždým vyberie hodnota \(S_t\) s najväčšou vyhladenou pravdepodobnosťou. Informačná množina \(\Omega_t\) označuje všetky informácie dostupné v čase \(t\).
Vo všeobecnosti, ak by bol stav \(S_t\) známy, neznáme parametre \(\theta\) modelu (AR parametre a rozptyl šumovej zložky) by sa odhadli jednoducho maximalizáciou funkcie vierohodnosti \(L(\theta|\mathcal{S})=\sum_{t=p+1}^n\log f(X_t|\Omega_{t-1},S_t)\), kde hustota \(f\) sa zvyčajne predpokladá z normálneho rozdelenia, čiže \[ f(X_t|\Omega_{t-1},S_t)=\frac1{\sqrt{2\pi}\sigma_{S_t}}\exp\left(\frac{-(X_t-\Phi_{S_t}'Y_t)^2}{2\sigma_{S_t}^2}\right). \tag{10.2}\]
Ak však stavy \(\mathcal{S}\) nie sú pozorovateľné, musia byť odhadnuté z časového radu a parametre tak zahŕňajú aj prechodové pravdepodobnosti, čiže \(\theta=(\Phi_1',\ldots,\Phi_m',\sigma_\varepsilon, p_{11},\ldots, p_{1(m-1)}, p_{21},\ldots,p_{m(m-1)})'\) 2 a vierohodnostná funkcia bude formálne \[ L(\theta)=\sum_{t=p+1}^n\log f(X_t|\Omega_{t-1}). \] Aplikovaním známeho vzťahu o pravdepodobnosti prieniku dvoch javov \(Pr(A\cap B)=Pr(A|B)Pr(B)\) a vety o úplnej pravdepodobnosti dostaneme \[ f(X_t|\Omega_{t-1})=\sum_{j=1}^m f(X_t|\Omega_{t-1},S_t=j)Pr(S_t=j|\Omega_{t-1}), \] kde \(f(X_t|\Omega_{t-1},S_t=j)\) je rovnaké ako v (10.2) a z Bayesovej vety \[ \begin{split} Pr(S_t=j|\Omega_{t-1}) & = \sum_{i=1}^m Pr(S_t=j|S_{t-1}=i,\Omega_{t-1})Pr(S_{t-1}=i|\Omega_{t-1}) \\ & = \sum_{i=1}^m p_{ij}\frac{f(X_{t-1}|\Omega_{t-2},S_{t-1}=i)Pr(S_{t-1}=i|\Omega_{t-2})}{\sum_{k=1}^m f(X_{t-1}|\Omega_{t-2},S_{t-1}=k)Pr(S_{t-1}=k|\Omega_{t-2})} \end{split} \tag{10.3}\] takže ak sú dané počiatočné pravdepodobnosti pre každý režim \(Pr(S_{p+1}=i|\Omega_p)\), pre \(i=1,\ldots,m\), potom log-vierohodnostná funkcia Markov switching AR modelu sa dá vypočítať iteračne.3 Pravdepodobnosti \(Pr(S_t=j|\Omega_{t-1})\) sa označujú ako predikované pravdepodobností a tvoria vektor \[ \hat\xi_{t,t-1} = \left(\begin{matrix} Pr(S_t=1|\Omega_{t-1}) \\ \vdots \\ Pr(S_t=m|\Omega_{t-1}) \end{matrix}\right), \] pomocou tohto označenia potom je možné vzťah (10.3) pre všetky režimy prepísať do tvaru \[ \hat\xi_{t,t-1} = P'\cdot\hat\xi_{t-1,t-1}, \qquad\text{kde}\qquad \hat\xi_{t-1,t-1} = \frac{\hat\xi_{t-1,t-2}\odot\eta_{t-1}}{\hat\xi_{t-1,t-2}'\cdot\eta_{t-1}}, \tag{10.4}\] pričom vektor \(\eta_t\) obsahuje hustotu zo vzťahu (10.2) pre všetky režimy, násobenie \(a\odot b=(a_1b_1,\ldots,a_mb_m)'\) a výraz v menovateli je hustota nepodmienená stavom, \(f(X_t|\Omega_{t-1})=\hat\xi_{t,t-1}'\cdot\eta_t\). Prvky vektora \(\hat\xi_{t,t}\) sú tzv. filtrované pravdepodobnosti \(Pr(S_{t}=i|\Omega_{t})\), ktoré sa spolu s predikovanými pre \(t=p+1,\ldots,n\) odhadnú iteračným algoritmom pomocou vzťahov (10.4).
