Kód
JohnsonJohnson |> tsibble::as_tsibble() |>
fabletools::model(
feasts::classical_decomposition(value, type = "multiplicative")
) |>
fabletools::components() |>
ggtime::autoplot() + labs(title = "")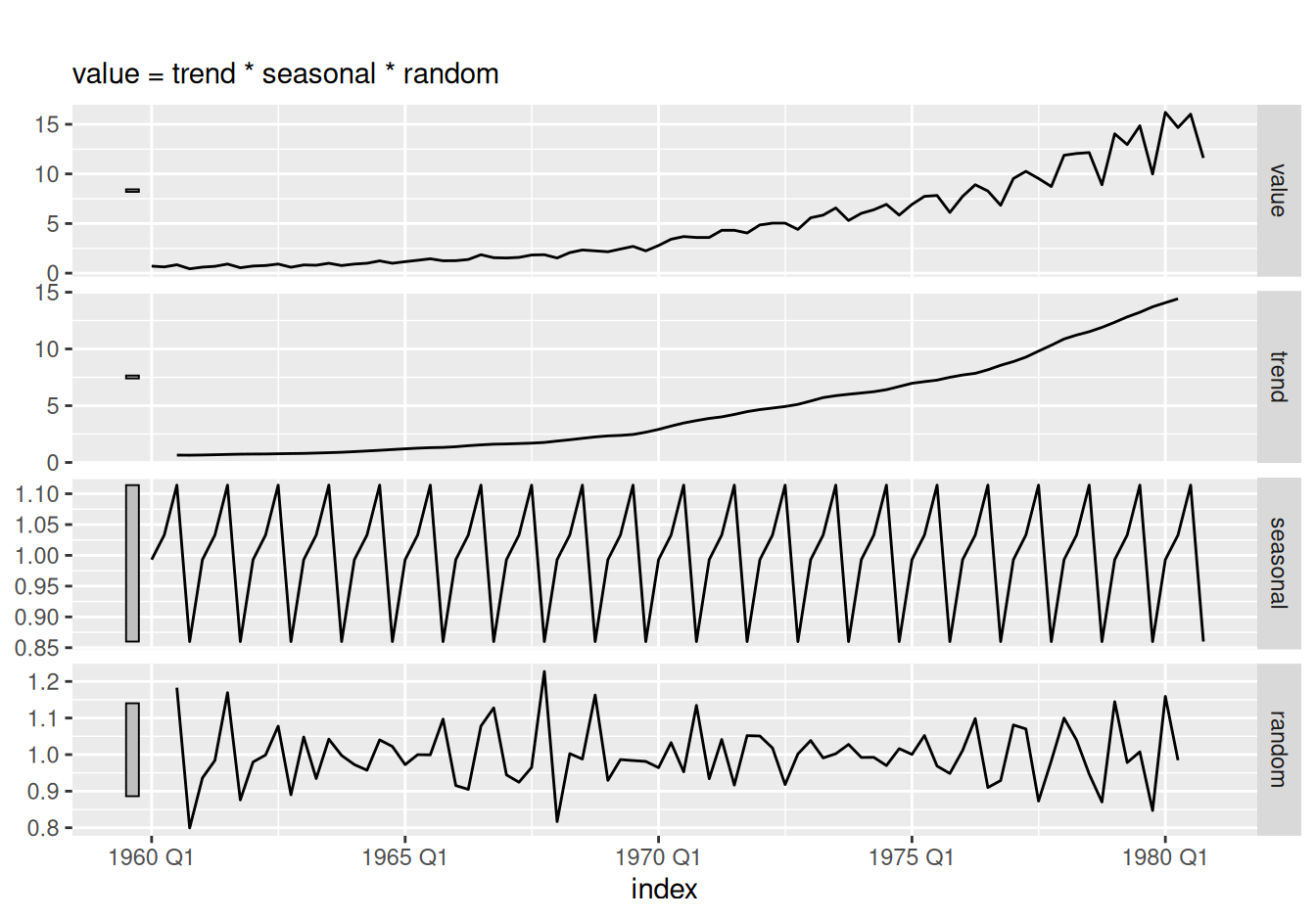
Dekompozičný prístup sa na časové rady pozerá najčastejšie ako na aditívnu kompozíciu troch základných zložiek, \[ y_t = T_t + S_t + R_t \] kde
Prvé dve zložky sú zodpovedné za nestacionaritu časového radu a často sa súhrnne nazývajú ako systematické (v dlhodobom horizonte). Významnosť systematických zložiek sa dá vyjadriť (a porovnať) pomocou relatívnej intenzity \(I\) voči reziduálnej zložke, napr. pre trend v aditívnej dekompozícii platí \[ I_T = \max\left(0, \frac{var(T_t)}{var(T_t + R_t)}\right) = \max\left(0, 1 - \frac{var(R_t)}{var(T_t + R_t)}\right) \]
Ak nestacionarita časového radu v rozptyle súvisí s jeho strednou hodnotu, konkrétne ak rozptyl všetkých zložiek okrem trendu rastie lineárne so strednou hodnotou, potom sa dá časový rad vyjadriť ako multiplikatívna kompozícia \[ y_t = T_t \cdot S_t \cdot R_t \]
Pri aditívnej dekompozícii sú jednotlivé zložky uvažované vo svojich skutočných absolútnych hodnotách a merané v jednotkách časového radu. Pri multiplikatívnej dekompozícii je vo svojich skutočných, absolútnych hodnotách uvažovaný a v jednotkách časového radu meraný iba trend, ostatné zložky sú vyjadrené v relatívnych hodnotách voči trendu a sú teda bezrozmerné. Multiplikatívny vzťah sa logaritmickou transformáciou dá previesť na aditívny, \[ \log(y_t) = \log(T_t) + \log(S_t) + \log(R_t) \] preto sa multiplikatívnou dekompozíciou nebudeme bližšie zaoberať.
Metódy odhadu jednotlivých zložiek časového radu sa líšia rôznym stupňom objektivity, presnosti a výpočtovej zložitosti. Ich výber do značnej miery závisí od cieľa dekompozície a od povahy časového radu.
V základe sa používajú najmä dva prístupy:
Postup spočíva
Filtračné metódy je výhodné použiť na začiatku, ešte vo fáze prieskumnej analýzy, kedy v časovom rade pomáhajú vizuálne oddeliť trend-cyklus od zvyšku. Nedajú sa použiť na predpovedanie, iba na popis – na prvotné odhalenie povahy časového radu, ako pomôcka pri voľbe typu stochastických (statických alebo dynamických regresných) modelov.
Klasická filtračná metóda má už vyše 100 rokov, ešte stále sa používa a je založená na kĺzavých (prípadne aj vážených) priemeroch. Na rovnakom princípe funguje novšia metóda X11, ktorá navyše umožňuje odhad aj na okrajoch časového radu, pomaly sa meniacu sezónnu zložku a zohladniť vplyv niektorých nepravidelností (napr. voľných dní) či známych prediktorov. Procedúra je plne automatická, odolná voči odľahlým pozorovaniam či náhlym zmenám v strednej hodnote (level shifts). Ešte univerzálnejšou je metóda STL (Seasonal and Trend decomposition using Loess), ktorá namiesto kĺzavého priemeru používa metódu LOESS (angl. locally estimated scatterplot smoothing, lokálna regresia používaná pre odhad nelineárnych závislostí). Oproti predošlým má niekoľko výhod, a) okrem mesačných a kvartálnych radov dokáže pracovať aj s inou sezonalitou, b) sezónna zložka sa v čase môže meniť flexibilnejšie, c) hladkosť trendu a cyklu sa dá kontrolovať, d) dovoľuje zvoliť robustný odhad. Naproti tomu nedokáže zohľadniť kalendárne odchýľky.
Pre ilustráciu, multiplikatívna dekompozícia na Obr. 2.1 odhaľuje jednotlivé zložky mechanizmu, ktorý generoval ceny akcií spoločnosti J&J: stredná hodnota exponenciálne rastie, sezónne kolísanie počas roka je v rozsahu približne 85% – 110% strednej hodnoty (s maximom v streťom a minimom v štvrtom kvartáli) a reziduálna zložka ukazuje niekoľko silných výkyvov oproti normálu, napr. tie okolo roku 1968 (čo v pôvodnom rade nevidno).
JohnsonJohnson |> tsibble::as_tsibble() |>
fabletools::model(
feasts::classical_decomposition(value, type = "multiplicative")
) |>
fabletools::components() |>
ggtime::autoplot() + labs(title = "")Trend a sezónnosť sú často deterministického charakteru, čiže ich procesy závisia iba od nenáhodnej premennej, ktorou je čas, preto veľmi obľúbené sú metódy založené na statickom regresnom modeli \[ y_t = \boldsymbol\beta\cdot\mathbf{f}(t) + \varepsilon_t \] Samozrejme predpokladá, že reziduálna zložka je v čase nekorelovaná a homoskedastická, čiže má charakter bieleho šumu. Ak to tak nie je, súčasťou modelovania dlhodobých systematických zložiek je aj modelovanie reziduálnej zložky (systematickej v krátkodobom horizonte), o ktorom bude reč v Kapitola 3.
Časové rady zvyčajne obsahujú reziduálnu zložku. Okrem nej môžu (ale nemusia) obsahovať aj jednu, dve alebo aj všetky tri (dlhodobé) systematické zložky. Bežný postup pri analýze časového radu pomocou dekompozičného prístupu a regresie je nasledovný:
Postup dekompozície ilustrujme na jednoduchom príklade časového radu hodnôt (napr. teploty) zaznamenávaných v hodinových intervaloch po dobu 4 dní na Obr. 2.2 (a) až Obr. 2.2 (d). Smernica trendovej priamky je približne 2.4°C/deň, amplitúda sezónnej zložky (teda najväčšia odchýlka od strednej hodnoty) je cca 3°C, perióda sa rovná 24hod a rezíduá majú N(0,1) rozdelenie.
