Kód
library(ggplot2)
library(patchwork)
library(tsibble) # needed for ggplot2 to plot tsibble correctlylibrary(ggplot2)
library(patchwork)
library(tsibble) # needed for ggplot2 to plot tsibble correctlyV praxi sa veľmi často stretávame s časovými radmi generovanými nestacionárnymi stochastickými procesmi, pričom nestacionarita procesu býva spôsobená buď v čase sa meniacou strednou hodnotou a/alebo v čase sa meniacim rozptylom procesu. Pôvod nestacionarity môže byť deterministický alebo stochastický, ako uvidíme neskôr. Pripomeňme, že modelovanie autokorelačnej štruktúry časového radu (napr. pomocou modelov ARMA) predpokladá jej nemennosť v čase, preto je stacionarizácia jedným z najdôležitejších krokov v analýze časových radov.
V prípade deterministickej povahy nestacionarity sa používajú postupy, ktoré boli spomínané v predošlých kapitolách:
Naproti tomu stochasticky nestacionárny časový rad sa najčastejšie stacionarizuje pomocou vhodných diferencií. Tie môžeme označiť operátorom \(\Delta_\ell^k\) a ako naznačuje použitie indexov, líšia sa v dvoch smeroch, podľa
Jednoduché prvé (first-order) diferencie \(\Delta\) zvyčajne odstránia iba trend, sezónne prvé diferencie \(\Delta_L\) zas eliminujú sezónnu zložku a často aj trend. Ak prvý stupeň diferencovania na dosiahnutie stacionarity nestačí, použije sa vyšší stupeň. Všeobecne platí, že vhodným diferencovaním dochádza k poklesu rozptylu, zatiaľčo príliš veľký stupeň diferencovania sprevádza nárast rozptylu.
Stochastickú nestacionaritu, ktorá sa dá skrotiť diferencovaním, je možné modelovať pomocou špeciálnych rozšírení ARMA modelov. O takých bude reč v nasledujúcich podkapitolách.
Špeciálny prípad nestacionárnych procesov sú integrované procesy, a to ARMA procesy, ktoré majú aspoň jeden AR koeficient rovný 1. Pripomeňme si, že ARMA je stacionárny práve vtedy, keď pre všetky korene autoregresného polynómu1 platí \(|x|>1\).
Ak môžeme AR polynóm \(\phi_p(x) = 1 - \varphi_1 x - \varphi_2 x^2 - ... - \varphi_p x^p\) napísať v tvare \[ \phi_p(x) = (1 - \alpha_1 x - \alpha_2 x^2 - ... - \alpha_{p-1} x^{p-1}) \, (1-x)=\phi_{p-1}(x)\, (1-x), \] taký proces nazývame \(I(1)\), integrovaný stupňa 1. Analogicky, proces I(d) má AR polynóm \[ \phi_p(x) = (1 - \alpha_1 x - \alpha_2 x^2 - ... - \alpha_{p-d} x^{p-d}) \, (1-x)^d=\phi_{p-d}(x)\, (1-x)^d \] a platí \(\phi_p(1) = \phi_{p-1}(1)=...= \phi_{p-(d-1)}(1)=0, \quad \phi_{p-d}(1) \neq 0\).
Pre procesy, ktorých AR polynómy nemajú jednotkové korene a \(|x|>1\), platí \(\phi_p(1) \neq 0\).
Proces typu I(1) môžme diferencovaním previesť na I(0). \[ \phi_p(B)y_t=\varepsilon_t \quad\Rightarrow\quad \phi_{p-1}(B)(1-B)y_t=\varepsilon_t \quad\Rightarrow\quad \phi_{p-1}(B)\Delta y_t=\varepsilon_t, \] pričom \(\phi_{p-1}(1)\neq0\). Teda ak \(y_t\sim I(1)\) potom \(\Delta y_t\sim I(0)\). Analogicky ak \(y_t\sim I(d)\) potom \(\Delta^d y_t\sim I(0)\).
Proces náhodnej prechádzky (angl. random walk proces) je špeciálny prípad AR(1) pre \(\varphi_1=1\), \[ y_t=y_{t-1} + \varepsilon_t, \] kde \(\varepsilon_t\) je proces bieleho šumu, \(E(\varepsilon_t)=0\), \(var(\varepsilon_t)=\sigma_\varepsilon^2\), prepísaný do tvaru \[ (1-B)y_t=\varepsilon_t. \] Po postupnom dosadení \[ y_t = y_{t-1} +\varepsilon_t = (y_{t-2} +\varepsilon_{t-1})+\varepsilon_t = ((y_{t-3} +\varepsilon_{t-2})+\varepsilon_{t-1})+\varepsilon_t = \ldots = \sum_{i=0}^\infty \varepsilon_{t-i} \] vidíme, že proces náhodnej prechádzky je tvorený kumulovaním náhodných premenných tvoriacich biely šum. Pretože jeho prvé diferencie tvoria proces bieleho šumu, proces náhodnej prechádzky je integrovaný proces rádu 1. Práve z tohoto súčtu (realizácií bieleho šumu) pochádza názov integrovaný.
Podmienená stredná hodnota \(E(y_t|y_{t-1})=y_{t-1}\) je premenlivá v čase a podmienený rozptyl \(var(y_t|y_{t-1})=\sigma_\varepsilon^2\) je v čase konštantný.
Predpokladajme, že proces \(y_t = y_{t-1} + \varepsilon_t\) má začiatok v čase \(t = 0\), pričom \(y_0\) je počiatočná deterministická podmienka. Potom ho môžeme zapísať v tvare \(y_t=y_0+\sum_{j=1}^t \varepsilon_j\) a jeho vlastnosti zhrnúť v nasledujujúcich bodoch:
Proces náhodnej prechádzky je teda nestacionárny proces. Zdrojom nestacionarity je tzv. stochastický trend \(ST_t= \sum_{j=1}^t \varepsilon_j\).
Uvažujme proces náhodnej prechádzky s konštantou \(\delta\), \[ \begin{split} y_t &= \delta+y_{t-1}+\varepsilon_t = \\ &= \delta+(\delta+y_{t-2}+\varepsilon_{t-1})+\varepsilon_t = \dots = \\ &= t\cdot \delta + y_0 + ST_t. \end{split} \] Je to stochastický proces \(\Delta y_t=\delta+\varepsilon_t\), čiže náhodná prechádzka s odklonom \(\delta\) (angl. drift), ktorý obsahuje zároveň deterministický aj stochastický trend.
Na Obr. 5.1 sú znázornené tri odlišné typy nestacionárnych procesov.
