Umelé neurónové siete (ANN, Artificial Neural Network) sú populárne vďaka tomu, že dokážu aproximovať takmer ľubovoľnú nelineárnu funkciu a s ľubovoľnou presnosťou. Ak sa aplikujú na časové rady s nelineárnou dynamikou, dokážu ju detekovať a prekonať popisnú schopnosť lineárnych hmodelov bez nutnosti špecifikovať konkrétnu nelineárnu funkciu. Na druhej strane, ich nevýhodou je veľmi náročná a často až nemožná interpretácia parametrov modelu, odhadnutá neurónová sieť sa nedá použiť na identifikáciu typu nelinearity, aby sa dal použiť niektorý zo špecifických parametrických modelov; preto sa ANN modely zvyknú označovať ako čierna skrinka (black box) a aplikujú sa najmä v oblasti rozpoznávania vzorov v objemných dátach (pattern recognition) a na predpovedanie. Dobré popisné schopnosti (in-smaple fit) však nezaručujú aj kvalitné predpovede (out-of-sample fit), práve naopak, prehnane komplexné modely so sebou prinášajú riziko, že okrem predpovedateľnej zložky (signál) sa v pozorovaniach snažia modelovať aj tú nepredpovedateľnú (šum), tzv. overfitting.
Kapitola je po teoretickej stránke spracovaná prevažne podľa (Franses a Van Dijk 2000). Keďže interpretačné hladisko modelov považujeme za dôležité (najmä pri štatistických modeloch), začneme prepojením na viacrežimové modely.
11.1 Od STAR ku ANN
Majme STAR model vo forme \[
X_t = \varphi_{1,0} + (\varphi_{2,0} - \varphi_{1,0})G(\gamma[X_{t-1}-c]) + \varepsilon_t
\] kde \[
G(x)=\frac1{1+exp(-x)}
\] je logistická funkcia. Takýto model vystihuje proces, v ktorom podmienená stredná hodnota \(X_t\) závisí od rozdielu prahovej premennej \(X_{t-1}\) a prahovej hodnoty \(c\) a mení sa spojite od \(\varphi_{1,0}\), ak \(X_{t-1}\ll c\), až po \(\varphi_{2,0}\) pre \(X_{t-1}\gg c\).