# data preparation
par <- list(a = 15, b = -0.1, c = 3) # process parameters
dat <- rbind( # sample span and time variable
data.frame(sample = "train", index = 1:96), # training sample
data.frame(sample = "valid", index = seq(96+1, length.out = 12)) # validation
) |>
dplyr::mutate( # time series components
Trend = par$a + par$b*index, # linear trend
Season = par$c * cos(2*pi*(index-12)/24), # sinusoid
Noise = rnorm(dplyr::n(), 0, 1), # gaussian noise
All = Trend + Season + Noise) # additive composition
# A
dat |> dplyr::filter(sample == "train") |>
dplyr::mutate(Residuals = All - Trend) |>
tidyr::pivot_longer(cols = c(All, Trend, Residuals),
names_to = "Component", values_to = "Value",
names_transform = forcats::as_factor) |>
ggplot() + aes(x = index, y = Value, color = Component) + geom_line() +
geom_hline(yintercept = 0, linetype = 3) +
scale_color_manual(values = c(1,4,2)) +
theme(legend.direction = "horizontal",
legend.justification = c("right","top"),
legend.position = c(1,1),
legend.title = element_blank())
# B
(dat$All - dat$Trend) |>
acf(plot = FALSE, lag.max = 30) |>
forecast::autoplot() +
annotate("text", hjust = "right", x = 30, y = 0.8,
label = "Data: trend residuals") +
labs(title = "")
# C
dat |> dplyr::filter(sample == "train") |>
dplyr::mutate(Residuals = All - Trend) |>
tidyr::pivot_longer(cols = c(Residuals, Season),
names_to = "Component", values_to = "Value",
names_transform = forcats::as_factor) |>
ggplot() + aes(x = index, y = Value, color = Component) + geom_line() +
geom_hline(yintercept = 0, linetype = 3) +
scale_color_manual(values = c(1,4)) +
theme(legend.direction = "horizontal",
legend.justification = c("right","top"),
legend.position = c(1,1),
legend.title = element_blank())
# D
dat |> dplyr::filter(sample == "train") |>
dplyr::mutate(TrendSeason = Trend + Season) |>
tidyr::pivot_longer(cols = c(All, TrendSeason, Noise),
names_to = "Component", values_to = "Value",
names_transform = forcats::as_factor) |>
ggplot() + aes(x = index) +
geom_line(aes(y = Value, color = Component)) +
scale_color_manual(values = c(1,4,2)) +
geom_line(aes(y = Trend + Season), color = 4, linetype = 2,
data = dat |> dplyr::filter(sample == "valid")) +
geom_hline(yintercept = 0, linetype = 3) +
theme(legend.direction = "horizontal",
legend.justification = c("right","top"),
legend.position = c(1,1),
legend.title = element_blank())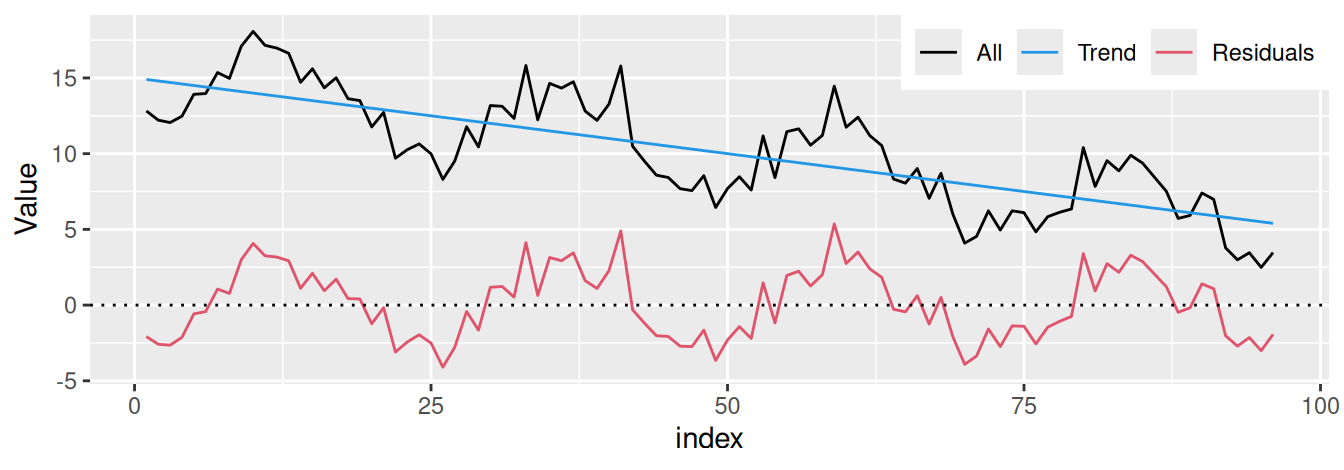
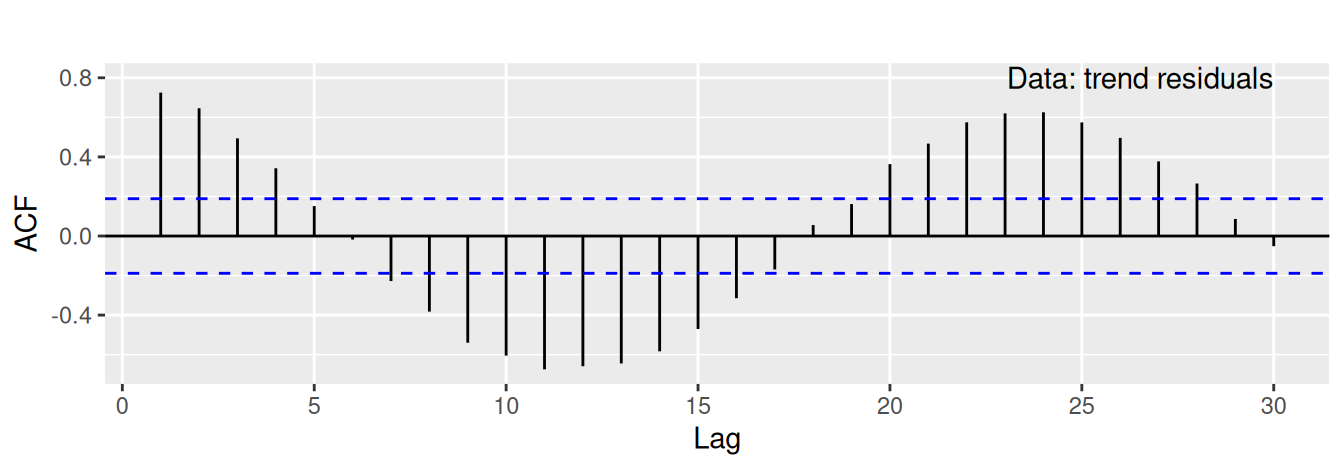
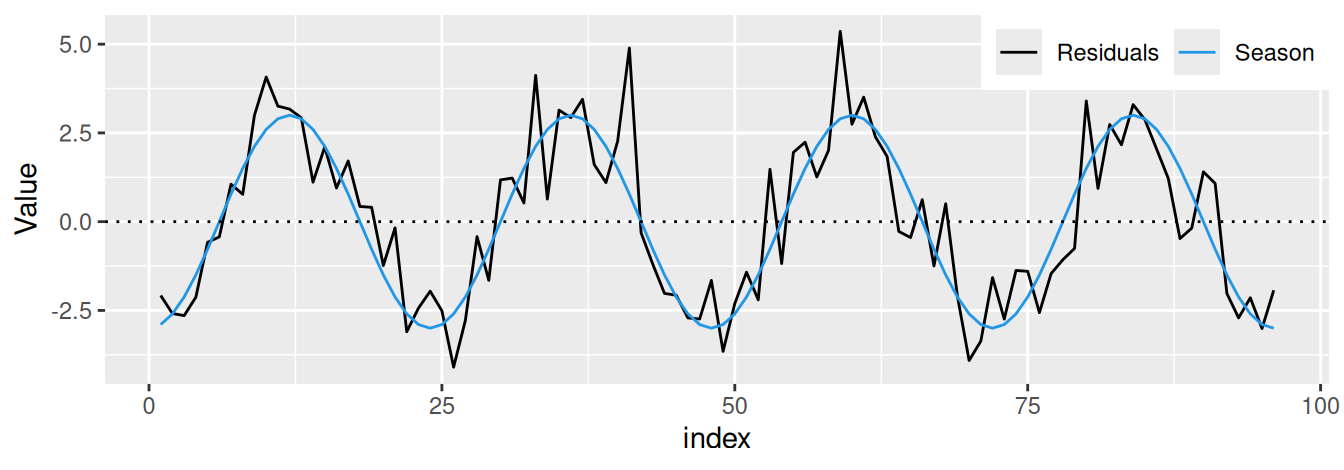
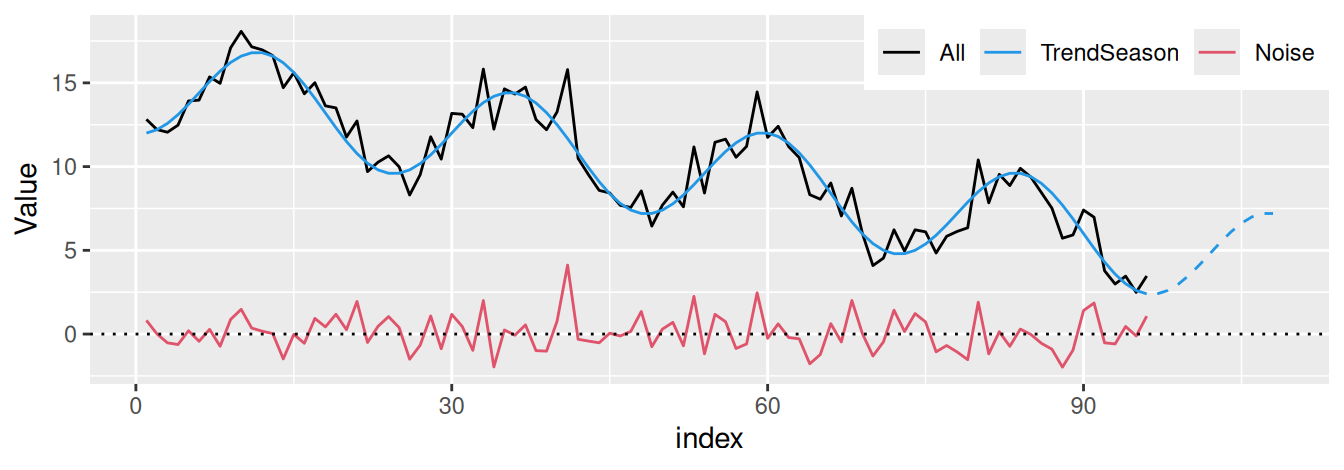
Výhodou dekompozície na systematické zložky pomocou regresných metód je okrem jednoduchosti modelovania aj možnosť predpovedania.
Pri určovaní (a eliminácii) trendu sa používajú dva prístupy (pozri napr. Cipra (1986) a Cipra (2008)),
Adaptívny prístup sa používa pri trendoch, ktoré v čase globálne menia svoj charakter, takže pre ich opis nemôžeme použiť žiadnu matematickú funkciu s konštantnými parametrami (iba lokálne). Známym zástupcom tejto skupiny je metóda kĺzavých priemerov (angl. moving average), exponenciálne vyhladzovanie (exponential smoothing) či lokálna regresia (napr. metóda LOESS – locally estimated scatterplot smoothing).
Metóda kĺzavých priemerov
Priemery sú počítané vždy z obdobia určitej dĺžky, pričom toto obdobie sa posúva (kĺže), čiže postupnosť empirických hodnôt nahradíme postupnosťou kĺzavých priemerov. Pri vhodnej voľbe kĺzavého obdobia sa dajú odstrániť periodické zložky (najmä sezónna). Výsledný časový rad je kratší o polovicu kĺzavého obdobia z každej strany.
Postup: 1) zvolíme dĺžku kĺzavého obdobia \(m<n\), 2) z prvých hodnôt čas.radu vypočítame prvý kĺzavý priemer \(KP_1=\frac{x_1+\ldots+x_m}{m}\), posunieme sa o jeden časový interval dopredu, \(KP_2=\frac{x_2+\ldots+x_{m+1}}{m}\), atď… 3) kĺzavé priemery sa zapisujú do stredu období, z ktorých boli vypočítané. Pri párnych \(m\) sa zvyknú ešte spriemerovať dve susedné.
Výhodou metódy je výpočtová jednoduchosť a prispôsobivosť lokálnemu priebehu, nevýhodou zas nevhodnosť pre výpočet predpovedí do budúcnosti.
Exponenciálne vyrovnávanie
Výpočet každej vyhladenej hodnoty je založený na všetkých dostupných minulých hodnotách č.radu, pričom váhy smerom do minulosti exponenciálne klesajú.
Postup: 1) zvolíme váhu \(w\in(0,1)\), obyčajne \(w>0.7\), pri menších hodnotách metóda príliš rýchlo reaguje na zmeny v charaktere č.radu, 2) potom \(EV_1=x_1\), \(EV_2 = (1-w) x_2 + w EV_1\), atď.
Metóda exponenciálneho vyrovnávania sa dá použiť aj na predpovedanie, rovnako váhu v rekurzívnom vzťahu je možné odhadnúť vhodnou optimalizáciou. Viac o metóde si preberieme v kapitole 7.
Subjektívne metódy klasického prístupu sa používajú pri predbežnej analýze časového radu. Pre dlhé časové rady môžme tvar (a typ) trendu určiť z grafického zobrazenia časového radu, príkladom je priemerovanie lokálnych extrémov trajektórie s vylúčením subjektívne nevyhovujúcich pozorovaní.
Analyticky sa trend popisuje pomocou niektorých jednoduchých matematických kriviek. Výhodou je ľahká konštrukcia predpovedí do budúcnosti (ak sa charakter trendu nezmení). Pri tomto postupe sa predpokladá, že časový rad má tvar \(y_t=T_t+e_t\), pričom reziduálna zložka má vlastnosti bieleho šumu (to umožní korektné použitie regresných metód). Typ vhodnej krivky určujeme na základe predbežného rozboru a teoretických znalostí procesu s ohľadom na ďalší vývoj.