Na základe predikovaných a filtrovaných pravdepodobností môžeme odhadnúť tzv. vyhladené pravdepodobnosti \(Pr(S_t=j|\Omega_n)\), tzn. pravdepodobnosť nastatia režimu \(j\) v čase \(t\) na základe informácií o pozorovaniach celého časového radu, a to vzťahom \[ \hat\xi_{t|n} = \hat\xi_{t|t} \odot (P\cdot[\hat\xi_{t+1|n}\div\hat\xi_{t+1|t}]) \tag{10.5}\] kde \(a\div b=(a_1/b_1,\ldots,a_m/b_m)\). Takže algoritmus tu pobeží pospiatky začnúc od \(\hat\xi_{n|n}\).
Iteračný výpočet pravdepodobností (10.4) predpokladá, že parametre \(\theta\) sú známe. Po ukončení iterácií pre \(t=p+1,\ldots,n\) a dané \(\theta\) je log-vierohodnostná funkcia známa, takže jej maximalizáciou možno numericky nájsť hodnoty \(\hat\theta\).
Ako bolo ukázané v (Hamilton 1990), maximálne-vierohodnostné odhady prechodových pravdepodobností sú dané vzťahom \[ \begin{split} p_{ij} &= \frac{\sum_{t=p+2}^n Pr(S_t=j,S_{t-1}=i|\Omega_n;\hat\theta)}{\sum_{t=p+2}^n Pr(S_{t-1}=i|\Omega_n;\hat\theta)}, \\ \hat\Phi_j &= \left(\sum_{t=p+1}^nY_t(j)\cdot Y_t(j)'\right)^{-1}\cdot \left(\sum_{t=p+1}^nY_t(j) x_t(j)\right),\\ \hat\sigma_\varepsilon^2 &= \frac1{n-p}\sum_{t=p+1}^n\sum_{j=1}^m(x_t-\hat\Phi_j'Y_t)^2Pr(S_t=j|\Omega_n;\hat\theta), \end{split} \] kde \(Y_t(j)=Y_t\sqrt{Pr(S_t=j|\Omega_n;\hat\theta)}\) a \(x_t(j)=x_t\sqrt{Pr(S_t=j|\Omega_n;\hat\theta)}\). Maximálne vierohodnostný odhad rozptylu šumovej zložky je priemerom štvorcov rezíduí z dvoch regresií odhadnutých váženou metódou najmenších štvorcov. Podrobnosti k odhadu v zrozumiteľnej podobe možno dohľadať napr. v (Kole 2019), podľa ktorého pravdepodobnosti \(p_{ij}\) sa dajú vypočítať pomocou jemne pozmenenej rekurzie (10.4) ako \[ p_{ij}^{(k)} = \frac{\sum_{t=p+2}^n \bar p_{ij,t}}{\sum_{t=p+2}^n \hat\xi_{t-1,n}}, \qquad\text{kde}\quad \bar p_{ij,t} = Pr(S_t=j,S_{t-1}=i|\Omega_n;\theta^{(k-1)}) = \hat\xi_{t-1|t-1,j}\frac{\hat\xi_{t|n,i}}{\hat\xi_{t|t-1,i}}p_{ij}^{(k-1)}. \]
Iteračná procedúra odhadov parametrov MSW modelu je aplikáciou EM algoritmu (Expectation Maximisation) a spočíva v nasledovných bodoch:
- S danými štartovacími hodnotami \(\theta^{(0)}\) sa pre \(t=p+1,\ldots,n\) vypočítajú predikované \(\hat\xi_{t|t-1}\) a filtrované \(\hat\xi_{t|t}\) pravdepodobnosti (pričom \(\hat\xi_{p+1|p}\) možno zvoliť napr. podľa rovnomerného rozdelenia, alebo odhadovať spolu s ostatnými parametrami). Pomocou nich pre \(t=n-1,\ldots,p+1\) sa vypočítajú vyhladené pravdepodobnosti \(\hat\xi_{t|n}\).
- Z vyhladených pravdepodobností \(\hat\xi_{t|n}\) a počiatočných prechodových pravdepodobností \(p_{ij}^{(0)}\) sa vypočítajú \(\hat p_{i,j}^{(1)}\), \(i,j= 1,\ldots,m\).