Ak teraz zavedieme predpoklad, že táto podmienená stredná hodnota závisí od rozdielu lineárnej kombinácie \(p\) oneskorených hodnôt \(\tilde Y_t=(X_{t-1},\ldots,X_{t-p})\) voči \(c\), dostávame \(X_t = \varphi_{1,0} + (\varphi_{2,0} - \varphi_{1,0})G(\gamma[\delta'\tilde Y_t-c]) + \varepsilon_t\), jednoduchý model umelej neurónovej siete, ktorý preparametrizovaním možno zapísať ako \[
X_t = \beta_0 + \beta_1 G(\gamma_1'Y_t) + \varepsilon_t\ ,
\] kde \(Y_t=(1,\tilde Y_t')'\) a prvky vektora \(\gamma_1=(\gamma_{1,0},\ldots,\gamma_{1,p})'\) možno ľahko vyjadriť pomocou \(\gamma,\delta,c\). Takýto ANN model sa teda dá interpretovať ako model s premenlivými režimami a prepínanie medzi nimi je určené lineárnou kombináciou premenných vlastného procesu. Ako sme však už spomenuli, neurónové siete sa zväčša neaplikujú s ohľadom na intepretáciu, ale aby dobre popísali potenciálne nelineárny vzťah medzi odozvou \(X_t\) a prediktormi \(Y_t\). To sa dosahuje pridaním ďalších zložiek s logistickými funkciami \[
X_t = \beta_0 + \sum_{j=1}^q \beta_j G(\gamma_j'Y_t) + \varepsilon_t
\tag{11.1}\]
Ilustrácia (jeden vstup)
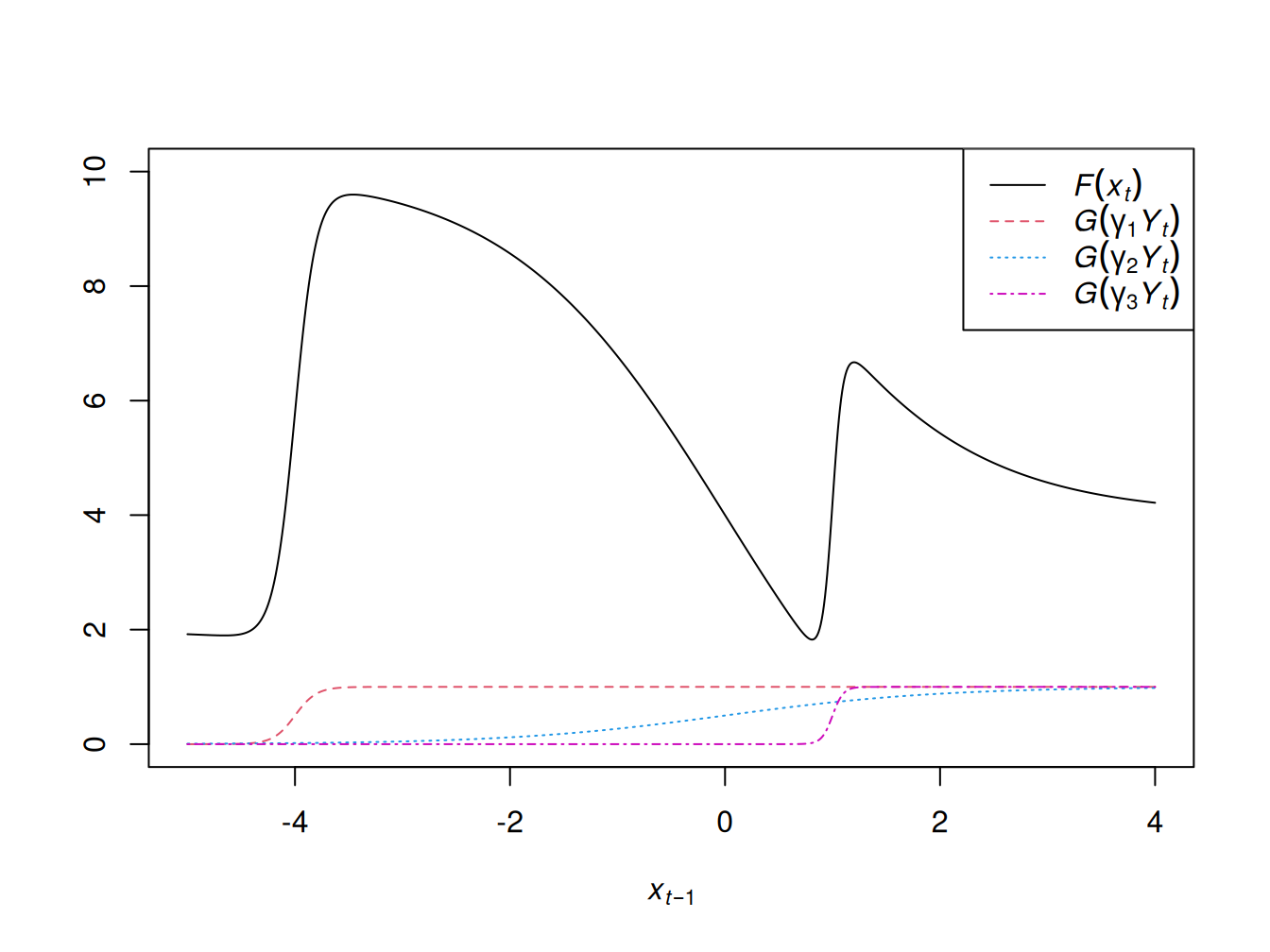
Pre ilustráciu nech \(p=1\), \(q=3\), \(\beta_0=2\), \(\beta=(8,-12,6)'\), \(\gamma_1=(40,10)\), \(\gamma_2=(0,1)\) a \(\gamma_3=(-20,20)\), potom na Obr. 11.1 sú zobrazené funkcie \(G(\gamma_j'Y_t)\) a skeleton \(F(X_t;\theta)=\beta_0 + \sum_{j=1}^q \beta_j G(\gamma_j'Y_t)\) modelu. Vidno ako pre nízke hodnoty \(X_{t-1}\) sú všetky logistické funkcie rovné nule a \(F(X_t;\theta)=\beta_0\). Ďalej, okolo bodu \(X_{t-1}=-4\) sa pomerne rýchlo aktivuje prvá logistická funkcia \(G(10[4+X_{t-1}])\), narastie z 0 na 1 a s ňou aj skeleton v miere, akú určuje parameter \(\beta_1=8\). Zároveň pomaly začína rásť druhá