Najčastejšie typy trendu podľa použitej matematickej krivky sú:
# linear
dat <- datasets::nhtemp |> broom::tidy() |>
dplyr::mutate(sample = ifelse(index < 1960, "train", "valid"))
fit <- lm(value ~ index, dat, subset = sample=="train")
cbind(dat, trend = predict(fit, newdata = dat)) |>
ggplot() + aes(x = index) +
geom_line(aes(y = value, color = sample), show.legend = FALSE) + # observed
geom_line(aes(y = trend, linetype = sample), color = 4, show.legend = FALSE) +
scale_color_manual(values = c(train = 1, valid = 2)) +
# annotate("text", hjust = "right",
# x = max(dat$index), y = min(dat$value) + 0.05*diff(range(dat$value)),
# label = expression(paste(Delta, T[t]==0.054)))
labs(x = "", y = "Temperature")
# quadratic
dat <- astsa::gtemp_both |> broom::tidy() |>
dplyr::mutate(sample = ifelse(index <= 1995, "train", "valid"))
fit <- lm(value ~ poly(index, 2), # subset argument does not work with poly
data = subset(dat, sample=="train"))
cbind(dat, trend = predict(fit, newdata = dat)) |>
ggplot() + aes(x = index) +
geom_line(aes(y = value, color = sample), show.legend = FALSE) + # observed
geom_line(aes(y = trend, linetype = sample), color = 4, show.legend = FALSE) +
scale_color_manual(values = c(train = 1, valid = 2)) +
labs(x = "", y = "Temperature anomaly")
# exponential
dat <- datasets::JohnsonJohnson |> broom::tidy() |>
dplyr::mutate(sample = ifelse(index <= 1977, "train", "valid"))
fit <- lm(log(value) ~ index, dat, subset = sample=="train")
cbind(dat, trend = exp(predict(fit, newdata = dat))) |>
ggplot() + aes(x = index) +
geom_line(aes(y = value, color = sample), show.legend = FALSE) + # observed
geom_line(aes(y = trend, linetype = sample), color = 4, show.legend = FALSE) +
scale_color_manual(values = c(train = 1, valid = 2)) +
labs(x = "", y = "Return")
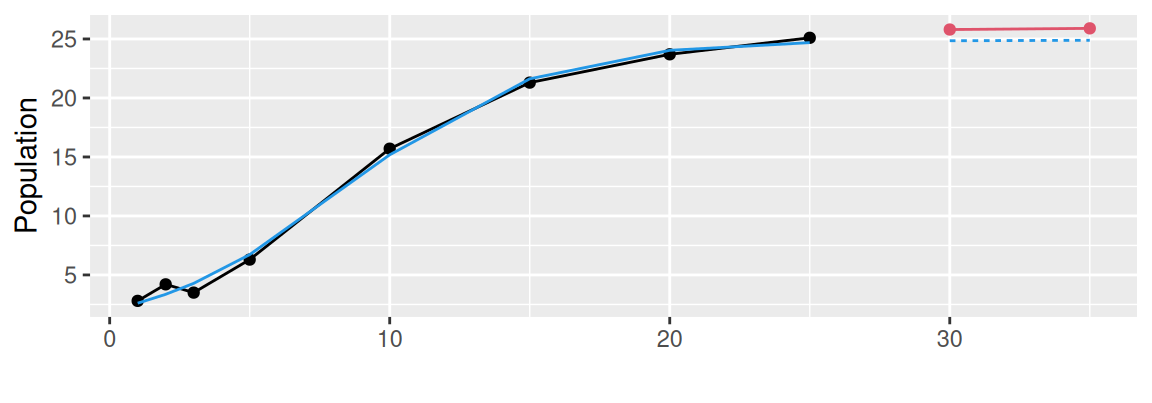
# logistic
dat <- data.frame( # http://strata.uga.edu/8370/lecturenotes/nonlinearRegression.html
index = c(1,2,3,5,10,15,20,25,30,35),
value = c(2.8,4.2,3.5,6.3,15.7,21.3,23.7,25.1,25.8,25.9)
) |>
dplyr::mutate(sample = ifelse(index <= 25, "train", "valid"))
fit <- nls(value ~ SSlogis(index, Asym, xmid, scal), dat, subset = sample=="train")
cbind(dat, trend = predict(fit, newdata = dat)) |>
ggplot() + aes(x = index) +
geom_line(aes(y = value, color = sample), show.legend = FALSE) + # observed
geom_point(aes(y = value, color = sample), show.legend = FALSE) + # observed
geom_line(aes(y = trend, linetype = sample), color = 4, show.legend = FALSE) +
scale_color_manual(values = c(train = 1, valid = 2)) +
labs(x = "", y = "Population")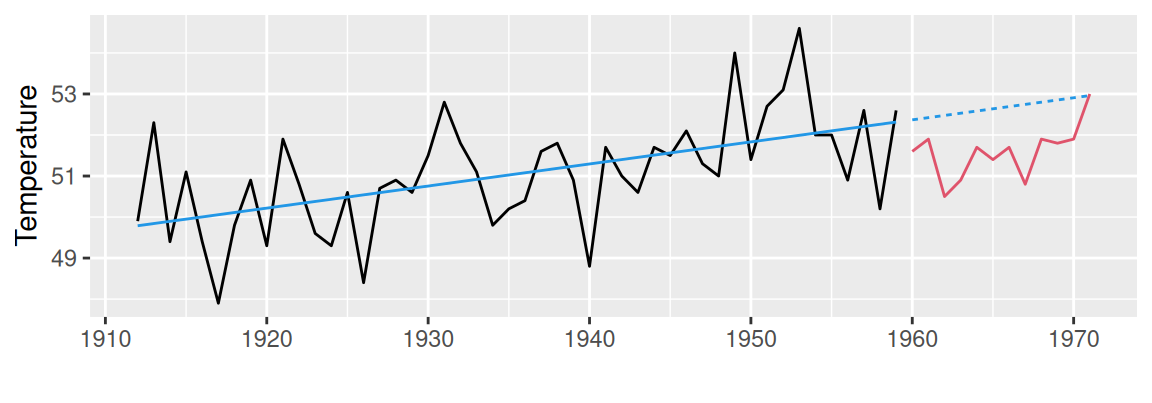
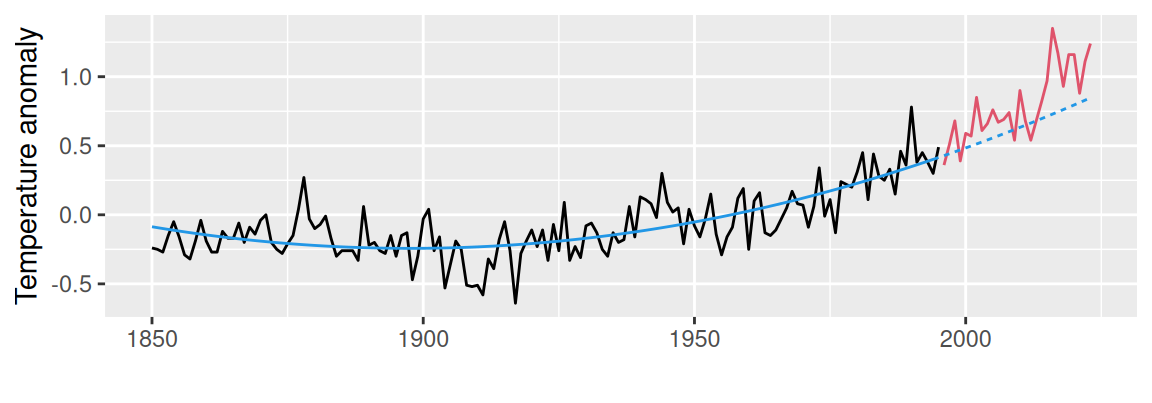
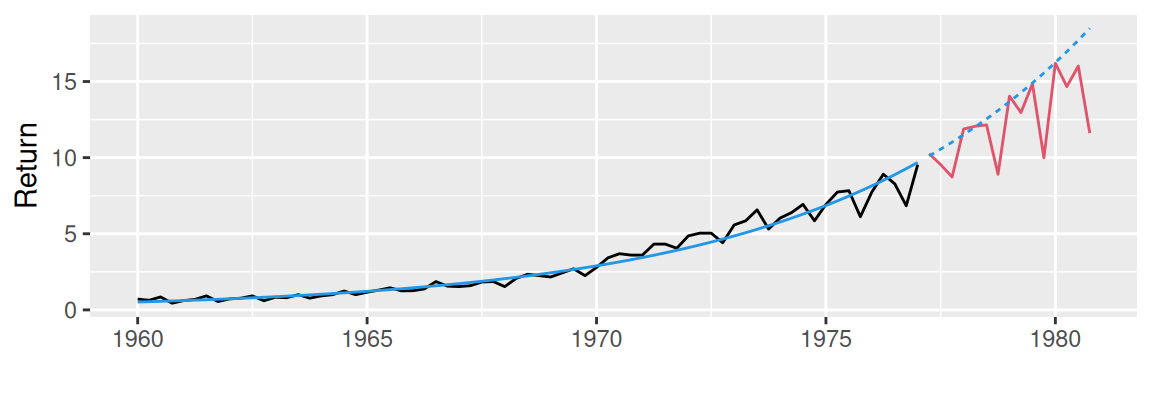
Napríklad kvadratický trend na Obr. 2.3 (b) bol odhadnutý regresnou metódou s členmi regresnej rovnice v maticovom tvare: \[ \mathbf{y} = \begin{pmatrix} -0.20 \\ -0.11 \\ \vdots \\ 0.46\end{pmatrix}, \quad \mathbf{X} = \begin{pmatrix} 1 & 1880 & 1880^2 \\ 1 & 1881 & 1881^2 \\ \vdots & \vdots & \vdots \\ 1 & 1995 & 1995^2 \end{pmatrix}, \quad \hat{\boldsymbol{\beta}} = \begin{pmatrix} 212 \\ -0.224 \\ 0.000059\end{pmatrix}, \quad \hat{\mathbf{e}} = \begin{pmatrix} 0.045 \\ 0.136 \\ \vdots \\ 0.121\end{pmatrix} \]
# data
dat <- data.frame(x = 3:7) |>
dplyr::mutate(max = pmax(0, x-5),
ind = dplyr::case_when(x < 5 ~ 0, x >= 5 ~ 1) # ,
# stepInd = ifelse(x<=5, "1", "2"),
# stepVal = dplyr::case_match(stepInd, "1" ~ 0, "2" ~ 3)
)
# plot
ggplot(dat) + aes(x = x) +
geom_line(aes(y = max, color = "max")) +
geom_step(aes(y = ind + 0.01, color = "ind")) + # +0.01 to distinguish lines
geom_point(aes(color = "ind"), x = 5, y = 1+0.01, show.legend = F) +
scale_x_continuous(breaks = 5, labels = expression(c[1])) +
scale_color_manual(
values = c("max" = 2, "ind" = 4), # assign colors
breaks = c("max","ind"), # ordering
labels = c(expression(paste(plain(max),"(0, t - ",c[1],")")),
expression(paste(1[group("[",list(c[1],infinity),")")](t)))
),
guide = guide_legend(title = "basis function")
) +
labs(x = "time", y = "") +
theme(legend.position = c(0.05,0.95), legend.justification = c("left","top"),
legend.text.align = 0) +
coord_cartesian(ylim = c(0,1.5))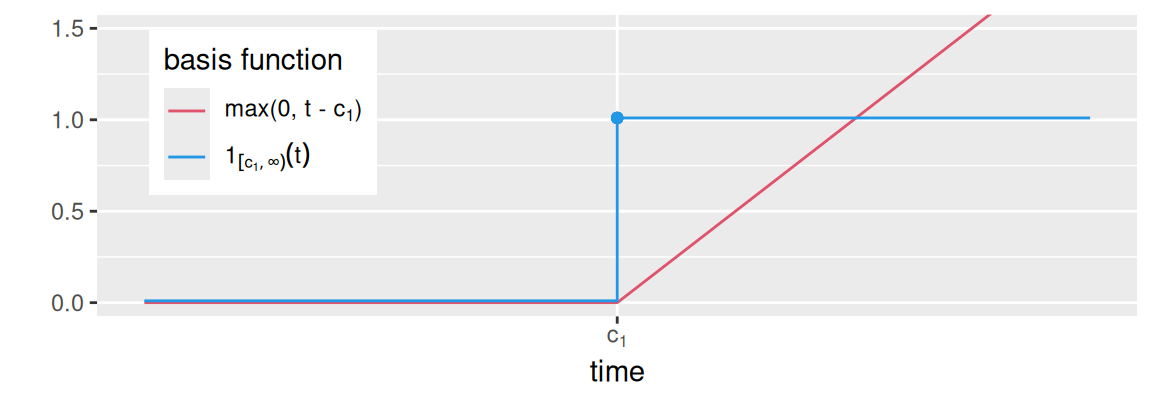
datAccidents <- data.frame(
index = 2010 + (0:71)/12,
value = c(1820,1594,1743,1637,1812,1753,1862,1844,1730,1980,1879,1957,1469,929,1135,1150,1306,1324,1276,1261,1264,1418,1086,1383,1117,995,949,996,1152,1227,1189,1213,1202,1341,1183,1314,1141,992,1054,978,1084,1186,1195,1193,1171,1202,1207,1183,995,877,1038,1049,1216,1177,1162,1113,1062,1333,1082,1190,1027,852,986,1023,1107,1194,1187,1239,1162,1272,1213,1273)