set.seed(1)
dat <- data.frame(Index = 1:300) |>
dplyr::mutate(Eps = Index |> length() |> rnorm(),
RWd = cumsum(Eps + 0.2),
RW = cumsum(Eps),
DT = Index*0.2 + Eps
)
dat |>
tidyr::pivot_longer(RWd:DT, names_to = "series", values_to = "value") |>
ggplot() + aes(x = Index, y = value, color = series) + geom_line() +
scale_color_manual(values = c(DT = 2, RW = 1, RWd = 4),
labels = c("deterministic trend", "random walk", "rand.walk with drift"),
name = NULL) +
theme(legend.position = "inside", legend.position.inside = c(0.02, 0.98),
legend.justification = c(0,1))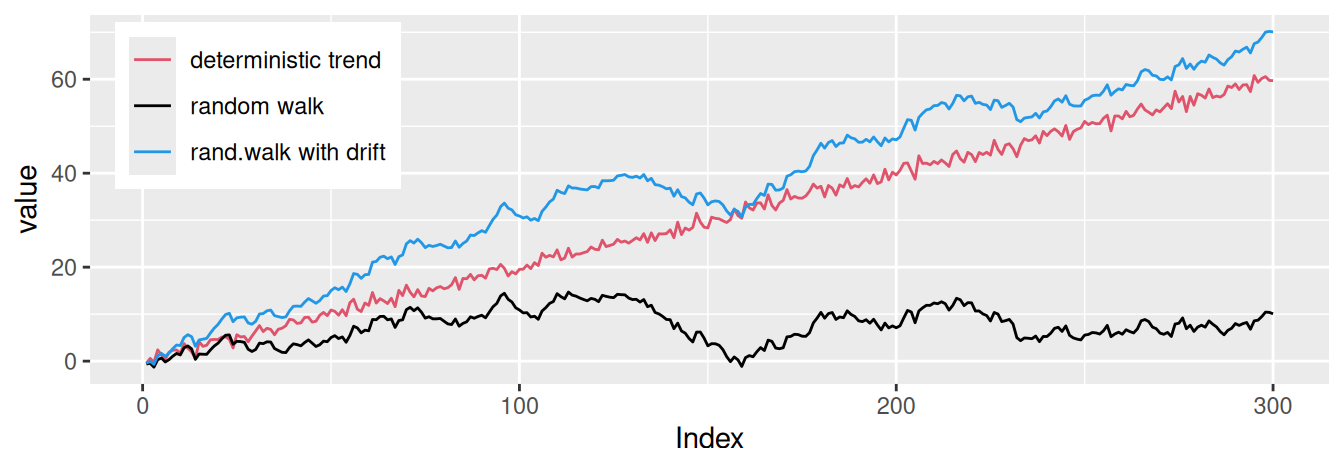
p1 <- dat$RW |>
acf(plot = FALSE) |>
forecast::autoplot() + ggtitle("")
p2 <- dat$RW |>
pacf(plot = FALSE) |>
forecast::autoplot() + ggtitle("")
p1 + p2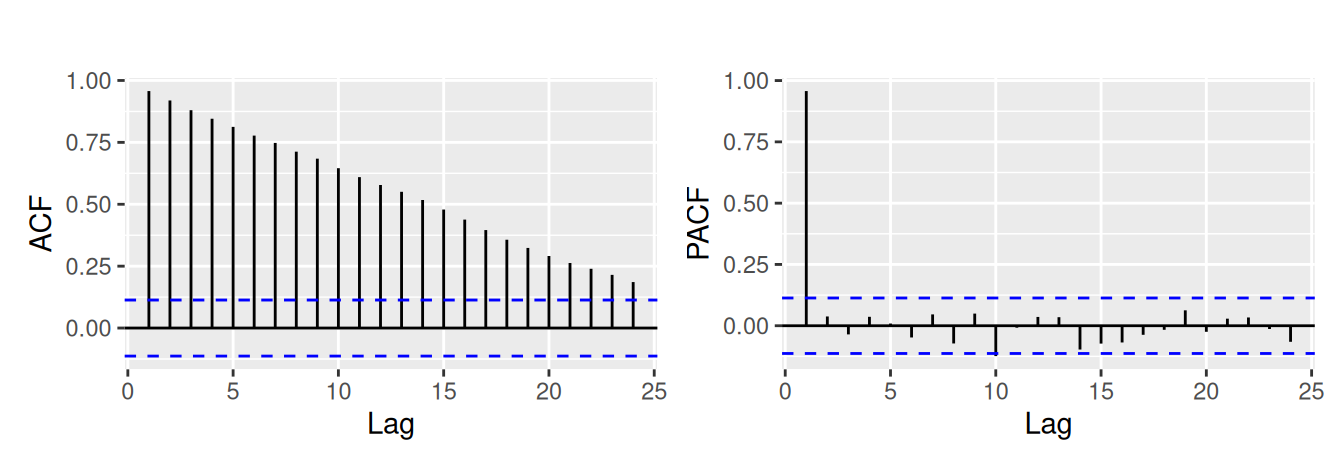
V kontexte vyššie spomínaných stacionarizujúcich transformácií tu treba poznamenať, že diferencovanie by sa nemalo používať pre stacionarizáciu procesu s deterministickým trendom \(y_t=\beta_0+\beta_1 t+\varepsilon_t\), pretože vedie k modelom s reziduálnou zložkou v tvare (neinvertibilného) MA procesu \(\Delta y_t=\beta_1+\varepsilon_t-\varepsilon_{t-1}\). Naopak – v prípade regresnej eliminácie stochastickej nestacionarity – pri náhodnej prechádzke vlastne ani nie je čo eliminovať a pri procese so stochastickým aj deterministickým trendom by sme napr. nemohli korektne testovať významnosť regresných parametrov pomocou štatistiky \(\frac{\hat{\beta}_i}{\hat{\sigma}_{\beta_i}}\), pretože by nemusela mať t-rozdelenie.
Najlepšou predpoveďou pri procese náhodnej prechádzky bez konštanty je naivná predpoveď.
Videli sme, že je dôležité vedieť určiť, či proces ARMA obsahuje jednotkové korene. Pretože subjektívne z ACF a PACF by nebolo možné odlíšiť náhodnú prechádzku od stacionárneho procesu s takmer jednotkovým koreňom, napr. \(y_t=0.95 y_{t-1}\), je potrebné použiť štatistické testy.
Uvažujme proces AR(\(p\)) s AR polynómom \[
\phi_p(B) = 1 - \varphi_1 \, B - \varphi_2 \, B^2 - ... - \varphi_p \, B^p,
\]
ktorý môžeme vyjadriť v tvare \[
\phi_p(B) = \phi_{p-1}(B)\; (1 - B),
\] čiže je to proces typu I(1). Potom pre neho platí \[
\phi_p(1) = 1 -\varphi_1 - \varphi_2 - ... - \varphi_p = 0.
\] Ak by \(\phi_p(1) \neq 0\), potom by AR(\(p\)) bol stacionárny proces typu I(0). Pri testovaní, či AR(\(p\)) je typu I(1) teda testujeme, či je \(\phi_p(1) = 0\).
Jeden z prvých bol Dickey-Fullerov test odvodený pre proces náhodnej prechádzky, teda \(H_0\colon y_t=y_{t-1}+\varepsilon_t\). Rozlišuje tri varianty podľa alternatívnej hypotézy, a to či je AR proces
Nulová hypotéza sa dá jednoducho (odčítaním \(y_{t-1}\)) prepísať na tvar \(H_0: \Delta y_t=\mu^*+\delta^*\ t+\varrho\ y_{t-1}+\varepsilon_t\) s \(\varrho=0\) zatiaľčo alternatívne hypotézy súborne \(H_1:\Delta y_t=\mu^*+\delta^*\ t+\varrho\ y_{t-1}+\varepsilon_t\) s koeficientom \(\varrho=\varphi_1-1<0\) (koeficienty \(\mu^*,\delta^*\) odvodíme neskôr) pričom zjavne v prvej variante platí 1) \(\mu=\delta=0\), v druhej variante zas 2) \(\delta=0\). V týchto rovniciach nás zaujíma iba parameter \(\varrho\), na vyhodnotenie testu však treba odhadnúť všetky. Preto sa urobí pomocná regresia podľa konkrétnej \(H_1\) (identifikujeme jednoducho podľa grafu časového radu) a vypočíta sa testovacia štatistika \[ DF=\frac{\hat\varrho}{\hat\sigma_{\varrho}} \] ktorá však na rozdiel od obyčajnej regresie nemá t-rozdelenie (ani asymptoticky a ani ak by \(\varepsilon_t\) bol biely šum) a tak jej rozdelnenie2 muselo byť zistené simulačne zvlášť pre všetky tri vaianty a pre rôzne dĺžky \(n\). Samozrejme nulovú hypotézu zamietame, ak \(DF < q_\alpha\).
Neskôr bola navrhnutá rozšírená verzia (augmented Dickey-Fuller test) pre autoregresný proces vyššieho rádu. V nasledujúcich častiach sú odvodené prípady pre všetky tri alternatívne hypotézy.
Predpokladajme, že AR polynóm môžeme písať v tvare: \[ \phi_p(B) =( 1 - \varphi_1 - \varphi_2 - ... - \varphi_p) \, B^i+\phi_{p-i}^\star(B) \, (1-B), \quad i = 1, 2, ..., p-1. \tag{5.1}\]
Napríklad pre AR(2) a \(i=1\) je AR polynóm \[ \begin{split} \phi_2(B) &= 1-\varphi_1B-\varphi_2B^2 = \underline{B} - \varphi_1B - \underline{\varphi_2B} + 1 - \underline{B} + \underline{\varphi_2B} - \varphi_2B^2 \\ &= (1-\varphi_1-\varphi_2)B + (1+\varphi_2B)(1-B). \end{split} \] Teda \(\phi_1^*(B)=(1+\varphi_2B)\equiv(1-\alpha_1^*B)\) a AR(2) typu I(1) bude \[ \begin{split} \phi_2(B)y_t & = \varepsilon_t \notag\\ (1-\varphi_1-\varphi_2)B\cdot y_t + (1-\alpha_1^*B)(1-B)y_t & = \varepsilon_t \notag\\ \phi_1^*(B)\Delta y_t & = \underbrace{(\varphi_1+\varphi_2-1)}_{\varrho}y_{t-1}+\varepsilon_t. \end{split} \tag{5.2}\] Ak je \(1-\varphi_1-\varphi_2=0\), rovnica (5.2) sa zredukuje na \(\phi_1^*(B)\Delta y_t = \varepsilon_t\), t.j. proces AR(1) pre \(\Delta y_t\).