logistická funkcia \(G(1[0-X_{t-1}])\) a postupne stláča skeleton dole (pretože \(\beta_2=-12\)), až kým nie je aktivovaná tretia logistická funkcia opäť s pozitívnou magnitúdou \(\beta_3=6\). Skeleton sa napokon pre veľké \(X_{t-1}\) ustáli na strednej hodnote \(\sum_{j=0}^4\beta_j=4\).
Obrázok 11.1: Skeleton a prechodové funkcie ANN modelu s jediným vstupom.
Z uvedeného príkladu je vidieť, že skeleton ANN modelu sa ako funkcia argumentu \(X_{t-1}\) mení podľa toho, ako sa menia hodnoty funkcií \(G\), a pridávaním ďalších takých komponentov by sa jeho flexibilita len zvyšovala, takže by dokázal aproximať ľubovoľný nelineárny vzťah medzi vstupom \(X_{t-1}\) a výstupom \(X_t\).
Ilustrácia (dva vstupy)
Zovšeobecnenie na komplikovanejšiu sieť si môžme ukázať na príklade s dvoma vstupmi a štyrmi logistickými funkciami, ako na Obr. 11.2, keď \(Y_t=(1,X_{t-1},X_{t-2})'\), \(\gamma_1=(0,-10,10)'\) atď. V nej prvá lineárna kombinácia \(\gamma_1'Y_t\) rozdeluje priestor \(Ran(X_{t-1})\times Ran(X_{t-2})\) na dva režimy: jeden, pre ktorý \(\gamma_{1,1}X_{t-1}+\gamma_{1,2}X_{t-2}\leq -\gamma_{1,0}\), takže \(G(\gamma_1'Y_t)<1/2\) (a v prípade rýchleho prechodu \(G(\gamma_1'Y_t)\approx0\)), a druhý režim, pre ktorý \(\gamma_{1,1}X_{t-1}+\gamma_{1,2}X_{t-1}\geq -\gamma_{1,0}\), čiže \(G(\gamma_1'Y_t)>1/2\) (a v prípade \(||(\gamma_1)_{-1}||\gg0\) prakticky \(G(\gamma_1'Y_t)\approx1\)). Spolu so zvyšnými tromi kombináciami rozdelí priestor na 10 oblastí-režimov, na obrázku indikovaných štvoricou \((G_1,G_2,G_3,G_4)\), kde \(G_i\) značí hodnotu \(G(\gamma_i'Y_t)\) pri dokonale skokovitom prechode.
Obrázok 11.2: Delenie priestoru prediktorov \(X_{t-1},X_{t-2}\) podľa aktivácie logistických funkcií s extrémnymi hodnotami \((G_1,G_2,G_3,G_4)\).