) |>
dplyr::mutate(sample = ifelse(index < 2015, "train", "valid"))
knots <- datAccidents$index[c(12,14)]
dat <- datAccidents |>
dplyr::mutate(max1 = pmax(index - knots[1], 0),
max2 = pmax(index - knots[2], 0),
ind = ifelse(index <= knots[1], 0, 1)
)
fit1 <- lm(value ~ index, dat, subset = sample=="train")
fit2 <- lm(value ~ index + max1 + max2, dat, subset = sample=="train")
fit3 <- lm(value ~ ind, dat, subset = sample=="train")
cbind(dat,
linear = predict(fit1, newdata = dat),
spline = predict(fit2, newdata = dat),
discontinuous = predict(fit3, newdata = dat)
) |>
ggplot() + aes(x = index) +
# two color scales could be handled by ggnewscale package
geom_point(aes(y = value), data = \(x) dplyr::filter(x, sample=="train")) +
geom_point(aes(y = value), data = \(x) dplyr::filter(x, sample=="valid"), color = 2) +
geom_line(aes(y = linear, linetype = sample, color = "linear")) +
geom_line(aes(y = spline, linetype = sample, color = "spline")) +
geom_line(aes(y = discontinuous, linetype = sample, color = "discontinuous"),
data = \(x) dplyr::filter(x, index <= knots[1])
) +
geom_line(aes(y = discontinuous, linetype = sample, color = "discontinuous"),
data = \(x) dplyr::filter(x, index > knots[1])
) + # cannot be solved by 'group' aes due to nonsolid linetype
geom_vline(xintercept = knots[1], linetype = 2) +
labs(x = "", y = "Accidents") +
scale_color_manual(
values = c("linear" = 3, "spline" = 4, "discontinuous" = 6),
breaks = c("linear", "spline", "discontinuous"),
# labels = c("lineárny", "lomený", "nespojitý"),
guide = guide_legend(title = "trend")
) +
guides(linetype = guide_none()) +
theme(#legend.direction = "horizontal",
legend.position = "inside",
legend.position.inside = c(0.99,0.99),
legend.justification = c("right","top"))
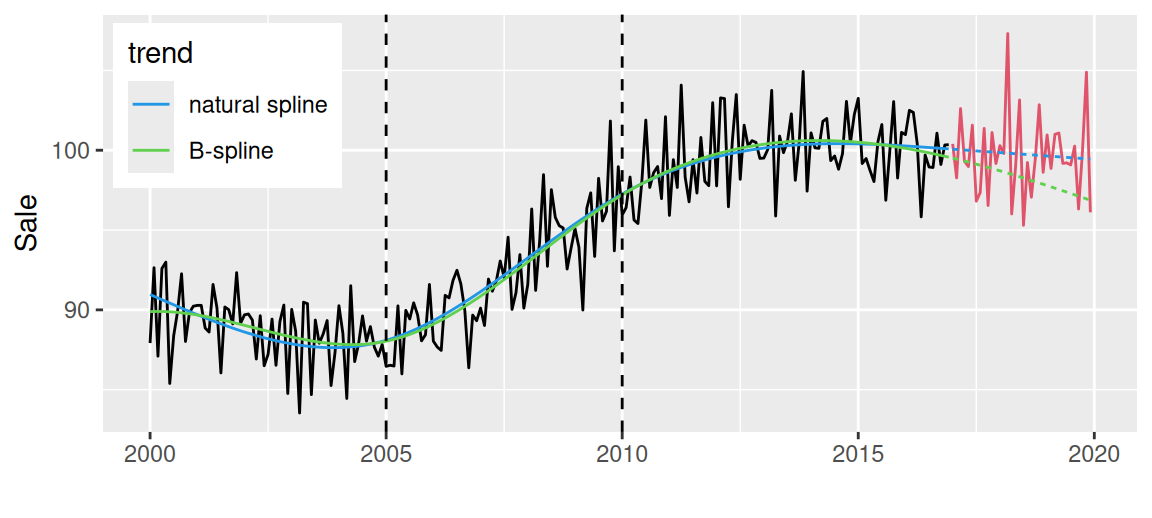
datSales <- data.frame(index = 2000 + (0:239)/12,
value = c(87.92,92.64,87.1,92.59,92.99,85.39,88.38,89.92,92.26,88.02,89.83,90.23,90.28,90.28,88.86,88.61,91.59,90.12,86.05,90.18,90.01,89.12,92.33,89.16,89.69,89.74,89.36,86.92,89.63,86.5,87.22,89.42,86.53,89.27,90.3,84.76,90.03,88.67,83.54,90.48,90.39,84.69,89.36,87.91,88.49,89.33,85.26,87.32,90.26,88.53,84.45,91.51,86.76,87.88,89.62,88.04,88.95,87.67,87.1,87.83,86.46,86.53,86.48,90.25,85.99,89.97,89.43,90.44,89.68,88.06,88.44,91.59,88.04,87.67,87.46,90.91,90.75,91.85,92.48,91.61,89.96,86.37,89.67,89.32,90.11,89.02,91.93,91.17,91.8,93.06,92.01,94.55,90.03,91.07,93.46,90.11,91.59,96.32,91.22,94.25,98.47,92.73,97.53,95.79,95.27,95.13,92.56,93.86,95.1,93.92,89.99,96.36,97.33,93.35,98.24,95.57,96.17,101.83,93.7,98.97,95.94,96.41,98.32,95.63,95.41,98.06,101.89,97.67,98.6,98.98,96.97,102.1,95.92,99.41,97.67,104.08,98.32,96.77,99.41,97.32,100.8,98.05,97.78,102.98,97.77,103.28,103.24,96.46,100.6,103.49,98.18,101.57,100.26,100.6,100.49,99.49,99.51,100.05,103.75,95.88,100.89,99.85,100.53,102.28,98.12,100.52,104.93,97.44,101.09,100.15,100.12,101.81,101.99,99.35,99.64,98.81,99.79,103.06,100.45,102.24,103.25,99.17,99.48,98.73,98.04,100.53,101.61,96.87,99.89,103.05,98.26,101.12,100.98,102.5,102.37,100.39,95.83,99.7,98.95,98.92,101.07,99.11,100.33,100.35,100.4,98.27,102.61,99.31,98.98,101.57,96.81,97.35,101.37,96.54,101.11,99.17,100.29,99.8,107.31,96.01,99.01,103.15,95.3,99.23,97.06,99.45,102.85,98.62,100.96,98.86,101,101.08,99.18,99.21,99.08,100.26,96.32,99.98,104.89,96.11)
) |>
dplyr::mutate(sample = ifelse(index < 2017, "train", "valid"))
knots <- c(2005, 2010)
fit1 <- lm(value ~ splines::ns(index, knots = knots),
data = subset(datSales, sample=="train")
) # beware, 'subset' argument does not work with bases like splines or poly
fit2 <- lm(value ~ splines::bs(index, knots = knots),
data = subset(datSales, sample=="train"))
cbind(datSales,
natural = predict(fit1, newdata = datSales),
B = predict(fit2, newdata = datSales)
) |>
ggplot() + aes(x = index) +
geom_line(aes(y = value), data = \(x) dplyr::filter(x, sample=="train")) +
geom_line(aes(y = value), data = \(x) dplyr::filter(x, sample=="valid"), color = 2) +
geom_line(aes(y = natural, linetype = sample, color = "natural")) +
geom_line(aes(y = B, linetype = sample, color = "B")) +
geom_vline(xintercept = knots, linetype = 2) +
labs(x = "", y = "Sale") +
scale_color_manual(
values = c("natural" = 4, "B" = 3),
breaks = c("natural", "B"),
labels = c("natural spline", "B-spline"),
guide = guide_legend(title = "trend")
) +
guides(linetype = guide_none()) +
theme(#legend.direction = "horizontal",
legend.position = "inside",