- Nakoniec sa vypočíta odhad autoregresných parametrov \(\hat\Phi_j^{(1)}\) a reziduálneho rozptylu \({\hat\sigma_\varepsilon^2}\,^{(1)}\). Získame tak nový odhad parametrov \(\hat\theta^{(1)}\), ktorý bude použitý v novej iterácii.
- Procedúra sa ukončí po dosiahnutí konvergencie, prakticky v kroku \(k\), pre ktorý \(||\theta^{(k)}-\theta^{(k-1)}||<\delta\) s nejakou malou hodnotou \(\delta\).
Identifikácia MSW modelu sa vykoná napr. minimalizáciou informačných kritérií, z ktorých napr. \(AIC=-2 ln L(\hat\theta|\Omega_n)+2[2(p+1)+m(m-1)]\).
10.3 Test linearity
V súvislosti s MSW modelmi sa na detekciu nelinearity používa LR testovacia štatistika \(LR=L_{MSW}-L_{AR}\), kde \(L_M\) je log-vierohodnostná funkcia modelu \(M\). Tá má za predpokladu \(H_0\colon\Phi_1=\Phi_2\), pričom \(P\) sú prebytočné parametre, neštandardné rozdelenie pravdepodobnosti, ktoré treba určiť simulačne. Postupuje sa tak, že sa z AR modelu vygeneruje veľké množstvo (N) časových radov, potom sa pre každý z nich odhadne AR a MSW model a vypočítajú simulované hodnoty \(\{LR^{(i)}\}_{i=1,\ldots,N}\), podobne ako pri teste nelinearity typu SETAR.
10.4 Diagnostická kontrola
10.4.1 Testy založené na skórovej funkcii
Diagnostickým testom MSW modelov sa venovala publikácia (Hamilton 1996), prvá skupina je modifikáciou Newey-Tauchen-White testu špecifikácie dynamiky v kontexte MSW modelov, druhá sú testy typu \(LM\). Pri všetkých k výpočtu stačí odhad modelu z nulovej hypotézy a všetky sú založené na tzv. skórovej funkcii (score function) \[ h_t(\theta)=\frac{\partial\log f(X_t|\Omega_{t-1};\theta)}{\partial \theta} \] teda gradientu log-vierohodnostnej funkcie. Dôvod použitia takejto funkcie je taký, že ak sú dáta skutočne generované z rozdelenia s hustotou \(f(X_t|\Omega_{t-1};\theta)\), takže prirodzene platí \(\int_{-\infty}^{\infty} f(X_t|\Omega_{t-1};\theta)dX_t=1\) z čoho diferencovaním \(\int_{-\infty}^{\infty} \frac{\partial f(X_t|\Omega_{t-1};\theta)}{\partial\theta}dX_t=0_q\), kde \(q\) je počet parametrov (prvkov vektora \(\theta\)), dostávame \(\int_{-\infty}^{\infty} \frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial\theta}f(X_t|\Omega_{t-1};\theta)dX_t=0_q\), potom z toho plynie, že \(E[h_t(\theta)|\Omega_{t-1}]=0_q\). To znamená, že, ak je model správny, hodnoty skórovej funkcie \(h_t(\theta)\) nie je možné predpovedať na základe informácie v čase \(t-1\), teda ani pomocou \(h_{t-1}(\theta)\), takže skórovú funkciu možno použiť na konštrukciu rôznych diagnostických testov.