V praktických aplikáciách sa ANN tvaru (11.1) zvykne rozšíriť o lineárny člen \(\Phi'\tilde Y_t\), \[
\begin{split}
X_t = \beta_0 + \Phi'\tilde Y_t + \sum_{j=1}^q \beta_j G(\gamma_j'Y_t) + \varepsilon_t \\
\text{kde} \qquad Y_t=(1,\tilde Y_t')',\qquad \tilde Y_t=(X_{t-1},\ldots,X_{t-p})'
\end{split}
\tag{11.2}\] čo síce nie je potrebné z hľadiska aproximácie, zato však uľahčuje intepretáciu modelu, pretože umožňuje vyhodnotiť, do akej miery je vzťah vstupov a výstupu lineárny a do akej miery nelineárny. Model (11.1) budeme značiť \(ANN_n(p,q)\), model (11.2) zas \(ANN_{ln}(p,q)\).
V nasledujúcej podkapitole prepojíme spomínané modely s terminológiou používanou pri umelých neurónových sieťach.
11.2 Terminológia neurónových sietí
Názvoslovie ustálené v prácach o umelých neurónových sieťach je z historických dôvodov odlišné od toho štatistického, pre podrobnejší prehľad o vzniku, motivácii, delení a spôsoboch konštrukcie ANN odporúčame napr. slovenskú publikácu (Kvasnička et al. 1997). V tejto terminológii (neurónová) sieť pozostáva z troch rôznych vrstiev (layers). Prvá je vstupná vrstva pozostávajúca z uzlov (neurónov), ktoré reprezentujú vysvetľujúce premenné, v našom prípade endogénne, \(X_{t-1},\ldots,X_{t-p}\), prípadne fixný absolútny člen 1, a ktoré sa často nazývajú jednoducho vstupy (inputs).1 Signál z týchto vstupov je následne v \(q\) neurónoch skrytej vrstvy (hidden layer) násobený tzv. silou prepojenia (synapsie), ide o váhu \(\gamma_{j,i}\) z \(i\)-teho vstupu do \(j\)-teho neurónu, \(i=0,\ldots,p\), \(j=1,\ldots,q\). Takto lineárne skombinované vstupy sa v každom neuróne skrytej vrstvy spracujú nelineárnou funkciou \(G\) nazývanou aktivačná, napríklad logistická (sigmoid), ktorá prevedie vstup do intervalu \([0,1]\), čo tvorí výstup neurónu.2 Nakoniec sa výstupy neurónov skrytej vrstvy pomocou váh \(\beta_0, \beta_1, \ldots, \beta_q\) lineárne skombinujú do výstupu, v našom prípade \(X_t\). Takýto typ siete sa nazýva jednovrstvová dopredná sieť (single hidden layer feedforward network), pretože je prítomná iba jedna skrytá vrstva a informácia tečie jedným smerom - od vstupov ku výstupu, pozri príklad \(ANN_n(3,2)\) na Obr. 11.3.
Obrázok 11.3: Dopredná neurónová sieť s jednou skrytou vrstvou \(ANN_n(3,2)\)
Hoci sa model dá ďalej zovšeobecniť pridaním skrytých vrstiev a/alebo umožnením spätnej odozvy (teda tokom informácie aj naspäť), jednovrstvové dopredné siete sú z ANN modelov v štatistickej analýze (časových radov) využívané najviac. Sú schopné absorbovať napr. aj abnormálne, odľahlé pozorovania (outliers) či trvalé zmeny v strednej hodnote (level shifts), pozri (Franses a Van Dijk 2000, Experiment 5.1).