legend.position.inside = c(0.01,0.98),
legend.justification = c("left","top"))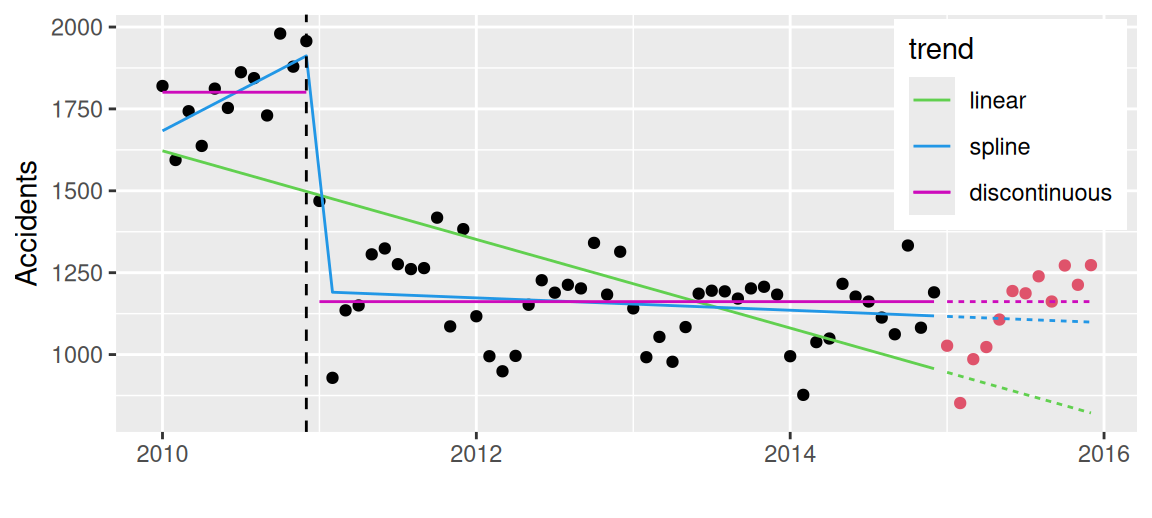
Periódu \(L\) sezónnej zložky určujeme z periodogramu, následne sa rozhodneme pre jeden z nasledujúcich regresných modelov:
# helper function, extracts month of the year from decimal format
year_to_month <- function(x) x |>
(\(x) x - floor(x))() |>
(`*`)(12) |>
round() |>
(`+`)(1) |>
as.factor()
# get residuals of trend (for both train and validation period)
dat <- datAccidents |>
(\(x) cbind(x, Tresiduals =
lm(value ~ pmax(index - index[12], 0) + pmax(index - index[14], 0),
data = subset(x, sample=="train")) |>
predict.lm(newdata = x) |>
(\(y) x$value - y)()
))()
# fit two seasonal models
fit1 <- lm(Tresiduals ~ year_to_month(index),
data = subset(dat, sample=="train")
)
fit2 <- lm(Tresiduals ~ sin(2*pi*index/1) + cos(2*pi*index/1),
data = subset(dat, sample=="train"))
# get both models values and also components for the harmonic one
dat <- cbind(dat,
indicator = predict(fit1, newdata = dat),
harmonic = predict(fit2, newdata = dat),
har = model.matrix(fit2, data = dat) |>
t() |> (`*`)(coef(fit2)) |> (`[`)(-1,) |> t()|> (`-`)(300) |>
(`colnames<-`)(1:2) # har.1 + har.2 = harmonic (- 300)
)
# plot them all
dat |>
ggplot() + aes(x = index) +
# data
geom_line(aes(y = Tresiduals), data = \(x) dplyr::filter(x, sample=="train")) +
geom_line(aes(y = Tresiduals), data = \(x) dplyr::filter(x, sample=="valid"),
color = 1) +
# model
geom_line(aes(y = indicator, linetype = sample, color = "indicator")) +
geom_line(aes(y = harmonic, linetype = sample, color = "harmonic")) +
# harmonic components
geom_line(aes(y = har.1, linetype = sample, color = "harmonic"), linewidth = 0.1) +
geom_line(aes(y = har.2, linetype = sample, color = "harmonic"), linewidth = 0.1) +
# tuning
labs(x = "", y = "Accidents (trend residuals)") +
scale_color_manual(
values = c("indicator" = "#00BFC4", "harmonic" = "#F8766D"), # scales::hue_pal()(2)
breaks = c("indicator", "harmonic"),
labels = c("indicator variables", "harmonic waves"),
guide = guide_legend(title = "seasonality")
) +
scale_y_continuous(sec.axis = sec_axis(~.+300, breaks = 0)) + # secondary axis
guides(linetype = guide_none()) +
theme(legend.direction = "horizontal",
legend.position = "inside", legend.position.inside = c(0.99,0.99),
legend.justification = c("right","top")) +
expand_limits(y = 320) # to accommodate legend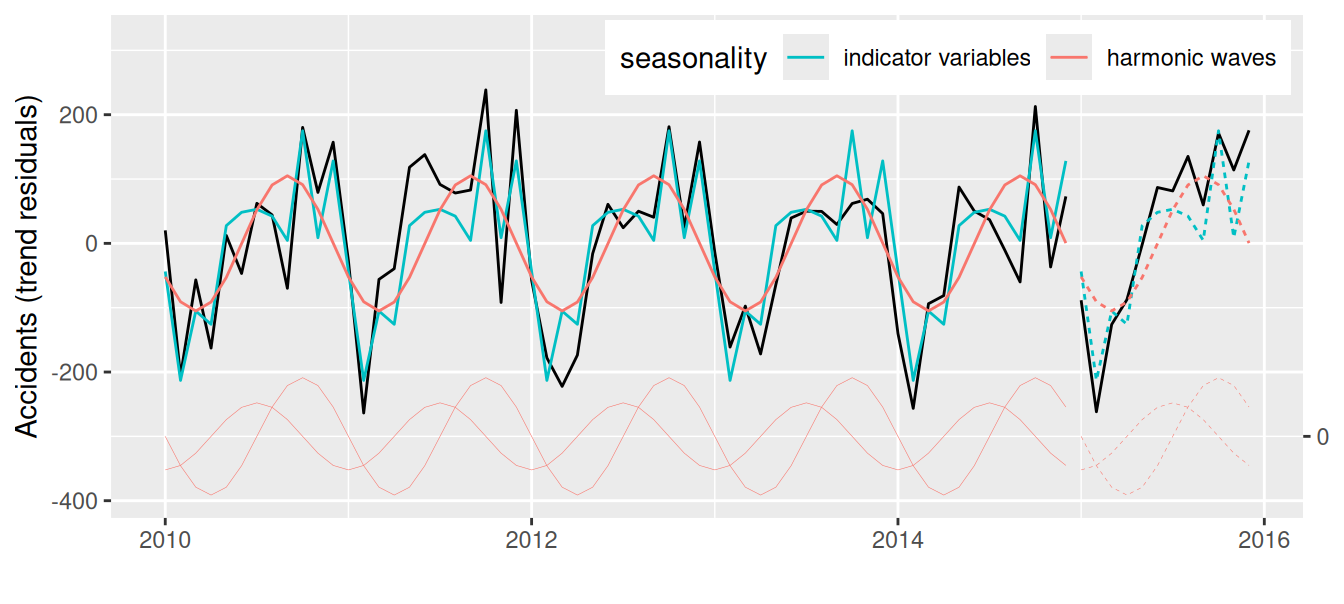
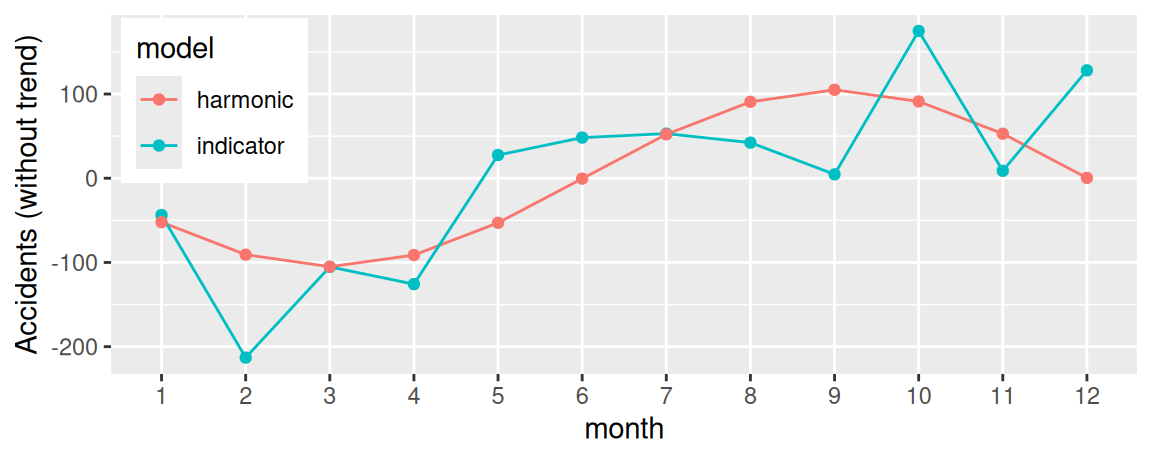
# ACF of trend residuals
# the following may not work due to a bug in as_tsibble
# dat |>
# tsibble::as_tsibble(index = index) |>
# feasts::ACF(Tresiduals) |>
# autoplot()
# surrogate solution
dat |>
dplyr::filter(sample == "train") |>
_$Tresiduals |> ts(start = 2010, frequency = 12) |>
forecast::ggAcf() + labs(title = NULL)
#
dat |>
dplyr::select(c(index, indicator, harmonic)) |>
dplyr::slice_head(n = 12) |>
dplyr::mutate(month = year_to_month(index)) |>
tidyr::pivot_longer(c(indicator, harmonic), names_to = "model", values_to = "value") |>
ggplot() + aes(x = month, y = value, color = model, group = model) +
geom_line() + geom_point() +
labs(x = "month", y = "Accidents (without trend)") +
theme(legend.justification = c("left","top"), legend.position = c(0.01, 0.99))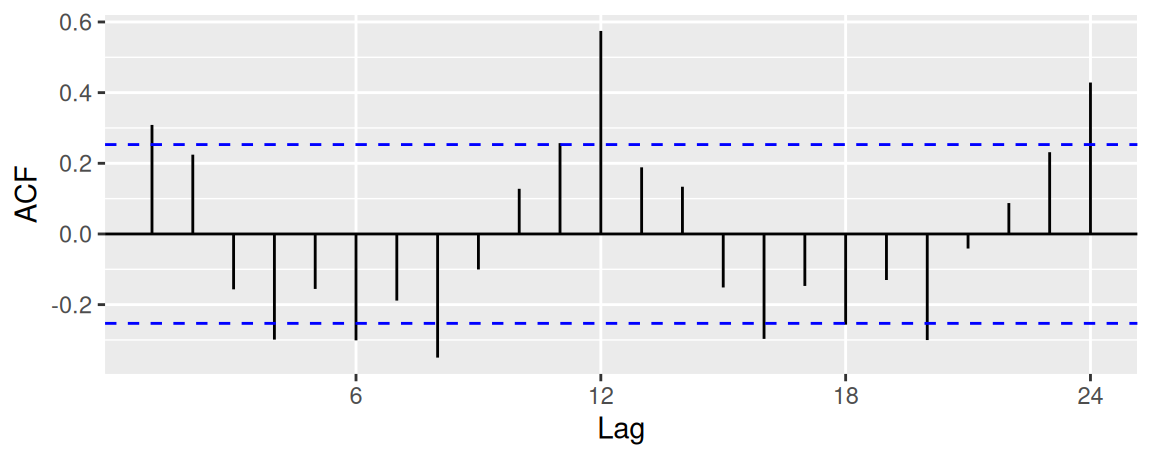
Doteraz sme sa zaoberali analýzou časových radov v časovej oblasti (napr. ACF bola funkciou posunutia v čase). Alternatívnym prístupom je analýza časových radov vo Fourierovom priestore, čiže v spektrálnej (frekvenčnej) oblasti, iným názvom spektrálna analýza. V jej prípade považujeme časový rad za súčet sínusových a kosínusových funkcií s rôznymi amplitúdami a frekvenciami. Pomocou štatistických nástrojov ako periodogram a spektrálna hustota je možné získať obraz o zastúpení jednotlivých frekvencií v časovom rade (tzv. spektrum) a vytipovať tie najvýznamnejšie, ktoré potom explicitne vystupujú v modeli cyklickej zložky.
V časovej oblasti sme skúmali kovariančnú alebo korelačnú funkciu stacionárnych stochastických procesov. Vo frekvenčnej oblasti je jej ekvivalentom funkcia spektrálnej hustoty (skrátene aj spektrum), ktorú môžeme vypočítať Fourierovou transformáciou \[ f(\omega) = \frac1{2\pi} \sum_{k=-\infty}^{\infty}\gamma(k) e^{-i k\omega} \] a opačne, inverznou Fourierovou transformáciou dostávame kovariančnú funkciu \[ \gamma(k) = \int_{-\pi}^{\pi}f(\omega) e^{i k\omega} d\omega . \] Predpokladáme pritom, že kovariančná funkcia \(\gamma(k)\) je absolútne sumovateľná, t.j. \(\sum_{k=-\infty}^{\infty}|\gamma(k)| < \infty\).