10.4.1.1 Výpočet gradientu
Pred tým, než si niektoré ukážeme, zosumarizujme výpočet \(h_t(\theta)\). Označme \(\theta_{\Phi,\sigma_\varepsilon}=(\Phi_1',\ldots,\Phi_m',\sigma_\varepsilon)\) takže \(\theta_{p}\) budú zvyšné parametre, potom pre \(i,j=1,\ldots,m\) a \(t=p+2,\ldots,n\) \[ \begin{split} \frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial\theta_{\Phi,\sigma_\varepsilon}} & = \sum_{j=1}^m\left( \frac{\partial \log f(X_t|\Omega_{t-1},S_t=j;\theta)}{\partial\theta_{\Phi,\sigma_\varepsilon}} + \right. \\ & \qquad + \left. \sum_{\tau=p+1}^{t-1}\sum_{S_\tau=1}^m \frac{\partial \log f(X_t|\Omega_{\tau-1},S_\tau=j;\theta)}{\partial\theta_{\Phi,\sigma_\varepsilon}}[Pr(S_\tau=j|\Omega_t)-Pr(S_\tau=j|\Omega_{t-1})]\right) \\ \frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial p_{ij}} & = \frac{1}{p_{ij}}Pr(S_t=j,S_{t-1}=i|\Omega_t) - \frac{1}{p_{im}}Pr(S_t=m,S_{t-1}=i|\Omega_t) + \\ & + \frac{1}{p_{ij}}\left(\sum_{\tau=p+2}^{t-1}[Pr(S_\tau=j,S_{\tau-1}=i|\Omega_t)-Pr(S_\tau=j,S_{\tau-1}=i|\Omega_{t-1})]\right) - \\ & \quad- \frac{1}{p_{im}}\left(\sum_{\tau=p+2}^{t-1}[Pr(S_\tau=m,S_{\tau-1}=i|\Omega_t)-Pr(S_\tau=m,S_{\tau-1}=i|\Omega_{t-1})]\right) + \\ & + \sum_{k=1}^m\frac{\log Pr(S_{p+1}=k;\theta_p)}{\partial p_{ij}}[Pr(S_{p+1}=k|\Omega_t)-Pr(S_{p+1}=k|\Omega_{t-1})] \end{split} \] pričom \(\frac{\partial \log f(X_{p+1}|\Omega_p;\theta)}{\partial p_{ij}} = \sum_{k=1}^m\frac{\log Pr(S_{p+1}=k;\theta_p)}{\partial p_{ij}}Pr(S_{p+1}=k|\Omega_{p+1})\). Pravdepodobnosť režimov počiatočného stavu \(S_{p+1}\) možno aproximovať ergodickými pravdepodobnosťami pomocou vzťahu (10.1).
10.4.1.2 Modifikácia Newey-Tauchen-White testu
White navrhol testy autokorelácie skórových funkcií, ktoré používajú testy podmienených momentov z prác Neweyho a Tauchena. Hamilton ich ďalej odvodil pre MSW modely. Na výpočet testovacej štatistiky potrebujeme \(r\times1\) vektor \(c_t(\hat\theta)\) pozostávajúci zo súčinov vybraných prvkov \(h_t(\hat\theta)\) s vybranými prvkami vektora \(h_{t-1}(\hat\theta)\) (tzn. vybraných prvkov matice \(h_{t}(\hat\theta)\cdot h_{t-1}(\hat\theta)'\). Ak je špecifikácia dynamiky modelu správna (\(H_0\)), súčiny majú strednú hodnotu rovnú nule, takže vektory \(c_t(\hat\theta)\) a \(c_{t-1}(\hat\theta)\) sú nezávislé. Potom testovacia štatistika \[ NTWH = \left(n^{-\frac12}\sum_{t=p+1}^nc_t(\hat\theta)\right)'\cdot (\hat M^{-1})_{(2,2)} \cdot \left(n^{-\frac12}\sum_{t=p+1}^nc_t(\hat\theta)\right) \quad\stackrel{a}{\sim}\quad \chi^2(r), \] kde \((\hat M^{-1})_{(2,2)}\) reprezentuje pravú dolnú \(r\times r\) sub-maticu matice \(\hat M^{-1}\), pričom \[ \hat M = n^{-1} \left(\begin{matrix} \sum_{t=p+1}^nh_t(\hat\theta)\cdot h_t(\hat\theta)' & \sum_{t=p+1}^nh_t(\hat\theta)\cdot c_t(\hat\theta)' \\ \sum_{t=p+1}^nc_t(\hat\theta)\cdot h_t(\hat\theta)' & \sum_{t=p+1}^nc_t(\hat\theta)\cdot c_t(\hat\theta)' \end{matrix}\right). \]
Ak chceme testovať nezávislosť (autokoreláciu prvého stupňa) rezíduí naprieč režimami, vektor \(c_t(\theta)\) bude obsahovať \(r=m^2\) súčinov \(\frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial\varphi_{j,0}}\ \frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial\varphi_{i,0}}\) pre \(i,j=1,\ldots,m\) a \(i\neq j\). Zderivovaním podľa absolútnych členov by sme videli, že výrazy v súčine obsahujú rezíduá škálované rozptylom a vážené aktuálnou pravdepodobnosťou konkrétneho režimu plus rozdiely pravdepodobností v okamihoch \(\tau<t\). Opäť, ak je dynamika modelu správna, tieto rozdiely by sa nemali dať predvídať.