11.3 Odhad parametrov
Parametre \(ANN_{ln}(p,q)\) sa dajú odhadnúť minimalizáciou štvorcov rezíduí \[
SSR(\theta)=\sum_{t=p+1}^n[x_t-F(\Omega_{t-1};\theta)]^2,
\] kde \(\theta=(\beta_0,\ldots,\beta_q,\gamma_1',\ldots,\gamma_q')'\) je \((p+1+q(p+2))\)-rozmerný vektor parametrov a \(F\) je skeleton modelu, čiže \(\hat\theta=\mathop{\operatorname{argmin}}_\theta SSR(\theta)\).3 Na nájdenie minima sa môže použiť ktorýkoľvek algoritmus nelineárnej metódy najmenších štvorcov, výpočet prebieha v iteráciách pomocou gradientu \[
\nabla SSR(\hat\theta^{(i)}) = \frac{\partial SSR(\theta)}{\partial\theta}\Bigg|_{\theta=\hat\theta^{(i)}}
\] a vzťahu \[
\hat\theta^{(i+1)} = \hat\theta^{(i)} - \lambda\ A(\hat\theta^{(i)})^{-1}\cdot\nabla SSR(\hat\theta^{(i)}),
\] kde \(\lambda\) je nejaký vhodný krok (tzv. learning rate koeficient) a ako matica \(A(\cdot)\) je napr. v Newton-Raphsonovom algoritme uvažovaná Hesova matica (matica druhých parciálnych derivácií). Veľmi populárnou metódou v ANN literatúre je tzv. gradient descent (alebo steepest descent) v ktorej \(A(\hat\theta^{(i)})=I\) a sleduje najstrmší pokles hodnôt účelovej funkcie. V kontexte ANN sa takýto iteračný odhad na základe minimalizácie chyby výstupu označuje ako metóda spätného šírenia chýb (backpropagation) a to znamená len toľko, že, zatiaľ čo výpočet skeletonu (vo vnútri účelovej funkcie) prebieha od vstupu k výstupu, reziduá v spätnej odozve spôsobia zmenu váh (parametrov) neurónovej siete. Postup pomocou účelovej funkcie \(SSR(\theta)\) používa na odhad v každej iterácii celú trénovaciu vzorku. Ak je však model zložitý, prípadne sú derivácie náročné na výpočet, alebo je trénovacia vzorka pomerne dlhá, vtedy sa použije tzv. rekurzívny odhad s účelovou funkciou \(SR_t(\theta)=[x_t-F(\Omega_{t-1};\theta)]^2\), čiže v každej iterácii sa na výstupe použije iba jedno pozorovanie, a keďže \(\nabla SR(\theta)=-2\nabla F(\Omega_{t-1};\theta)[x_t-F(\Omega_{t-1};\theta)]\) vzťah pre aktualizovaný odhad je \[
\hat\theta^{(t+1)} = \hat\theta^{(t)} + \lambda\nabla F(\Omega_t;\hat\theta^{(t))} [x_{t+1}-F(\Omega_t;\hat\theta^{(t)})], \qquad t=p+1,\ldots,n,
\] kde \(\hat\theta^{(t)}\) je odhad založený na prvých \(t\) pozorovaniach. Ak nebola dosiahnutá konvergencia, môže sa pokračovať od začiatku. Táto metóda sa nazýva stochastic gradient descent (alebo aj learning) a hoci je odhad menej efektívny (potrebuje viac pozorovaní na skonvergovanie), je podstatne rýchlejší. Metóda založená na \(SSR(\theta)\) je potom známa aj ako batch gradient descent (alebo batch learning). Ak je trénovacia vzorka nejak slušne (pravdepodobnostne) rozdelená, takže kratšie úseky dokážu poskytnúť dobrú aproximáciu gradientu, potom zaujímavým kompromisom sa ukazuje byť tzv. mini-batch gradient descent, kedy algoritmus iteruje po týchto úsekoch trénovacej vzorky časového radu.