Analogicky pre AR(p). Na základe (5.1) pre \(i=1\), test jednotkového koreňa AR polynómu \(t\)-testom pre parameter \(\varrho\) v pomocnej regresii (značíme ju ADF) \[ \Delta \, y_t = \varrho \, y_{t-1} + \alpha_1^\star \Delta \, y_{t-1} + ... + \alpha_{p-1}^\star \Delta \, y_{t-(p-1)}+\varepsilon_t. \] Testovacia štatistika TS, nulová hypotéza \(H_0\colon \quad \varrho = 0\) aj alternatívna hypotéza \(H_1\colon \varrho \neq 0\) sú rovnaké ako pri jednoduchom DF teste, rovnako tak rozdelenie pravdepodobnosti TS. Pribudla však nutnosť určenie rádu \(p\), a to napr. štandardným porovnaním AR modelov pomocou informačného kritéria AIC.
Predpokladajme, že proces \(\left\lbrace y_t \right\rbrace\) obsahuje aj konštantu a lineárny trend.
Napríklad proces AR(1) \[ \begin{split} y_t-\mu-\delta t & = \varphi_1(y_{t-1}-\mu-\delta(t-1))+\varepsilon_t\\ y_t & = \mu + \delta t + \varphi_1 y_{t-1} - \varphi_1\mu - \varphi_1\delta t + \varphi_1\delta + \varepsilon_t\\ y_t & = (1-\varphi_1)\mu + \varphi_1\delta + (1-\varphi_1)\delta t+ \varphi_1y_{t-1} + \varepsilon_t \\ y_t & = \begin{cases} \mu^* + \delta^*t + \varphi_1y_{t-1} + \varepsilon_t & \text{ ak je } \varphi_1\neq1 \\ \delta + y_{t-1} + \varepsilon_t & \text{ ak } \varphi_1=1 \end{cases} \end{split} \]
Potom pomocná regresia ADF prejde do tvaru \[ \Delta \, y_t = \mu^\star + \delta^\star \, t +\varrho \, y_{t-1} + \alpha_1^\star \Delta \, y_{t-1} + ... + \alpha_{p-1}^\star \Delta \, y_{t-(p-1)}+\varepsilon_t. \]
je podobný DF testu, ale prípadná autokorelovanosť rezíduí nie je zohľadnená pridaním autoregresných členov ako v ADF ale priamo korekciou odhadnutej smerodajnej odchýlky \(\hat\sigma_\varrho\) v štýle Newey-Westovho odhadu (ktorý sa v klasickej regresii používa na zohľadnenie heteroskedasticity a autokorelovanosti rezíduí).
KPSS (podľa autorov Kwiatkovski-Philips-Schmidt-Shin) test je testom stacionarity rezíduí (teda nie priamo jednotkového koreňa) a reaguje na skutočnosť, že DF test niekedy máva slabú rozlišovaciu schopnosť 3, preto KPSS má \(H_0\) a \(H_1\) postavené opačne ako DF a aplikuje sa súčasne s DF – za smerodajné sa berú iba prípady, ak sú oba testy v zhode.
Predpokladajme, že \(y_t\) môžeme rozložiť do súčtu náhodnej prechádzky a stacionárneho časového radu chybovej zložky, prípadne aj deterministického trendu: \[ y_t = ST_t + e_t,\quad \text{resp.}\quad y_t = DT_t + ST_t + e_t, \] kde
KPSS je test typu LM (Lagrange multipliers), a nulová hypotéza, že proces \(\left\lbrace y_t \right\rbrace\) je stacionárny (resp. stacionárny okolo lineárneho trendu, t.j. trendovo stacionárny) je formulovaná: \[ H_0\colon \sigma_\epsilon^2=0 \qquad H_1\colon \sigma_\epsilon^2>0, \] Testovacia štatistika sa vypočíta zo vzťahu \(KPSS = \frac{1}{n^2} \frac{\sum_{t=1}^n \left(\sum_{i=1}^t e_i\right)^2}{\sigma^2(q)}\) pričom konzistentný odhad \(\hat{\sigma}_e^2\) dostaneme z \[\hat{\sigma}_e^2(q)=\frac{1}{n} \sum_{t=1}^n e_t^2 +\frac{2}{n} \sum_{j=1}^q w(j,q) \sum_{t=j+1}^n e_t e_{t-j},\] kde \(w(j, q)\) je váhová funkcia. Odporúča sa použiť Bartlettovo okno \(w(j,q)=1-\frac{j}{q+1}\), ktoré zaručuje nezápornosť \(\hat{\sigma}_e^2(q)\). Aby bol rozptyl \(\hat{\sigma}_e^2(q)\) konzistentný, n aj q musia byť dostatočne veľké (odporúča sa \(q \sim \sqrt{n}\)). Nulovú hypotézu zamietame ak \(KPSS\) je väčšie ako kritická hodnota z tabuľky.
| model | \(\alpha\) | KPSS |
|---|---|---|
| bez trendu | 0.01 | 0.74 |
| 0.05 | 0.46 | |
| 0.10 | 0.35 | |
| s trendom | 0.01 | 0.22 |
| 0.05 | 0.15 | |
| 0.10 | 0.12 |
Box-Jenkinsova metodológia má pre časové rady so stochastickým trendom, ktoré sa dajú stacionarizovať diferencovaním, určené modely integrovaných zmiešaných procesov ARIMA(\(p,d,q\)) \[ \phi(B)\Delta^d y_t = \delta + \theta(B)\varepsilon_t, \tag{5.3}\] kde \(\Delta^d y_t=(1-B)^d y_t\) je \(d\)-ta diferencia procesu \(y_t\), pre ktorú je ARMA(\(p,q\)) model (5.3) stacionárny a invertibilný. Potom sa časový rad \(y_t\) dá modelovať v dvoch krokoch: najprv vhodným diferencovaním a potom klasickým postupom B-J metodológie ako pri modeloch stacionárnych časových radov.
Špeciálne prípady už poznáme,
Driftový parameter \(\delta\) modeluje nenulovú úroveň procesu \(\Delta^d y_t\), t.j. deterministický trend v tvare polynómu \(d\)-teho stupňa pre pôvodný proces \(y_t\). Pre \(d>0\) je model ARIMA invariantný voči strednej hodnote \(y_t\), preto je zbytočné pred diferencovaním časový rad centrovať.