Uhlová frekvencia \(\omega\) v predošlých vzťahoch je počet cyklov v radiánoch (jeden cyklus sa rovná uhlu \(2\pi\)) za časovú jednotku (t.j. časový interval medzi dvoma hodnotami č.r.). Dĺžka periódy \(L=\frac{2 \pi}{\omega}\) je čas, za ktorý sa uskutoční jeden cyklus, pozri Obr. 2.7.
dat <- data.frame(time = seq(0, 5, length.out = 200)) |>
dplyr::mutate(f1 = sin(2*pi*time/4),
f2 = sin(2*pi*time/1)
)
dat |>
ggplot() + aes(x = time, y = f1) + geom_line() + labs(y = "") +
geom_hline(yintercept = 0, linetype = 3)
dat |>
ggplot() + aes(x = time, y = f2) + geom_line() + labs(y = "") +
geom_hline(yintercept = 0, linetype = 3)
Pretože \(\gamma(-k)=\gamma(k)\) a tiež \[ \begin{split} e^{-ik\omega} &= \cos(k\omega) - i\sin(k\omega) \\ e^{-i(-k\omega)} = e^{ik\omega} &= \cos(k\omega) + i\sin(k\omega) \end{split} \] môžeme spektrum písať \[ \begin{split} f(\omega) &= \frac{1}{2\pi} \left( \gamma(0) + \sum_{k=1}^{\infty}\gamma(k) e^{i k\omega} + \sum_{k=1}^{\infty}\gamma(k) e^{-i k\omega} \right) \notag \\ &= \frac{1}{2\pi} \left( \gamma(0) + \sum_{k=1}^{\infty}\gamma(k) [ \cos(k\omega) + i\sin(k\omega) + \cos(k\omega) - i\sin(k\omega) ] \right) \notag \\ &= \frac{1}{2\pi} \left( \gamma(0) + 2\sum_{k=1}^{\infty}\gamma(k) \cos(k\omega) \right). \end{split} \tag{2.1}\]
Z tohoto zápisu už priamo vidno vlastnosti spektra, a síce že \(f(\omega)\) je reálna párna funkcia, periodická s periódou \(2\pi\), takže nám stačí skúmať spektrum len pre \(\omega\in[0,\pi]\).
Ak položíme \(k=0\), dostávame \(\gamma(0) = \sigma^2 = \int_{-\pi}^{\pi}f(\omega)d\omega\). Vidno, že celková disperzia stacionárneho stoch. procesu môže byť “rozložená” na niekoľko zložiek s rôznymi frekvenciami, pričom \(f(\omega)d\omega\) je príspevok k celkovej disperzii zložky v rozsahu frekvencie \((\omega,\omega+d\omega)\).
Pre proces bieleho šumu \(\varepsilon_t\) platí \[ \gamma(k)=\begin{cases} \sigma^2 & k=0 \\ 0 & k \neq 0, \end{cases} \] z čoho podľa (2.1) dostávame \[ f(\omega) = \frac{\sigma^2}{2 \pi}. \] Z toho vyplýva, že spektrálna hustota je konštantná pre všetky frekvencie; každá frekvencia v spektre prispieva rovnakým dielom k celkovej variancii. To je pôvod názvu biely šum – je ako biele svetlo, ktoré je rovnomernou zmesou všetkých frekvencií, t.j. farieb vo viditeľnom spektre.
V praxi sa používajú dva prístupy na odhad spektra:
Pri parametrickom sa najprv odhaduje vhodný lineárny model (ARMA) pre daný stac. stoch. proces, a potom sa vypočíta spektrálna hustota modelu. Tento prístup je pre určenie frekvencií cykl. zložky nevhodný.
Pri neparametrickom sa odhadne výberové spektrum priamo z hodnôt č.r. pomocou výberovej autokovariančnej funkcie \(\hat\gamma(k)\): \[
\hat f(\omega) = \frac1{2\pi} \sum_{k=-(n-1)}^{n-1}\hat\gamma(k) e^{-i k\omega}, \qquad \omega\in[-\pi,\pi].
\] V tomto vzorci je \(\omega\) spojitá premenná, preto funkciu \(\hat f(\omega)\) nazývame spojité výberové spektrum. Alternatívne je možné ju vypočítať z
\[
\hat f(\omega) = \frac1{2\pi} \left( \hat\gamma(0) + 2 \sum_{k=1}^{n-1}\hat\gamma(k) \cos(k\omega) \right)
\]
V praxi však uvažujeme \(\hat f(\omega)\) len na diskrétnej množine Fourierových frekvencií \(\omega_j=\frac{2\pi j}{n}\) pre \(j=0,1,\ldots,n-1\). Funkciu \(\hat f(\omega_j)\) pre \(j=0,1,\ldots,n-1\) nazývame diskrétne výberové spektrum, a môžeme ho vypočítať pomocou vzťahu \[ \hat f(\omega_j) = \frac{1}{2\pi\ n} \left|\sum_{t=1}^{n}y_t e^{i t \omega_j} \right|^2 \] Aj diskrétne výberové spektrum je reálna párna funkcia s periódou \(2\pi\), preto ho stačí skúmať na intervale \([0,\pi]\), teda pre \(j<\frac{n-1}2\).
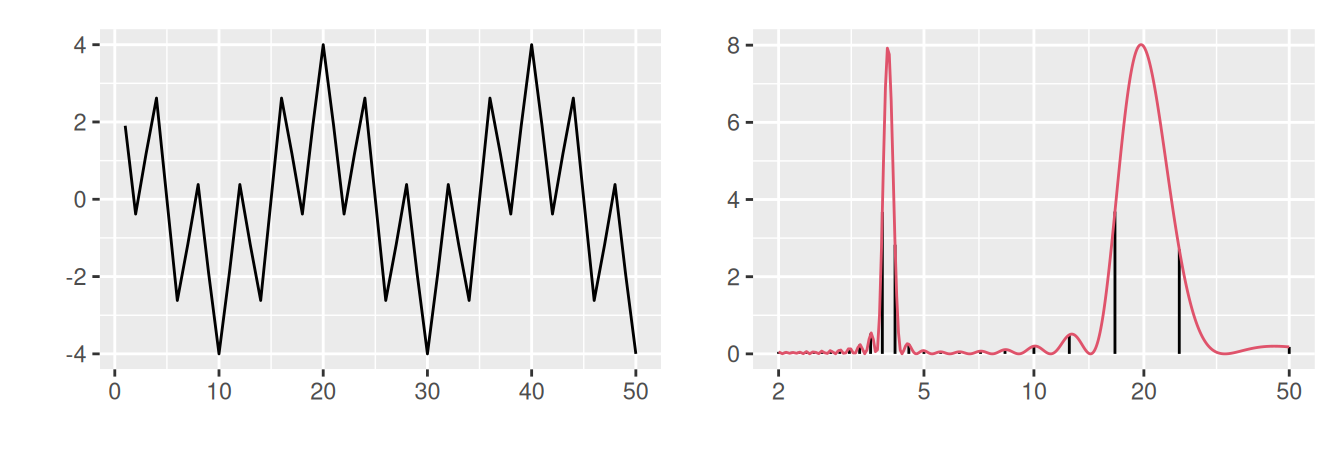
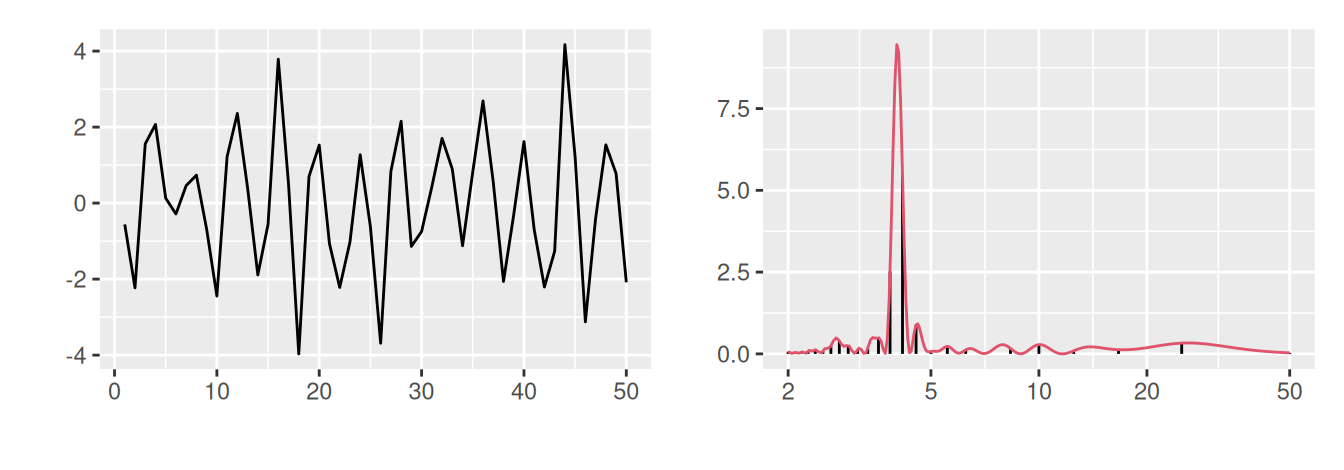
Graf výberového spektra sa nazýva periodogram, pozri Obr. 2.8 pre ilustráciu spojitej a diskrétnej spektrálnej hustoty štyroch rôznych časových radov.
# sample data
n <- 50
set.seed(123)
dat <- data.frame(index = 1:n) |>
dplyr::mutate(signal1 = 2 * cos(2 * pi * index / 4),
signal2 = 2 * cos(2 * pi * index / 20),
signal12 = signal1 + signal2,
noise = rnorm(n),
signal1noise = signal1 + noise
)
# discrete sample spectrum
fspectrum <- function(x) {
n <- length(x)
(abs(fft(x)[seq(1,n/2)+1])^2) / (2*pi*n) # fourier spectrum without 1st value
}
specD <- dat |>
dplyr::reframe(across(-index, fspectrum),
period = n / seq(1, floor(n/2))
)
# continuous spectrum
fdens <- Vectorize(
FUN = function(omega, x) (abs(sum(x*exp(1i*(1:n)*omega)))^2)/(2*pi*n),
vectorize.args = "omega"
)
period <- seq(2, n, length.out = 1000)
specC <- dat |>
dplyr::reframe(across(-index, ~fdens(2*pi/period, .x)),
period = period
)
rm(period) # the above does not work in local() due to reframe envir
# check consistency:
# cbind.data.frame(period = specD$period,
# fdens = fdens(2*pi/specD$period, dat$signal1) |> round(2),
# fspec = specD$signal1 |> round(2)
# )
# plot
# signal (L=4)
p1 <- ggplot(dat) + aes(x = index, y = signal1) + geom_line() +
labs(x = "", y = "", title = "time series")
p2 <- ggplot() + aes(x = period) +
geom_linerange(aes(ymax = signal1), data = specD, ymin = 0) +
geom_line(aes(y = signal1), data = specC, color = 2) +
labs(x = "", y = "", title = "spectrum") +
scale_x_log10(breaks = c(2,5,10,20,50))
p1 + p2
# signal (L=4, L=20)
p1 <- ggplot(dat) + aes(x = index, y = signal12) + geom_line() +
labs(x = "", y = "")
p2 <- ggplot() + aes(x = period) +
geom_linerange(aes(ymax = signal12), data = specD, ymin = 0) +
geom_line(aes(y = signal12), data = specC, color = 2) +
labs(x = "", y = "") +
scale_x_log10(breaks = c(2,5,10,20,50))
p1 + p2
# signal (L=4) + noise N(0,1)
p1 <- ggplot(dat) + aes(x = index, y = signal1noise) + geom_line() +
labs(x = "", y = "")
p2 <- ggplot() + aes(x = period) +