Komplikácia nastáva, ak má účelová funkcia okrem globálneho minima aj jedno alebo niekoľko lokálnych, pretože odhad môže skonvergovať práve do jedného z nich. Preto sa šanca na nájdenie minima bežne zvyšuje opakovaním procedúry – zakaždým s inými počiatočnými hodnotami \(\hat\theta^{(0)}\). Tie sa môžu zistiť napr. pomocou Nelder-Meadovho simplexového algoritmu, ktorý dokáže rýchlo prehľadať veľkú časť priestoru parametrov.
Ďalšou metódou, ako zlepšiť numerické vlastnosti nelineárnej MNŠ, je transformácia hodnôt data setu, aby boli v porovnateľnej mierke, napríklad do intervalu [0,1] pomocou funkcie \(T(x)=\frac{x-\min(x)}{\max(x)-\min(x)}\), alebo štandardizácia na nulovú strednú hodnotu a jednotkovú smerodajnú odchýlku pomocou \(T(x)=\frac{x-\bar{x}}{\sigma_x}\). Toto má ešte väčší zmysel pri zaradení aj exogénnych náhodných premenných do modelu.
Je zjavné, že ANN vzhľadom na svoju aproximačnú povahu zvyknú rizikom overfitting-u trpieť viac než modely s dobrou interpretačnou vlastnosťou, najmä, keď je k dispozícii len malé množstvo pozorovaní. Overfitting dokážu optimalizačné metódy zmierniť troma spôsobmi:
náhodným odstraňovaním neurónov počas trénovania siete (pruning, dropout), ktoré môže znížiť neželanú koreláciu medzi váhami,
redukcia počtu parametrov pomocou \(L_1\)-regularizácie, vhodné najmä pri veľkom počte prediktorov,
tlmenie váh pomocou \(L_2\)-regularizácie.
Prvé dva spadajú skôr pod identifikáciu než pod odhad modelu, zmyslom tretieho je zabrániť jednotlivým parametrom - váham, aby “vybuchli” do prehnanej veľkosti. To sa dá efektívne dosiahnuť pridaním penalizujúceho člena do účelovej funkcie, takže \[
SSR^*(\theta) = \sum_{t=p+1}^n[x_t-F(\Omega_{t-1};\theta)]^2 + r_\varphi\sum_{i=1}^p\varphi_i^2 + r_\beta\sum_{j=0}^q\beta_j^2 + r_\gamma\sum_{j=1}^q\sum_{i=0}^p\gamma_{j,i}^2
\] a tlmiace koeficienty \(r_\varphi,r_\beta,r_\gamma\) (tzv. weight decay) by mali byť určené vopred (napr. \(r_\varphi=0.01\) a \(r_\beta=r_\gamma=0.001\)), pričom neslobodno zabudnúť na transformáciu vstupov a výstupu do porovnateľnej veľkosti, aby malo tlmenie váh zmysel.
11.4 Identifikácia a vyhodnotenie modelu
Vystavanie ANN modelu, či už (11.2) s lineárnou časťou alebo (11.1) bez nej, vyžaduje voľbu
aktivačnej funkcie \(G(\cdot)\),
počtu neurónov v skrytej vrstve \(q\),
počtu vstupov, resp. oneskorení \(p\) endogénnej premennej \(X_t\).
V praxi voľba \(G\) často padne na prednastavenú logistickú funkciu, hoci je na výber aj z iných, napr. \(G(x) = \tanh(z)\) sa občas tiež používa.
Na výber vhodných hodnôt hyperparametrov \(p,q\) je niekoľko rôznych stratégií. Jednou je použitie hrubej sily – odhadnutie modelov vo všetkých kombináciách \(p\in\{1,2,\ldots,p_{\max}\}\) a \(q\in\{1,2,\ldots,q_{\max}\}\) a výber súčasne \(p\) aj \(q\) minimalizáciou informačného kritéria ako napr. \(AIC=n\log(\hat\sigma_\varepsilon^2)+2k\) alebo \(BIC=n\log(\hat\sigma_\varepsilon^2)+k\log(n)\), kde opäť \(k=p+1+q(p+2)\). V alternatívnej, menej výpočtovo náročnej stratégii sa pomocou lineárneho modelu \(AR(p)\) zvolí najpr. vhodné \(p\) a potom pre dané \(p\) určí vhodné \(q\); tu je však riziko, že \(p\) bude príliš malé alebo príliš veľké, ako sme spomínali pri SETAR modeloch v Sekcia 8.5.