Stupeň diferencovania \(d\) je pre väčšinu časových radov rovný 1, iba zriedkavo \(d=2\). Možnosti jeho určenia zahřňajú
set.seed(3)
dat <- data.frame(Index = 0:100) |>
dplyr::mutate(
Diff0 = arima.sim(n = length(Index)-1, model=list(order=c(0,1,0), sd=1)),
Diff1 = c(NA, diff(Diff0)),
Diff2 = c(NA, NA, diff(Diff0, differences = 2))
)
ylab <- c(expression(x[t]),
expression(paste(Delta,x[t])),
expression(paste(Delta^{2},x[t]))
)
p11 <- ggplot(dat) + aes(x = Index, y = Diff0) + geom_line() +
labs(y = ylab[1], subtitle = paste("s2 = ", round(var(dat$Diff0),2)))
p12 <- dat$Diff0 |> acf(plot = FALSE) |> forecast::autoplot() + ggtitle("")
p21 <- ggplot(dat) + aes(x = Index, y = Diff1) + geom_line() +
labs(y = ylab[2], subtitle = paste("s2 = ", round(var(dat$Diff1, na.rm = TRUE),2)))
p22 <- dat$Diff1 |> acf(plot = FALSE, na.action = na.omit) |>
forecast::autoplot() + ggtitle("")
p31 <- ggplot(dat) + aes(x = Index, y = Diff2) + geom_line() +
labs(y = ylab[3], subtitle = paste("s2 = ", round(var(dat$Diff2, na.rm = TRUE),2)))
p32 <- dat$Diff2 |> acf(plot = FALSE, na.action = na.omit) |>
forecast::autoplot() + ggtitle("")
(p11 + p12) / (p21 + p22) / (p31 + p32)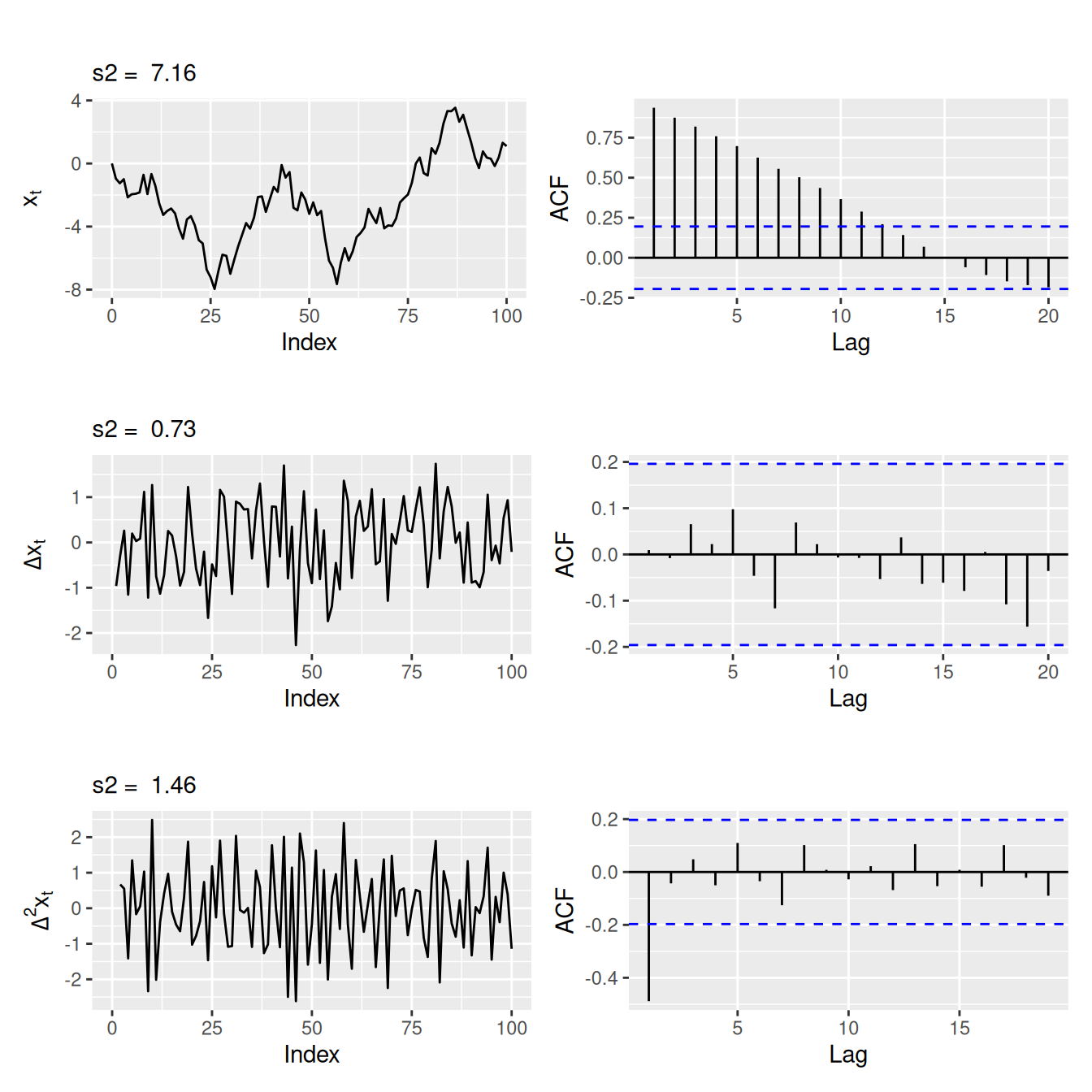
Tu sa treba ešte zastaviť pri význame konštantného (absolútneho) členu v modeli časového radu. V stacionárnych procesoch má súvis so strednou hodnotou (úrovňou) procesu, napr. pre MA(1) proces \(y_t=\beta_0 + \varepsilon_t+\theta_1 \varepsilon_{t-1}\) je priamo \(E(y_t)=\beta_0\), kým pre AR(1) proces \(y_t=\beta_0+\varphi_1y_{t-1}+\varepsilon_t\) je \(E(y_t)=\beta_0/(1-\varphi_1)\). No v náhodnej prechádzke s driftom \(y_t=\beta_0+y_{t-1}+\varepsilon_t\) je konštanta smernicou deterministického trendu.
Na dlhodobé predpovede z modelu ARIMA(\(p,d,q\)) majú stupeň diferencovania \(d\) a absolútny člen \(\delta\) zásadný vplyv, napríklad s
Ďalej s rastúcim \(d\) bude dramaticky rásť veľkosť predpovedného intervalu (pri \(d=0\) je takmer konštantnej dĺžky).
Model ARIMA sa dá zovšeobecniť tak, aby bolo možné modelovať aj sezónnosť. Ak by sme chceli vyjadriť napríklad časový rad iba januárových pozorovaní, použili by sme model ARIMA(\(P,D,Q\)) procesu \(\Phi(B_{12})\Delta_{12}^Dy_t=\Theta(B^{12})y_t\), kde \(t\) zodpovedá januáru, pričom \(\Delta_{12}=1-B^{12}\) je sezónny diferenčný operátor a \(\Phi,\Theta\) sú sezónne AR, resp. MA polynómy. Podobne by sa modelovali aj pozorovania v ostatných mesiacoch.
Hodnoty náhodnej zložky \(y_t\) sú pravdepodobne medzi rôznymi mesiacmi tiež korelované (predpokladáme súvis napr. januárových a februárových hodnôt), Túto (nesezónnu) závislosť môžeme popísať ARIMA(\(p,d,q\)) modelom \(\phi(B)\Delta^dy_t=\theta(B)\varepsilon_t\), kde \(\varepsilon_t\) už predstavuje biely šum a \(t\) je z klasickej indexovej množiny. Oba modely sa dajú spojiť do jediného modelu, a vo všeobecnosti doplniť aj driftový člen pre zahrnutie deterministického trendu. Vyjadrením diferenčného operátora pomocou operátora spätného posunutia dostaneme model (multiplikatívneho) procesu SARIMA\((p,d,q)\times(P,D,Q)_L\) v tvare \[ \Phi(B^L)\phi(B)(1-B^L)^D(1-B)^d y_t = \delta + \Theta(B^L)\theta(B)\varepsilon_t \] kde \(L\) je sezónna perióda, v nášom príklade \(L=12\).
Model SARIMA(1,0,0)(1,0,0)\(_{12}\) má (nesezónny) autoregresný polynóm \(\phi(B)=1-\varphi_1B\) a sezónny AR polynóm \(\Phi(B)=1-\Phi_1B^{12}\). Po dosadení do vzťahu a bez uváženia driftu platí \((1-\Phi_1 B^{12})(1-\varphi_1B)y_t = \varepsilon_t\) takže po rozpísaní dostaneme vzťah \[ y_t = \varphi_1y_{t-1} + \Phi_1y_{t-12} + (-\varphi_1\Phi_1)y_{t-13} + \varepsilon_t . \] Ten prakticky vyjadruje autoregresný model stupňa 13, ktorého väčšina parametrov sa rovná nule.
Najnáročnejšou fázou výstavby všeobecného modelu SARIMA\((p,d,q)\times(P,D,Q)_L\) je identifikácia, pretože priebeh ACF a PACF môže byť kvôli sezónnosti komplikovaný. Napr. SARIMA\((0,0,q)\times(0,0,Q)_L\) má ACF(\(k\)) nenulovú iba v bodoch \[ k=1,\ldots,q,L-q,\ldots,L+q,2L-q,\ldots,2L+q,\ldots,L\,Q-q,L\,Q+q \] a analogicky SARIMA\((p,0,0)\times(P,0,0)_L\) má v týchto bodoch nenulovú PACF. Zvyčajne je identifikácia záležitosťou voľby najlepšieho modelu z viacerých alternatív, pomocou softvéru.