geom_linerange(aes(ymax = signal1noise), data = specD, ymin = 0) +
geom_line(aes(y = signal1noise), data = specC, color = 2) +
labs(x = "", y = "") +
scale_x_log10(breaks = c(2,5,10,20,50))
p1 + p2
# noise N(0,1)
p1 <- ggplot(dat) + aes(x = index, y = noise) + geom_line() +
labs(x = "index", y = "")
p2 <- ggplot() + aes(x = period) +
geom_linerange(aes(ymax = noise), data = specD, ymin = 0) +
geom_line(aes(y = noise), data = specC, color = 2) +
geom_hline(yintercept = 1/(2*pi), linetype = 3) +
annotate("text", hjust = "center", vjust = "bottom", x = 50-0.2, y = 1.1 * 1/(2*pi),
label = "frac(sigma, 2 * pi)", parse = TRUE) +
labs(x = "period", y = "") +
scale_x_log10(breaks = c(2,5,10,20,50))
p1 + p2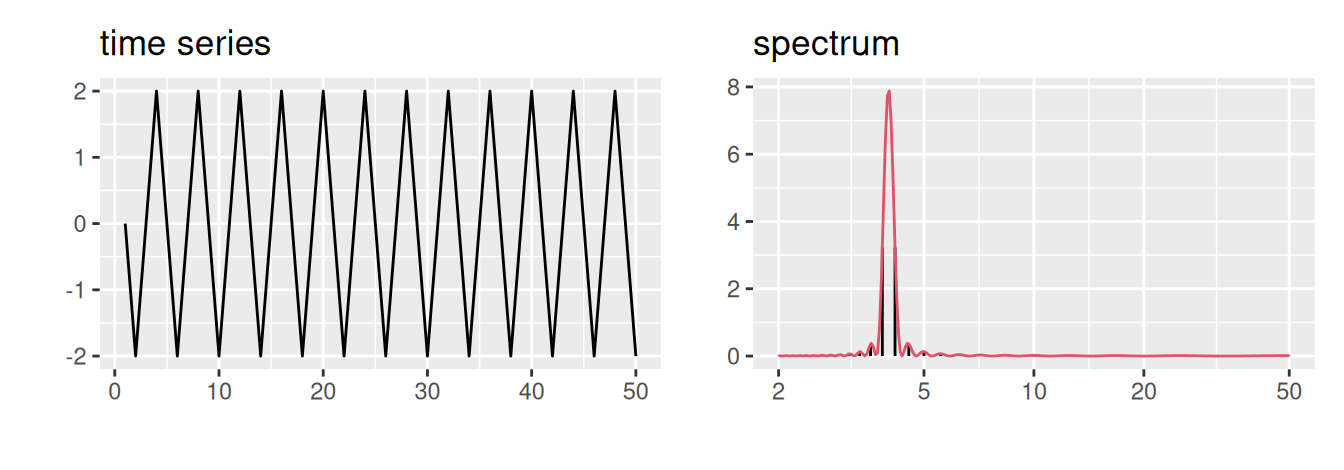
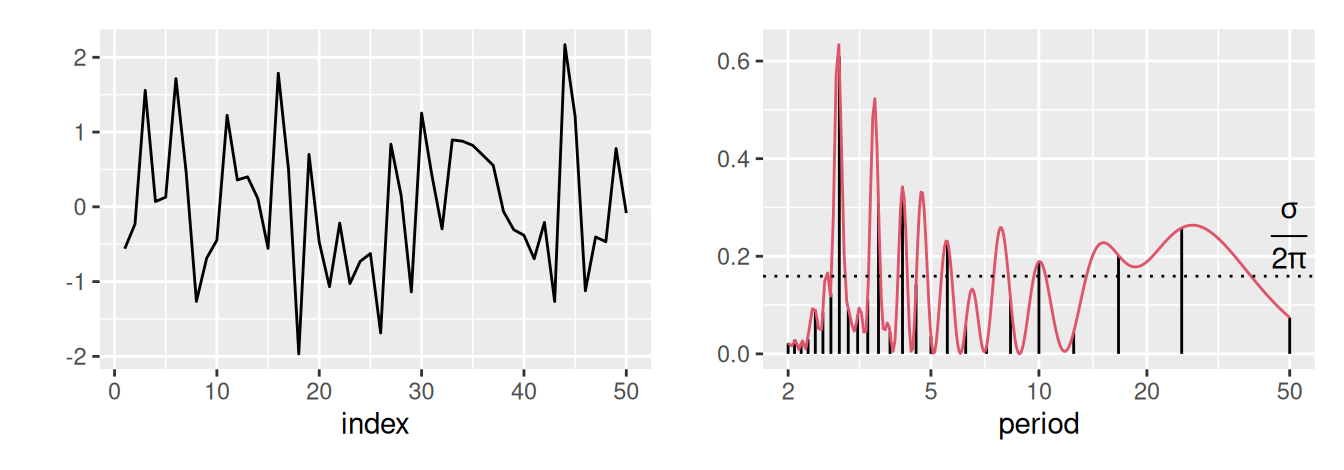
Predpokladajme, že stochastický proces \(\{y_t\}_{t=1}^n\) môžeme vyjadriť ako súčet cyklickej zložky \(C_t\) a bieleho šumu \(\varepsilon_t \sim N(0,\sigma^2)\), teda v tvare \[ \begin{split} y_t &= C_t + \varepsilon_t, \\ \text{kde }\quad C_t &= \sum_{j=1}^r \left( \beta_{1j} \, \cos(\omega_j \, t) + \beta_{2j} \, \sin(\omega_j \, t) \right), \end{split} \tag{2.2}\] \(t = 1,\ldots,n\) je časový index a množinu \(\{\omega_j\}_{j=1,\ldots,r}\) tvoria navzájom rôzne (neznáme) frekvencie z intervalu \((0,\pi)\) pre \(r\) periodických zložiek obsiahnutých v časovom rade.
Postup pri určení významných frekvencií je nasledovný:
Významné frekvencie napokon použijeme v regresnej analýze na určenie cyklickej zložky.
Jeden z historicky prvých testov významnosti bol Fisherov testov periodicity, v ktorom testovaná hypotéza \(H_0\colon y_t=\varepsilon_t\) stojí oproti alternatíve (2.2), t.j. predpokladáme, že č.r. neobsahuje žiadnu periodickú zložku a je priamo rovný procesu bieleho šumu \(\varepsilon_t\) s rozdelením \(N(0,\sigma^2)\). Testovacie štatistiky sú založené na hodnotách diskr. výberového spektra č.r., postupujeme nasledovne:
Ak pomocou Fisherovho testu zistíme významnú frekvenciu \(\omega_k\), môžeme testovať významnosť ďalšej veľkej hodnoty výberového spektra tak, že vynecháme hodnotu \(\hat{f}(\omega_k)\) a s ostatnými hodnotami pokračujeme analogicky ako v predchádzajúcom prípade, avšak pre \(m - 1\) hodnôt. Test ukončíme, keď dostaneme prvú frekvenciu, ktorá už nebude štatisticky významná.
Po odfiltrovaní systematických zložiek zo skúmaného časového radu dostávame rezíduá \(u_1,\ldots,u_n\) ako realizácie stacionárneho stochastického procesu \(\{u_t\}_{t=1,\ldots,n}\), ktorý však ešte stále nemusí tvoriť biely šum. Hypotézu o náhodnosti reziduálnej zložky, teda \(H_0\): \(u_t=\varepsilon_t\) oproti \(H_1\): \(u_t\neq \varepsilon_t\) môžeme formálne overiť testami náhodnosti (pozri napr. Cipra (1986) a Cipra (2008)):
Testy založené na znamienkach diferencií a koeficientoch konkordancie sa odporúčajú pri podozrení z existencie lineárneho trendu (t.j. systematického posunu nahor či nadol), zatiaľčo testy vychádzajúce z bodov zvratu či zo skupín okolo mediánu sú vhodné skôr pri podozrení zo zmien periodického charakteru.
Predpokladajme stacionárny stochastický proces \(\{u_t\}\) s vlastnosťami \(E(u_t) = 0\), \(E(u_t u_{t+k}) \neq 0\) pre \(k \neq 0\), taký že \[ u_t=\rho \, u_{t-1}+\varepsilon_t\ , \] kde \(\rho\) je neznámy parameter (tzv. koeficient autokorelácie), pre ktorý platí \(-1 < \rho < 1\) 1 a \(\varepsilon_t\) je náhodný člen, pre ktorý platí \(E(\varepsilon_t) = 0\), \(var(\varepsilon_t) = \sigma_\varepsilon^2\), \(\varepsilon_t \sim N(0, \sigma_\varepsilon^2 )\), \(E(\varepsilon_t \varepsilon_{t+k}) = 0\), \(E(\varepsilon_t \, u_{t-1}) = 0\).
Potom testujeme \(H_0\colon \rho = 0\ \) oproti \(H_1\colon \rho \neq 0\). Testovacia štatistika (pre \(n > 15\)) \[ DW=\frac{\sum_{t=2}^n (u_t-u_{t-1})^2}{\sum_{t=1}^n u_t^2} \] má rozdelenie pravdepodobnosti tabuľkované pre k (počet parametrov modelu systematických zložiek) a n (rozsah súboru). Vždy nadobúda hodnoty od 0 po 4.
Vypočítanú hodnotu D-W testu porovnáme s dolnou (\(d_L\)) a hornou (\(d_U\)) hranicou, ktoré nájdeme v tabuľkách na internete 2 (pre príslušný počet pozorovaní a parametrov) a podľa Obr. 2.9 (a) buď \(H_0\)
# reduce plot margins
old <- par(mar = c(3,2,1,1))
# Durbin-Watson
curve(dnorm(x, 0,1), xlim=c(-3,3), xaxt='n', yaxt='n', ann=F)
dL <- -1.8; dU <- -1.2
axis(1, at=c(-3, dL,dU, 0, -dU, -dL, 3), labels=c(0,"dL","dU", 2, "4-dU","4-dL", 4), cex.axis=0.8)
coord <- data.frame(
x = c(dL, seq(dL,dU,0.02), dU),
y = c(0, dnorm(seq(dL,dU,0.02)), 0)
)
polygon(coord$x, coord$y, col=gray(.8))
polygon(- coord$x, coord$y, col=gray(.8))
text(x=c(0, dL-0.4,-(dL-0.4), (dL+dU)/2,-(dL+dU)/2),
y=c(dnorm(0)/2, dnorm(dL-0.4)/2, dnorm(dL-0.4)/2, dnorm((dL+dU)/2)/2, dnorm((dL+dU)/2)/2),
labels=c(paste("H0 \n non-rejection region "), "H1", "H1", ": /", ": /")
)
# other
coord <- data.frame(
x = c(-2, seq(-2, 2, 0.02), 2),
y = c(0, dnorm(seq(-2, 2, 0.02)), 0)
)
curve(dnorm(x, 0,1), xlim=c(-3,3), xaxt='n', xlab = "test statistic",
ylab = expression("density function of N("*mu*","*sigma*")")
)
axis(1, at=c(-2, 0, 2), labels =
c(expression(mu - 2*sigma), expression(mu), expression(mu + 2*sigma)),
cex.axis=0.8)
polygon(coord$x, coord$y, col=gray(.9))
text(x = c(0, 0), labels = c("95%", "H0 non-rejection region"),
y = c(0.2, 0.05))
# reset graphical parameters
par(old)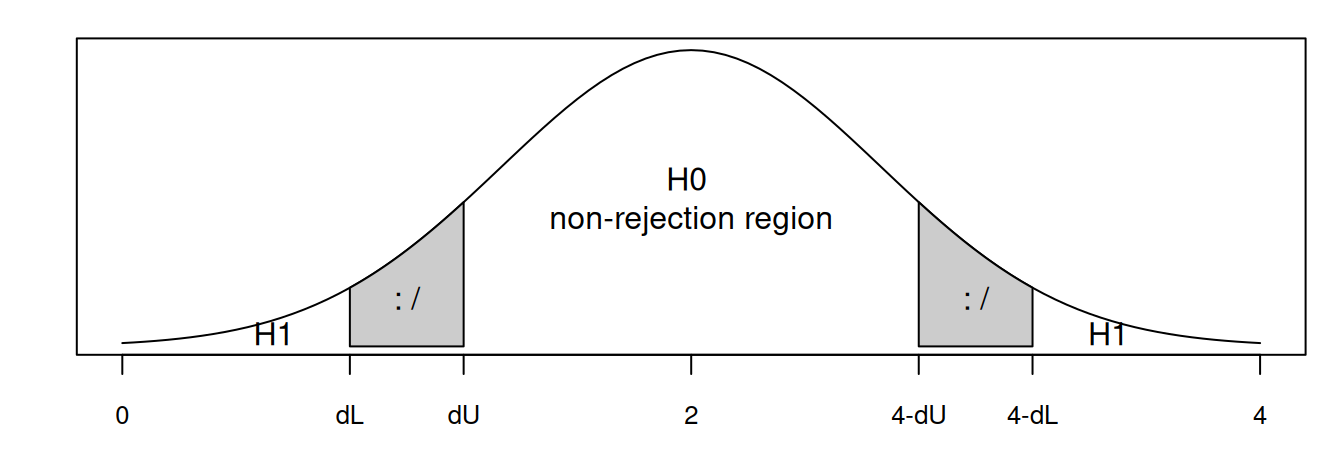
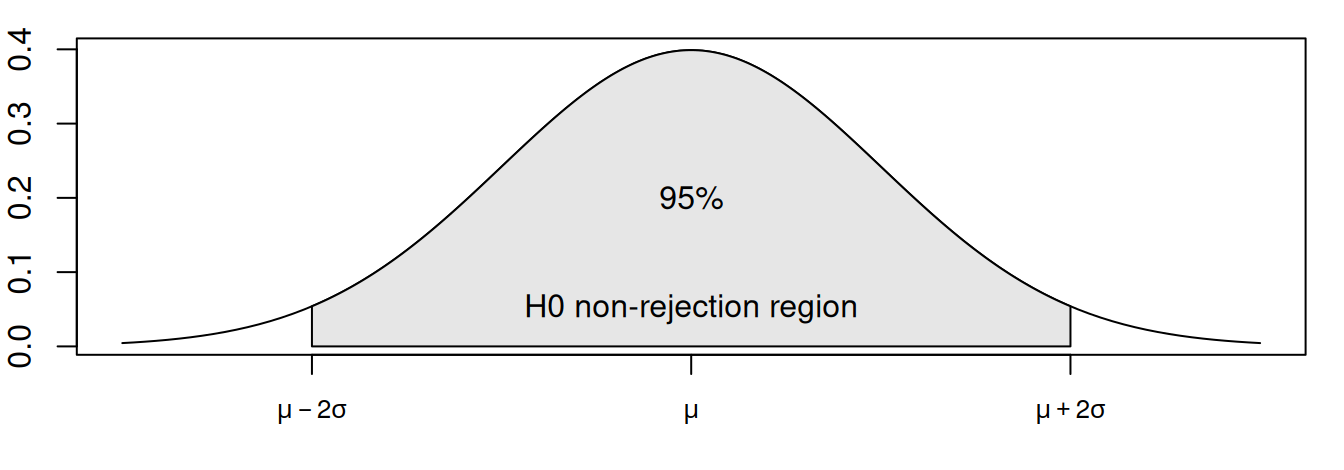
Nulovú hypotézu \(H_0\colon \rho(k)=0\), \(\forall k>0\), na hladine významnosti 5% zamietame, ak \(|\hat\rho(k)| > 2\ \sigma(r_k)\), kde \(\sigma_{\rho(k)}\approx\sqrt{\frac1n}\). V opačnom prípade považujeme časový rad za realizáciu navzájom nekorelovaných rovnako rozdelených náhodných premenných.