Situácia sa ešte komplikuje, ak má model obsahovať aj exogénne premenné s ich oneskorenými hodnotami. Vtedy je na mieste obzvlášť starostlivý výber vyvetľujúcich premenných na základe odbornej znalosti mechanizmu, ktorý generoval pozorovaný časový rad. Ak takou znalosťou nedisponujeme, prispôsobí sa niektorý z algoritmov používaných pri regresných modeloch, napr. step-wise, pri ktorom sa k základnému modelu postupne pridávajú (alebo z tzv. nasýteného modelu uberajú) vstupy resp. skryté neuróny a v jednom kroku sa ponechá len ten s najväčším príspevkom … až po krok, kedy už hodnota inf. kritéria ďalej neklesá.
Modernejšie postupy ako napr. v predošlej kapitole spomínaná \(L_1\) regularizácia alebo náhodné odstraňovanie elementov modelu sú implementované v algoritmoch pre odhad, t.j., učenie neurónových sietí.
Čo sa týka vyhodnotenia modelu, pri určovaní významnosti vstupných premenných sa nemôžeme spoľahnúť na klasický \(t\)-test významnosti parametrov, pretože jednotlivé parametre, napr. váhy spojení nemajú jasne definovaný zmysel. Preto treba testovať významnosť všetkých parametrov zodpovedajúcich konkrétnemu vstupu spoločne. Jeden prístup testuje nulovosť kombinácie parametrov pomocou Waldovej testovacej štatistiky, detaily pozri (Franses a Van Dijk 2000). Ďalší prístup k ohodnoteniu významnosti vplyvu konkrétnej vstupnej premennej \(X_{t-i}\) na výstupnú poskytuje tzv. analýza senzitivity, v ktorej sa zafixujú hodnoty ostatných prediktorov, napr. na strednej hodnote, a skúmajú sa zmeny \(X_t\) pre rôzne hodnoty \(X_{t-i}\). S tým súvisí jednoduché posúdenie pomocou derivácie \(\frac{\partial F(\Omega_{t-1};\hat\theta)}{\partial X_{t-i}}\).
Nemenej dôležitým je vyhodnotenie modelu na základe jeho predpovednej schopnosti. Predpovede pomocou ANN sa vypočítajú analogicky ako z modelov SETAR či STAR, pozri Sekcia 8.10. Keďže však u takéhoto modelu typu black-box treba počítať so zvýšeným rizikom overfiting-u, je potrebné výber modelu poistiť aj inými metódami, obzvlášť vtedy, ak má model slúžiť na predpovedanie. Zvyšovaním počtu neurónov v skrytej vrstve sa stáva, že niektoré sú vyhradené na zachytenie šumu či jednorázových udalostí ako napr. odľahlých pozorovaní. Potom sa stáva, že takéto neuróny sa aktivujú aj počas obdobia evaluačnej vzorky a tak predpovedajú odľahlé hodnoty, ktoré tam nie sú. Rovnováhu medzi popisnou a predpovednou schopnosťou ovplyvňuje aj nastavenie tlmiacich koeficientov (weight decay) – ak sú príliš malé, zlepšuje sa flexibilita modelu, ale trpí tým kvalita predpovedí. Neexistuje jednoznačný postup, ako zabezpečiť túto rovnováhu a teda ako nastaviť počet skrytých neurónov a tlmiacich koeficientov, no vo všeobecnosti sa ako prevencia prehnanej komplexnosti modelu používa tzv. metóda nazývaná cross-validation. Pri nej sa trénovacia vzorka rozdelí na odhadovaciu a testovaciu, potom parametre ANN sa odhadujú pomocou pozorovaní z odhadovacej vzorky no zároveň sa v každej iterácii zaznamenáva aj súčet štvorcov predpovedných chýb (alebo MSE) z testovacej vzorky. Odhadovací cyklus sa zastaví, akonáhle začne súčet štvorcov rásť, pretože od toho okamihu by neurónová sieť začala modelovať už iba šum a ďalšie netypické udalosti.