# prepare data
dat <- within(list(), { # mutate list (not dframe 'cause tseries are of unequal length)
Observed = AirPassengers
ObsLog = Observed |> log()
ObsLogSdif = ObsLog |> diff(lag = 12)
ObsLogSdifDif = ObsLogSdif |> diff()
}) |>
rev() |> # reverse, because within() adds new objects to the beginning
do.call(ts.union, args = _) |> # make multivariate ts
tsibble::as_tsibble(pivot_longer = FALSE) # convert to time series tibble
# # direct composition:
# dat <- ts.union(Observed = AirPassengers,
# ObsLog = AirPassengers |> log(),
# ObsLogSdif = AirPassengers |> log() |> diff(lag = 12),
# ObsLogSdifDif = AirPassengers |> log() |> diff(lag = 12) |> diff()
# ) |>
# tsibble::as_tsibble(index = index, pivot_longer = FALSE)
# estimate models
fit <- dat |>
fabletools::model( # period is chosen automatically from index attribute
'SARIMA(1,1,0)(1,1,0)_12' = fable::ARIMA(log(Observed) ~ pdq(1,1,0) + PDQ(1,1,0)),
'SARIMA(0,1,1)(0,1,1)_12' = fable::ARIMA(log(Observed) ~ pdq(0,1,1) + PDQ(0,1,1)),
'SARIMA(1,1,1)(1,1,1)_12' = fable::ARIMA(log(Observed) ~ pdq(1,1,1) + PDQ(1,1,1))
)Postup vybudovania SARIMA modelu si teraz ukážeme na príklade mesačného počtu pasažierov (medzinárodnych letov) aeroliniek v rokoch 1949-1960, pozri (Shumway a Stoffer 2017, Example 3.49).
dat |>
tidyr::pivot_longer(cols = -index, names_to = "series", values_to = "value") |>
dplyr::mutate(
series = dplyr::case_match(series,
"ObsLog" ~ "--> Logarithm",
"ObsLogSdif" ~ "--> Seasonal diff.",
"ObsLogSdifDif" ~ "--> First differences",
.default = series),
series = forcats::as_factor(series) # preserve ordering
) |>
tidyr::drop_na(value) |>
ggplot() + aes(x = index, y = value) + geom_line() +
facet_grid(vars(series), scales = "free_y") 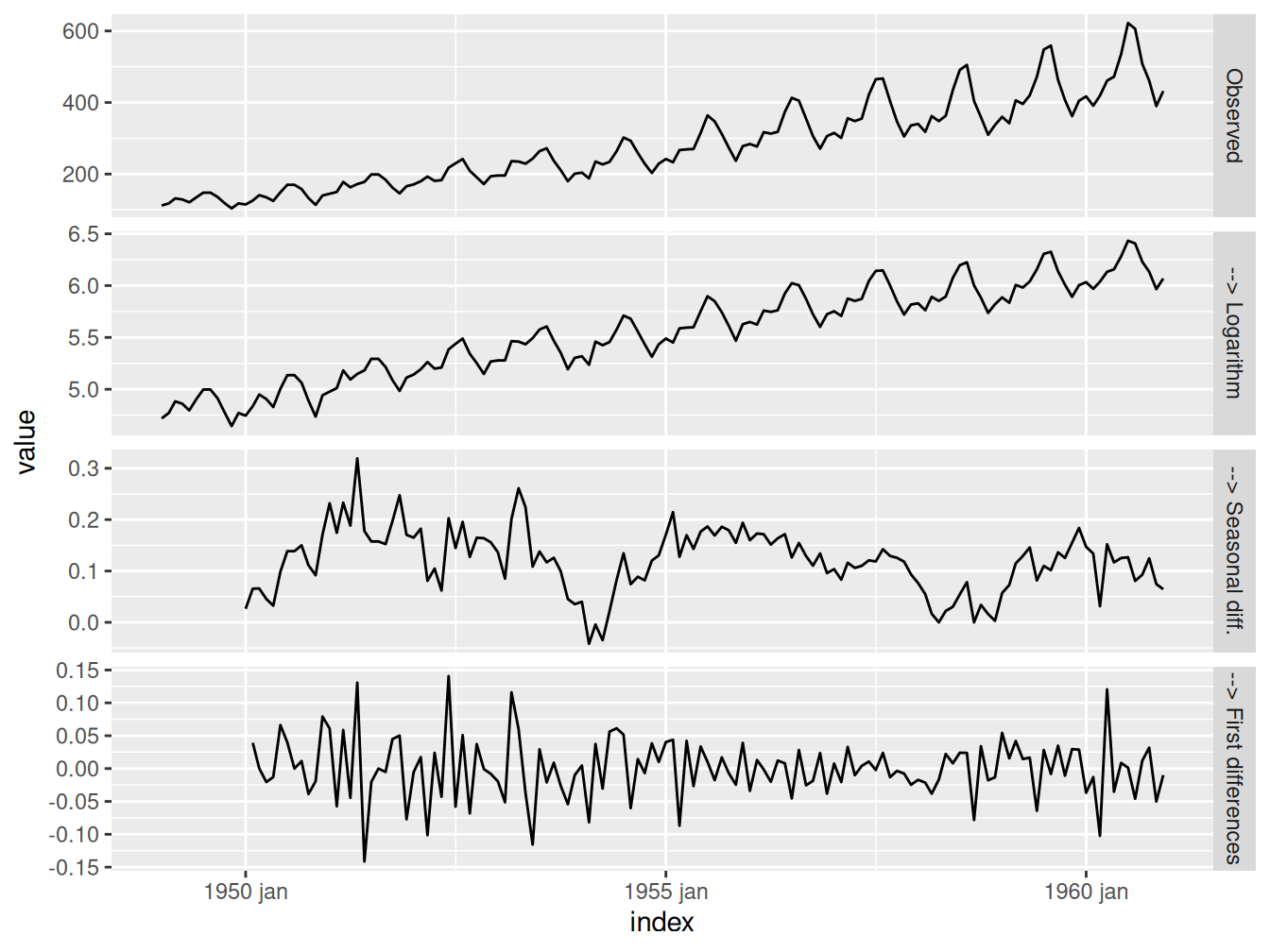