Test nezávislosti vo vnútri \(j\)-teho režimu sa dosiahne obsadením \(c_t(\theta)\) jediným prvkom \(\frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial\varphi_{j,0}}\ \frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial\varphi_{j,0}}\).
Platnosť Markovovských predpokladov sa otestuje napr. pomocou (pre \(j=1,\ldots,m\))
- \(\frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial p_{jj}}\ \frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial\varphi_{j,0}}\) (predpoklad, že prechodové pravdepodobnosti nezávisia od pozorovaní \(X_t\)) a
- \(\frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial p_{jj}}\ \frac{\partial \log f(X_t|\Omega_{t-1};\theta)}{\partial p_{jj}}\) (klasický predpoklad Markovovskej vlastnosti 1.stupňa)
potom \(r=2m\).
10.4.1.3 Testy typu LM
Predpokladajme, že \(r\times 1\) vektor parametrov \(\beta\) je odhadovaný tak, že posledných \(r_0\) parametrov sú nútene rovné nule. Potom prvých \(r-r_0\) prvkov priemerného gradientu \(\frac1{n-p}\sum_{t=p+1}^n h_t(\hat\beta)\) sa rovná nule, zatiaľčo veľkosť zvyšných odráža o koľko by vierohodnostná funkcia narástla, keby posledné parametre už neboli viazané podmienkou. To sa dá využiť výpočtom testovacej štatistiky \[ LM = \left(n^{-\frac12}\sum_{t=p+1}^nh_t(\hat\beta)\right)'\cdot \left(n^{-1}\sum_{t=p+1}^nh_t(\hat\beta)\cdot h_t(\hat\beta)'\right)^{-1}\cdot \left(n^{-\frac12}\sum_{t=p+1}^nh_t(\hat\beta)\right) \quad\stackrel{a}{\sim}\quad \chi^2(r_0). \]
- Test autokorelácie rezíduí (1.stupňa a naprieč režimami) vychádza z podmienenej hustoty s parametrami \(\beta=(\theta',\rho)'\) \[ f(X_t|\Omega_{t-1},S_t=j,S_{t-1}=i;\beta) = \frac1{\sqrt{2\pi}\sigma_\varepsilon}\exp\left( \frac{-\Big((X_t-\Phi_j'Y_t)-\rho(X_{t-1}-\Phi_i'Y_{t-1})\Big)^2}{2\sigma_\varepsilon^2} \right), \] nulová hypotéza je formulovaná ako \(H_0\colon \rho=0\) a posledný prvok skórovej funkcie sa vypočíta vzťahom \[ \begin{split} \frac{\partial \log f(X_t|\Omega_{t-1};\beta}{\partial \rho}\Big|_{\rho=0} & = \sum_{i=1}^m\sum_{j=1}^m\psi_{t,ij}Pr(S_t=j,S_{t-1}=i|\Omega_t;\theta) + \\ & + \sum_{\tau=p+1}^{t-1}\sum_{i=1}^m\sum_{j=1}^m \psi_{\tau,ij} [Pr(S_t=j,S_{t-1}=i|\Omega_t;\theta)-Pr(S_t=j,S_{t-1}=i|\Omega_{t-1};\theta)], \end{split} \] kde \(\psi_{t,ij}=\frac{\partial \log f(X_t|\Omega_{t-1}, S_t=j, S_{t-1}=i;\beta}{\partial \rho}\Big|_{\rho=0} = \frac{(X_t-\Phi_j'Y_t)(X_{t-1}-\Phi_i'Y_{t-1})}{\sigma_\varepsilon^2}\). Potom testovacia štatistika je jednoducho \(LM=\frac{\left(\sum_{t=p+1}^nh_t(\hat\beta)\right)^2}{\sum_{t=p+1}^nh_t(\hat\beta)^2}\) a má asymptoticky \(\chi^2(1)\) rozdelenie. Dá sa získať ako \(LM=nR^2\) z lineárnej regresie závislosti 1 od \(h_t(\hat\beta)\).