Test je založený na počte kladných prvých diferencií daného časového radu \(u_1,..., u_n\), t.j. na počte bodov, v ktorých časový rad rastie. Ak sú niektoré susedné hodnoty rovnaké, potom ich až na jednu z časového radu vynecháme.
Definujme náhodnú premennú \(P_t\) predpisom \(P_t=\begin{cases} 1 & u_{t-1}<u_t \\ 0 & u_{t-1}>u_t \end{cases}\), pričom zjavne \(E(P_t)=\frac{1}{2}\), a \(var(P_t)=E(P_t^2)-E(P_t)^2=\frac{1}{2}-\frac{1}{4}=\frac{1}{4}\). Označme počet kladných prírastkov \(P = \sum_{t=2}^n P_t\), ktorého stredná hodnota \(E(P)=\frac{n-1}{2}\), a disperzia sa vypočíta pomocou vzťahu \(var(P) = var\left(\sum_{t=2}^n P_t\right) = \sum_{t=2}^n var(P_t) + 2 \sum_{t=2}^n cov(P_t,P_{t+1})\).
Je zrejmé, že \(cov(P_t,P_{t+k})=0\) pre \(k>2\) (pretože porovnávame len \(u_{t-1}\) s \(u_t\)), no pre \(k=1\) po názornom rozpísaní dostaneme\(cov(P_t,P_{t+1}) = E(P_{t}P_{t+1}) - E(P_{t})\cdot E(P_{t+1}) = (1\cdot\frac16+0\cdot\frac56)-\frac12\cdot\frac12=-\frac1{12}\). Potom disperzia \(var(P)=(n-1)\frac14+2(n-2)(-\frac1{12})=\frac{3(n-1)-2(n-2)}{12}=\frac{n+1}{12}\).
Náhodná premenná \(P\) má za podmienky platnosti \(H_0\) asymptoticky normálne rozdelenie, takže vyhodnotenie testu je jednoduché, pozri Obr. 2.9 (b), pričom \(\mu=E(P)\) a \(\sigma=\sqrt{var(P)}\). Analogicky sa vyhodnotia aj nasledujúce testy.
Koeficienty konkordancie alebo poradovej korelácie sú miery zhody v náraste alebo poklese poradí hodnôt dvoch náhodných premenných. Najznámejšie sú Spearmanov \(\rho_S\) a Kendallov \(\rho_K\) koeficient.
Testy založené na týchto koeficientoch sú veľmi podobné, vychádzajú z testovacej štatistiky \(TS=\frac{\rho-E(\rho)}{\sqrt{var(\rho)}}\), ktorá má asymptoticky za predpokladu platnosti \(H_0\) normované normálne rozdelenie N(0,1), teda vyhodnotenie testu je podobné ako pri ostatných testoch náhodnosti: \(H_0\) zamietame ak \(|TS|\) prekročí (\(1-\frac{\alpha}2\))-kvantil hypotetického rozdelenia \(TS\).
Spearmanov koeficient je definovaný vzťahom \(\rho_S = 1-\frac{6}{n (n^2-1)}\sum_{i=1}^n (i-q_i)^2\), kde \(q_i\) označuje poradie (angl. rank) hodnoty č.r. \(u_i\) (t.j. index v súbore usporiadanom podľa veľkosti). Potom, ak platí \(H_0\), platí aj \(E(\rho_S)=0\) a \(var(\rho_S)=\frac{1}{n-1}\). V prípade rovnakých hodnôt (angl. ties) v súbore, napr. \(u=\{5, 1, -2, 1\}\) sa poradia zvyknú pridelovať postupne \(q=\{4, 2, 1, 3\}\) alebo sa priemerujú \(q=\{4, 2.5, 1, 2.5\}\).
Kendallov koeficient dostaneme zo vzťahu \(\rho_K = \frac{4a}{n(n-1)}-1\), kde \(a\) je počet takých dvojíc \(u_s\) a \(u_t\), že \(u_s<u_t\) pre \(s<t\), a potom za predpokladu \(H_0\) platí \(E(\rho_K)=0\) a \(var(\rho_K)=\frac{2(2n+5)}{9n(n-1)}\).
Test je v zahraničnej literatúre známy ako turning point test. Tak ako pri znamienkovom teste sa pred jeho aplikovaním z časového radu vynechajú duplicitné susedné hodnoty (t.j. iba tie v slede za sebou).
Bod \(u_t\) nazveme bodom zvratu, ak \(u_{t-1} < u_t > u_{t+1}\) (tzv. horný kritický bod), resp. \(u_{t-1} > u_t < u_{t+1}\) (tzv. dolný kritický bod). Definujme náhodnú premennú \(M_t\) predpisom: \[ M_t=\begin{cases} 1 & \text{ak } u_{t-1} < u_t > u_{t+1} \text{ alebo } u_{t-1} > u_t < u_{t+1} \\ 0 & \mbox{ inak} \end{cases} \] potom (podobne ako v teste založenom na znamienkach diferencií) možno ukázať, že \(E[M_t]=\frac{2}{3}\) a \(var(M_t)=\frac{2}{9}\).
Celkový počet kritických bodov v časovom rade bude \(M=\sum_{t=2}^{n-1} M_t\) a za predpokladu \(H_0\) má \(M\) asymptoticky normálne rozdelenie s parametrami \(E(M)=\frac{2(n-2)}{3}\), \(var(M)=\frac{16n-29}{90}\).
Postup je taký, že 1.) vypočítame výberový medián \(Me\), 2.) vylúčime všetky pozorovania, ktorých hodnota je rovná mediánu, 3.) ostatné pozorovania združíme do skupín tak, že všetky pozorovania v danej skupine ležia buď nad priamkou \(u_t=Me\) alebo pod ňou. Označme \(P\) počet týchto skupín a \(m\) celkový počet pozorovaní pod priamkou (alebo ekvivalentne nad priamkou).
Hypotézu \(H_0\) nezamietame na hladine významnosti \(\alpha\), keď pre normovanú náhodnú premennú \(Z=\frac{P-(m+1)}{\sqrt{m*(m-1)/(2m-1)}}\) platí \(z_{\frac{\alpha}{2}} < Z < z_{1-\frac{\alpha}{2}}\), kde \(z_{\frac{\alpha}{2}}\) a \(z_{1-\frac{\alpha}{2}}\) sú kvantily N(0,1). Pritom zjavne \(P\gg E(P)\) (príliš prekračujúce) značí príliš časté oscilácie \(u_t\) okolo mediánu a \(P\ll E(P)\) zas príliš zriedkavé (\(u_t\) sa priveľmi zdržuje na jednej strane od mediánu).
Časový rad \(\{1.6,0.8,1.2,0.5,0.9,1.1,1.1,0.6,1.5,0.8,0.9,1.2,0.5,1.3,0.8,1.2\}\) dĺžky \(n=16\) je mediánom \(Me=1\) rozdelený na \(m=8\) pozorovaní nad a \(m\) pozorovaní pod mediánom \(Me=1.0\). Počet skupín s rovnakým znamienkom je \(P=13\), pozri Obr. 2.10.
Potom \(Z=|13-(8+1)|/\sqrt{8(8-1)/(16-1)}=2.07>1.96\) a tak na hladine významnosti \(5\%\) zamietame \(H_0\). Časový rad teda nie je realizáciou bieleho šumu.
dat <- data.frame(
U = c(1.6,0.8,1.2,0.5,0.9,1.1,1.1,0.6,1.5,0.8,0.9,1.2,0.5,1.3,0.8,1.2)
) |>
tibble::rowid_to_column(var = "index") |>
dplyr::mutate(above = ifelse(U > median(U), 1, -1),
change = diff(above) |> as.logical() |> c(FALSE),
mid = index + 1/2
)
ggplot(dat) +
geom_point(aes(x = index, y = U, color = above), show.legend = FALSE) +
geom_hline(yintercept = median(dat$U), linetype = 2) +
geom_vline(aes(xintercept = mid),
data = function(x) dplyr::filter(x, change),
linetype = 3)
# randtests::runs.test(U, plot=T)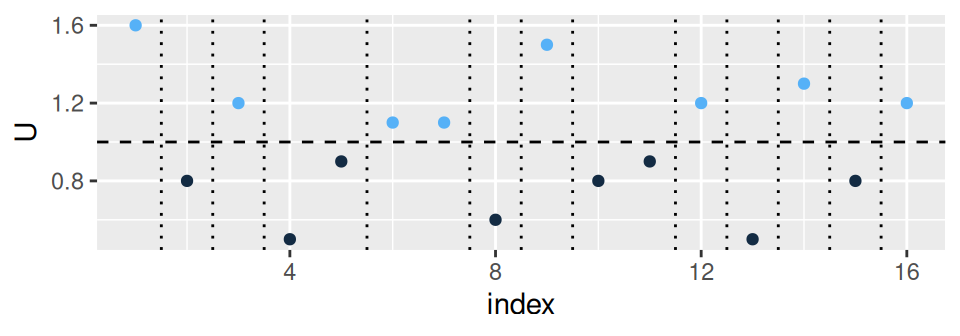
Pre \(\rho>1\) by náhodné poruchy s časom geometricky narastali, pre \(\rho<-1\) okrem geom. nárastu aj oscilovali, a tak by vplyv náhodných porúch prevyšoval deterministickú zložku.↩︎
Napr. v súbore https://www3.nd.edu/~wevans1/econ30331/Durbin_Watson_tables.pdf↩︎