p1 <- dat |> feasts::ACF(ObsLogSdifDif, lag_max = 40) |> autoplot()
p2 <- dat |> feasts::PACF(ObsLogSdifDif, lag_max = 40) |> autoplot()
p1 + p2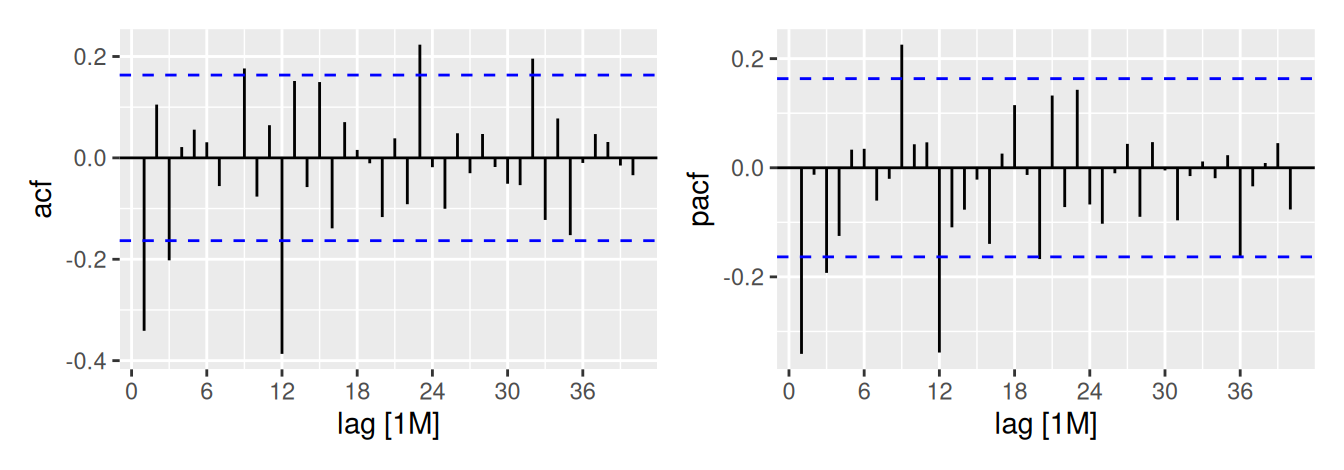
fit |> generics::glance() |>
dplyr::select(.model, AIC:BIC) |>
knitr::kable()| .model | AIC | AICc | BIC |
|---|---|---|---|
| SARIMA(1,1,0)(1,1,0)_12 | -474.8188 | -474.6299 | -466.1932 |
| SARIMA(0,1,1)(0,1,1)_12 | -483.3991 | -483.2101 | -474.7735 |
| SARIMA(1,1,1)(1,1,1)_12 | -480.3109 | -479.8309 | -465.9349 |
fit |>
dplyr::select(`SARIMA(0,1,1)(0,1,1)_12`) |>
feasts::gg_tsresiduals(lag_max = 40)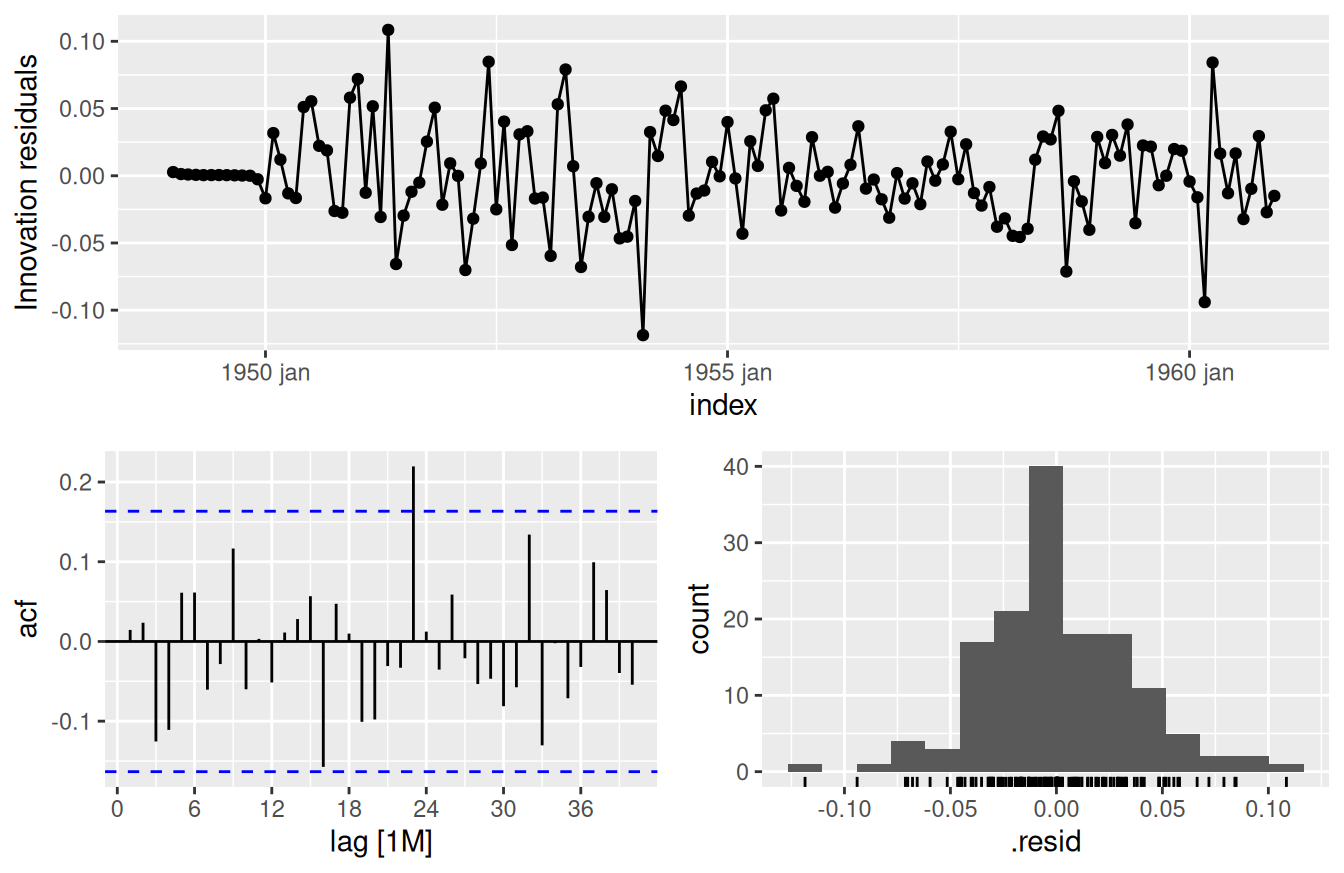
fit |>
dplyr::select(`SARIMA(0,1,1)(0,1,1)_12`) |>
generics::forecast() |>
autoplot() +
autolayer(dat, .vars = Observed)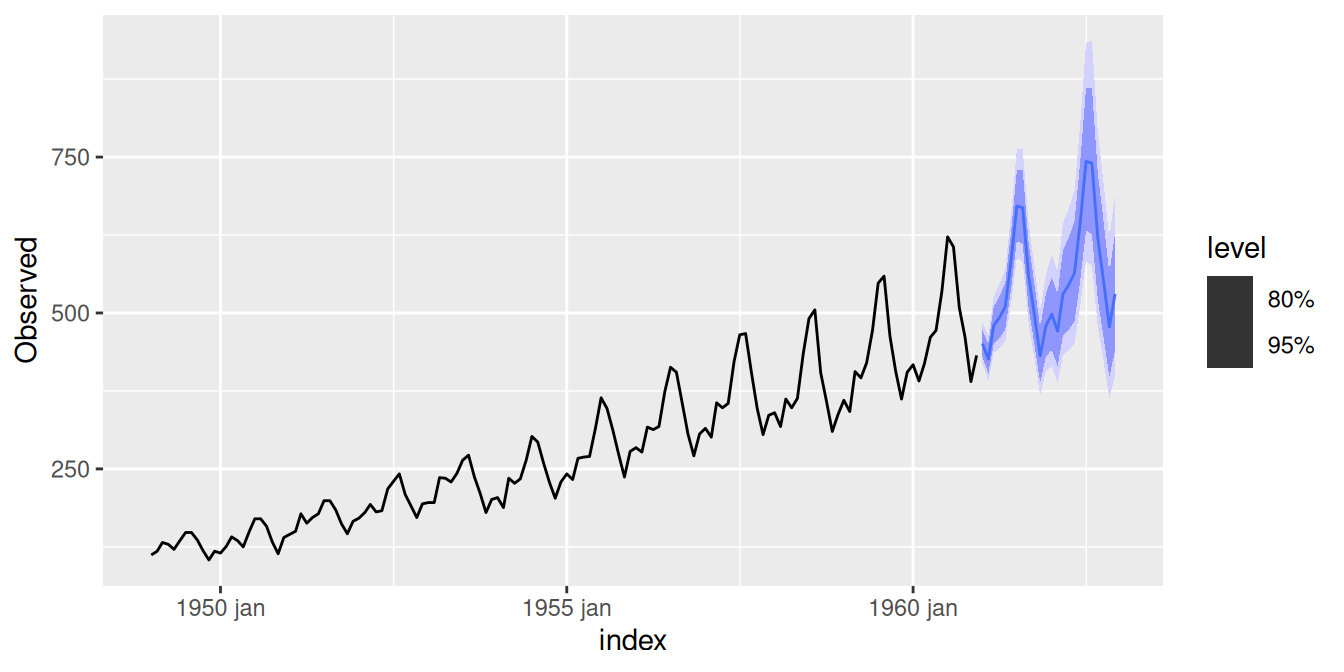
Niektoré časové rady zostávajú autokorelované aj cez veľmi dlhé časové vzdialenosti. Ich ACF klesá rýchlejšie ako pri ARIMA (kde klesá pomaly a lineárne) ale pomalšie ako pri ARMA (kde klesá rýchlo a exponenciálne), takže aplikovanie už prvých diferencií by znamenalo prediferencovanie. Označujú sa za procesy s dlhou pamäťou (angl. long-memory, persistent process) a pre ich modelovanie sa osvedčilo frakcionálne diferencovanie. Proces ARFIMA(p,d,q), teda fractionally integrated ARMA, predstavuje kompromis medzi stacionárnym ARMA a plne diferencovaným ARIMA procesom, \[ \phi(B)(1-B)^d (y_t-\mu)=\theta(B)\varepsilon_t. \] Podobne ako stacionárny ARMA sa dá formálne rozšíriť na MA(\(\infty\)) \[ y_t=(1-B)^{-d}\phi^{-1}(B)\theta(B)\varepsilon_t=\sum_{i=0}^\infty\psi_iB^i\varepsilon_t=\sum_{i=0}^\infty\psi_i\varepsilon_{t-i} \] a pre \(|d|<0.5\) je stacionárny, ale platí \(\sum\psi_i^2<\infty\) (na rozdiel od absolútnej sumovatelnosti \(\sum|\psi_i|<\infty\) pri ARMA procese).