- Autokoreláciu vo vnútri režimov ide testovať analogicky ak sa použije hustota \(f(X_t|\Omega_{t-1},S_t=j,S_{t-1}=j;\beta)\).
10.4.2 Test ostávajúcej nelinearity
Na testovanie ostávajúcej nelinearity sa opäť (podobne ako pri SETAR) použije test vierohodnostným pomerom (likelihood ratio), tentokrát však máme vierohodnostnú funkciu už vyjadrenú explicitne. Nulová hypotéza, že postačuje 2-režimový model, stojí oproti alternatívnej, že správny je 3-režimový. Testovacie kritérium \[ LR = L_{MSW3} - L_{MSW2}, \] kde \(L_{MSWm}\) je hodnota log-vierohodnostnej funkcie \(m\)-režimového MSW modelu, nemá štandardné rozdelenie pravdepodobnosti a kritické hodnoty tak musíme určiť simuláciou: pomocou MSW-2 vygenerujeme veľké množstvo (minimálne \(N=5000\)) umelých časových radov, pre každý odhadneme parametre MSW3 a vypočítame hodnoty \(LR^{(i)}\), \(i=1,\ldots,N\), ktoré poslúžia na výpočet kritických hodnôt alebo p-hodnoty.
10.5 Predpovedanie
Oproti predošlým modelom s endogénnou stav-vysvetľujúcou premennou (SETAR a STAR) predpoveď \(X_t\) pomocou MSW modelov v sebe zahŕňa aj predpovedanie pravdepodobnosti nastatia konkrétneho režimu.
Jednokroková predpoveď je opäť pomerne jednoduchá, vychádza z podmienenej hustoty \(f(X_t|\Omega_{t-1}, S_t)\), pričom zjavne musíme počítať s predpoveďou pre každý režim, predpoveď je daná ako podmienená stredná hodnota \[ \begin{split} E(X_{t+1}|\Omega_t) & = \int_R x_{t+1} f(x_{t+1}|\Omega_t)dx_{t+1} = \\ & = \int_R x_{t+1} \left(\sum_{j=1}^m f(x_{t+1}|\Omega_{t}, S_{t+1}=j) Pr(S_{t+1}=j|\Omega_{t})\right)dx_{t+1} = \\ & = \sum_{j=1}^m Pr(S_{t+1}=j|\Omega_{t}) \int_R x_{t+1} f(x_{t+1}|\Omega_{t}, S_{t+1}=j) dx_{t+1} = \\ & = \sum_{j=1}^m Pr(S_{t+1}=j|\Omega_{t}) E(x_{t+1}|\Omega_{t}, S_{t+1}=j) = \\ & = (\Phi_1 Y_{t+1}, \ldots, \Phi_m Y_{t+1})\hat\xi_{t+1|t} \end{split} \] kde predikovaná pravdepodobnosť \(\hat\xi_{t+1|t}\) sa vypočíta pomocou (10.4). To platí pre \(t=n\). Pre ďalšie časové okamihy je zrejme potrebný rekurzívny výpočet predikovanej a filtrovanej pravdepodobnosti podľa (10.4), pričom vektor podmienenej hustoty \(\eta_t\) sa počíta pomocou pozorovaných hodnôt \(\{x_\tau\}_{\tau=(t-1),\ldots,1}\).
Viackrokové predpovede \(X_{t+h}\) využívajú viackrokovú predpoveď nepodmienenej pravdepodnosti stavu, \[ \hat\xi_{t+h|t} = P'\hat\xi_{t+h-1|t}=P'\cdot P'\cdot\ldots\cdot P'\hat\xi_{t|t}=(P')^h\hat\xi_{t|t} \] pričom opäť možno vypočítať naivné predpovede alebo stredné predpovede zo simulácií.
Pri doplnkovom štúdiu z dostupnej literatúry si treba dať pozor na to, že matica prechodových pravdepodobností je často definovaná v transponovanom tvare.↩︎
Teda bez nadbytočných parametrov z posledného stĺpca \(P\), pretože \(p_{im}=1-\sum_{j=1}^{m-1}p_{ij}\).↩︎
Implementácia je jednoduchá, no výpočet je kôli iteráciám pomalý, vhodnejšie je preto reprezentovať MSW ako state space model, pre ktorého odhad sú dostupné optimalizované procedúry v jazyku C.↩︎