Pre úplnosť, inou metódou, ako sa poistiť proti neželanej predikcii outlierov, je vyšetriť, ktoré neuróny v skrytej vrstve sa aktivujú iba raz alebo veľmi zriedkavo. Tieto sa potom potenciálne môžu vynechať pri predpovedaní, resp. je možné nahradiť aktivačnú funkciu každého takého neurónu priemerom jej hodnôt. Ide o pomerne subjektívnu metódu.
11.5 Záverečné poznámky
Autori v (Franses a Van Dijk 2000) skúmali, nakoľko je ANN príbuzný modelom TAR, STAR, MSW či bilineárnemu. Ako vyplýva z toho, čo sme hovorili na začiatku, modely umelých neurónových sietí sú príbuzné modelom s režimami danými pozorovateľnou náhodnou premennou: napr. \(ANN_{ln}(p,1)\) zovšeobecňuje dvojrežimový STAR v tom, že prepínanie režimov je dané kombináciou všetkých prediktorov, na druhej strane ho zjednodušuje, pretože sa s režimom mení iba absolútny člen. Podobne napr. \(ANN_{ln}(p,2)\) sa veľmi podobá na štvor-režimový tzv. Nested STAR. Ďalej, nahradením logistickej aktivačnej funkcie indikačnou dostávame paralelu ANN so SETAR modelmi.
Čo sa však týka vzťahu ku MSW, tu nie je apriori jasné, ako by ich ANN mohli nahradiť, keďže do stochastického procesu vstupuje ďalší, nepozorovaný stochastický proces. Vo (Franses a Van Dijk 2000, Experiment 5.2 - 5.5) sú skúmané vzťahy ANN ku iným nelineárnym modelom aj experimentálne. Stručne zhrnuté, ANN môže dobre aproximovat SETAR/STAR aj bilineárny model (v zmysle schopnosti predpovedat, oproti AR), ale nie MSW ani GARCH. To však znamená, že model neurónových sietí by sa dal využiť na konštrukciu testu nelinearity všeobecnejšej, než je iba SETAR, alebo iba STAR, či inej. Jeden taký test je z rodiny portmanteu-ových testov (podobne ako Ljung-Box) a bližšie podrobnosti sa dajú nájsť opäť v (Franses a Van Dijk 2000).
Franses, Philip Hans, a Dick Van Dijk. 2000. Non-linear time series models in empirical finance. Cambridge University Press.
Kvasnička, Vladimír, Ľubica Beňušková, Jiří Pospíchal, Igor Farkaš, Peter Tiňo, a Andrej Kráľ. 1997. Úvod do teórie neurónových sietí. Bratislava: Iris. https://doi.org/ISBN 80-227-1645-6.
Fixný člen nemusí byť formálne súčasťou vstupnej vrstvy neurónovej siete, naviac môžu ho obsahovať aj ďalšie vrstvy, a to implicitne v prijímacej časti neurónov.↩︎
Model neurónu zo skrytej vrstvy - s kombináciou synapsií a aktivačnou funkciou (v pôvodnom zmysle iba skokovitou) - sa nazýva perceptrón.↩︎
Funkcia \(SSR(\theta)\) je v optimalizácii jedna z často používaných účelových (utility) funkcií. Keďže ide o minimalizačný problém, účelová funkcia sa zvykne nazývať aj stratovou (loss/cost function).↩︎

.png)