Stupeň diferencovania d sa stáva súčasťou odhadovaných parametrov (pri zápornom d ide o tzv. antipersistent proces), odhad musí byť vykonaný numerickými metódami (napr. Gauss-Newton). Dá sa ukázať, že pre autokorelačnú funkciu platí \(\rho(k)\approx k^{2d-1}\) pre veľké k, z čoho pre \(0<d<0.5\) vidno, že \(\sum_{k=-\infty}^{\infty}|\rho(k)|=\infty\), čo vysvetľuje názov “modely s dlhou pamäťou” alebo “perzistentné modely”. Uplatňujú sa napr. pri hydrologických, environmentálnych, finančných i ekonomických časových radoch.
dat <- ts.union(
index = time(astsa::varve),
Observed = astsa::varve,
ObsLog = astsa::varve |> log(),
ObsLogDif = astsa::varve |> log() |> diff()
) |>
as.data.frame()
fit <- list(
arFima = dat$ObsLog |> {\(x) x-mean(x)}() |> fracdiff::fracdiff(nar=0, nma=0),
arFima_auto = dat$ObsLog |> forecast::arfima(), # automatically p=q=0 chosen
arima = dat$ObsLog |> arima(order=c(0,1,1))
)Model ARFIMA ilustrujeme na záznamoch tzv. paleoklimatickej ľadovcovej varvy (čo je nános usadenín piesku a prachu v dôsledku topenia ľadovcov v jarnom období), ktorá dokáže sprostredkovať informácie o parametroch paleolitickej klímy ako napr. teplota (v teplejších rokoch sa usádza viac piesku a prachu). Časový rad (označený ako Observed na Obr. 5.8) tvorí hrúbka ľadovcovej varvy z oblasti Massachusetts z obdobia pred 11,834 až 11200 rokmi (spolu 634 rokov). Pozri (Shumway a Stoffer 2017, Example 5.1).
Rozptyl rastie so strednou hodnotou, preto časový rad transformujeme logaritmom (ObsLog). Z ACF na Obr. 5.9 (a) vidno dlhú pamäť procesu. Trend ani sezónnu zložku v takomto prípade nemá zmysel uvažovať.
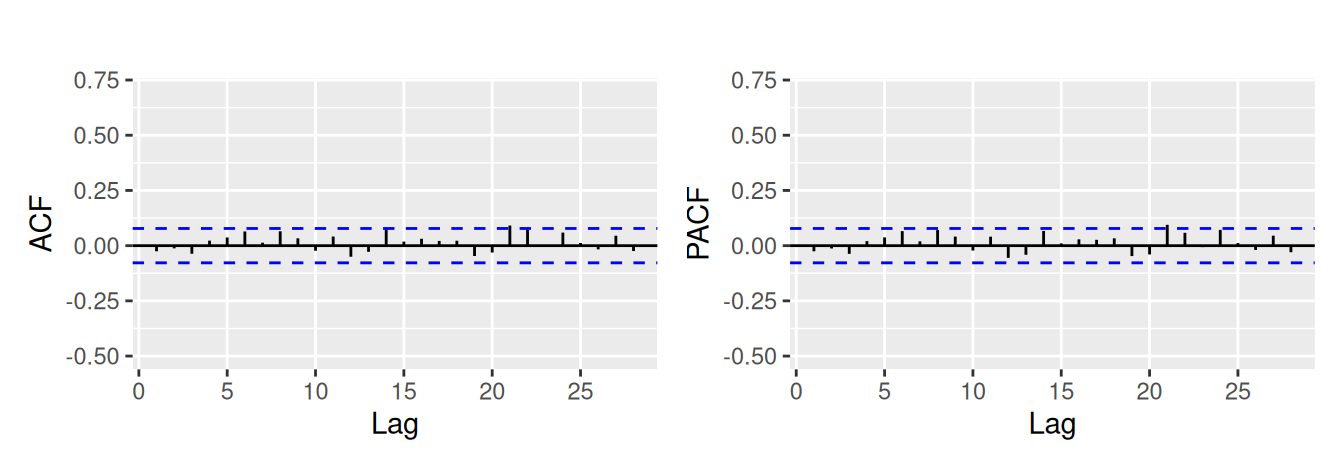
Odhadom modelu ARFIMA dostaneme odhad stupňa diferencovania, \(d=0.37\). Z korelogramu frakcionálnych diferencií na Obr. 5.9 (b) sa nezdá, že by bol potrebný AR alebo MA člen.
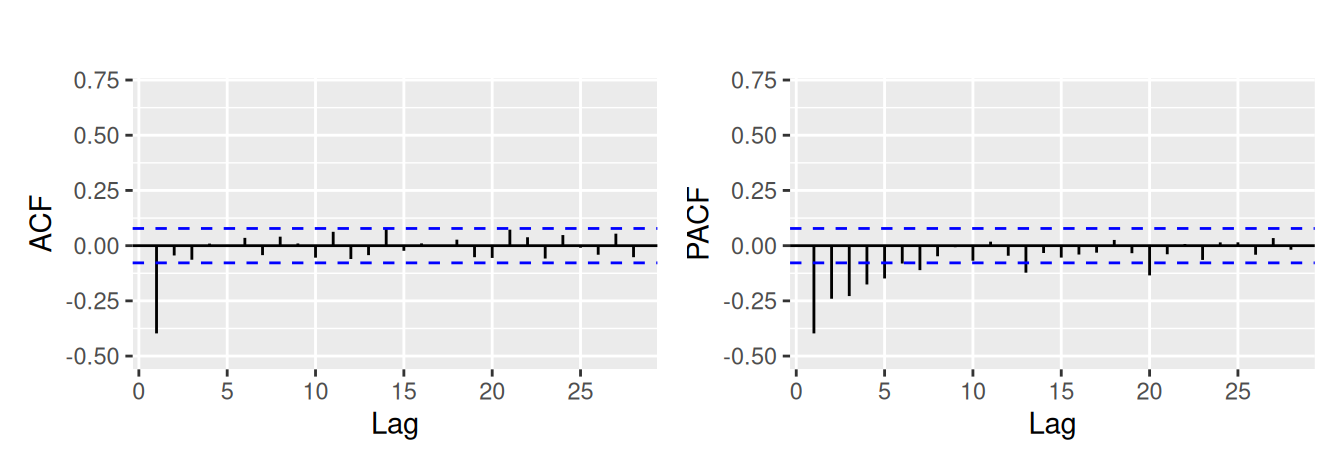
Naproti tomu klasickým postupom (ARIMA) by sme aplikovali prvé diferencie – ich ACF/PACF je na Obr. 5.9 (c) – a identifikovali ARIMA(0,1,1). Rezíduá by však boli stále autokorelované (s p-hodnotou Box-Pierce testu rovnou 0.0026) preto by sme proces nakoniec identifikovali ako ARIMA(1,1,1). To je výrazne zložitejší model, vrátime sa teda ku ARFIMA a použijeme ho na predpovedanie (Obr. 5.10).
dat |>
tidyr::pivot_longer(c(Observed, ObsLog), names_to = "series") |>
ggplot() + aes(x = index, y = value) + geom_line() +
facet_wrap(~series, ncol = 1, scales = "free_y") +
labs(y = "")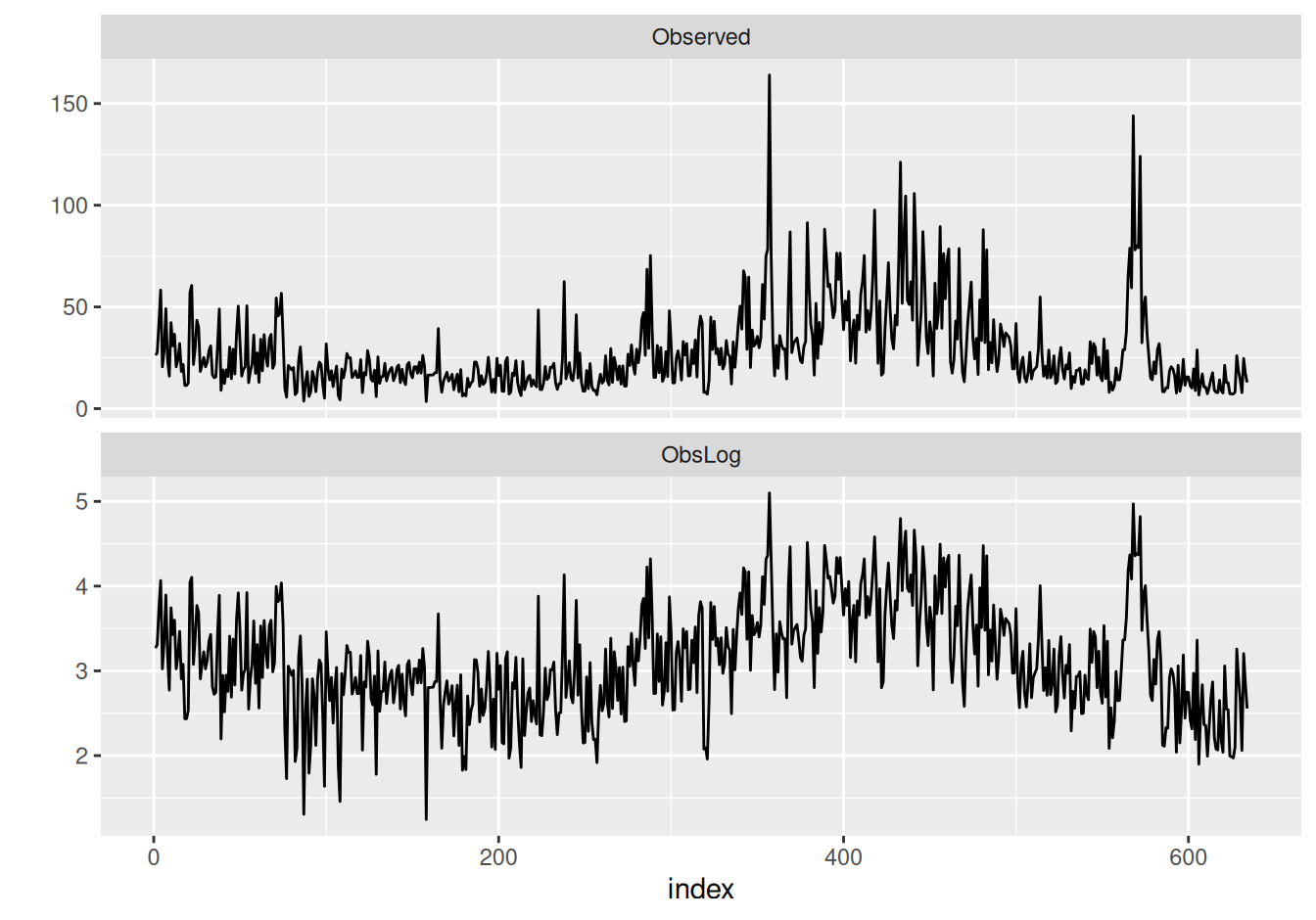
# utility function
ggAcfPacf <- function(x, ylim = c(-0.5,0.7)) {
p1 <- x |> acf(plot = FALSE, na.action = na.omit) |>
autoplot() + labs(title = "") + expand_limits(y = ylim)
p2 <- x |> pacf(plot = FALSE, na.action = na.omit) |>
autoplot() + labs(title = "") + expand_limits(y = ylim)
p1 + p2
}
# plots
dat$ObsLog |> ggAcfPacf()
fit$arFima |> residuals() |> ggAcfPacf()
dat$ObsLogDif |> ggAcfPacf()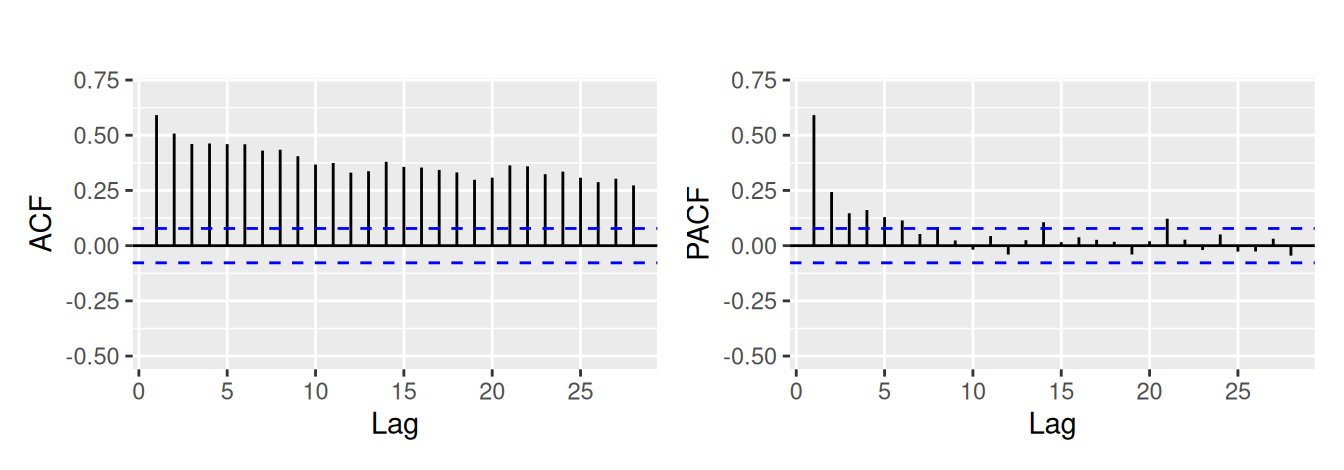
fit$arFima_auto |> forecast::forecast(h=100) |> autoplot() + labs(y = "ObsLog", title = "")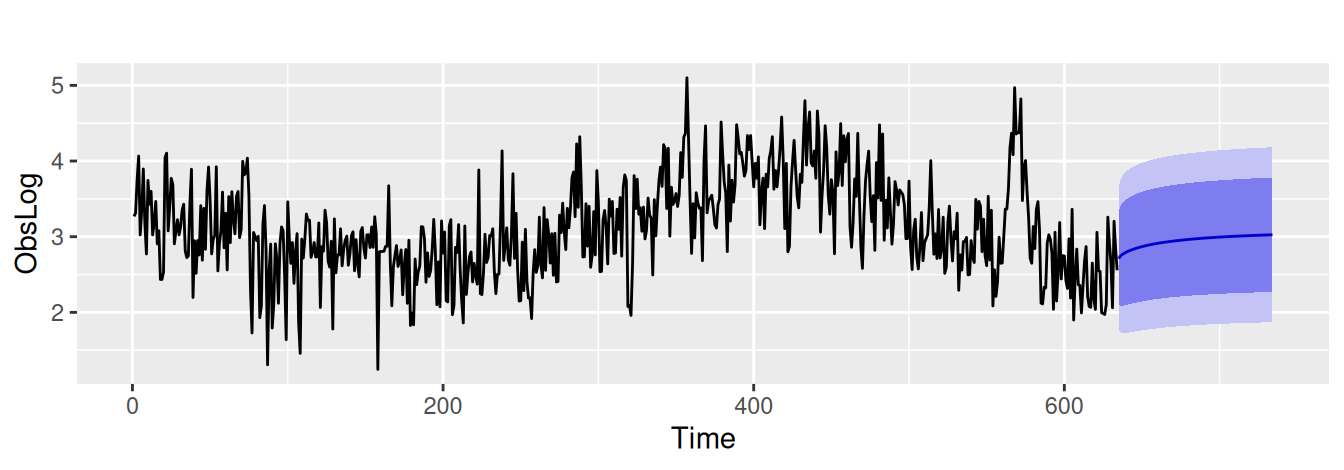
Časové rady, ktoré sú nestacionárne kvôli premenlivému rozptylu, a ten nerastie so strednou hodnotou, sa nedajú stacionarizovať Box-Cox transformáciou.
Namiesto toho môžme skúsiť vyjadriť rozptyl náhodnej zložky \(e_t\) ako funkciu času a modelovať pomocou autoregresného modelu podmienenej heteroskedasticiy (angl. autoregressive conditionally heteroscedastic) ARCH(p), \[
\begin{split}
e_t &= \sigma_t\varepsilon_t\ , \\
\sigma_t^2 &= \alpha_0 + \sum_{i=1}^p\alpha_ie_{t-i}^2\ ,
\end{split}
\] kde \(\varepsilon_t\) je biely šum, alebo pomocou zovšeobecneného, GARCH(p,q) modelu \[
\sigma_t^2 = \alpha_0 + \sum_{i=1}^p\alpha_ie_{t-i}^2 + \sum_{i=1}^q\beta_i\sigma_{t-i}^2
\]
kde \(\alpha_0,\alpha_i,\beta_i\) sú parametre.
V celej kapitole budeme kvôli zavedenému indexovaniu AR polynóm značiť písmenom \(\phi\), ktoré je príbuzné ku označeniu jednotlivých parametrov \(\varphi_i\).↩︎
Rozdelenie DF má ťažšie konce (fat tails) ako t-rozdelenie, takže jeho kvantily sú v absolútnej hodnote podstatne väčšie.↩︎
Napr. v prípade procesu \(y_t=0.95y_{t-1}+\varepsilon_t\), ak nedokáže zamietnuť nulovú hypotézu jednotkového koreňa, znamená to, že buď skutočne platí nestacionarita, alebo že nemáme dosť informácií na jej zamietnutie (napr. krátky časový rad).↩︎
Pri testovaní 20 hodnôt je pri \(\alpha=0.05\) ešte prípustné, že sa objaví jedna mierne vybočujúca hodnota.↩︎